
클러스터 및 PM2에 대해 자세히 알아보기
원문: https://medium.com/@manikmudholkar831995/clustering-and-pm2-multitasking-in-nodejs-c6b10249cfd4
이 글은 시니어 엔지니어를 위한 고급 Node.js 시리즈의 여섯 번째 글입니다. 이 글에서는 클러스터가 무엇인지, 왜 필요한지, 어떻게 작동하는지, 그리고 클러스터를 사용하여 최상의 성능을 얻는 방법에 대해 자세히 설명하겠습니다. 공식 문서는 Node.js Cluster에 있습니다. 시니어 엔지니어를 위한 고급 Node.js 시리즈의 다른 글은 아래에서 확인할 수 있습니다.
시리즈 로드맵
- V8 자바스크립트 엔진
- NodeJS의 비동기 IO
- Node.js의 이벤트 루프
- 워커 스레드 : Node.js의 멀티태스킹
- 자식 프로세스 : Node.js의 멀티태스킹
- 클러스터링 및 PM2: Node.js의 멀티태스킹 (현재 글)
- Debunking Common NodeJS Misconceptions
목차
- 클러스터링은 무엇이며 왜 필요한가요?
- 내부적으로 무슨 일이 일어나나요?
- 매우 낮은 수준에서는 무슨 일이 일어나나요?
- 프로세스 간에 워크로드를 효과적으로 분산하는 방법은 무엇인가요?
- 무엇을 가지고 작업할 수 있나요?
- 클러스터 모듈로 스케일링하기
- 예상치 못한 워커 종료로부터 복구하기
- 워커 스레드와 클러스터 중 어느 것이 더 좋나요?
- Node.js와 함께 PM2 클러스터 모드 사용하기
클러스터링은 무엇이며 왜 필요한가요?
Node.js는 싱글 스레드 아키텍처로 인해 CPU 집약적인 작업에 특화되어 있지 않다는 것이 잘 알려져 있습니다. 하지만 그렇다고 해서 이러한 작업에 활용할 수 없다는 의미는 아닙니다. 실제로 Node.js는 멀티 스레드 아키텍처를 활용하기 위해 워커 스레드를 사용하고, 멀티 프로세싱을 위해 자식 프로세스를 사용하는 등 CPU 집약적인 작업을 처리할 수 있는 몇 가지 옵션을 제공합니다. 워커 스레드는 CPU 집약적인 작업에 유용하지만, 프로세스 격리 측면에서는 최선의 선택이 아닐 수 있습니다. 반면에 자식 프로세스를 생성하는 것은 기본적으로 여러 프로세스 간 로드 밸런싱을 제공하지는 않지만 고려해볼 만한 옵션입니다. 하지만 걱정하지 마세요. 여기 영웅이 있으니까요. 바로 클러스터링입니다!

클러스터링은 여러 자식 프로세스 내에서 로드 밸런싱을 위한 솔루션을 제공함으로써 문제를 해결합니다. Node.js 프로세스 클러스터를 사용하면 애플리케이션 스레드 간에 워크로드를 분산할 수 있는 Node.js 인스턴스를 여러 개 실행할 수 있습니다.
클러스터 모듈을 사용하면 서버 포트를 공유하는 자식 프로세스를 쉽게 생성할 수 있습니다.
내부적으로 무슨 일이 일어나나요?
내부 구조는 비교적 단순합니다. 워커 프로세스는 child_process.fork() 메서드를 사용하여 생성되므로 IPC를 통해 부모와 통신하고 서버 핸들을 주고받을 수 있습니다.
모든 운영 체제에서 프로세스는 포트를 사용하여 다른 시스템과 통신을 설정할 수 있습니다. 즉, 할당된 포트는 해당 특정 프로세스만 사용할 수 있음을 의미합니다. 그렇다면 이러한 모든 프로세스가 어떻게 동일한 포트를 공유할 수 있을까요? 기본 프로세스는 수신자 역할을 하며 수신 요청을 지속적으로 모니터링하고 이를 워커 또는 포크된 프로세스에 위임합니다.
프로그램의 워커는 독립적인 프로세스이므로 다른 워커에 영향을 주지 않고 종료하거나 다시 시작할 수 있습니다. 활성 상태의 워커가 있는 한 서버는 연결을 계속 수락합니다. 그러나 모든 워커가 비활성 상태이면 기존 연결이 종료되고 새 연결이 거부됩니다. 한 가지 중요한 점은 Node.js가 워커 관리를 자동으로 처리하지 않는다는 점입니다. 대신 특정 요구 사항에 따라 워커 풀을 처리하는 것은 애플리케이션의 의무입니다.
매우 낮은 수준에서는 무슨 일이 일어나나요?
시스템 프로그래머라면 이 말을 들어보셨을 겁니다. fork()의 동작은 C 프로그래머에게 매우 익숙한 기능입니다. 기본적으로 fork() 시스템 콜이 호출되면 현재 프로세스가 복제됩니다. 자식 프로세스는 부모 프로세스로부터 열려 있는 파일, 네트워크 연결 및 메모리 데이터 구조를 상속받습니다. 효율성을 보장하기 위해 copy on write라는 기술이 사용됩니다. 즉, 쓰기 작업이 발생할 때까지 동일한 메모리 위치가 공유되며, 이 시점에서 각 포크된 프로세스는 자체 복사본을 갖게 됩니다. 프로세스가 포크되면 서로 격리됩니다.
프로세스 간에 워크로드를 효과적으로 분산하는 방법은 무엇인가요?
실제로 이를 달성하는 방법에는 두 가지가 있습니다.
첫 번째 방법은 Windows를 제외한 모든 플랫폼에서 기본적으로 사용되는 라운드 로빈 방식입니다. 이 방식에서는 기본 프로세스가 포트에서 연결을 수신하고 새 연결을 수락한 후 라운드 로빈 방식으로 워커에게 균등하게 분산합니다. 또한 특정 워커 프로세스에 과부하가 걸리지 않도록 지능적인 메커니즘도 통합되어 있습니다.
두 번째 방법은 기본 프로세스에서 수신 소켓을 생성한 다음 관심 있는 워커에게 전달하는 것입니다. 그러면 이러한 워커는 들어오는 연결을 직접 수락할 수 있습니다. 기본적으로 마스터 프로세스는 수신 소켓을 생성하고 이를 수신 연결을 직접 처리하는 워커에게 전달하는 역할을 담당합니다.
이론상으로는 두 번째 방법이 더 나은 것 같지 않나요? 그러나 현실은 이와는 거리가 멀 수 있습니다. 메인 프로세스는 단순히 워커 스레드를 포크하기만 하고 이러한 네트워크 요청을 프로세스에 분산하고 전달하는 것은 운영 체제에 맡깁니다. 운영 체제는 네트워크 부하를 분산하기 위해 설계된 것이 아니라 프로세스 실행을 예약하는 것이 주된 목적입니다. 따라서 대부분의 부하가 동일한 프로세스 일부에 의해 처리됩니다. 이러한 동작은 서로 다른 프로세스 간의 컨텍스트 전환을 최소화하는 것을 목표로 하기 때문에 운영 체제 스케줄러에 적합할 수 있습니다. 하지만 네트워크 요청에 대한 부하를 분산하는 데는 적합하지 않습니다. 그렇기 때문에 라운드 로빈 방식이 도입된 것입니다.
첫 번째 방법은 Windows를 제외한 모든 플랫폼에서 기본적으로 활성화되어 있습니다. cluster.schedulingPolicy 변수를 사용하여 전역적으로 수정할 수 있습니다. 이때, 상수 cluster.SCHED_RR (라운드 로빈) 또는 cluster.SCHED_NONE(운영 체제에서 처리)을 설정합니다.
요약하자면, 각 프로세스에는 자체 할당된 고유한 포트가 있지만 기본 프로세스는 여러 워커 간에 이 포트 공유를 효율적으로 관리하여 원활한 통신과 로드 밸런싱을 보장합니다.
무엇을 가지고 작업할 수 있나요?
일반적으로 많은 프로그램에서 따르는 패턴은 다음과 같습니다.
if(cluster.isPrimary) {
// fork()
} else {
//do work
}클러스터 모듈 사용법은 반복적인 패턴에 기반하고 있어 애플리케이션 인스턴스를 여러 개 실행하기가 매우 쉽습니다.
CPU 수를 검색하고 각 CPU에 대해 워커 프로세스를 포크하는 마스터 프로세스를 생성하고 각 자식 프로세스는 콘솔에 메시지를 출력하고 종료하는 간단한 예제를 살펴보겠습니다.
index.js는 다음과 같습니다.
const cluster = require('node:cluster');
const http = require('node:http');
const numCPUs = require('node:os').availableParallelism();
const process = require('node:process');
if (cluster.isPrimary) {
console.log(`Primary ${process.pid} is running`);
// 워커를 포크합니다.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// 워커는 모든 TCP 연결을 공유할 수 있습니다.
// 이 경우, HTTP 서버입니다.
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}$ node index.js
Primary 3596 is running
Worker 4324 started
Worker 4520 started
Worker 6056 started
Worker 5644 started각 요청은 서로 다른 PID가 포함된 메시지를 반환합니다. 이는 이러한 요청이 서로 다른 워커에 의해 처리되어 부하가 분산되고 있음을 의미합니다.
이전 글들을 읽었다면 워커 스레드와 비슷합니다. 프로그램을 실행하면 메인 프로세스가 가장 먼저 실행되고 isPrimary 속성이 true이므로 if 블록에서 CPU 수와 동일한 수의 하위 프로세스를 cluster.fork로 생성합니다. 그 후 이러한 하위 프로세스는 동일한 파일을 실행하지만 isPrimary는 false가 됩니다. 이를 통해 하위 프로세스에 대한 로직을 분리하여 작성할 수 있습니다.
isPrimary, isWorker
isPrimary, isWorker와 같은 플래그를 사용하면 현재 프로세스의 종류를 식별하는 데 도움이 됩니다.
cluster.schedulingPolicy
cluster.schedulingPolicy를 사용하면 현재 프로세스가 가져야 하는 스케줄링 정책의 종류를 설정할 수 있습니다. 스케줄링 정책은 라운드 로빈의 경우, cluster.SCHED_RR이거나 운영 체제에 맡기는 경우 cluster.SCHED_NONE입니다.
disconnect, error, exit, listening, message, online events
클러스터 모듈은 이벤트 기반이므로 마스터는 disconnect, error, exit, listening, message, online과 같은 이벤트를 수신할 수 있습니다. 이러한 이벤트는 cluster와 클러스터를 통해 생성하는 worker 프로세스 모두에 존재합니다.
클러스터 모듈로 스케일링하기
이전 예제에서 모든 워커 프로세스는 동일한 포트에서 수신 대기합니다. cluster 모듈은 파일 핸들과 소켓에 집합적으로 접근할 수 있는 여러 워커 프로세스를 실행하는 편리한 방법을 제공합니다. 이를 통해 워커 프로세스를 관리하는 마스터 프로세스 내에 Node.js 애플리케이션을 캡슐화할 수 있습니다. 워커 프로세스가 데이터베이스에 저장된 사용자 세션에 접근해야 하는 경우 프로세스 간에 통신을 설정할 필요가 없습니다. 모든 워커가 동일한 데이터베이스 연결에 접근할 수 있으므로 추가 설정 없이도 사용자 세션과 원활하게 상호 작용할 수 있습니다.
예상치 못한 워커 종료로부터 복구하기
동일한 애플리케이션의 여러 인스턴스를 시작하면 중복 시스템이 생성되어 어떤 이유로든 하나의 인스턴스가 다운되더라도 들어오는 요청을 처리할 수 있는 다른 인스턴스가 준비되어 있습니다. 어떤 경우든 워커 프로세스 중 하나가 충돌하더라도 서버가 함께 다운되지 않습니다. 나머지 워커와 메인 프로세스는 그대로 유지됩니다.
어떤 경우든 워커 프로세스가 종료되면 새 프로세스를 생성할 수 있어야 합니다. 이때 exit가 다음과 같이 유용하게 사용됩니다.
cluster.on('exit', (worker, code, signal) => {
console.log('worker %d died (%s). restarting...',
worker.process.pid, signal || code);
cluster.fork();
});마스터 프로세스 자체가 더 이상 존재하지 않게 된다면 어떻게 될까요? 마스터 프로세스가 이러한 시나리오를 방지하도록 단순하게 설계되었음에도 불구하고 충돌 가능성은 여전히 있습니다. 다운 타임을 최소화하려면
forever모듈 또는Upstart와 같은 프로세스 관리자를 사용하여 클러스터링된 애플리케이션을 감독하는 것이 좋습니다.
워커 스레드와 클러스터 중 어느 것이 더 좋나요?
Node.js의 각 워커 스레드에는 libuv와 같은 자체 기본 루프가 있습니다. 마찬가지로 클러스터링의 각 복제된 Node.js 프로세스에도 자체 기본 루프가 있습니다.
클러스터링은 들어오는 요청을 Node.js 서버의 여러 복사본에 분산하는 데 사용되는 기술로, 로드 밸런싱을 가능하게 합니다.
반면에 워커 스레드를 사용하면 단일 Node.js 프로세스가 시간이 오래 걸리는 함수를 별도의 스레드에 위임하여 기본 루프가 차단되지 않도록 할 수 있습니다.
어떤 접근이 더 적합한지는 해결하고자 하는 문제의 성격에 따라 달라집니다. 워커 스레드는 시간이 오래 걸리는 함수를 처리하는 데 적합하고, 클러스터링을 사용하면 서버가 요청을 병렬로 처리하여 더 많은 요청을 처리할 수 있습니다. 필요한 경우 시간이 오래 걸리는 함수에 대해 각 Node.js 클러스터 프로세스에 워커 스레드를 할당하여 두 가지 방법을 모두 활용할 수 있습니다.

Node.js와 함께 PM2 클러스터 모드 사용하기
클러스터 모듈이 있지만 자동 재시작 및 로드 밸런싱과 같은 다양한 작업을 관리해야 할 책임은 여전히 존재합니다. 그러나 PM2를 사용하면 이러한 세부 사항에 대해 걱정할 필요가 없습니다.
PM2에는 몇 가지 중요한 기능이 있습니다.
- 자동 재시작: Node.js 애플리케이션이 충돌하거나 오류가 발생하면 PM2가 자동으로 재시작합니다.
- 프로세스 모니터링: PM2는 로그를 저장하고, 리소스 사용량을 모니터링하고, Node.js 프로세스 상태를 추적하여 애플리케이션 상태를 추적합니다.
- 로드 밸런싱: PM2는 내장 모듈을 통해 로드 밸런싱을 간소화합니다.
- 무중단 배포: PM2는 애플리케이션을 다시 로드할 수 있어 배포 중 다운타임이 없도록 할 수 있습니다.
- 자동 시작: PM2는 실행 중인 프로세스의 상태를 저장하고 시스템 재부팅 시 자동으로 프로세스를 시작할 수 있습니다.
- 다중 애플리케이션 관리: PM2를 사용하면 다른 Node.js 프로세스를 실행하고 서버 리소스를 최적화할 수 있습니다.
PM2는 기본적으로 설치되어 있지 않으므로 별도로 설치해야 합니다.
npm install pm2 -g이전 예제를 가져와 클러스터 방식이 아닌 방식으로 축소하면 다음과 같습니다.
const http = require('http');
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);이제 sudo pm2 start index.js -i 4를 실행하기만 하면 됩니다.
여기서 index.js는 애플리케이션 이름이고 -i는 워커 수를 나타냅니다. PM2를 사용하여 4개의 워커가 생성되어 4개의 CPU 코어를 모두 활용합니다.
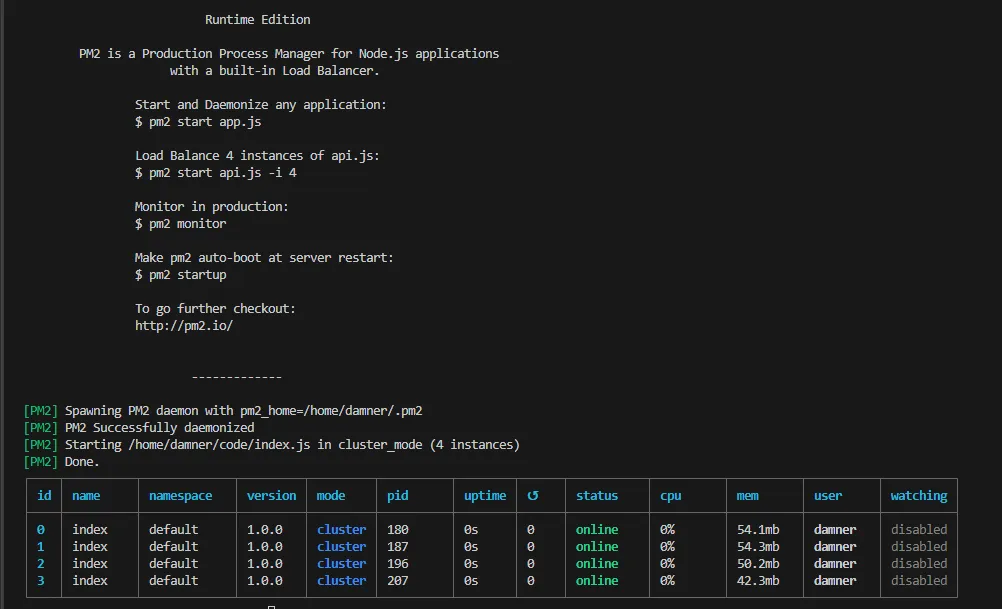
출력
PM2와 함께 "max" 옵션을 사용하면 사용 가능한 CPU 수를 자동으로 감지하고 시스템에서 가능한 최대 프로세스 수를 실행합니다.
sudo pm2 start index.js -i max또는
sudo pm2 start index.js -i 0또한 기존 실행 중인 클러스터에 워커를 추가해야 하는 경우 다음을 사용할 수 있습니다.
sudo pm2 scale index.js +1🚀 한국어로 된 프런트엔드 아티클을 빠르게 받아보고 싶다면 Korean FE Article을 구독해주세요!
