
구분
-
논리 모델링 업무에 대한 이해가 많이 필요
-
엔티티 속성 관계 도출 정규화 작업 업무적인 요건 모델링
-
어느정도 적당한 소프트웨어 개발 경험이 필요함.
-
물리 모델링은 DBMS의 종류와 기능 성능에 이해가 필요함
-
종류별로 최적의 컬럼 타입 데이터의 접근 패턴을 분석해서 인덱스 전량 수립 및 반정규화 등 성능 적 요소 모델링 적용
- 소규모 프로젝터는 소프트웨어 개발자가 논리+물리 모델링 동시에 진행하기 도 함
- 보통 성능 보완 이런것들은 DBA가 완성함
CHAR VS VARCHAR

- 문자의 최대 저장 갯수 의미 (길이가) EX ) CHAR(10) 10글자 적용 가능
- CHAR는 고정길이 VARCHAR는 가변길이 저장
문자셋의 중요성
-
문자셋은 각 문자를 어떻게 인코딩할지 결정합니다.
-
문자셋에 따라 같은 글자 수라도 실제 저장에 필요한 바이트 수가 달라집니다.
-
캐릭터와 바캐릭터 타입의 컬럼 모두 어떤 문자셋으로 정의되었느냐에 따라 사용하는 저장공간 크기가 달라짐
-
EX) 라틴1 문자셋을 사용하는 캐릭터쉽과 VARCHAR타입 컬럼은 최대 10글자 까지 저장하지만
-
라틴 1문자만 저장할 수 있기 때문에 최대 10바이트까지만 사용할수 있게 됨
-
영어, 숫자, 일부 특수문자만 저장 가능하다는 제한이 있음
-
UTF-8은 가변 길이 인코딩 방식
-
문자에 따라 1~4바이트를 사용할 수 있다
-
영어 알파벳: 1바이트per문자 (10글자 = 10바이트)
-
한글: 3바이트per문자 (10글자 = 30바이트)
-
특정 이모지: 4바이트per문자 (10글자 = 40바이트)
-
CHAR(10)이나 VARCHAR(10)으로 정의해도 실제 저장 공간은 10~40바이트가 될 수 있음
-
UTF-8 MB4문자셋을 사용하는 캐릭터와 VARCHAR타입 컬럼 경우 10글자 까지 저장할 수 있긴 하지만
-
저장하는 글자의 문자셋이 UTF-8이기 때문에 최소 10 바이트에 최대 40바이트 사용할수 있게 됨
-
UTF-8 문자셋은 가변 길이 문자셋이기 때문에 영어 알파벳 10글자가 저장되면 10 바이트 사용하고
-
한글 10글자를 저장하면 30바이트 특정 이모지는 40바이트까지 사용할수 있게됨
차이점
- CHAR는 고정길이 저장 (저장되는 문자의 값의 길이에 관계없이 최대 설정된 크기만큼 항상 공간 할당 사용)
- 예: CHAR(10)에 'ABC'를 저장하면 10바이트를 모두 사용
- 최대 255 문자까지 저장 가능
- VARCHAR는 가변길이 저장( 실제 저장된 문자열의 길이만큼만 공간을 사용)
- 예: VARCHAR(10)에 'ABC'를 저장하면 실제로는 3바이트만 사용
- VARCHAR 16000 문자까지 저장
길이 정보 저장
- CHAR 저장된 값의 길이를 별도 관리 안함
- 일반적으로 CHAR는 길이 정보를 저장하지 x
- 그러나 UTF-8 MB4와 같은 가변 길이 문자셋을 사용할 경우, CHAR도 VARCHAR처럼 길이 정보를 저장
- 이는 가변 길이 문자셋에서는 문자당 사용하는 바이트 수가 다를 수 있기 때문
- VARCHAR 저장된 문자열 값의 실제 바이트수를 관리하는 길이 저장 바이트가 있는데
- VARCHAR는 항상 저장된 문자열의 실제 길이 정보를 함께 저장
- 이 길이 정보는 1바이트 또는 2바이트를 사용 (밑에 랑 같은말)
- 필요에 따라서 1바이트에 2바이트까지 사용
- 이 길이 정보는 데이터 앞부분에 추가
- 255바이트 이하의 데이터: 길이 정보에 1바이트 사용
- 255바이트 초과 데이터: 길이 정보에 2바이트 사용
- 예시


-
오랜만에 기억이안나서 그림도..
-
VARCHAR(100)에 'Hello' 저장 시:
-
데이터 길이: 5바이트
-
길이 정보: 1바이트 (255 이하이므로)
-
총 사용 공간: 6바이트 (5 + 1)
-
VARCHAR(1000)에 300바이트 길이의 텍스트 저장 시:
-
데이터 길이: 300바이트
-
길이 정보: 2바이트 (255 초과이므로)
-
총 사용 공간: 302바이트 (300 + 2)
이유
- 1바이트로는 0-255까지의 값만 표현 가능
- 더 긴 문자열의 길이를 저장하려면 2바이트가 필요
장점
- 짧은 문자열에 대해서는 공간을 절약
- 긴 문자열도 효율적으로 저장
라틴1 문자셋(고정길이 문자 셋)
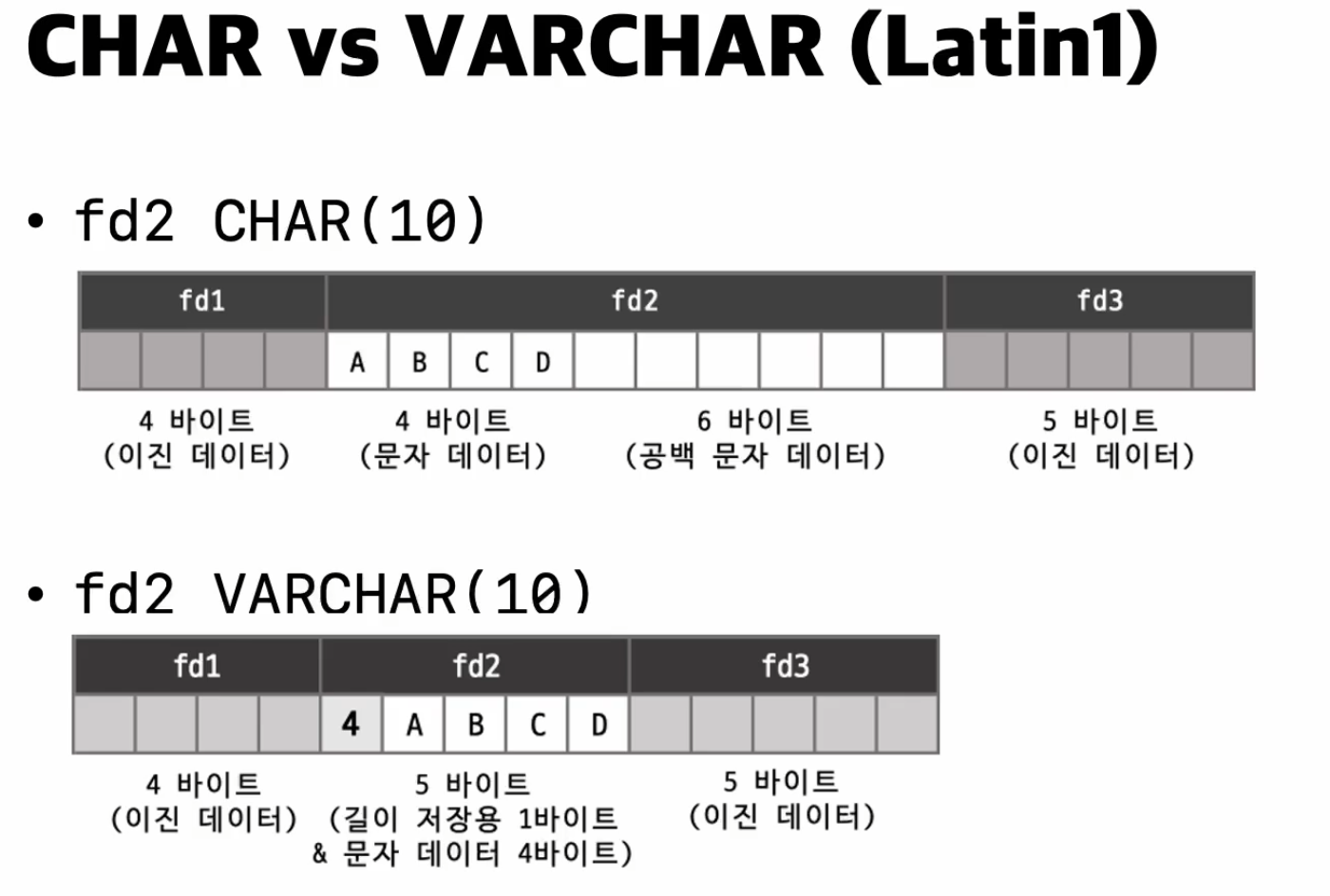
- CHAR는 10바이트의 공간을 예약하고 4바이트만 사용하고 6바이트는 비워둠
- fd는 꼭필요한 4바이트만 할당해서 사용함.
- 길이 정보가 4가 저장되 있음 그래서 총 길이정보까지 5바이트
- 컬럼 바로앞에 길이정보가 저장된 것 처럼 보이지만 설명의 편의를 위한 것임
- 실제로는 순서가 다르고 복잡한 형태로 저장됨
UTF8MB4

-
CHAR 타입경우 UTF-8 MB4 문자셋 사용경우 한글잔즌 최대 4바이트 사용할 수 있어서
-
최대 40바이트까지 빈공백 예약할수 있는 것처럼 보임
-
실제 MYSQL 서버는 빈 공백 공간을 예약할 때에는 문자의 개수보다 바이트수로 빈 공백 공간을 예약해두도록 작동
-
즉 한글 두글자를 저장하면 한글 한글자는 3바이트를 사용하기 때문에 FD2컬럼에는 6바이트를 사용 함.
-
결론적으로 FD2 컬럼에 4개의 빈 공백 공간만 예약해 둠
-
만약 한글 네글자가 저장되면 실제 12바이트 저장공간이 필요하게 됨
-
그래서 12 바이트가 저장됨. 4글자가 12바이트를 사용하기 때문에 CHAR 10컬럼 타입에 정의도니 길이 10보다 더 큰 길이여서 추가로 빈 공간을 더 할당해 두지 않음. 캐릭터 타입이라 하더라도
-
UTF-8 MB4와 같은 가변 길이 캐릭터셋을 사용하는 경우 예약해 두는 빈 공간이 단순한 부족한 글자 수만큼 아님
-
때론 예약된 빈공간 없음
-
이런 특성으로 인해 UTF-8 MB4와 같은 가변 길이 문자셋을 사용하는 CHAR타입 경우 VHARCHAR와 조금 비슷하게 동작
-
그리고 가변길이 문자셋인경우 캐릭터 타입이라 하더라도 실제 저장된 문자의 값이 사용하는 바이트수가
-
별도로 관리 되어야함
-
UTF-8 MB4는 가변길이 문자셋이기 때문에 여기 그림에서도 10과 12라는 숫자값이
-
컬럼 앞단에 표시되는걸 확인함.
-
VARCHAR는 실제 저장된 값이 사용하는 공간만 할당됨. 문자셋 상관없이 항상 꼭필요한 문자셋 공간만 할당함
정리


- 라틴1 문자셋 (고정 길이 문자셋)
- CHAR(10)에서:
- 10바이트 공간 예약
- 실제 데이터 'abcd'는 4바이트 사용, 나머지 6바이트는 빈 공간
- VARCHAR(10)에서
- 실제 데이터 길이인 4바이트만 사용
- 추가로 1바이트의 길이 정보 저장 (총 5바이트)
- 이유 : CHAR는 고정 길이로 항상 정의된 길이만큼 공간을 사용하지만, VARCHAR는 실제 데이터 길이만큼만 공간을 사용
- UTF8MB4 문자셋 (가변 길이 문자셋)
-
CHAR(10)에서
- 한글은 글자당 최대 3바이트 사용
- 두 글자 저장 시 6바이트 사용, 4바이트 빈 공간만 예약
- 네 글자 저장 시 12바이트 사용, 추가 빈 공간 없음
-
VARCHAR에서
- 항상 실제 데이터가 사용하는 공간만 할당
-
이유: UTF8MB4는 가변 길이 문자셋이므로 CHAR 타입도 VARCHAR와 유사하게 동작합니다. 실제 사용된 바이트 수에 따라 저장 공간이 결정
CHAR 타입의 공간낭비
- 고정된 길이의 값 저장은 CHAR / 그 외 경우 VARCHAR
- 고정된 문자는 char 길이가변하면 varchar 아직도 변함없이 많이 알고있는 사실
- 이 기준대로라면 char(13) 선택해야됨 그런대 varchar(13)을 선택하면?
- 둘 중 뭘 선택해도 차이가 없다. 물론 varchar 크기가 한바이트 크기가 커지지만 영향이 없음.
- 결론: 고정길이 문자열 char캐릭터 사용하는건 의미가 없다.
- 그래서 varchar 사용해야 되남
- 그럼 char의 장점을 최대한 활용할 있는 기준은 아님
- char varchar 차이는 공간을 미리 예약하나 안하나
- 공간을 미리 예약한다? -> 공간의 낭비
CHAR 대신 VARCHAR를 사용?
- 어떤 경우에는 CHAR 타입의 공간 낭비 심함
- 저장되는 문자열의 최소 최대 길이 가변 폭이 큰경우 (ex: 1~100)
- char 경우 공간낭비가 100 까지 커질수 있음
- 하지만 그렇지않고 작은경우
- 저장되는 문자열의 최소 최대 길이 가변폭이 작은경우 90~100
- 10바이트 정도로 소량의 낭비만 남음
- 그래도 결론적으로 varchar 선택을 해야 됨. 한 바이트라도 아낀다
- 근대 빈 예약공간이 장점을 제공한다면 몇 십 바이트 정도는 가치가 있는경우가있따
- 그 경우가 저장되는 값의 길이 변동이 크지 않다면 낭비는 크지 않음
정리
- 대부분의 경우 VARCHAR를 사용하는 것이 공간 효율성 측면에서 유리
- 하지만 데이터의 특성과 사용 패턴을 고려하여 CHAR의 사용도 검토할 필요가 있음
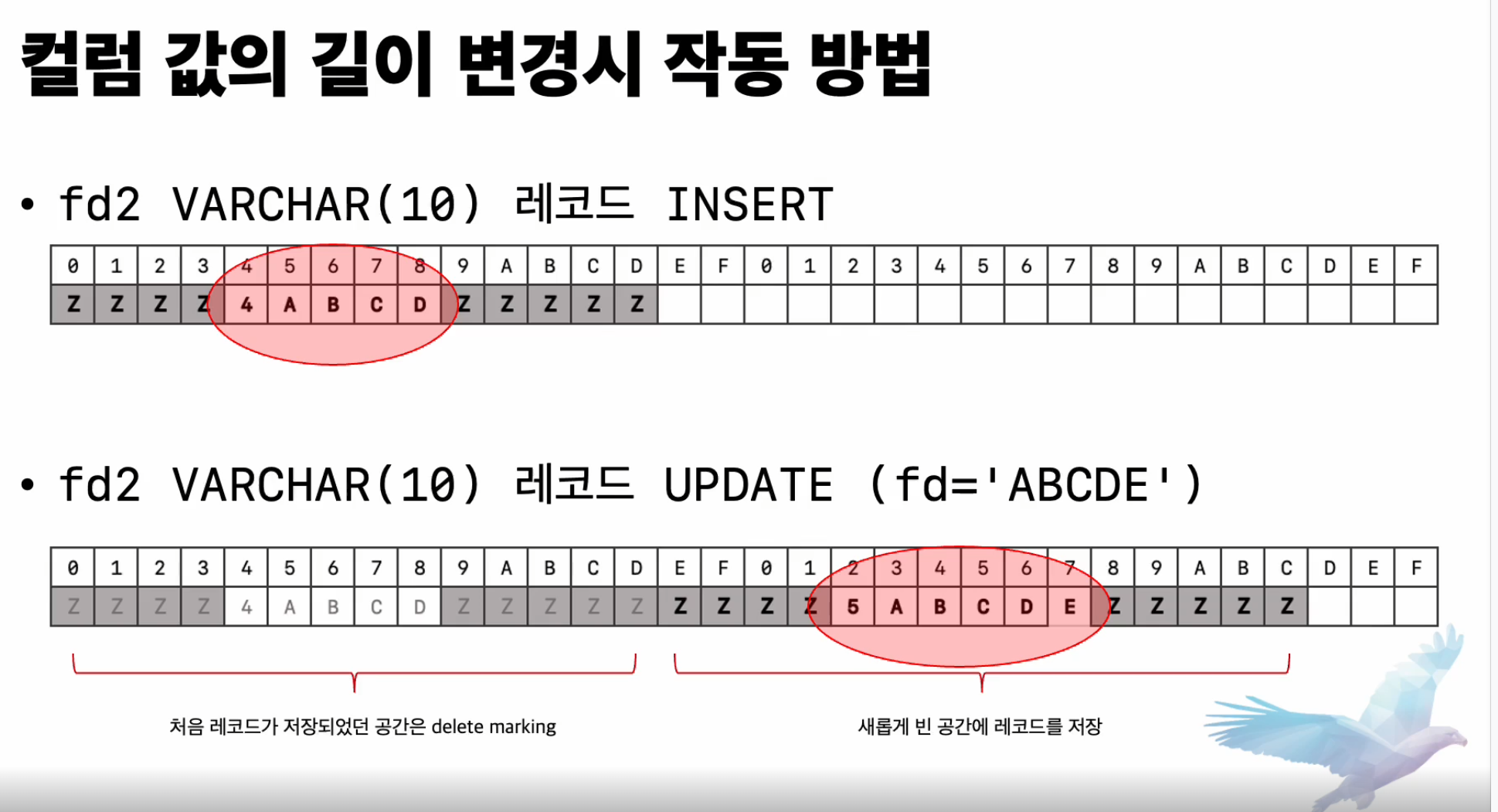
- FD2 컬럼 VARCHAR(10)
- ABCD 인서트시 FD2 컬럼에 채워짐
- 길이가 한글자더긴 ABCDE 업데이트가 되면?
- 레코더 길이 바껴서 인플레스 업데이트 x
- 동일 데이터 페이지 내에서 15바이트 저장할수있는 새로운 레코더 찾아야됨
- 기존 레코드는 삭제표시 함
- 지속적으로 인서트가 업데이트 되면 빈 공간을 찾기가 어려워 지게 됨
- 결국 페이지 레코더드를 컴팩션 -> 새로운 레코더를 저장하는 공간을 찾게됨
근대 CHAR 였다면?
- MYSQL 서버는 FD2컬럼을 위해 충분한 공간 미리 예약해 두었기 때문에
- 공간 낭비는 되어도 한 글자 더 늘어나는 형태 업데이트가 진행되어도
- 컬럼의 예약된 공간에 데이터를 저장만 하면 되기 때문에 레코드를 통째로 저장할 빈 공간을 찾아서 레코드를 옮겨쓰는
- 복잡한 과정을 거치지 않아도됨
- 레코드의 위치를 옮겨적어야되는 가능성을 낮춰준다
- 결론적으로 저장되는 문자열의 가변 길이 폭이 좁고 자주 변경되는 컬럼경우 VARCHAR보단 CHAR가 더나음
- 컬럼 길이 변경시 데이터 페이지 관리 작업 최소화하고 자엽스럽게 페이지의 프레그멘테이션 최소화 효과 나옴
- 데이터 페이지 조각 모음 작업이 덜 필요해지게 됨
- 또한 레코드 이동 줄어 프레그멘테이션이 줄어들어 공간 절약 효과까지 얻음
- 이런 효과는 CHAR타입이 VARCHAR보다 공간낭비를 더 줄여 줄수 있다.

- 이런 경우의 CHAR를 선택하면 됨
