워크로드 API 카테고리 개요
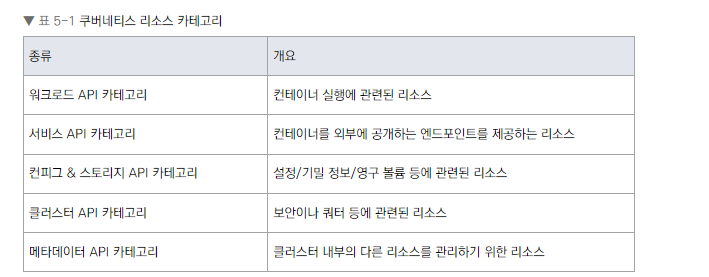
- 카테고리 개요
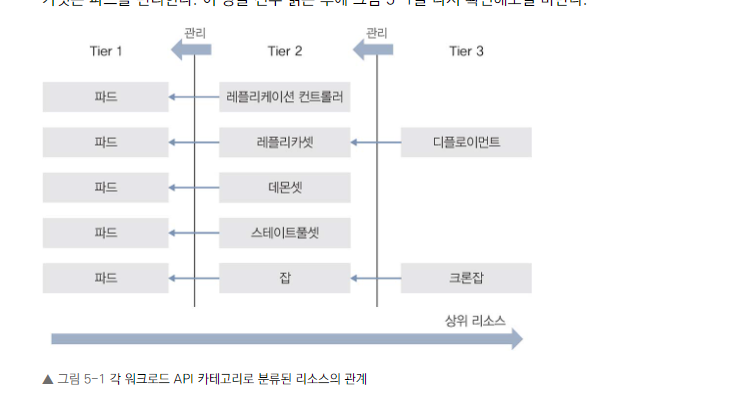
워크로드 API 카테고리 리소스
- 파드 (Pod)
- 레플리케이션 컨트롤러 (Replication Controller)
- 레플리카셋 (ReplicaSet)
- 디플로이먼트 (Deployment)
- 데몬셋 (DaemonSet)
- 스테이트풀셋 (StatefulSet)
- 잡 (Job)
- 크론잡 (CronJob)
이유: 이 리스트는 사용자가 직접 사용할 수 있는 주요 워크로드 리소스를 보여줍니다. 각 리소스는 특정 use case에 맞게 설계되었습니다.
워크로드 리소스의 계층 구조
- 파드가 최소 단위입니다.
- 상위 리소스가 하위 리소스를 관리하는 부모-자식 관계가 존재합니다.
- 예: 디플로이먼트 → 레플리카셋 → 파드
이유: 이 계층 구조는 쿠버네티스의 리소스 관리 방식을 이해하는 데 중요합니다. 각 레벨의 리소스가 어떻게 상호작용하는지 보여줍니다.
각 리소스의 역할 (간략히)
- 파드: 가장 기본적인 배포 단위, 하나 이상의 컨테이너 그룹
- 레플리케이션 컨트롤러: 지정된 수의 파드 복제본을 유지 (레거시)
- 레플리카셋: 레플리케이션 컨트롤러의 후속 버전, 더 유연한 셀렉터 지원
- 디플로이먼트: 레플리카셋을 관리하며, 롤링 업데이트와 롤백을 지원
- 데몬셋: 모든 (또는 일부) 노드에 파드의 사본을 실행
- 스테이트풀셋: 상태 유지가 필요한 애플리케이션을 위한 리소스
- 잡: 완료 후 종료되는 일회성 태스크를 실행
- 크론잡: 주기적으로 잡을 실행
이유: 각 리소스의 기본적인 역할을 이해하는 것은 적절한 리소스를 선택하고 사용하는 데 중요합니다.
학습 방법 제안
- 각 리소스를 개별적으로 학습한 후, 전체 구조를 다시 살펴보세요.
- 실제 예제를 통해 각 리소스의 사용법을 익히세요.
- 리소스 간의 관계와 상호작용을 이해하는 데 집중하세요.
파드
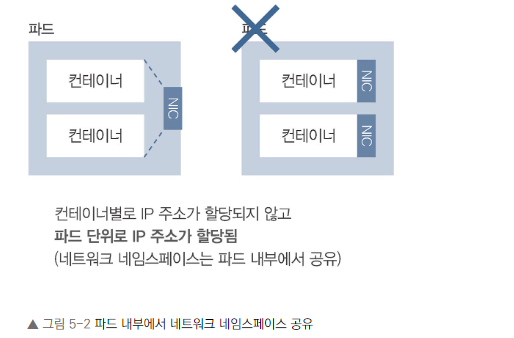
파드의 정의
- 워크로드 리소스의 최소 단위입니다.
- 한 개 이상의 컨테이너로 구성됩니다.
이유: 파드의 기본 개념을 이해하는 것은 쿠버네티스 아키텍처의 기초가 됩니다.
파드 내 컨테이너의 네트워크 특성
- 같은 파드 내 컨테이너들은 네트워크적으로 격리되어 있지 않습니다.
- 파드 내 모든 컨테이너는 동일한 IP 주소를 공유합니다.
- 파드 내 컨테이너들은 localhost를 통해 서로 통신할 수 있습니다.
파드 내 컨테이너 구성
- 대부분의 경우 하나의 파드에 하나의 컨테이너를 포함합니다.
- 때로는 메인 컨테이너와 이를 지원하는 서브 컨테이너를 포함할 수 있습니다.
서브 컨테이너의 예
- 프록시 역할을 하는 컨테이너
- 설정값을 동적으로 변경하는 컨테이너
- 로컬 캐시용 컨테이너
- SSL용 컨테이너
파드 디자인 패턴
- 여러 컨테이너가 하나의 파드에 존재하는 경우, 각 특징에 따라 다양한 디자인 패턴이 제시되어 있습니다.
주의사항
- nginx와 redis와 같은 독립적인 메인 컨테이너들을 하나의 파드에 넣는 것은 권장되지 않습니다.
이유: 개별 파드의 이동이 어려워지고 전체 구조가 복잡해질 수 있기 때문입니다.
파드 디자인 패턴
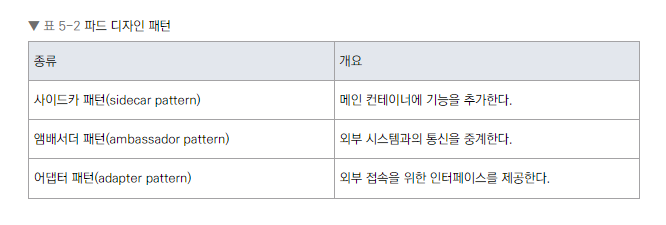
사이드카 패턴
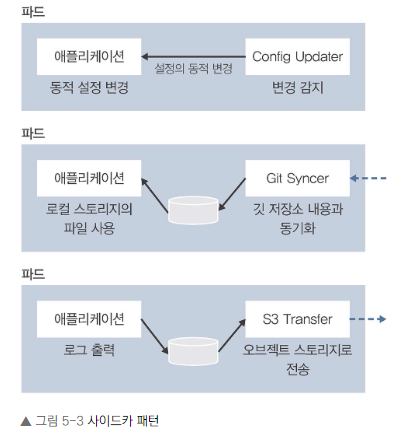
- 정의: 메인 컨테이너에 보조적인 기능을 추가하는 서브 컨테이너를 포함하는 패턴
- 예시:
• 설정 변경을 감지하고 동적으로 적용하는 컨테이너
• 깃 저장소와 로컬 스토리지를 동기화하는 컨테이너
• 로그 파일을 오브젝트 스토리지로 전송하는 컨테이너 - 특징: 주로 데이터와 설정 관련 작업에 사용됨
이유: 사이드카 패턴은 주 애플리케이션의 기능을 확장하거나 보완하는 데 유용합니다. 이를 통해 주 애플리케이션의 코드를 변경하지 않고도 추가 기능을 구현할 수 있습니다.
앰배서더 패턴
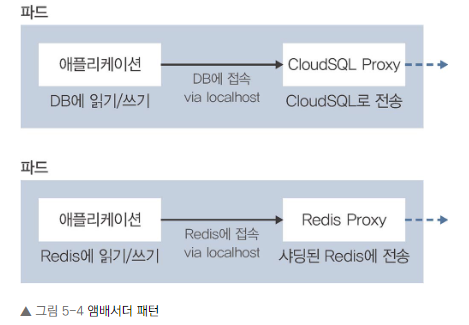
- 정의: 메인 컨테이너와 외부 시스템 간의 통신을 중계하는 서브 컨테이너를 포함하는 패턴
- 작동 방식:
• 메인 컨테이너는 localhost를 통해 앰배서더 컨테이너에 접속
• 앰배서더 컨테이너가 외부 시스템과 실제 통신을 담당 - 장점:
• 메인 컨테이너와 외부 시스템 간의 결합도를 낮춤
• 환경 변화에 유연하게 대응 가능 (예: 개발 환경과 서비스 환경의 차이)
이유: 앰배서더 패턴은 애플리케이션의 네트워크 통신을 추상화하여, 환경 변화에 더 유연하게 대응할 수 있게 합니다. 이는 특히 마이크로서비스 아키텍처에서 유용합니다.
어댑터 패턴
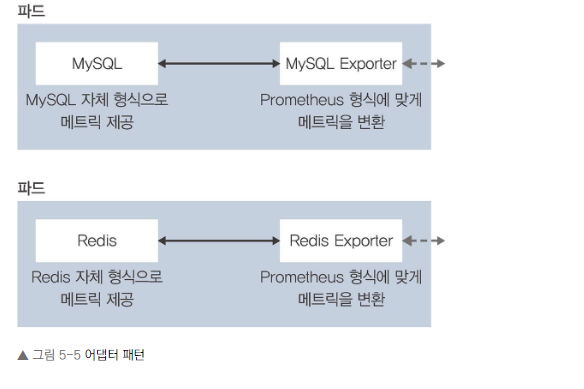
- 정의: 서로 다른 데이터 형식을 변환해주는 컨테이너를 포함하는 패턴
- 예시: 프로메테우스와 같은 모니터링 도구를 위한 메트릭 형식 변환
- 작동 방식:
• 외부 요청을 받아 메인 컨테이너의 데이터를 적절한 형식으로 변환
• 메인 컨테이너와 어댑터 컨테이너는 localhost를 통해 통신
이유: 어댑터 패턴은 서로 다른 시스템 간의 호환성 문제를 해결합니다. 이를 통해 기존 애플리케이션을 수정하지 않고도 새로운 시스템과 통합할 수 있습니다.
-
공통점
-
모든 패턴에서 컨테이너 간 통신은 localhost를 통해 이루어집니다.
-
각 패턴은 메인 컨테이너의 기능을 확장하거나 보완합니다.
파드 생성
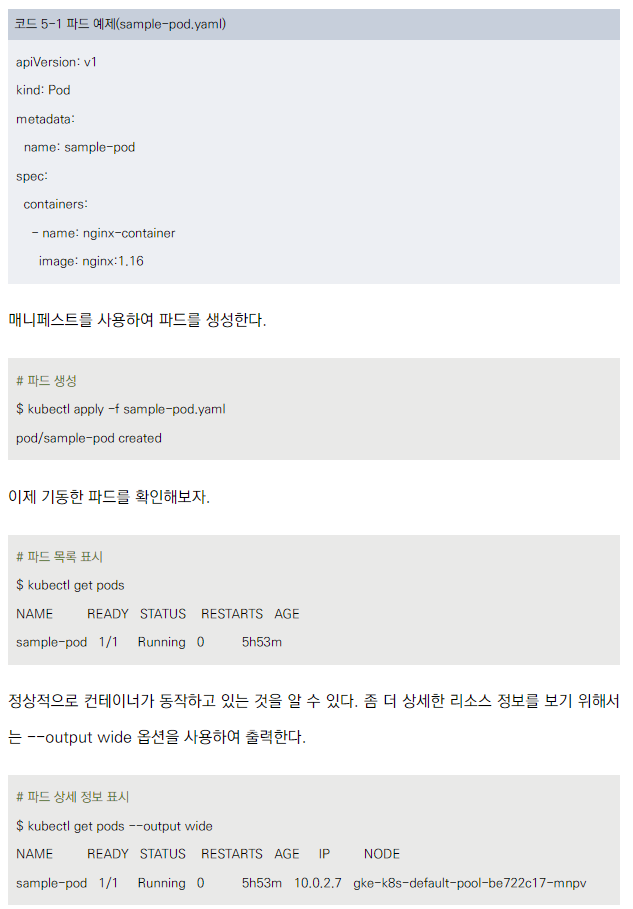
단일 컨테이너 파드 생성
- 매니페스트 파일(sample-pod.yaml)을 사용하여 nginx 컨테이너를 포함한 파드를 생성합니다.
- kubectl apply -f sample-pod.yaml 명령어로 파드를 생성합니다.
- kubectl get pods 명령어로 파드의 상태를 확인합니다.
이유: 이는 가장 기본적인 파드 생성 과정을 보여줍니다. 실제 환경에서 자주 사용되는 방법입니다.
파드 상세 정보 확인
- kubectl get pods --output wide 명령어를 사용하여 더 자세한 정보를 확인합니다.
- IP 주소, 노드 정보 등을 볼 수 있습니다.
이유: 이 명령어는 문제 해결이나 네트워크 구성 확인 시 유용합니다.
두 개의 컨테이너를 포함한 파드 생성
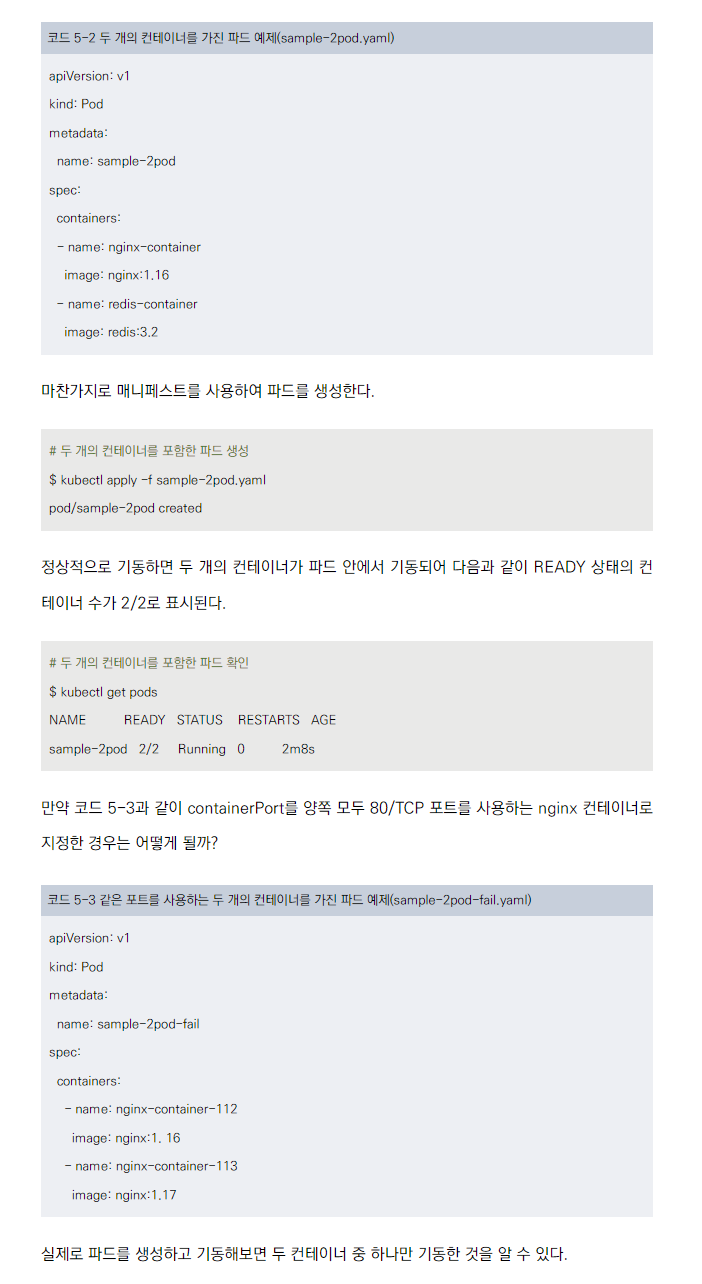
다중 컨테이너 파드 생성
- nginx와 redis 컨테이너를 포함한 파드를 생성합니다(sample-2pod.yaml).
- kubectl apply -f sample-2pod.yaml 명령어로 파드를 생성합니다.
- kubectl get pods로 확인 시 READY 상태가 2/2로 표시됩니다.
이유: 이 예제는 하나의 파드에 여러 컨테이너를 포함시킬 수 있음을 보여줍니다. 하지만 이는 권장되는 방식은 아닙니다.
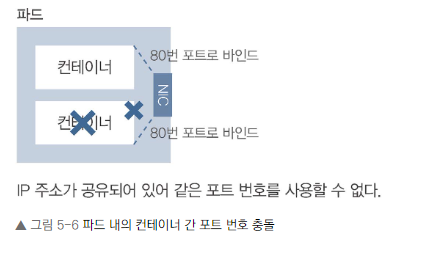
포트 충돌 상황
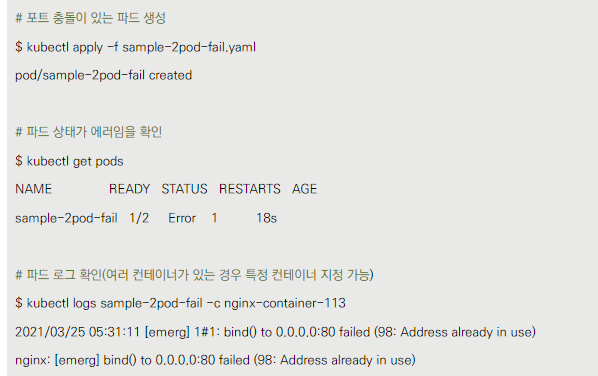
- 두 개의 nginx 컨테이너가 같은 포트(80)를 사용하는 파드를 생성합니다(sample-2pod-fail.yaml).
- 파드 생성 후 상태를 확인하면 Error 상태가 됩니다.
- kubectl logs 명령어로 로그를 확인하면 포트 충돌 오류를 볼 수 있습니다.
이유: 이 예제는 파드 내 컨테이너 간 포트 충돌이 발생할 수 있음을 보여줍니다. 이는 파드 설계 시 주의해야 할 중요한 점입니다.
- 네트워크 네임스페이스 공유
- 파드 내의 모든 컨테이너는 네트워크 네임스페이스를 공유합니다.
- 따라서 같은 파드 내에서는 포트 번호가 충돌하지 않도록 해야 합니다.
이유: 이 개념을 이해하는 것은 파드 내 컨테이너 설계 시 매우 중요합니다.
컨테이너 로그인과 명령어 실행


컨테이너 "로그인" 개념
- 실제로는 SSH처럼 직접 로그인하는 것이 아닙니다.
- kubectl exec 명령어를 사용하여 컨테이너 내부에서 명령을 실행합니다.
- -it 옵션은 대화형 터미널을 제공합니다.
이유: 이는 컨테이너 환경의 특성과 보안 모델 때문입니다. 직접적인 SSH 접근보다 kubectl을 통한 관리가 더 안전하고 쿠버네티스 중심적입니다.
컨테이너 내부 접근
-
kubectl exec -it sample-pod -- /bin/bash
-
이 명령어로 컨테이너 내부의 bash 셸에 접근할 수 있습니다.
이유: 이 방법을 통해 컨테이너 내부 환경을 직접 확인하고 문제를 해결할 수 있습니다.
컨테이너 내부 상태 확인
- IP 주소, 리스닝 포트, 실행 중인 프로세스 등을 확인할 수 있습니다.
- 필요한 도구(iproute2, procps)를 설치해야 할 수 있습니다.
이유: 이러한 정보는 네트워크 문제 해결, 성능 분석, 보안 점검 등에 필수적입니다.
다양한 exec 명령어 사용-
- 단일 명령어 실행: kubectl exec -it sample-pod -- /bin/ls
- 특정 컨테이너 지정: kubectl exec -it sample-2pod -c nginx-container -- /bin/ls
- 옵션 포함 명령어: kubectl exec -it sample-pod -- /bin/ls --all --classify
- 파이프 사용: kubectl exec -it sample-pod -- /bin/bash -c "ls --all --classify | grep lib"
이유: 이러한 다양한 사용법은 컨테이너 관리와 문제 해결에 유연성을 제공합니다.
주의사항:
컨테이너 내부 환경 수정은 일시적이며, 컨테이너 재시작 시 초기화됩니다.
프로덕션 환경에서는 보안상의 이유로 exec 사용을 제한할 수 있습니다.
ENTRYPOINT 명령/CMD 명령과 command/args
도커와 쿠버네티스의 용어 차이
- 도커: ENTRYPOINT와 CMD
- 쿠버네티스: command와 args
이유: 이 차이를 이해하는 것은 도커에서 쿠버네티스로 전환할 때 혼란을 방지하고, 올바른 설정을 위해 중요합니다.
주의점
- 도커의 CMD가 쿠버네티스의 command가 아니라 args에 대응됩니다.
쿠버네티스에서의 덮어쓰기
- spec.containers[].command: 도커의 ENTRYPOINT를 덮어씁니다.
- spec.containers[].args: 도커의 CMD를 덮어씁니다.
이유: 이 기능을 통해 동일한 이미지를 다양한 방식으로 실행할 수 있어, 유연성이 증가합니다.
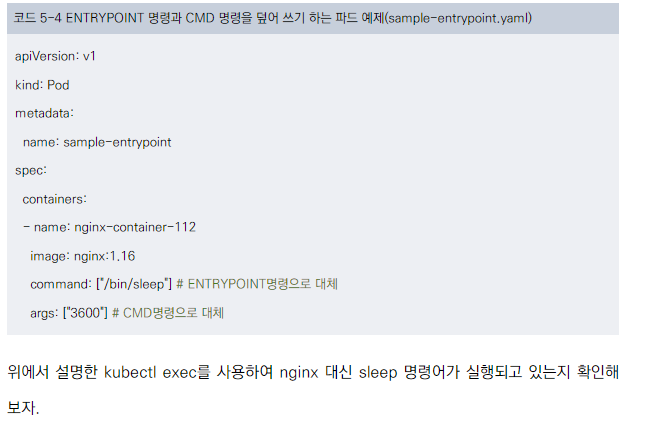
예제 설명 (sample-entrypoint.yaml)
- nginx:1.16 이미지를 사용하지만, 기본 nginx 프로세스 대신 sleep 명령어를 실행합니다.
- command: ["/bin/sleep"]은 ENTRYPOINT를 덮어씁니다.
- args: ["3600"]은 CMD를 덮어씁니다.
이유: 이 예제는 동일한 이미지를 완전히 다른 목적으로 사용할 수 있음을 보여줍니다. 이는 테스트, 디버깅, 또는 특수한 운영 상황에서 유용할 수 있습니다.
확인 방법
- kubectl exec를 사용하여 실제로 sleep 명령어가 실행되고 있는지 확인할 수 있습니다.
이유: 실제로 설정이 적용되었는지 확인하는 것은 운영 상 중요합니다. 이를 통해 의도한 대로 컨테이너가 동작하고 있는지 확인할 수 있습니다.
파드명 제한

파드 이름 규칙
- RFC1123의 호스트명 규약을 따릅니다.
- 사용 가능한 문자: 영문 소문자와 숫자
- 사용 가능한 기호: '-' 또는 '.'
- 시작과 끝은 반드시 영문 소문자나 숫자여야 합니다.
이유: 이러한 규칙은 DNS 호환성과 일관성을 유지하기 위해 중요합니다. 쿠버네티스는 파드 이름을 내부 DNS에 사용하기 때문입니다.
예제 분석 (sample-podname-fail.yaml)
- 파드 이름 "sample_podname_fail"은 규칙을 위반합니다.
- 문제점: '_' (언더스코어) 사용
이유: 언더스코어는 DNS 이름에서 허용되지 않는 문자입니다. 이는 네트워킹 문제를 방지하기 위함입니다.
에러 메시지 해석
CopyThe Pod "sample_podname_fail" is invalid: metadata.name: Invalid value:
"sample_podname_fail": a DNS-1123 subdomain must consist of lower case alphanumeric characters, '-' or '.', and must start and end with an alphanumeric character
- 에러 메시지는 정확히 어떤 규칙을 위반했는지 설명합니다.
이유: 상세한 에러 메시지는 사용자가 문제를 빠르게 식별하고 수정할 수 있게 해줍니다.
올바른 이름 예시
- "sample-podname"
- "samplepodname"
- "sample.podname"
이유: 이러한 예시는 규칙을 준수하며, 실제 사용 시 참고할 수 있습니다.
주의사항:
자동화 스크립트나 CI/CD 파이프라인에서 파드 이름을 생성할 때 특히 주의해야 합니다.
이름 생성 시 자동으로 규칙을 검증하는 로직을 추가하는 것이 좋습니다.
호스트의 네트워크 구성을 사용한 파드 기동

hostNetwork 설정의 의미
- 파드가 호스트의 네트워크 네임스페이스를 직접 사용하게 됩니다.
- IP 주소, 호스트명, DNS 설정 등이 호스트의 것을 그대로 상속받습니다.
이유: 이 설정은 특정 상황에서 호스트 수준의 네트워크 접근이 필요할 때 유용합니다.
IP 주소 확인
- 파드의 IP 주소와 노드의 IP 주소가 동일합니다 (10.178.0.63).
이유: 이는 파드가 호스트의 네트워크 스택을 직접 사용하고 있음을 증명합니다.
호스트명 확인
- 파드의 호스트명이 노드의 호스트명과 동일합니다 (gke-k8s-default-pool-be722c17-mnpv).
이유: 호스트명도 호스트에서 상속받았음을 보여줍니다.
DNS 설정 확인
- /etc/resolv.conf 파일의 내용이 호스트의 것과 동일합니다.
이유: DNS 설정도 호스트에서 상속받았음을 나타냅니다.
주의사항
- hostNetwork: true 설정은 보안상 주의가 필요합니다.
- 파드가 호스트의 모든 네트워크 인터페이스에 접근할 수 있게 됩니다.
이유: 이 설정은 파드에 과도한 권한을 줄 수 있어, 필요한 경우에만 제한적으로 사용해야 합니다.
사용 사례
- 네트워크 모니터링 도구
- 특정 포트를 호스트 레벨에서 사용해야 하는 애플리케이션
이유: 이러한 특수한 경우에 hostNetwork 설정이 유용할 수 있습니다.
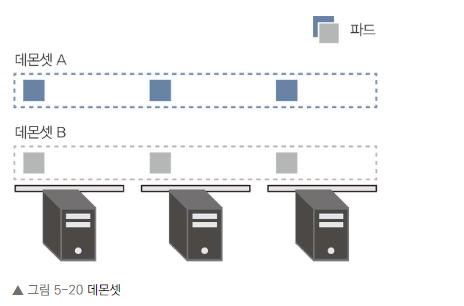
데몬 셋
-
데몬셋(DaemonSet)은 레플리카셋의 특수한 형태입니다.
-
레플리카셋과 달리, 데몬셋은 각 쿠버네티스 노드에 하나의 파드만 배치합니다.
-
데몬셋은 레플리카 수를 지정할 수 없으며, 한 노드에 두 개 이상의 파드를 배치할 수 없습니다.
-
노드 선택기나 노드 안티어피니티를 사용하여 특정 노드에 파드 배치를 제외할 수 있습니다.
-
새로운 노드가 추가되면 데몬셋은 자동으로 해당 노드에 파드를 배치합니다.
-
데몬셋은 모든 노드에서 실행해야 하는 프로세스(예: 로그 수집기, 모니터링 도구)에 유용합니다.
-
데몬셋 생성 예제와 YAML 파일 구조가 제공되었습니다.
-
데몬셋의 업데이트 전략에는 OnDelete와 RollingUpdate 두 가지가 있습니다.
-
OnDelete: 파드가 삭제될 때만 새 정의로 업데이트
-
RollingUpdate: 즉시 파드 업데이트 (기본값)
레플리카셋
- 쿠버네티스에서 사용되는 리소스 타입 중 하나
- 목적: 지정된 수의 파드 복제본(replica)을 유지하는 것
- 사용자가 원하는 파드의 수를 지정합니다.
- 레플리카셋은 현재 실행 중인 파드의 수를 지속적으로 모니터링합니다.
- 실제 파드 수가 원하는 수보다 적으면 새 파드를 생성합니다.
- 실제 파드 수가 원하는 수보다 많으면 초과 파드를 제거합니다.
유연한 배포
- 클러스터의 노드들 사이에 파드를 분산 배치할 수 있습니다.
- 각 노드의 리소스 상황에 따라 파드 수가 다를 수 있습니다.
고가용성
- 노드 장애 등으로 파드가 사라지면 자동으로 새 파드를 생성합니다.
스케일링
- 필요에 따라 레플리카 수를 쉽게 조정할 수 있습니다
일반적인 상황:
보통 쿠버네티스는 노드 하나당 한 개의 파드를 강제하지 않습니다.
쿠버네티스 스케줄러는 클러스터 전체의 리소스 활용도를 최적화하려고 합니다.
따라서 한 노드에 여러 개의 파드가 배치될 수 있고, 어떤 노드에는 특정 파드가 없을 수도 있습니다.
-
레플리카셋의 경우
-
레플리카셋은 지정된 수의 파드 복제본을 유지
-
이 파드들은 클러스터의 여러 노드에 분산될 수 있습니다.
-
한 노드에 여러 개의 동일한 파드가 실행될 수도 있고, 어떤 노드에는 해당 파드가 없을 수도 있습니다.
-
데몬셋은 각 노드에 정확히 하나의 파드를 실행하도록 설계
-
이는 로그 수집기나 모니터링 에이전트처럼 모든 노드에서 실행되어야 하는 서비스에 유용
OnDelete 업데이트 전략
- 데몬셋 매니페스트를 수정해도 기존 파드는 즉시 업데이트되지 않습니다.
- 파드가 다시 생성될 때나 수동으로 지정한 시점에 업데이트가 이루어집니다.
- 설정에서는 type 외에 다른 항목을 지정할 수 없습니다.
OnDelete 사용 이유
- 데몬셋은 주로 모니터링이나 로그 전송 용도로 사용되어 즉시 업데이트가 불필요한 경우가 많습니다.
OnDelete 설정 예제
- YAML 파일로 OnDelete 전략을 사용하는 데몬셋 설정 방법을 보여줌
OnDelete 사용 시 주의사항
- 파드가 다양한 이유로 정지되기 전까지는 업데이트되지 않습니다.
- 장기간 이전 버전이 사용될 수 있으므로 주의가 필요
수동 업데이트 방법
- kubectl delete pod 명령어로 파드를 수동으로 정지시켜 새 버전의 파드를 생성 가능
정리
- OnDelete 전략은 즉시 업데이트가 필요하지 않은 데몬셋에 유용하지만, 장기간 구버전 사용의 위험이 있으므로 신중히 사용해야 한다는 것입니다.
RollingUpdate 전략
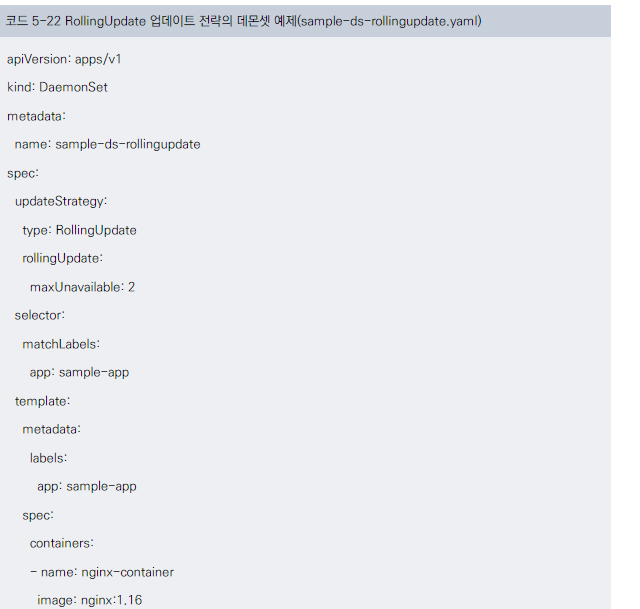
- 데몬셋도 디플로이먼트처럼 RollingUpdate를 사용할 수 있습니다.
- 이는 파드를 점진적으로 업데이트하는 방식입니다.
데몬셋의 RollingUpdate 특징
- 노드당 하나의 파드만 가능하므로, 최대 파드 수(maxSurge)를 설정할 수 없습니다.
- 동시에 정지 가능한 최대 파드 수(maxUnavailable)만 지정할 수 있습니다.
maxUnavailable 설정
- 예: maxUnavailable=2는 파드를 두 개씩 동시에 업데이트합니다.
- 기본값은 1입니다.
- 0으로 설정할 수 없습니다.
YAML 예제
- RollingUpdate 전략을 사용하는 데몬셋 설정을 보여줍니다.
- maxUnavailable을 2로 설정한 예시를 제공합니다.
스테이트풀셋
- 레플리카셋의 특수한 형태
- 스테이트풀(stateful)한 워크로드(예: 데이터베이스)를 위한 리소스
레플리카셋과의 주요 차이점
- 파드 이름에 숫자 인덱스가 부여됨 (예: sample-statefulset-0, sample-statefulset-1)
- 파드 이름이 변경되지 않음
- 데이터를 영구적으로 저장하는 구조
스테이트풀셋 생성
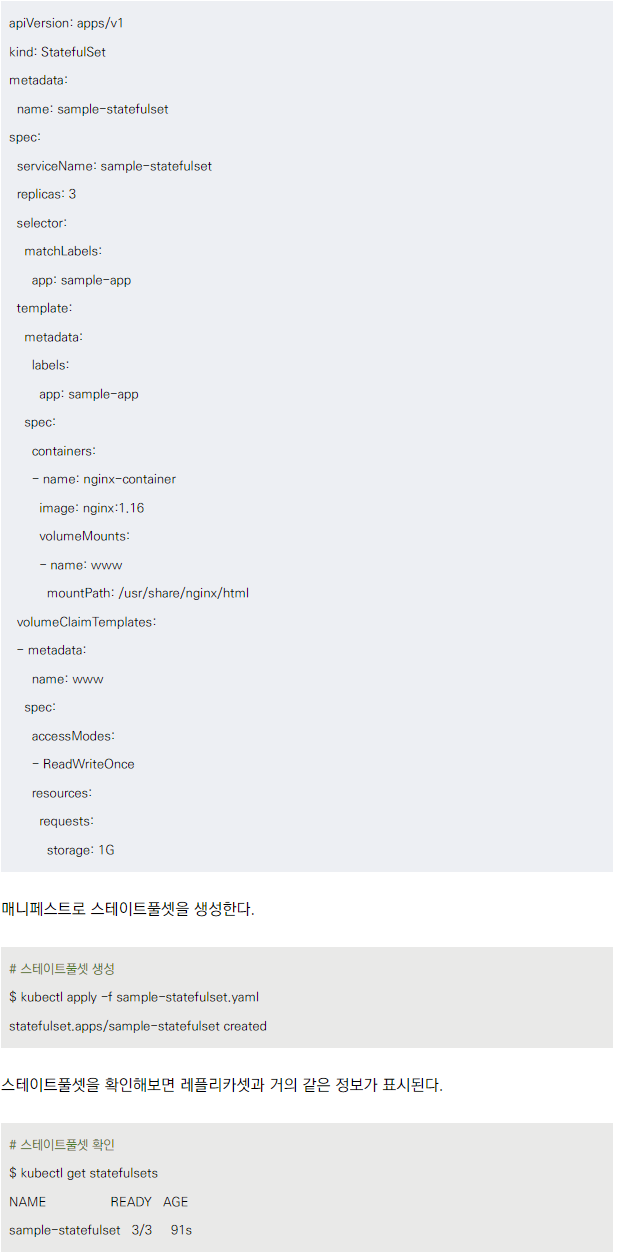
- YAML 파일을 통해 생성
- volumeClaimTemplates를 사용하여 영구 볼륨 클레임 설정 가능
- 영구 볼륨을 사용하여 파드 재시작 시에도 동일한 데이터 유지
스테이트풀셋 확인
- kubectl 명령어로 스테이트풀셋, 파드, 영구 볼륨 클레임, 영구 볼륨 확인 가능
정리
- 스테이트풀셋은 상태를 유지해야 하는 애플리케이션에 적합한 쿠버네티스 리소스
- 일관된 네트워크 식별자, 안정적인 스토리지, 순차적인 배포와 스케일링을 제공하여 데이터베이스와 같은 상태 유지가 필요한 애플리케이션의 운영을 용이
스테이트풀셋 스케일링


스테이트풀셋 스케일링 방법
- kubectl apply -f 명령어로 YAML 파일 수정 후 적용
- kubectl scale 명령어 사용
스케일링 특징
- 파드를 동시에 하나씩만 생성하거나 삭제함
- 시간이 더 걸릴 수 있음
스케일 아웃 (증가) 과정
- 인덱스가 가장 작은 파드부터 순차적으로 생성
- 이전 파드가 Ready 상태가 된 후 다음 파드 생성
스케일 인 (감소) 과정
- 인덱스가 가장 큰 파드부터 역순으로 삭제
레플리카셋과의 차이점
- 레플리카셋: 파드가 무작위로 삭제됨
- 스테이트풀셋: 순서가 정해져 있어 예측 가능함
스테이트풀셋의 장점
- 0번째 파드가 항상 먼저 생성되고 가장 늦게 삭제됨
- 마스터-슬레이브 구조의 애플리케이션에 적합
정리
- 테이트풀셋은 순서와 고유성이 중요한 애플리케이션에 적합한 리소스입니다. 특히 데이터베이스와 같이 상태를 유지해야 하는 애플리케이션의 스케일링에 유용하며, 예측 가능한 방식으로 파드를 관리
스테이트풀셋의 라이프사이클
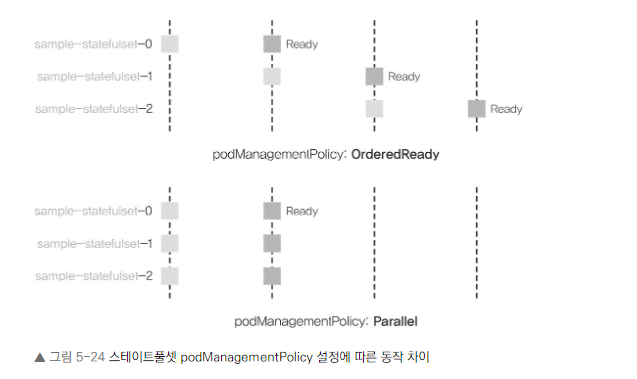
스테이트풀셋의 기본 동작
- 파드를 하나씩 순차적으로 생성
- 이전 파드가 Ready 상태가 된 후 다음 파드 생성
podManagementPolicy 설정
- spec.podManagementPolicy를 사용하여 파드 생성 방식 변경 가능
- 기본값: OrderedReady (순차적 생성)
- Parallel 설정: 병렬로 동시에 파드 생성 가능
Parallel 설정의 효과
- 레플리카셋과 유사하게 모든 파드를 동시에 생성
-파드 생성 시간 단축 가능
사용 예시
- YAML 파일에서 spec.podManagementPolicy: Parallel 지정
- 이 설정으로 스테이트풀셋 생성 시 모든 파드가 동시에 기동
정리
- 스테이트풀셋은 기본적으로 순차적인 파드 생성을 통해 예측 가능한 동작을 제공하지만, 필요에 따라 병렬 생성 방식을 선택할 수 있어 유연성을 갖추고 있습니다. 이를 통해 애플리케이션의 요구사항에 따라 적절한 배포 전략을 선택할 수 있습니다.
스테이트풀셋 업데이트 전략
- OnDelete와 RollingUpdate 두 가지 옵션
- 기본값은 RollingUpdate
OnDelete 전략

- 매니페스트 변경 시 즉시 업데이트하지 않음
- 파드가 다시 생성될 때만 새 설정 적용
- 데이터베이스 등 수동 업데이트가 필요한 경우에 유용
RollingUpdate 전략
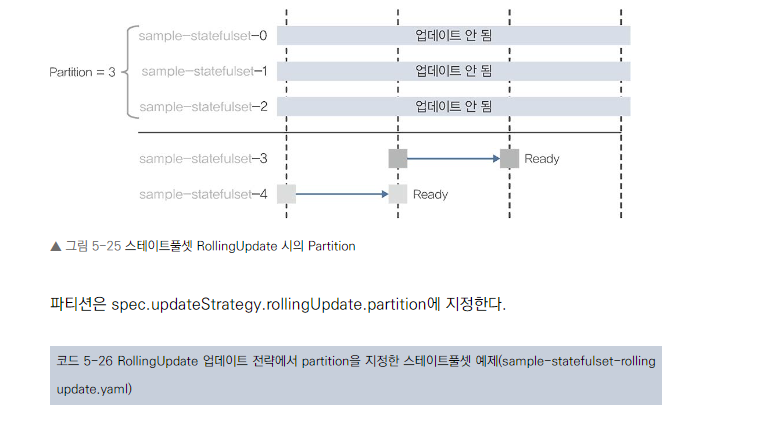
- 즉시 파드 업데이트
- 영속성 데이터로 인해 추가 파드 생성 없이 업데이트
- 파드를 하나씩 순차적으로 업데이트
partition 설정
- 부분적 업데이트 가능
- 특정 인덱스 이상의 파드만 업데이트
- 안전한 단계적 업데이트에 유용
정리
스테이트풀셋은 상태 유지가 중요한 애플리케이션을 위해 세밀한 업데이트 전략을 제공합니다. OnDelete와 RollingUpdate 전략, 그리고 partition 설정을 통해 애플리케이션의 특성과 요구사항에 맞는 유연한 업데이트 방식을 선택
OnDelete 전략의 필요성
- 데이터베이스와 같은 상태 유지가 중요한 애플리케이션의 경우, 자동 업데이트가 위험할 수 있습니다.
- 관리자가 적절한 시점을 선택하여 수동으로 업데이트를 진행하고 싶을 때 유용합니다.
- 예: 데이터 마이그레이션이 필요한 경우, 트래픽이 적은 시간대에 업데이트를 진행하고 싶을 때
RollingUpdate 전략의 장점
- 자동화된 업데이트 프로세스를 제공합니다.
- 서비스 중단 없이 점진적으로 업데이트할 수 있습니다.
- 대부분의 일반적인 상황에서 권장되는 전략입니다.
Partition을 사용한 RollingUpdate의 필요성
- 대규모 클러스터나 중요한 서비스의 경우, 전체 시스템을 한 번에 업데이트하는 것이 위험할 수 있습니다.
- 일부 파드만 먼저 업데이트하여 새 버전의 안정성을 테스트할 수 있습니다.
- 문제 발생 시 빠르게 롤백할 수 있는 안전망을 제공합니다.
- 예: 카나리 배포 전략을 구현할 때 유용합니다.
영구 볼륨 데이터 저장 확인
영구 볼륨 확인
- 컨테이너 내부에 영구 볼륨이 마운트되어 있는지 확인합니다.
- 영구 볼륨은 별도의 디스크로 마운트됩니다.
데이터 지속성 테스트
- 영구 볼륨에 파일을 생성하고, 파드를 삭제하거나 컨테이너를 정지시켜도 데이터가 유지되는지 확인합니다.
- 파드가 재생성되어도 같은 이름을 유지하며, 데이터도 그대로 유지됩니다.
스테이트풀셋 삭제와 영구 볼륨
- 스테이트풀셋을 삭제해도 영구 볼륨은 자동으로 삭제되지 않습니다.
- 이는 데이터 백업 기회를 제공하기 위함입니다.
- 스테이트풀셋을 재생성하면 기존 영구 볼륨의 데이터를 그대로 사용할 수 있습니다.
리소스 관리와 비용
- 사용하지 않는 영구 볼륨은 비용이 발생할 수 있으므로, 필요 없는 경우 수동으로 삭제해야 합니다.
- 영구 볼륨 클레임(PVC)을 삭제해도 실제 영구 볼륨(PV)은 삭제되지 않을 수 있습니다(ClaimPolicy 설정에 따라 다- 름).
잡
잡(Job)의 정의와 특징
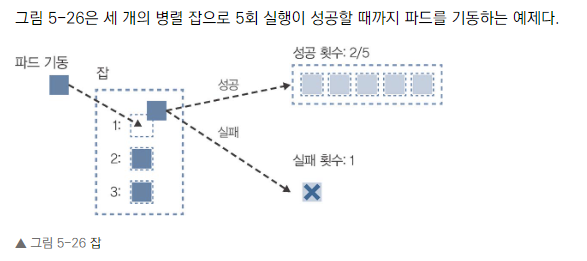
- 잡은 한 번만 실행되는 컨테이너 기반 리소스입니다.
- N개의 병렬 실행과 지정된 횟수의 정상 종료를 보장합니다.
레플리카셋과의 차이점
- 기동 중인 파드가 정지되는 것을 전제로 만들어졌는지에 있음
- 레플리카셋은 파드의 정지를 예상치 못한 에러로 간주합니다.
- 잡은 파드의 정상 종료를 전제로 설계되었습니다.
- 레플리카셋 등에서는 정상 종료 횟수 등을 셀 수 없기 때문에 배치 처리인 경우에는 잡을 적극적으로 사용
잡의 용도
- 배치 처리 작업에 적합합니다 (예: rsync, 파일 업로드 등).
잡 생성 및 관리
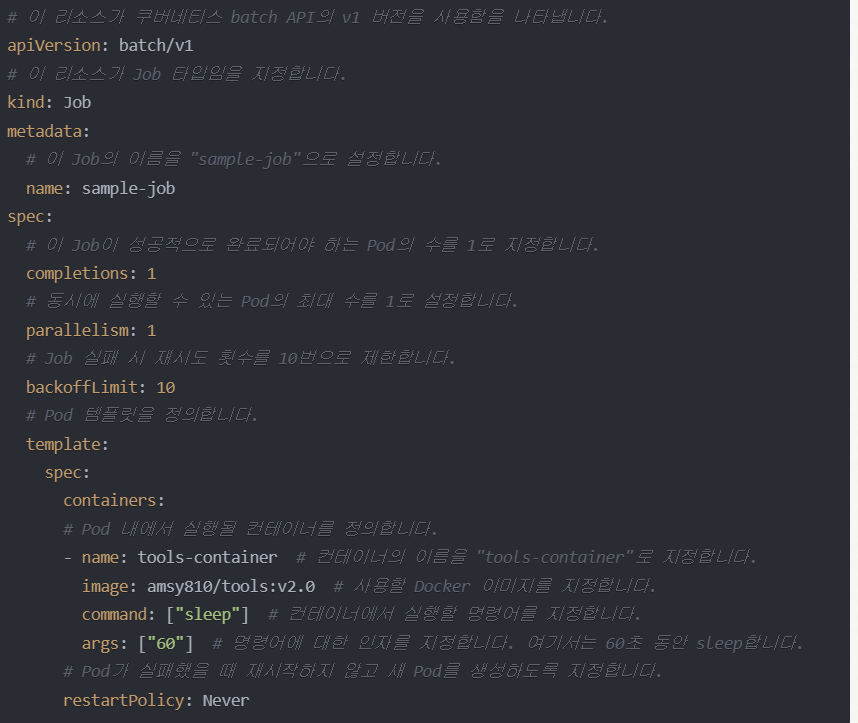


- YAML 매니페스트를 통해 잡을 정의하고 생성합니다.
- 레플리카셋과 마찬가지로 레이블과 셀렉터는 명시적으로 지정할 수 있지만, 쿠버네티스가 유니크한 uuid를 자동으로 생성하기 때문에 잡에서는 명시적으로 지정하는 것을 추천
- kubectl get jobs로 잡의 상태를 확인할 수 있습니다.
restartPolicy의 중요성
- Never: 파드 장애 시 새로운 파드를 생성합니다.
- OnFailure: 동일한 파드를 사용하여 잡을 재시작합니다.
실제 예제를 통한 동작 확인
- restartPolicy: Never를 사용한 잡의 동작을 보여줍니다.
- 파드 내 프로세스가 종료되면 새로운 파드가 생성됩니다.
restartPolicy에 따른 동작 차이
RestartPolicy의 동작 차이

- Job 매니페스트의 spec.template.spec.restartPolicy에는 OnFailure 또는 Never 중 하나를 지정해야 합니다.
- Never: 파드에 장애가 발생하면 새로운 파드를 생성합니다.
- OnFailure: 같은 파드를 재사용하여 Job을 다시 시작합니다.
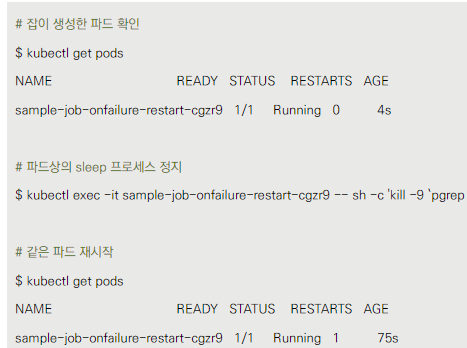
restartPolicy: Never의 경우

- 예제 매니페스트를 통해 Never 정책의 동작을 보여줍니다.
- Docker에서 프로세스 ID=1로 실행되는 sleep 명령어의 특성을 설명합니다.
- 실제로 파드의 sleep 프로세스를 종료시켰을 때, 새로운 파드가 생성되는 것을 확인합니다.
restartPolicy: OnFailure의 경우
- OnFailure 정책을 사용한 예제 매니페스트를 제시합니다.
- 파드의 sleep 프로세스를 종료시켰을 때, 같은 파드가 재시작되는 것을 보여줍니다.
- RESTARTS 카운터가 증가하고, 노드와 IP 주소는 변경되지 않습니다.
- 단, 영구 볼륨이나 hostPath를 마운트하지 않은 경우 데이터가 유실될 수 있음을 언급합니다.
태스크와 작업 큐 병렬 실행

잡(Job)의 병렬 실행 설정
- completions: 성공해야 할 총 횟수
- parallelism: 동시에 실행할 수 있는 파드의 수
- backoffLimit: 실패를 허용하는 횟수
- completions와 병렬성을 지정하는 parallelism 설정 항목에 각각 1을 지정했다. 이 설정들의 기본값은 1이기 때문에 명시적으로 지정하지 않아도 동작은 변하지 않는다.
주요 워크로드 유형과 설정
- 1회만 실행하는 태스크 (One Shot Task)
- N개 병렬로 실행시키는 태스크 (Multi Task)
- 한 개씩 실행하는 작업 큐
- N개 병렬로 실행하는 작업 큐
파라미터 변경
- completions는 변경 불가
- parallelism과 backoffLimit은 변경 가능 (kubectl apply로 적용)
One Shot Task 예제
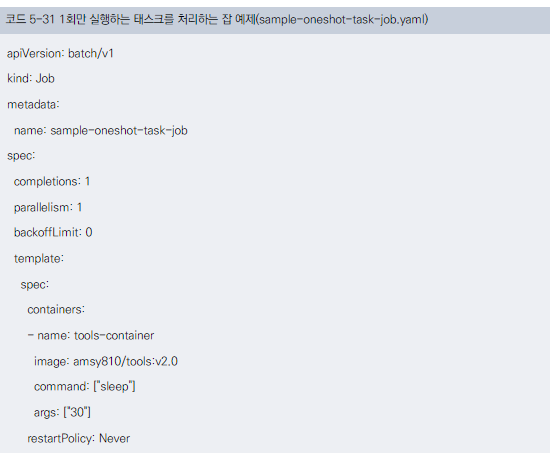
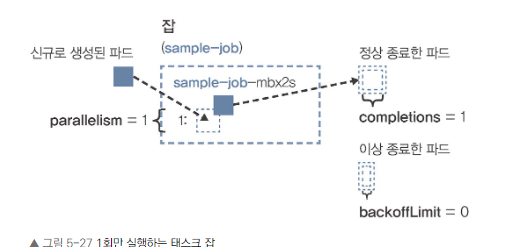
- completions=1, parallelism=1, backoffLimit=0
- ‘한 개 병렬로 실행/성공 횟수가 1이 되면 종료/실패 횟수가 0이 되면 종료(실패를 허용하지 않음)’라는 조건
- 성공 여부와 관계없이 반드시 1회만 실행
Multi Task 예제

- 성공 횟수(completions)와 병렬 수(parallelism)를 변경하여 병렬 태스크(Multi Task)를 생성할 수 있다
- completions=5, parallelism=3, backoffLimit=5
- 5회 성공할 때까지 3개의 파드를 병렬로 실행
- 남은 작업 수가 병렬 수보다 적으면 그만큼만 파드 생성
주의사항
- parallelism이 completions보다 크면 completions 만큼만 파드 생성
- 병렬 수(parallelism)를 성공 횟수(completions) 이상으로 설정하면 성공 횟수만큼만 파드가 생성
- 예를 들어 completions=3/parallelism=5를 지정하고 잡을 실행해도 파드는 다섯 개가 아닌 세 개만 작성된다.
Multi WorkQueue (N개 병렬로 실행하는 작업 큐)
completions를 지정하지 않고 parallelism만 지정
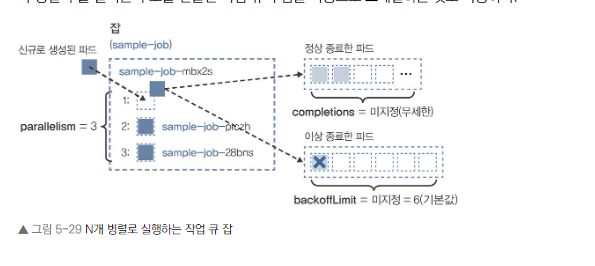
-
지금까지의 태스크 잡처럼 개별 파드의 정상 종료가 성공 횟수에 도달할 때까지 실행하는 것이 아니라, 큰 처리 전체가 정상 종료할 때까지 몇 개의 병렬 수로 계속 실행하고 싶은 경우가 있다.
-
그런 경우 작업 큐의 잡을 사용한다.
-
작업 큐의 잡은 성공 횟수(completions)를 지정하지 않고 병렬 수(parallelism)만 지정
-
지정된 병렬 수로 파드를 실행하고, 하나라도 정상 종료하면 새 파드를 생성하지 않음
-
메시지 큐와 함께 사용하여 전체 작업 진행을 관리
Single WorkQueue (한 개씩 실행하는 작업 큐)
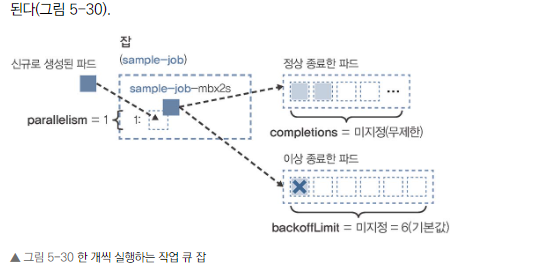
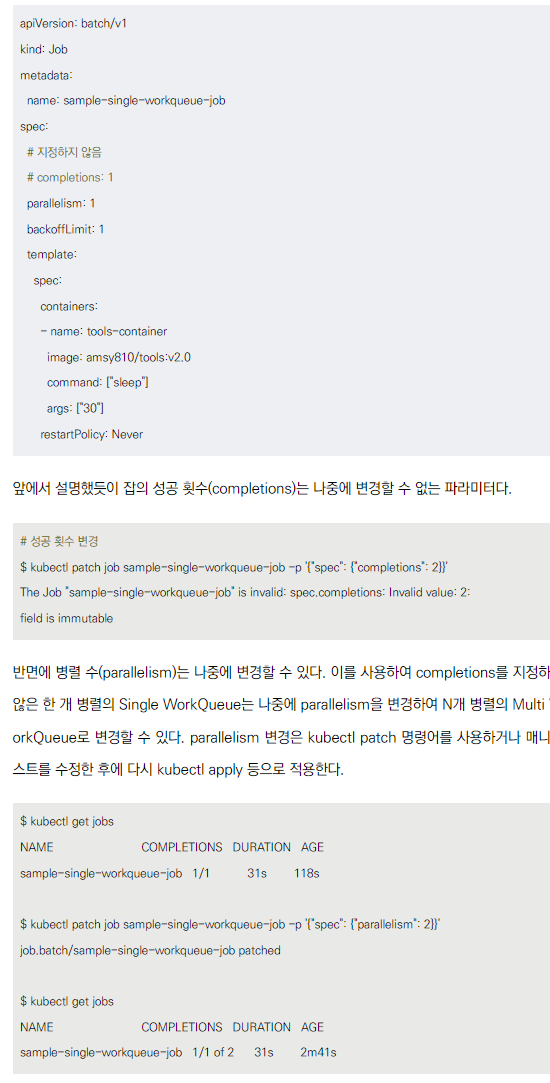
- completions를 지정하지 않고 parallelism을 1로 지정
- 한 번 정상 종료할 때까지 한 개씩 실행
파라미터 변경
- completions는 변경 불가
- parallelism은 변경 가능 (kubectl patch 또는 kubectl apply로 적용)
일정 기간 후 잡 삭제
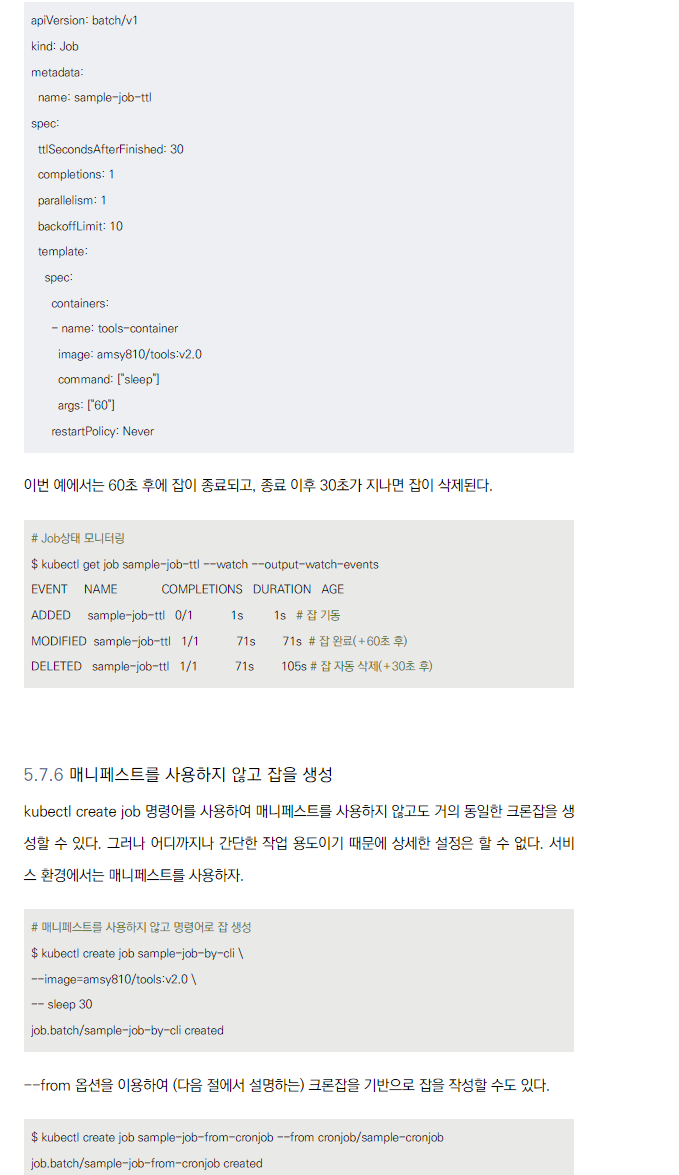
- spec.ttlSecondsAfterFinished를 설정하여 잡 종료 후 자동 삭제 가능
매니페스트 없이 잡 생성
- kubectl create job 명령어로 간단한 잡 생성 가능
- --from 옵션을 사용하여 크론잡을 기반으로 잡 생성 가능
크론잡

- CronJob은 Job과 유사한 리소스입니다.
- 쿠버네티스 1.4 이전에는 ScheduledJob이라고 불렸습니다.
- CronJob은 크론과 같이 스케줄링된 시간에 잡을 생성
CronJob, Job, Pod는 3계층 구조를 이룹니다
- CronJob이 Job을 관리
- Job이 Pod를 관리
CronJob 생성 예제
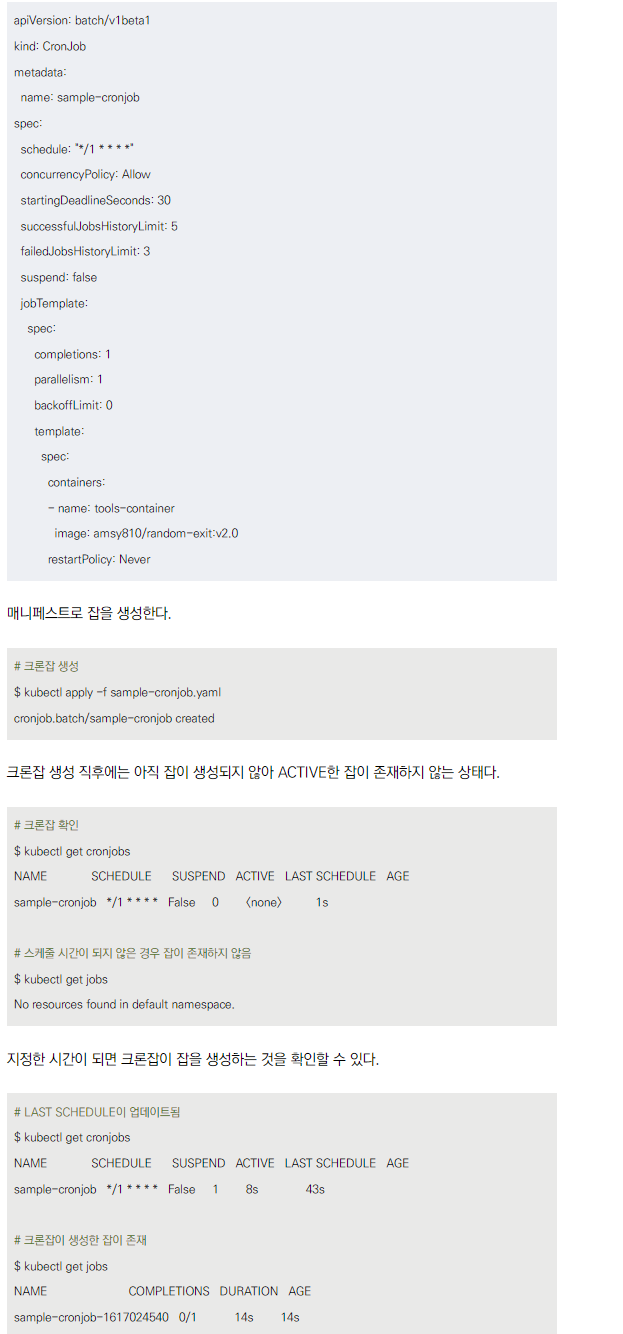
- 1분마다 50% 확률로 성공하는 Job을 생성
- YAML 파일로 정의 (apiVersion, kind, metadata, spec 등 포함)
CronJob 생성 후 동작
- 처음에는 ACTIVE한 Job이 없음
- 스케줄 시간이 되면 Job 생성
- kubectl 명령어로 상태 확인 가능
정리
- CronJob은 쿠버네티스에서 반복적인 작업을 스케줄링하는 강력한 도구입니다.
- 정해진 시간에 자동으로 Job을 생성하여 작업을 수행할 수 있게 해주며,
- 이는 배치 작업이나 정기적인 유지보수 작업에 매우 유용합니다.
크론잡 일시 정지
CronJob 일시 정지

- spec.suspend를 true로 설정하면 스케줄 대상에서 제외됨
- kubectl patch 명령어로 빠르게 변경 가능
- SUSPEND 상태가 True로 변경되면 더 이상 Job 생성되지 않음
CronJob 임의 시점 실행

- kubectl create job 명령어와 --from 옵션 사용
- 정기적 실행 외에 필요한 시점에 Job 생성 가능
동시 실행 제어
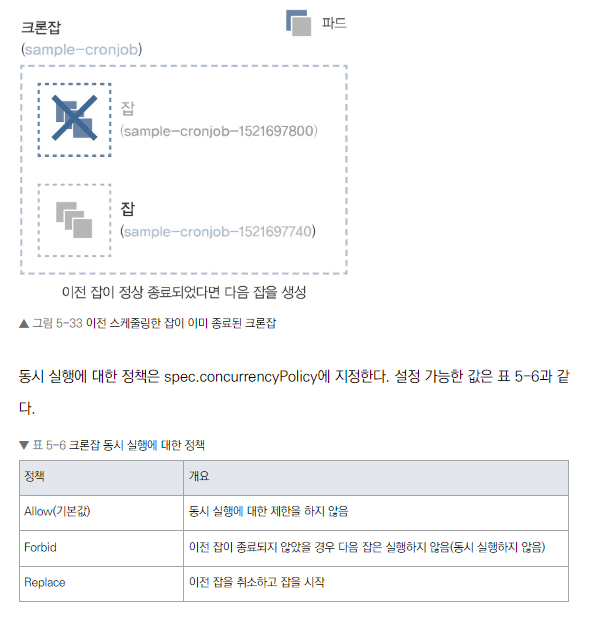
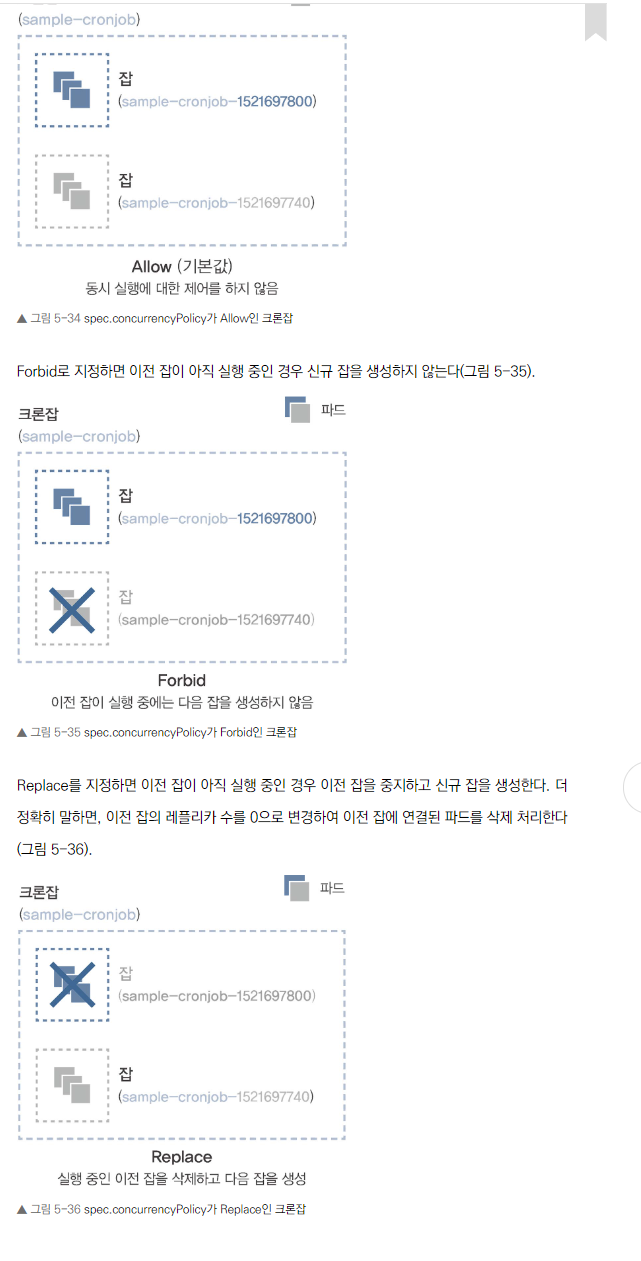
- spec.concurrencyPolicy로 설정
- Allow (기본값): 제한 없이 동시 실행
- Forbid: 이전 Job이 종료되지 않으면 새 Job 실행하지 않음
- Replace: 이전 Job 취소하고 새 Job 시작
정리
- CronJob은 단순히 정해진 시간에 Job을 생성하는 것 외에도 다양한 제어 기능을 제공합니다.
- 일시 정지, 임의 실행, 동시 실행 제어 등의 기능을 통해 더욱 유연하고 효율적인 작업 스케줄링이 가능합니다.
- 이러한 기능들은 실제 운영 환경에서 매우 유용하게 사용될 수 있습니다.
실행 시작 기한 제어
실행 시작 기한 제어
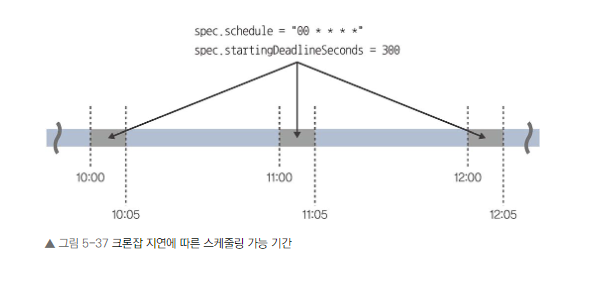
- 크론잡은 지정한 시간이 되면 쿠버네티스 마스터가 잡을 생성
- 쿠버네티스 마스커가 일시적으로 정지되는 경우등과 같이 시작시간이 지연되면
- 그 지연 시간을 허용하는 시간을 밑에 명령어로 지정
- spec.startingDeadlineSeconds로 설정
- 예를들어 매시 00분에 시작하는 잡을 매시 00~05분에만 실행 가능 설정경우 300초로 설정
- 지연 시간을 허용하는 기간을 초 단위로 지정
- 기본값은 무제한 지연 허용
CronJob 이력
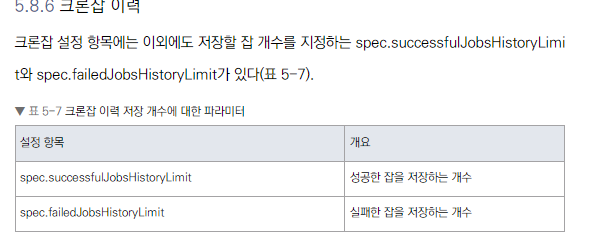
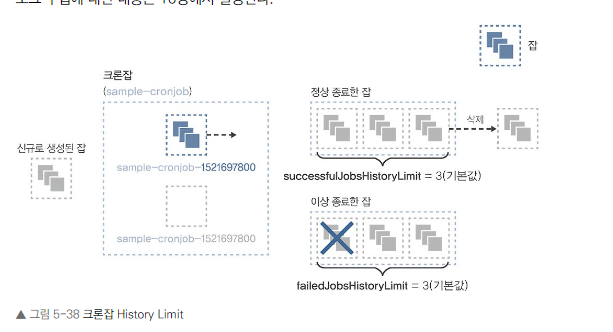

- spec.successfulJobsHistoryLimit: 성공한 Job 저장 개수
- spec.failedJobsHistoryLimit: 실패한 Job 저장 개수
- 기본값은 둘 다 3
- 0으로 설정 시 Job은 종료 즉시 삭제됨
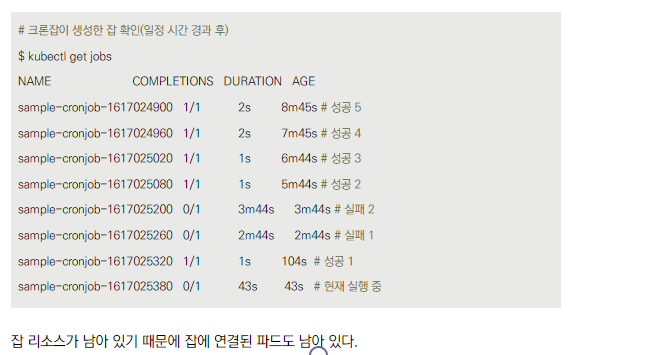
Job 및 Pod 확인
- kubectl get jobs로 Job 목록 확인
- kubectl get pods로 Pod 목록 확인
- kubectl logs로 Pod 로그 확인 가능
매니페스트 없이 CronJob 생성

- kubectl create cronjob 명령어 사용
- 간단한 작업에 적합, 상세 설정은 제한적
- 서비스 환경에서는 매니페스트 사용 권장
정리
- CronJob은 다양한 설정을 통해 세밀한 제어가 가능합니다.
- 실행 시작 기한, 이력 관리, 로그 확인 등의 기능을 통해 복잡한 스케줄링 요구사항을 충족시킬 수 있습니다.
- 그러나 운영 환경에서는 매니페스트를 통한 설정과 외부 로그 시스템 사용을 권장합니다. - 이를 통해 더 안정적이고 관리하기 쉬운 시스템을 구축할 수 있습니다.
요약
-
쿠버네티스는 다양한 프로세스 특성에 맞는 리소스를 제공합니다.
-
기본적으로 파드나 레플리카셋은 디플로이먼트를 통해 생성하는 것이 권장됩니다.
8개의 주요 워크로드 API 리소스
-
파드: 디버깅이나 확인 용도
-
레플리케이션 컨트롤러: 권장하지 않음 (레플리카셋 사용 권장)
-
레플리카셋: 파드 스케일링 관리, 주로 디플로이먼트를 통해 사용
-
디플로이먼트: 스케일링 가능한 워크로드에 사용
-
데몬셋: 각 노드에 하나씩 파드 배포
-
스테이트풀셋: 상태를 가진 워크로드(예: 영속성 데이터)에 사용
-
잡: 작업 큐나 태스크 등 종료가 필요한 워크로드에 사용
-
크론잡: 정기적으로 잡을 생성할 때 사용
추가
job
- 잡은 일회성 작업을 실행하기 위한 쿠버네티스 리소스
- 데이터베이스 마이그레이션
- 예를 들어, 애플리케이션의 새 버전을 배포할 때 데이터베이스 스키마를 업데이트해야 한다고 가정해봅시다.
yamlCopyapiVersion: batch/v1
kind: Job
metadata:
name: database-migration
spec:
template:
spec:
containers:
- name: db-migrator
image: my-migrator:v1
command: ["python", "migrate.py"]
restartPolicy: Never- 이 잡은 데이터베이스 마이그레이션 스크립트를 실행하고, 작업이 완료되면 종료됩니다
- 용량 데이터 처리월말 리포트 생성 / 파일 백업
정기적인 백업 작업을 잡으로 실행 / 메일 발송
대량의 이메일을 발송해야 하는 경우 등..
