람다식
-
people.maxBy(it.age)
-
람다식의관한 설명들 중요한 내용만 요약해서 적어보자
-
람다식의서 함수의 유일한? 인자이면 호출시 빈괄호는 없어도됨
-
ex ) people.maxBy { p:Person -> p.age}
파라미터 타입제거
-
people.maxBy {p.Person -> p.age} 에서 -> peple.mayBy{p -> p.age}
-
컴파일러가 추론해서 생략함
-
보통 람다를 쓰면 실무에서 파라미터는 한개이다 책에선 여러개일 경우도있지만
-
보통 하나인 경우에만 예제를쓴다 (실무에서도 마찬가지지 )
-
람다식 파라미터는 it(따로 람다 파라미터 이름을 지정하지 않으면)
-
people.maxby{it.age}
-
tip 에서 내가 실수했떤 내용이나온다. 람다가 중첩시 it도 중첩되는대
-
이러면 코드가 명확해지지않아 가독성이 나빠져서 따로 명확한 이름일 지정해 주는게 좋다.
현재 영역에 있는 변수 접근
-
코틀린은 자바와 달리 람다 밖 함수에 있는 파이널이 아닌 변수에 접근가능..
-
이러한 변수를 "효과적으로 파이널(Effectively Final)"
-
즉 람다 내부에서 해당 변수를 변경하지 않으면
-
변수를 final 변수처럼 취급 한다.
-
코틀린에선 효과적 파이널 / 비효과적 파이널 다
-
접근 가능
-
그래서 바깥의 변수를 변경하거나 변경하지 않아도 됨
fun main() { var counter = 0 val numbers = listOf(1, 2, 3, 4, 5) numbers.forEach { counter += it } println("Counter: $counter") } -
이 경우 변수가 변경 되는데 동시성 문제를 초래 할 수 있다.
- synchronized 블록사용
- @Volatile 모든 스레드가 항상 메모리 최신값 읽게하기
- 원자적 연산 AtomicInteger등 원자 클래스 사용
- ThreadLocal : 스레드 별로 변수 값 갖도록 공유자원 사용 X 다른 스레드에 영향을 미치지 않게.
왜 람다밖 함수에 파이널이 아닌 변수에 접근 하고 변경 하지?
- 해당 변수를 자동으로 캡쳐하기 때문.
- 람다 외부에 있는 변수를 사용할 때 그 변수를 캡쳐해
자신의 범위내 사용할수 있는 상태로 만들기 때문 - 스레드 안정성 주의 ?? 무슨 소리지.
- 코틀린에서 람다는 외부 변수를 자동으로 캡쳐?
람다가 외부 변수 가져와 자신의 영역에서 사용할 수 있게 만든다는 의미. - 이렇게 하면 람다 내부에서 외부 변수를 마치 자신의 변수처럼 사용 할 수 있음. 캡쳐는 꼭 final일 필요 없다.
-
그래서 결론은?
-
이런 기능이 있는 이유? 코드가 간결하고 명확해지고,
-
코드 가독성 향상 외부 변수 사용으로 코드 더 명확.
-
클로저 이점: 외부 변수를 캡쳐하는건 람다는 클로저라 함.
클로저를 사용하면 내부에서 외부 컨텍스트에 대한 참조 유지해 함수형 프로그래밍 패턴을 더 쉽게 구현. -
동작의 캡슐화 : 작은 동작들을 쉽게 캡슐화 가능해.
코드 재사용이 가능하고 모듈화 함.
람다를 사용하지 않은 경우:
kotlin
Copy code
fun main() {
val numbers = listOf(1, 2, 3, 4, 5)
val evenNumbers = mutableListOf<Int>()
for (number in numbers) {
if (number % 2 == 0) {
evenNumbers.add(number)
}
}
println(evenNumbers)
}
람다를 사용한 경우:
kotlin
Copy code
fun main() {
val numbers = listOf(1, 2, 3, 4, 5)
val evenNumbers = numbers.filter { number -> number % 2 == 0 }
println(evenNumbers)
}
//클로저 예시
// 각각의 클로저가 독립적으로 상태유지 서로 다른 스레드
접근시 충돌은 없음.
// 완벽한 안전 보장은 아님
//여전히 동시성 문제 발생
fun main() {
val makeCounter = fun(): () -> Int {
var count = 0
return { count++ }
}
val counter1 = makeCounter()
val counter2 = makeCounter()
println("counter1: ${counter1()}") // 출력: counter1: 0
println("counter1: ${counter1()}") // 출력: counter1: 1
println("counter1: ${counter1()}") // 출력: counter1: 2
println("counter2: ${counter2()}") // 출력: counter2: 0
println("counter2: ${counter2()}") // 출력: counter2: 1
}
동작의 캡슐화 예시:
람다를 인자로 받는 함수:
// applyOperation 함수는 람다를 인자로 받아 동작을 캡슐화하고, 이를 조합하여 다양한 결과를 생성
kotlin
Copy code
fun applyOperation(a: Int, b: Int, operation: (Int, Int) -> Int): Int {
return operation(a, b)
}
fun main() {
val addition = { a: Int, b: Int -> a + b }
val multiplication = { a: Int, b: Int -> a * b }
println(applyOperation(2, 3, addition)) // 5
println(applyOperation(2, 3, multiplication)) // 6
}
멤버 참조
-
val getAge= Person::age
-
멤버 참조는 프로퍼티나 메소드를 단하나만호출하는함수값을만들어준다
-
val getAge= {person: Person ->person.age )
-
함수 참조와 / 프로퍼티 참조
// 함수 참조 fun printMessage(message: String) { println(message) } val functionReference = ::printMessage functionReference("Hello, Kotlin!") // "Hello, Kotlin!"이 출력됩니다. //프로퍼티 참조 class Person(val name: String, val age: Int) val person = Person("Alice", 30) val namePropertyReference = Person::name val personName = namePropertyReference.get(person) println(personName) // "Alice"가 출력됩니다.
컬렉션 함수형 API
- filter 는 걸러주고 / map은 새로운형태로 변환.
All, any ,find ,count
- size 보단 count
- find = findOrnull
Group by
val people = listOf(
Person("Alice", 31),
Person("Bob", 29),
Person("Carol", 31)
)
println(people.groupBy { it.age })
출력된 컬렉션을 보기 좋게 정리하겠습니다.
css
Copy code
{
29=[Person(name=Bob, age=29)],
31=[Person(name=Alice, age=31), Person(name=Carol, age=31)]
}flat map / flatten
-
코틀린의 고차 함수
-
중첩된 컬렉션을 단일 컬렉션 변환시 사용
val nestedList = listOf( listOf(1, 2, 3), listOf(4, 5, 6), listOf(7, 8, 9) ) val flatList = nestedList.flatMap { it } println(flatList) // [1, 2, 3, 4, 5, 6, 7, 8, 9] val nestedList = listOf( listOf(1, 2, 3), listOf(4, 5, 6), listOf(7, 8, 9) )
val flatList = nestedList.flatten()
println(flatList) // [1, 2, 3, 4, 5, 6, 7, 8, 9]
- 차이점은 flatMap은 변환 함수 적용
- flatten 변환 함수 없이 단일 컬렉션으로
지연 계산 LAZY
-
map과 Filter를 동시에 사용하면 임시의 2개리스트가 생김.
-
원소가 많을경우 성능이 낮아짐 .
val numbers = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) val evenSquares = mutableListOf<Int>() for (number in numbers) { if (number % 2 == 0) { evenSquares.add(number * number) } } println(evenSquares) // 위 코드와 비교해보면서 보자 val numbers = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) val evenSquares = numbers.asSequence() .filter { it % 2 == 0 } .map { it * it } for (square in evenSquares) { println(square) } -
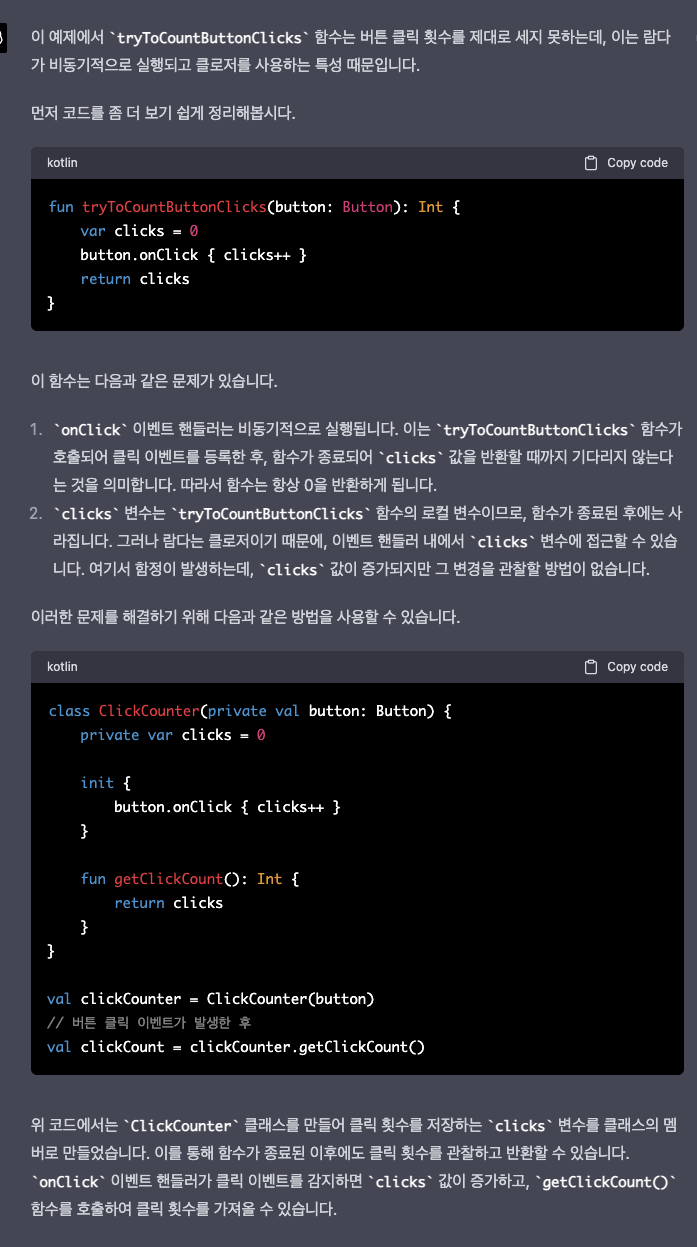
핵심은 filter와 map 함수가 즉시 연산되지 않고, 이후에 실제 값이 필요한 시점(여기서는 for 루프)에 계산되는 지연 계산 방식을 사용한다는 점입니다.
-
시퀀스 사용시 연산이 필요한 시점에 각 요소가 실행됨
-
2나올때 연산 4나올때 연산 등..
시퀀스 연산 실행: 중간 연산과 최종 연산
-
시퀀스 연산은 중간 / 최종으로 나뉨 .
-
printin(listof (1, 2, 3, 4) . asSequence ()
map (it *it J.find (it >3)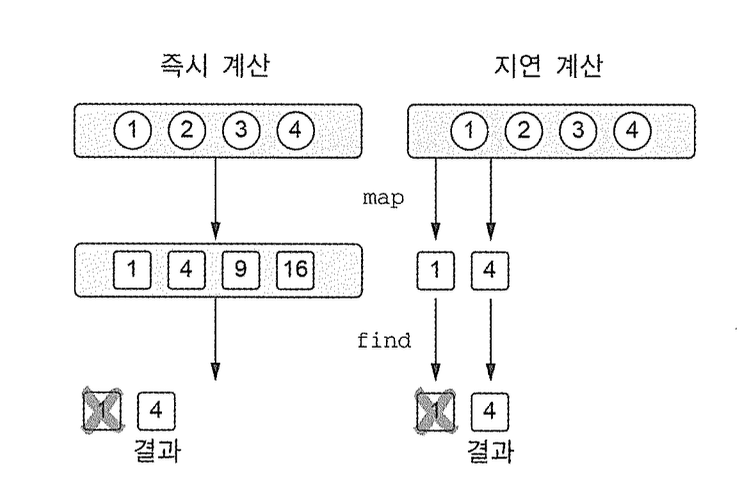
-
시퀀스는 왜 ? 사용 자바6 기반으로 코틀린이 만들어졌기때문에 스트림이없어서
-
대신 시퀀스 사용 중간 연산는 다른 시퀀스를 반환하고 최종 연산은 결과를 반환함
-
시퀀스는 원소를 하나씩 처리함. 일부 원소 계산이 이루어지지 않을 수 있음
-
왜 사용? 실무에선 그럴일이 별로없지만 연산이 많을경우
-
시퀀스를사용해 필요한 원소만 처리해 부하를 줄임.
val people = listOf(Person("Alice", 29), Person("Bob", 31), Person("Charles", 31), Person("Dan", 21)) // map and filter in sequence println(people.asSequence().map(Person::name).filter { it.length < 4 }.toList()) // filter and map in sequence println(people.asSequence().filter { it.name.length < 4 }.map(Person::name).toList())
시퀀스 만들기
- 결론적으로 시퀀스를 사용하면서 원소하나하나 연산한다는 의미
자바함수형인터페이스활
- 코틀린은 무명 클래스 대신 람다를 넘길 수 있음
- 자바에서도 배운적이있는 펑셔널 함수 -> 함수형 인터페이스
- SAM 인터페이스 라고함, 싱글 추상 함수란 뜻..
- 인터페이스에 함수가 하나있으면 파라미터로 인터페이스를 표현가능함
- button.setonclickListener lview->... )
- public interface OnClickListener {
voidonClick(Viewv); • v iew->... 3
)
수신객체지정람다: with와apply
-
수신 객체 지정 람다는 람다 함수의 인자 목록을 먼저 정의하고, 그 다음에 람다 함수 본문을 작성합니다. 이 때, 인자 목록에서 첫 번째 인자에는 수신 객체를 지정할 수 있습니다. 그리고 해당 인자를 람다 본문에서 this로 사용할 수 있습니다.
-
With는 수신객체 지정 람다를 활용함.
-
with는 파라미터가 두개 수신객체 , 람다 .
-
객체의 여러 메서드를 호출하고 그 결과를 변수에 담아야 하는 경우 (with)
-
내가 이해한점
-
with 는 그럼 단일 객체에 연산이나 동작에대해 간결하게 표현하는거구나
-
확장함수 == 수신 객체 지정 람다 ?
-
this는 생략가능
fun alphabet(): String { val result = StringBuilder() for (letter in 'A'..'Z') { result.append(letter) } result.append("\nNow I know the alphabet!") return result.toString() } println(alphabet()) val result = StringBuilder() with(result) { for (letter in 'A'..'Z') { this.append(letter) } append("\nNow I know the alphabet!") } return result.toString() } // with 유무 차이 . val person = Person("John", 30) person.setName("Mary") person.setAge(35) val message = person.getMessage() val message = with(Person("John", 30)) { setName("Mary") setAge(35) getMessage() }
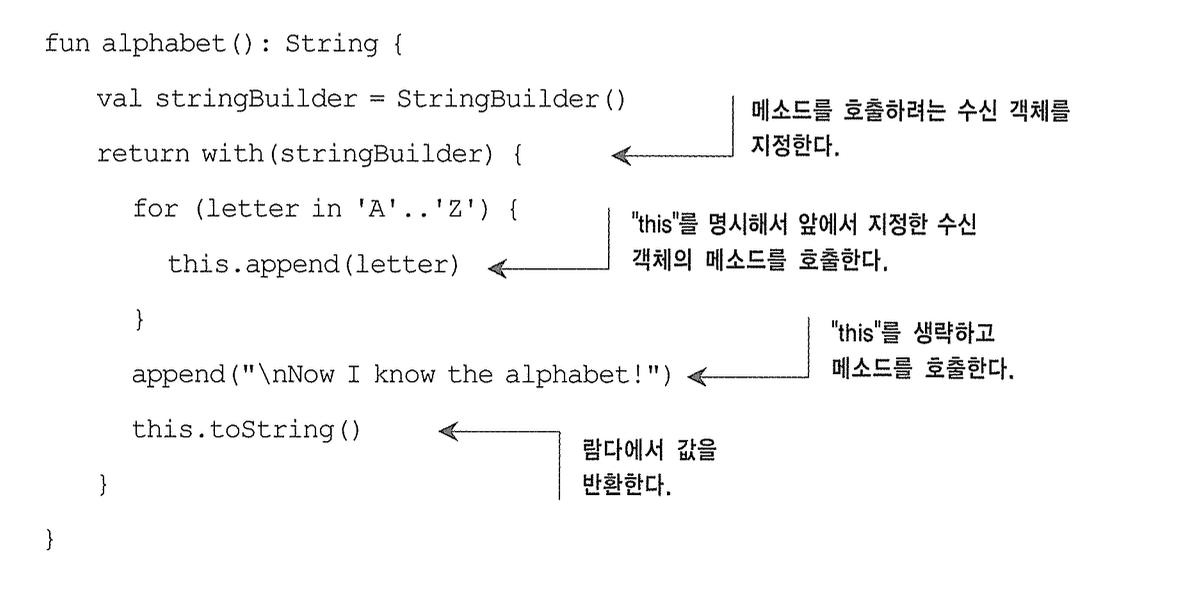
- 책 예제에선 stringBuilder 수신객체 뒤에 람다도 파라미터!
Apply
-
자신에게 전달된 객체 반환!
fun alphabet() = StringBuilder().apply { for (letter in 'A'..'Z') { append(letter) append("\nNow I know the alphabet!") } }.toString() -
apply는 람다 식을 수신 객체로 지정하고 해당 람다에서 수신 객체의 속성이나 메서드를 사용할 수 있도록 합니다
-
얘도 살짝 확장함수 같다.
-
즉시 프로퍼티 중 일부를 초기화 할경우 유용
차이점
-
with는 객체와 람다를 매개 변수로 취하며, 람다에서는 객체의 메서드와 속성에 대한 참조를 직접 지정해야 합니다. 이렇게 지정된 블록 내에서는 수신 객체에 대한 암시적인 참조가 생기므로, 코드의 가독성이 향상됩니다.
val person = Person("John", 30, "Male") // with를 사용하여 person 객체의 속성에 액세스 val nameAndAge = with(person) { "Name: $name, Age: $age" } // 결과: "Name: John, Age: 30" -
apply는 수신 객체와 람다를 취하며, 람다에서는 수신 객체의 메서드와 속성에 대한 참조를 this를 사용하여 지정합니다. 이렇게 지정된 블록 내에서는 수신 객체에 대한 암시적인 참조가 생성되므로, apply를 사용하여 수신 객체를 초기화하고 속성을 설정하는 것이 일반적입니다.
val person = Person("John", 30, "Male") // apply를 사용하여 person 객체의 속성 초기화 person.apply { name = "Jane" age = 25 } // 결과: Person(name=Jane, age=25, gender=Male) -
즉, with는 객체의 속성 및 메서드에 대한 액세스를 간결하게 하지만, 객체를 초기화하거나 수정하지는 않습니다. 반면 apply는 객체를 초기화하거나 수정하는 데 사용되며, 코드의 가독성을 높일 수 있습니다.
