
개요
장고에서 로그를 발생시킨 다음 nosql인 MongoDB에 적재하기로 결정한 후,
Django에서 MongoDB까지 이어지는 파이프라인을 어떻게 만들어야 할지에 대한 고민이 있었다.
장고에서 몽고디비로 로그 데이터를 바로 쏘기보다는 데이터 유실 방지를 위해 Kafka로 중간 버퍼를 걸어두는 쪽이 효율적일 것 같아 Django - Kakfa - MongoDB와 같은 파이프라인을 생각해보았다.
만일 몽고디비가 있는 서버 다운이 일어나더라도 Kafka에 retention을 어느정도 걸어두면 몽고디비를 복구시킨 후 몽고에 다시 적재하면 로그 데이터 유실 걱정이 없겠다 싶어 위와 같은 파이프라인을 고려함
Kafka MongoDB Connector
Kafka Connect 정의
Kafka와 MongoDB를 연결해주는 것이 뭐가 있을까 하고 찾아보다 발견한 것이 Kafka Connect이다.
Kafka Connect
- 간단하게 말해 Kafka와 다른 시스템 간의 데이터를 주고 받기 위한 오픈소스 프레임워크이다.
- REST API를 활용해 Connector를 생성, 수정, 삭제할 수 있음!
- 두 가지 종류의 Connector 존재
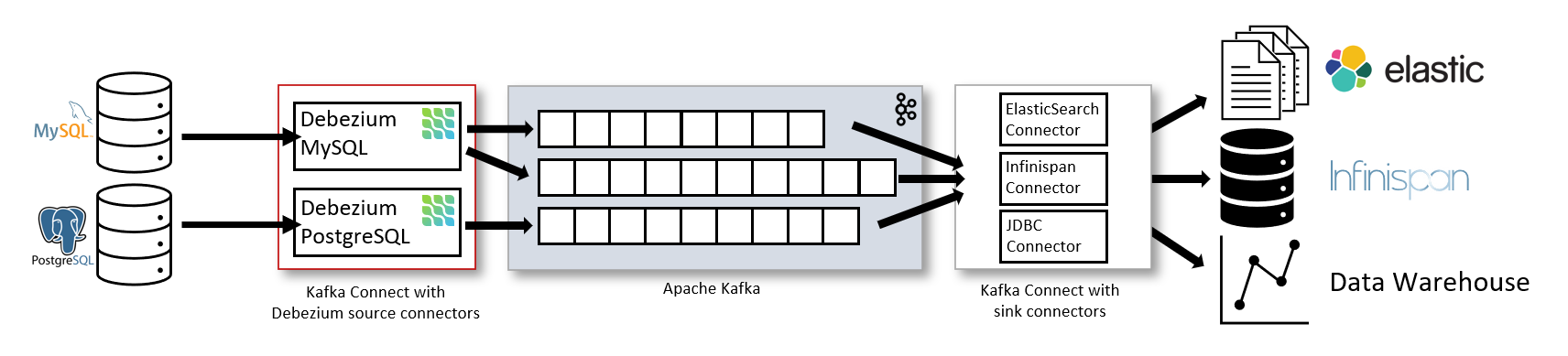
- Source Connector: 외부 시스템 -> Kafka
- Sink Connector: Kafka -> 외부 시스템
Kafka Connector 실습
먼저 confluent 사이트로부터 커넥터를 다운받아야 한다.
저는 들어가자마자 있는 다운로드 버튼을 통해 다운받고 kafka 서버에 옮겼습니다.
-
connector plugins을 모아둘 폴더 설정
-
저는 $KAFKA_HOME=/usr/local/kafka로 설정되어 있었고, connector plugins은 /usr/local/kafka/plugins/ 하위에 저장하였습니다! 참고하세요
# 커넥터 플러그인을 모아놓을 디렉토리 생성 cd /usr/local/kafka mkdir plugins sudo chown -R $USER:$USER /usr/local/kafka/plugins
-
로컬에서 다운받은 mongo-kafka-connect폴더를 서버로 전송
-
저는 ssh 통신을 5000번 포트로 열어주어 '-P 5000' 옵션을 추가해주었고 기본 포트인 22 포트로 열어주신 분들은 저 옵션을 안달아도 됩니다.
scp -r -P 5000 ./mongodb-kafka-connect-mongodb-1.8.1 ubuntu@[본인 ip]:/usr/local/kafka/plugins
-
Kafka connect에는 분산 모드, 단일 모드 둘 다 존재하지만 결국에는 분산모드로 구축할 것이라 connect-distributed.properties에 plugins 경로를 적어주었습니다.
vim $KAFKA_HOME/config/connect-distributed.properties ------ #line 23 # 본인 public ip 주소를 적어주세요 예시) 1.2.3.4:9092 bootstrap.servers=[public_ip]:9092 #line 34 key.converter.schemas.enable=false value.converter.schemas.enable=false #line 89 plugin.path=/usr/lib/jvm/java-11-openjdk-amd64,/usr/local/kafka/plugins ------
-
systemd에 등록
sudo vim /lib/systemd/system/kafka-connector.service ----- [Unit] Description=kafka-connector Documentation=https://kafka.apache.org// After=network.target kafka.target [Service] Type=simple User=ubuntu Environment="LOG_DIR=$KAFKA_HOME/logs/connector" ExecStart=/usr/local/kafka/bin/connect-distributed.sh /usr/local/kafka/config/connect-distributed.properties & TimeoutStopSec=180 Restart=no [Install] WantedBy=multi-user.target ----- # plugin 경로 추가 및 재기동 sudo systemctl stop kafka-connector.service sudo systemctl start kafka-connector.service # plugin 설치 확인 # 잘 설치되었다면 아래와 같이 설치된 플러그인 목록이 뜸 curl http://121.141.216.208:8083/connector-plugins | jq [ { "class": "com.mongodb.kafka.connect.MongoSinkConnector", "type": "sink", "version": "1.8.1" }, { "class": "com.mongodb.kafka.connect.MongoSourceConnector", "type": "source", "version": "1.8.1" }, ...
-
json파일을 만들어 Sink Connector를 생성해줍니다.
# connector 생성 mkdir $KAFKA_HOME/json # 새로운 파일 생성 vim $KAFKA_HOME/json/kafka-to-mongo.json ----- { "name": "mongoSink-sample", "config": { "connector.class":"com.mongodb.kafka.connect.MongoSinkConnector", # 일을 진행할 최대 업무자 수 "tasks.max":"2", # kafka topic "topics":"django_test", # mongodb ip, port(default: 27017) "connection.uri":"mongodb://[public_ip]:27027", # mongodb database "database":"test", # mongodb collection "collection":"table" } } # connector 등록 curl -X POST -H "Content-Type: application/json" \ --data @kafka-to-mongo.json http://[public_ip]:8083/connectors
-
커넥터 상태를 확인하여 잘 등록되었는지 봐야 합니다.
여기서 java 오류 등 오류가 난다고 뜨면 잘 등록이 안된 것. 오류 메세지를 잘 봐야 해요!!!# connector 이름 확인 curl [public_ip]:8083/connectors > ["mongoSink-sample"] # 커넥터 상태 확인 curl 121.141.216.208:8083/connectors/[본인이 설정한 커넥터 이름]/status | jq
-
커넥터 상태를 확인했을 때 다음과 같은 오류 발생한다면
Unexpected character (''' (code 39)): was expecting double-quote to start field name
-
직역한 그대로 따옴표('') 때문에 몽고에 안들어간다는 의미이므로 넣을 데이터의 형태를 따옴표('')로 감싸는 것이 아닌 쌍따옴표("")로 감싸는 형태로 바꿔주어 넣어줍니다.
-
{'example' : 'single quotation'} -> {"example" : "double quotation"}
import json dict = {'example' : 'single quotation'} # 포맷을 '(홑따옴표) 대신 "(쌍따옴표)로 변경 data = json.dumps(dict)
-
