자료구조(Data Structure)
자료구조란?
데이터를 포함하고 저장하는 방법
자료를 '효율'적으로 접근 및 수정하기 위해 자료의 조직, 관리, 저장하는 것
자료구조와 알고리즘을 구분하는 방법이 있다면, 자료구조는 '데이터의 표현 및 저장 방법'을 뜻하자면, 알고리즘은 표현 및 저장된 데이터를 대상으로 하는 '문제의 해결 방법'을 초점으로 두고 있다. 즉, 자료구조적 측면을 잘 알고 있을 때 더 좋은, 더 효율적인 코드를 작성할 수 있다.
자료구조의 종류
선형구조 : 리스트 , 스택 ,큐
비선형구조 : 트리, 그래프
파일구조 : 순차파일, 색인파일, 직접파일
단순구조 : 정수, 실수, 문자, 문자열
알고리즘의 성능분석 방법
앞서말한, 자료구조와 알고리즘을 둘 다 잘 알고 있을 때 더 좋은 효과를 볼 수 있다. 같은 알고리즘이더라도 더 빠르고, 더 메모리를 적게 쓰는 코드일수록 더 높은 성능을 보일 수 있기 때문이다. 그렇다면, 알고리즘의 성능을 분석하는 요소가 무엇이 있을까?
시간 복잡도
시간복잡도(time complexity) : 알고리즘의 수행 시간, 즉 속도에 연관공간 복잡도
공간복잡도(space complexity) : 메모리 사용량에 대한 분석 결과사실, 2가지의 척도를 다 만족할 수 있어야 최적의 알고리즘이라고는 할 수 있지만, 우리는 '시간복잡도'에 초점을 더 둔다. 그렇기에 빅오 표기법이라는 것을 공부하는데, 이 다음에 설명해보도록 하겠다.
빅-오 표기법(Big-Oh Notation)
알고리즘을 시간 복잡도를 통해 계산할 때, 우리는 최선의 경우인(best case)와 최악의 경우(worst case)를 비교하여 계산할 수 있다. 여기서 주목해야할 점은 최선의 결과는 굳이 신경을 쓸 이유가 없다. 이미 평균적인 경우를 기준으로 볼 때, 대부분 만족할만한 결과를 보이는 것이 당연하고, 이를 통해 우리는 알고리즘의 시간 복잡도 계산하기는 쉽지 않기 때문이다.
그러면, 빅 오 표기법에 대한 개념을 알아볼까?
빅-오 표기법
T(n)을 한 알고리즘이 수행할 때 n의 값에 따라 수행하는 연산의 수를 나타내는 식이라고 가정해보자.
T(n)이 다항식으로 표현될 때, 최고차항의 차수가 빅-오가 된다.
그 이유를 알아보자면, 데이터의 수가 증가함에 따라 최고차항의 연산의
수가 가장 큰 영향을 미치기 때문이다. 대표적인 빅-오
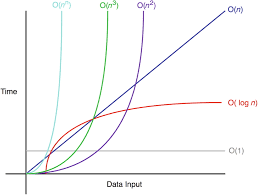
위 사진은 대표적인 빅-오를 그래프로 표현한 것이다. 하나씩 알아보도록 하자.
아래로 내려갈수록 n의 값의 커짐에 따라 무리가 되는 알고리즘이라고 생각하고 보면 좋을 것이다.
O(1) : 상수형 빅-오.
연산횟수가 데이터 수에 관계없이 고정인 유형의 알고리즘
O(log n) : 로그형 빅-오.
'데이터 수의 증가율' 에 비해 '연산횟수의 증가율'이 훨씬 낮은 알고리즘
O(n) : 선형 빅-오
데이터의 수와 연산횟수가 비례
O(nlogn) : 선형 로그형 빅-오
데이터의 수가 두배 늘 때, 연산횟수는 두배를 조금 넘게 증가하는 알고리즘을 의미, 생각보다 이에 해당하는 알고리즘이 많기에 알고 있으면 좋다.
O(n^2), O(n^3)
데이터의 수의 제곱, 세제곱에 해당하는 연산횟수를 요구하는 알고리즘
O(2^n) : 지수형 빅-오
사용하기에 매우 무리가 있는 비현실적인 알고리즘
이렇게 오늘은 자료구조의 기본 개념과 빅-오 표기법에 대하여 알아봤다. 다음 공부하고 있는 자료는 윤성우의 <열혈 자료구조> 책을 참고로 공부하고 있기에 목차와 매우 유사할 수 있다.
이 글을 시작으로, 군 전역 전 학습했던 부분의 복습과 더불어 나의 velog 활동을 다시 시작하려고 한다. 이번 6월은 자료구조를 기반으로 할 것 같고, 7월부터는 C++ 과 정보처리기능사 실기 공부를 같이 병행해서 할 것 같다.. velog를 활용하여 개발자의 꿈을 꾸는 코린이들 화이팅,,!!!
