
워커 스레드에 대해 자세히 알아보기
원문: https://medium.com/@manikmudholkar831995/worker-threads-multitasking-in-nodejs-6028cdf35e9d
이 글은 시니어 엔지니어를 위한 고급 Node.js 시리즈의 네 번째 글입니다. 이 글에서는 워커 스레드가 무엇인지, 왜 필요한지, 어떻게 작동하는지, 그리고 워커 스레드를 사용하여 최상의 성능을 얻는 방법에 대해 자세히 설명하겠습니다. 공식 문서는 worker_threads에 있습니다. 시니어 엔지니어를 위한 고급 Node.js 시리즈의 다른 글은 아래에서 확인할 수 있습니다.
시리즈 로드맵
- V8 자바스크립트 엔진
- NodeJS의 비동기 IO
- Node.js의 이벤트 루프
- 워커 스레드 : Node.js의 멀티태스킹 (현재 글)
- Child Processes : Multitasking in NodeJS
- Clustering and PM2: Multitasking in NodeJS
- Debunking Common NodeJS Misconceptions
목차
- 워커 스레드가 필요한 이유
- 워커스레드가 무엇인지 이해하기 위한 전제 조건
- 동시성 vs 병렬성
- 프로세스와 스레드 이해
- 비유
- 그렇다면 워커 스레드란 정확히 무엇일까요?
- 내부에서 어떤 일이 발생하나요?
- 작업할 수 있는 모든 것은 무엇인가요?
- isMainThread, threadId
- 워커 이벤트
- 워커 옵션
- MessageChannel
- MessagePort & MessagePort 이벤트
- 스레드 간에 데이터를 전달하는 방법
- Atomics
- 포트 전송
- Array Buffer 전송
- SharedArray 버퍼를 사용한 데이터 공유
- 워커 스레드 고충
워커 스레드가 필요한 이유
서버는 CPU 집약적인 워크로드로 인해 빠르게 과부하가 걸릴 수 있습니다. 예를 들어, 두 개의 엔드포인트가 있다고 가정해 보겠습니다. 하나는 단순하고 CPU를 많이 사용하지 않는 작업을 수행하는 반면, 다른 하나는 완료하는 데 10초가 걸리는 복잡한 CPU 집약적인 작업을 처리합니다. 만약 서버가 CPU 사용량이 많은 요청을 처리하느라 바쁘다면, CPU를 많이 사용하지 않는 요청에는 즉시 응답하지 못할 수 있습니다. 이러한 문제는 Node.js의 황금률, 즉 이벤트 루프를 차단하지 않는다는 원칙을 위반했기 때문에 발생합니다.
Node.js는 싱글 스레드 아키텍처를 기반으로 하기 때문에 CPU 집약적인 작업에 적합하지 않은 것으로 잘 알려져 있습니다. 하지만 그렇다고 해서 CPU 집약적인 작업을 처리할 수 없거나, 멀티 스레드 아키텍처의 이점을 활용할 수 없다는 뜻일까요? 절대 아닙니다! 워커 스레드라는 영웅이 등장하여 해결책이 되어 줄 것입니다...

Node.js v10.5.0에서는 worker_threads 모듈을 통해 실험적인 컨셉의 워커 스레드를 도입했으며, 이는 Node.js v12 LTS부터 안정적인 기능으로 자리 잡았습니다.
워커스레드가 무엇인지 이해하기 위한 전제 조건

동시성 vs 병렬성
동시성은 싱글 코어에서 한 번에 여러 작업을 처리하는 것입니다. 병렬성은 멀티 코어에서 한 번에 여러 작업을 수행하는 것입니다. - Rob Pike
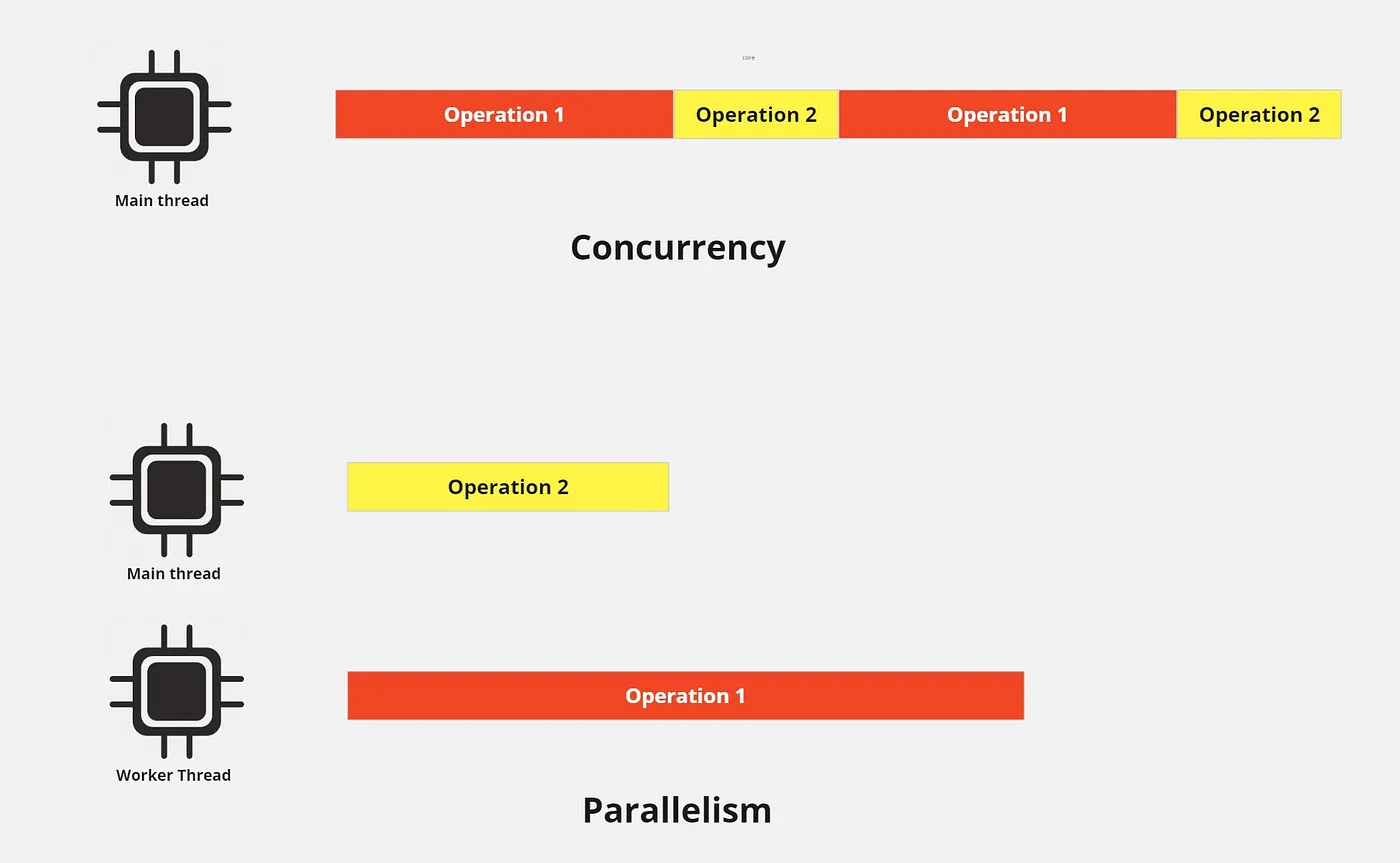
Operation 1 = CPU 집약적, Operation 2 = 비 CPU 집약적
먼저 워커 스레드의 핵심 개념, 즉 동시성이 아닌 병렬성을 이해하는 것부터 시작해 보겠습니다. 위 이미지에서 볼 수 있듯이, 싱글 스레드에서 여러 작업을 수행(동시성)하는 것은 동시에 실행(병렬성)하는 것보다 시간이 더 오래 걸립니다.
동시성 모델은 네트워크 통신, 파일/데이터베이스 읽기 및 쓰기와 같이 작업해야 하는 실제 데이터가 네트워크나 디스크에서 제공될 때까지 기다리는 IO 작업에서 유용합니다. 그리고 CPU나 스레드는 속도를 높이는 데 별다른 역할을 하지 못합니다. 따라서 대부분의 시간이 대기 시간에 소요됩니다. 따라서 스레드는 그 시간에 다른 작업을 할 수 있으므로 더 합리적입니다.
그러나 이 접근 방식은 CPU 집약적인 작업에는 적합하지 않을 수 있습니다. 작업 2는 비교적 빠르게 처리되었지만 싱글 코어/스레드만 활용했기 때문에 결국 시간이 더 오래 걸렸습니다. 멀티 스레드/코어를 활용함으로써 CPU 집약적인 작업은 워커 스레드에 위임하고, CPU 집약적이지 않은 작업은 메인 스레드에서 실행할 수 있었습니다.
NodeJS에서 I/O 작업은 별도로 처리되며, 작업이 완료되면 이벤트 루프가 해당 I/O 작업과 연관된 콜백을 마이크로태스크 큐에 추가합니다. 메인 스레드의 콜 스택이 비워지면 콜백이 콜 스택에 푸시된 후 실행됩니다. 여기서 중요한 점은, I/O 작업과 관련된 콜백 함수 자체는 병렬로 실행되지 않지만 파일을 읽거나 네트워크 요청을 보내는 작업 자체는 스레드의 도움을 받아 병렬로 처리됩니다. I/O 작업이 완료되면 관련 콜백은 메인 스레드에서 실행됩니다.
프로세스와 스레드 이해
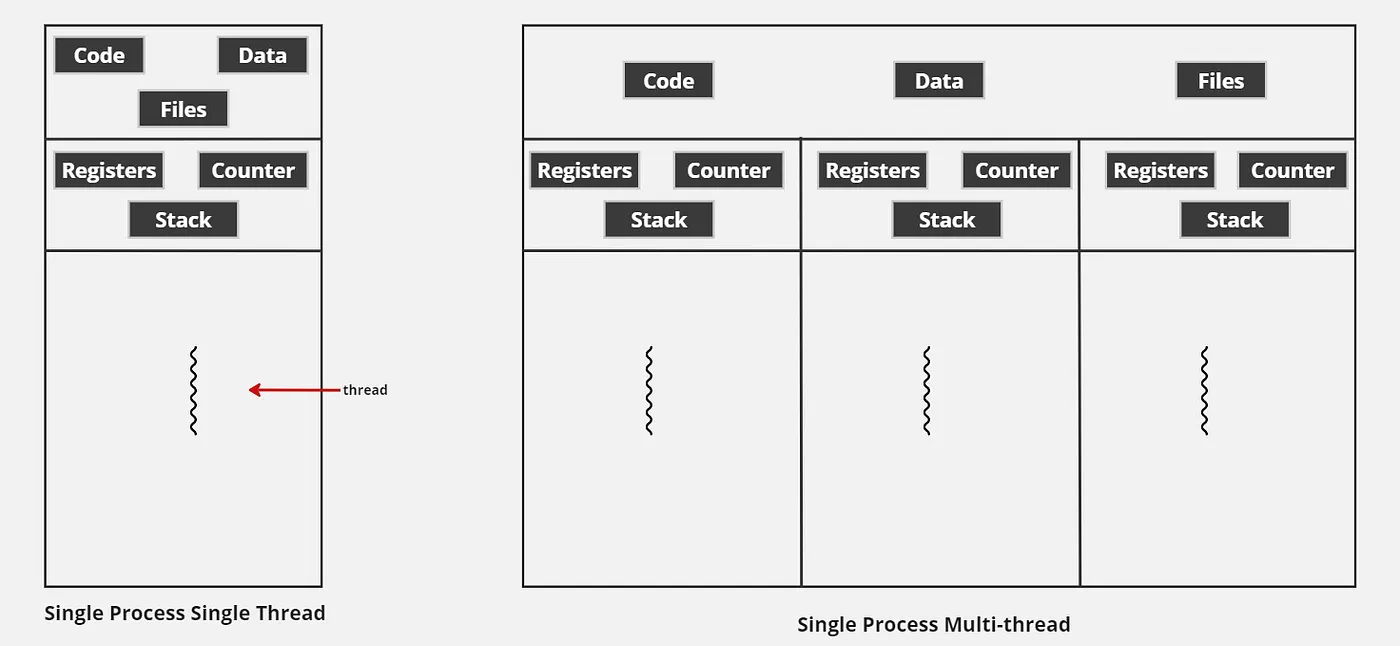
프로세스는 운영 체제에서 실행 중인 프로그램입니다. 각 프로세스는 자체 메모리가 있으며 실행 중인 다른 프로그램의 메모리를 보거나 접근할 수 없습니다. 하나의 프로세스는 한 번에 하나의 작업만 실행할 수 있습니다. 싱글 코어 시스템에서는 여러 프로세스가 동시 실행됩니다. 즉, 운영 체제가 일정한 간격으로 프로세스를 전환하면서 실행하는 방식입니다. 멀티 코어 시스템에서는 운영 체제가 각 코어에서 개별 프로세스를 동시에 실행하도록 스케줄링합니다.
스레드는 프로세스와 유사하게 한 번에 하나의 작업을 실행할 수 있습니다. 프로세스와 달리 스레드에는 자체 메모리가 없습니다. 대신 프로세스의 메모리 내에 존재합니다. 하나의 프로세스가 생성되면 여러 개의 스레드가 코드를 병렬로 실행할 수 있습니다. 또한 스레드 간에는 메시지 전달이나 프로세스 메모리의 데이터 공유를 통해 서로 통신할 수 있습니다. 이러한 특성 덕분에 스레드는 프로세스보다 가볍습니다. 새로운 스레드를 생성할 때 운영 체제로부터 추가적인 메모리를 할당받을 필요가 없기 때문입니다. 스레드의 실행 방식은 프로세스와 유사한 동작을 보입니다.
비유
간단히 말해 워커 스레드는 식당에서 여러 접시의 음식을 동시에 준비하기 위해 메인 셰프와 함께 추가 요리사를 두는 것과 같습니다.

그렇다면 워커 스레드란 정확히 무엇일까요?
이 섹션에서는 worker-threads 모듈을 사용하여 CPU 집약적인 작업을 다른 스레드로 위임함으로써 메인 스레드가 차단되는 것을 방지하는 방법을 다룹니다. 이를 위해 CPU 집약적인 작업을 수행할 worker.js 파일을 생성합니다. 그런 다음, parent.js 파일에서 worker-threads 모듈을 사용하여 스레드를 초기화하고, worker.js의 작업을 시작합니다. 이렇게 하면 해당 작업이 메인 스레드와 병렬로 실행됩니다. 작업이 완료되면 워커 스레드는 작업 결과가 포함된 메시지를 메인 스레드로 다시 보냅니다.
parent.js는 다음과 같습니다.
const {Worker} = require('worker_threads');
const worker = new Worker('./worker.js', {workerData: {num: 5}});
worker.on('message', (result) => {
console.log('square of 5 is :', result);
})
worker.on("error", (msg) => {
console.log(msg);
});
console.log('hurreyy')먼저 worker_threads 모듈을 import하고 Worker 클래스를 구조 분해 할당합니다. new 키워드를 사용하여 Worker의 인스턴스를 생성하고, 인자로 worker.js 파일 경로를 전달하여 Worker를 호출합니다. 이렇게 하면 새로운 스레드가 생성되며 worker.js 파일의 코드가 다른 코어의 스레드에서 실행되기 시작합니다.
그 다음에는 on("message") 메서드를 사용하여 worker 인스턴스에 이벤트를 추가하고 메시지 이벤트를 수신하도록 설정합니다. worker.js 파일에서 결과가 포함된 메시지를 수신하면 메서드의 콜백에 매개 변수로 전달되고, 콜백은 CPU 집약적인 작업의 결과가 포함된 응답을 사용자에게 반환합니다.
다음으로, on("error") 메서드를 사용해서 worker 인스턴스에 또 다른 이벤트를 추가하여 오류 이벤트를 수신하도록 설정합니다.
worker.js는 다음과 같습니다.
const {parentPort, workerData} = require('worker_threads');
parentPort.postMessage(workerData.num * workerData.num)첫 번째 줄에서 worker_threads 모듈을 불러오고 parentPort 클래스를 추출합니다. 이 클래스는 메인 스레드로 메시지를 전송할 수 있는 메서드를 제공합니다. WorkerData에는 스레드가 초기화될 때 메인 스레드에서 전달된 데이터가 포함됩니다. 그런 다음, parentPort 클래스의 postMessage() 메서드를 호출하여 CPU 집약적인 작업의 결과(예: 제곱값)를 포함한 메시지를 메인 스레드로 전송합니다.
node parent.js를 실행하면 아래와 같은 출력이 표시됩니다.
hurreyy
square of 5 is : 25내부에서 어떤 일이 발생하나요?
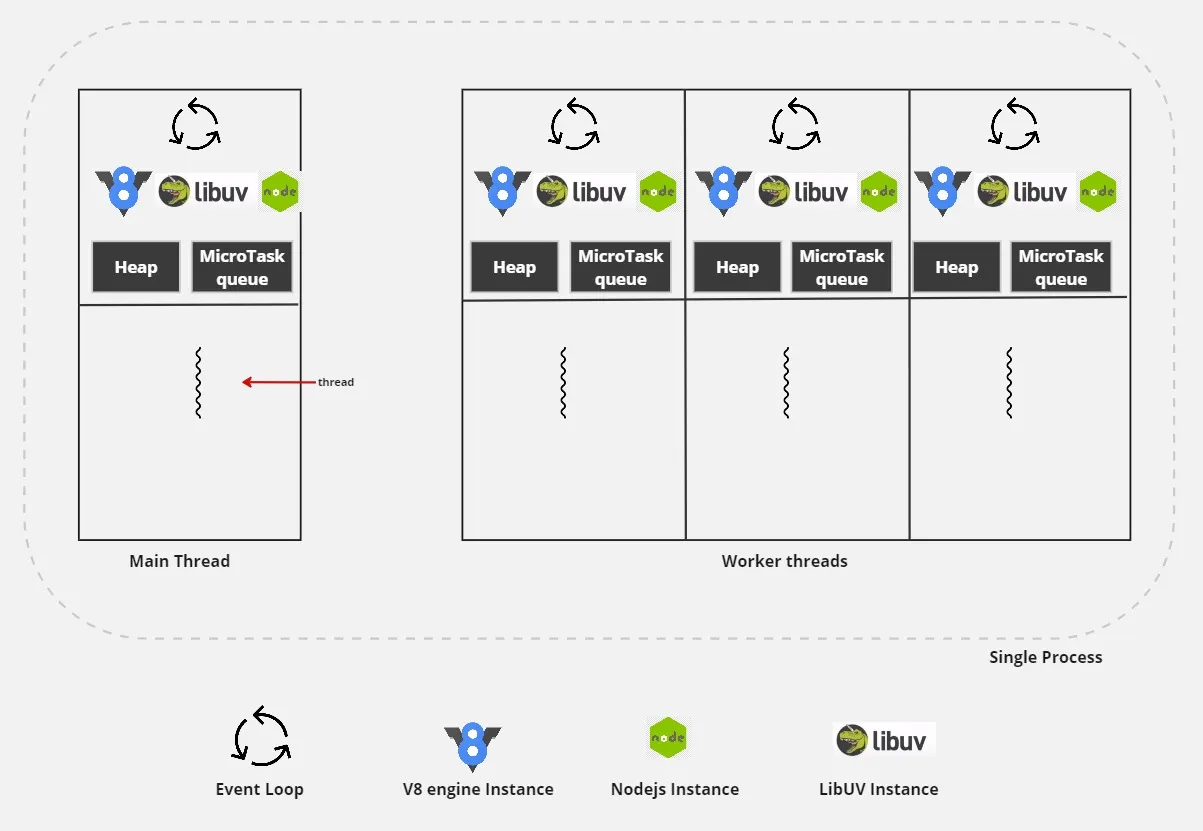
Node.js 프로세스가 시작될 때 하나의 프로세스, 하나의 스레드, 하나의 이벤트 루프, 하나의 V8 엔진 인스턴스, 하나의 Node.js 인스턴스로 시작된다는 것은 이미 알고 계실 것입니다. 메인 스레드와 마찬가지로 각 워커는 동일한 프로세스 내에 자체 V8, node, libuv 인스턴스 및 이벤트 루프의 인스턴스를 갖게 됩니다.
V8 분리(V8 isolate)란 크롬 V8 런타임 내의 독립적인 엔티티를 의미합니다. 자체 JS 힙과 마이크로태스크 큐를 가지고 있습니다. 이 독특한 설정 덕분에 모든 Node.js 워커는 다른 워커와 완전히 격리된 상태에서 자바스크립트 코드를 실행할 수 있습니다. 그러나 이러한 격리에는 대가가 따르는데, 워커는 서로의 힙에 직접 접근할 수 없습니다. 따라서 각 워커는 다른 워커 및 상위 워커의 이벤트 루프와 독립적으로 작동하는 자체 libuv 이벤트 루프를 유지합니다.
워커 스레드를 사용하면 특정 시점에서 스레드가 종료될 수 있으며 반드시 부모 프로세스가 종료되는 것을 의미하는 것은 아닙니다. 워커에 의해 할당된 리소스가 워커가 종료된 후에도 남아 있는 것은 좋은 방법이 아니며, 메모리 누수가 발생하므로 이를 방지해야 합니다. 우리는 Node.js를 자체적으로 내장하고, Node.js에 새로운 스레드를 생성한 다음 해당 스레드 내에 새 Node.js 인스턴스를 생성할 수 있는 기능을 제공하여 본질적으로 동일한 하나의 프로세스 내에서 독립적인 스레드를 실행하고자 합니다.
worker_threads 구현은 여러 개의 독립적인 자바스크립트 워커를 사용할 수 있도록 하여 애플리케이션에서 동시성을 제공하며, 워커와 부모 워커 간의 통신은 Node.js에서 처리됩니다. 메인 프로그램과 워커 "스레드" 간에 암묵적인 메모리 공유는 없습니다. 대신 이벤트 기반 메시징 시스템이 제공되므로 프로세스 간에 값을 교환할 수 있습니다.
각 워커는 메시지 채널을 통해 상위 워커와 연결됩니다.
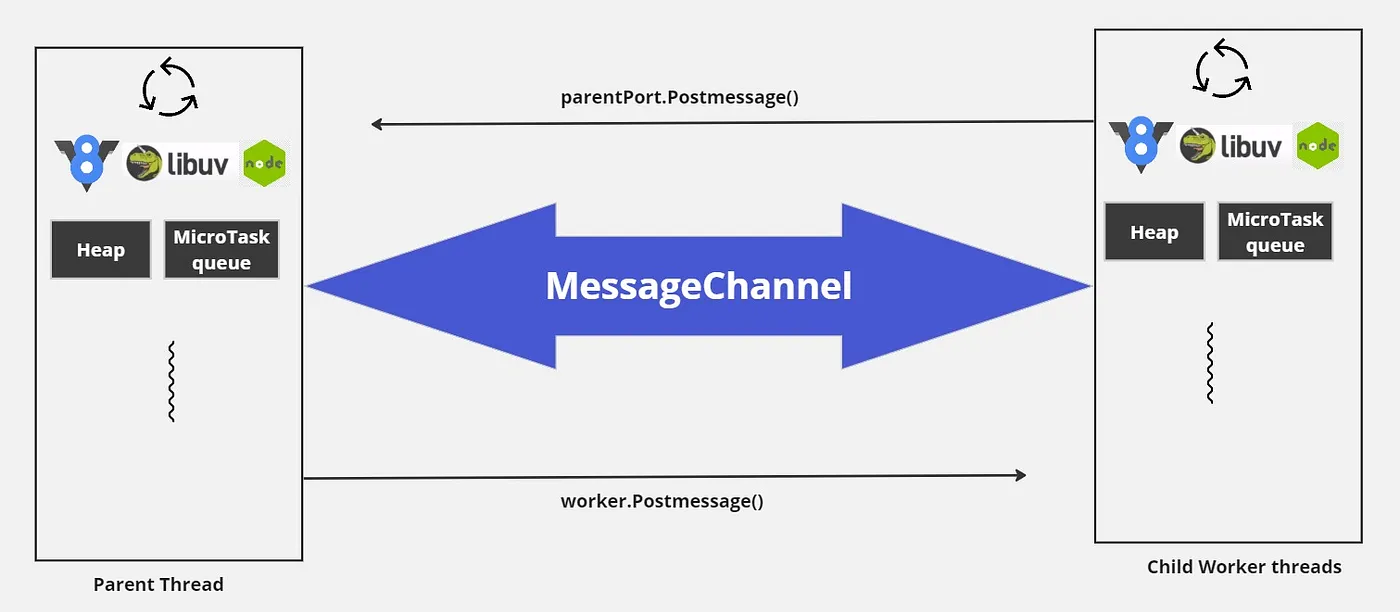
워커 스레드는 백그라운드에서 두 가지 단계로 작동합니다. 첫 번째 단계는 워커 인스턴스가 생성되고 부모 워커와 자식 워커 간의 초기 통신이 설정되는 워커 초기화입니다. 이를 통해 부모 워커에서 자식 워커로 워커 메타데이터를 전송할 수 있습니다.
초기화 메타데이터란 무엇인가요? 워커 실행 스크립트가 워커를 시작하기 위해 필요한 정보로, 워커로 실행할 스크립트의 이름, 워커 데이터 및 추가 세부 정보 등이 있습니다. 이 예제에서 초기화 메타데이터는 다음과 같은 메시지일 뿐입니다. 헤이 워커, worker-simple.js를 워커 데이터 {num: 5}와 함께 실행해 줄 수 있나요?
두 번째 단계는 워커 실행으로, 사용자가 제공한 workerData와 부모 워커가 제공한 기타 메타데이터를 사용하여 사용자의 워커 자바스크립트 스크립트가 실행됩니다. 이 단계에서 새로운 v8 인스턴스가 생성되어 워커에 할당되며 libuv가 자체 이벤트 루프와 함께 초기화됩니다.이후, 초기화 메타데이터가 읽혀지고 worker.js가 실행됩니다.
작업할 때 무엇을 사용할 수 있나요?
isMainThread, threadId
새로운 워커 파일을 생성하지 않고 싶다면 워커 인스턴스화를 할 때, __filename을 스크립트 경로로 전달하면 현재 파일 자체가 워커로 사용됩니다. 그리고 isMainThread를 사용하면 메인 스레드와 워커 스레드에서 실행할 로직을 분리할 수 있습니다. 또한 인스턴스화된 객체는 고유한 threadId라는 프로퍼티를 갖습니다.
워커 이벤트
워커는 원하는 콜백에 연결할 수 있는 몇 가지 이벤트를 제공합니다.
-
message: 워커 스레드가
parentPort.postMessage()를 호출했을 때'message'이벤트가 발생합니다. -
exit: 워커가 중지되면
'exit'이벤트가 발생합니다. 워커가process.exit()를 호출하여 종료된 경우exitCode매개변수에는 전달된 종료 코드가 설정됩니다. 워커가 강제 종료된 경우exitCode매개변수는1이 됩니다. 이것은 모든Worker인스턴스에서 발생하는 최종 이벤트입니다. -
error: 워커 스레드가 잡히지 않은 예외를 던지면
'error'이벤트가 발생합니다. 이 경우 워커가 종료됩니다. -
online:
'online'이벤트는 워커 스레드가 자바스크립트 코드 실행을 시작했을 때 발생합니다.
const {
Worker, isMainThread, parentPort, workerData,
} = require('node:worker_threads');
if (isMainThread) {
module.exports = function parseJSAsync(script) {
return new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: script,
});
worker.on('message', resolve);
worker.on('error', reject);
worker.on('exit', (code) => {
if (code !== 0)
reject(new Error(`Worker stopped with exit code ${code}`));
});
});
};
} else {
const { parse } = require('some-js-parsing-library');
const script = workerData;
parentPort.postMessage(parse(script));
}위의 예시는 각 parseJSAsync() 호출마다 새로운 Worker 스레드를 생성합니다. 실제로 이러한 종류의 작업을 처리할 때는 워커 풀을 사용하세요. 그렇지 않으면 워커를 만드는 데 드는 오버헤드로 인해 워커의 이점을 초과할 가능성이 높습니다.
워커 옵션
파일 이름과 함께 워커를 생성하는 동안 두 번째 인자로 특정 옵션을 보낼 수 있습니다. const worker = new Worker(__filename, OptionsObject) 일부 OptionObject 속성은 다음과 같습니다.
-
argv: 워커의
process.argv에 문자열화되어 추가될 인자의 목록입니다. 이것은 대부분workerData와 유사하지만, 스크립트에 CLI 옵션으로 전달된 것처럼 전역process.argv에서 값을 사용할 수 있습니다. -
workerdata: 워커 스레드에 전달하려는 데이터입니다. 이 데이터는 HTML structured clone 알고리즘을 사용하여 워커에서 복제됩니다.
-
transferList:
ArrayBuffer | MessagePort | FileHandle | X509Certificate | Blob과 같은 항목을 포함할 수 있는 배열 타입의 속성입니다. 만약workData에 하나 이상의MessagePort와 유사한 객체가 포함되어 있다면,transferList에 해당 항목을 반드시 지정해야 하며 그렇지 않으면ERR_MISSING_MESSAGE_PORT_IN_TRANSFER_LIST가 throw됩니다. 자세한 내용은 아래에서 설명합니다. -
env: 설정시, 워커 스레드 내부의
process.env의 초기 값을 지정합니다. 특수 값으로worker.SHARE_ENV를 사용하여 부모 스레드와 자식 스레드가 환경 변수를 공유하도록 지정할 수 있으며, 이 경우 한 스레드의process.env객체를 변경하면 다른 스레드에도 영향을 미칩니다. -
resourceLimits: 새로운 자바스크립트 엔진 인스턴스에 대한 선택적 집합입니다. 이 제한에 도달하면 해당 워커 인스턴스는 종료됩니다. 이러한 제한은 자바스크립트 엔진에만 영향을 미치며
ArrayBuffer를 포함한 외부 데이터에는 영향을 미치지 않습니다. 이러한 제한이 설정되어 있더라도 전역 메모리 부족 상황이 발생하면 프로세스가 중단될 수 있습니다. 일부 제약 조건은maxYoungGenerationSizeMb(메인 힙의 최대 크기(MB)),maxOldGenerationSizeMbcodeRangeSizeMbstackSizeMb입니다. -
name: 디버깅/식별을 위해 워커 제목에 추가할 수 있는 선택적 이름으로, 최종 제목 형식은 다음과 같습니다.
[worker ${id}] ${name}기본값은''입니다.
MessageChannel
스레드 간의 통신을 위해서는 통신 채널과 통신할 포트라는 두 가지 구성 요소가 중요합니다. 먼저 통신 채널, 즉 MessageChannel이 통신하기 전에 설정되어야 합니다.
MessageChannel은 비동기, 양방향 통신 채널입니다. new MessageChannel()을 호출하면 서로 연결된 [MessagePort](https://nodejs.org/api/worker_threads.html#class-messageport) 인스턴스를 참조하는 port1과 port2 속성을 가진 객체를 반환하며, 이 객체에는 자체 메서드가 없습니다. 기본적으로 port1과 port2는 하나의 채널 양 끝단에 위치한 두 개의 포트일 뿐입니다.
const { MessageChannel } = require('node:worker_threads');
const { port1, port2 } = new MessageChannel();
port1.on('message', (message) => console.log('received', message));
port2.postMessage({ foo: 'bar' });
// 출력: port1.on('message')` 리스너로부터 { foo: 'bar' }를 수신했습니다.한 포트는 메시지를 보내는 데 사용되고 다른 포트는 메시지를 받는 데 사용됩니다. 기본적으로 port1과 port2는 채널의 양쪽 끝에 불과합니다.

MessagePort & MessagePort 이벤트
이전에는 워커에서 부모로 메시지를 보내기 위해 parentPort.postMessage()를 사용했는데, 이는 parentPort와 Worker가 모두 MessagePort 클래스의 인스턴스이기 때문입니다. 이것은 콜백에 태그를 지정할 수 있는 postMessage와 message 및 close와 같은 이벤트를 제공합니다.
- message: 수신되는 모든 메시지에 대해 이벤트가 발생합니다.
- close: 채널의 양쪽 연결이 끊어지면 이벤트가 발생합니다.
const { MessageChannel } = require('node:worker_threads');
const { port1, port2 } = new MessageChannel();
// 출력:
// foobar
// closed!
port2.on('message', (message) => console.log(message));
port2.on('close', () => console.log('closed!'));
port1.postMessage('foobar');
port1.close();스레드 간에 데이터를 전달하는 방법
- 데이터 복제
- 스레드 간 데이터를 전달하는 방법에는 여러 가지가 있습니다. 기본적으로 이 데이터는 복제됩니다. 즉, 발신자와 수신자 모두 자신의 데이터 사본을 갖게 됩니다. 이 데이터는 Structured Cloned 알고리즘을 사용하여 복제됩니다. 전달되는 데이터가 깊숙이 중첩되어 있는 경우, 데이터를 복제하는 데 상당한 처리 능력이 필요하게 됩니다. 따라서 데이터 복사본을 보유하는 것이 항상 최선의 방법은 아닙니다.
- 데이터 전송
- 위의 단점을 극복할 수 있는 방법 중 하나는 데이터를 전송하는 것입니다. transferList 옵션을 사용하면 이 작업을 수행할 수 있습니다.
transferList를 사용하면 문자 그대로 송신자에서 수신자로 데이터를 전달합니다. 이렇게 하면 송신자 측에서 더 이상 해당 데이터에 접근할 수 없게 됩니다.transferList에는ArrayBuffer,MessagePort,FileHandle객체의 목록을 포함할 수 있습니다. 전송이 완료된 후에는 이 객체들을 송신 측에서 더 이상 사용할 수 없습니다 (비록 해당 객체들이value에 포함되어 있지 않더라도 마찬가지입니다). 현재로서는 네트워크 소켓과 같은 핸들 전송은 현재 지원되지 않습니다. (자식 프로세스를 통해서만 가능)
- 위의 단점을 극복할 수 있는 방법 중 하나는 데이터를 전송하는 것입니다. transferList 옵션을 사용하면 이 작업을 수행할 수 있습니다.
- 동일한 데이터 공유
- SharedArray 버퍼를 사용하여 송신자와 수신자 간에 동일한 데이터를 공유할 수 있습니다.
Atomics
공유 메모리는 워커나 메인 스레드에서 동시에 생성 및 업데이트될 수 있으며 이로 인해 경쟁 상태 및 동기화 문제가 발생할 수 있습니다. 이러한 문제를 방지하기 위해 Atomics를 사용할 수 있습니다. 공유 메모리가 사용되면 여러 스레드가 동일한 메모리 내 데이터를 읽고 쓸 수 있습니다. 원자적 연산(Atomic operations)은 각 연산이 완료된 후에야 다음 연산이 시작되도록 보장하며 연산이 중단되지 않도록 합니다. new 연산자를 사용하거나 Atomics 객체를 함수로 호출할 수 없습니다. Atomics의 모든 프로퍼티와 메서드는 Math 객체와 마찬가지로 static입니다.
Atomics.load(): 배열의 지정된 인덱스에 있는 값을 반환합니다. 인덱스에 대한 일종의 getter입니다.
Atomic.store(): 지정된 배열의 특정 인덱스에 저장합니다. 저장된 값을 반환합니다.
Atomics.and()/Atomics.or()/Atomics.sub()/Atomics.xor()/Atomics.add(): 비트 연산을 수행합니다.
Atomics.notify()/Atomics.wait(): 특정 조건이 참이 될 때까지 대기하는 방법을 제공하며, 일반적으로 블로킹 구조로 사용됩니다.
이제 다양한 방법으로 데이터를 전달해 보겠습니다.
포트 전송
일반적으로 포트를 전송 목록에 전달할 때 유용합니다. 이제 왜 그렇게 해야 하냐고 생각할 수도 있습니다. 이렇게 하면 메시지 채널을 재사용할 수 있습니다. 한번 시도해 봅시다.
parent.js는 다음과 같습니다.
const { Worker, MessageChannel } = require('worker_threads');
const { port1, port2 } = new MessageChannel()
const worker = new Worker('./worker.js')
port1.on("message", msg => {
console.log(`Message from worker----> ${msg}`)
})
worker.postMessage({ port: port2}, [port2])worker.js는 다음과 같습니다.
const {parentPort} = require('worker_threads');
parentPort.on("message", msg => {
msg.port.postMessage('Sent Hi from using transfered port')
})출력되는 메시지는 Message from worker — → Sent Hi from using transfered port 입니다.
Array Buffer 전송
Array Buffer는 고정된 길이와 연속적인 메모리 영역을 가지며 한 번 선언된 길이는 변경할 수 없습니다. 일반 배열처럼 내부의 값에 직접 접근할 수 없으며, 이를 위해 Data View라는 것이 필요합니다. Data View는 선언된 Array Buffer를 어떤 방식으로 바라보는지에 따라 달라집니다.
예를 들어, 16 바이트 크기의 Array Buffer(16 바이트 === 128 비트)를 선언한다고 가정해 보겠습니다.
const arrayBuffer = new ArrayBuffer(16)
이제 이 128 비트를 어떤 방식으로 바라볼 것인지에 따라 다르게 해석할 수 있습니다.
-
128 비트를 8비트 * 16개 블록, 즉 8비트 정수 배열로 해석할 수 있습니다.
const dataview = new Int8Array(arrayBuffer, 0, 16) -
128 비트를 16비트 * 8개 블록, 즉 16비트 정수 배열로 해석할 수 있습니다.
const dataview = new Int16Array(arrayBuffer, 0, 8) -
128 비트를 32 비트 * 4개 블록, 즉 32비트 정수 배열로 해석할 수 있습니다.
const dataview = new Int32Array(arrayBuffer, 0, 4)
이처럼 Int8Array, Int16Array, Int32Array, BigInt64Array 등은 타입 배열(Array Buffer 내부 데이터를 다양한 방식으로 해석하고 표현하는 방법)이라고 합니다.
parent.js는 다음과 같습니다.
const { Worker } = require('worker_threads');
const worker = new Worker('./worker.js')
const arrayBuffer = new ArrayBuffer(16)
const dataview = new Int8Array(arrayBuffer, 0, 16) // all 0 by default
console.log('In Parent Before Transfer' + dataview)
worker.postMessage(dataview, [dataview.buffer])
// console.log('In Parent After Transfer' + dataview)worker.js는 다음과 같습니다.
const {parentPort} = require('worker_threads');
parentPort.on("message", msg => {
console.log('In worker after transfer' + msg)
})출력은 다음과 같습니다.

따라서 이것은 데이터가 전송되었음을 증명합니다.
parent.js의 마지막 줄에서 주석을 제거하면 parent.js가 이미 전송된 Array Buffer에 접근할 수 없음을 증명하는 다음 오류가 발생합니다.

SharedArray 버퍼를 사용한 데이터 공유
이제 이 Array Buffer를 전송해 보겠습니다.
parent.js는 다음과 같습니다.
const { Worker } = require('worker_threads');
const worker = new Worker('./worker.js')
const sharedArrayBuffer = new SharedArrayBuffer(16)
const dataview = new Int8Array(sharedArrayBuffer, 0, 16) // all 0 by default
console.log('In Parent Before Sharing' + dataview)
worker.postMessage(dataview)
console.log('In Parent After Sharing' + dataview)worker.js는 다음과 같습니다.
const {parentPort} = require('worker_threads');
parentPort.on("message", msg => {
console.log('In worker after Sharing' + msg)
})
이번에는 부모에서의 마지막 로그가 오류를 발생시키지 않습니다. 왜냐하면 데이터가 실제로 공유되고 있으며, 전송되거나 복제되지 않기 때문입니다.
워커 스레드 고충
-
Node.js 워커 스레드는 일반적인 스레드가 아닙니다. 다른 언어처럼 멀티스레드가 되려면 기본적으로 스레드가 동일한 상태를 공유해야 합니다. Node.js 워커 스레드는 자체 V8, libuv 인스턴스, 이벤트 루프 및 개별 힙을 보유하여 다른 워커 스레드와 독립적으로 작동합니다.
-
IO에 워커 스레드를 사용하는 것은 쓸모가 없습니다. 자체 V8 엔진으로 워커 프로세스를 생성하고 유지하는 데 드는 비용은 Node.js의 비동기 I/O 구현보다 훨씬 비효율적입니다.
-
워커 스레드는 프로세스를 생성하는 비용보다 성능 향상이 훨씬 클 것으로 예상되는 경우에 사용해야 합니다.
-
공유 워커 스레드 풀을 활용하면 비효율성을 줄이고 새로운 워커를 생성할 필요가 없습니다. 이러한 접근 방식은 시간과 리소스를 절약할 뿐만 아니라 워커 풀 관리도 간소화합니다. Piscina 및 Poolifier 같은 라이브러리는 워커 풀 관리의 복잡성을 처리하여 편리한 솔루션을 제공하므로 더 중요한 작업에 집중할 수 있습니다.
-
워커 스레드를 디버깅하는 것은 이벤트와 해당 워커, 그리고 그로 인한 결과 사이의 명확한 연결이 부족하기 때문에 상당히 어려울 수 있습니다. 단순히
console.log()문에만 의존하여 디버깅하는 것은 지루하고 오류가 발생하기 쉬운 과정이 될 수 있습니다. 하지만 보다 효과적인 진단 정보를 얻을 수 있는 해결책이 있습니다. 워커 풀에 AsyncResource를 연결하면 풀 내에서 발생하는 활동을 정확하게 추적할 수 있는 포괄적인 비동기 스택 추적을 얻을 수 있습니다. 이 귀중한 도구를 사용하면 특정 효과로 이어지는 전체 이벤트 흐름을 관찰할 수 있습니다. -
자식 프로세스를 사용할지 워커 스레드를 사용할지 혼란스러울 때는 항상 CPU 집약적인 작업에는 워커 스레드를 사용하고 앱을 확장하려는 경우, 자식 프로세스를 사용하는 것을 기억하세요.
-
코어 개수보다 더 많은 스레드를 생성하면 컨텍스트 스위칭에서 CPU 사용률이 낭비되므로 실제로 성능 향상에 큰 도움이 되지 않습니다. 그렇기 때문에 스레드 풀을 신중하게 사용해야 합니다.
-
Piscina, Bree, Poolifier, WorkerPool은 워커 스레드 모듈을 래핑하여 더 편리한 인터페이스나 고급 기능을 제공하는 인기 라이브러리들입니다.
참조
- https://blog.insiderattack.net/deep-dive-into-worker-threads-in-node-js-e75e10546b11
- https://betterprogramming.pub/a-deep-dive-into-the-node-js-thread-pool-a1f32a4f8628
- https://www.youtube.com/watch?v=-JE8P2TiJEg
- https://www.youtube.com/watch?v=P1sWw1bLyVg
- https://nodesource.com/blog/worker-threads-nodejs/
- https://www.digitalocean.com/community/tutorials/how-to-use-multithreading-in-node-js
- https://snyk.io/blog/node-js-multithreading-with-worker-threads/
- https://snyk.io/blog/node-js-multithreading-worker-threads-pros-cons/
- https://www.youtube.com/watch?v=kDr7YycaZ5E
- https://stackoverflow.com/questions/61831510/when-a-workerthread-is-created-in-nodejs-does-it-utilize-the-same-core-in-which
🚀 한국어로 된 프런트엔드 아티클을 빠르게 받아보고 싶다면 Korean FE Article을 구독해주세요!

node 동시성 관련 글 처음보는분들을 위한 토막상식:
libuv는 그럴듯한 기술용어가 되었지만 사실 그냥 유니콘 벨로시랩터라는 뜻입니다