1장 컴퓨터 시스템 개요
-
입력장치 혹은 네트워크 어댑터를 통해서 컴퓨터에 무언가 처리요청
-
메모리에 있는 명령을 읽어 CPU에서 실행 -> 결과값 메모리 다른영역에 기록
-
메모리의 데이터를 하드디스크등 저장 장치에 기록 OR 네트워크를 통해
다른 컴퓨터에 전송하거나 디스플레이등 출력장치를 통해 결과 값 보여줌반복
이러한 순서를 반복해서 사용자에게 하나의 처리(기능) 정리한 것을 프로그램! 이라 함
애플리케이션: 사용자가 직접사용 어플 컴퓨터 프로그램등..
미들웨어: 여러 가지 애플리케이션이 공통으로 하는 처리를 묶어서 실행을 도와줌
ex) 웹서버 , 데이터베이스
OS : 하드웨어를 직접 조작하여 애플리케이션이나 미들웨어 실행에 필요한 기능 제공
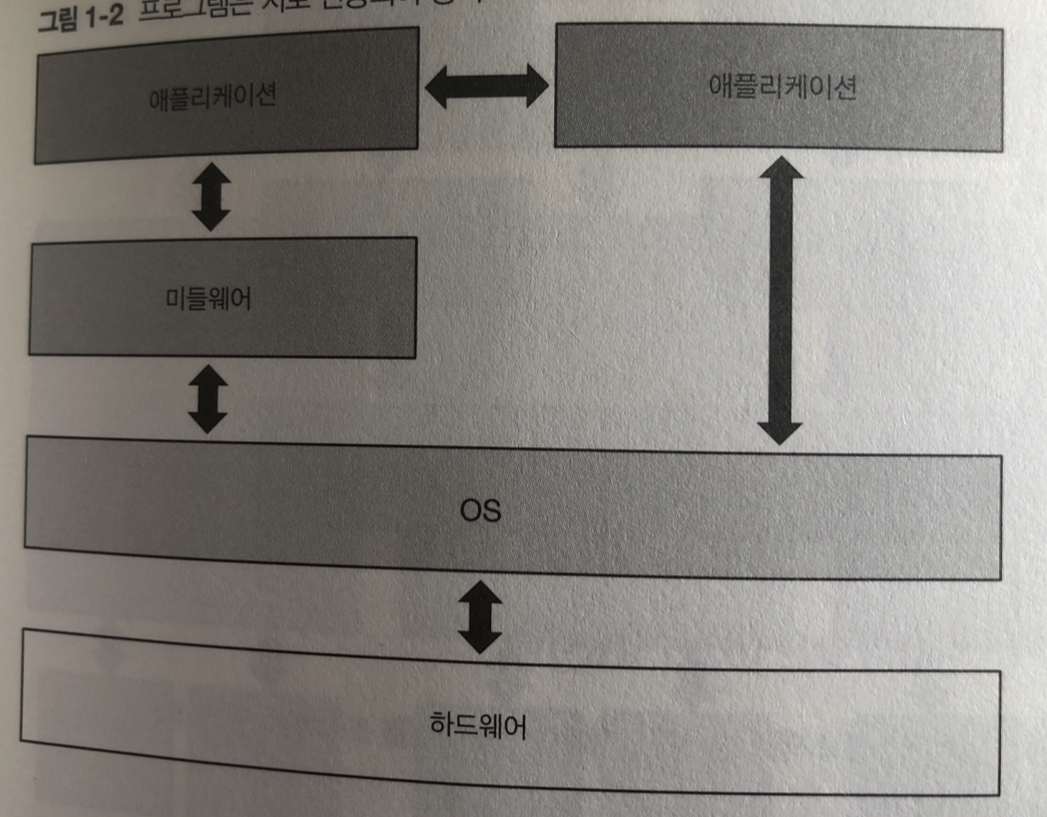
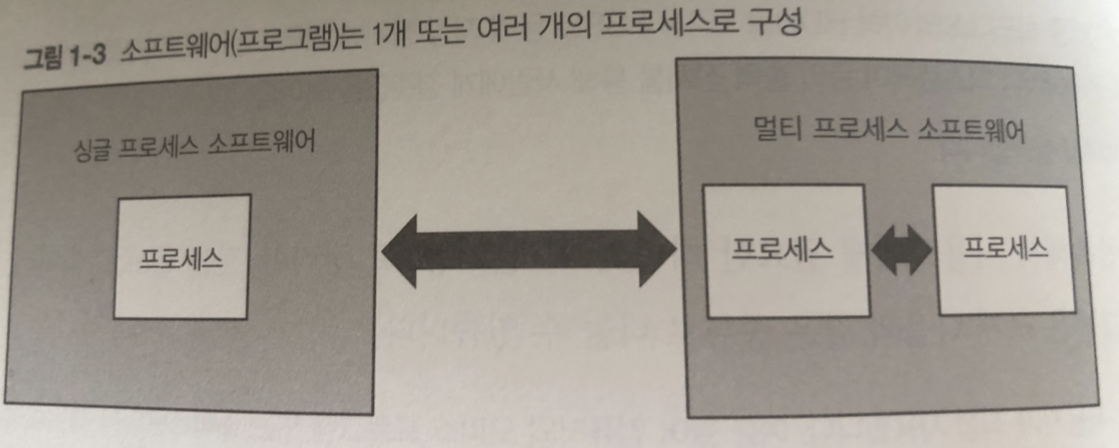
OS 는 여러가지 프로그램을 프로세스라고 하는 단위로 실행
프로그램은 1개 혹은 여러개의 프로세스로 구성됨
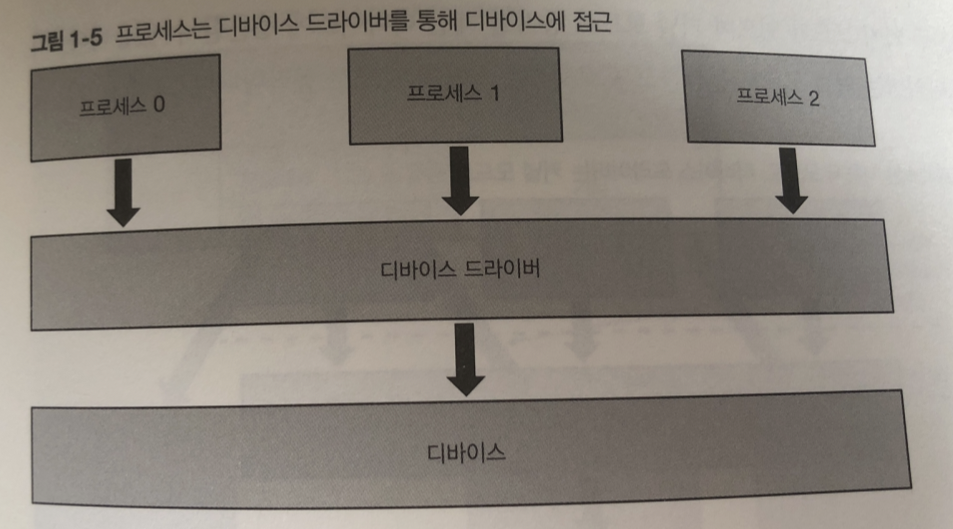
리눅스의 역할을 외부장치(디바이스) 를 조작 하는 일.
리눅스가 없으면? 여러 개의 프로세스를 각각 디바이스를 조작하는 코드를 작성해야됨
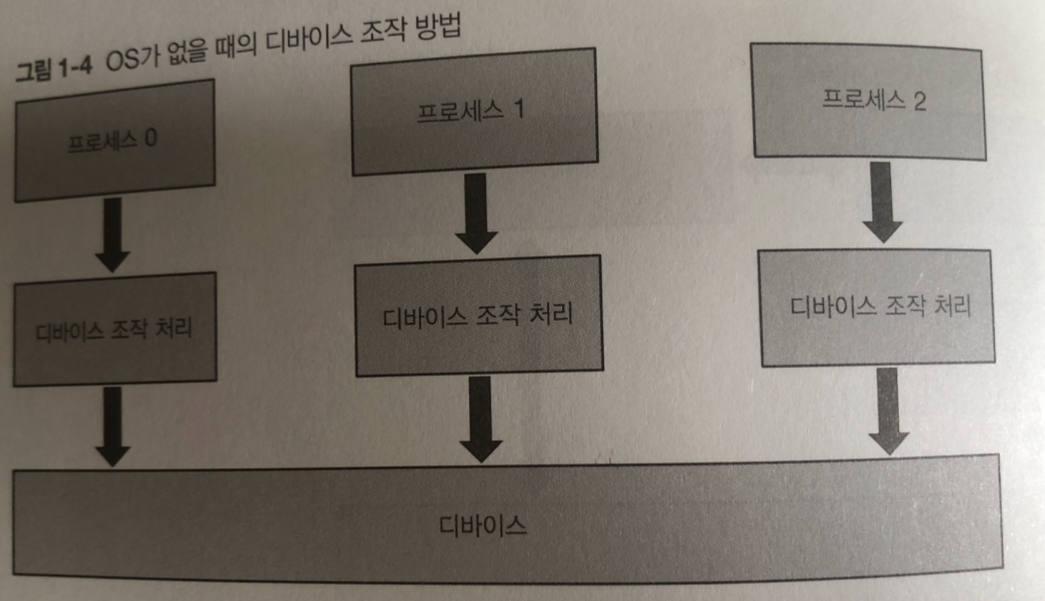
단점 : 모든 애플리케이션 개발자가 디바이스 스펙을 상세히 알아야함
개발 비용이 커짐
멀티 프로세스가 동시에 디바이스를 조작할 경우 예상외 동작 발생
이러한 단점으로 디바이스 드라이버라는 프로그램을 통해 다바이스를 다룸
그래서 디바이스 드라이버를 통해서만 프로세스가 디바이스를 조작 함
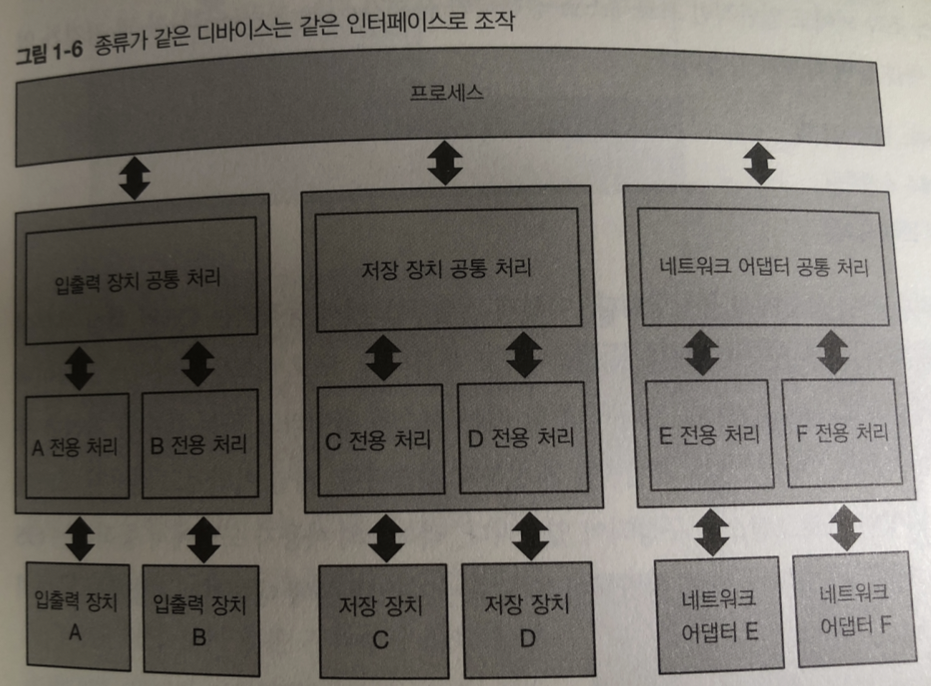
그림과 같이 디바이스 종류가 같으면 같은 인터페이스로 조작하도록 되어 있음
- 버그나 해킹목적으로 의도된 특정 프로세스가 디바이스 드라이버를 통해
디바이스에 접근함이라는 룰을 깨면 멀티 프로세스가 동시에 디바이스를 조작하려고
시도하는 상황발생~!
이런 문제를 피하고자 CPU에 있는 기능을 이용.
프로세스가 직접 하드웨어에 접근하는 것을 차단한다. CPU 에는 커널 모드(디바이스접근가능) 와 사용자 모드가 있다.
디바이스 드라이버는 커널모드로 작동하고 프로세스는 사용자 모드로 작동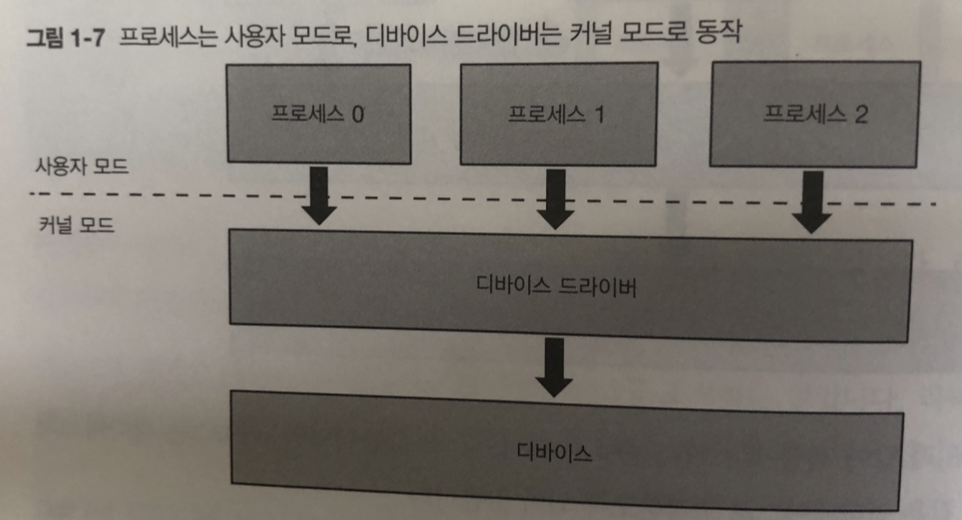
프로세스 실행하면 문제되는 처리 (디바이스 조작 외) -> 커널모드에서 동작
- 프로세스 관리 시스템
- 프로세스 스케줄링
- 메모리 관리 시스템
이런식으로 커널 모드에서 동작하는 OS의 핵심부분을 처리를 모아 담당하는 프로그램을
커널
커널 이란?
메모리에 상주하는 부분으로써 운영체제의 핵심적인 부분을 뜻한다.
이에 반에 넓은 의미의 운영체제는 커널뿐 아니라 각종 시스템을 위한 유틸리티들을 광범위하게 포함하는 개념이다. (보통은 운영체제라고 하면 커널을 말하게 된다.)
시스템 콜: 프로세스가 커널이 제공하는 기능을 커널에 요청
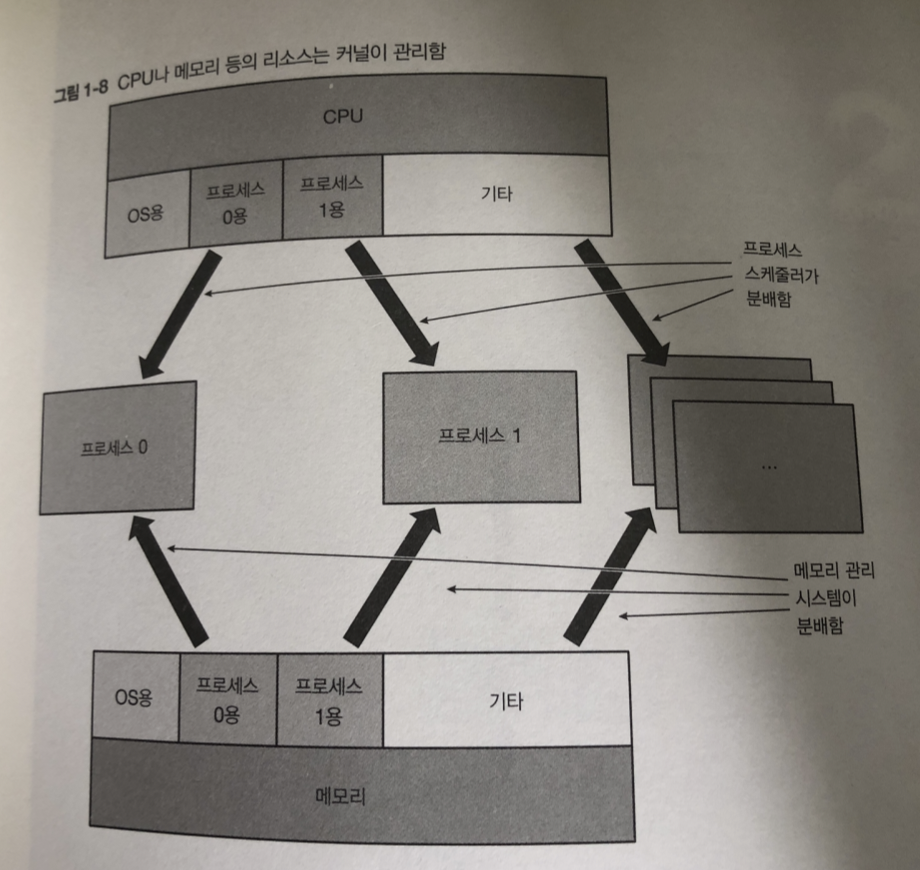
커널은 시스템에 탑재된 CPU나 메모리 자원을 관리하고 있음
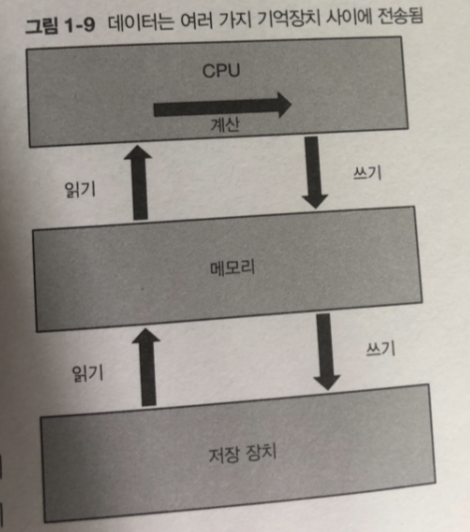
프로세스 실행에 있어서는 다양한 데이터가 메모리를 중심으로
CPU의 레지스터나 저장 장치 같은 기억장치에 전송 됨.

저장장치에 보관된 데이터는 파일시스템이라는 프로그램을 통해 보통 접근함.
2장 사용자 모드로 구현되는 기능
사용자 모드 프로그램
- 라이브러리 형태
- 단독 프로그램
으로 구성 되 어 있음
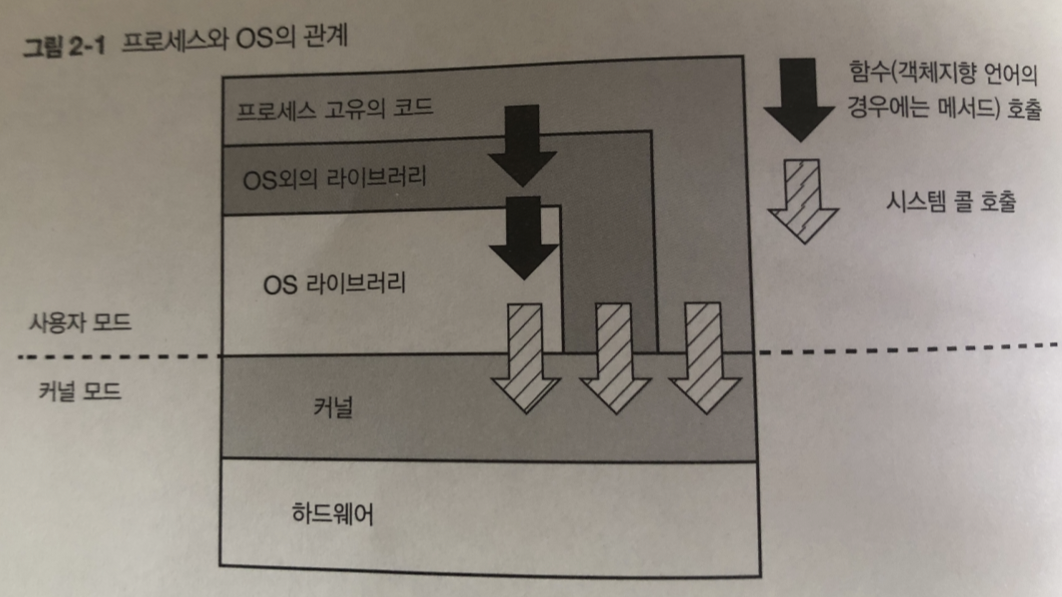
그림은 사용자 모드의 프로세스 처리부터 -> 시스템 콜을 통한 커널처리 호출 방식
시스템 콜
프로세스는 프로세스의 생성이나 하드웨어의 조작 등 커널의 도움이 필요할 경우
시스템 콜을 통해 커널에 처리 요청 함.
시스템 콜의 종류
- 프로세스 생성 ,삭제
- 메모리 확보 , 해제
- 프로세스 간 통신(IPC)
- 네트워크
- 파일시스템 다루기
- 파일 다루기(디바이스 접근)
CPU의 모드 변경
CPU의 특수한 명령을 실행해야만 호출되는 시스템 콜
프로세스는 보통 사용자 모드로 실행한다
커널 처리를 위해 시스템 콜 호출 하면 CPU에서 인터럽트 발생
(인터럽트? 일을하 고 있는대 인터럽트 발생하면 그일부터 실행? 이런의미 인듯)
그러면 CPU는 커널모드로 변경됨 요청한 내용을 처리하기 위해 커널은 동작하기 시작
요청 내용 끝나면 커널내 시스템 콜 종료 .. 요약할수 없을까.. ㅠㅠ
사용자 모드로 돌아가 다시 프로세스 실행
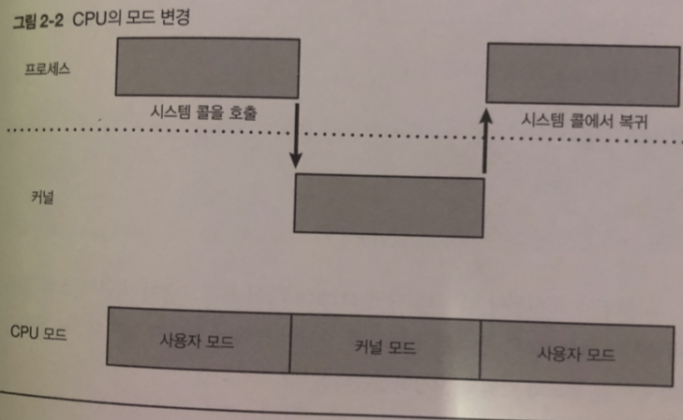
그림 참조.
- 커널은 프로세스가 요청한 내용을 처리하기전에 요청이 유효 한지 확인
- 시스템 메모리 용랴ㅑㅇ 이상의 메모리 요구 등.
만약에 요구사항이 맞지 않으면 커널 시스템 콜 실패!
시스템 콜 호출의 동작 순서
strace 명령어로 확인 .


strace 명령어로 확인
각각의 줄은 1개의 시스템 콜 호출
1번은 write 시스템 콜
이 밖에 OS에서 제공되는.. 시작과 종료 처리등 많이 시스템 콜을 호출 함..

위 그림은 파이썬 print 실행시 strace 화면
2번 시스템 콜 외에 파이썬은도 또한 많은 시스템콜을 호출했지만 신경쓸 필요는 없다
실험
사용자 모드와 커널 모드중 어느쪽에 실행되고있는지 확인해 보자!
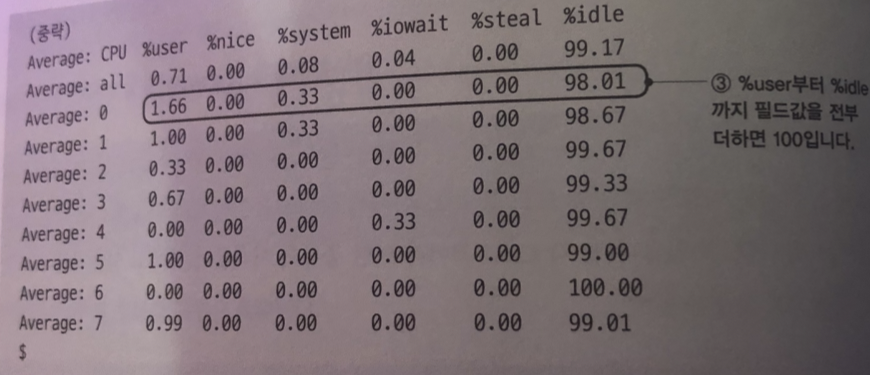
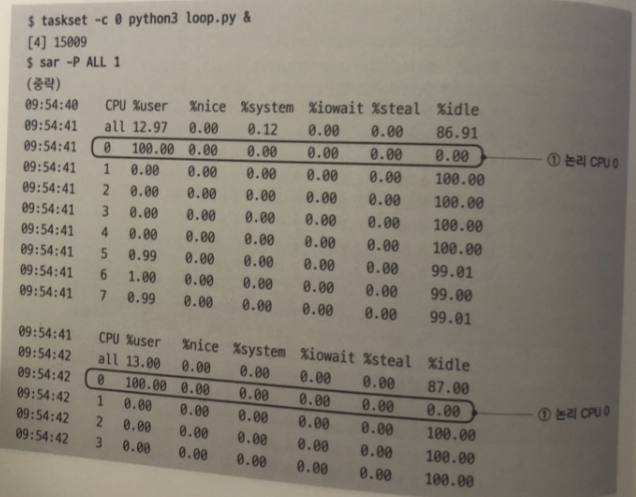
1줄에는 1개의 cpu가 대응 이 시스템은 8개의 cpu코어 정보가 출력되고 있음
%system: CPU 코어가 커널 모드에서 시스템 콜 등 처리를 실행하고있는 시간 비율은

시스템콜을 호출하지 않고 무한 for 문 작성시
cpu 0 코어에서는 유저 프로세스 loop프로그램이 계속 동작하고 있다.
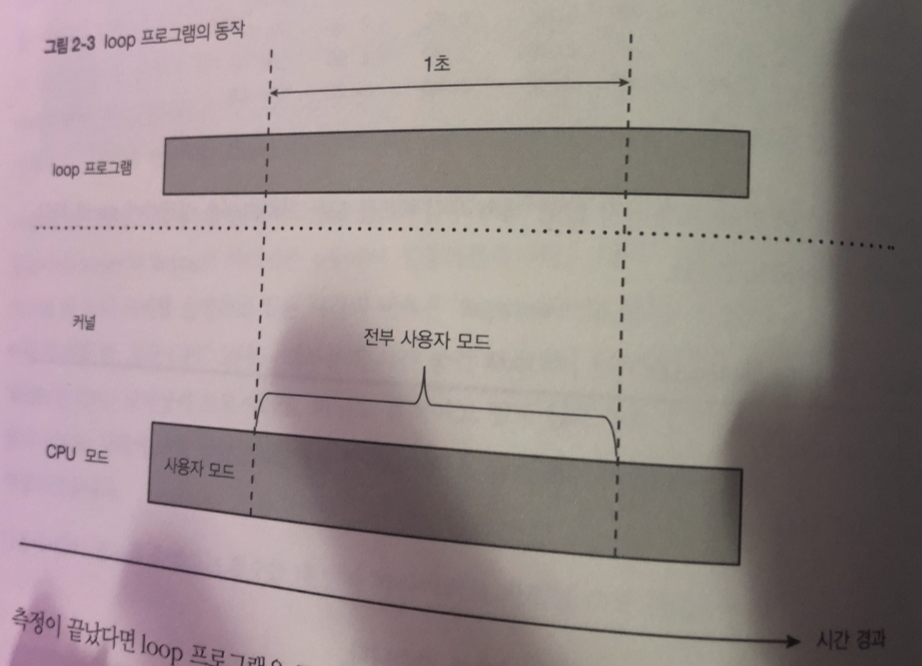
그림을 보면 사용자 모드에서만 동작하는 걸 알 수 있다.
이번에는 getppid() 시스템콜 무한루프 프로그램을 실행시켜보자
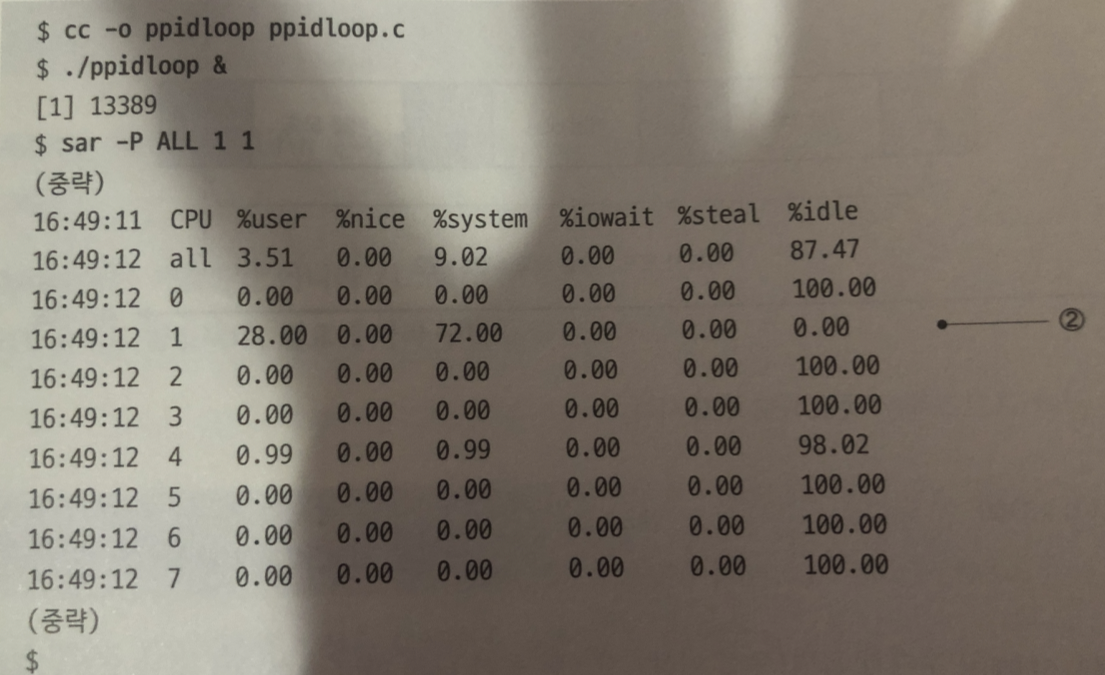
실행결과 2번은 통계 정보?? 측정하고있던 1초 동안 한일을 알수 있다.
28 % 는 ppidloop 프로그램 실행 비율
시스템콜에 의한 나머지 72프로는 커널처리.
28 프로 비율이 나오는것은 프로그램안에 main() 함수 안 getppid() 무한루프를
하기 위해 루프를 처리하는데 프로그램이 프로세스를 사용하기 때문

%system 수치가 크면 시스템 콜이 너무 많이 호출 OR 시스템 과부하 등 이유가 있다.
시스템 콜의 소요 시간
strace -T 명령어를 사용하면 시스템 콜 처리 시간을 마이크로 단위로 알 수 있다.
구체적으로 어떤 시스템콜이 시간이 많이걸리는지 확인하기 위해

시스템 콜의 wrapper 함수
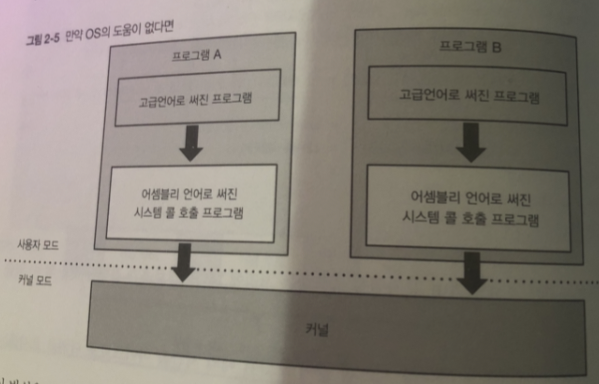
리눅스에는 프로그램 작성을 도와주기 위해 여러 라이브러리 함수가 있다.
시스템 콜은 보통 아키텍처에 의존하는 어셈블리 코드를 사용해 호출할 필요가 있음
그래서 OS에 도움이 없다면
각 프로그램은 시스템 콜을 호출 할 때마다 아키텍처에 의존하는
어셈블리 언어를 써서 고급언어로부터 어셈블리 코드를 호출 해야됨
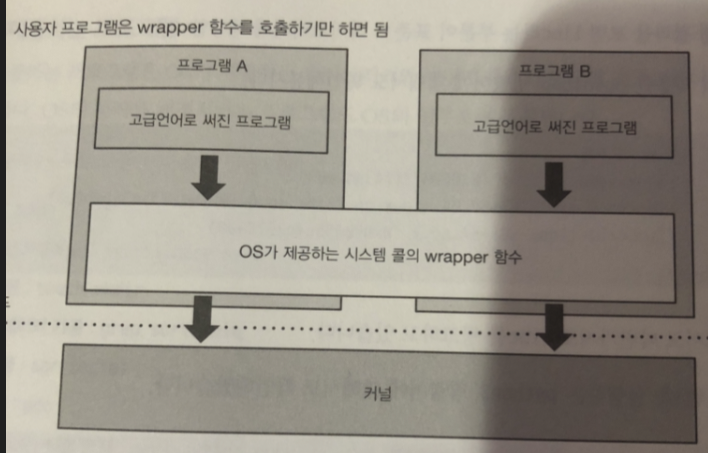
표준 C 라이브러리
리눅스에는 표준 C 라이브러리가 제공됨 (glibe 를 링크하고 있음)
glibe 는 시스템 콜의 wrapper 함수를 포함
- POSIX 규격에 정의된 함수
(유닉스 계열 OS가 갖추어야 할 각종 기능 정해둔 규격)

libc라는 부분이 표준 C 라이브러리에 해당
OS가 제공하는 프로그램
OS가 제공하는 프로그램은 OS가 제공하는
라이브러리와 마찬가지로 대부분의 프로그램이 필요 함
OS의 동작을 변경시키는 프로그램도 OS의 일부로 제공 함
- 시스템 초기화 : init
- OS의 동작을 바꿈 : sysfctl.niice.sync
- 파일관련 : touch.mkdir
- 텍스트 데이터 가공 : grep.sort.uniq
- 성능 측정 : sar.iostat
- 컴파일러 : gcc
- 스크립트 언어 실행 환경 : perl.pyhon. ruby
- 쉘 : bash
- 윈도우 시스템 : X
3장 프로세스 관리
커널의 프로세스 생성 및 삭제 기능에대해 설명
이번 장에는 가상 기억장치가 없는 단순한 경우에만 설명
프로세스 생성의 목적
목적 1
같은 프로그램의 처리를 여러 개의 프로세스가 나눠서 처리
ex) 웹 서버처럼 리퀘스트가 여러 개 들어왔을 때 동시에 처리해야 하는 경우
목적 2
전혀 다른 프로그램을 생성합니다. 예를 들어 bash로 부터 각종 프로그램을 새로 생성하 는 경우
생성 목적에는 fork() , execve() 함수를 사용함.
(시스템 내부에서는 clone() , execve() 시스템콜 호출)
fork() 함수
목적 1 번에는 fork() 함수만 사용함
fork() 함수 실행 한 프로세스와 함께 새로운 프로세스 1개 생성 됨.
생성 전의 프로세스를 부모프로세스 , 새롭게 생성된 프로세스를 자식 프로세스
프로세스 생성 순서
- 자식 프로세스용 메모리 영역을 작성하고 거기에 부모 프로세스 메모리 복사
- fork() 함수의 리턴값이 각기 다른 것을 이용 하여 부모 프로세스와
자식 프로세스가 서로 다른 코드를 실행하도록 분기.
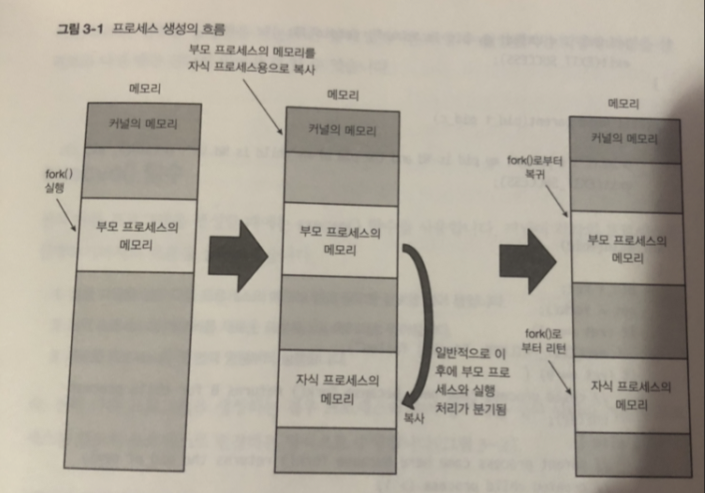
그림 을 보면
프로세스를 새로 만들고.
부모 프로세스는 자신의 프로세스 ID와 자식의 프로세스ID 출력 뒤 종료
fork() 함수를 리턴 할 때 부모 프로세스는 자식 프로세스의 ID를
자식 프로세스는 0을 리턴 함 이를 이용해 서로 프로세스의 처리를 나눠서 실행함

코드를 보면 fork() 한뒤 부모 프로세스가 가 먼저 실행되고
뒤이어 자식 프로세스가 생성되면서 child() 함수도 호출된다. (분기)
execve() 함수
전혀 다른 프로그램을 생성할 때에는 execve() 함수 이용
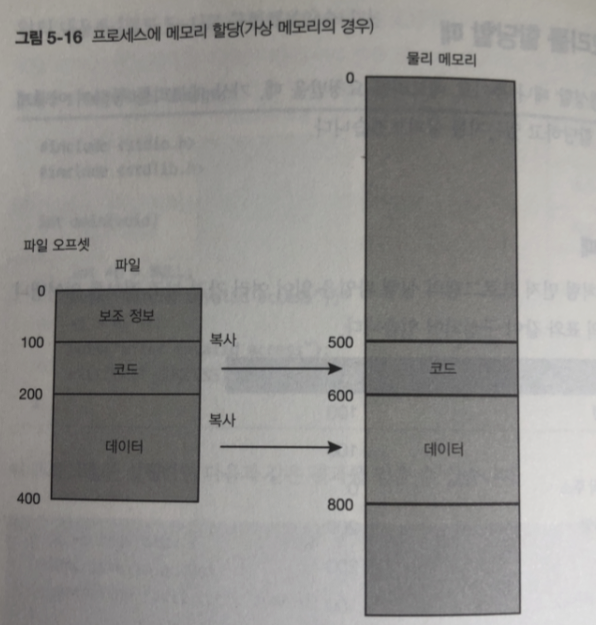
- 실행파일을 읽은 다음 프로세스의 매모리 앱에 필요한 정보를 읽는다.
- 현재 프로세스의 메모리를 새로운 프로세스의 데이터로 덮어씀
- 새로운 프로세스의 첫 번째 명령 부터 실행
다른 프로그램을 생성하는 경우 기존 프로세스를 별도의 프로세스로 변경하는 방식임
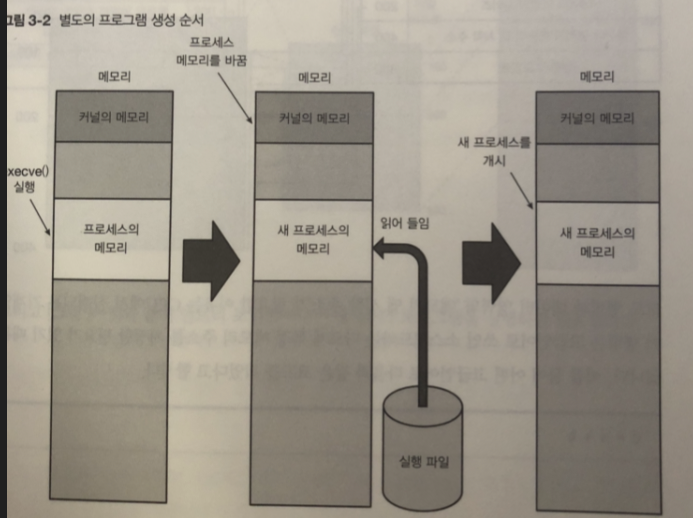
실행 파일을 읽고 -> 프로세스의 메모리 맵에 필요한 정보를 읽음
실행 파일은 프로세스의 실행 중에 사용하는 코드와 데이터 이외 다음 과 같은 정보가 필요
- 코드를 포함한 데이터 영역의 파일상 오프셋, 사이즈 , 메모리 맵 시작 주소
- 코드 외의 변수 둥에서의 데이터 영역에 대한 같은 정보 (오프셋, 사이즈 ,메모리 맵 시작주소)
- 최초로 실행할 명령의 메모리 주소 (엔트리 포인트: entry point)
-- 오프셋에 대한 간략 설명

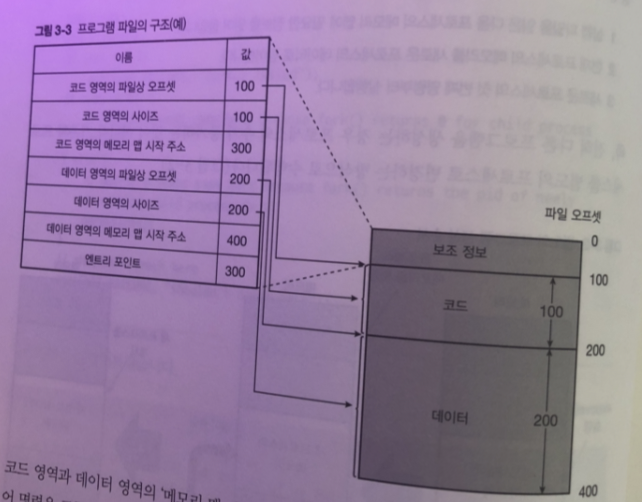
그림에서 보면 코드영역 과 데이터 영역의 메모리 맵 시작 시작 주소가 필요 한 이유는
CPU에서 실행되는 기계언어 명령은 특정 주소를 메모리 주소를 지정할 필요가 있기 때문
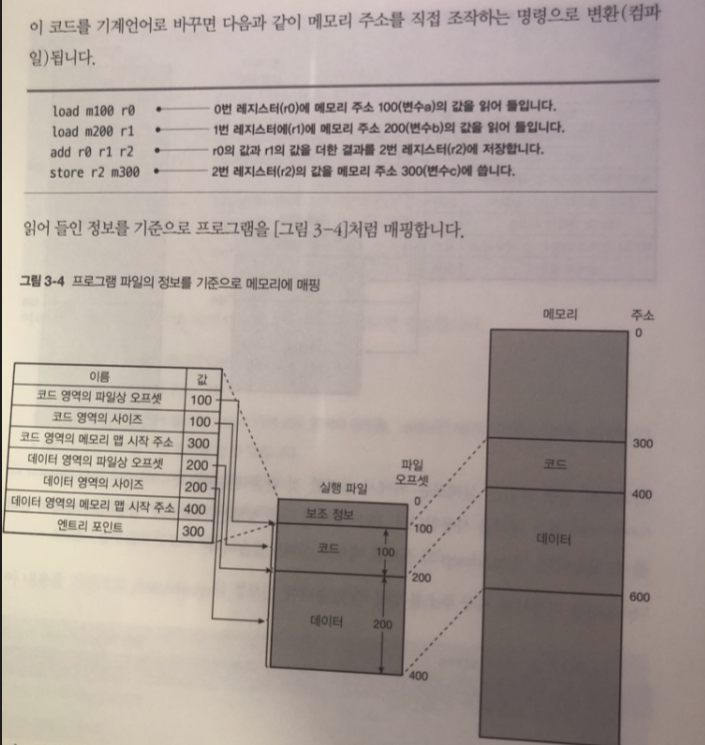
그림 처럼 고급언어를 컴파일 하면 메모리 주소를 직접 조작하는 명령어로 전환된다.
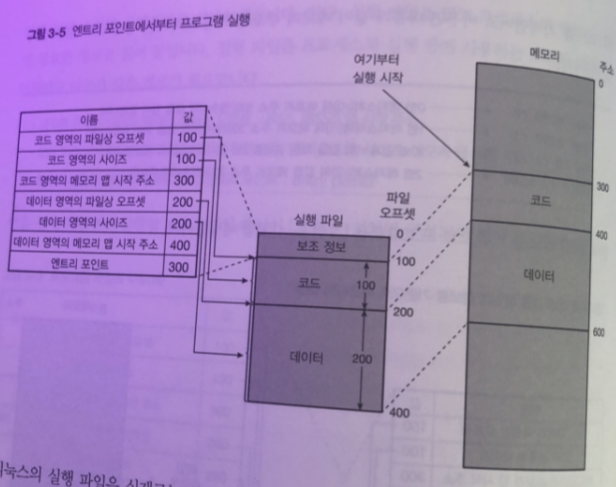
엔트리 포인트에서부터 프로그램 실행
리눅스의 실행 파일은 실제로
ELF(Executable and Linkable Format) 형식 사용

프로그램의 엔트리 포인트 를 알 수 있다.
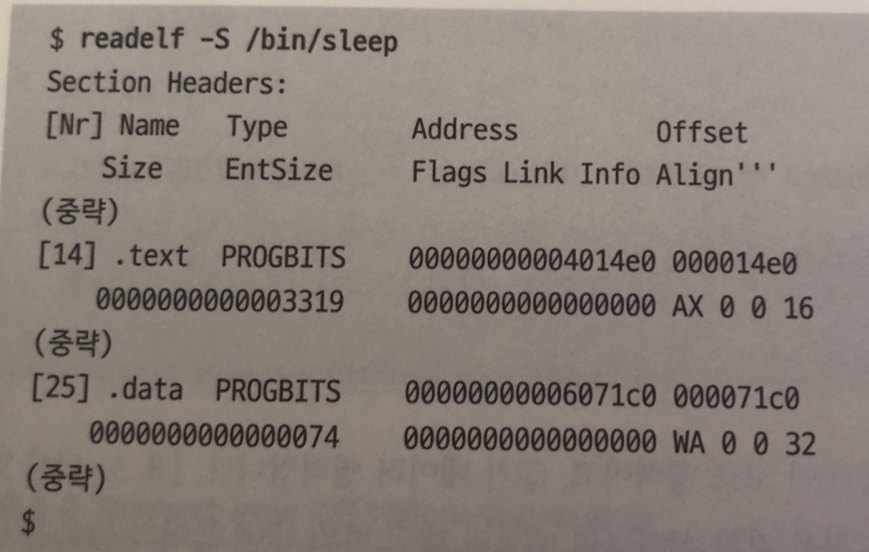
-
출력된 내용은 두 줄이 하나의 세트
-
수치는 전부 16진수
-
세트 중 첫 줄의 두 번째 필드가 .text 이면 코드 영역의 정보 .
.data면 데이터 영역의 정보를 의미 -
세트의 다음 위치를 보면 정보를 알 수 있습니다.
- 메모리 맵 시작 주소: 첫 줄의 네 번째 필드
- 파일상의 오프셋: 첫 줄의 다섯 번째 필드
- 사이즈: 둘째 줄의 첫 번째 필드

sleep 명령어 확인

1번 코드영역 / 2번 데이터 영역
코드와 데이터 영역 사이즈 값을 보면 메모리맵 의 범위 안에 들어 가 있음을 확인 할 수 있다.
전혀 다른 프로세스를 새로 생성할때 는 부모가 될 프로세스로부터
fork() 함수를 호출 한 다음 돌아온 자식 프로세스가 exec() 함수를 호출하는 방식임
즉 fork and exec 방식을 주로 사용한다 .
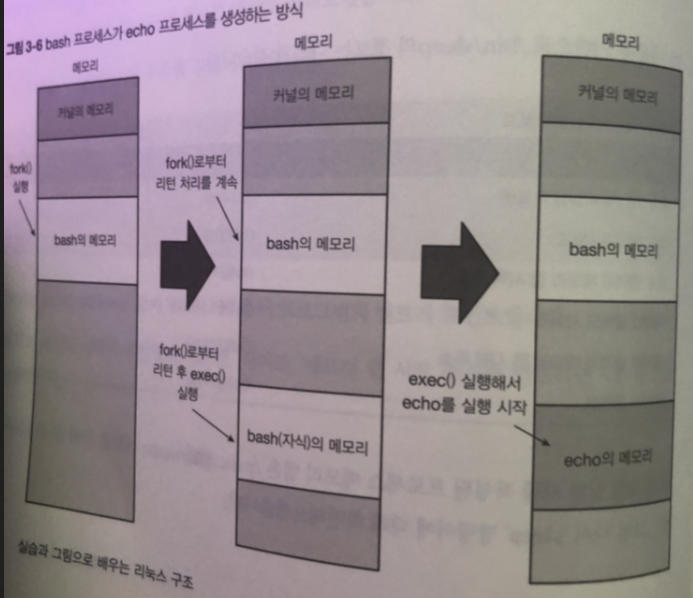


- 프로세스를 새로 만들고
- 부모 프로세스는 echo hello 프로그램을 생성 ->
자신의 프로세스 ID와 자식의 프로세스 ID 출력하고 종료
자식 프로세스는 자신의 프로세스 ID 출력하고 종료
종료 처리
_exit() 함수 사용 ( 내부에서는 'exit_group()' 시스템콜 호출)

할당된 메모리 전부 회수
직접 호출하기 보단 표준 C 라이브러리의 exit() 함수를 호출해서 종료함
4장 프로세스 스케줄러
여러개의 프로세스를 동시에 동작 시키는 것 처럼 보이게 하는 기능
동작방식
-
하나의 CPU는 동시에 하나의 프로세스만 처리할 수 있습니다.
-
하나의 CPU에는 여러 개의 프로세스를 실행해야 할 때는 각 프로세스를 적절한 시간으로
쪼개서 번갈아 처리함 ( 타임 슬라이스 )
리눅스에서 멀티코어 CPU는 코어가 1개의 CPU로 인식
이 책에선 논리 CPU라고 설정하고 시작
하이퍼스레드 기능이 있으면 각 코어 내의 각각의 하이스 스레드가 논리 CPU로 인식됨
테스트 프로그램의 사양
여러 개를 동시에 움직여 통계 정보를 얻어 보자
- 특정 시점에 논리 CPU에는 어떤 프로세스가 동작 중인지
- 각각의 프로세스는 어느 정도 진행 되었는지
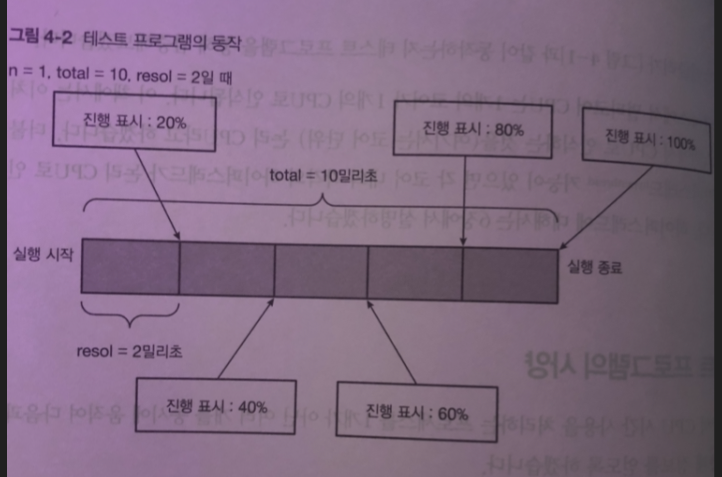
명령어 라인의 파라미터 (n , total, resol)
n: 동시의 동작하는 프로세스 수
total: 프로그램이 동작하는 총 시간(밀리초 단위)
resol : 데이터 수집 간격(밀리초 단위)
n개의 프로세스가 동작다음 모두 종료되면 프로그램 종료
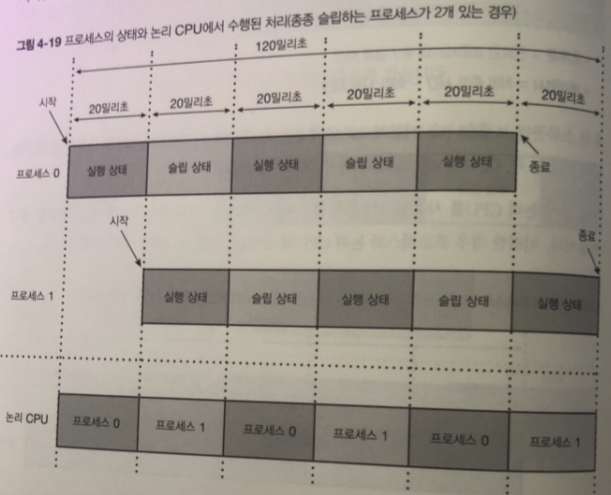
각 프로세스 동작 방식
- CPU 시간을 total 밀리초만큼 사용 후 종료
- CPU 시간을 resol 밀리초만큼 사용할 때마다 프로세스별로 고유의 ID(0부터 n-1 까지의 각 프로세스 의 고유번호) 프로그램 시작 시점부터 경과한 시간 , 진행도(%) 기록
종료할 때에 위의 데이터를 tab으로 구분하여 한 줄 씩 출력
테스트 프로그램 작성
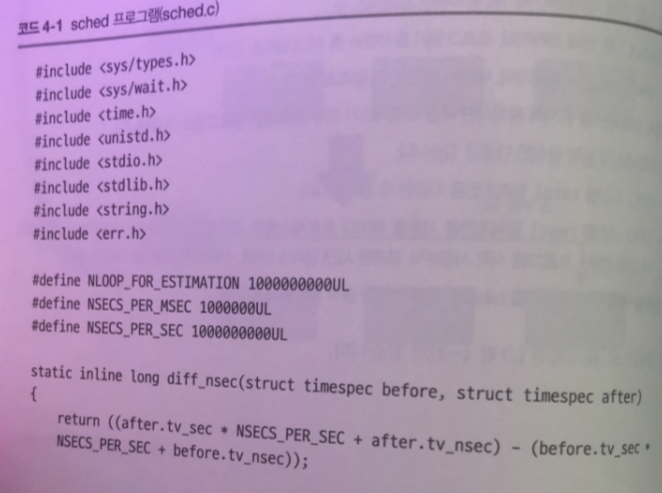




코드가 길지만 간추려보면
중요 포인트는 CPU 시간을 1밀리초 단위로 사용처리에 필요한 계산량을 추정하는
1 - loops_per_msce() 함수
최초에 적당한 횟수(NLOOP_FOR_ESTIMATION) 만큼 아무것도 하지 않는
루프를 돌려 필요 시간 측정
-> 컴파일 cc -o sched sched.c
첫 번째 실험
실험 4-A : 동작 프로세스가 1개
실험 4-B : 동작 프로세스가 2개
실험 4-C : 동작 프로세스가 4개
시스템 부하가 걸린다? 로드밸런서가 프로세스를 여러 개의 논리 CPU 나눠 실행 함
taskset : cpu 지정하고 여기에서만 지정한 프로그램 동작하게.
실험 4-A


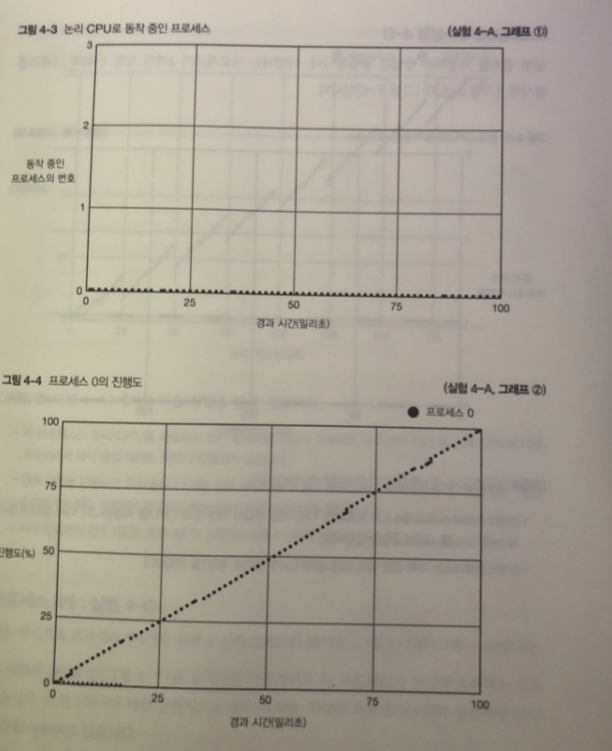
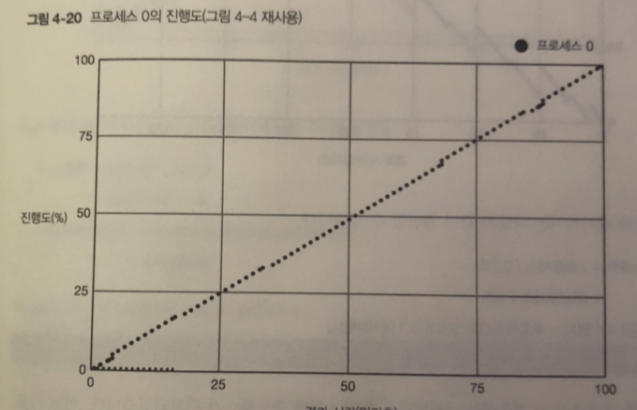
측정 결과와 그래프
그림 1 프로세스 0이 항상 동작중
실험 4-B
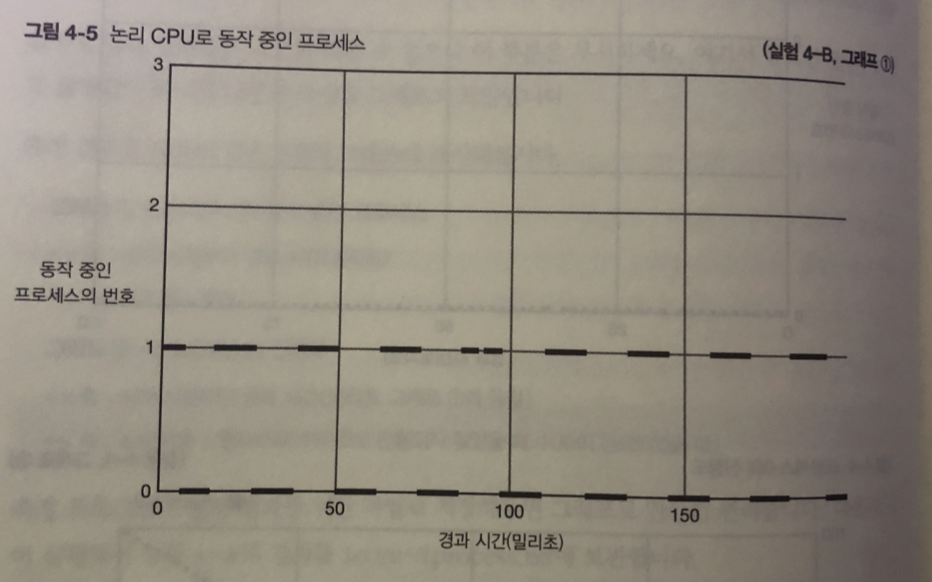
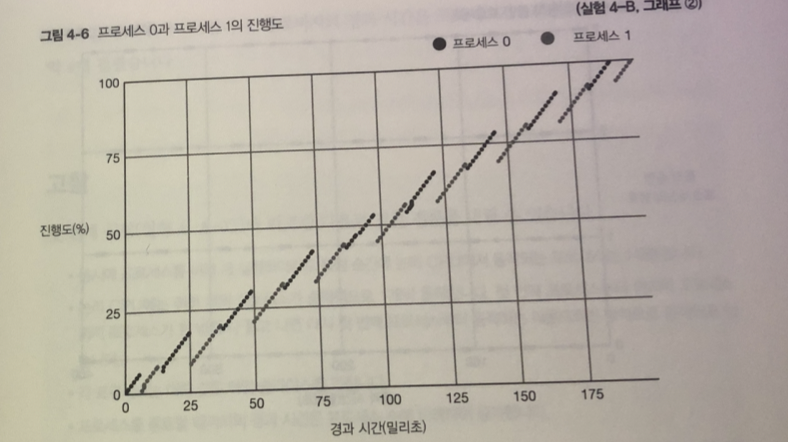
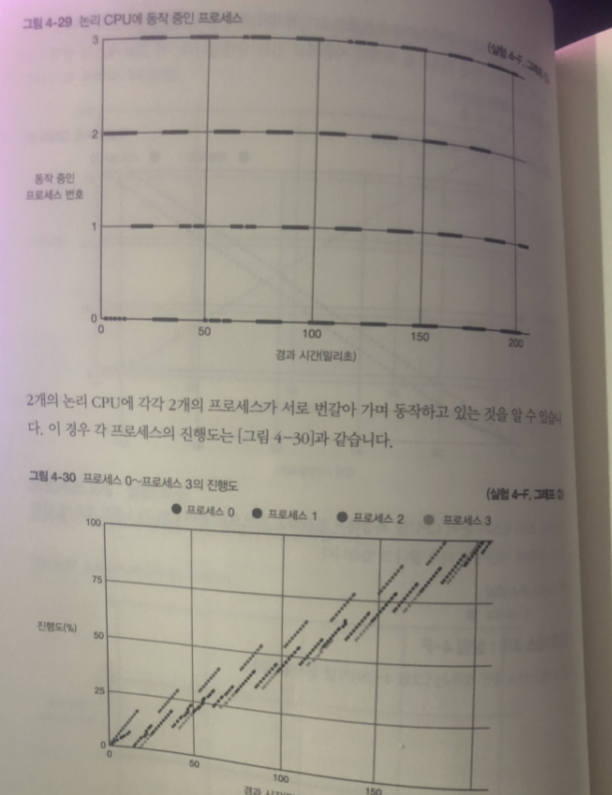
그림 1 - 2개의 프로세스가 서로 반갈아 가며 논리 CPU 사용 중
다시 말하면 동시에 CPU 사용하는게 아님
- 2개 의 프로세스느 대략 같은 양의 타임 슬라이스를 가짐
그림 2 - 각 프로세스는 논리 CPU 사용하고 있을 동안만 처리 됨.
- 단위 시간별 진행도는 프로세스가 1개 일 때와 비교하면 절반 정도
2 개일 때 1 밀리초마다 0.5% 진행도
- 처리 시간은 2 배정도 실험 4-A 보다
실험 4-C

고찰
- 동시에 프로세스를 여러 개 실행하더라도 특정 순간에 논리 CPU 에 동작하는 건 1개 뿐
- 논리 CPU에는 여러 개의 프로세스가 순차적으로 1 개씩 동작 (라운드 로빈 방식)
- 각 프로세스는 대략 같은 타임 슬라이스
- 프로세스를 종료할 때 까지의 경과 시간은 프로세스 수에 비례 증가
컨텍스트 스위치
논리 CPU 상에서 동작하는 프로세스가 바뀌는 것을 컨텍스트 스위치라고 함
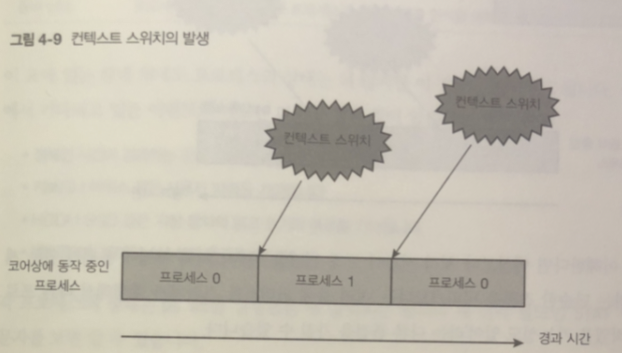
어떤 프로그램을 수행 하더라도 컨텍스트 스위치는 타임 슬라이스를 모두 소비하면 발생

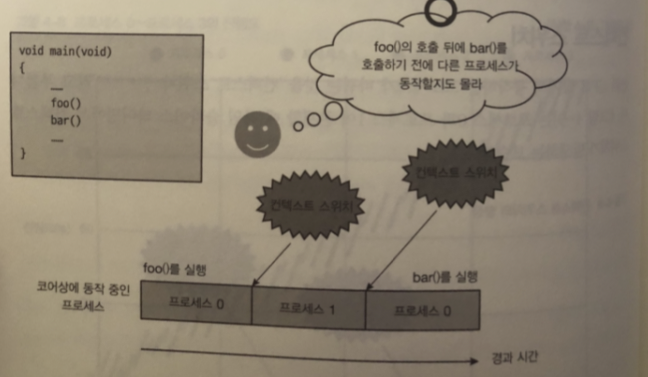
위는 잘못된 이해
아래가 올바른 이해
타임 슬라이스가 모두 소비해야 bar()를 실행 함으로
그래서 예상보다 처리 시간이 오래 걸렸을 때
이 처리 자체에 문제가 있는게 틀림없어!
-> 처리 중에 컨텍스트 스위치가 발생해서 다른 프로세스가 움직였을 가능성도 있어 라는 관점이 생김
프로세스의 상태
ps ax : 시스템에 존재하는 프로세스 목록 확인
sched 프로그램내 프로세스만 cpu 시간을 분배 하고 있는데
시스템의 다른 프로세스는 무엇을 했을까?
프로세스 진행 상태는 여러 상태가 있는데 대부분 프로세스는 슬립 상태
실행 상태 : 현재 논리 CPU를 사용하고 있습니다
실행 대기 상태: CPU 시간이 할당되기를 기다리고 있습니다
슬립 상태: 이벤트가 발생하기를 기다리고 있으며 이벤트 발생까지 CPU 시간을 사용 X
좀비 상태 : 프로세스가 종료한 뒤 부모 프로세스가 종료 상태를 인식할 때까지 대기
슬립상태에서 기다리고 있는 이벤트
- 정해진 시간이 경과하는 것을 기다림( ex) 3분 대기)
- 키보드나 마우스 같은 사용자 입력을 기다림
- HDD나 SSD 같은 저장 장치의 읽고 쓰기의 종료를 기다립니다
- 네트워크의 데이터 송수신의 종료를 기다립니다.

ps ax R 상태 프로세스의 상태를 출력하기 위해 동작중이기 때문
bash가 슬립인 상태는 입력 값을 기다리고 있기 때문
D 상태로 있는것은 수 밀리초 정도 지나면 다른 상태로 바뀜
장시간 내 D가 바뀌지 않는다?
- 스토리지 I/O가 종료되지 않는 상태로 되어있다.
- 커널 내 뭔가 문제가 발생하고 있다.
상태 변환
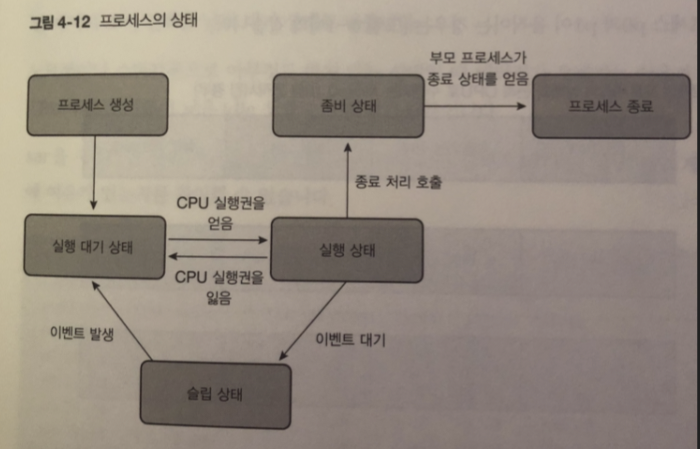
그림을 보듯이 살아있는 동안 실행 상태 , 실행 가능 상태 , 슬립상태를 몇 번이고 오감
- 슬립 상태로 가지 않는 프로세스
4-A 실험


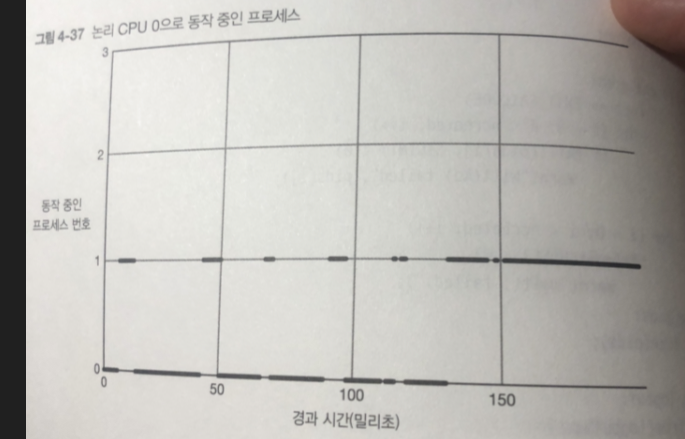
idle 상태
위 그림 처럼
하나의 프로세스가 CPU 0 에서 동작하지 않는 시간이 있다.
이때 논리 CPU에는 무슨일이 벌어 질까?
idle 프로세스라 하는 아무것도 하지 않는 특수한 프로세스가 동작 하고 있다.
idle 프로세스 가장 단순한 구현은 ->
새로운 프로세스가 생성되거나 슬립 상태에 있는 프로세스가
깨어날 대까지 아무 의미 없는 루프를 하고 있다.
그러나 이렇게 만들면
전력만 낭비하기 때문에 CPU의 특수한 명령을 이용해 논리 CPU를 휴식 상태로
만들어 하나 이상의 프로세스가 실행 가능한 상태가 될때까지 소비 전력을 낮춰
대기 상태로 만듬
EX) 노트북이나 스마트폰으로 아무것도 하지 않으면 배터리가 오래가는 이유가
논리 CPU가 소비 전력이 낮은 idle 상태로 오래 있기 때문
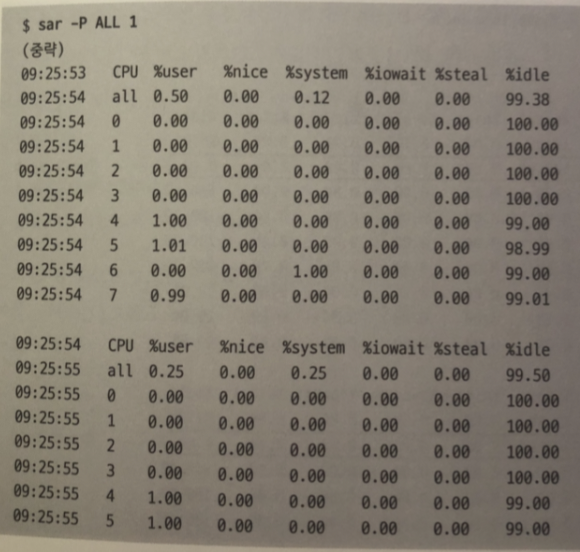
현재는 시스템 전체가 CPU 시간을 거의 사용하지 않았음을 알 수 있다.
다음은 무한루프를 도는 코드를 싱행 했을때는?
여러가지 상태 변환
실제 시스템에는 다양한 프로세스가 각각 다양한 상태를 거치게 됨.
다음 과 같은 프로세스가 실행될 때?
- 사용자로부터 입력 받기.
- 입력받은 내용으로 파일을 읽는다.

- 논리 CPU로 한 번에 실행할 수 있는 프로세스는 1개
- 슬립 상태에서는 CPU 시간을 사용하지 않음
스룻풋과 레이턴시
각종 처리의 성능 지표 스루풋 과 레이턴시 개념 정리
스루풋 : 단위 시간당 처리된 일의 양으로 높을수록 좋다.
레이턴시: 각각의 처리가 시작부터 종료까지의 경과된 시간으로 짧을수록 좋습니다
계산식
스루풋 : 완료된 프로세스의 수 / 경과 시간
레이턴시 = 처리종료시간 - 처리 시작 시간
스루풋
스루풋은 논리 CPU의 연산 리소스를 사용하면 할수록 높아짐.
-> idle 상태가 적어질 수록 높아짐

CPU를 사용했다 슬립 했다가 반복하는 프로세스
그림을 보면 idel 이 40 %
스루풋 = 1 프로세스 / 100 밀리 초 - > 1 프로세스 / 0.1 초
10개 프로세스 1초
스루풋 = 2프로세스 / 120 밀리초 -> 2 프로세스 / 0.12 -> 16.7 프로세스 /1초
idle = 0%
이 결과로 idle 이 낮을 수록 스루풋이 높아진다.
레이턴시
4-A~C 데이터 사용
스루풋은 동일
4-A = 100 밀리 초
4-B = 200 밀리초
4-C = 400 밀리초
결론 -> 논리 CPU의 능력을 전부 활용 (idle 0%) 하면
- 스루풋은 동일 하다
(좀 더 정확히 하면 idle 0인데도 프로세스를 계속 늘리면
컨텍스트 스위치의 오버헤드등 의 증가로 오히려 스루풋이 감소함)- 프로세스를 늘릴수록 레이턴시는 계속 증가 함.
- 각 프로세스의 평균 레이턴시는 비슷함
- 마지막 내용 보충 : 여러 개의 프로세스가 실행 가능한 상태에서
스케줄러가 라운드로빈 방식이 아닌 1개의 프로세스가 종료 후
다음 프로세스가 스케줄링 하는 방식으로 가정 했을 때
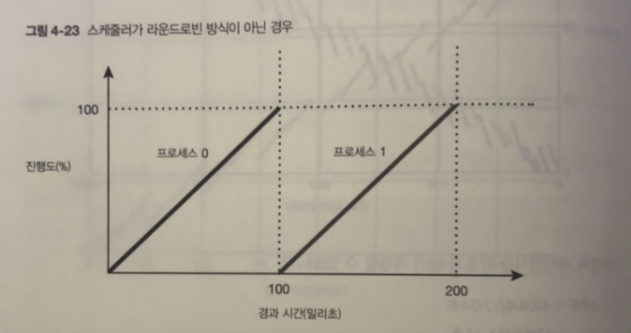
이런 경우 스루픗은 변화 X
라운드 로빈과 다르게 이번에는 스케줄이 200 밀리초 불평등 발생
이러한 불평등을 피하기 위해 스케절러는 각 논리 CPU 시간을 매우 잘게 타임 슬라이스로
쪼개서 각 프로세스에 할당 함.
실제 시스템
idle 상태가 없거나 실행 대기 상태 프로세스가 없는경우
스루풋과 레이턴시는 최대가 됨.
허나 실제 시스템에 돌아가는 논리 CPU는 다음과 같다
idle 상태: 논리 CPU가 쉬고 있어서 스루풋이 떨어짐
프로세스 동작 중 : 실행 디기의 프로세스가 없기 때문에 이상적인 상태.
그러나 이러한 상태는 다음의 프로세스가 실행 가능한 상태가 되면
2개의 프로세스의 레이턴시가 둘다 길어짐
프로세스가 대기 중 : 실행 대기 프로세스가 있다. 스루풋은 높지만 레이턴시가 길어짐
스루풋 <-> 레이턴시 는 상관 관계
실세 시스템을 설계할 때는 성능 목표로 필요한 스루풋과 레이턴시를 정의함.
sar의 %idle
sar - q의 runq-sz 필드 이 수치는 실행 중 혹은 실행 대기 프로세스의 수를 표시
(전체 논리 CPU의 합계)


논리 CPU가 여러 개일 때 스케줄링
지금 까지는 1개의 논리 CPU 로만 설명 했다.
만약 논리 CPU가 여러개라면
이 경우 스케줄러 안의 논리 CPU를 여러 개 다루기 위해
로드 밸런서
글로벌 스케줄러
기능이 동작 한다.
로드밸런서 : 여러 개의 논리 CPU에 프로세스를 분배 해주는 역할
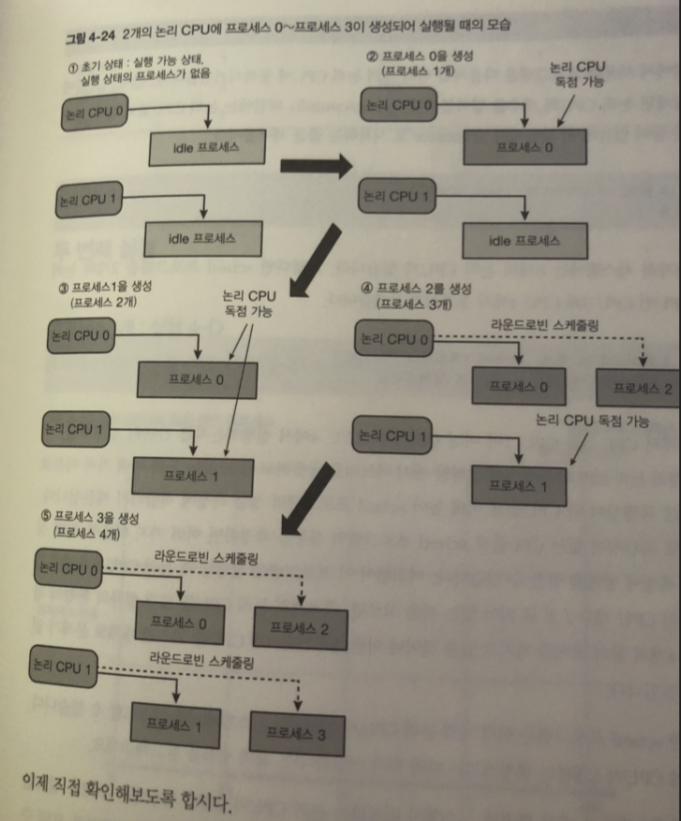
실험 방법
여러 개의 논리 CPU에 동작 시켜보자.
sched 프로개름을 2개의 논리 CPU 인 0 ,4 에 동작시키자
$ taskset -c 0,4 ./sched <프로세스 수 > 100 1
간단하게 캐시 메모리를 공유하지않는 등 독립성이 높은 0,4 CPU 로만 동작하게해
성능 측정에 용이하기 때문에 0,4 CPU로 실험
코어가 16개인경우? 0, 16/2 CPU 이용하면됨 이런식으로.

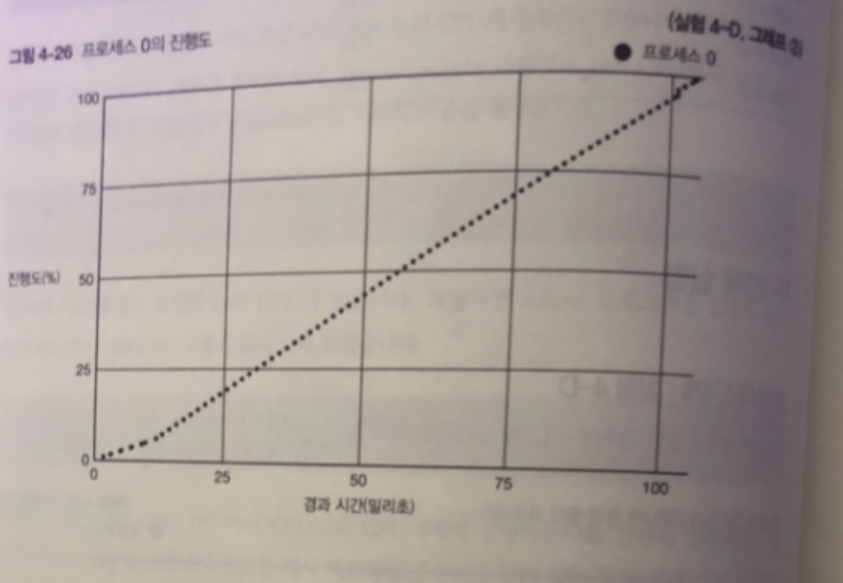
논리 CPU 의 동작중인 프로세스와 프로세스 의 진행도는
프로세스가 1개인 경우로 CPU가 1개일 때 와 결과 같다.
프로세스 2개 실험
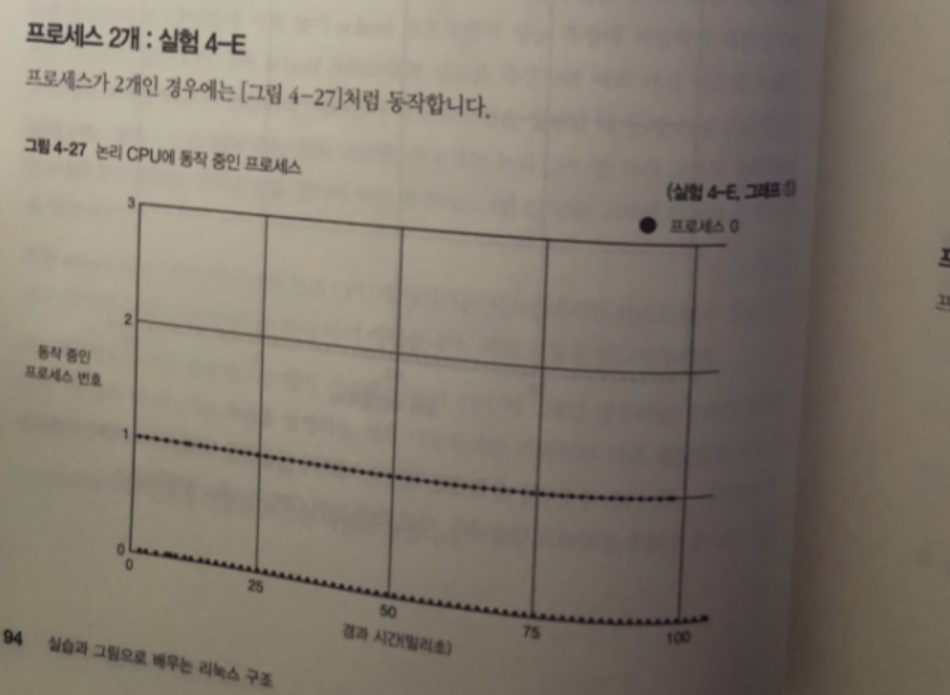
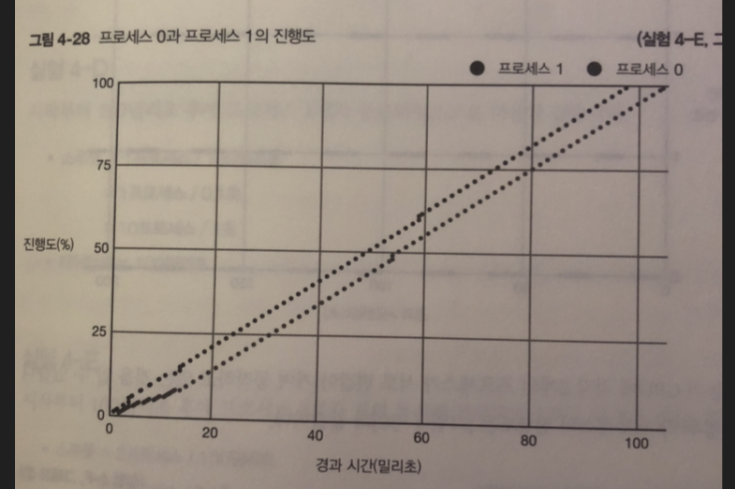
프로세스 4개 실험
각각 2개의 CPU가 서로 번갈아 가며 동작
각 실험 스루풋 과 레이턴시
D : 스루풋 10 프로세스 / 1 초 레이턴시 : 100 밀리초
E : 스루풋 20 프로세스 / 1 초 레이턴시 : 100 밀리초
F : 스루풋 20 프로세스 / 1 초 레이턴시 : 200 밀리 초
고찰
실험 결과로 알수 있는 사신
- 1개의 CPU에 동시에 처리되는 프로세스는 1개.
- 여러 개의 프로세스가 실행 가능한 경우 각각의 프로세스를 적절한
길이의 시간 ( 타임슬라이스 ) 마다 CPU 에서 순차 적으로 처리- 멀티코어 CPU 환경에서 여러 개의 프로세스를 동시에 동적 시키지 않으면 스루풋이
오르지 않는다. 코어가 N개 있으면 성능이 N 배라 말할 수 있는건 최선의 케이스- 단 1개의 논리 CPU의 경우와 마찬가지로 프로세스 수를 논리 CPU 수보다 많게 하더 라도 스루풋은 오르지 않는다.
경과 시간과 사용 시간
time 명령어를 통해서 프로세스를 동작 시키면 프로세스의 시작 부터 종료까지
시간 사이에 경과 시간과 사용시간이라는 두 가지 수치를 얻을 수 있다.
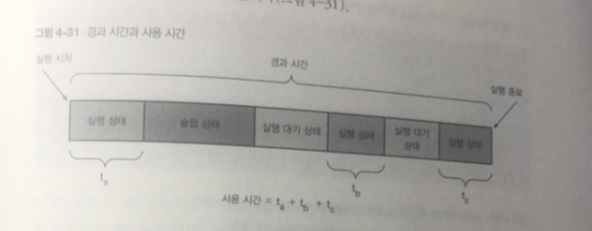
경과 시간: 프로세스가 시작해서 종료할 때까지의 경과 시간
스톱워치로 프로세스의 시작 부터 종료 까지 시간을 측정한 것을 상상해 보면 됨.
사용 시간 : 프로세스가 실제로 논리 CPU를 사용한 시간

time 사용해서
total(처리의 소요시간 ) : 10 초
resol(진행도 표시 ) : 10 초
real : 경과 시간
user + sys = 사용 시간
user : 프로세스가 실행 중인 사용자 모드에서 CPU 를 사용 한 시간.
sys : 프로세스의 실행 중에 사용자 모드의 처리로부터 호출된 커널이 시스템 콜을 실행한 시간
그림에서 부터 1개의 프로세스가 논리 CPU를 독점할 수 있또록
경과 시간과 사용 시간이 거의 같음을 알 수 있다.
또한 대부분의 시간은 사용자 모드에서 루프 처리를 하고 있기 때문에
sys의 값은 거의 0 이다.
그림에서 100% 진행도를 얻으려면 9.8 초가 걸리는대
사용시간이 11.6 초가 걸렸다.
이 두 시간 차이는 실제 처리전 1밀리초의 CPU을 사용하는 계산량을 측정하기 위해
전처리(sched.c 의 loops_per_msec() 함수 ) 에 걸린 시간 임

그림 참조

경과 시간 사용 시간이 2배가 됨.
각각의 프로세스가 논리 CPU를 절반씩 밖에 사용할 수 없기 때문


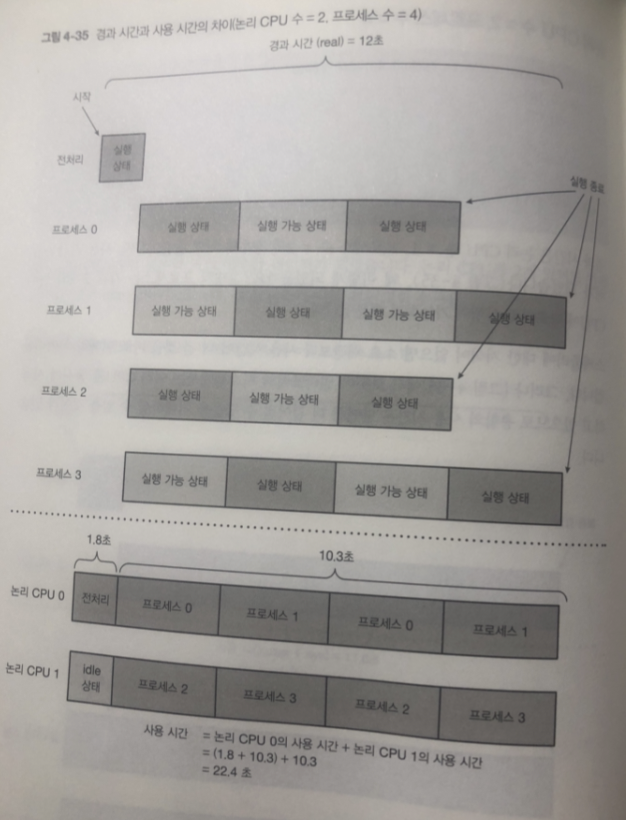
CPU가 2개이고 프로세스가 4개가 되었는대
경과 시간은 같지만 사용 시간은 2배가 되었다.
Cpu 0 + Cpu1 사용시간을 합쳤기 때문에.
슬립을 사용하는 프로세스
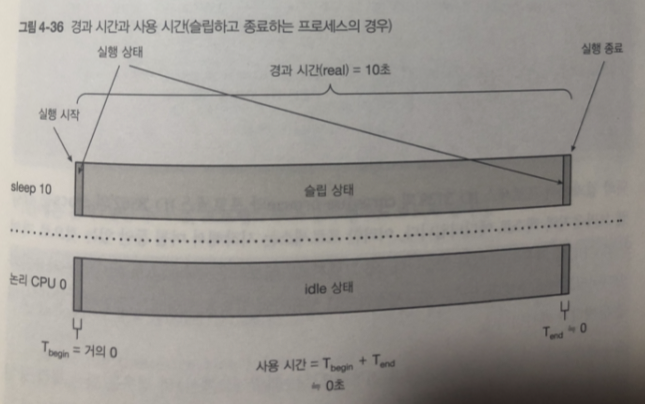
프로그램이 시장부터 일정한 시간동안 슬립 하고 종료하는 프로세스라면?

CPU는 사용 되지 않았기 때문에 0
실제 프로세스
ps -eo 명령어의 etime 필드 와 Time 필드는
프로세스의 시작부터 현재까지의 경과 시간과 사용 시간 표시
여기서는
프로세스 ID, 명령어 이름 , 경과 시간 , 사용시간 을 표시

위 그림은 각각 웹 브라우저 와 텍스트 에디터 프로세스
그런대 몇일동안 논리 CPU 사용을 왜 안하 지?
사용자와 인터랙티브 방식으로 동작하는 프로세스 이므로
사용자의 입력을 기다리는 동안 슬립 상태를 유지하기 때문

그 다음은 CPU 시간을 사용하는 처리(전형적으로 과학기술 계산) 의 경우는
다른 동작중인 프로세스가 없다면 사용 시간의 경과 시간과 사용할 CPU 개수를
곱한 값 에 거의 근접하게 됨.
무한 루프를 도느 loop.py 실행
논리 CPU = 1 프로세스 = 1

우선순위 변경
스케줄러에 관련된 시스템 콜이나 프로그램에 대해 알아 보자
nice() 시스템 콜
실행의 우선 순위를 -19~ 20 까지 설정
기본값은 0
높은 프로세스는 평균보다 CPU 시간을 더 많이 배정 받는다
우선순위 높이는건 root 권한만 내리는 건 누구라도
실험 해보자
프로세스 2개
첫번째 파라미터 total 두번째 파라미터 resol
2개중 하나는 우선순위 0 다른 하나는 우선순위 5
나머지는 원래 sched
결과
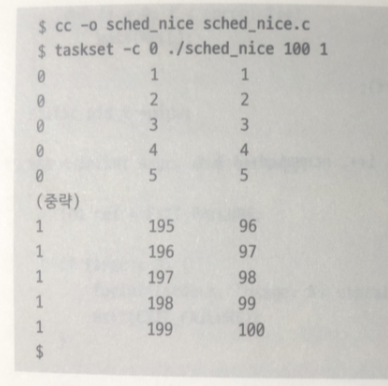
우선 순위가 높은 프로세스 0 이 우선순위가 낮은 프로세스 1 과 비교하면
더많은 CPU 시간을 할당 받음
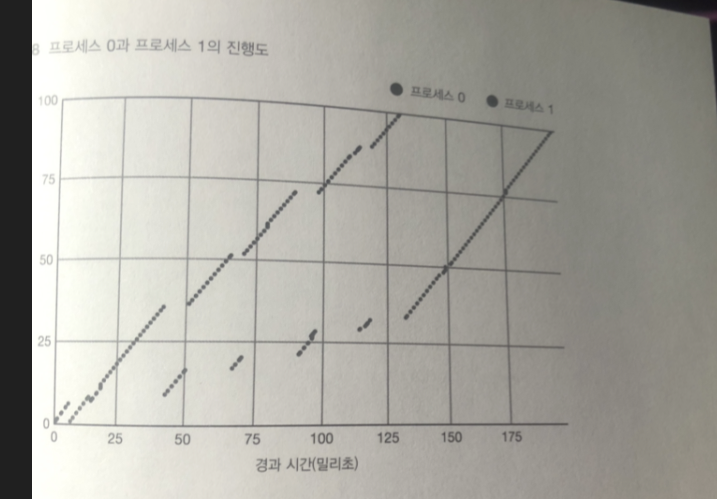
프로세스 0이 먼저 종료
nice - n에서 프로그램도 우선순위 변경가능.
메모리 관리 5 장

리눅스는 커널의 메모리 관리 시스템으로 메모리 관리 함
메모리의 통계 정보
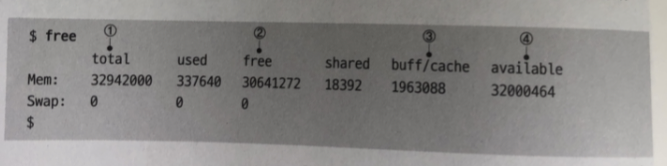
시스템의 총 메모리의 양 / 사용 중인 메모리 의 양은 free 명령어로 확인
total: 시스템에 탑재된 전체 메모리 용량
free: 표기상 이용하지 않는 메모리 (available 필드 참조)
buff/cache : 버퍼 캐시 또는 페이지 캐시 가 이용하는 메모리 시스템의 빈 메모리가
(free 필드의 값) 부족하면 커널이 해제 하고 buff/cache에 할당함
available : 실질적으로 사용 가능한 메모리 free 필드 값이 부족 해지면
해제되는 커널 내의 메모리 영역 사이즈를 더한 값으로 해제 될 수 있는
메모리에는 버퍼 캐시나 페이지 캐시의 대부분 혹은 다른 커널 내의 메모리 일부가 포함 됨
free + buff/cache + 다른커널 내 해제할 수 있는 메모리

해제 가능 + free
sar -r 명령어 또한 메모리 관련 통계 얻을 수 있음
메모리 부족
메모리 사용량이 증가하면 ?
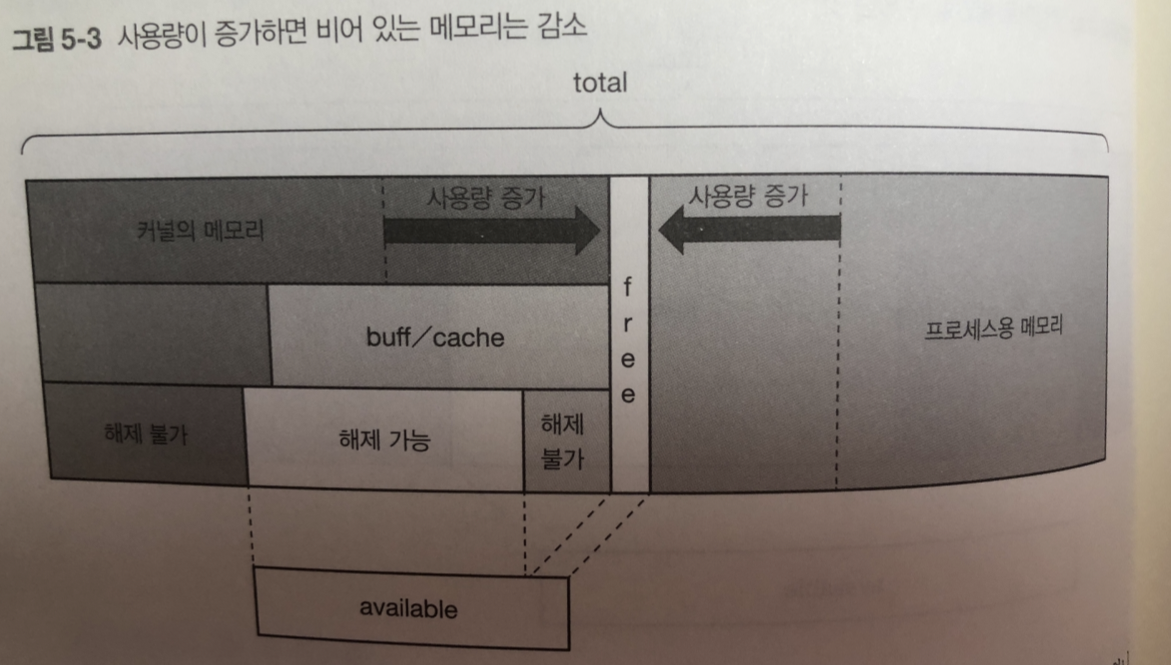
free 와 해제 가능한 영역을 해제함
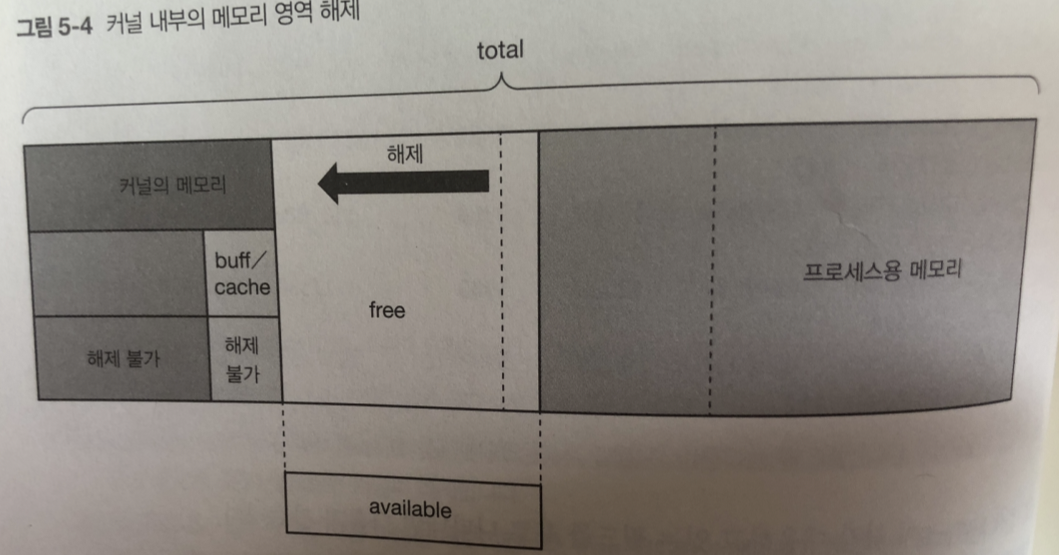
사용량이 계속 증가하면 메모리 관리 시스템은 커널 내부의 해제 가능한 메모리 영역을 해제 해버림
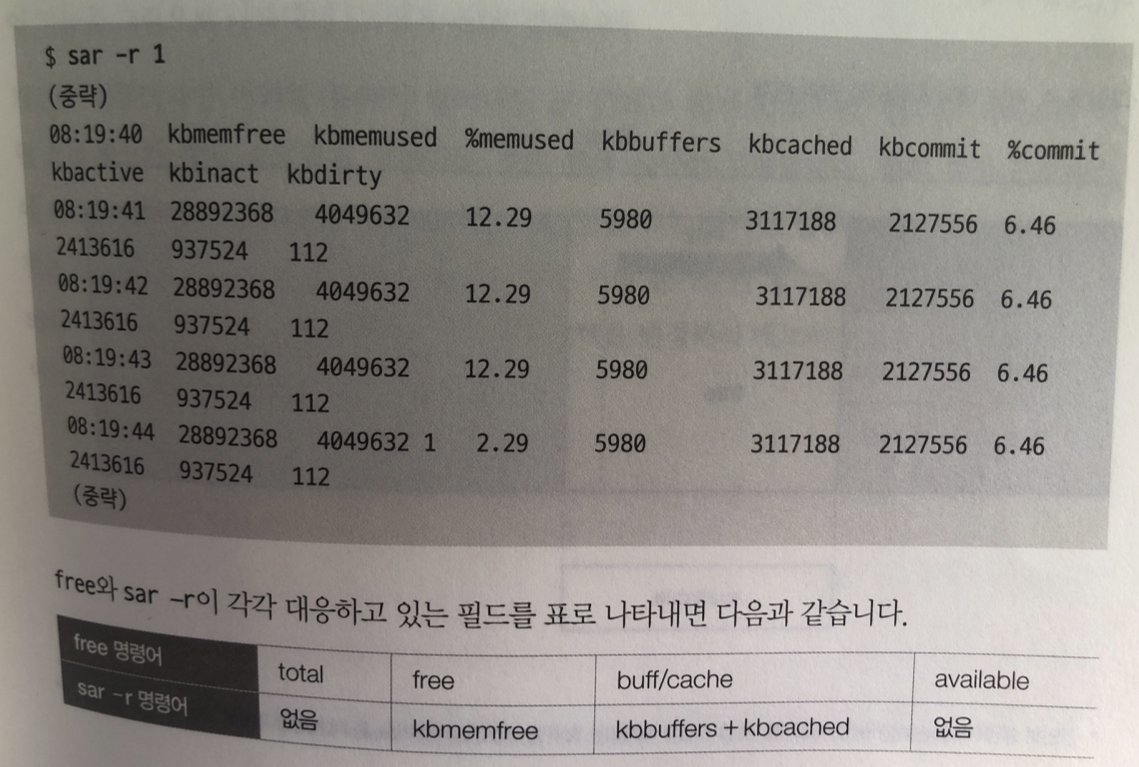
이후에도 메모리 사용량이 계속 증가하면? 메모리가 부족해서 동작할수 없는
메모리 부족 상태가 됨
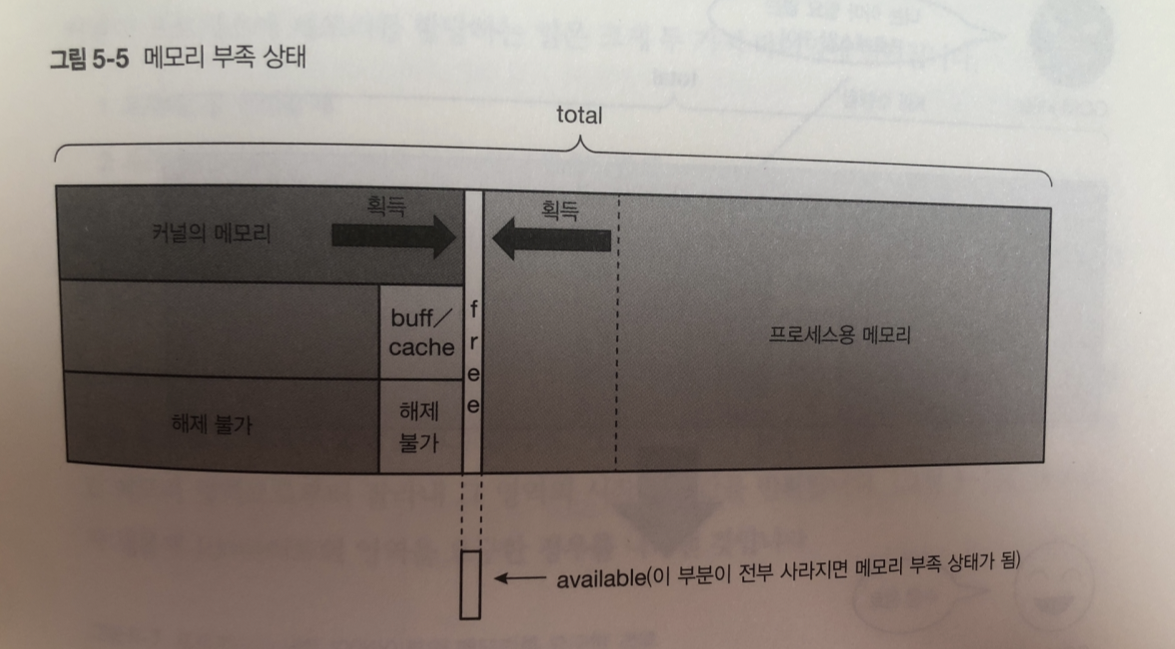
이런 상태일 경우 적절한 프로세스 선택해 강제 종료함
서버에서는 vm.panic_on_oom 파라미터의 기본값을 변경해 메모리 부족시 시스템 강제종료함
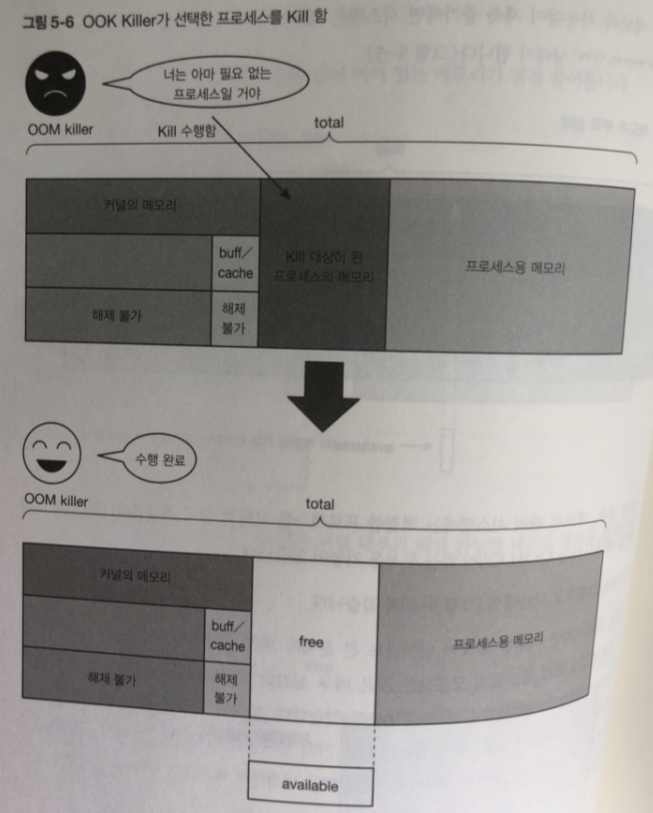
단순 메모리 할당
프로세스에 메모리를 어떻게 할당할까 ?
여기서는 가상 메모리가 없는 단순한 경우와 가상 메모리가 없어서 생기는 문제점 얘기해보자
커널이 프로세스에 메모리를 할당하는 일은 2가지 때 벌어짐
- 프로세스를 생성할 때 ( ex) fork, execve)
- 프로세스를 생성한 뒤 추가로 동적 메모리를 할당할 때
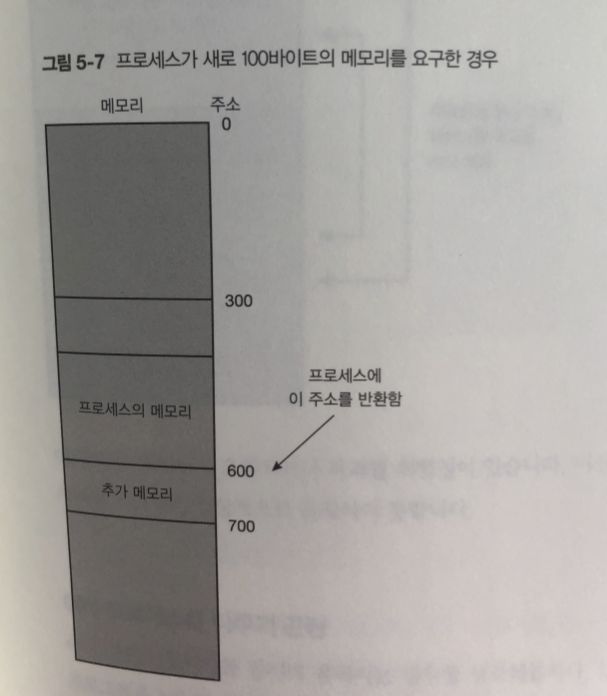
프로세스가 추가 메모리가 더 필요하면
커널에 메모리 확보용 시스템 콜 호출해 메모리 할당을 요청.
커널은 메모리 할당 요청 받으면 -> 필요 사이즈를 빈 메모리 영억으로부터 잘라냄
결과 그영역의 시작 주소값을 반환
문제점 (위 메모리 할당 문제)
- 메모리 단편화 (memory fragmentation)
- 다른 용도의 메모리에 접근 가능
- 여러 프로세스를 다루기 곤란
메모리 단편화
프로세스가 생성 된 뒤 메모리 획득 해제 반복 하면 메모리 단편화 문제가 생김.
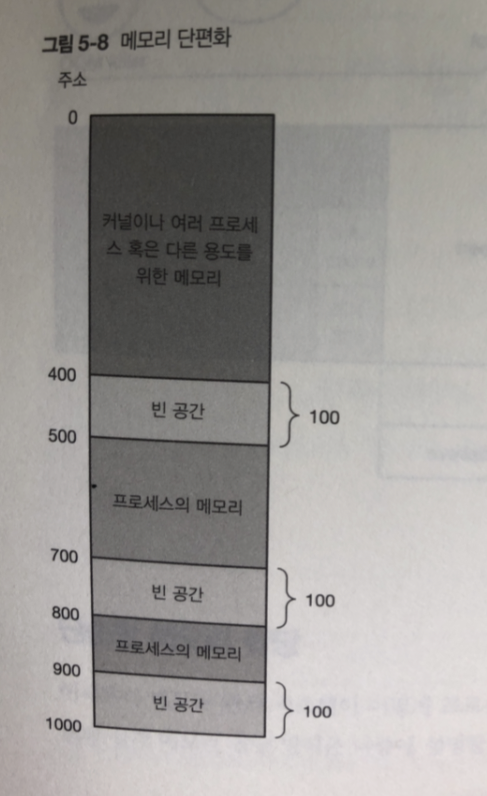
300 바이트나 비어 있지만 떨어져 있기때문에 100 바이트 보다 큰 영역 확보는 실패 함
3개 영역을 하나로 다룬다면 괜찮지만 ..
-
프로그램은 메모리를 획득할때마다 얻은 메모리가 몇개 의 영역으로 나누어져
있는지 확인해야되는 불편함.. -
100 바이트보다 큰 하나의 데이터, 예를 들어 300바이트의 배열을 만드는 용도로 사용X
다른 용도의 메모리에 접근 가능
프로세스가 커널이나 다른 프로세스가 사용하고 있는 주소를 직접 지정하면 그영역 접근 가능
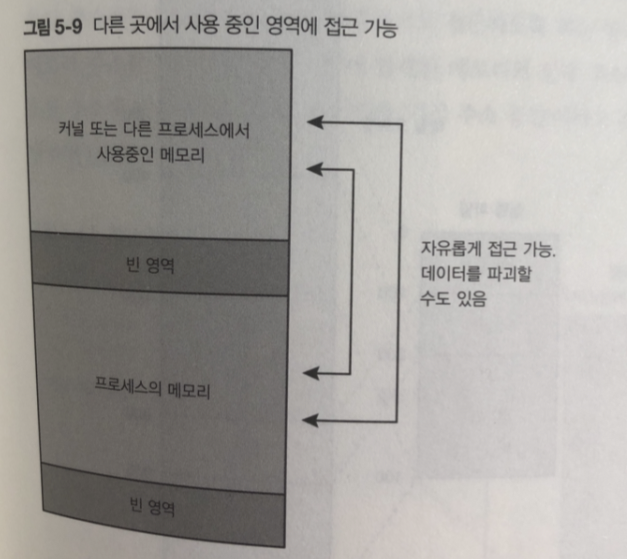
이 방식은 데이터 오염되거나 파괴 가능성 있음.
여러 프로세스 다루기 곤란
여러 개의 프로세스가 동시의 움직이면 ?
동일한 프로그램을 1개 더 가동해 메모리에 매핑하려 하면 문제 생김
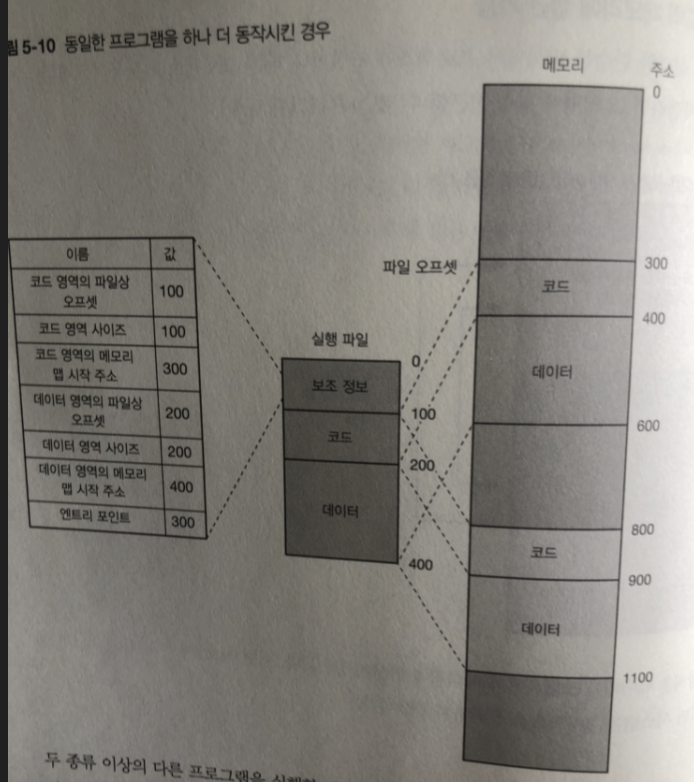
왜냐 하면 코드가 300번지에 데이터가 400번지에 배치 되지않으면 정상적으로 작동 안함
그림은 억지로 주소( 800~1100)를 바꾼 다음 매핑해서 동작시켜도
명령과 데이터에서 지정한 메모리 주소가 원래 가지고 있떤 값과 다르기 때문에 동작하지 않음
또한 다른 프로세스나 커널의 영역을 파괴할 위험도 지님
두 종류 이상의 다른 프로그램 실행 시킬 때도 마찬가지라
이런 단순한 메모리 할당 방식은 각 프로그램이
동작할 주소가 겹치지 않도록 프로그래밍 해야되서 불편함.
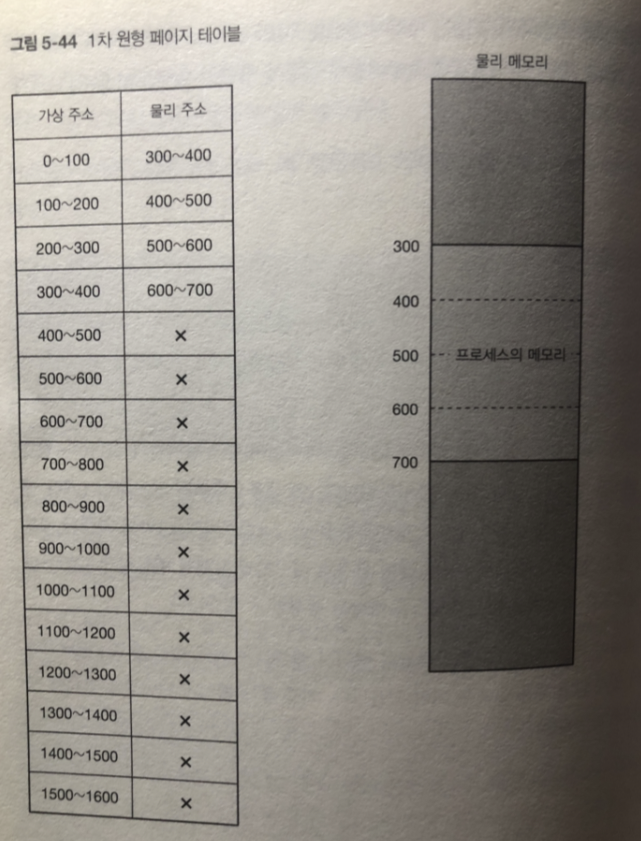
가상 메모리
앞에 문제를 해결하고자 가상 메모리 기능을 이용하고 있따.
시스템에 탑재한 메모리를 프로세스가
직접 접근하지 않고 가상 주소라는 주소를 사용해서 간접적으로 접근 함.
프로세스에 보이는 메모리 주소 - > 가상 주소
메모리의 실제 주소 - > 물리 주소
또한 주소에 따라사 접근 가능한 범위를 -> 가상 주소 공간
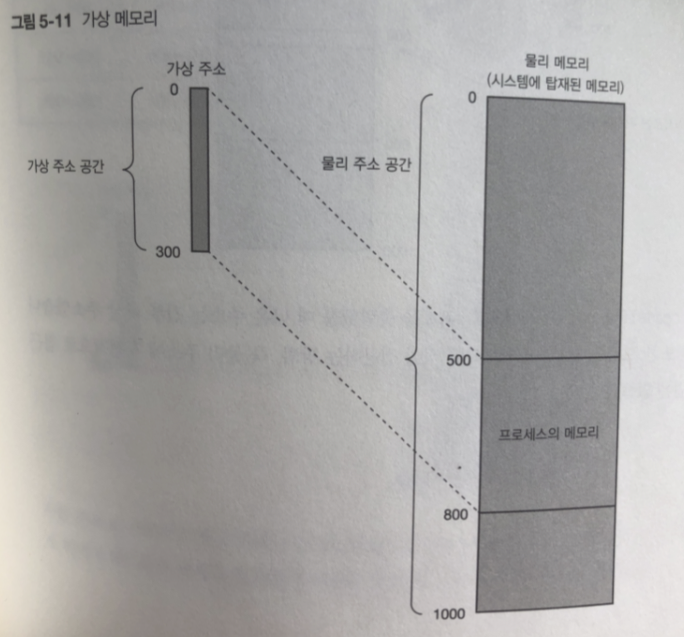
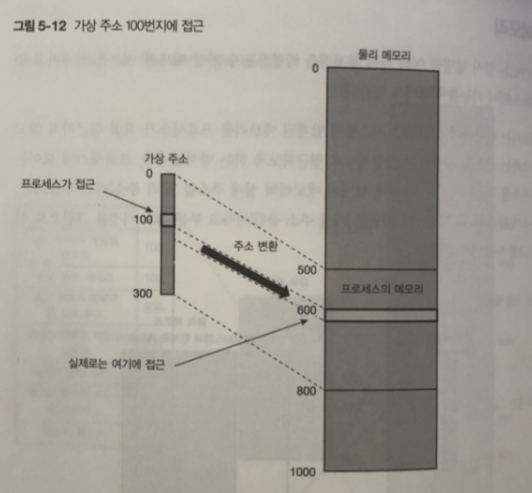
그림 처럼 동작 함.
프로세스로부터 메모리에 직접 접근하는 방식 즉 물리 주소에 직접적을 접근하는 방법은 없다.
페이지 테이블
가상 주소에서 물리주소로 변환하는 과정은 -> 커널 내부에 보관되어있는
페이지 테이블을 사용함
가상메모리는 전체 메모리를 페이지라는 단위로 관리하고 있어서 변환은
페이지 단위로 이루어짐.
페이지 테이블에 한 페이지에 대한 데이터를 "페이지 테이블 앤트리" 라 함
여기에는 가상 주소와 물리 주소에 대한 정보가 들어 있다.
페이지 사이즈 (x86_64 기준 4킬로바이트 이 책에선 100바이트로 잡는다)
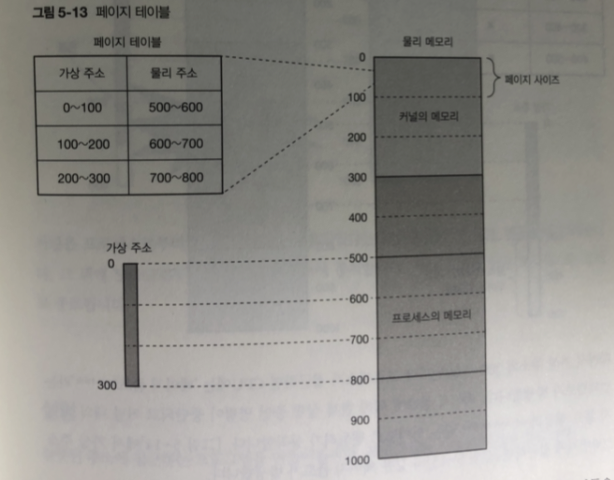
그림 처럼 페이지 테이블을 참조해 가상주소가 실제 메모리로 접근한다
300번지 이후의 가상주소 접근 하면?

CPU에서 페이지 폴트 라는 이터럽트 발생.
현재 실행 중인 명령이 중단되고 -> 페이지 폴트 핸들러 라는 인터럽트 핸들러 동작
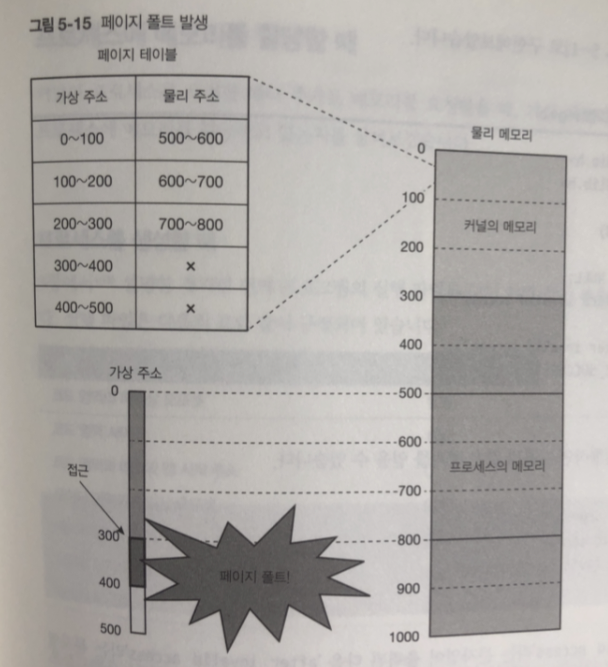
커널은 프로세스로 부터 메모리 접근이 잘못 되었따는 내용을 페이지 폴트 핸들러에 공지함
그 뒤에 SIGSGV 시그널을 프로세스에 통지하고 프로세스 강제종료
실험
잘못된 주소에 접근하는 프로그램 만들어 보자
before invalid accescs 문자열 출력
반드시 접근 실패하는 NULL 주소에 적절한 값( 여기서는 0) 을 넣어 본다
after invalid access 문자열을 출력

잘못된 주소로 접근해 Segmentation fault 문자열 출력되고 종료.
프로세스에서 메모리를 할당할 때
프로세스를 생성하거나 추가 메모리를 요청 받을 때
가상메모리를 통하여 어떻게 프로세스에 메모리를 할당할까
프로세스를 생성 할때

프로그램을 실행하는데 필요한 메모리 사이즈 : 코드영역 사이즈 + 데이터 영역 사이즈
= 300
리눅스에서는 실제 물리 메모리 할당은
-> 디맨드 페이징 방식 이용

추가적인 메모리 할당
프로세스가 새 메모리를 요구 - > 커널은 새로운 메모리 할당 -> 대응하는 페이지 테이블 생성 -> 메모리(물맂 ㅜ소)에 대응하는 가상 주소를 프로세스에 반환
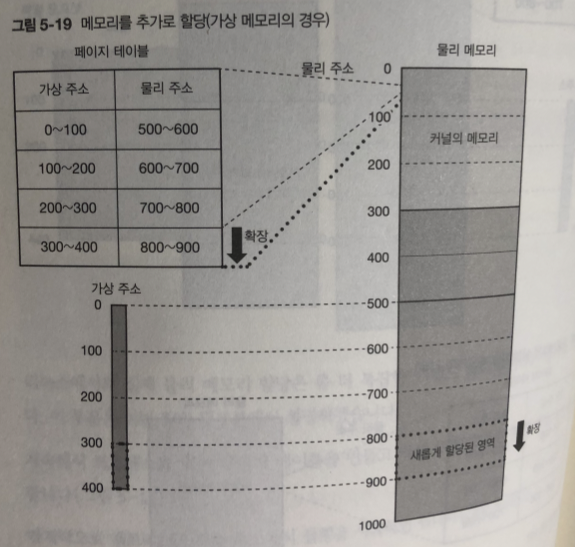
실험
- 프로세스의 메모리 맵 정보(/Proc/pid/maps를 출력) 표시한다
- 메모리를 새로 100메가바이트 확보
- 다시 메모리 맵 정보 표시


mmap() 함수에서는 리눅스 커널에 새로운 메모리 요구하는 시스템 콜 호출
system() 첫번째 파라미터에 지정된 명령어를 리눅스 시스템에 실행

실행 결과
1 : 주소에 대한 메모리맵 성공
2 : 메모리 영역 행 추가 ( 새로 확보 된 메모리)
첫번째 시작주소 두번째 마지막 주소

영역 사이즈 확인 -> 100메가바이트
고수준 레벨에서 메모리 할당
실제로 메모리는 어떻게 할당 할까?
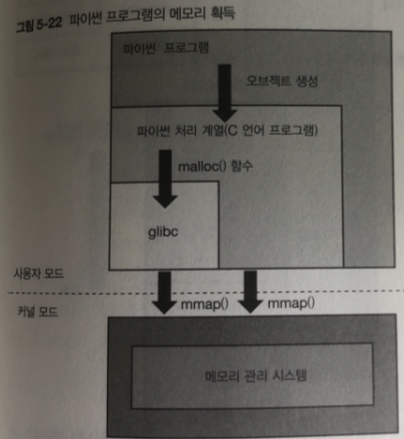
malloc() 함수가 메모리 확보 함수 . 리눅스에서는 내부적으로
malloc() 함수에서 mmap() 함수를 호출하여 구현함.
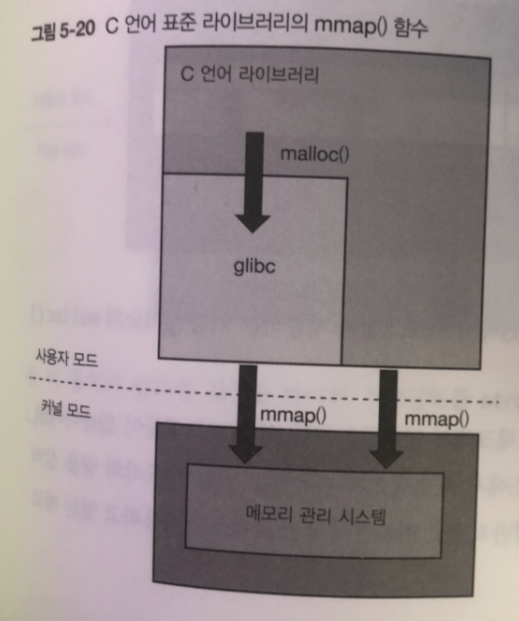
mmap() 함수는 페이지 단위로 메모리를 확보 malloc() 함수는 바이트 단위로 메모리 확보
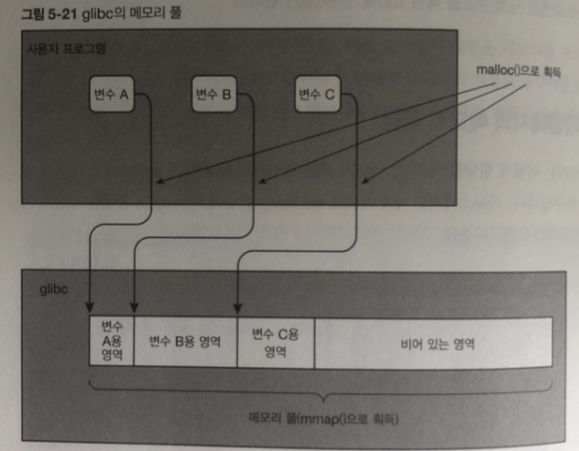
glibc 는 mmap() 시스템 콜 이용해 메모리 영역 확보해 메모리 풀 생성
프로그램에서 malloc()이 호출되면 메모리 풀로부터 필요한 양을 바이트 단위로
잘라내서 반환 처리 함.
풀로 만들어둔 메모리가 더 없을경우?
mmap() 다시 호출 새로운 메모리 확보
이것이 OS가 사용자 모드로 동작할때 OS에서 프로그램에 제공 하는 기능
(glibc의 malloc()함수) 이다
사용하고 있는 메모리의 양을 체크 알려주는 기능 프로그램
프로그램이 알려주는 사용량과 리눅스 프로세스가 사용하는 메모리양이 다른경우가 많음
왜 ?
리눅스에서 측정한 메모리의 양은 프로세스가 생성될때 와 mmap() 함수를 호출 했을 때에
할당한 메모리를 전부 더한 값이며 프로그램이 체크한 메모리 사용양은
malloc() 함수등으로 획득한 바이트 수의 총합 이기 때문에
해결법
메모리 단편화의 문제
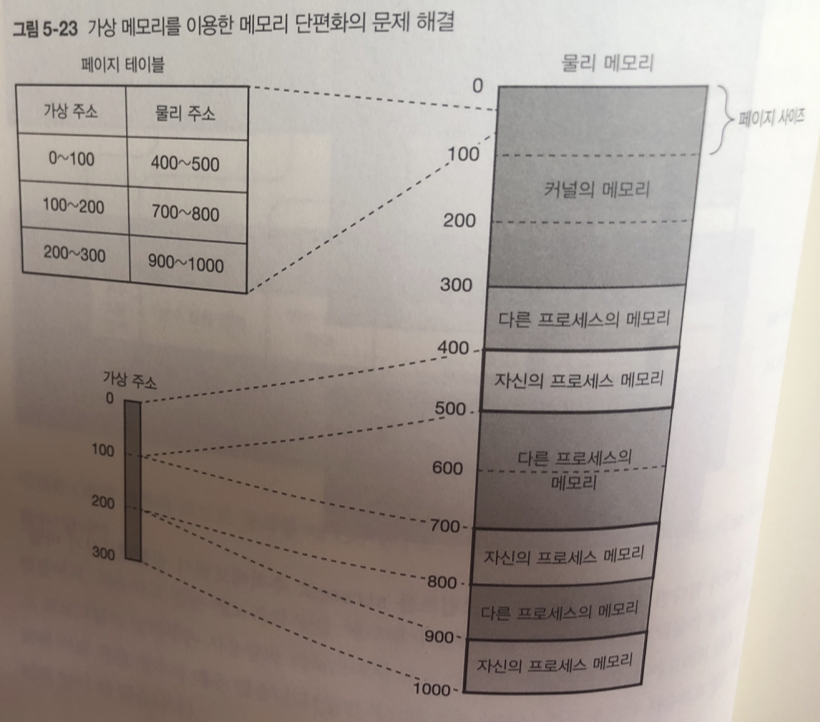
물리메모리 나뉘어져있는거 -> 가상 메모리에선 하나의 큰영역으로 표시
다른 용도의 메모리에 접근 가능 한문제
가상 주소 공간은 프로세스 별로 만들어짐 / 페이지 테이블 역시 마찬가지

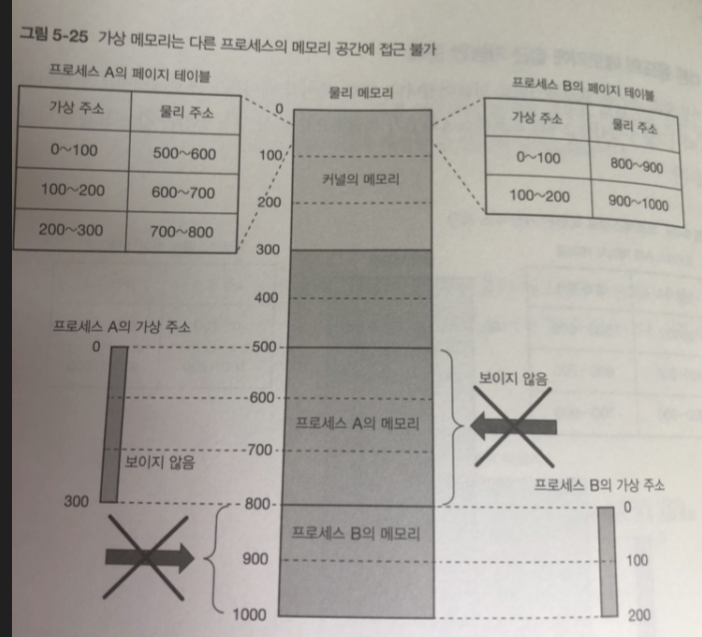
가상 메모리는 다른 프로세스의 메모리 공간에 접근 불가능 하다.
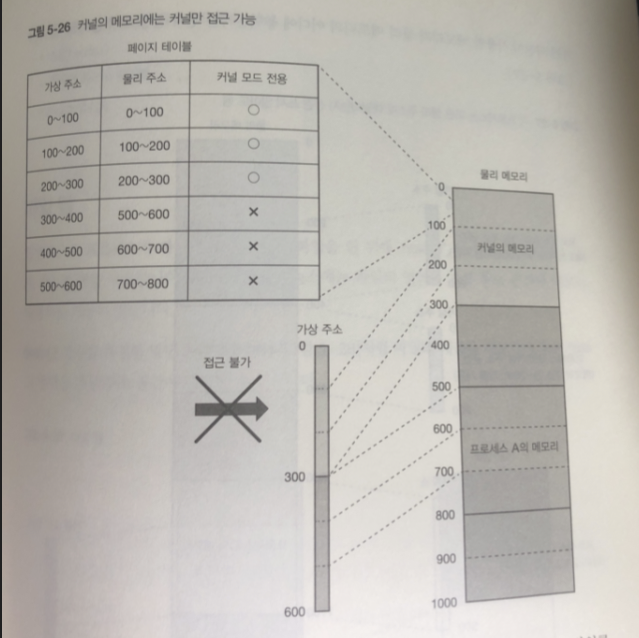
커널 자체가 사용하는 메모리에 대응하는 페이지 테이블 엔트리는 CPU가
커널 모드로 실행할 때만 접근 가능한 커널 모드 전용 이라 정보가 추가됨.
이 부분도 사용자 모드로 동작하는 프로세스는 접근 못함
여러 프로세스를 다루기 곤란한 문제
가상 주소 공간으로 인해 다른 프로그램과 주소가 겹치는 것은 걱정 할 필요 없다.
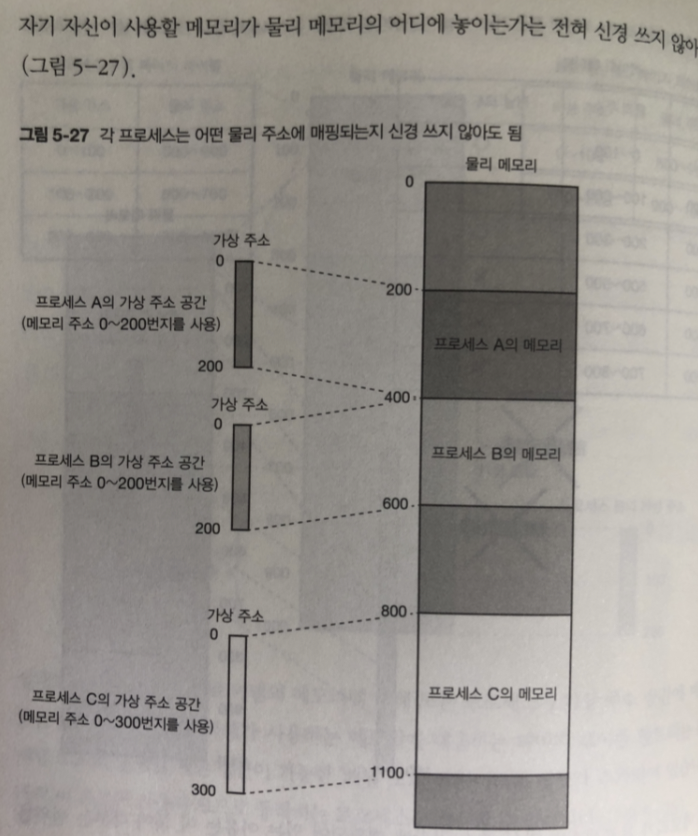
가상 메모리의 응용
- 파일맵
- 디맨드 페이징
- Copy on Write 방식의 고속 프로세스 생성
- 스왑(swap)
- 계층형 페이지 테이블
- Huge page
파일 맵
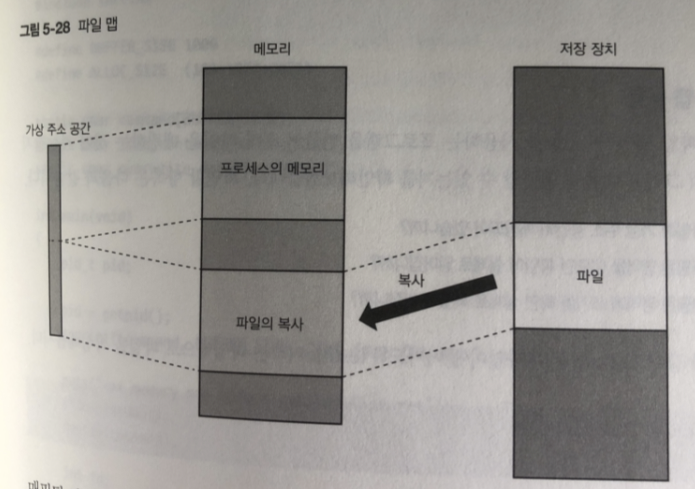
일반적으로 프로세스가 파일에 접근 할때는
read() write() lseek() 등 시스템 콜 사용
mmap() 함수를 특정한 방법으로 호출하면,
파일의 내용을 메모리에 읽어서 가상 주소 공간에 매핑할 수 있다.
매핑된 파일은 메모리에 접근하는 것과 같은 방식으로 접근할 수 있고, 접근하여 수정한 영역은 나중에(6장에서 설명) 실제 파일에 기록된다.
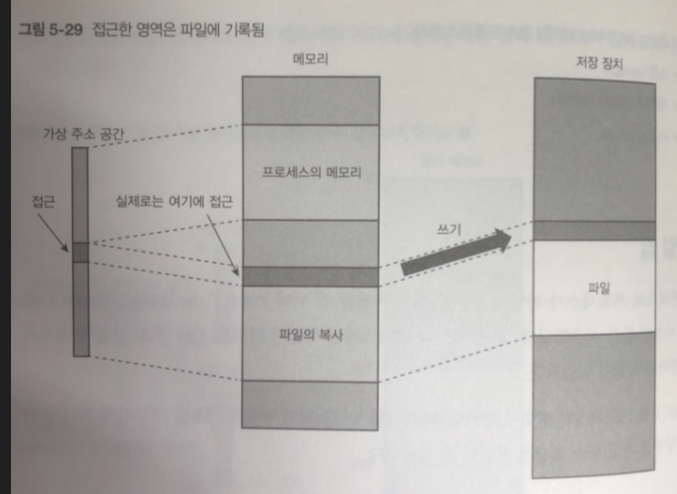
매핑된 파일은 메모리 접근과 같은 방식으로 접근 가능
접근한 영역은 그림과 같이 나중에 적절한 타이밍에 저장 장치 내의 파일이 써짐
파일 맵 실험
파일이 가상 주소 공간에 매핑되는지
매핑된 영역을 읽으면 파일이 실제로 읽어지는지
매핑된 영역에 쓰기를 하면 실제 파일에 써지는지
echo hello > testfile
hello 라는 문자열이 들어가는 testfile 파일명 작성
- 프로세스의 메모리 맵 정보(/proc/PID/maps)를 출력한다.
- testfile을 열어둔다.
- 파일을 mmap()으로 메모리 공간에 매핑한다.
- 프로세스의 메모리 맵 정보를 다시 출력한다.
- 매핑 영역의 데이터를 읽어서 출력한다.
- 매핑 영역에 쓰기를 시도한다.
- 파일 확인


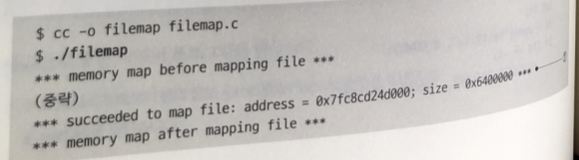
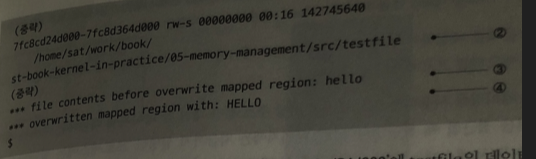
1 . mmap() 함수가 정상 실행되어 testfile의 데이터 주소가 매핑 됨.
2 . mmap() 함수를 수행한 뒤 메모리 맵 정보에는
mmap() 함수를 실행하기 전에는 없었던 testfile이 매핑됨
3. testfile 덮어쓰기전 내용
- 파일 덮어쓰기.
덮어쓰이용 데이터 (overwrite_data) 를 memcpy() 함수로 복사만 해도 변경됨
디맨드 페이징
프로세스가 생성 될 때 mapp() 시스템 콜로 프로세스에 메모리 할당 했을 때
- 커널이 필요한 영역을 메모리 확보합니다
- 커널이 페이지 테이블을 설정하여 가상 주소 공간을 물리 주소 공간에 매핑합니다.
그러나 이 방법은 메모리를 낭비한다. (커널이 메모리를 미리 확보해놓는 방식)
이유: 확보한 메모리중 다음처럼 메모리 확보할 때부터 프로세스가 종료될때까지
사용하지 않는 영역이 있어서
커다란 프로그램 중 실행에 사용하지 않는 기능을 위한 코드 영역과 데이터영역
glibc가 확보한 메모리 앱중 유저가 malloc() 함수로 확보하지 않는 부분
이러한 문제로 인해 리눅스는 디맨드 페이징 (또는 요구 페이징) 방식을 사용해
메모리를 프로세스에 할당함
디맨드 페이징을 사용하면 프로세스의 가상 주소 공간 내의 각 페이제 대응하는 주소는
페이지에 처음 접근할 때 할당됨
각 페이지에는 지금까지 설명한
1. 프로세스에는 할당되지 않음
2. 프로세스 할당 O 물리 메모리에 할당 O
새로운 상태를 추가해서
-> 프로세스 에는 할당 O 물리메모리에 할당 X
(가상 주소 공간은 존재하지만 물리 주소 공간에 매핑되지 않은 상태를 의미한다.)
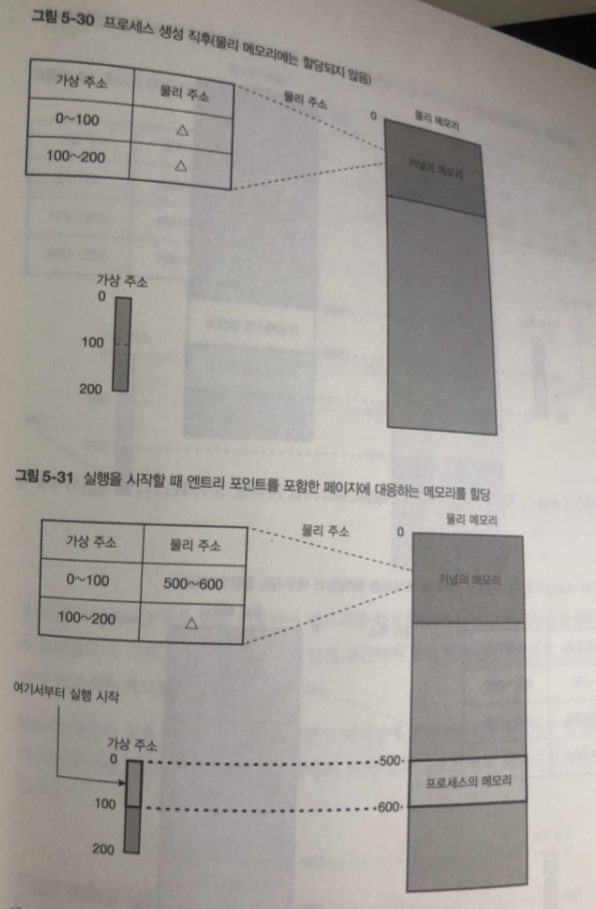
디맨드 페이징 처리 흐름
- 프로세스 생성
- 프로세스 가상 주소 공간 안에 코드 영역이나 데이터 영역에 대응하는 페이지에 프로
세스 영역 얻었음 정보 기록
(이시점에서 물리 메모리에 할당되지 않음) 5-30 세모는 아직 물리 메모리 할당 안됨- 프로그램이 엔트리 포인트로 부터 실행을 시작 할때에는 5-31 과 같이
물리 메모리가 할당 됨.
처리 흐름 다시
- 프로그램이 엔트리 포인트에 접근한다.
- CPU가 페이지 테이블을 참조해서 엔트리 포인트가 속한 페이지에 대응하는 가상 주소가
물리 주소에 아직 매핑되지 않음을 검출한다. - CPU에 페이지 폴트가 발생한다.
- 커널의 페이지 폴트 핸들러가 1에 의해 접근된 페이지에 물리 메모리를 할당하여
페이지 폴트를 지웁니다. - 사용자 모드로 돌아와서 프로세스가 실행을 계쏙한다.
- 프로세스는 자신이 실행하는 동안 페이지 폴트가 발생한 사실 자체를 모르고 넘어감
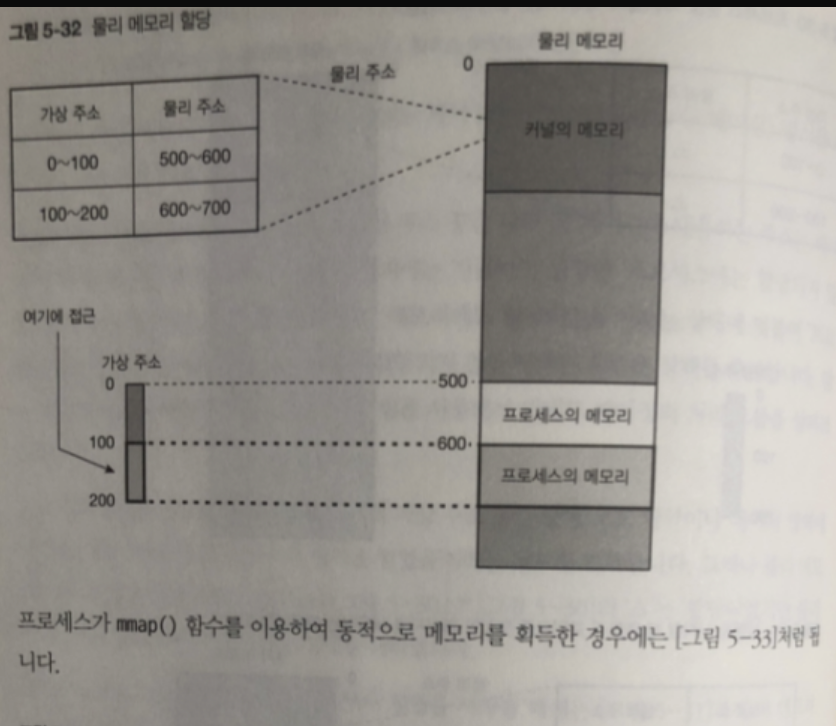
페이지용 물리 메모리가 할당된 다음 마찬가지로 아직 할당되지 않는 다른 영역에 접근
하게 되면 위와 같은 처리가 다시 실행되 내부에 페이지 폴트가 발생하고 실제의 메모리가
할당된 뒤 페이지 폴트를 5-32 와 같이 지움
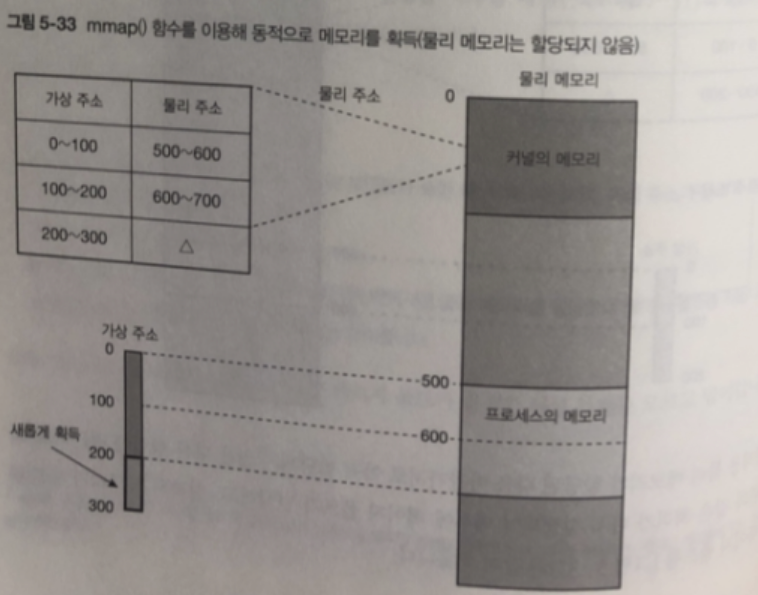

프로세스에서 mmap() 함수를 통해 동적으로 메모리를 획득한 경우
"가상 메모리를 확보한 상태" 라고 볼 수 있다.
이 가상 메모리에 접근할 때 물리 메모리를 확보하고 매핑하는 것을
"물리 메모리를 확보한 상태" 라고 표현한다.
이 때 가상 메모리와는 상관없이 물리 메모리 부족이 발생할 수 있다.
디맨드 페이징 실험
확인할 항목
- 메모리 획득 시 가상 메모리 사용량만 증가한다. (물리 메모리 사용량은 그대로)
- 획득한 메모리에 접근하면 페이지 폴트가 발생하고, 물리 메모리의 사용량이 증가한다.
테스트 프로그램
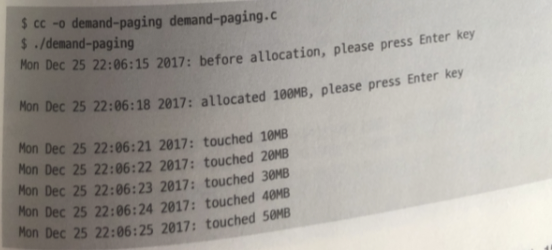
이 프로그램이 실행되는 동안 sar -r 명령어를 통해 메모리 사용량을 분석한다. 이를 위해 출력 메시지에 현재 시간을 표시한다.
-
메모리 획득 전에 메시지를 출력한다. 그 후 사용자의 입력을 기다린다.
-
100MiB 메모리 획득
-
다시 한번 메시지를 출력하고 사용자의 입력을 기다린다.
-
획득한 메모리를 처음부터 끝까지 1페이지씩 접근하고, 10MiB씩 접근할 때마다 메시지 출력
-
사용자의 입력을 기다린다.


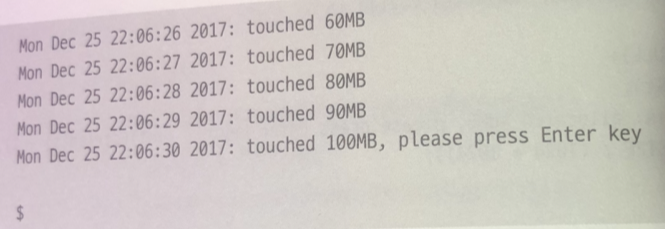
무사히 종료... 그런대 정보가 부족하다..
시스템의 정보를 얻는 각종 프로그램을 다른 터미널에서 실행할 필요가 있따.
-
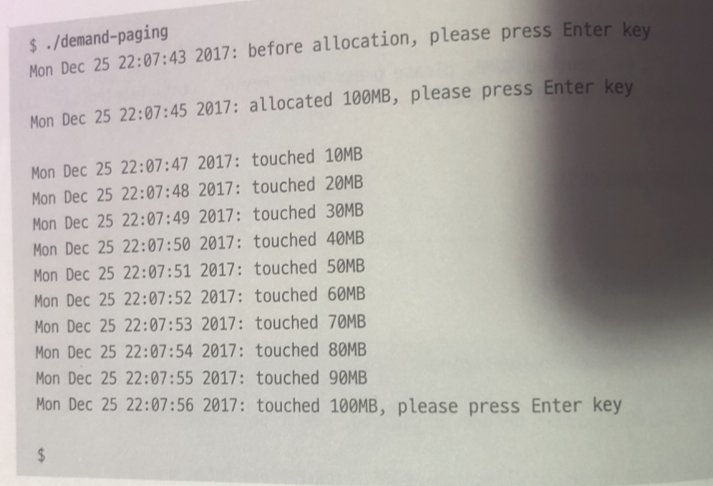
sar -r 이용하여 1초마다 시스템이 사용하는 메모리 측정
-
다른 터미널에선 demand-paging 프로그램 실행
반면에


각 출력된 시간을 비교해보면
- 메모리 영역을 획득해서 그 영역에 실제로 접근할 때까지 시스템 물리 메모리 사용량
(kbmemused) 필드의 값은 거의 변화 없다.- 메모리에 접근이 시작되면서 초당 10메가바이트 정도 사용량이 증가
- 메모리 접근이 종료된 뒤에는 메모리 사용량이 변화하지 않음
- 프로세스가 종료되면 메모리 사용량은 프로세스 시작전으로 돌아감
sar -B 명령어로 페이지 폴트가 발생되는 순간을 보자
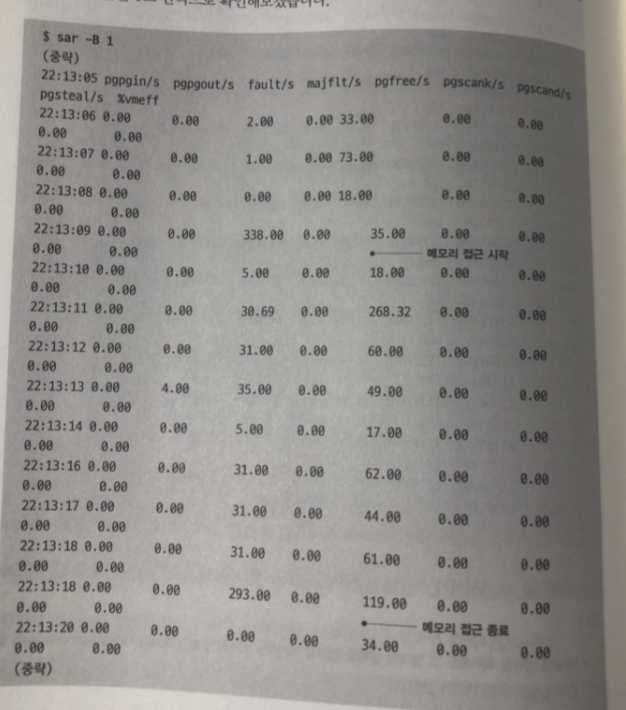
fault/s 필드값이 증가 하고 있음 (폴트 수 나타냄)
두번 째 이후 페이지 폴트가 발생하지 않음
첫번 째 접근 이후 물리 메모리가 이미 할당 되었기 때문에
프로세스 별 메모리 통계 확인
가상 메모리의 양, 확보된 물리 메모리의 양
프로세스 생성 시부터 페이지 폴트의 횟수 확인
ps -eo 명령어의 vsz, rss, maj_flt, min_flt 필드로 확인할 수 있다.
페이지 폴트의 횟수는 maj_flt(Major Fault) + min_flt(Minor Fault)이다.
확인을 위한 셸 스크립트 실행 (터미널 2개)

실행 결과는 각 줄의 demand-paging 필드의 오른쪽 에 있는
4개 의 필드가 각각
가상 메모리의 양, 확보된 물리 메모리의 양 , Major Fault 횟수 , Minor Falut 횟수
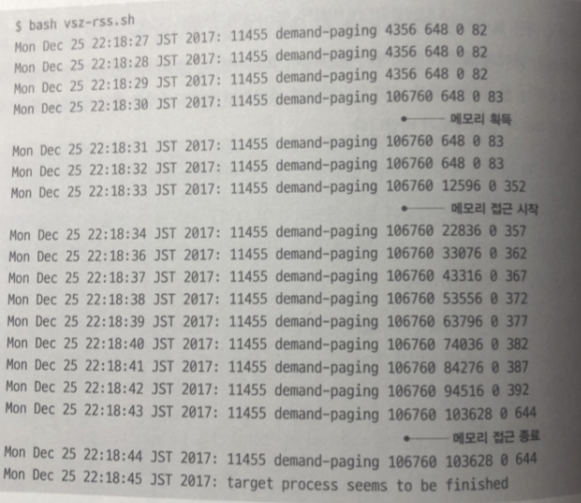
- 메모리 영역을 획득하고 나서 접근할 때 까지 가상 메모리의 사용량이 100메가 바이트
증가 물리 메모리는 증가하지 않는다.- 메모리 접근을 하면 물리 메모리 사용량이 매초 10메가 바이트 정도 증가하지만 가상 메모리는 변화가 없다.
- 메모리 접근이 종료 된 뒤 물리 메모리 사용량은 획득하기전가 비교해보면 100 메가 바이트 가 증가 되있다.
가상 메모리 부족과 물리 메모리 부족
프로세스 실행 중 메모리 획득에 실패하면 종종 이상 종료 함.
원인은 가상메모리 부족 / 물리 메모리 부족 이기 때문에
가상 메모리 부족: 프로세스가 가상 주소 고간의 범위가 꽉 차도록 전부사용
-> 가상 메모리 요청을 더 했을때 발생
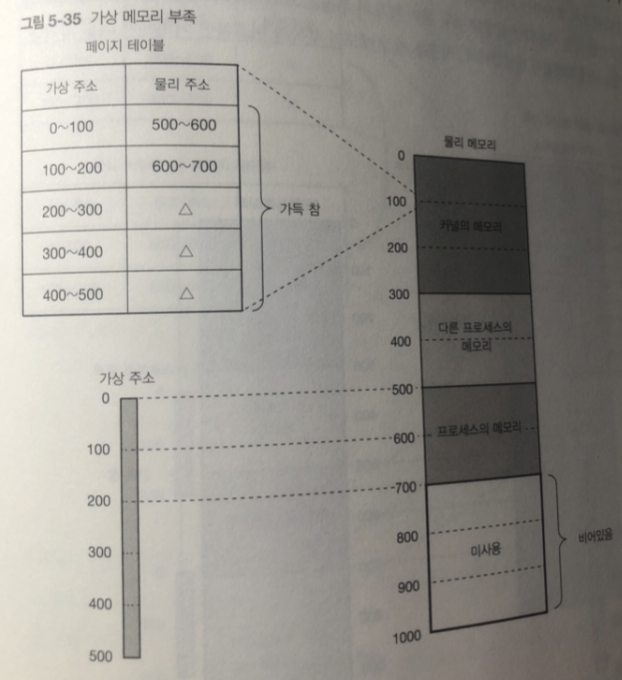
물리 메모리는 비어있지만 페이지 테이블 은 꽉차 있음
- 가상 메모리 부족은 x86 아키텍처에서는 공간이 4기가바이트 밖에 없기 때문에
데이터베이스 같은 큰 규모의 프로그램을 사용할 때 종종 발생
-> x86_64 아키텍처에는 가상 주소 공간이 128 테라바이트나 있기 때문에 거의 발생 안함
허나.. 미래에는 부족할지도
물리 메모리 부족 : 가상 메모리가 얼마나 남아 있느냐 관계 없이 발생
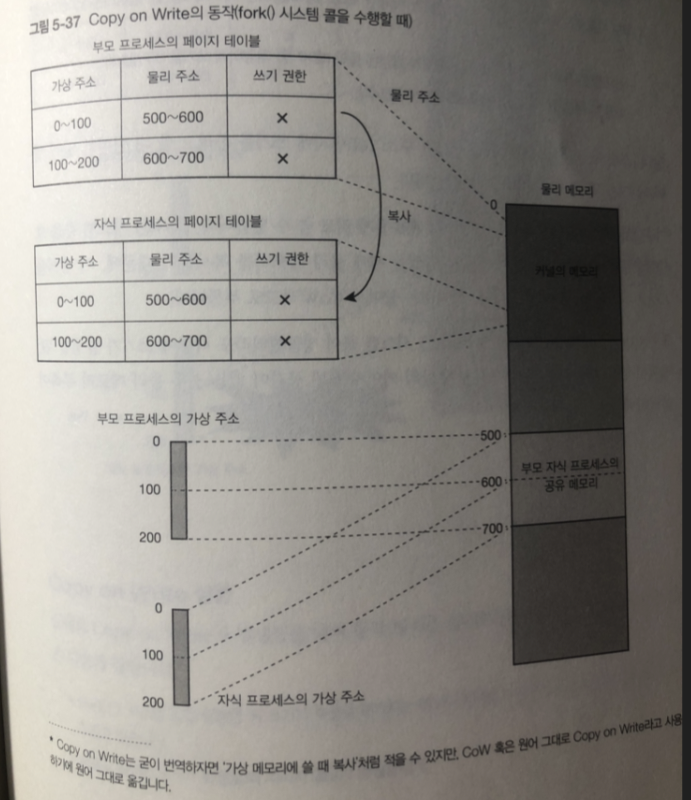
Copy on Write
fork() 시스템 콜도 가상메모리 방식을 사용해 고속 화됨.
fork() 시스템 콜을 수행할 때는 부모 프로세스의 메모리를 자식 프로세스 에
전부 복사하지 않고 페이지 테이블만 복사함.
페이지 테이블 엔트리 안에는 쓰기 권한 을 나타내는 필드가 있지만
부모 자식도 전체 페이지 쓰기 권한 무효화 함.
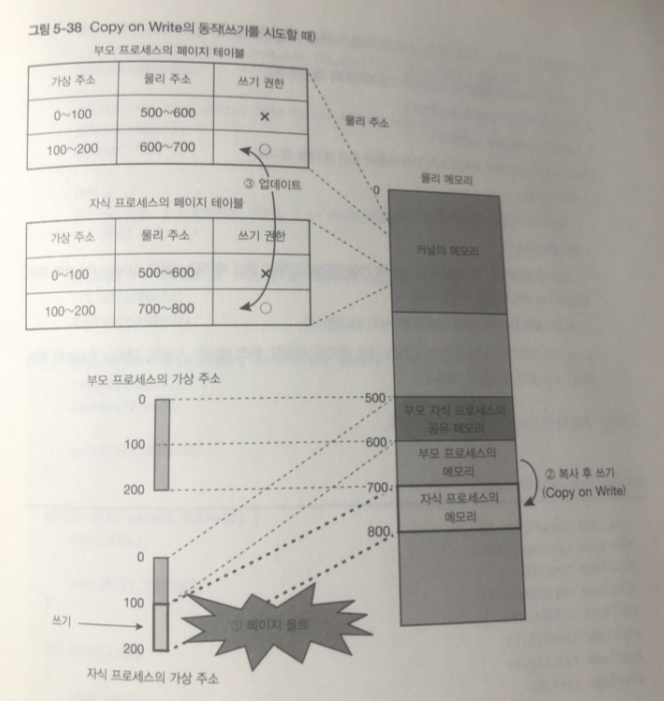
부모 혹은 자식 프로세스의 어느 쪽이든 페이지의 어딘가를 변경하려 하면
-
페이지에 쓰기는 허용하지 않기 때문에 쓰려고 하면 CPU에 페이지 폴트 발생
-
CPU가 커널 모드로 변경되어 커널의 페이지 폴트 핸들러가 동작
-
페이지 폴트 핸들러는 접근한 페이지를 다른 장소에 복사하고 쓰려고 한 프로세스에
할당한 후 내용을 다시 작성 -
부모 프로세스 , 자식프로세스 각각 공유가 해제된 페이지에 대응하는
페이지 테이블 엔트리를 업데이트 함- 쓰기를 한 프로세스 쪽에 엔트리는 새롭게 할당된 물리 페이지를 매핑하여 쓰기를 허가
- 다른 쪽 프로세스의 엔트리에도 쓰기를 허가
Copy on Write 실험
- Fork() 시스템 콜을 실행한 뒤 쓰기가 수행될 때 가지는 메모리 영역을
부모 프로세스와 자식 프로세스가 공유하고 있다.- 메모리 영역에 쓰기가 발생할 때 페이지 폴트가 발생.
테스트 프로그램
-
100MiB 메모리를 확보하여 모든 페이지에 접근한다.
-
시스템 메모리 사용량 출력
-
fork() 시스템 콜 호출
-
자식 프로세스에서 시스템 메모리 사용량 및 자식 프로세스의 메모리 사용량을 출력한다.
-
1에서 확보한 메모리 영역에 자식 프로세스가 전부 쓰기 작업을 수행한다.
-
자식 프로세스에서 시스템 메모리 사용량 및 자식 프로세스의 메모리 사용량을 출력한다.
부모프로세스
1. 자식 프로세스의 종료를 기다린다
자식 프로세스
1. 시스템 메모리의 사용량과 자기 자신의 가상메모리 사용량 물리 메모리 사용량 ,
Major Fault 횟수 Minor Fault 횟수 표시
2. 1에서 획득 한 영역 전부 의 페이지에 쓰기 접근
- 1번 내용 다시

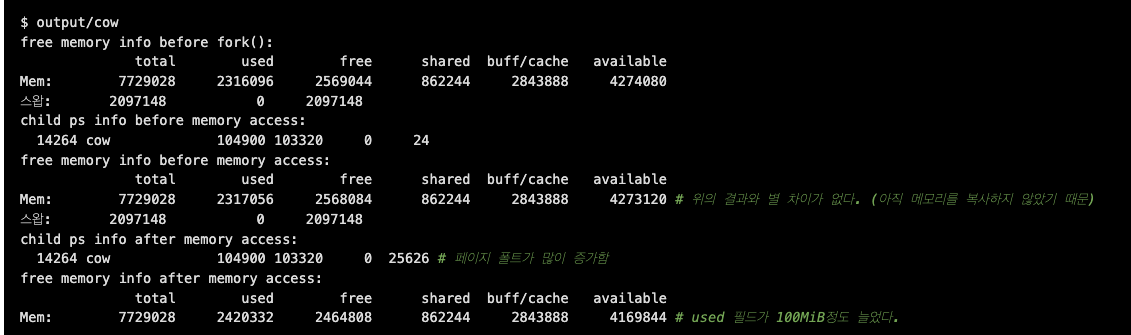
결과
부모 프로세스의 메모리 사용량은 100메가 바이트를 넘지만 fork() 시스템 콜을 실행
한 뒤 자식 프로세스 메모리에 쓰기 접근 하기 전에는 메모리 사용량은 수백 킬로바이트만 증가
자식 프로세스가 메모리에 쓰기 접근 한 뒤 페이지 폴트 수가 증가하고 메모리 사용량은
100메가 바이트 증가 (= 페이지 공유가 해제됨)
ps 명령어로 부모 프로세스와 자식 프로세스의 메모리를 확인할 때,
공유된 부분은 두 프로세스에서 모두 표시된다는 것에 주의해야 한다.
메모리의 합을 계산할 때 그냥 더해버리면 공유된 부분이 중복으로 더해지는 것이다.
스왑
물리 메모리가 부족하면 메모리 부족 상태가 됨.
리눅스에는 메모리 부족에 대응하는 구제 장치가 있는데
가상 메모리 방식을 응용한 스왑(swap) 이다.
스왑은 저장 장치의 일부를 일시적으로 메모리 대신 사용
물리 메모리가 부족한 상태 에서 물리 메모리를 획득 할 때
-> 기존에 사용하던 물리 메모리의 일부분을 저장장치에 저장해 빈 공간 생성
이때 메모리의 내용이 저장된 영역을 스왑 영역이라 함. ( 윈도우에 서 스왑영역은 가상메모리)
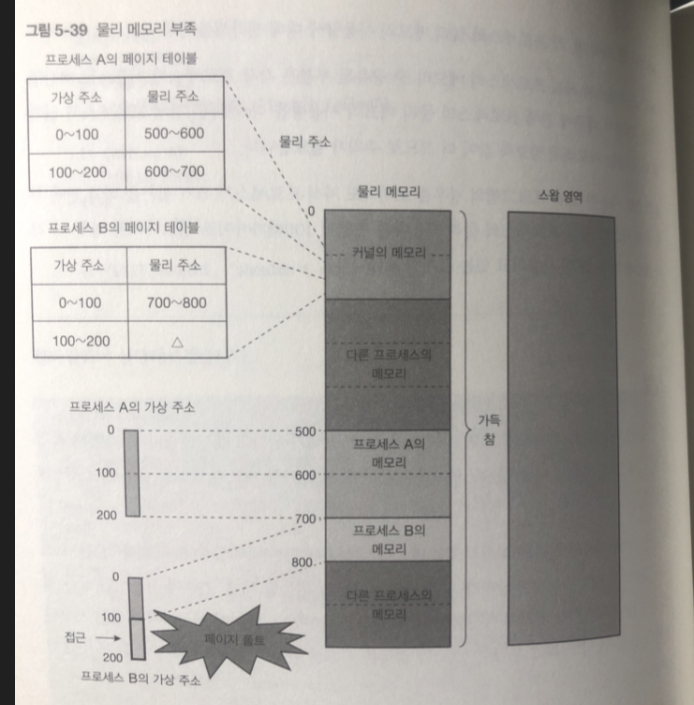
그림은 메모리가 부족한 상황에 물리 메모리가 추가로 필요하다할 때 이다.
프로세스 B의 가상주소 100 번지에는 처음으로 접근하면 페이지 폴트가 일어남
이때 물리 메모리에 빈 공간이 없으므로 커널은 사용 중인 물리 메모리의 일부를 스왑 영역에 임시 보관함
이를 스왑 아웃 이라 함.
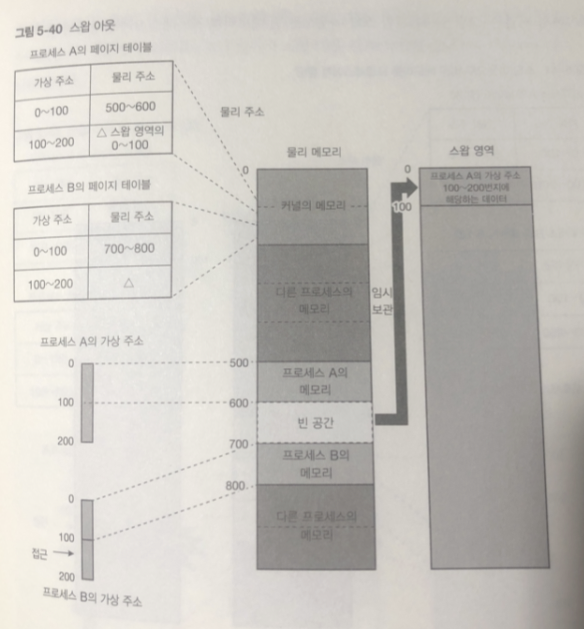
어느 영역이 스왑 아웃 될 것인가는
앞으로 사용되지 않을 듯한 것을
커널이 특정한 알고리즘을 통해 결정 함.
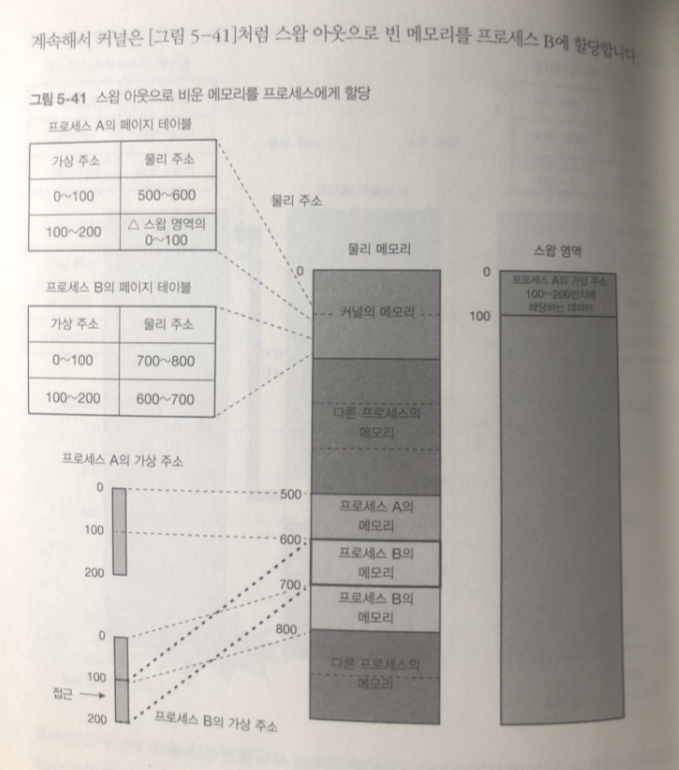
스왑 아웃으로 빈 메모리를 프로세스 B가 할당
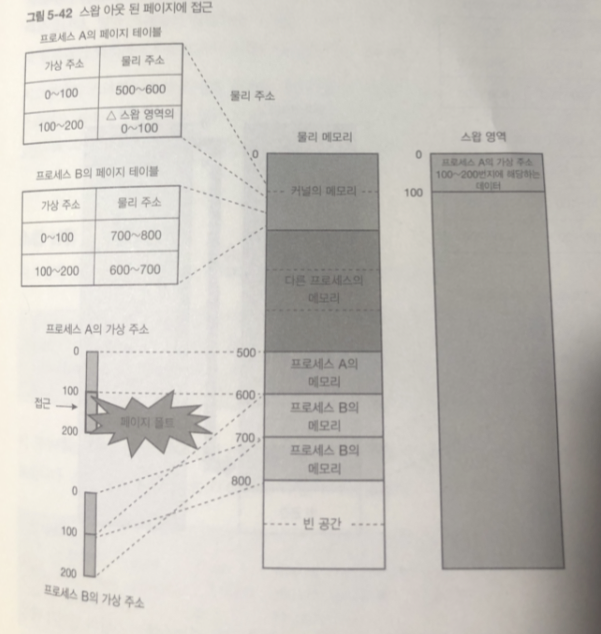
페이지 폴트 발생! 이경우 스왑 영역에 임시 보관했던 데이터를 물리데이터로 되돌림
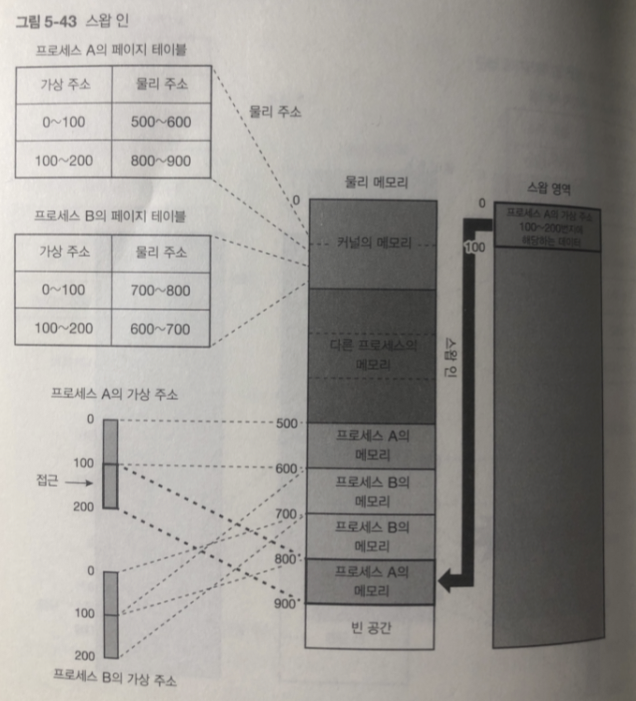
swap in 스왑 인이라고 함
스와핑 : 스왑 인 + 스왑 아웃을
-> 리눅스에선 스왑의 단위가 페이지 단위이므로 페이징이라 부르기도 함.
(페이지 인 / 페이지 아웃)
단점 : 저장 장치에 접근하는 속도가 메모리에 접근하는 속도에 비해 너무 느림.
시스템의 메모리 부족이 만성적으로 부족하면
메모리 접근 할때마다 스와핑이 반복되는 스래싱 상태가 됨.
스왑 실험

아직 명령어 실행 전이라 used 값 0 스왑 사용 하지 않고 있다.

pswpin/s 필드가 스왑 인 된 페이지 수 (1초 당)
pswpout/s 필드가 스왑 아웃 된 페이지의 수 (1초당)
시스템이 나빠질 경우 양쪽 수치가 0이 아님. (스와핑 의심)
sar - S 명령어를 사용해 스왑이 발생하고 잇을때 그게 언젠가 사라질지
스래싱 될지 알 수 있다.

kbswpused : 스왑 영역의 사용량
점점 증가 하면 위험 함.
Major Fault : 스와핑과 같이 저장 장치에 대한 접근이 발생하는 페이지 폴트
Minor Fault : 저장 장치에 대한 접근이 발생하지 않는 페이지 폴트
Major Fault 가 성능 영향력이 더큼.
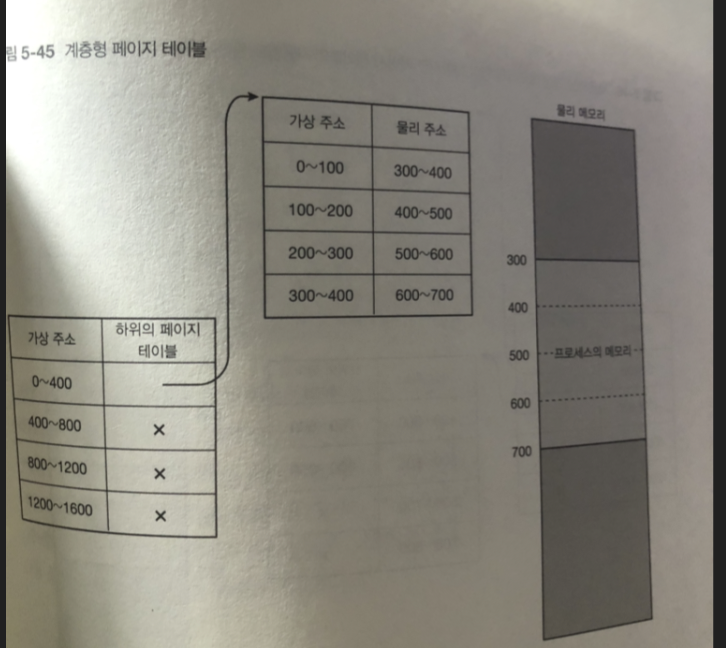
계층형 페이지 테이블
앞서 프로세스의 페이지 테이블에는 가상 주소 공간 페이지의 전부에 걸쳐서
대응 되는 물리 메모리가 존재하는가 나타내는 데이터를 가지고 있음
-> 1차원 구조로 가볍게 구현한다 생각해보자
1차원적으로 페이지 테이블을 구성할 경우
x86_64 아키텍처에서 보통 가상 주소 공간의 크기는 128TiB이다.
1페이지는 4KiB, PTE는 8Byte이다.
프로세스 1개당 페이지 테이블의 크기는 이론상 8Byte * 128TiB / 4KiB = 256GiB이다.
위와 같이 1차원적으로 페이지 테이블을 구성하면 크기가 엄청나게 커지므로, x86_64의 페이지 테이블은 계층형 구조로 되어있어 메모리를 절약한다.
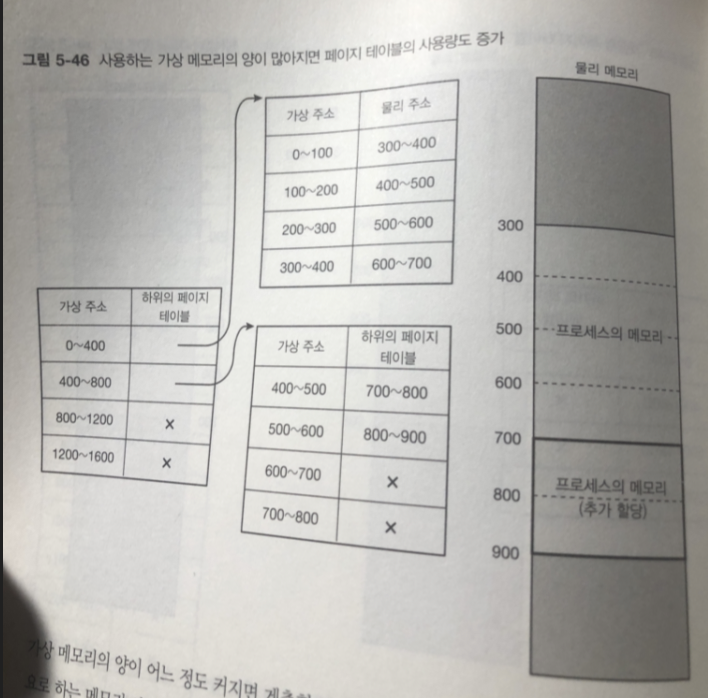
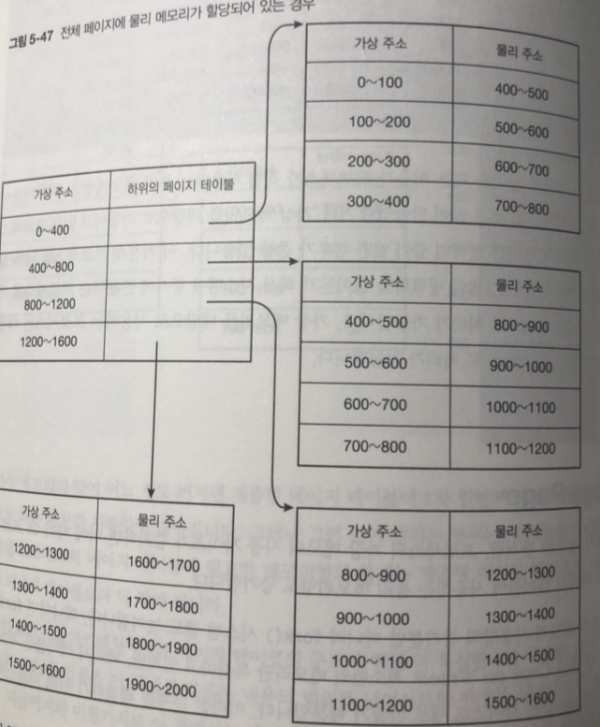
예를 들어 1차원적으로 0부터 15까지(페이지 단위라고 생각하자)의 가상 주소에 대한 PTE 중 앞의 4개만 사용하는 페이지 테이블이라면, 4개씩 묶어서 하위 페이지 테이블의 주소를 가리키도록 한다. 03, 47, 811, 1215 이렇게 묶으면 4개의 PTE가 필요하고, 하위 페이지 테이블로 0부터 3까지 4개의 PTE, 즉 전체 16개의 PTE를 8개로 줄일 수 있다.
물론 사용하는 가상 메모리의 양이 많아지면 필요한 페이지 테이블도 많아지고, 어느 순간부터는 1차원적인 페이지 테이블보다 용량이 더 커질 수도 있다. 하지만 일반적인 상황에서 그런 상황은 발생하지 않는다.
실제 x86_64 아키텍처에서는 페이지 테이블의 구조가 4단 구조이다.
ex ) 물리 메모리 400바이트만 사용하는 경우
1차원
계층형
페이지 엔트리가 16 -> 8개 로
페이지 테이블 엔트리
페이지 테이블 엔트리(Page Table Entry, 줄여서 PTE)는 페이지 테이블의 레코드이다.
Huge Page
프로세스의 가상 메모리 사용 사이즉 증가 하면
프로세스의 페이지 테이블에 사용하는 물리 메모리 양도 증가함
이 경우 메모리 사용량 증가 뿐 아니라 fork() 시스템 콜 늦어짐.
-> Copy on Write로 최소한의 메모리만 복사하고 있지만
페이지 테이블은 부모의 프로세스와 같은 사이즈로 새로 만들어 지기 때문
이런 문제를 해결하기 위해 Huge Page 기능.
-> 프로세스의 페이지 테이블에 필요한 메모리양 줄임
가상 주소 뭉탱이를 물리 주소 뭉탱이에 매핑한다고 생각하면 된다.
페이지의 크기를 4KiB에서 2MiB로 크게 잡는 등의 방식을 사용한다.
이를 통해 페이지 테이블에 필요한 메모리의 양이 줄어들며,
MMU의 캐시 역할을 하는 TLBtranslation lookaside buffer의 hit을 증가시켜 성능을 향상시킨다.
사이즈가 400바이트의 Huge Page로 변경

페이지 엔트리 갯수가 20 -> 4개로 줄어 듬
사용 방법
mmap() 함수의 flags 파라미터에 MAP_HUGETLB 플래그 등을 넣어서 Huge Page를 획득할 수 있다.
Huge Page 참고 :
https://linux.systemv.pe.kr/tag/hugepage-%EB%9E%80/
Transparent Huge Page
가상 주소 공간에 연속된 여러 개의 4킬로바이트 페이지가 특정 조건을 만족하면
자동으로 Huge Page로 바꿔주는 기능
문제점 :
Huge Page로 묶거나, 다시 4KiB 페이지로 분리할 때 국소적으로 성능이 하락하는 경우가 존재한다.
이 기능을 무효화해서 사용하지 않는 경우도 있다.

출저 : https://caniro.tistory.com/286
6장 메모리 계층
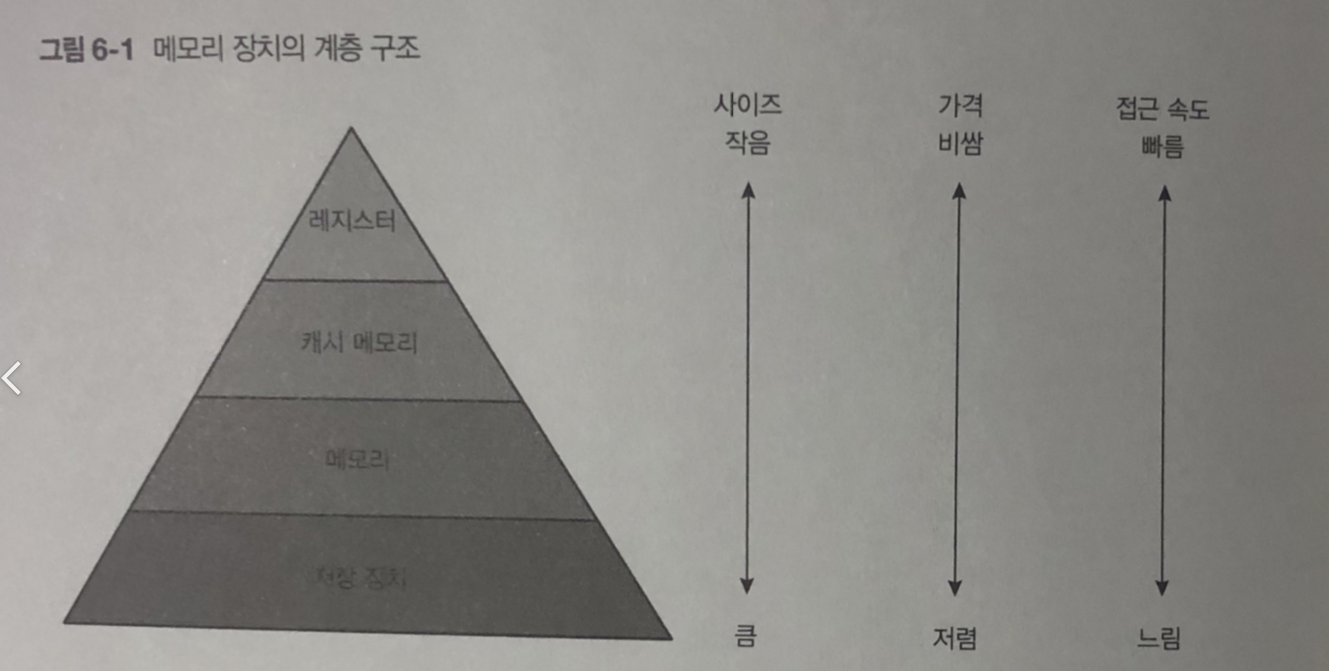
컴퓨터 메모리 장치의 계층 구조.
레스스터 / 캐시 메모리 / 메모리 / 저장 장치
- 구체적으로 크기와 성능에 얼마나 차이가 있을 까
- 이런 차이를 고려하여 하드웨어나 리눅스는 어떤 구조로 되어 있을 까?
캐시 메모리
컴퓨터의 기본 동작 흐름
처리 1 . 명령어를 바탕을 메모리에서 레지스터로 데이터를 읽기
처리 2 . 레지스터에 있는 데이터를 바탕으로 계산
처리 3 . 계산 결과를 메모리에 쓴다.
레지스터에서 계산 평균 시간 > 메모리에 접근하는데 걸리는 시간
극도로 느림.
처리2가 아무리 빨라도 처리 1 과 3 속도상 벽몽 지점이 되버림
느리다... 레이턴시 증가..
레지스터 안에서 계산 하는 것 / 메모리에 접근 하는 것
캐시메모리는 양쪽의 처리 시간의 차이를 메우는 데 필요
캐시 메모리는 레지스터에 접근 할 때 메모리와 비교 해보면 아주 빠름.
처리 1 과 처리 3을 고속화 시킬수 있다.
캐시 메모리 동작
지금 부터 캐시 메모리는 하드웨어 안에서 전부 처리 (커널 안통함)
처리 1 에서 일단 캐시 메모리에 읽어온 뒤 같은 내용을
(메모리에서 먼저 캐시 메모리로
캐시 라인 사이즈cache line size만큼(CPU에서 정함) 읽어오고)
이때 읽어온 크기는 CPU에서 지정한 캐시 라인 사이즈 만큼
다시 레지스터로 읽음.
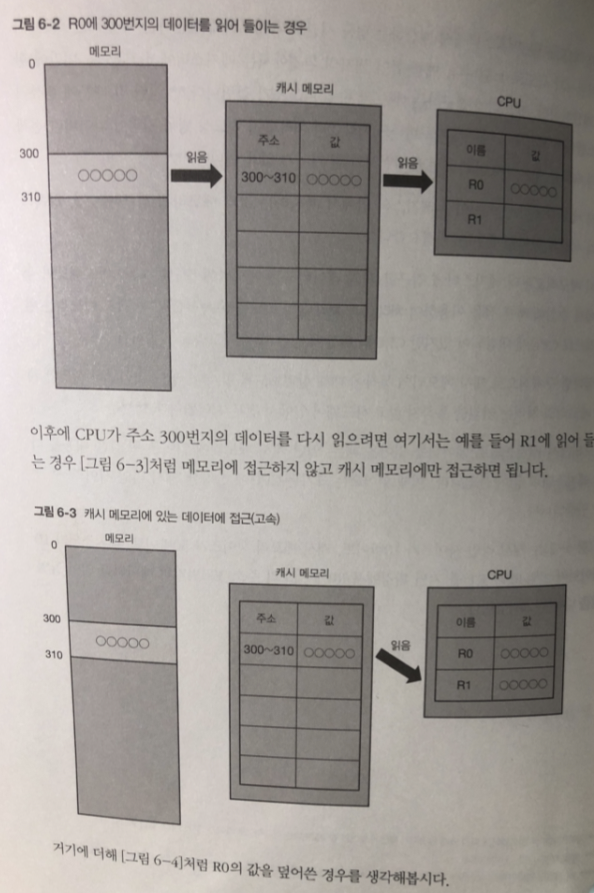
캐시 라인 사이즈 : 10 바이트
캐시 메모리 사이즈 : 50바이트
레지스터 : 10바이트 (2개)
R0 에서 먼저 읽어서 캐시메모리에 정보가 있기 때문에
R1 이 다시 읽게 되면 캐시 메모리 부터 읽으면 됨으로 고속화 처리가 됨.
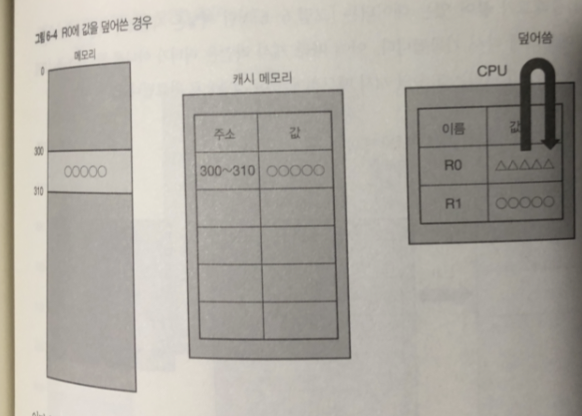
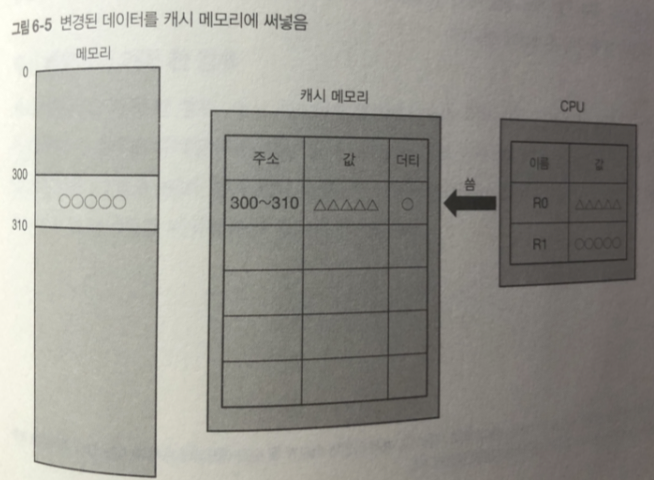
300번지 변경된 데이터를 캐시 메모리에 옮긴다 .
옮긴 데이터 쓰는 단위로 캐시 라인 사이즈.
그리고 캐시 메모리는 데이터가 변경 되었음을 나타내는 플래그 를 표시
플래그가 표시된 캐시 라인을 더티(dirty) 라고 부름.
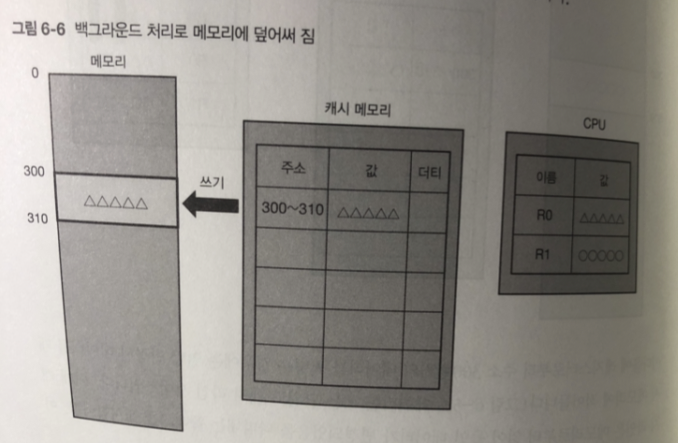
더티 플래그가 있으면
나중에 백그라운드 처리로 메모리에 기록하고 더티 플래그를 제거한다.
(이에 캐시 라인은 더티가 아님)
-> 캐시라인이 더티가 되는 순간 메모리에 즉시 써넣는 방식
쓰기 처리는 고속의 캐시메모리에 쓰는 것만으로 완료
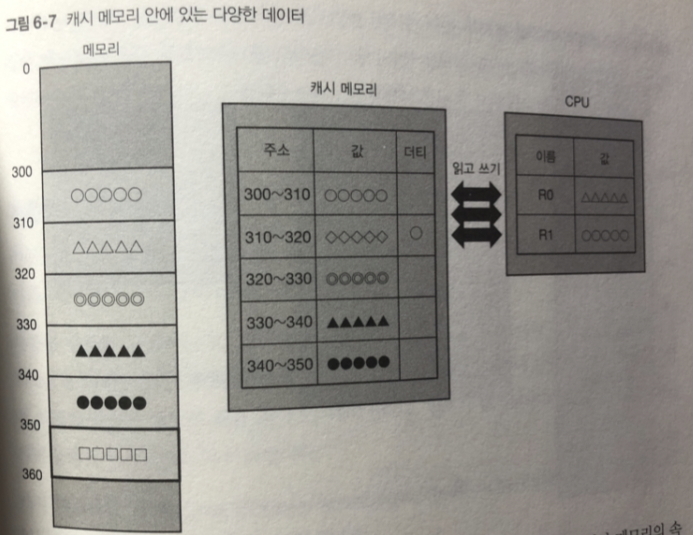
CPU가 캐시메모리에 접근할 때에는 모든 접근이 고속 처리 됨.
캐시 메모리가 가득 찬 경우
기존 캐시 메모리 중 1 개를 파기 함.
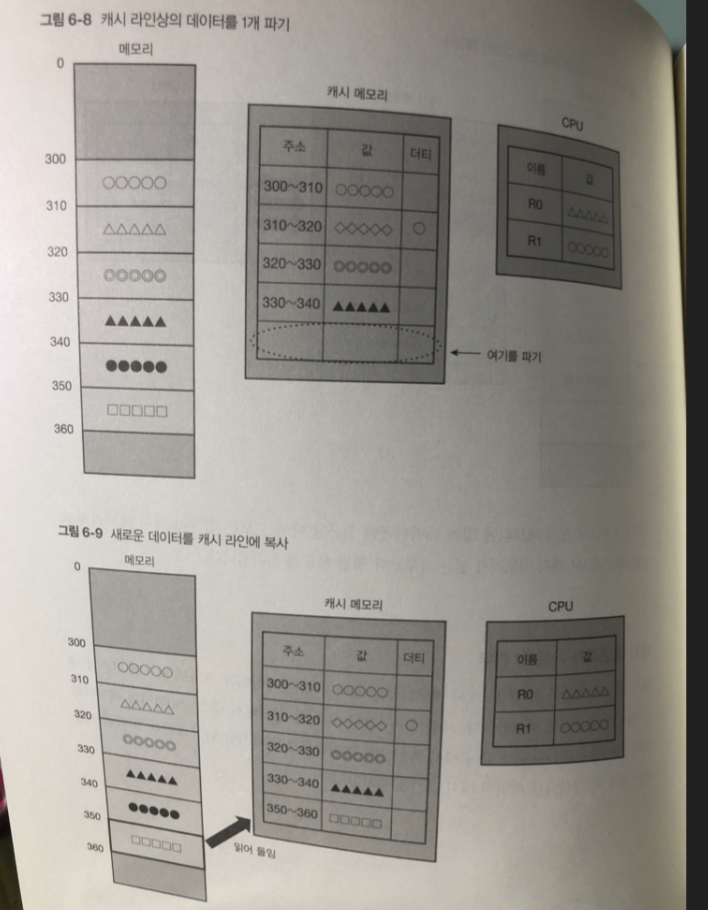
파기하는 캐시가 더티라면? - > 대응되는 메모리에 덮어 씀 다음 동기화 진행
캐시 메모리가 가득 차고 모든 캐시 라인이 더티?
메모리 접근 할때 마다 캐시 라인안의 데이터가 자주 바뀌는 스래싱
발생 성능 이 크게 감소
계층형 캐시 메모리
최근 CPU (x86_64) 캐시메모리는 계층형으로 되어 있음
각 계층은 사이즈 , 레이턴시 , 어느 논리 CPU 사이 공유 가능
계층 형 구조를 구석하는 각 캐시 메모리는
L1 / L2 / L3 (Level)
L1: 가장 용량이 적으며 빠름
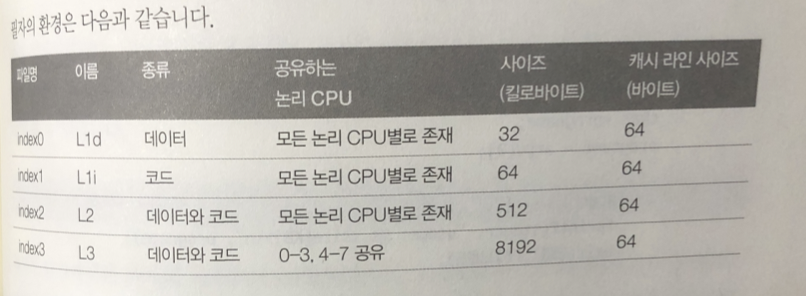
type : 캐시할 데이터의 종류 . Data라면 데이터 만을 code면 code만을
Unified라면 코드랑 데이터를 캐시
shared_cpu_list : 캐시를 공유할 논리 CPU 목록
size : 파일 사이즈
coherency_line_size : 캐시 라인 사이즈
캐시 실험
- 명령의 첫 번째 파라미터 입력값을 사이즈로(킬로바이트) 메모리 확보
- 확보한 메모리 영역 안에 정해진 횟수만큼 시퀀셜 접근
- 한번 접근할 때마다 걸린 소요 시간을 표시(2의 소요시간 / 2의 접근횟수)


컴파일
-03 : 최적화 옵션


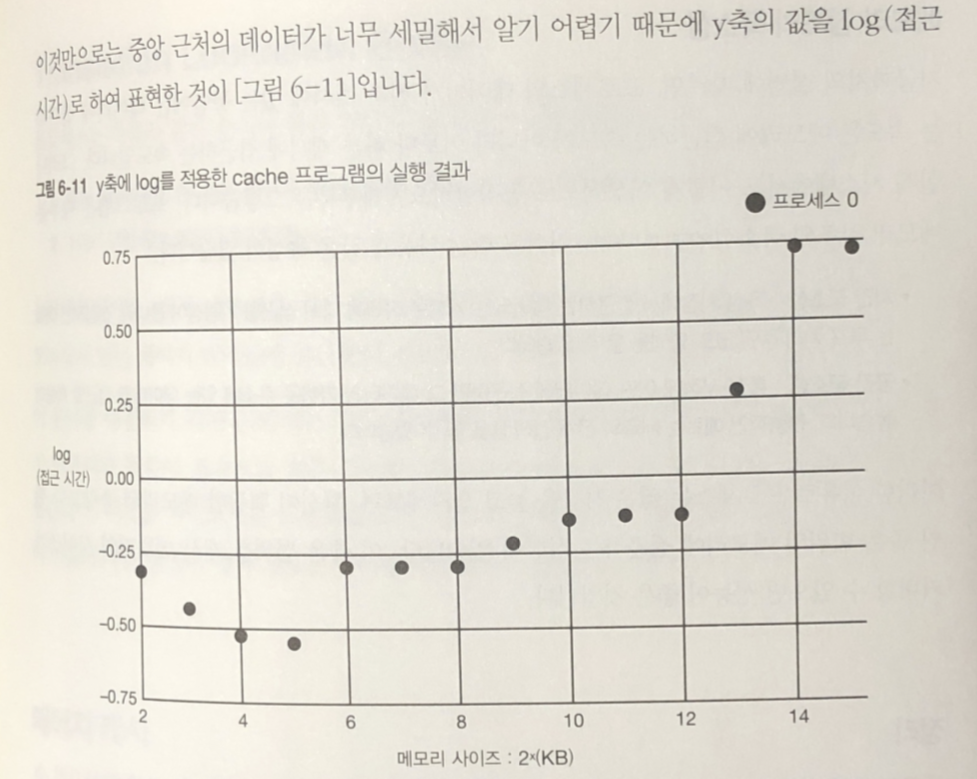
실험 환경
L1 : 64KB L2 : 512 KB L3 : 8MB
4 킬로 바이트 -> 32 메가바이트까지 2배씩 증가시켜서 실험
각 캐시의 사이즈를 경계로 해서 계단식 변화가 있다.
추가 설명
- 메모리 사이즈가 4킬로바이트나 16킬로 바이트의 경우 32 킬로바이트
때 보다 성능이 좋은것은 측정 프로그램 정밀도 문제
어셈블리어 코드로 해결 가능.- 이 측정에서 중요한 것은 절대적인 값이 아니라 접근하는 메모리 영역
의 사이즈에 따라 성능이 급변하는 점.
메모리 참조의 국소성
시간 국소성: 특정 시점에서 접근하는 데이터는 가까운 미래에 다시 접근 가능성이
크다. ex) 루프 처리 중 영역
공간 국소성 : 특정 시점에 어떤 데이터에 접근하면 그 데이터와 가까운 주소에 있는
데이터를 접근할 확률이 높다. ex) 배열의 전체검색
이런 이유로 프로세스는 짧은 시간을 놓고 생각하면
자신이 획득한 메모리의 총량보다 훨씬 좁은 범위의 메모리에 접근하는 성향이 있음
이 좁은 범위를 캐시 메모리의 사이즈가 커버 하면 성능이 좋다.
-> 캐시는 프로세스가 요구한 것보다 더 많은 데이터를 메모리에서 가져와놓고
cache hit를 높인다.
정리
프로그램의 워크로드를 캐시 메모리 사이즈에 들어가게 하는 것만으로 성능 향상이 큼
속도를 중시하는 프로개름은 캐시 메모리의 효과를 최대한으로 끌어내기 위해
데이터의 배열이나 알고리즘 혹은 설정을 연구해 메모리 접근 범위를 작게 하는것이 좋다.
시스템 설정을 변경했을때? 성능이 나빠지는 경우 프로그램의 데이터가 캐시 메모리에 전부 들어가지 않았을 가능성 존재
Translation Lookaside Buffer
CPU에 존재하는 가상 주소 변환 고속화 장치이다.프로세스는 다음 순서로 가상 주소의 데이터에 접근
-
물리 메모리상에 존재하는 페이지 테이블을 참고해 가상 주소를 물리 주소로 변환.
-
1에서 구한 물리 메모리에 접근
캐시 메모리를 사용해 고속화 하는 것은 2
1은 물리 메모리상에 있는 페이지 테이블에 접근해야 함으로 캐시 동작 XXXX
이 문제 해결
-> CPU 에는 가상 주소에서 물리 주소로의 변환표를 보관함.
캐시 메모리와 똑같이 고속으로 접근 가능한 Tranlation Lookaside Buffer
라는 영역을 만든 것임.
-> 1을 고속화 함.
페이지 캐시
CPU로 부터 메모리에 접근 하는 속도 에 비해 저장 장치에 접근 하는 속도는 너무 느림
이 속도 차이를 줄이기 위한
페이지 캐시
캐시 메모리와 매우 비슷.
캐시 메모리 : 메모리의 데이터를 캐싱
페이지 캐시 : 저장 장치 내의 파일 데이터를 메모리에 캐싱
페이지 캐시는 페이지 단위로 데이터를 다룸.
시스템의 메모리가 허용하는 한,
각 프로세스가 페이지 캐시에 없는 파일을 읽을 때마다 페이지 캐시 사이즈가 점점 증가한다.
만약 시스템 메모리가 부족해지면, 커널이 페이지 캐시를 해제한다.
더티 플래그가 없는 페이지부터 해제하며,
그래도 부족하면 더티 페이지를 라이트 백write back한 뒤 해제한다.
이 때 저장 장치에 접근하므로 성능 저하가 발생할 수 있다.
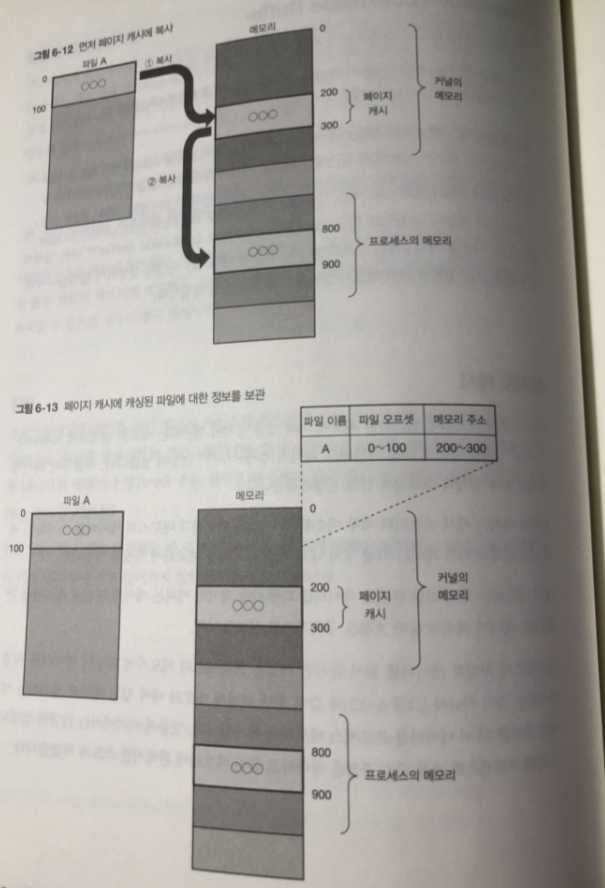
- 프로세스가 파일 데이터 읽음
- 커널의 메모리 내에 있는 페이지 캐시라는 영역에 복사
- 2 데이터를 프로세스 메모리에 복사.
커널은 자신의 메모리 안에 페이지 캐시에 캐싱한 파일과
정보를 보관하는 관리 영역을 가지고 있다.

페이지 캐시에 존재하는 데이터를 다시 읽으면 커널은 페이지 캐시의 데이터 돌려줌
쓰기
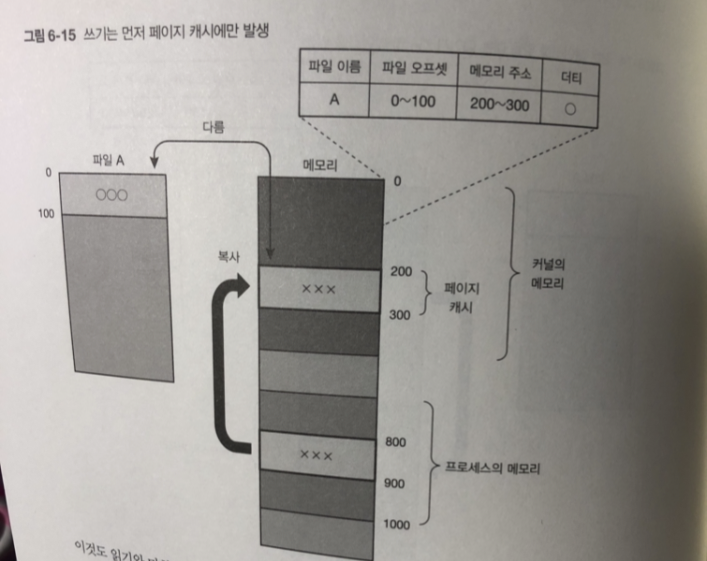
프로세스가 데이터를 파일에 쓰면 ! 페이지 캐시에 데이터를 쓴다.
이때 데이터의 내용은 저장 장치의 내용 보다 새로운것 flag 붙임
-> 더티페이지(dirty page)
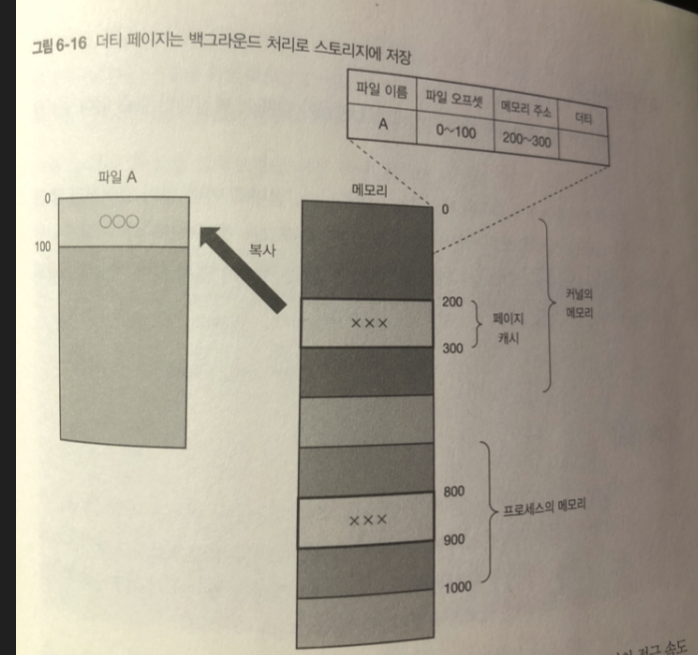
더티페이지의 내용은 나중에 커널의 백그라운드로 처리
스토리지 내의 파일에 반영 함
각 프로세스가 접근하는 파일 데이터가 전부 페이지 캐시에 있으면
시스템 파일의 접근 속도는 메모리 접근 속도임으로 빠르게 동작
동기화된 쓰기
페이지 캐시에 더티 페이지가 있는 상태로 시스템 전원이 강제로 꺼지면?
페이지 캐시의 데이터는 사라짐.
이런일이 벌어지면 안돼는 파일 경우
Open() 시스템 콜로 파일을 열때 0_SYNC 플래그를 설정해 둔다
이러면 나중에 파일 write() 시스템 콜을 수행 할 때 마다
데이터는 페이지 캐시 외에 저장 장치에도 동기화 되어 쓰기가 수행 됨.
버퍼 캐시
페이지 캐시와 비슷 한구 조 버퍼 캐시.
디바이스 파일을 이용하여 저장 장치에 접근하는 목적으로 사용(7장)
-> 페이지 캐시와 버퍼 캐시를 합쳐서 저장 장치 안의 데이터를 넣어두는 방식
파일의 읽기 테스트
파일 읽기 2회 실행뒤 소요시간 비교
testfile 1기가 바이트 파일 생성
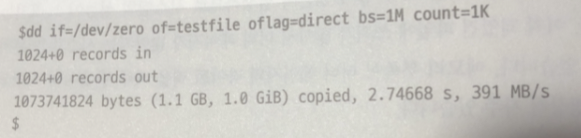
oflag =direct -> 파라미터를 지정해서 다이렉트I/O 라는 방법으로 파일 쓰기
-> 페이지 캐시를 사용하지 않음 -> testfile 파일의 페이지 캐시는 없음
2초 정도 걸림.
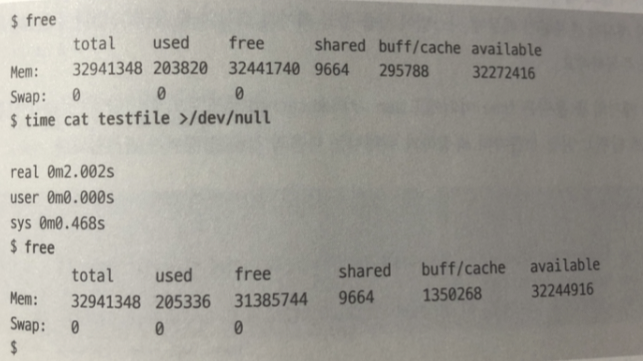
- 처음 읽기 때문에 저장 장치 접근 (경과 시간) real 2초 중에
프로세스 혹은 프로세스에 처리를 요청받은 커널이 CPU를 사용한
시간이 0.468초 - 그러므로 전체의 3/4 정도 1.54 초는 저장 장치로부터 읽기가 끝나기를
기다리는 시간. - 측정 전후 시스템 전체의 페이지 캐시 1기가 바이트 증가. (testfil)
파일의 캐시에 해당 .

시간이 빠르게 단축.
페이지 캐시에 있는 데이터를 복사 했기 때문에.
페이지 캐시의 총 용량은 free이외에 sar -r의 kbcached 필드로 확인가능
(KB)

통계 정보
위 테스트시 통계 정보 확인
- 저장 장치로 부터 페이지 캐시에 데이터를 읽은 페이지 인 횟수
- 페이지 캐시로부터 저장 장치에 페이지를 쓴 페이지 아웃 횟수
- 저장 장치에 대한 I/O의 양

sar -B로 페이지 인 / 아웃 정보 얻기.
Read-twice.sh 는 백그라운드로 sar -B 실행.
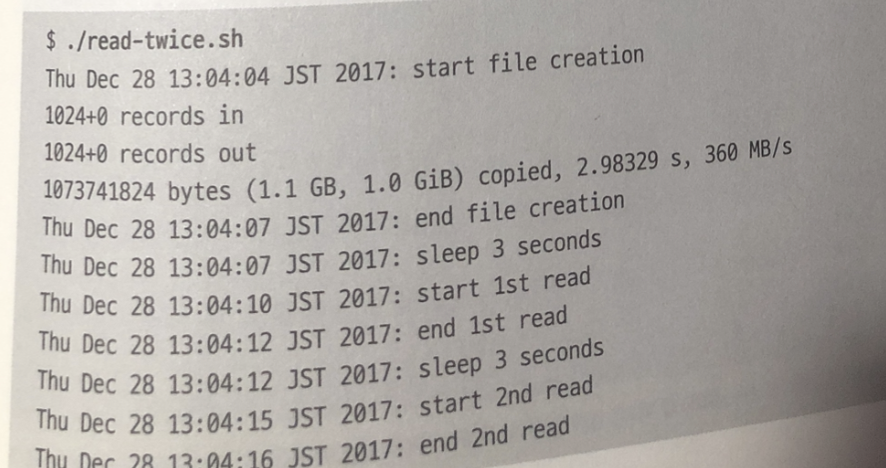
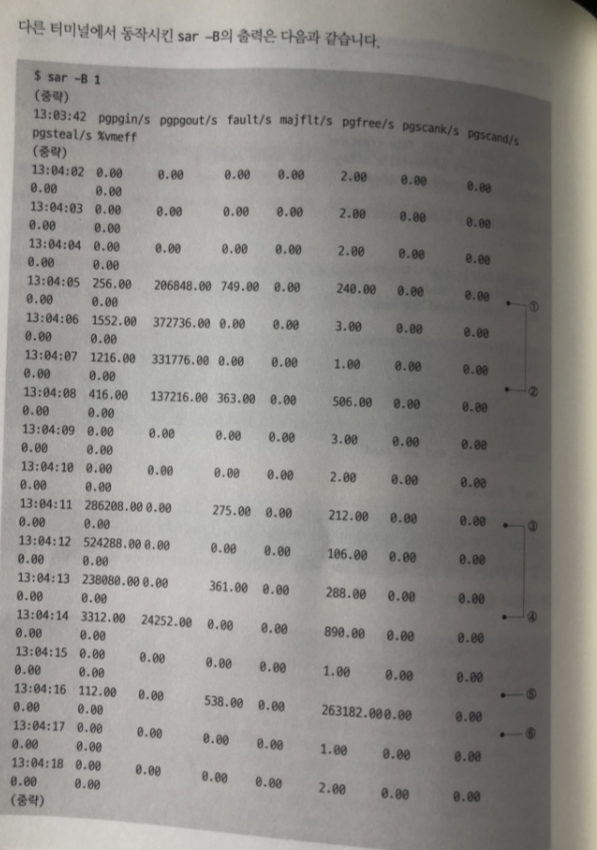
- 파일 작성 시 (1~2)에 총 1기가 바이트 페이지 아웃 발생.
( 페이지 캐시를 사용하지 않을때에도 파일의 데이터를 저장장치에 쓸 때에는 페이지 아웃으로 카운트)- 첫 번째로 파일을 읽을 때 (3~4)는 총 1기가바이트 페이지 인 발생
저장 장치로 부터 페이지 캐시에 데이터를 읽어 들임
(testfile의 내용을 페이지 캐시로 불러온 것이다.)- 두 번째로 읽을 (5~6) 페이지 인 발생 X 조금 발생하는건 시스템 다른 처리 때문 (페이지 인이 발생하지않는다 tesfile 두번째 읽을 떄)
sar -d -p 명령어로 I/O 양 확인
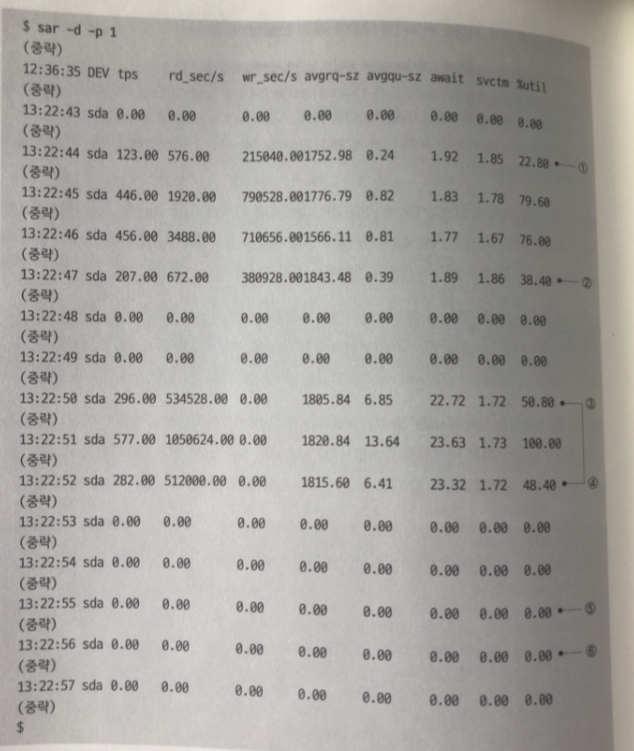
sar -d - p의 rd_sec/s 와 wr/sec/s 가 각각 1초당 개별의 저장 장치
(이경우에는 sda) 에 대해서 읽고 쓴 데이터양 단위는 섹터로 512 바이트 해당
결과
- 파일을 작성할때 (1~2)에 총 1기가 바이트의 쓰기가 발생
- 첫 번째로 파일을 읽을때 (3~4) 에 총 1기가 바이트의 읽기 발생
- 두 번째로 읽을 때 (5~6) 읽기 발생하지 않음
%util이 측정 시간 (이 경우 1초) 동안 저장 장치에 접근한 시간의 할당량
sar - P ALL 명령어 등 으로 %iowwait라는 비슷한 값을 얻을수 있지만
이것은 CPU가 idle 상태로 해당 CPU 에 I/O를 대기 하고 있는 프로세스가
존재하고 있음의 시간 할당량
파일의 쓰기 테스트
파일에서 쓰기 처리 다음에 발생하는 라이트 백 처리 관해서 확인..
*testfile을 생성할 때, 페이지 캐시 사용 유무에 따른 소요 시간의 차이를 관찰한다.

I/O 파일을 쓰면서 소요 시간 측정
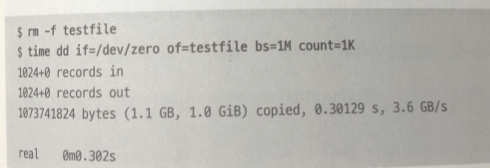

쓰기 속도 8 배 이상 차이.. (페이지 캐시 쓰냐 안쓰냐 차이가..)
2.5601 < - > 0.30129
통계 정보
쓰기에 대한 통계 정보..



쓰기 중 1~2 에는 페이지 아웃 발생하지 않음
I/O 발생량 확인
sar -d -p 의 통계 정보를 얻으면서 실행한 write.sh 스크립트 결과
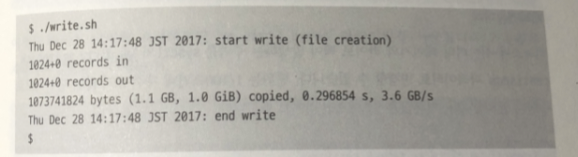


쓰기가 발생하는 동안 장비에는 I/O 발생하지 않음 (페이지캐시껄 사용해서)
메모리의 내용을 디스크에 저장하는 것을
'페이지 아웃(page-out) ',
디스크의 내용을 메모리에서 읽어들이는 작업을
'페이지 인(page-in) ' 라고 합니다.
튜닝 파라미터
- CPU가 캐시메모리를 바꿀 때 메모리를 같이 바꾸는 방법 (라이트 쓰루)
- CPU가 캐시메모리를 바꾸고 일정한 시간에 한번에 메모리의 값을 바꾸는 방법 (라이트 백)
페이지 캐시를 제어하기 위한 다양한 튜닝 파라미터

라이트 백 주기를 sysctl의 'vm.dirty_writeback_centisecs' 파라미터 변경 할 수 있음
단위는 1/100 자주 안쓰는 단위이므로 주의
기본 값은 5초에 1번 라이트 백
- 값을 0으로 하면 주기적인 라이트 백은 발생하지 않지만 위험하다고 한다.

시스템 메모리 부족시 라이트 백 부하가 커기는 것을 방지하는 파라미터
'vm.dirty_background_ratio' 파라미터로 지정한 퍼센트를
초과한 경우 백그라운드 라이트 백 동작 ( 기본값 10)
시스템의 물리 메모리 중 더티 페이지가 차지하는 최대 비율
더티 페이지가 이 값(퍼센트)을 초과할 경우 백그라운드 라이트 백 처리가 동작한다.
메모리가 부족할 때 라이트 백 부하가 커지는 것을 방지한다.
바이트 단위 지정 'vm_dirty_background_bytes' 파라미터

더티 페이지가 차지하는 비율이 이 값(퍼센트)을 초과하면, 프로세스에 의한 파일에 쓰기의 연장으로 동기적인 라이트 백을 수행한다.

더티 페이지가 차지하는 비율 'vm.dirty_ratio' 파라미터에 의해
지정된 퍼센트를 초과하면 프로세스에 의한 파일에 쓰기의 연장으로
동기적인 라이트백 수행
vm.dirty_ratio를 비율 대신 바이트 단위로 설정할 때 사용한다.

이것도 바위트 단위로 지정하려면 vm.dirty_bytes 파라미터 사용
시스템의 메모리가 부족해 갑자기 더티페이지의 라이트백이 자주 발생하는 일없게..
시스템 캐시 삭제 방법
/proc/sys/vm/drop_caches 라는 파일에 3을 넣어줌
/proc/sys/vm/drop_caches 라는 파일에 3을 넣으면 페이지 캐시가 비워진다고 한다.

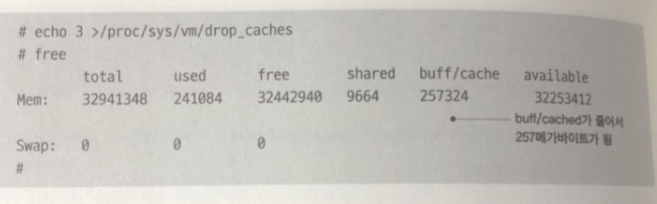
실제로 사용할 기회는 드물지만
시스템 성능에 페이지 캐시의 영향을 확인하는 용도로 편리
정리
- 파일의 데이터가 페이지 캐시가 있다면 없는 경우에 비해 파일 접근이 빠르다.
- 설정 변경이나 시간이 지나면서 시스템의 성능이 느려졌다면.
파일의 데이터가 페이지 캐시에 제대로 들어 가지 못했을 수도 있다. - sysctl 파라미터를 잘 튜닝하면 페이지 캐시의 라이트 백이 자주 발생하셔 생기
는 I/O 부하를 막을 수 있따 - sar -B / sar -d -p 등 페이지 캐시에 관한 통계정보 얻을 수 있다
하이퍼스레드
CPU 계산 처리 소요 시간에 비해 메모리 접근의 레이턴시가 매우 느림.
캐시 메모리 레이턴시도 CPU 계산 처리에 비교하면 느린 편.
결론 : CPU 사용 시간 대부분은 메모리 혹은 캐시 메모리로부터 데이터를
기다리는 일로 낭비 되고 있다.
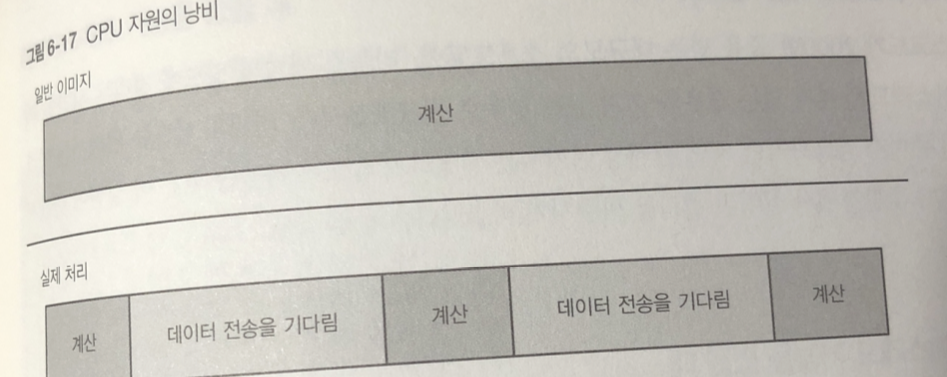
하이퍼 스레드의 기능으로 대기시간 때문에 낭비되는 CPU 자원을
유효하게 활용 가능.
(하이퍼 스레드는 프로세스와 대응되는 스래드라는 용어와 관계 없다)
하이퍼스레드 기능은 CPU 코어 안의 레지스터 등 일부 자원을
여러개 (일반적으로 2개) 준비해 두고. 시스템 입장에서 각각 논리 CPU
로써 인식되는 하이퍼스레드라는 단위로 분할되는 하드웨어 기능이다.
각각의 하이퍼스레드는 앞서 말한 대로 특정 조건 아래에서 여러개가 동시에 실행
하이퍼 스레드 기능은 무조건 좋은건 아니며
그 효과는 하이퍼 스레드상 동작하는 프로세스의 행동 따라 다름.
현실적으로 부하가 걸리는 상황에서 20~30 퍼 성능 향상이 나오면 훌륭함.
하이퍼스레드 기능 테스트.
리눅스 커널의 빌드에 걸리는 시간을
하이퍼스레드 유무에 따라 비교하자.
하이퍼스래드 기능 껐을 때


빌드 소요 시간은 93.7초
하이퍼스래드 기능 켰을 때


하이퍼 스레드의 짝을 이루는 논리 CPU 확인

73.3초
약 22퍼 성능 향상 확인.
실제로는 하이퍼 스래드 사용해서 향상이 안나올 수 있음..
7장 파일시스템
리눅스는 저장 장치안에 데이터에 접근 할때
직접 접근은 하지않고 파일 시스템을 통해 접근함.
저장 장치 : 저장장치 안에 지정된 주소에 대해 특정 사이즈의 데이터를 읽거나 씀
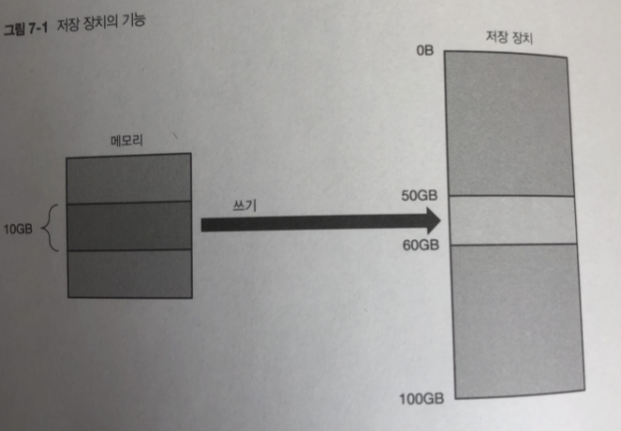
파일 시스템이 없다면. 문서를 작성하고 저장 할때
스스로 10기가 바이트 데이터를 50기가 바이트 지점에씀 따로 요청해야 됨.
그리고 다음에 읽을 때 보관한 주소 사이즈를 기억해야 됨.
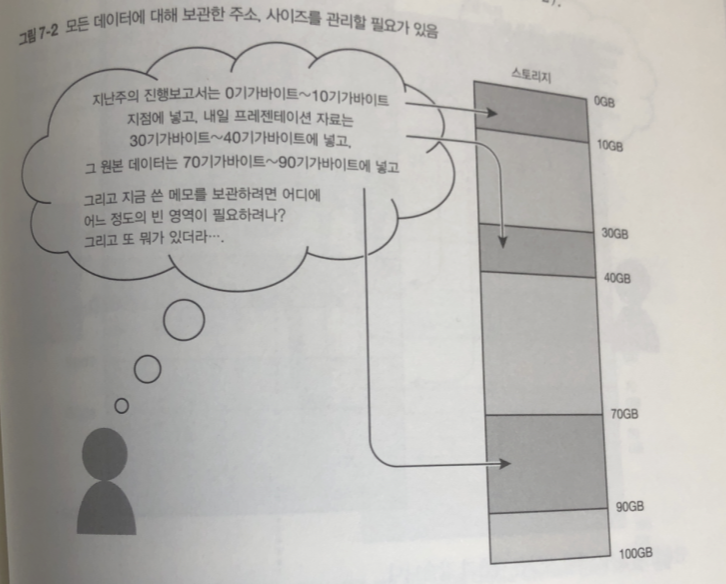
이런 복잡한 처리 피하고 어디에 어느 정도 데이터가 있는 지 관리하는게
파일 시스템
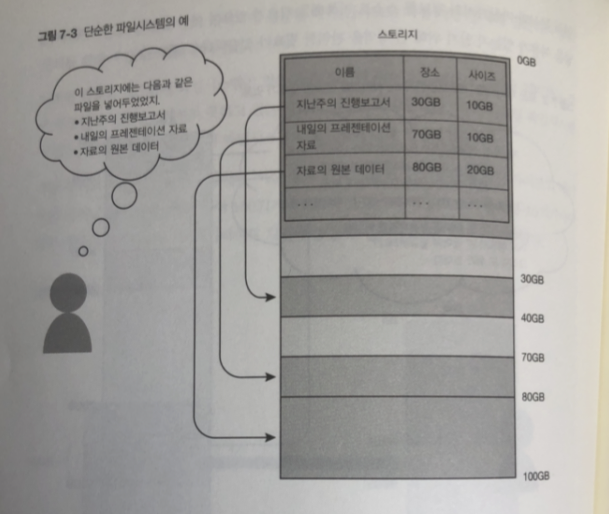
일반적 단순한 파일 시스템 0번째 부터 차례대로..
리눅스의 파일 시스템
디렉터리: 파일을 카테고리별로 정리할수 있는 리눅스 파일 시스템
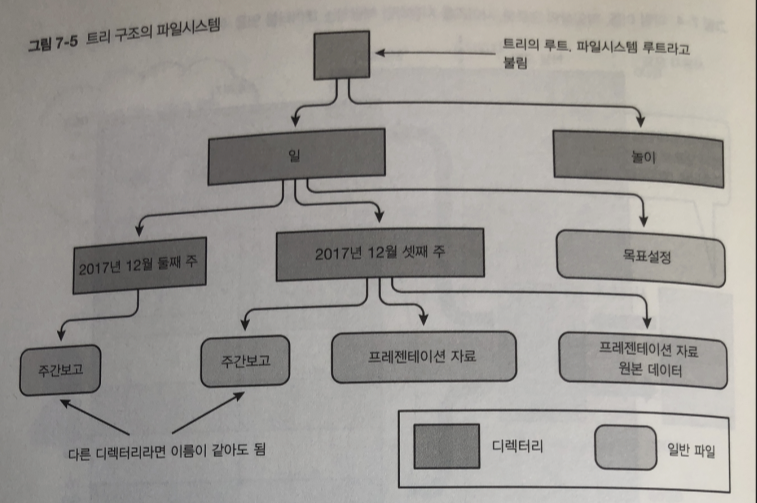
리눅스 파일시스템
Ext4
XFS
Btrfs
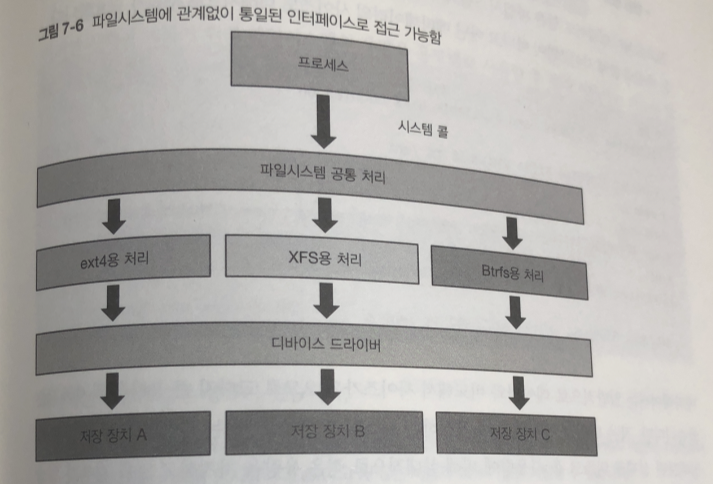
어떤 파일 시스템을 시스템 콜 호출한다면 동일된 인터페이스
- 파일의 작성 삭제 :create() , unlink()
- 파일을 열고 닫음 : open() , close()
- 열린 파일로부터 데이터 읽어 들임 : read()
- 열린 파일에 데이터를 씀 : write()
- 열린 파일의 특정 위치로 이동 : lseek()
- 위에 언급한 것 이외의 파일시스템에 의존적인 특수한 처리 : Ioctl()
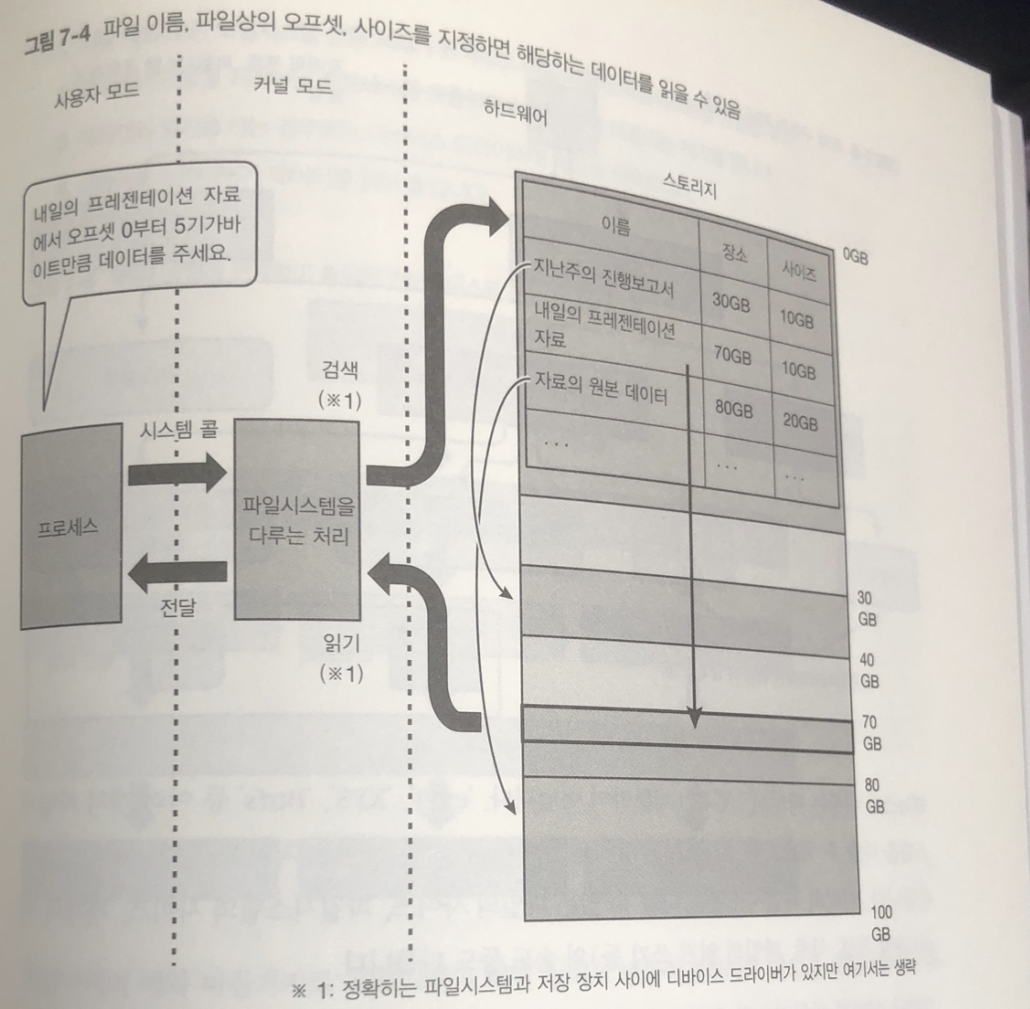
이런 동작으로 시스템 콜이 호출되면 다음 순서로 파일 데이터가 읽어짐
- 커널 내의 모든 파일 시스템은 공통 처리 동작, 대상 파일의 파일시스템 판별
- 각 파일시스템을 처리하는 프로세스를 호출하여 시스템 콜에 대응되는 처리
- 데이터를 읽기를 하는 경우에는 디바이스 드라이버에 처리 의뢰
- 디아비스 드라이버가 데이터를 읽음
데이터와 메타 데이터
파일 시스템에는 데이터와 메타 데이터 두종류가 있음
데이터 : 사용자가 작성한 문서나 사진, 동영상, 프로그램등의내용
메타데이터 : 파일의 이름이나 저장 장치 내에 위치 사이즈 등의 보조 정보
- 종류: 데이터를 보관하는 일반 파일 인지 디렉터리인지 혹은 다른 종유인지 판별정보
시간 정보: 작성한 시간 , 최후에 접근한 시간, 최후에 내용이 변경된 시간
권한 정보: 어느 사용자가 파일에 접근이 가능한가.
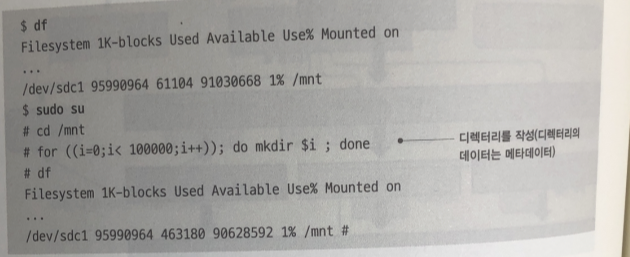
df : 파일 시스템의 스토리지 사용량 메타 데이터의 사이즈도 더해 진것이다.
용량 제한
특정 용도가 파일시스템의 용량을 무제한으로 사용 할 수 있다면?
다른 용도로 사용할 용량 부족.

쿼터

파일시스템의 용량을 용도별로 사용할 수 있게 제한하는 기능
- 사용자 쿼터 : 파일의 소유자인 사용자 별로 용량 제한.
(ext4,XFS 사용자 쿼터기능 사용가능) - 디렉터리 쿼터 : (혹은 프로젝트 쿼터) : 특정 디렉터리 별로 용량을 제한
(ext4,XFS는 디렉터리 쿼터 기능 사용 가능) - 서브 불륨 쿼터: 파일시스템 내의 서브 볼륨이라는 단위별 용량을 제한하는 것으 로 거의 디렉터리 쿼터와 사용 법 유사(Btrfs 서브 볼륨쿼터 사용 가능)
파일 시스템이 깨진 경우
데이터를 파일 스토리지에 쓰고 있는 도중 전원이 강제적으로 끊어 졌을 때..
이런 처리중 하나라도 누락 되면. 아토믹한 처리라고 부름
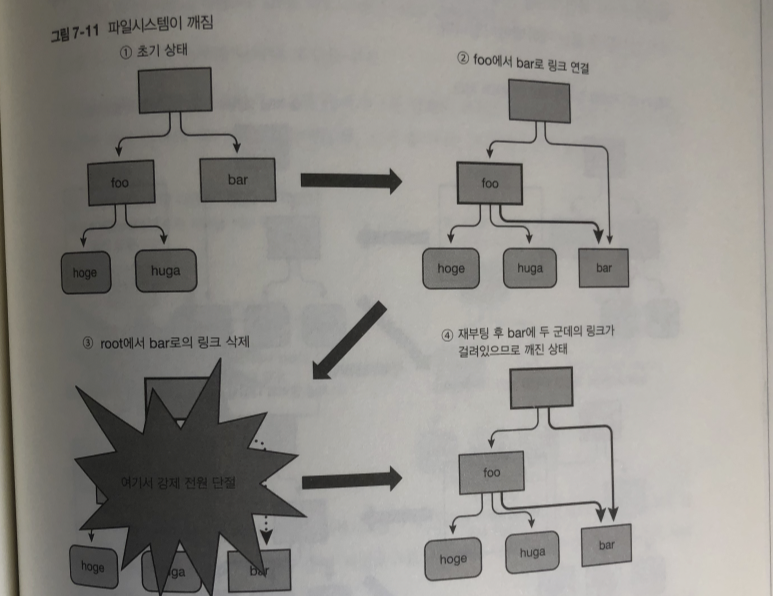
이런 상태가 발견되면 파일 시스템이 감지.
마운트 시 발견되면 파일시스템의 마운트 불가능..
최악 인경우 시스템에 패닉이 발생
파일 시스템이 깨지는 것을 막기 위한 기술
저널링 (ext4,XFS) / Copy on Write(Btrfs)
저널링
파일 시스템 안에 저널 영역이라는 특수한 영역준비.
저널 영역은 사용자가 인식 할 수 없는 메타데이터
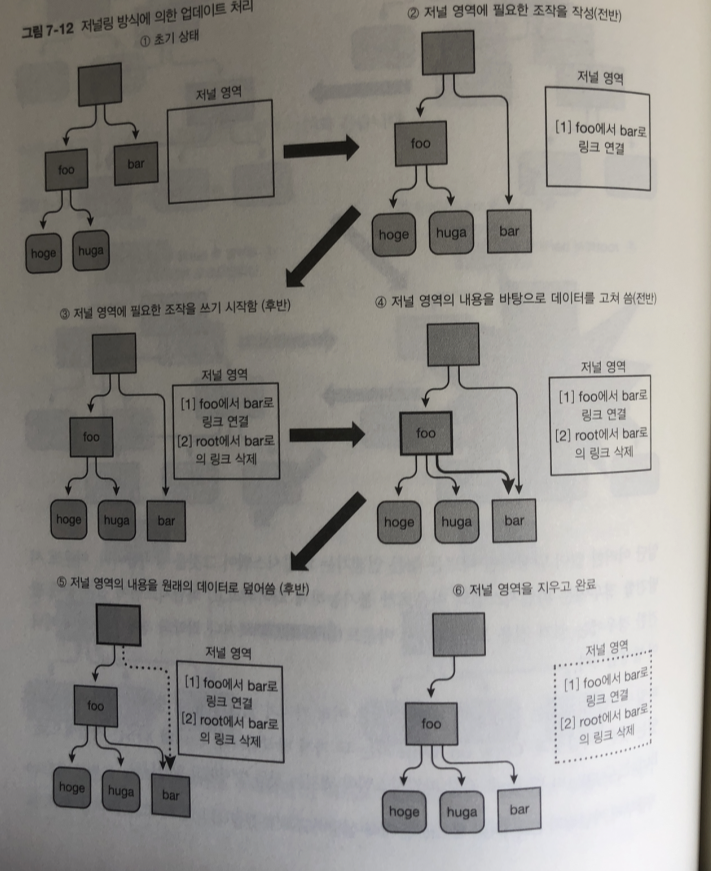
따로 영역을 만들어서 히스토리를 작성 해서 결과 반영하기.
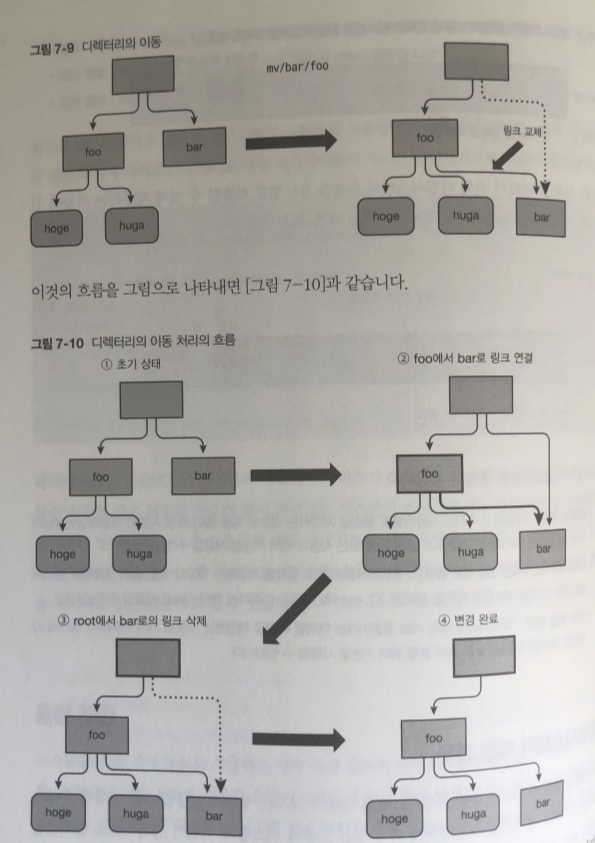
파일시스템 업데이트 순서
- 업데이트에 필요한 아토믹한 처리의 목록을 일단 저널 영역에 작성 (저널로그)
- 저널 영역의 내용을 바탕으로 실제로 파일 시스템의 내용을 업데이트
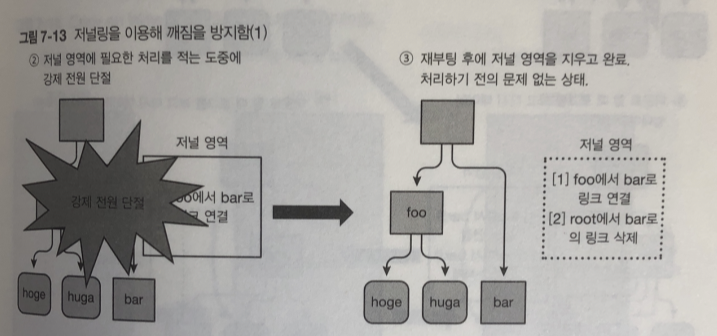
2번 부분에서 연결 끊기면 저널 영역 데이터만 지워지고 실제로 처리 안됌
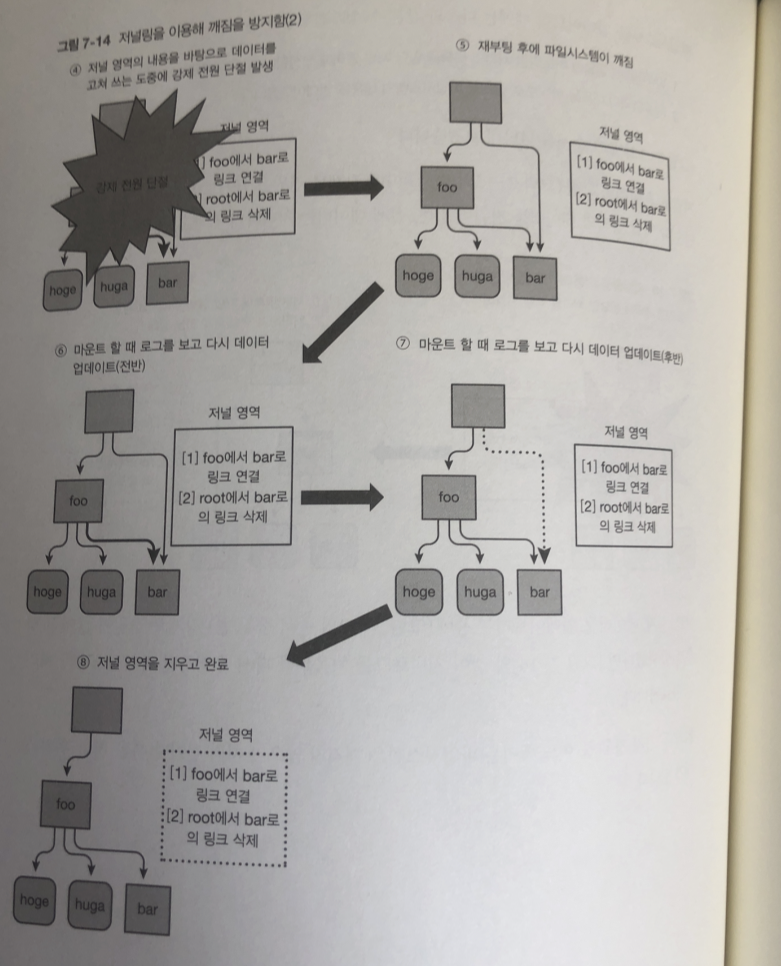
4번 부분에서 전원이 끊어 지면. 저널로그를 읽고 파일 수행 처리함.
Copy on Write
파일 시스템이 데이터를 넣는 법 을 알아보자
(ext4 , XFS)

파일을 작성하면 파일의 배치 장소는 원칙적으로 바뀌지 않음
파일의 내용을 업데이트 할때마다 새로운 데이터를 써넣음
이것과는 다르게 Btrfs 등 Copy on Write형의 파일 시스템은
파일을 작성하더라도 업데이트 할때마다 다른 장소에 데이터 씀
(실제로는 파일이 업데이트된 부분만 다른 장소에 복사됨)


아토믹으로 처리해야할 여러개의 처리를 실행할 경우
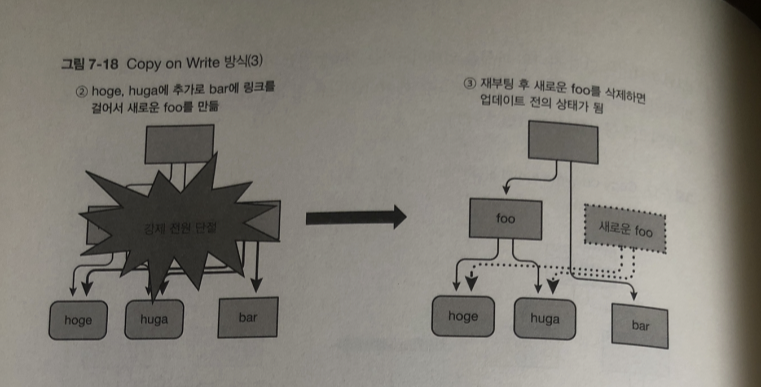
그래도 깨지는 것을 막을 수 없는 경우
여전히 발생 가능 성이 있다
파일시스템의 깨짐에 대한 대책
정기적으로 백업 -> 마지막 백업 날짜로 데이털 복원
백업을 할 수 없으면
파일시스템에 준비된 복구용 명령어 이용.
공통 : fsck
ext4: fsck.ext4
XFS : xfs.repair
Btrfs : btrfs check
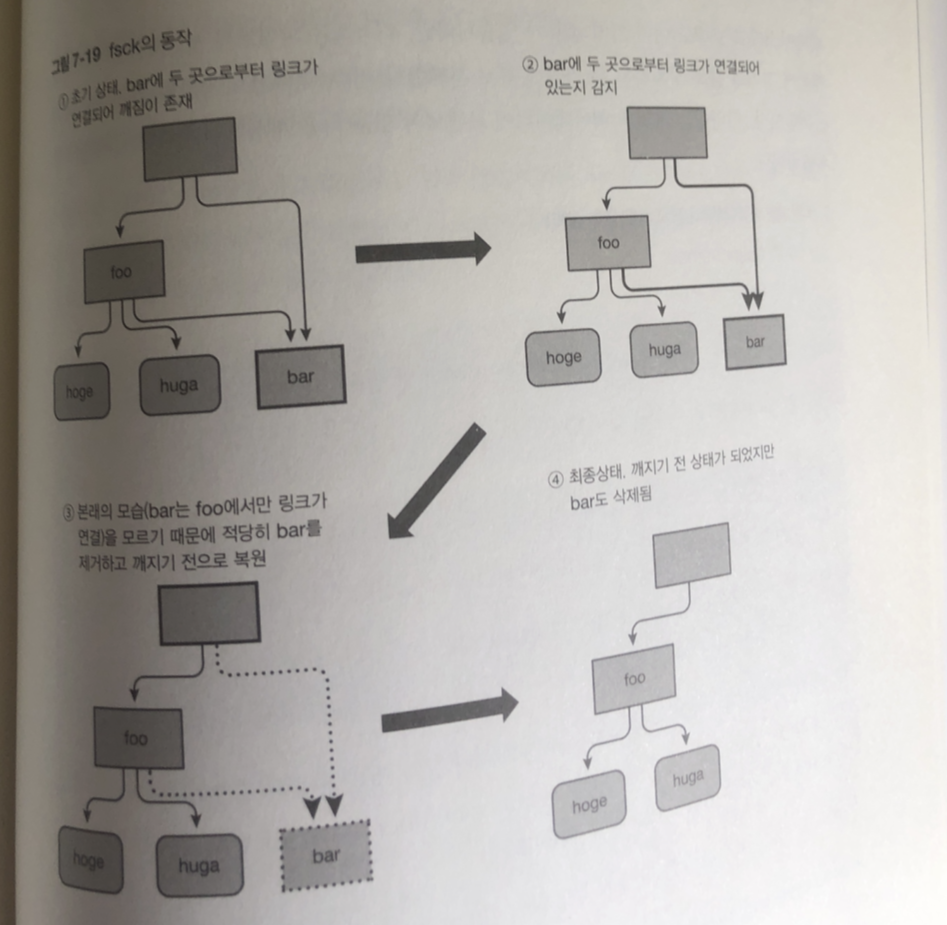
이 명령어 사용시 시스템을 깨지지 않은 상태로 고칠 수 있음
하지만 추천하지 않음
- 깨지지 않았음을 확인하거나 복구하기 위해 파일 시스템 전체 조사함.
소요 시간이 파일시스템 사용량에 따라 증가, 수 테라바이트의 파일 시스템이면
수 시간이 아니라 수일 단위의 시간이 필요함- 복구에 오랜 시간이 들여도 결국 실패하고 끝나는 경우도 많음
- 사용자가 원하는 상태로 복원한다고 보장 할수 없음.
fsck는 어디까지나 데이터가 깨진 파일시스템을 무리해서라도 마운트하려는 명령어
처리하면서 깨진 데이터는 내용과 관계 없이 삭제함
파일의 종류
일반 파일 / 디렉토리 파일 그 이외에 디바이스 파일
리눅스는 스스로 동작하고 있는 하드웨어상의 장치를 거의 모두 파일로서 표현.
(네트워크 어댑터는 예외로 장치에 대응되는 파일이 없다)
리눅스에서는 장치를 파일과 동등하게
open(), read(), write() 등 시스템 콜을 이용
장치의 고유한 복잡한 조작에는 ioctl() 시스템 콜 사용
디바이스 파일 접근은 Root 만 가능
리눅스는 파일로서 접근하는 디바이스를
캐릭터 장치 / 블록 장치 라는 두 가지 종류로 분류
파일의 종류 ( 캐릭터 장치 혹은 블록장치)
각 디바이스 파일은 /dev 아래 존재
장치의 Major number
장치의 Minor number

b로 시작하면 블록장치
c로 시작하면 캐릭터 장치
5번째 필드가 Major number 6번째 필드가 Minor number
캐릭터 장치
캐릭터 장치는 읽기와 쓰기가 가능 (탐색 은 되지 않는다)
종류
터미널 : bash 등 쉘
키보드
마우스
ex) 터미널의 디바이스 파일은 다음과 같이 다름
write() 시스템 콜: 터미널에 데이터 출력
read() 시스템 콜 : 터미널의 데이터를 입력

실제로 터미널 조작 해보자 .
프로세스에 연결 되어있는 터미널은 ps ax 명령어의 두번째 필드로 알아낼 수있음
bash : /dev/pst/9 연결되어있는장치
터미널 디바이스에 'hello' 문자열 씀 (정확히 디바이스 파일에 write()시스템 콜 요청 )
터미널에 문자열 출력.
echo 는 표준 출력에 'hello'를 쓰고 있고 리눅스에 의해 표준 출력이
현재의 터미널과 연결되어 있기 때문
다른 터미널 조작해보기 : 터미널 2개 열고 다음을 실행

위에는 기존 터미널 아래는 새 터미널
- 실제로 애플리케이션이 터미널의 디바이스 파일을 직접 조작하기 보다는,
리눅스가 제공하는 셸이나 라이브러리가 직접 디바이스 파일을 다루는 편이다.
애플리케이션은 셸이나 라이브러리가 제공하는 인터페이스를 쉽게 사용하는 편이다.
블록 장치
블록 장치는 단순히 파일 읽고 쓰기 이외 랜덤 접근 가능
ex) SSD , HDD 저장 장치
블록 장치에 데이터를 읽고 쓰는 것으로 일반적인 파일처럼
스토리지의 특정 장소에 있는 데이터에 접근 가능
블록 장치는 파일시스템을 작성해 마운트함으로서 직접 접근하지 않고
파일 시세틈으로 경유해서 사용
블록 장치를 직접 다루는 경우
- 파티션 테이블 업데이트 (parted 명령어 등 사용)
- 블록 장치 레벨의 데이터 백업 & 복구 (dd 명령어 등을 사용)
- 파일시스템의 작성 (각 파일시스템의 mkfs 명령어를 사용)
- 파일시스템의 마운트(mount 명령어 사용)
- fsck
블록 장치를 직접 조작


적당한 이름으로 마운트를 하고 데이터를 살펴보면
strings 명령어를 사용하여 파일 시스템의 들어있는 /dev/sdc7안에
문자열 정보만 추출한다.
첫번째 필드에는 파일 오프셋 / 두 번째 필드에는 찾은 문자열
- lost+found 디렉터리와 testfile이라는 파일명 (메타데이터)
- 위에 적은 파일의 내용인 Hello world 라는 문자열 (데이터)

testfile 내용을 블록 장치로부터 변경 하자
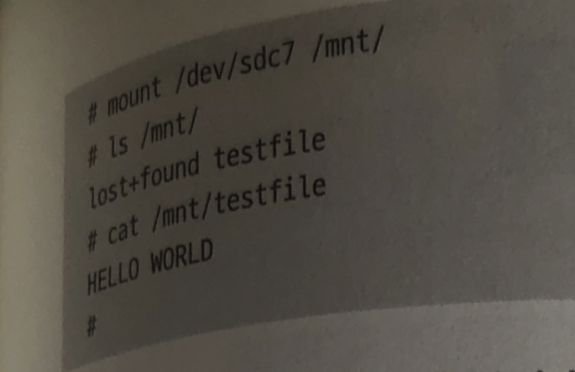
파일 시스템을 다시 마운트 해서 보면
Testfile 내용이 바뀌어 있다.
이것으로 블록 장치를 직접 조작해 저장 장치를 다룰 수 있음.
파일시스템도 단지 저장 장치에 배치된 데이터의 불가
결론
파일 시스템과 블록 장치의 관계를 알기 위해 파일시스템의 내용을
블록 장치로부터 직접 변경해보았다.
-
위에 적은 파일 내용을 덮어쓰는 것은 현재 버전의 ext4에는 잘 될지 모르지만
다른 파일 시스템이나 미래에 포맷이 바뀐 ext4에서는 똑같이 동작한다고
보장 할 수 없다. -
파일시스템의 내용물을 직접 바꾸는 것은 굉장히 위험하기 때문에 반드시 테스트용
파일시스템에서 해보기를 권장 -
파일시스템을 마운트 한 상태에서 그것을 보관하는 블록 장치에 동시에 접근하는 것은 불가능 하다. 파일시스템이 깨질 가능성 이 있어 파괴 위험성이 있다.
메모리를 기반으로 한 파일 시스템
저장 장치 대신 메모리에 작성하는 tmpfs라는 파일 시스템이 있다.
이 파일시스템에 보존 한 데이터는 전원을 꺼버리면 사라지지만
저장 장치의 접근이 전혀 발생하지 않아 고속으로 사용 가능
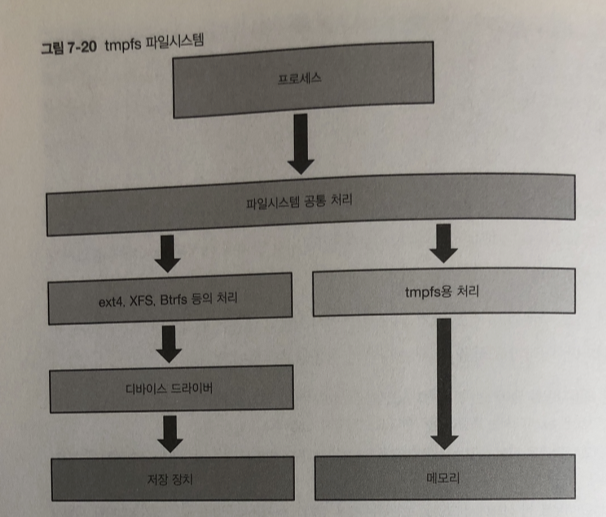
재부팅 후에 남아있을 필요 없는 /tmp , /var/run에 사용하는 경우많음

Tmpfs는 마운트 할 때 작성
이때 size 마운트 옵션으로 최대 사이즈를 사용하고 있다.
처음부터 최대 용량 메모리를 확보하지않고
파일시스템 내 영역이 처음 접근 할때 페이지 단위로 메모리를 확보하는
방식이므로 문제 없다.

free의 출력 결과에 있는 shared 필드 값이 tmpfs에 의해
실제로 사용될 메모리 양을 표시
네트워크 파일 시스템
가상 파일 시스템
커널 안에 여러가지 정보를 얻거나 동작을 변경하기 위한
다양한 파일 시스템이 존재
Procfs
시스템에 존재하는 프로세스 정보를 얻기위해 procfs 파일 시스템 존재
/proc 이하 마운트 됨. /proc/pid 이하의 파일에 접금함으로서
각 프로세스 정보를 얻음 ..

/proc/pid/maps : 프로세스 메모리 맵
/proc/pid/cmdlin : 프로세스 명령어 라인 파라미터
/proc/pid/stat : 프로세스의 상태 , 지금까지 사용한 CPU 시간, 우선도 사용 메모리 양등..
/proc/cpuinfo : 시스템에 탑재한 CPU에 대한 정보
/proc/diskstat : 시스템에 탑재한 저장 장치에 대한 정보
/proc/meminfo : 시스템의 메모리에 대한 정보
/proc/sys 이하의 파일 : 커널의 각종 튜닝 파라미터. sysctl와
/etc/sysctl.conf로 변경하는 파라미터 1:1 대응
-- 지금 까지 나왔던 ps , sar , top ,free 등 OS가 제공하는 각종 정보를 표시하는 명령어는 procfs로 부터 얻고 있엇다.
(좀 더 자세한 의미는 man 페이지(man proc) 참고)
sysfs
procfs 잡다한 정보가 많음. procfs를 마구잡이로 사용하는 것을 막기 위해
이러한 정보를 배치하는 장소를 어느 정도 정하기 위해 만든 sysfs
/sys 이하 마우트
sysfs
- /sys/devices 이하의 파일들 : 시스템에 탑재된 디바이스 에 대한 정보
- /sys/fs 이하의 파일 : 시스템에 존재하는 각종 파일시스템에 대한 정보
cgroupfs
하나의 프로세스나 여러개의 프로세스로 만들어진 그룹에 대해
여러가지 리소스 사용량의 제한을 가하는 cgroup 기능
cgroup 라는 파일시스템을 통해 다루게 됨 (Root 권한만)
/sys/fs/cgroup
ex)
CPU : 그룹이 CPU의 전체 리로스 중 50% 일정한 비율 이상은 사용할 수 없도록
함 /sys/fs/cgroup/cpu 이하의 파일을 읽고 쓰는 것으로 제어 가능
메모리 : 그룹이 물리 메모리 중 특정량 , 예를 들어 1기가바이트 밖에 사용하지
못하게 하는 등 /sys/fs/cgroup/memory 이하의 파일을 읽고 쓰는 것
으로 제어
cgroup은 예를 들어 docker 등의 컨테이너 관리 소프트 웨어나
virt-manager 등 가상 시스템 관리 소프트웨어 등에 각각의
컨테어이너나 가상 시스템의 리소스를 제한하기 위해 사용 할 수 있다.
특히 하나의 시스템상에 여러 개의 컨테이너나 가상 시스템이 공존하는
서버 시스템에 사용함.
Btrfs
ext4 , XFS 보다 좀더 풍부한 기능 제공
멀티 볼륨
ext4 XFS는 하나의 파티션에 대응하여 하나의 파일 시스템은 만듬
Btrfs는 여러개의 저장장치/파디션 으로부터 거대한 스토리지 풀을 만듬.
거기에 마운트한 서브 볼륨이란 영역 작성
스토리지 풀은 LVM으로 구현된 볼륨 그룹, 서브 볼륨은 LVM으로 구현된 논리 볼륨과 파일시스템을 더한 것과 비슷함.
Btrfs는 파일시스템 + LVM과 같은 볼륨 매니저라 생각하는편이 쉬움


Btrfs 파일시스템에 저장 장치의 추가 삭제 교환가능
이러한 작업으 할때 용량 변화에 따른 파일시스템의 크기 조정 처리는 안해도 됨
스냅샷
btrfs는 서브 볼륨 단위로 스냅샨 만들 수 있음
스냅샷 작성은 데이터를 참조하는 메타데이터의 작성 혹은
스냅샵 내의 더티페이지 라이트 백을 하는 것만으로 처리할 수 있기 때문에
일반적인 복사 보다 빠르다.
원래 서브 볼륨과 스냅샨은 데이터를 공유하기때문에 공간 낭비도 적다.
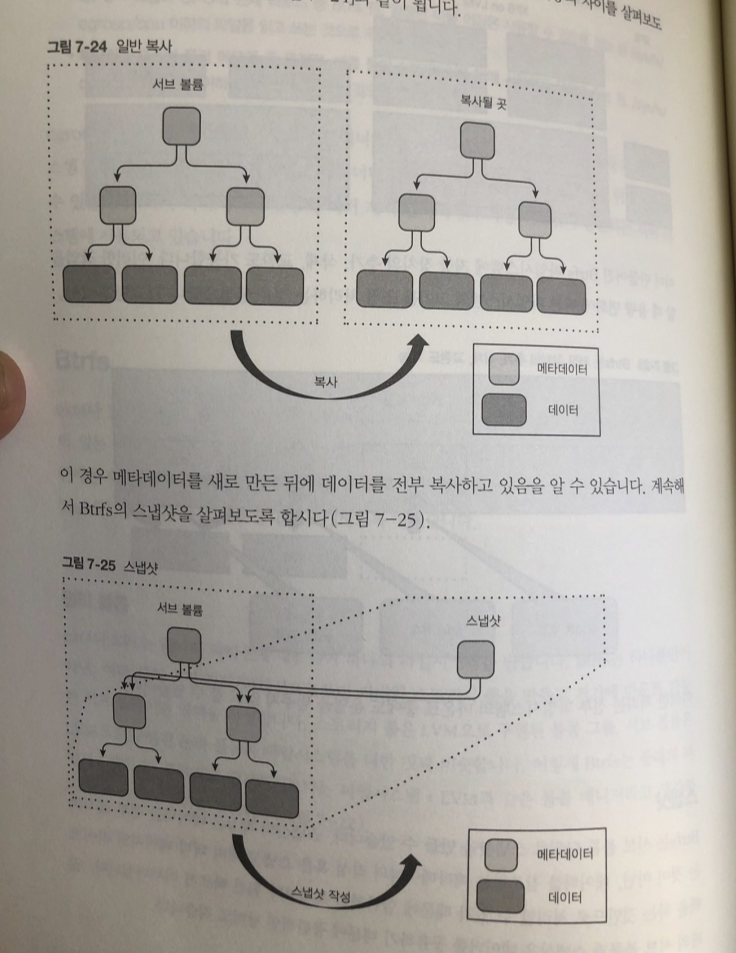
일반복사 vs 스냅샷 차이
root 노드만 새로 만들어 다음 레벨의 노드를 링크를 거는 걸로 끝남
데이터 복사는 발생하지 않기 때문에. 훨씬 고속으로 작성
RAID
btrfs에는 파일시스템 레벨에 RAID 작성을 포함
지원되는 것은
RAID 0 , 1 ,10 ,5 , 6
- dup(같은 데이터를 같은 저장 장치에 이중화,하나의 장치용 ) 이다.
어느 RAID 레벨로 설정되는지의 단위는 서브 볼륨이 아닌 Btrfs 파일시스템 전체다.
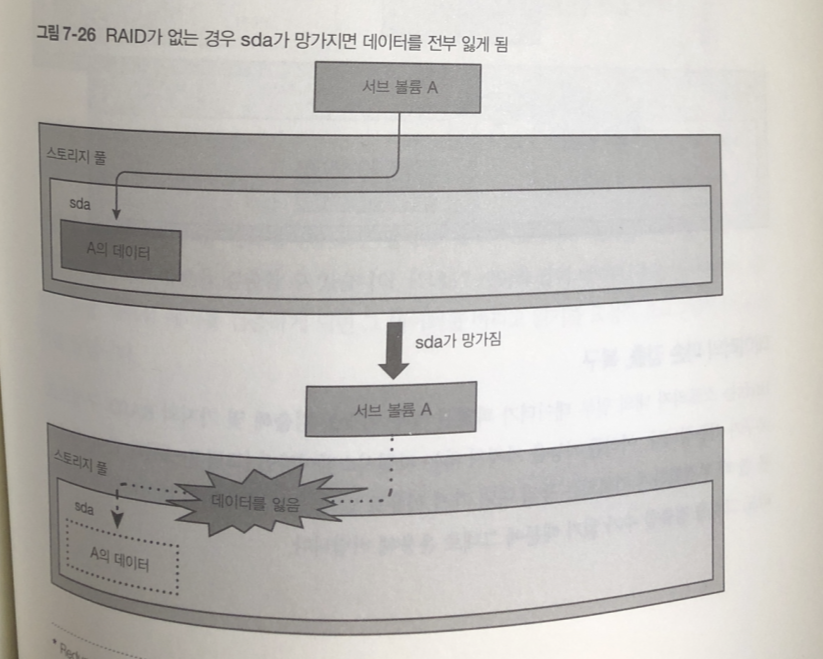

레이드가 있고 없고의 차이
데이터의 파손 검출,복구
Btrfs는 스토리 내의 일부 데이터가 파괴된 경우
검출해 몇가지 RAID 구성으로 복구 가능
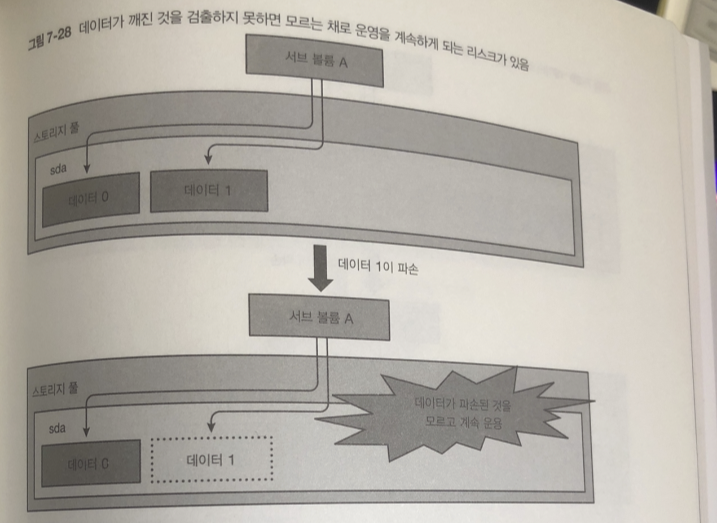
이러한 기능을 가지지 않는 파일 시스템이면 파괴되서 검출 할수 없음
반면
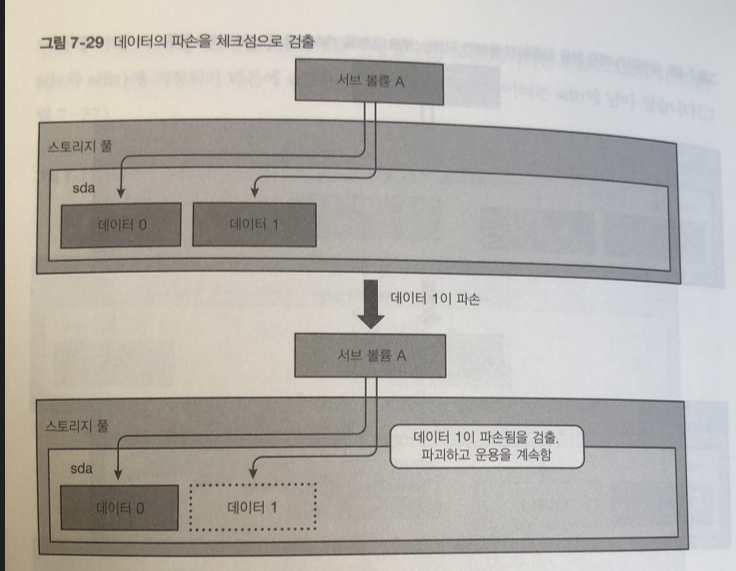
Btrfs는 데이터 , 메타데이터 모두 일정의 데이터 크기마다 체크섬을 가지고 있다.
데이터의 파손을 검출할 수 있음.
RAID 1 , 10, 5 ,6 dup의 구성이면 다른 체크섬이 일치하는 정확한 데이터를
기준으로 파괴된 데이터를 복구합니다.
RAID 5,6의 경우에도 패리티를 사용해서 같은것을 할 수 있다.
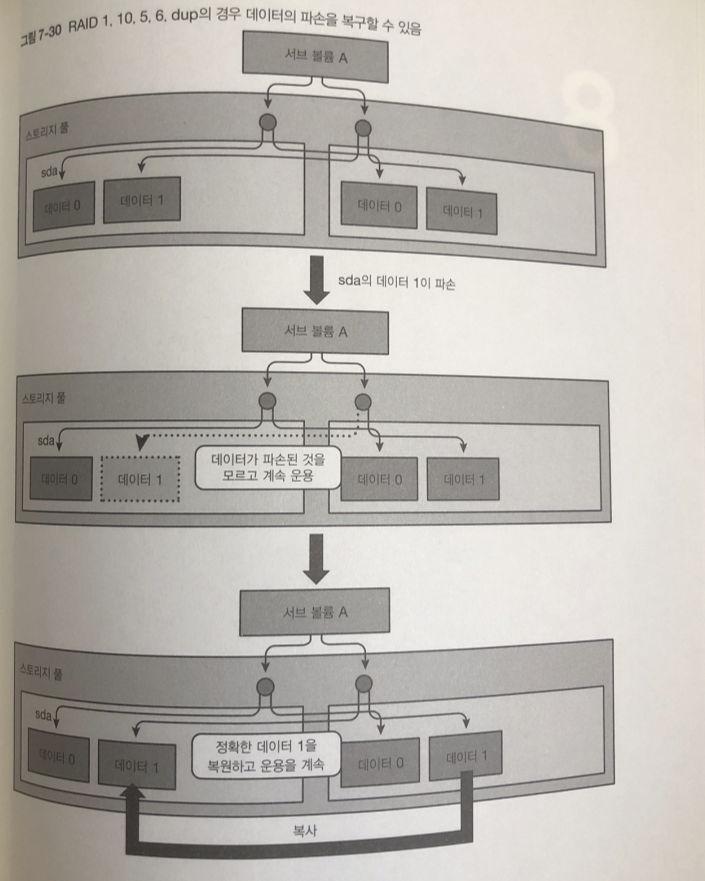
RAID 1로 구성된 복구 흐름
읽기 요청한 곳은 데이터가 일시적으로 깨졌음을 모르고 지나가게 됨.
ext4 나 XFS도 메타데이터에 체크섬을 넣음으로 깨진 메타 데이터를 검출하여
파괴하는 것은 가능하지만
메타데이터뿐 아니라 데이터의 파손도 검출하고 파괴 복구하는 기능을 가진
파일시스템은 Btrfs 뿐임
저장장치 8장
저장 장치와 관련된 커널에 기능에 대해 설명
HDD의 데이터 읽기 쓰기의 동작 방식
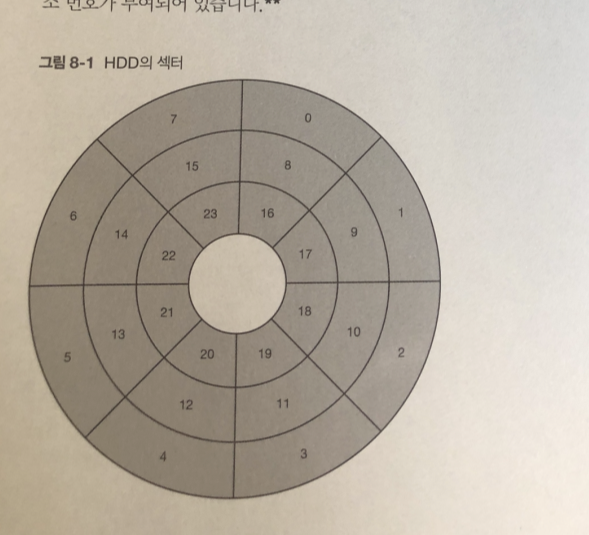
HDD는 데이터를 자기 정보로 변환하여 플래터라고 불리는 자기장치에 기록 하는 저장 장치
섹터라고 불리는 단위를 씀. 각각 주소 번호가 부여 되어 있다.
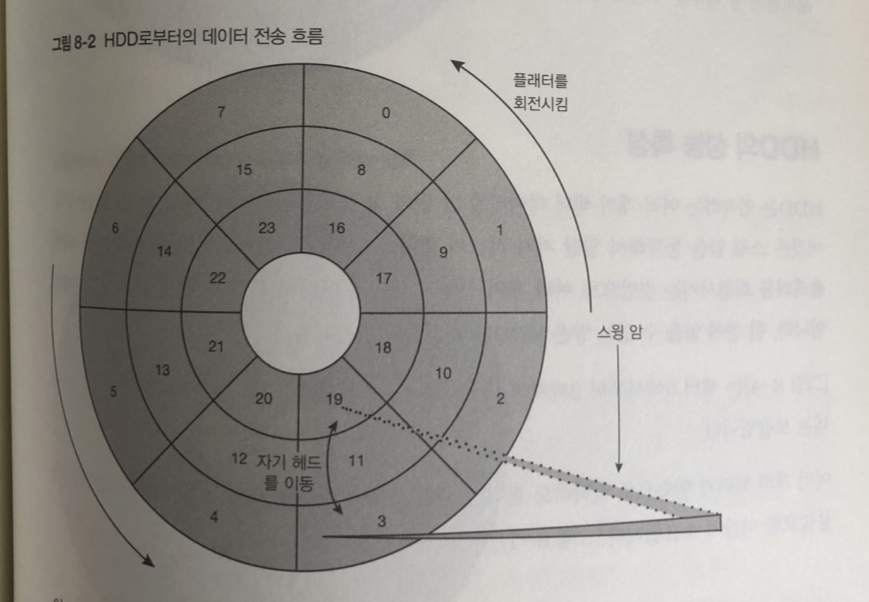
플래터의 각 세터 데이터는 자기 헤드라는 부품에 의해 읽고 쓰임.
자기 헤드는 스윙 암이라는 부품이 달려 있으며 스윙 암이 움직임으로써
자기 헤드를 플래터의 동심원 반경 반향으로 이동 시킴
플래터를 회전 시킴으로써 자기 헤드를 읽고 싶은 대상 섹터의 바로위에 오도록 함
HDD로 부터 데이터 전송 흐름
- 디바이스 드라이버가 데이터의 읽고 쓰기에 필요한 정보를 HDD에 전달.
섹터 번호 , 섹터의 개수, 그리고 섹터의 종류(읽기 쓰기 ) 등이 있다. - 스윙 암을 이동시키거나 플래터를 회전시켜 접근하고자 하는 섹터 위에 자기 헤드 를 위치 시킨다
- 데이터를 읽고 씀
- 읽을 경우 HDD의 읽기 처리가 완료된다.
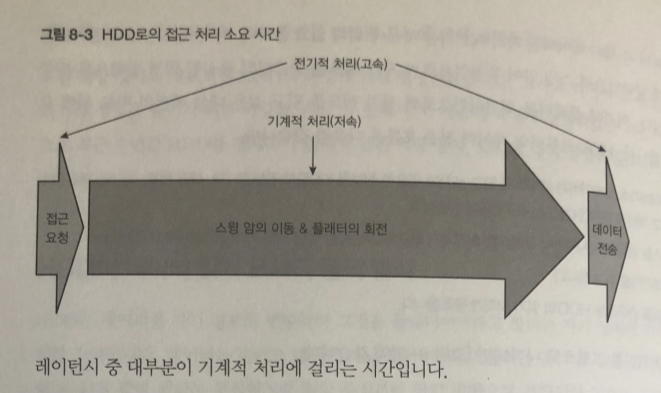
1 과 4는 고속 처리
반면 스윙 암의 동작 과 플래터의 회전은 훨씬 더 느린 기계적 처리.
-> HDD에 접근하는 레이턴시는 하드웨어의 처리 속도에 따라 영향을 받게 된다.
레이턴시가 많이 길어 짐.
HDD 성능 특성
HDD는 연속하는 여러 개의 섹터 데이터를 한 번의 접근 요청에 의해 함께 읽기 가능
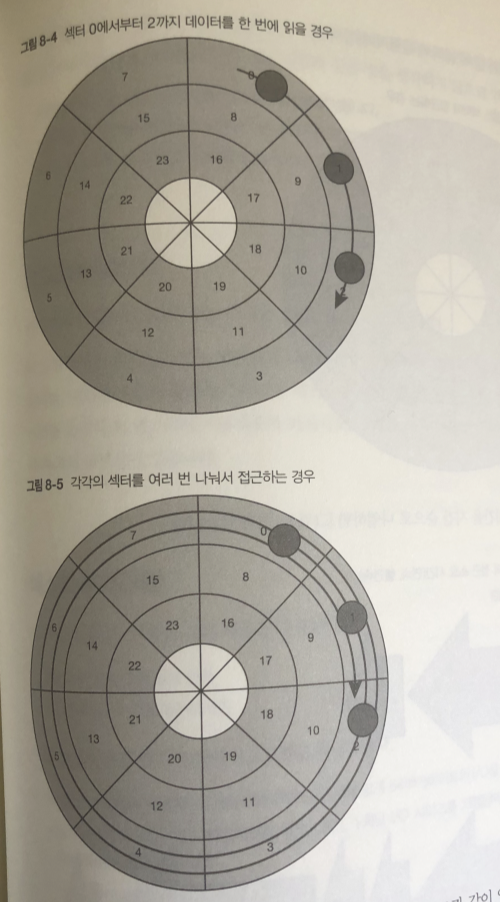
스윙 암이 동작하면서 자기 헤드 위치를 원하는 동심원에 맞추기만 하면
플래터를 회전 시키는 것만으로 여러 개의 연속된 섹터의 데이터를 한번에 읽을 수 있어서.
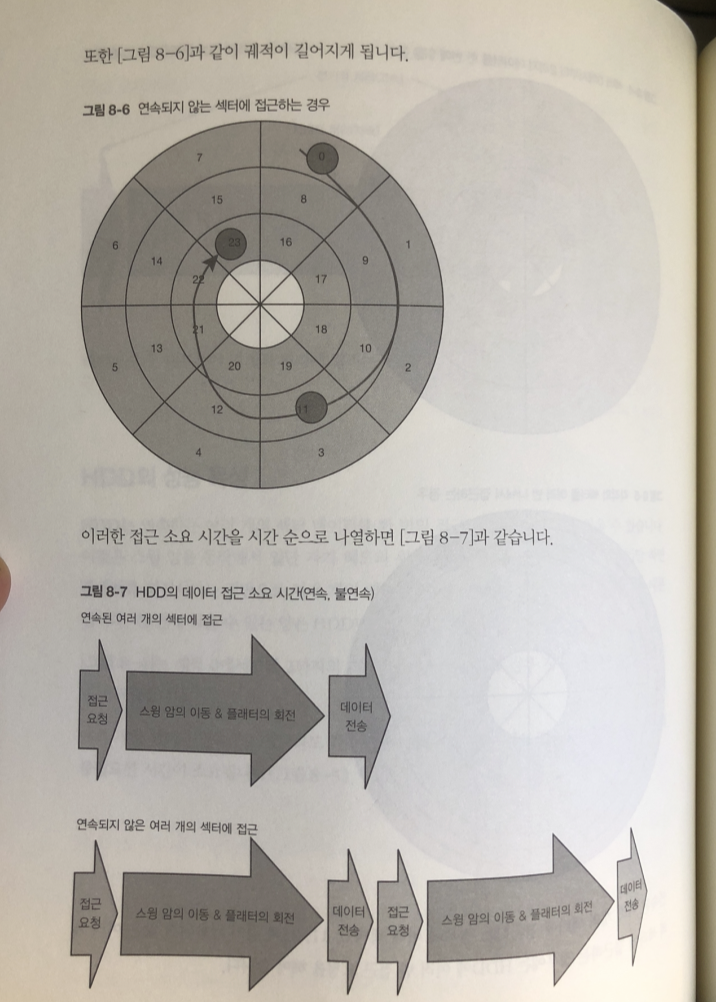
이러한 성능 특성 때문에 파일시스템은 각 파일의 데이터를 되도록 연속된 영역에
배치 되도록 함.
프로그램을 만들 때도 다음과 같은것을 생각 해야된다.
- 파일 내의 데이터를 연속으로 혹은 가까운 영역에 배치
- 연속된 영역에 접근할 때에는 여러 번 나누기보다 한 번에 하도록 한다.
- 파일은 되도록 큰사이즈로 시퀀셜하게 접근한다
HDD의 테스트
움익이고있는 데이터를 측정하기 위해 블록 장치의 데이터를 직접 읽도록 하자.
테스트 프로그램
I/O 사이즈에 따른 성능 변화
시퀀셜 접근과 랜덤 접근의 차이
프로그램 작성
-
지정된 파티션의 처음부터 1기가바이트까지의 영역에 합계 64 메가 바이트 I/O 요청
-
읽기와 쓰기의 종류, 접근 패턴(시퀀셜,랜덤 접근), 1회당 I/O 사이즈를 지정할 수 있게 한다.
1파라미터 : 파일명
2파라미터 : 이번 장 뒷부분에서 설명할 커널의 I/O 지원기능을 켜거나 끈다
3파라미터 : 읽기와쓰기의 종류 (r=읽기 , w=쓰기)
4파라미터 : 접근 패턴(seq=시퀀셜 접근, rand=랜덤 접근)
5파라미터 : 1회당 I/O 사이즈[KiB]




주의점
- open() 함수에 O_DIRECT 플래그를 넣으면 다이렉트 I/O 수행
이경우 커널의 I/O 지원기능을 사용하지 않을 수 있따- ioctl() 함수를 사용하여 지정한 장치에 대응하는 저장 장치의 섹터 사이즈 획득
- 저장 장치에 전달하는 데이터를 보관하는 버퍼
(소스코드상으로 buf변수)용 메모리 영역을 확보가히 위해
malloc() 함수가 아닌 posix_memalign() 함수라는 유사한 함수 사용
이 함수는 획득한 메모리의 시작 주소ㅡㄹ 지정한 수의 배수를 만들어 줌(정렬 함)
이렇게 하는 이유는 다이렉트 I/O 에 사용하는 버퍼의 시작 주소와 사이즈가
저장 장치의 섹터사이즈의 배수가 될 필요가 있어서.
4 . fdatasync() 함수를 사용하여 앞서 요청된 I/O 처리를 완료할 때까지
기다립니다. 그 이유는 다이렉트 I/O가 아닌 일반적인 I/O 일경우
write() gkatnsms I/O 요청한뒤 기다리지 않기 때문에.
빌드방법

시퀀셜 접근

/dev/sdb5 : 사용중
다음 파라미터로 데이터를 얻는다.

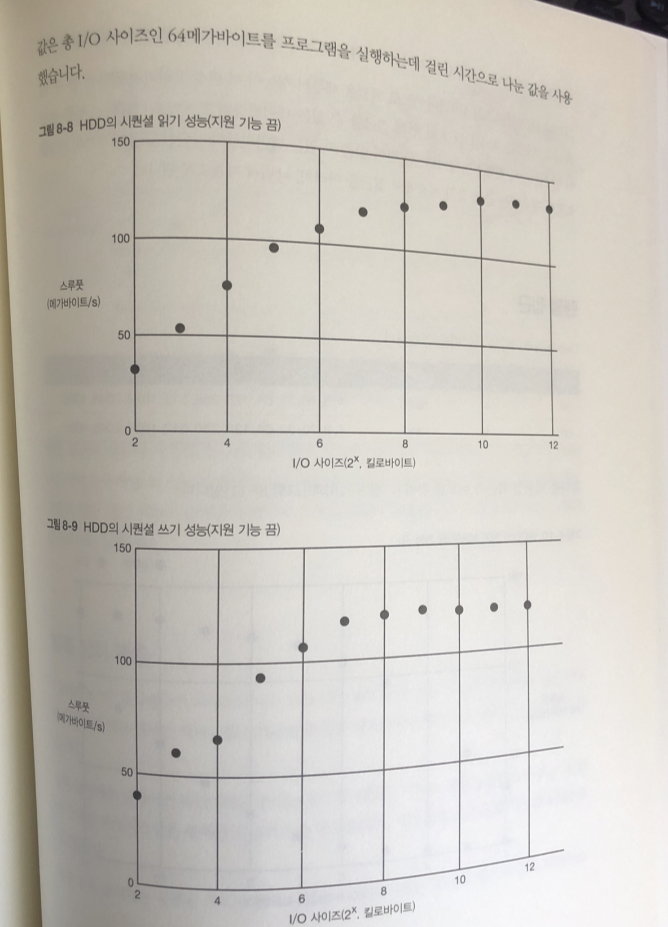
읽기와 쓰기에대한 그래프
읽기와 쓰기 모두 1회당 I/O 사이즈가 커질수록 스루풋 성능이 향상됨.
I/O 사이즈가 1 메가바이트로 되었을때 성능이 더이상 올라가지 않음..
이것은 HDD가 한 번에 접근할 수있는 데이터량의 한계
이때 스루풋이 HDD 최대 성능
한 번에 읽을 수 있는 데이터량의 상한선을 넘는 크기의 I/O를 요청한 경우에는
블록 장치 계층에서 접근을 여러번 나눠서 가져오게 됨.
랜덤 접근
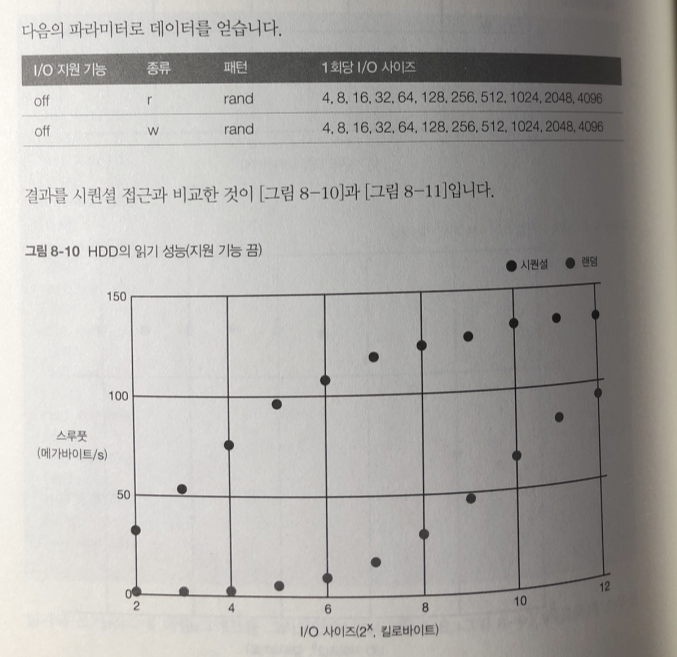

랜덤 접근은 시퀀셜 접근보다 성능이 전체적으로 떨어 진다.
특히 I/O 사이즈가 작을때 성능의 차이가 두드러짐.
I/O 사이즈가 커질수록 전체 프로그램의 접근 대기 시간이 줄어들기 때문에
스루풋 성능이 올라간다. 그래도 시퀀셜 보다 느림
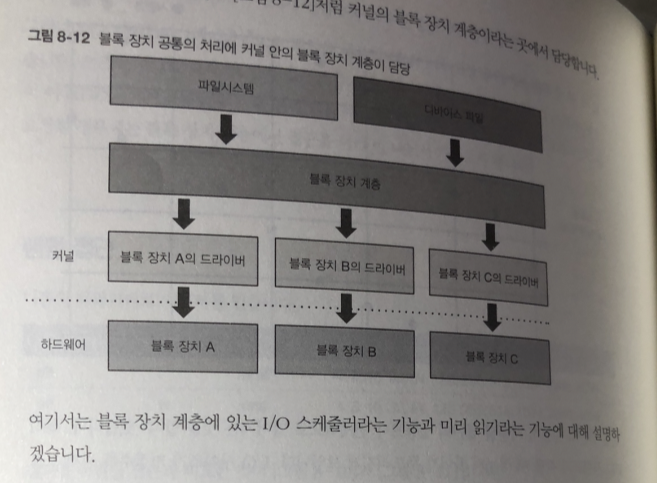
블록 장치 계층
HDD & SDD 등의 랜덤 접근이 가능하며 일정 단위로 (섹터)
접근 가능한 장치를 합쳐 블록 장치로 분류.
블록 장치에는 디바이스 파일이라고 불리는 특수한 파일을 가지고 직접 접근하던가.
그 위에 구축된 파일 시스템을 통해서 간접적으로 접근.
대부분 소프트웨어는 간접적으로 접근한다
각종 블록 장치에는 공통된 처리가 많기 때문에 이러한 처리는 각각의 장치에 대한
드라이버를 구현하지 않고 커널의 블록 장치 계층이라는 곳에서 담당
I/O 스케줄러
블록 장치 계층의 I/O 스케줄러 기능은 블록 장치에 접근하려는 요청을
일정 기간 동안 모아둔다.
그리고 다음과 같은 가공을 한 다음 디바이스 드라이버에 I/O 요청을 함으로서
성능을 향상시킨다.
병합(merge) : 여러 개의 연속된 섹터에 대한 I/O 요청을 하나로 모은다.
정렬(sort) : 여러 개의 불연속 적인 섹터에 대한 I/O 요청을 섹터 번호 순서대로 정리 한다.
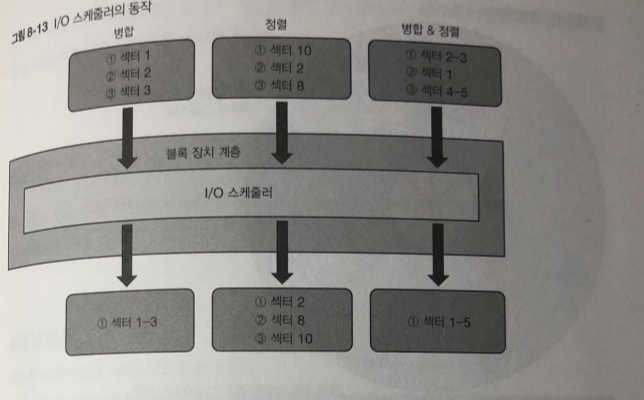
I/O 스케줄러 덕분에 사용자 프로그램을 만드는 사람이 블록 장치의 성능 특성에 대해
이해 할 필요 없이 어느 정도 성능이 나오게 되있음.
미리 보기
프로그램이 데이터에 접근할 때에는 공간적 국소성이라는 특징이 있다.
이 특징을 이용하기 위해서 블록 장치 계층에는 미리 읽기 기능이 있음.
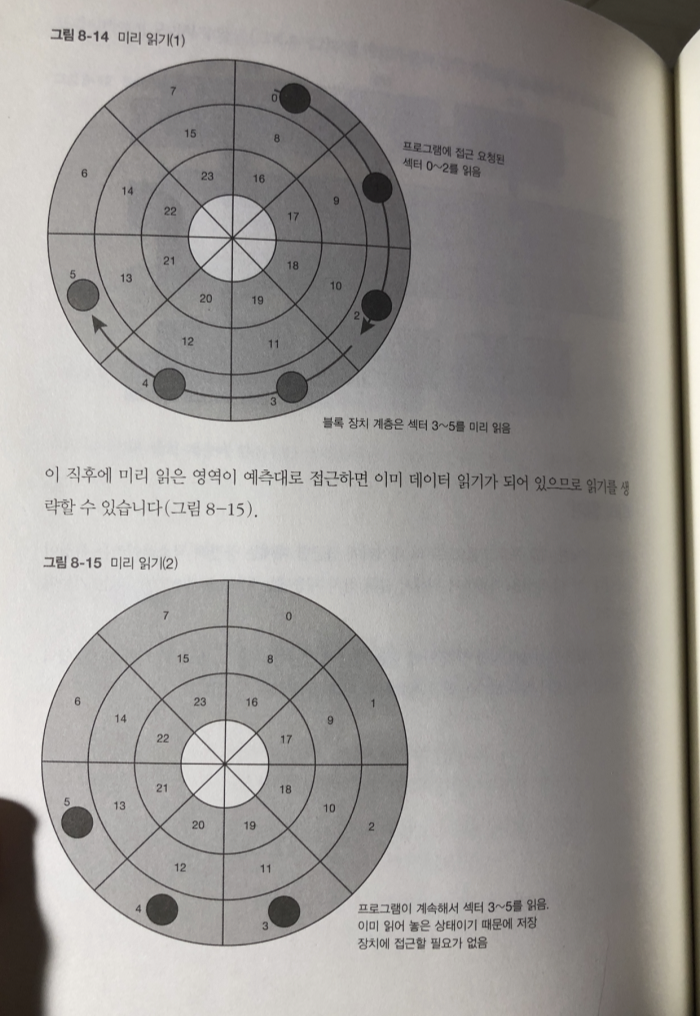
저장 장치에 안에 있는 영역에 접근한 다음 그 바로 뒤에 연속되는 영역에
접근할 가능성이 매우 크다는 점을 예측해 미리 읽어 둔다.
-> 이런 방법이 시퀀셜 접근의 경우 성능을 높일 수 있다.
예측대로 접근하지 않았을 경우 단순히 읽었던 데이터는 버림
테스트
여기서 I/O 지원 기능을 사용한 경우 I/O 성능을 확인하고
기능을 사용하지 않았을 때와 비교
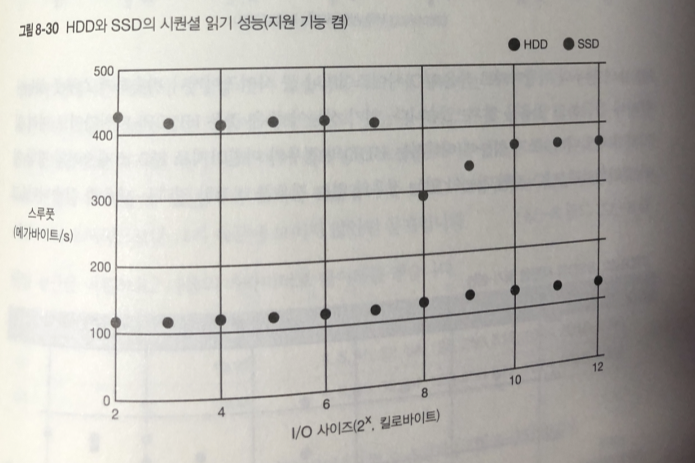
시퀀셜 접근
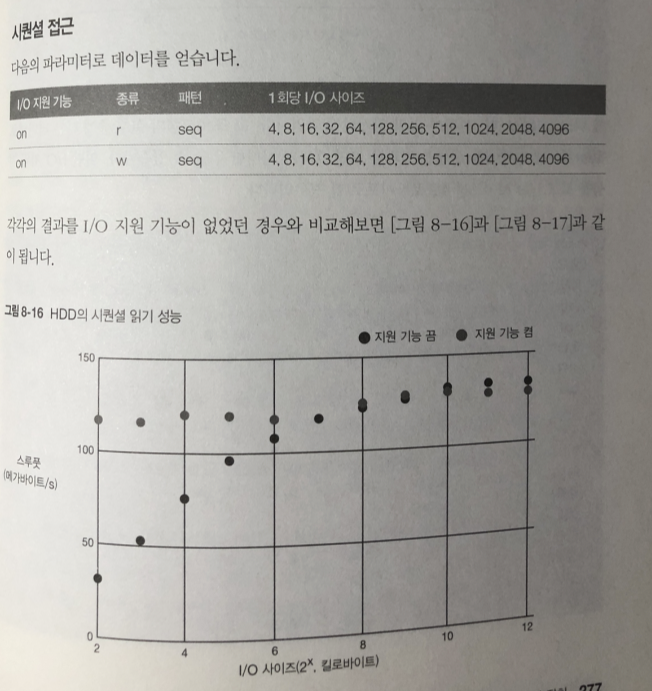
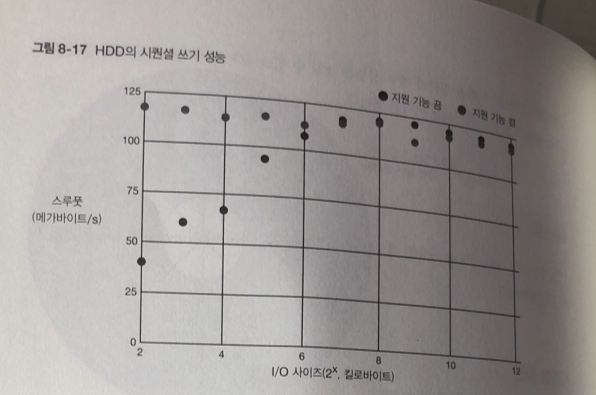
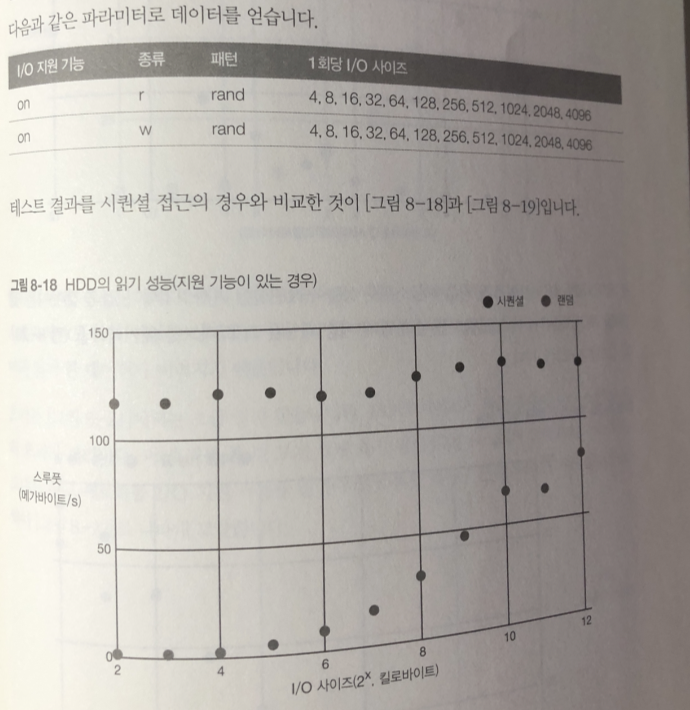
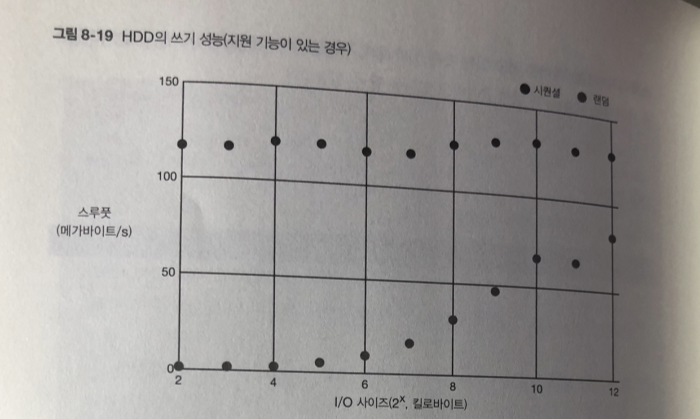
읽기 쓰기 모두 I/O 사이즈가 작은 시점 부터 스루풋 성능이 HDD의 한계까지
아슬아슬 하게 나오고 있다. 이것이 미리 읽기 효과
io 프로그램 실행중 'iostat -x' 명령어를 실행한 결과를 보면
효과가 어떤지 알 수 있다.
일단 지원 기능을 끄고 사이즈를 4킬로 바이트로 했을때 (I/O)

1~2 부분이 sdb가 I/O를 처리하고 있는 곳 약 3초정도 64 킬로바이트 읽고 있음

rkB/s 필드가 초당 읽은 용량을 의미한다.
지원 기능을 끈 상태와 켠 상태 두 가지를 비교해보면, 껐을 때는 여러 번에 걸쳐 읽어오고 켰을 때는 한번에 많이 불러오는 것을 알 수 있다. 즉 미리 읽기를 통해 데이터를 메모리에 미리 불러와서 스루풋 성능을 높이는 것이다.
rrqm/s 필드가 읽기 처리에 대한 병합 처리량이다. 읽기에 I/O 스케줄러가 동작하는 경우는 여러 프로세스로부터 병렬로 읽기를 하거나, 비동기 I/O 등이므로, 이 테스트 프로그램에서는 병합 기능이 동작하지 않는다.
wrqm/s 필드가 쓰기 처리에 대한 병합 처리량이다. 자잘한 I/O 쓰기 요청을 병합하여 일정 사이즈 이상이 되면 HDD의 실제 I/O가 수행되어 쓰기 처리를 고속화한다.
통계 데이터에서 실제로 병합해보면 어떻게 동작하나 살펴보자

스토리지가 I/O 처리를 하고 있는 것은 1~3의 부분이다.

스토리지가 I/O 처리를 하고 있는 것은 1과 2의 부분이다.
1에서는 I/O를 병합하고 있음을 나타내는 wrqm/s가 증가하고 있따.
랜덤 접근
두 경우 I/O 사이즈가 커질수록 스루풋 성능이 시퀀셜에 가까워 지다가
결국 같아 짐... 테스트 결과를 블록 장치 계층 기능을 끄고
비교한 데이터는 아래에 ..
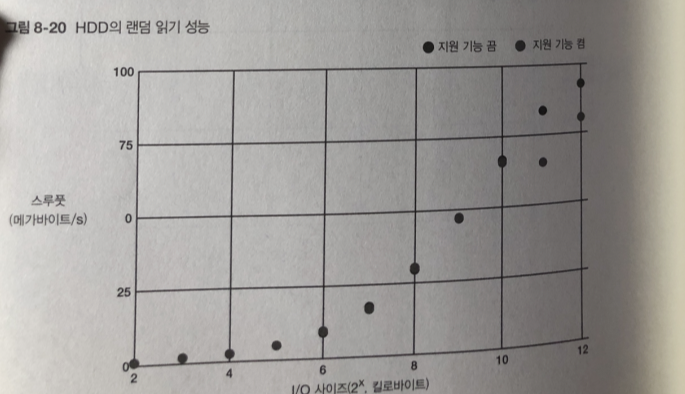

읽기 랜덤 접근은 거의 바뀌지 않고 있다.
이유: I/O 스케줄러가 동작하지 않아서 미리 읽기를 하더라도 시퀀셜 접근이
되지 않음으로 미리 읽기한 데이터가 버려지기 때문.
쓰기의 경우 I/O 사이즈가 작을 때 I/O 스케줄러의 효과가 있기는 하다.
즉 랜덤 접근 중에 우연히 접근 영역이 연속된 I/O 요청에 대해 병합이 발생한다.
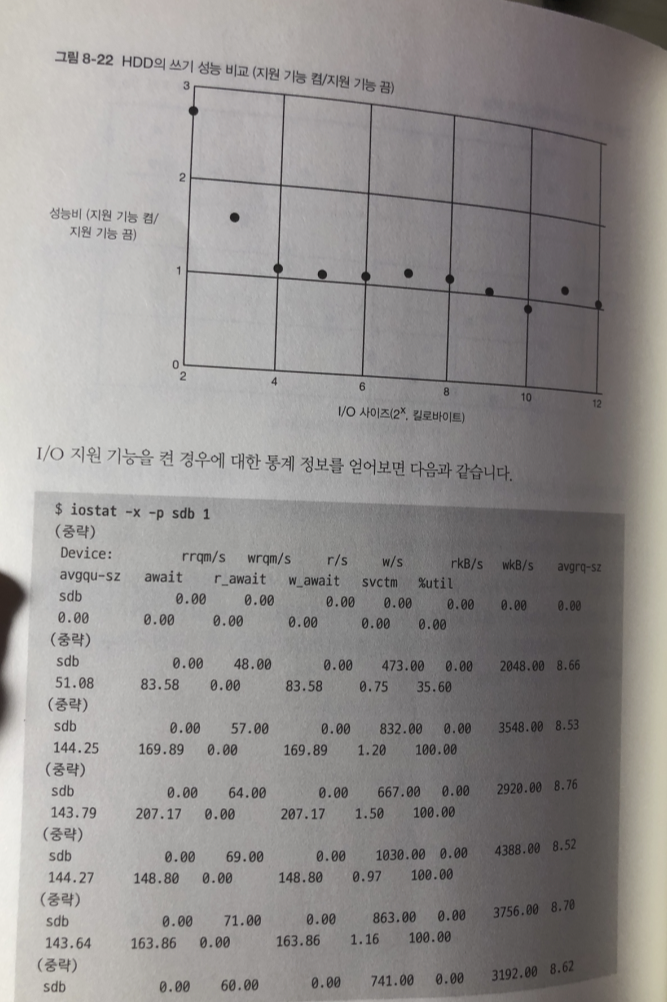

세로 축을 I/O 지원기능을 켠 경우의 스루풋 성능 / 끈경우 스루풋 성능 표현
시퀀셜의 경우 만큼은 아니지만 병합이 발생하고 있다
랜덤 접근 중 우연히 접근 영역이 연속해서 있는 I/O 요청이 병합된 결과
SSD의 동작 방식
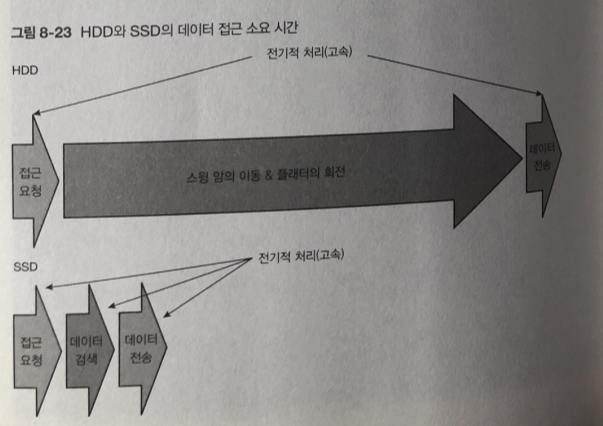
SSD: 데이터에 접근 하는 것이 전기적 동작만으로 이루어 짐.
이런 특징으로 랜덤 접근 성능도 HDD 보다 빠름
SSD의 테스트
시퀀셜 접근 (기능 끔)

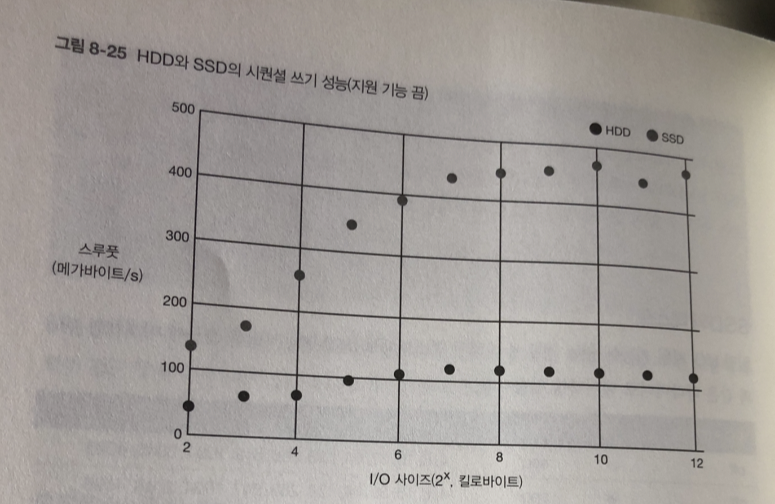
HDD 보다 몇배는 빠르다..
랜덤 접근 (기능 끔)


읽기와 쓰기 모두 I/O 사이즈가 클수록 스루풋 성능이 높아지는 건 HDD와 같다.
시퀀셜 접근때보다 더욱 큰 차이로 벌어짐..
I/O 가 적을 수록 더 두드러 짐.
랜덤 vs 시퀀셜 (기능 끔)
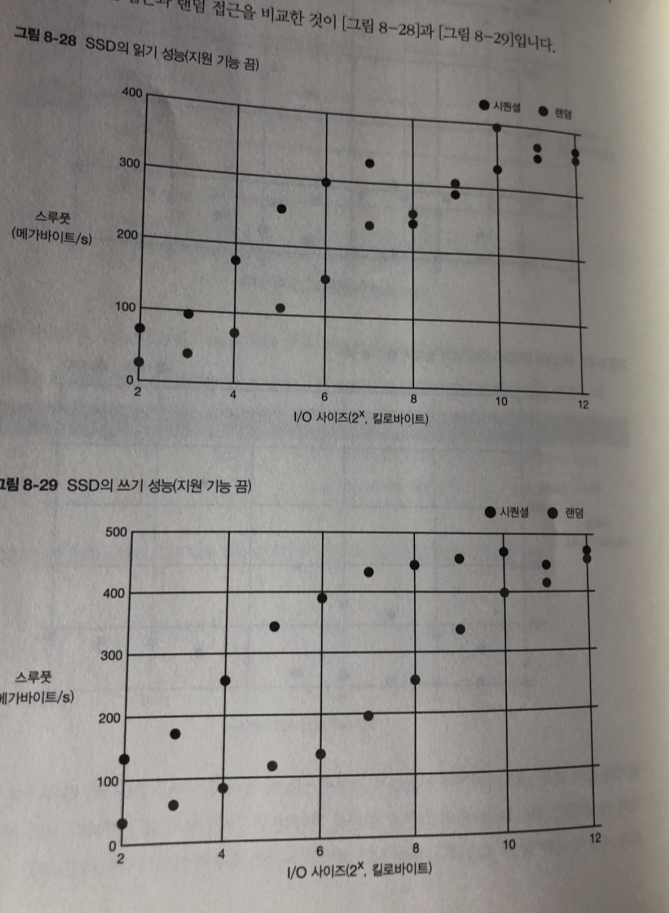
시퀀셜 접근과 랜덤 접근 비교
시퀀셜 접근이 랜덤 접근보다 성능이 더 높지만 HDD와 보다는 차이가 적다.
시퀀셜 (기능 킴)

미리 읽기에 효과로 스루풋 성능이 사이즈 관계 없이 한계에 접근.
쓰기의 경우도 I/O 스케줄러의 병합 처리 효과.
시퀀셜 (지원기능 on/off) 비교
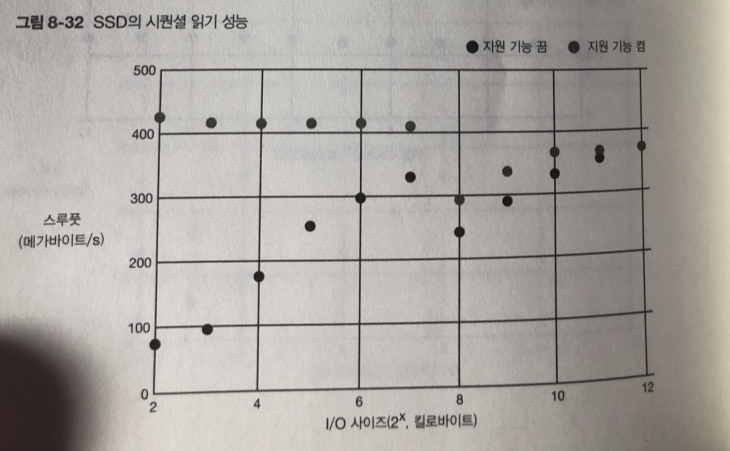
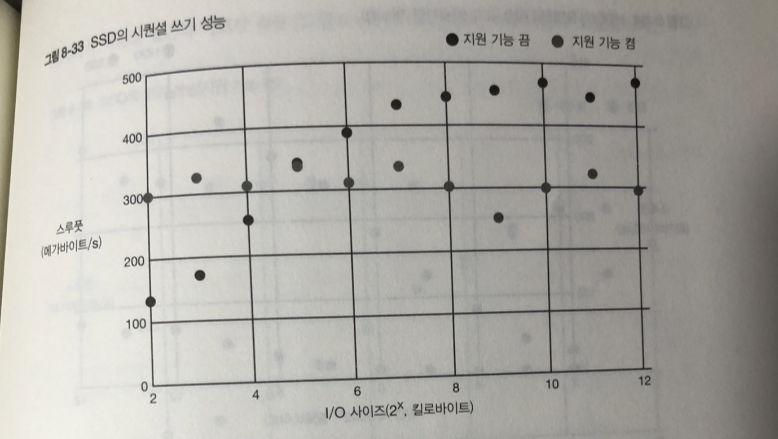
쓰기 경우 I/O 지원기능이 없는경우에 비해 오히려 있는경우가 스루풋이 더 낮다.
이유 : I/O 스케줄러의 처리를 하기 위해 여러 개의 I/O 요청을 모아 두었다가
처리하는 오버헤드가 SSD의 경우 무시할수 없는 부하가 되기 때문.
HDD에는 기계적 처리 소요시간이 더크기 때문에 보이지 않는 문제.
랜덤 접근 (기능 on)

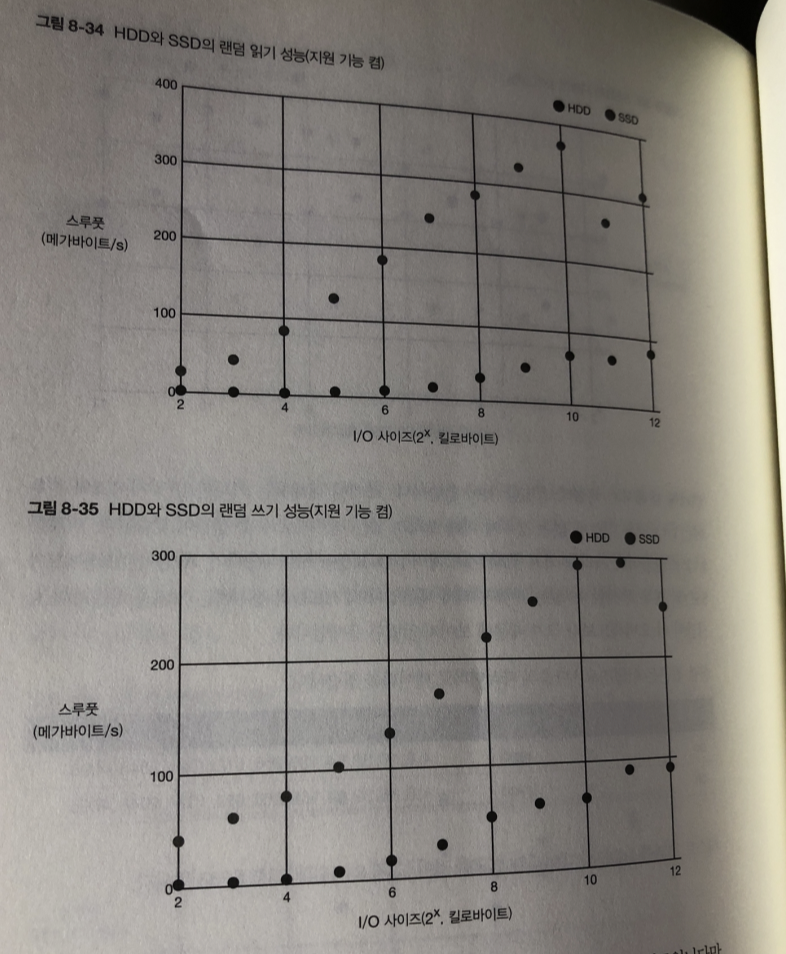
ssd 가 훨씬 좋다..
랜덤 접근 시퀀셜 비교
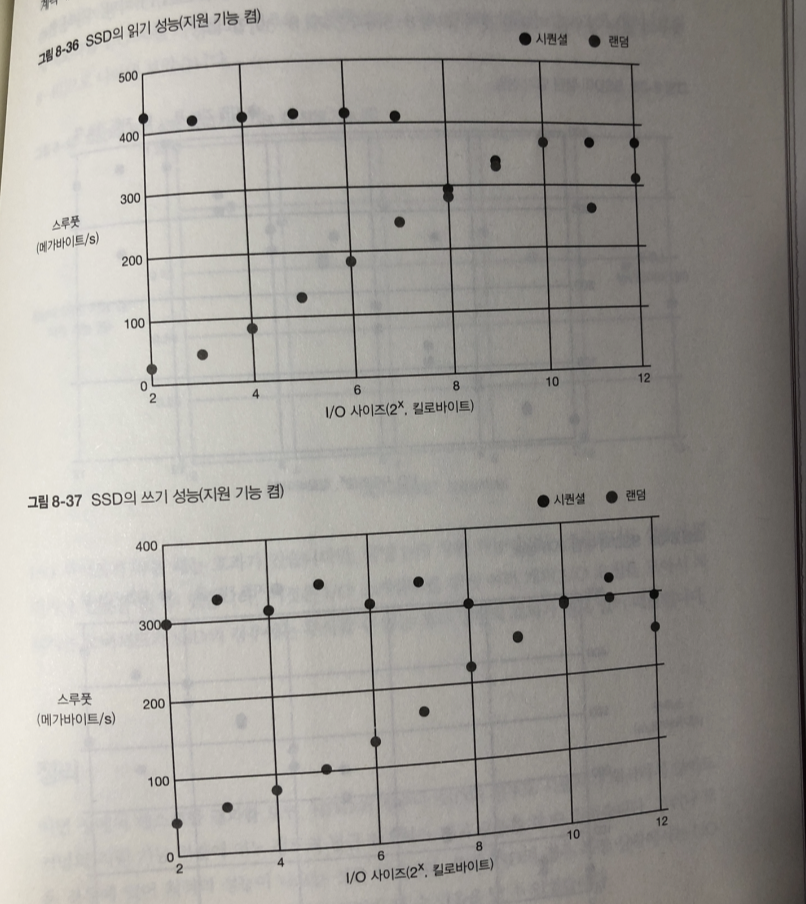
랜덤 접근 지원 기능(on/off)
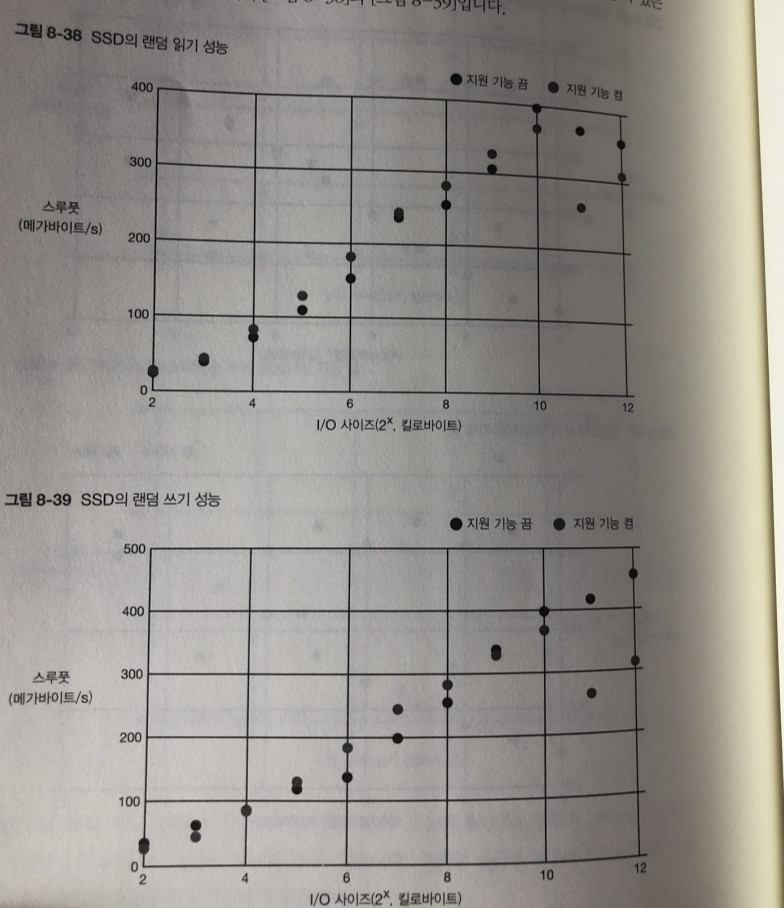
읽기 차이가 없다 HDD와 마찬가지로 미리 읽기도 I/O 스케줄러도 동작 안해서

조금 더알기 쉽게 새로 축변경
쓰기 경우 I/O 지원기능이 없는경우에 비해 오히려 있는경우가 스루풋이 더 낮다.
I/O 스케줄러의 처리를 하기 위해 여러 개의 I/O 요청을 모아 두었다가
처리하는 오버헤드가 SSD의 경우 무시할수 없는 부하가 되기 때문.
정렬의 효과가 별로 없기 때문.
정리
이번 장에서 테스트 결과를 보면
커널의 지원 기능 덕분에 접근 최적화가 되고있다.
그러나 모든 상황에 최적의 성능이 나오는건 아니다 (SSD)
전기적 신호때문에 빠른 결과 I/O 스케줄러에 의해 떨어 트려지니까.
소프트 웨어 만들 때 주의사항
- 파일 안에 데이터가 연속되도록 혹은 가까운 영역에 배치
- 연속된 영역에서 접근은 여러 번으로 나누기보다는 한 번에 처리
- 파일에는 되도록 큰 사이즈로 시퀀셜 하게 접근.
