NA는 값이 기록되지 않았거나 관측되지 않은 경우 데이터에 저장되는 값으로 ‘결측치’라고 부른다. 예를 들어, 인구 조사에서 특정 가구가 소득을 묻는 항목에 답을 하지 않았다면 해당 값은 NA로 기록될 것이다.
출처 : 더북(The book) - R을 이용한 데이터 처리 & 분석 실무
모든 데이터가 완벽할 순 없습니다. 위 더북(The book)출처의 인용문 내 예시와 비슷하게 고객 중 누군가가 대답을 하지 않거나 대답을 했어도 특정 내용만 빼고 말했을 수 있으니까요. 혹은 단순히 누락된 부분이 있을수도 있구요.
이렇게 기록상 없는 값을 NA, 즉 결측치(Missing Value)라고 합니다. 데이터를 처리하기에 앞서 NA 유무를 꼭 확인한 후 어떻게 손볼 지 결정해야 합니다. 오늘은 기본 및 여러 패키지로 유무 확인방법에 대해 알아보겠습니다. 🤓
🍎 항목
- 결측치 유무 확인
1) 유무 확인 - 기본, naniar 활용
2) 시각화 - naniar, VIM 활용 - 결측치 처리하기
1) 없애기 - 기본 활용
2) 대체하기 - dplyr 활용
🍎 naniar 패키지의 riskfactors 예제 데이터를 활용한 실습
- 결측치 유무 확인
1) 기본 함수 : 데이터 내 전체 결측치
# NA 여부를 행렬 형태로 반환
# NA 일 경우 TRUE, NA가 아닐 경우 FALSE
is.na(riskfactors) # 전체 결측치 반환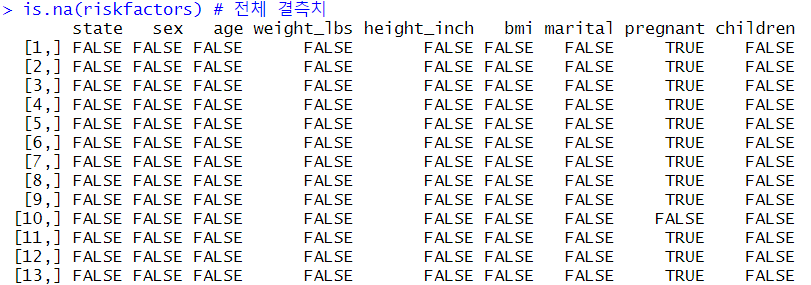
2) 기본함수 : 변수별 결측치 및 결측치의 합
is.na(riskfactors$smoke_stop) # 변수별 결측치
sum(is.na(riskfactors$smoke_stop)) # 변수별 결측치의 합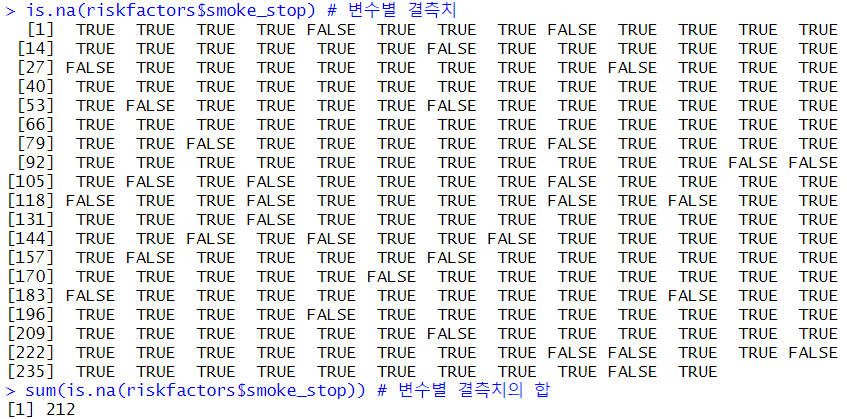
3) 기본함수 : 데이터 전체 행별 결측치 및 결측치의 합
# 각 행별로 NA가 포함된 행인지 아닌지를 반환
# NA가 있을 경우 FALSE, NA가 없을 경우 TRUE로 is.na()와는 반대
complete.cases(riskfactors)
# sum()함수를 통해 NA가 없는 행의 개수를 확인할 수 있다
sum(complete.cases(riskfactors))
# 반대로 NA가 있는 행의 개수를 알고 싶다면 앞에 !를 붙인다
sum(!complete.cases(riskfactors))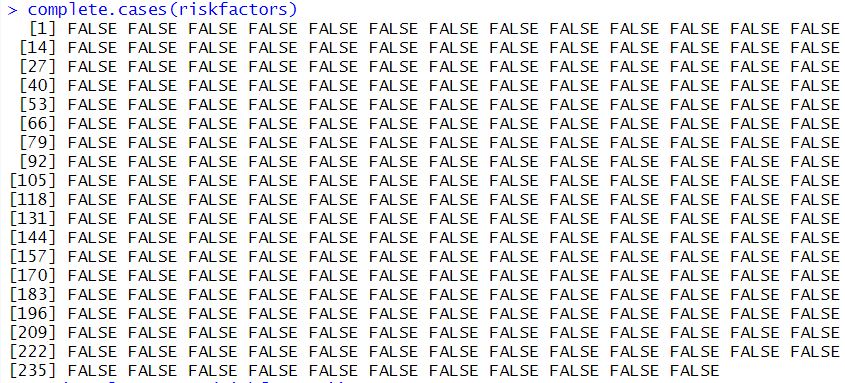

위 기본 함수를 활용한 결과를 보면 riskfactors 예제 데이터는 모든 행에 NA값이 있습니다. 🤮 그렇다면 각 행 혹은 열별로 NA값이 얼마나 있는지 한번에 확인해봐야겠는데, naniar 패키지를 사용하면 됩니다.
4) naniar 패키지 : 결측치 요약
library(naniar) #naniar 패키지를 불러옵니다.
naniar::miss_case_summary(riskfactors) # case : 행 기준
naniar::miss_var_summary(riskfactors) # variable : 변수 기준
4) naniar, VIM 패키지 : 결측치 시각화
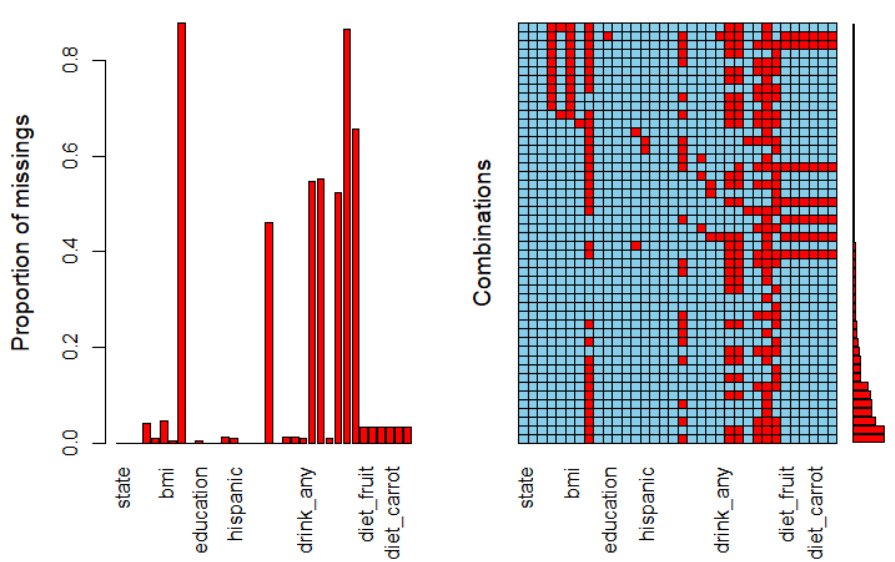
① naniar::vis_miss(riskfactors)

② naniar::gg_miss_var(riskfactors)
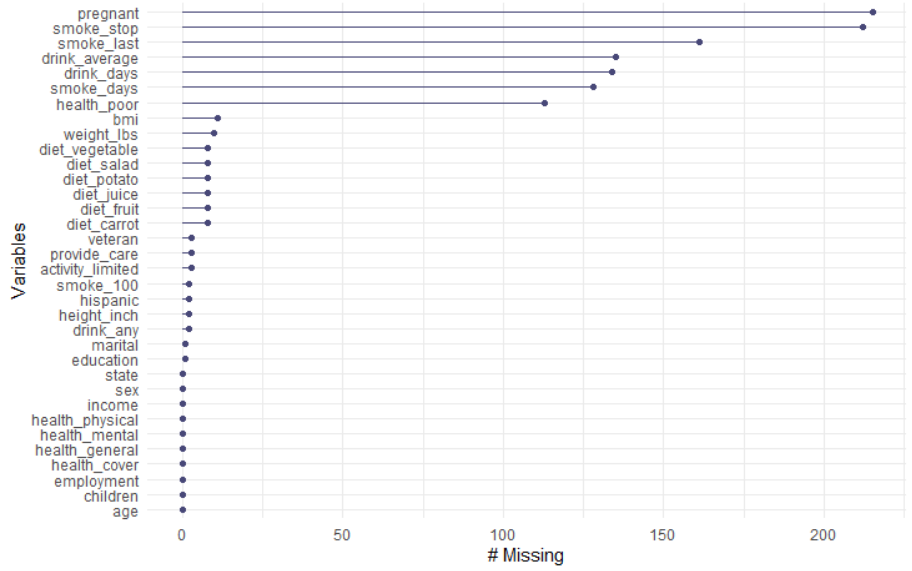
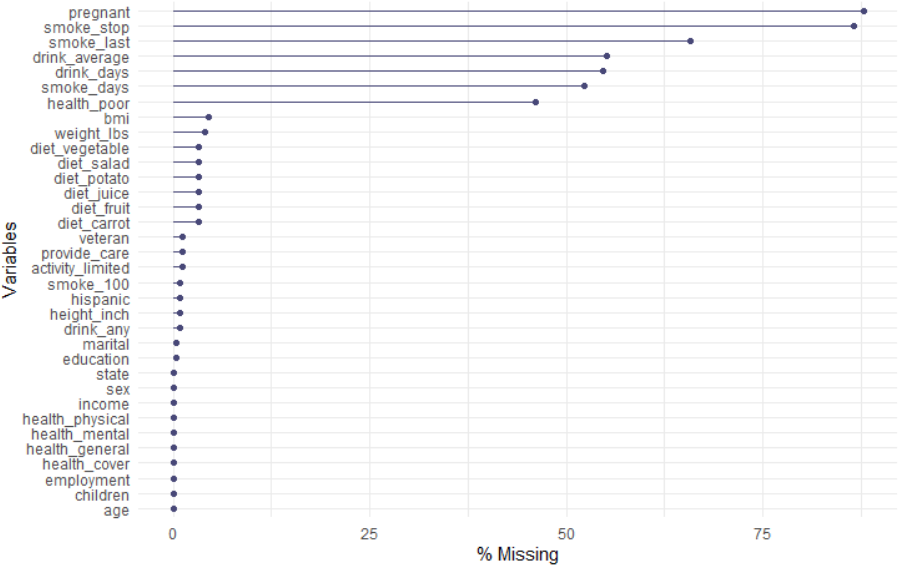
③ naniar::gg_miss_var(riskfactors, show_pct = TRUE)
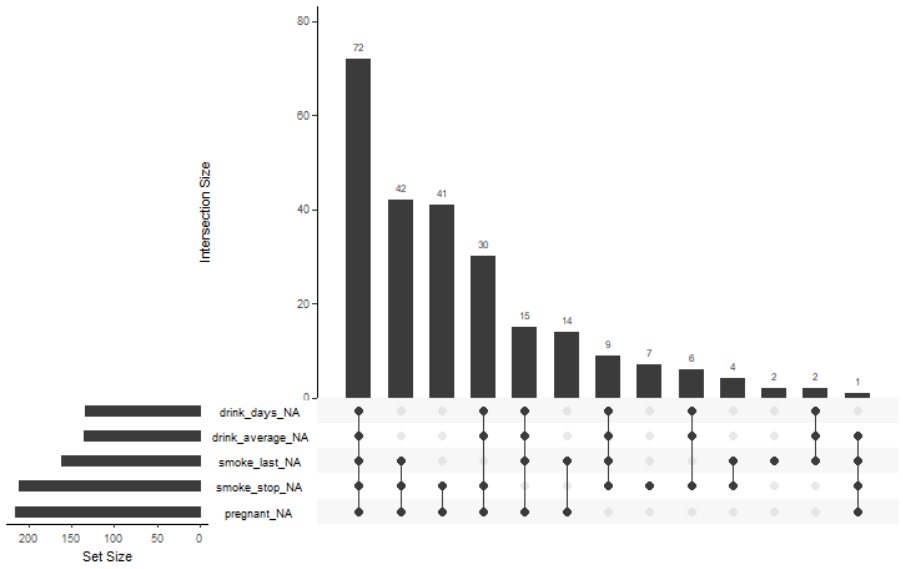
④ naniar::gg_miss_upset(riskfactors)
⑤ library(VIM); VIM::aggr(riskfactors)
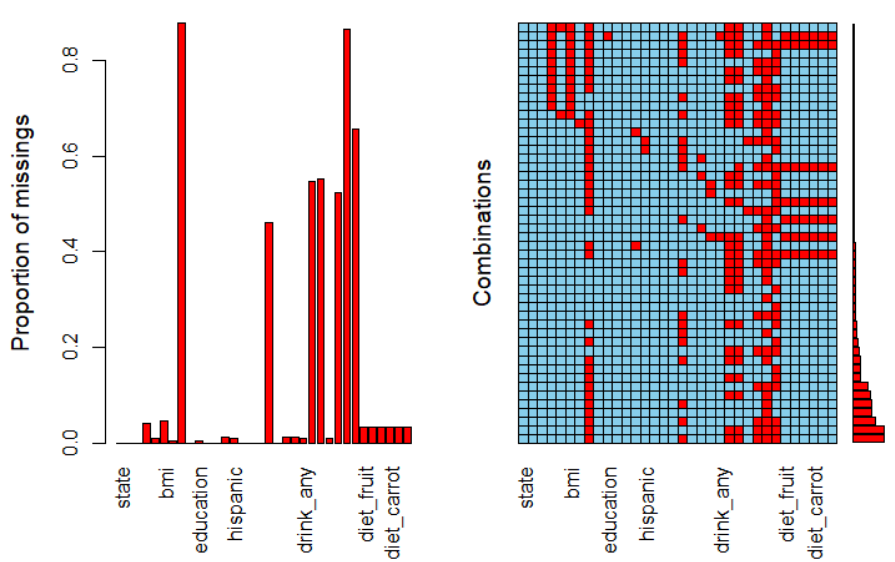
-
결측치 처리하기
결측치를 처리하는 방법은 데이터마다 다릅니다. 모두 없애거나 특정 값으로 대체할 수도 있고 NA가 너무 많은 변수가 있다면 변수 자체를 삭제할 수도 있습니다. 본 포스팅에서는riskfactors데이터에서 NA가 가장 많은 pregnant를 처리해보겠습니다.1) 삭제
# NA가 포함된 행 없애기
na.omit(riskfactors)
# 특정 변수 1개에 대해서만 NA가 포함된 행 없애기
riskfactors[complete.cases(riskfactors$pregnant), ]
# 특정 변수 2개 이상에 대해 NA가 포함된 행 없애기
riskfactors[complete.cases(riskfactors$pregnant, riskfactors$smoke_stop), ] 2) 대체
- 대체는 평균 외에도 중앙값, 최빈수, 0 등으로 설정할 수 있다
- dplyr 패키지의 mutate 함수는 새로운 열을 만들어 주거나 기존 열을 덮어씌울 수 있는 함수
- ifelse 함수를 활용하면 조건을 걸어 데이터 변형이 가능 ifelse(test = 조건, yes = 조건에 해당될 경우의 반환값, no = 조건에 해당되지 않은 경우의 반환값)
riskfactors %>%
dplyr::mutate(pregnant = ifelse(is.na(pregnant),
mean(pregnant, na.rm = TRUE),
pregnant)) # pregnant 변수의 값이 na일 경우 평균으로, 아닐 경우 그대로 유지 dlookr 패키지를 활용해서도 결측치를 확인할 수 있는데 컴퓨터 오류때문에 추가하지 못했어요..🤯 대신 시간이 될 때 dlookr 패키지의 막강한 EDA 기능까지 모두 아우르는 포스팅 해보겠습니다.
이 포스팅은 이부일 선생님의 현장강의를 많이 참고하였습니다.
