컴퓨터 시스템 구성 3장
프로그램 실행시 하드 웨어 역할
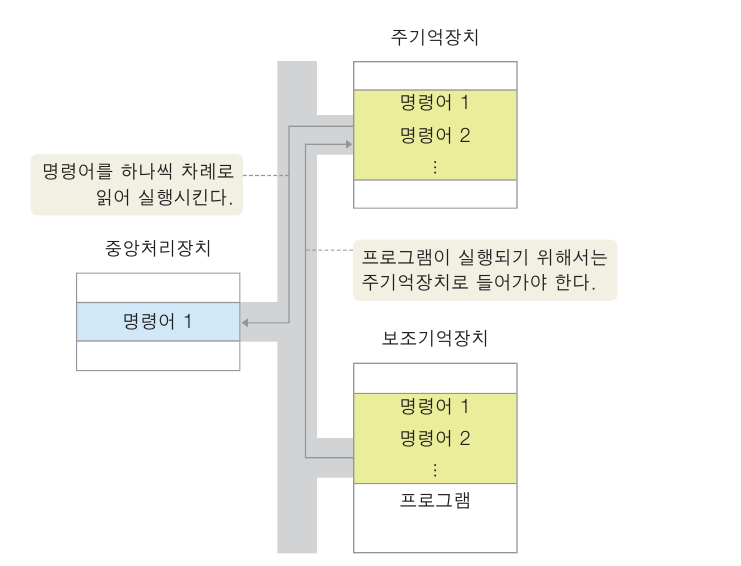
보조 기억 장치 -> 명령어 호출 -> 주기억장치로 이동
-> 중앙 처리장치에서 하나씩 명령어 읽어와 실행
중앙 처리 장치
제어장치
( 명령어 해독 -> 연산 장치 주기억장치, 입출력장치 동작 지시)
연산장치
( 제어장치의 지시에 따라 연산 수행)
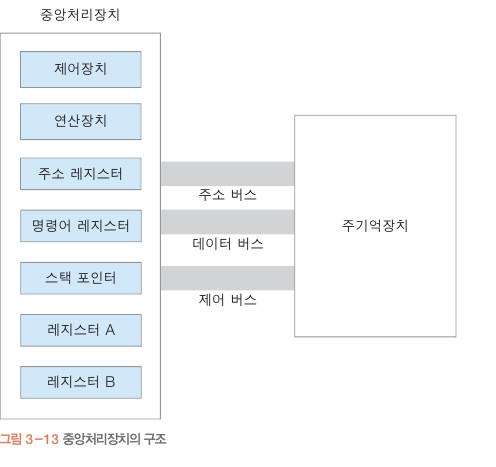
레지스터
(명령어 실행시 필요한 정보 저장)
레지스터 종류
-
주소 레지스터 : 다음 실행될 명령어가 저장된 주기억장치 주소 저장
-
명령어 레지스터 : 현재 실행 중인 명령어 저장
-
스택 포인터 : 주기억장치 스택의 데이터 삽익 삭제가 이루어 지는 주소 저장
-
레지스터 A/B : 명령어 실행 중에 연산과 관련된 데이터 저장
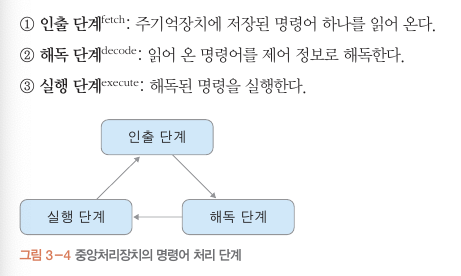
중앙처리장치의 명령어 처리 단계
주기억장치
전체 기억 공간은 분할 되어 있고 각 주소가 할당 되 있음.
동작
읽기: CPU가 주기억장치에 데이터 저장
쓰기 : CPU가 주기억장치 데이터 읽기

쓰기
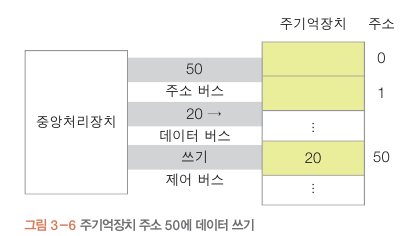
50 주소에 20 데이터를 쓰기..
읽기
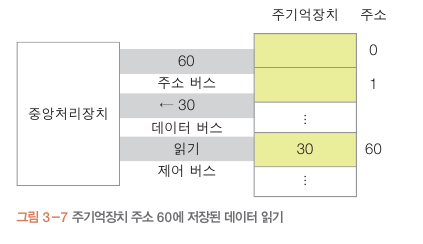
60 주소에 30 인 데이터 읽기
주소 버스 : 50 / 60
제어 버스 : 쓰기 / 읽기
데이터 버스 : 20/ 30
컴퓨터 시스템의 동작
부팅
바이오스 실행
롬에 저장된 바이오스 실행 -> 그래픽 카드 초기화 및 장치 상태 검사 -> 보조기억 장치의 부트 섹터에 저장된 부팅프로그램 메모리로 이동
부팅 프로그램 실행
CPU가 부팅 프로그램 실행 (주기억장치에 있는)
부팅 프로그램은 운영체제를 찾아 주기억 장치로 이동
운영체제 실행

프로그램 실행

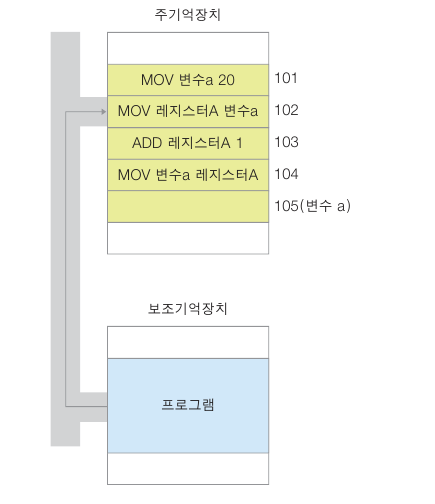
프로그램 실행 명령을 내리면 보조기억장치 -> 주기억장치로 이동
빈공간에 저장 됨.
결과 :

크게 일정한 흐름을 벗어나지 않는다.
- 주소 레지스터 에 주소 저장
- 해당 주소에 명령어 읽어서 명령어 레지스터에 저장
- 명령어 레지스터 실행
- 주소값 +1
- 명령어에 따라 레지스터 A/B 저장
순차적으로 반복.
프로그램 명령어
명령어의 기본 형식과 종류
cpu는 명령어를 읽어와 실행

연산 코드 : Cpu가 실행해야 할 동작을 나타냄 (And,OR,더하기등)
피연산자 : 동작에 필요한 값 또는 저장공간(레지스터 또는 주기억장치 주소)

cpu에 따라 피연산자 개수는 차이가 있는데 이책에선
두 개위 주로.
cpu가 제공하는 명령어 분류
데이터 전송 명령어 :
- 레지스터 또는 주기억장치 데이터를 레지스터 또는 주기억 장치로 이동.
-
[10],[50] 대괄호로 감싸고 있는 것은 주기억 장치 의미
10은 주소가 10인 부분.
연산 명령어 : 더하기 빼기 나누기 같은 논리연산 레지스터에 저장된 비트를 이동시키는 시프트를 수행한다.
분기 명령어 : 다음에 실행될 명령어 지정
데이터 전송 명령어

스택
삽입 삭제가 한쪽으로만 일어나 가장 최근에 삽입된 데이터가 먼저 삭제됨
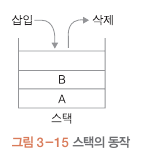
push : 데이터 넣기 / pop : 데이터 꺼내기

스택포인터는 여기서 사용되는군..
push 명령어를 사용하면 스택 포인터가 1 이 더해진다
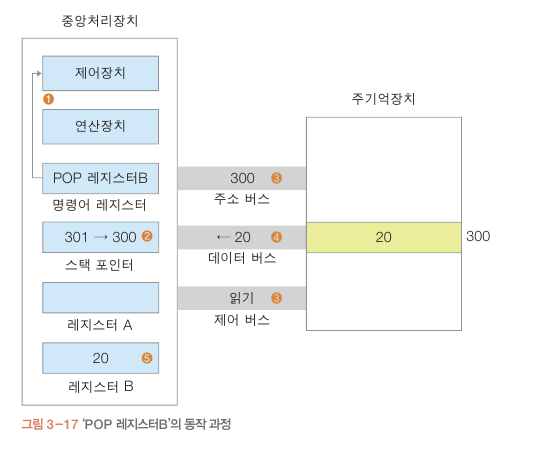
pop 은 스택포인터가 1이 감소 한다.
시프트 데이터
시프트 명령어는 레지스터에 저장된 데이터의 비트 이동 시킴.

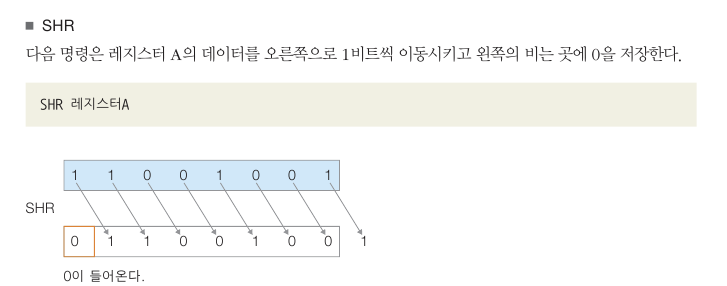
SHL 도 반대로 하면 됨.
CIR / CIL
오른쪽 왼쪽으로 비트를 이동시킨다음 벗어나는 비트가 제일
왼쪽으로 온다
분기 명령어
JUMP / CALL 바로 아래 위치한 명령어가아닌
다른 위치로 명령어로 분기를 시킴
JUMP : 특정 주소로 분기 할때
원래 동작은 주소 레지스터를 +1 만큼 증가하는 거지만
ex) JUMP [100] 게되면 다음은 100 번째
주소에 있는 명령어를 실행 한다.
CALL: 다른위치로 잠시 분기 했다가 다시 돌아올때 사용

스택 영역에 현 주소를 저장하고. (스택 포인터 +1)
100 번째 주소를가 명령어를 실행한다.
Return 은 함수의 끝이 므로
CALL[100] 다음 주소의 명령어를 실행하라는 뜻임.
-> 스택 포인터 1 감소 -> 주소 51 주소 레지스터에 저장
-> 주소 51 명령어 실행
운영체제
기능
사용자 인터페이스 제공 / 컴퓨터 자원 관리
컴퓨터 시스템 자원 관리
운영체제는 주기억장치의 어느 영역이 비어있는지 확인 뒤
보조 기억장치에 저장된 프로그램을 주기억 장치로 옮김
(CPU는 메모리에 저장된 프로그램과 데이터를 처리 할 수 있으니)
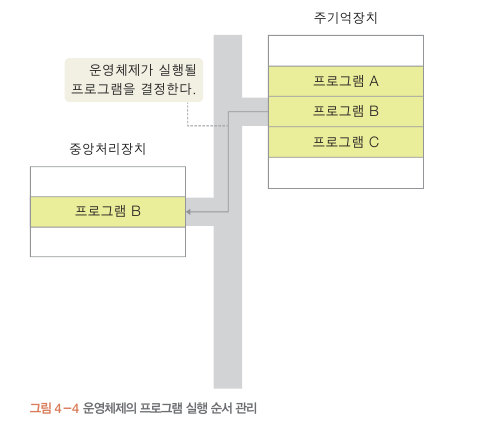
CPU가 어떤 프로그램을 먼저 실행시킬 지도 담당
프로세스 관리
프로세스 개념
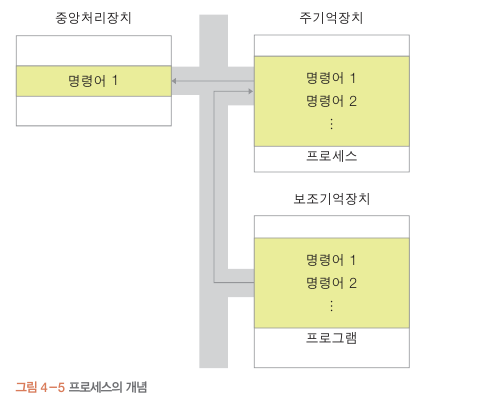
프로세스란?
주기억장치로 올라간 프로그램을 말한다.
(실행중 인 프로그램)
실행에 필요한 다양한 정보가 포함 됨.
PCB (프로세스 제어 블록)
프로세스에 대한 정보를 저장하는 장소.
프로세스 생성 -> 프로세스 제어 블록 생성

프로세스 상태 : 실행 상태 OR 준비 상태 등 현태 상태
주소 레지스터 값: CPU의 주소 레지스터라는 레지스터에 저장된 값
다음에 실행 될 명령어 주기억장치 주소 저장
스케줄링 정보 : 다음에 실행될 프로세스 결정하는데 필요한 정보
프로세스 스케줄링 정책, 우선순위등 저장
주기억장치 정보 : 해당 프로세스스가 주기억장치의 어느영역에 있는지 나타냄
프로세스 상태
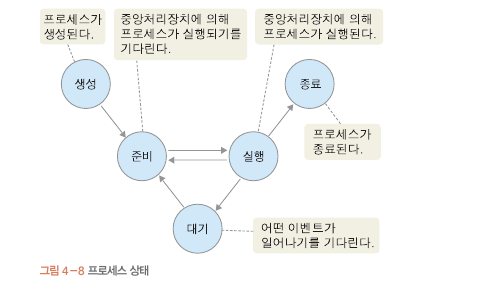
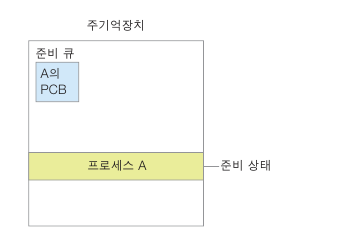
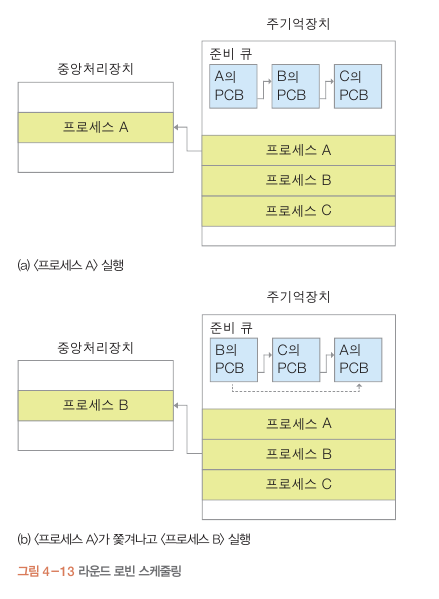
새로운 프로세스 A가 생성 되면 A의 PCB 가 준비큐에 연결됨.
준비큐 : 준비 상태에서 실행을 대기하는 프로세스의 모임
CPU에서 할당을 받으면 삽입 순서대로 빠져나감
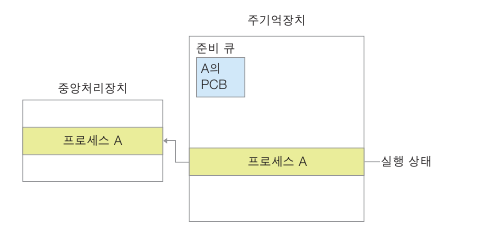
CPU에 할당 받아 실행. PCB의 일부 정보가 CPU레지스터에 저장 됨 이 상태를 실행 상태라 한다.
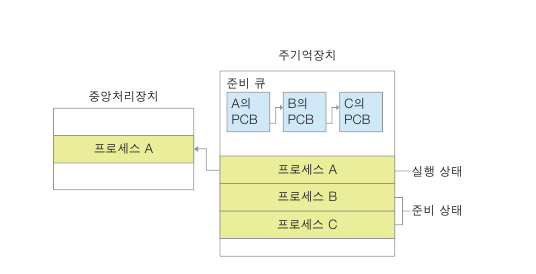
프로세스 B , C가 생성 되었다. 프로세스 B , C가 준비큐 에서
어떻게 실행 될까?

1번째 프로세스 A가 종료 될때. 그다음 프로세스B가 선택되서 실행
상태로 바뀐다. (준비큐에 삽입 순서대로)

2번째
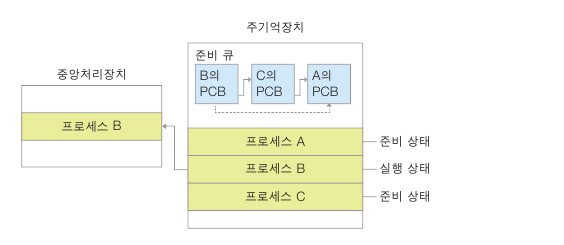
프로세스 A가 너무 오랜시간 차지하는 경우
이때 프로세스 A를 잠시 중단하고(준비) 준비큐에 프로세스 A PCB를 맨뒤로
그다음 프로세스 B를 실행한다. (PCB 가장 앞에 위치시킴)
이때 CPU에 일부레지스터에 저장되는 프로세스 A의 정보를
프로세스 A PCB가 저장하고
프로세스 B PCB 일부 정보를 CPU의 레지스터에 저장 함
이러한 동작을 문맥 전환(context switch)
ex) 주소 레지스터 값
3번째
프로세스 A가 대기 이벤트가 발생한 경우
프로세스가 디스크 입출력 명령어를 발생하면 입출력이
완료될때까지 CPU는 아무일도 하지못한다. sleep 포함
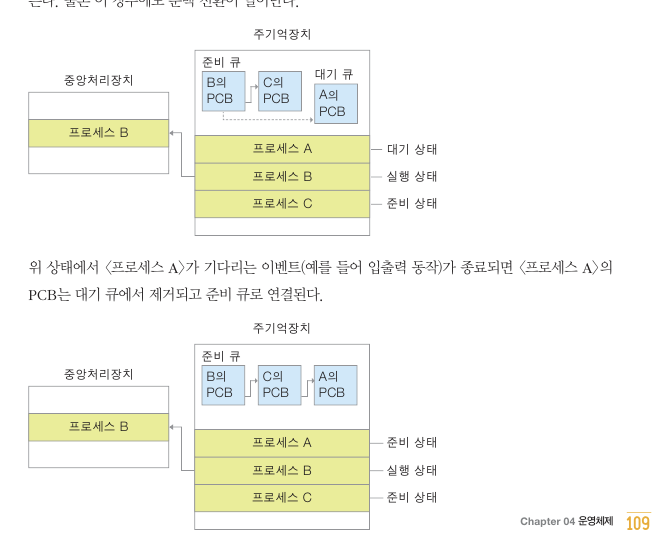
그래서 프로세스 A가 준비큐에서 대기큐로 (대기)
프로세스 B를 실행
문맥전환이 일어남.
프로세스 스케줄링
한번에 여러 개의 프로세스 실행 이용률 최대화
-> 다중 프로그래밍
다음은 어떤 프로세스를 실행할지 ??
FCFS 스케줄링
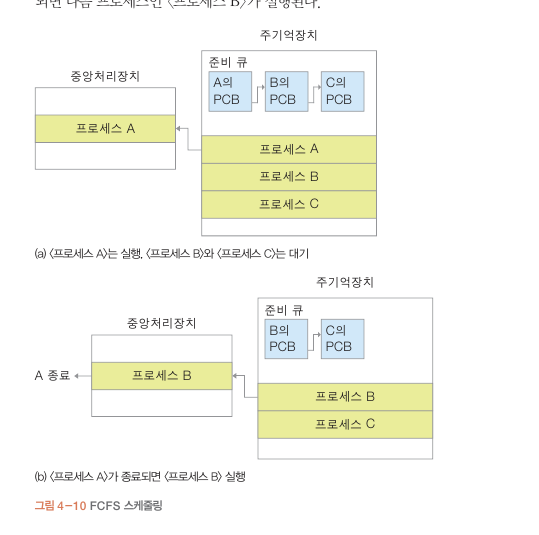
먼저 도착한 프로세스 먼저 실행.
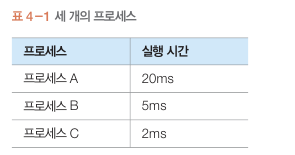
평균 대기 시간을 구해보면..
0 + 20 + 25 / 3 = 15
A -> B -> C 순서대로 실행시
(맨 마지막 프로세스 C가 실행하기까지 걸리는 시간)
C -> B -> A
2 + 7 + 0 / 3 = 3
라운드 로빈 스케줄링
여러 프로세스들이 CPU를 조금씩 돌아가며 차지
대부분의 시스템이 이방식을 쓴다.
프로세스들은 일정한 시간 할당량을 CPU로 부터 받아
실행하고 종료하지 못하면 준비 상태로 쫒겨나고 다음 준비큐
프로세스를 실행한다.
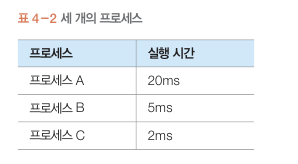
시간할당량이 4ms일때 평균 대기시간은?

7+10+8 /3 = 8.3
(문맥 전환 시간 고려X)
시간 할당량의 크기가 성능에 큰영향을 미치기때문에
적절한 시간 할당량은 10~100ms이다
우선순위 스케줄링
높은 우선순위 프로세스를 CPU에 할당
우선순위가 같으면 FCFS 스케줄링..
프로세스 우선순위는 프로세스 실행자의 직위
또는 프로세스의 중요성에 의해 결정되며 PCB에 저장됨.
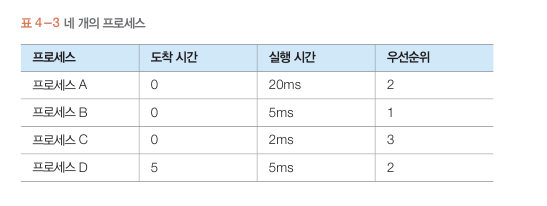
평균 대기시간 : 0 + 5 + 20 + 30 / 4 = 13.75
우선순위가 낮으면 오랫동안 실행되지 않는 문제가 발생
이런 경우 에이징이라는 해결 책이 있는데
일정시간 동안 실행되지 않으면 우선순위를 한 단계씩
높이는 방법.
주 기억 장치 관리
단일연속 주기억 장치

운영체제 외 하나의 사용자 프로그램만 저장
분할 주기억 장치

현재 컴퓨터 시스템 방식
여러 개의 프로세스를 주기억장치에 저장후 실행
가상 메모리의 개념
프로그램이 실행되기 위해선 보조기억장치 -> 주기억장치로 올라가야됨
그러나 주 기억장치 공간이 부족하면 실행 안됨
해결책: 당장 실행에 필요한 부분만 주기억 장치
나머지는 보조기억장치에 두고 동작
페이징
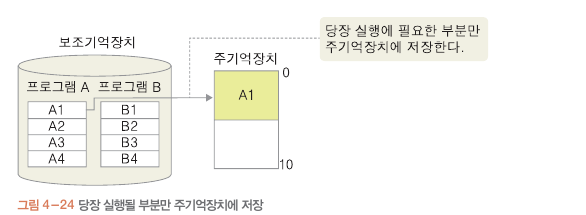
크기가 20인 프로그램 A 와 B
프로그램을 일정한 크기로 나누었는데
이런 단위를 페이지 라고 한다.
페이지 단위를 주 기억장치에 올려 동작하는 것이 페이징.
이때 실제 주기억장치의 페이지에 해당되는 부분을 프레임이라 함.


운영체제는 프로세스마다 각 페이지가 주기억장치
어디 프레임에 저장되는지 나타내는 테이블을 관리하는데
이 테이블이 페이지 테이블 이다.
임의의 페이지가 실행할때 -> 주기억장치 페이지 탐색
-> 보조기억 장치 페이지를 주기억장치 프레임에 저장한 후
접근
페이지 교체 알고리즘
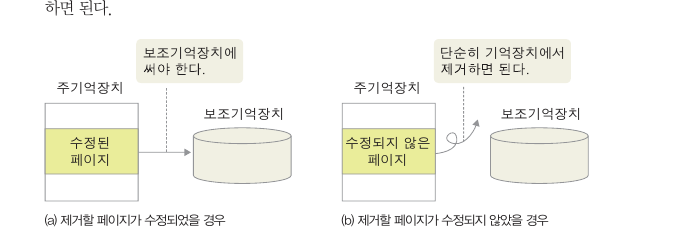
새로운 페이지를 주기억장치에 저장할때 페이지 프레임이없으면
주기억 장치에서 제거할 페이지를 결정해야 함.
이런 동작을 페이지 교체 라고 함.
제거할 페이지의 내용이 주기억 장치에 수정되었으면
보조기억장치에 수정된 사항을 반드시 써줘야 하고
수정되지 않았따면 단순히 주기억장치에 제거하면 된다.

ex) FIFO , LRU , LFU
FIFO

가장 먼저 올라온 페이지를 제거 하는 방식
LAU
주기억 장치에 올라온 페이지 중 가장 오랫동안 사용하지 않는
페이지 교채

LFU
사용빈도가 가장 낮은 페이지 제거

파일관리
파일 시스템의 이해
파일 저장 - > 운영체제가 보조기억장치에 저장
윈도우의 파일 시스템
FAT / NTFS /
FAT의 구조
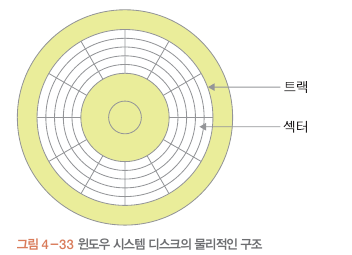

트랙 : 동심원
섹터 : 동심원의 조각
시스템 영역: 디스크와 데이터 영역에 중요한 정보를 저장하는 곳
부트 레코드 : 컴퓨터를 처음 켰을때 동작하는 프로그램 저장
이 프로그램은 디스크에 저장되있는 운영체제를
주기억장치로 올리는 역할
파일 할당 테이블 : 데이터 영역의 어느 부분이 사용 되고 있는지 나타냄
오류 발생시 다른 파일 할당프로그램을 이용하기 위해 테이블 2개가 있다.
루트 디렉토리: 디스크에 저장된 파일에 대한 정보를 보관하는 곳
파일이름,파일확장자 ,기록시간날짜 등..
파일 속성을 의미, 루트
데이터 영역: 일반적인 파일과 서브 디렉토리 저장하는 영역
클러스터 단위로 관리함.
클러스터는 몇개의 섹터로 이루어짐
FAT의 동작과정
클러스터 크기는 : 1000바이트
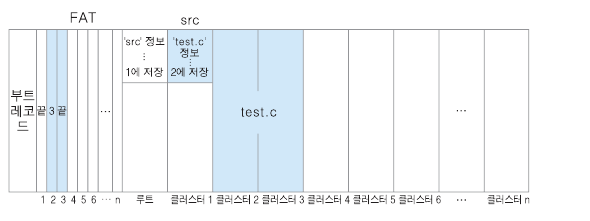
클러스터1 에 src 디렉토리 만들고. 이에 대한 정보는
루트 디렉토리에 저장 함. 저장 정보중 파일 시작 클러스터 번호인 1 도 포함 의미없는 값인 끝도 포함

test.c 파일 생성. 두개의 클러스터가 필요 함으로 (1500바이트)
클러스터 2~3에 저장 . test.c 에 대한 정보는 src에 저장

결론 ..
유닉스(리눅스)의 파일 시스템
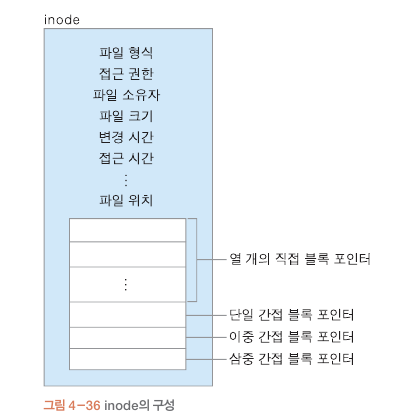
부트 블록: 운영체제를 주기억 장치의 올리는 역할
수퍼 블록: 디스크에 대한 다양한 정보 저장하는 곳.
전체 블록의 수 , 크기, 등..
inode 리스트 : innode 모아 놓은 곳
데이터 블록 : 일반적인 파일과 디렉토리 간접 블록 저장 영역

직접 블록 포인터에는 파일이 저장된 블록번호 저장
간접 블록 포인터에는 블록 번호들을 모아놓은 블록번호들을 저장
유닉스(리눅스) 파일 시스템 동작 과정
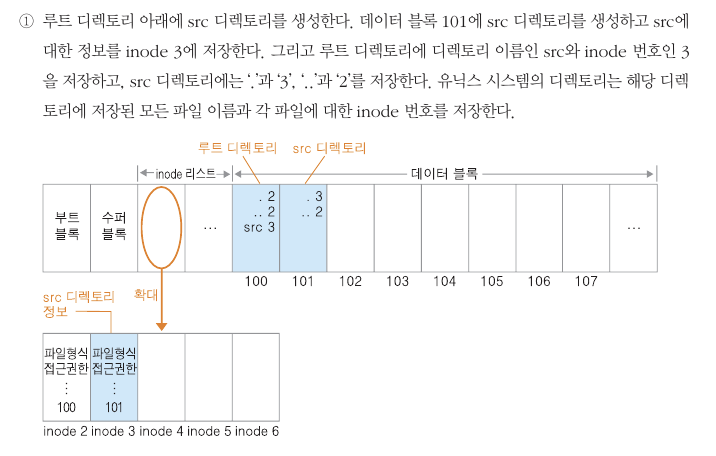
유닉스로 포맷하면 첫 번째 데이트 블록이 루트 디렉토리에 생성
루트 디렉토리 정보는 inode 2에 저장
innode 100은 루트 디렉토리가 저장된 블록 번호 의미
.. 부모 디렉토리 의미

루트 디렉토리 안에 src 파일 생성
데이터 블록 101 의 디렉토리를 생성하고..
src에 대한 정보는 inode 3에 저장
루트 디렉토리에 inode 번호 3 저장.
유닉스 시스템의 디렉토리는 해당 디렉토리에 저장된
모든 파일 이름과 각 파일에 대한 Inode 번호를 저장한다.

결론

윈도우 시스템이랑 틀리긴하지만 일정부분은 비슷하다.
프로그래밍 언어
구조적 자료형
여러 자료형을 묶어서 하나의 단위로 처리하는것
튜플
하나 이상의 데이터를 순서대로 저장하는 자료형
저장된값은 변경 할 수 없다.

인덱스로 관리함 ..
자료구조
프로그램에서 쉽게 이용할 수 있또록 구성된 데이터 간의 논리적 관계
ex)
연결 리스트
각 데이터를 포인터로 연결하는 구조.
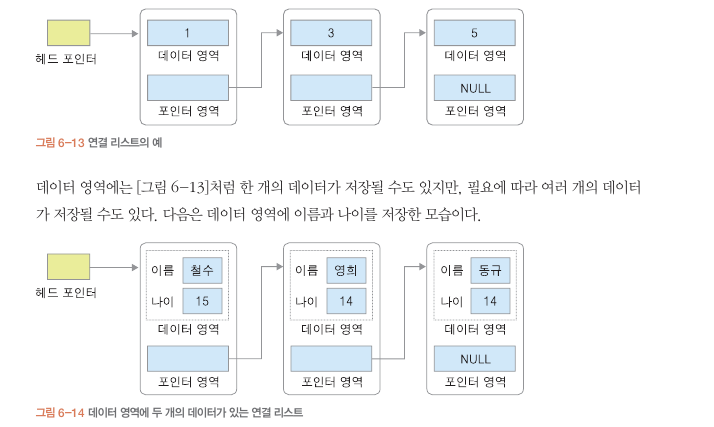
1번째는 단순 연결 리스트.
이중 연결 리스트
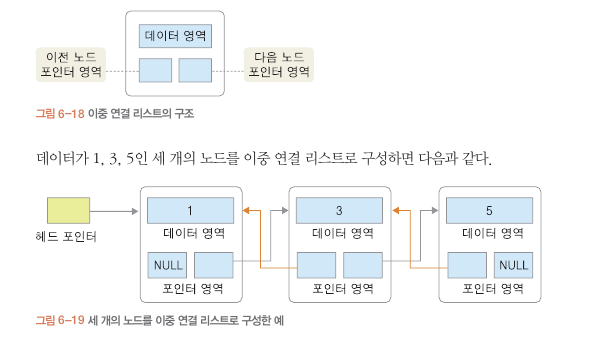
앞 뒤로 연결되서 검색 가능
큐
선입 선출(FIFO) 로 구현

원형 큐로 기존 배열 큐의 문제 해결
그래프
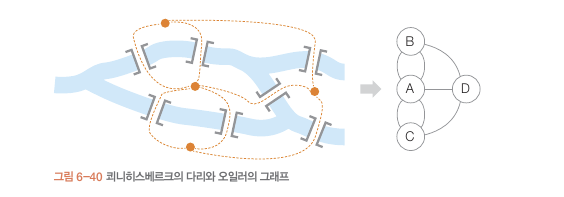
간선 : 정점 과 정점 연결
차수 : 정접에 접한 간선의 수
A = 5개
G = (V,E)
V: 정접의 집합
E: 간선의 집합
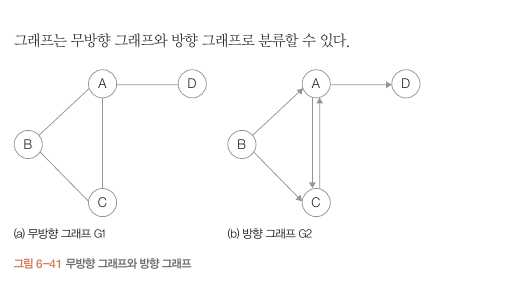

무방향 그래프와 방향 그래프의 차이.
방향 그래프는 진입 차수와 진출 차수로 나뉨.
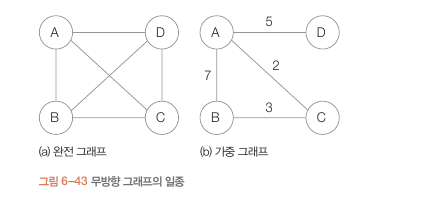
무방향 그래프의 일종
그래프의 탐색
모든 정점을 방문하는 것을 탐색
깊이 우선 탐색
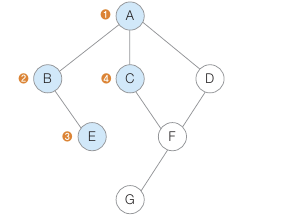
시작 정점에서 방문 하지 않는 정점을 방문하고
다음에는 방문한 정점에서 다시 연결된 방문하지 않는 정점 순으로
모든 정점을 탐색하는 방식
그림대로 순서대로 갔다 다시 돌아와서 방문하지 않는 접점 방문
너비 우선 탐색
시작 정점 먼저 방문하고 시작 정점과 연결된 모든 정점 방문.
그리고 새롭게 방문한 정점들에 연결된 아직 방문하지 않는 정점 방문
(큐를 이용해 탐색)
트리
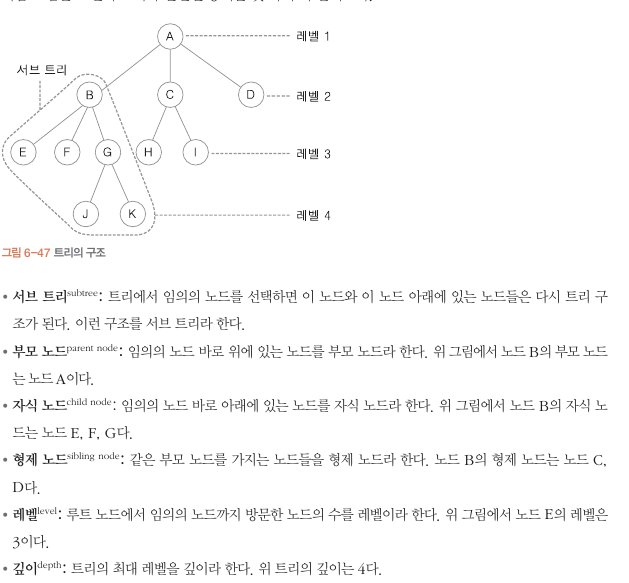
트리의 구조
이진 트리
자식 노드가 두개 이하읜 트리
전위 순회
루트 노드 > 왼쪽 서브트리 > 오른쪽 서브 트리 순 방문

중위 순회
왼쪽 서브트리 -> 루트 노드 , 오른쪽 서브 트리 순으로 방문

후위 순회
왼쪽 서브트리 , 오른쪽 서브트리 루트 노드 순

이진 탐색 트리
트리 중 같은 데이터를 갖는 노드가 없으며
왼쪽 서브 트리에 있는 모든 데이터가 현재 노드보다 작고
오른쪽 서브 트리에있는 모든 데이터가 현재 노드 데이터보다
큰 트리를 말함
데이터 삽입 삭제 검색등 자주 발생하는 경우 효율적
