
Zookeeper
폴더 생성
# Zookeeper 데이터 디렉토리 생성
# server1, server2에서 실행
sudo mkdir -p /usr/local/zookeeper/data
sudo mkdir -p /usr/local/zookeeper/logs
# server1의 경우, data2, logs2도 생성
sudo mkdir -p /usr/local/zookeeper/data2
sudo mkdir -p /usr/local/zookeeper/logs2
# Zookeeper 디렉토리 사용자 그룹 변경
sudo chown -R $USER:$USER /usr/local/zookeeperzoo.cfg
server1, server2 모두 실행해주세요.
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
아래 내용 수정 후 저장.
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
clientPort=2181
server.1=server1:2888:3888
server.2=server1:2889:3889
server.3=server2:2888:3888
server1에서만 추가로 설정. server 1에서는 zookeeper를 2대 설정해야 하므로, zoo.cfg와 zoo2.cfg로 설정파일을 2개 만들어준다.
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo2.cfg
아래 내용 수정 후 저장.
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data2
dataLogDir=/usr/local/zookeeper/logs2
clientPort=2182
server.1=server1:2888:3888
server.2=server1:2889:3889
server.3=server2:2888:3888myid 설정
# myid 파일 각각 편집
# 아래 내용 수정 후 저장(server1 - 1, 2/ server2 = 3 설정)
## server 1
sudo vim /usr/local/zookeeper/data/myid
1
sudo vim /usr/local/zookeeper/data2/myid
2
## server 2
sudo vim /usr/local/zookeeper/data/myid
3Hadoop 실행
# server1 zookeeper 실행
/usr/local/zookeeper/bin/zkServer.sh start zoo.cfg
/usr/local/zookeeper/bin/zkServer.sh start zoo2.cfg
# server2 zookeeper 실행
/usr/local/zookeeper/bin/zkServer.sh start zoo.cfg
# server1 zookeeper 초기화

hdfs zkfc -formatZK
# server1 journalnode 실행
hdfs --daemon start journalnode
# server2 journalnode 실행
hdfs --daemon start journalnode
# server1
hdfs namenode -format
# server1 journalnode 초기화
hdfs namenode -initializeSharedEdits
# server1의 NN, zkfc 실행 (server1 Active로 사용)
hdfs --daemon start namenode
hdfs --daemon start zkfc
# server1 datanode 실행
hdfs --daemon start datanode
# server2의 NN, zkfc 실행
hdfs namenode -bootstrapStandby
hdfs --daemon start namenode
hdfs --daemon start zkfc
# server2 datanode 실행
hdfs --daemon start datanode
위의 코드들은 맨 처음 실행할 때만 진행해주면 되고, 그 이후부터는
다음 명령어로 hadoop을 종료하고
stop-all.shhadoop을 실행하면 된다.
start-all.shhadoop 실행한 후 jps를 찍어보았을 때 다음과 같이 보이면 됩니다. 
hdfs 명령어들
Namenode, Datanodes 상태 확인. 데이터노드가 2대 살아있는 것을 볼 수 있다.
hdfs dfsadmin -report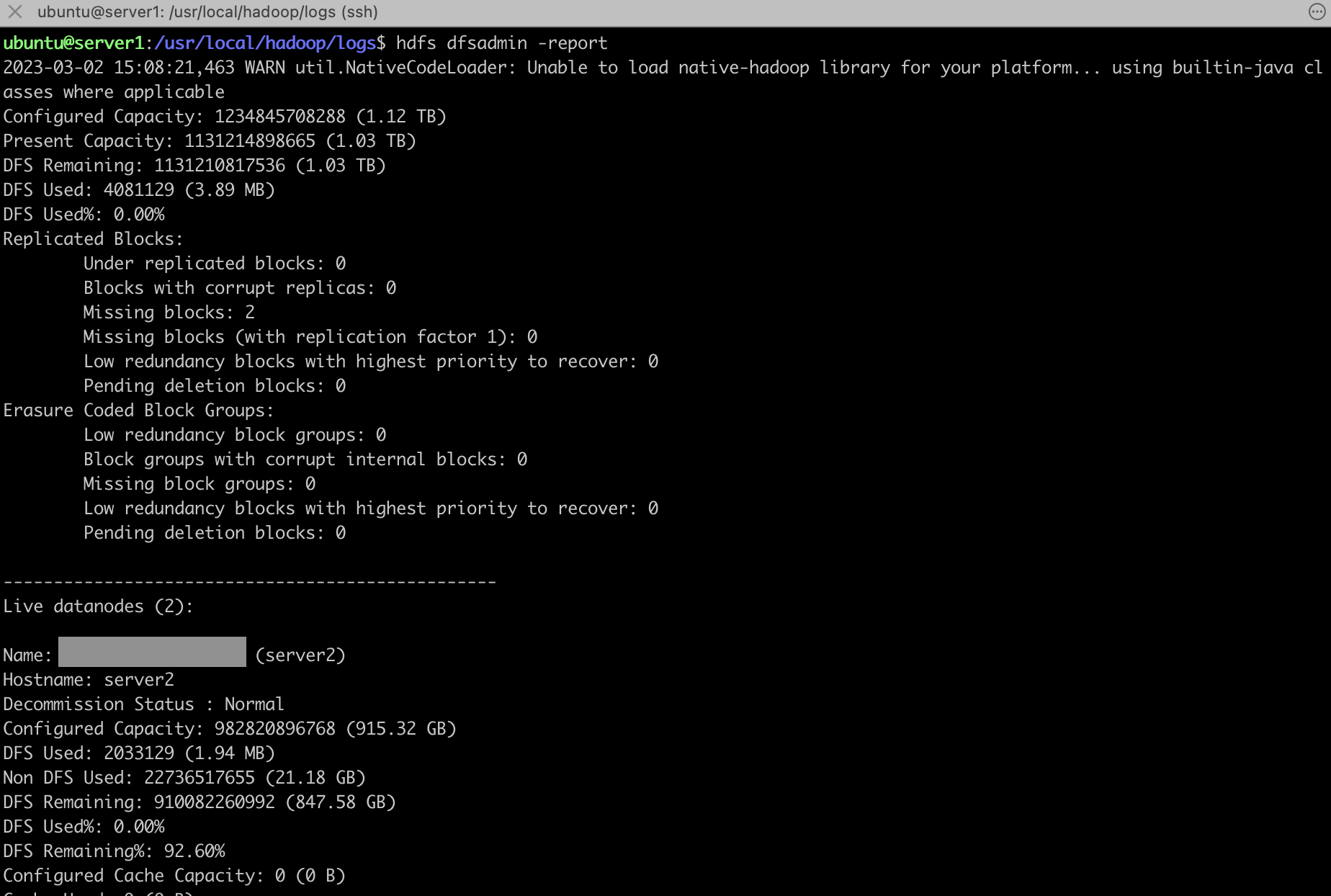
active, standby 상태 확인
hdfs haadmin -getAllServiceState
