
📚 목차
1. Overall
2. 선형 시간 알고리즘
3. 선형 이하 시간 알고리즘
4. 지수 시간 알고리즘
5. 시간 복잡도
6. 수행 시간 어림짐작하기
7. 계산 복잡도 클래스: P, NP, NP-완비력하세요
프로그램 실행 시간이 알고리즘의 속도와 비례하지 않는 이유
1. 수행 시간은 프로그래밍 언어, 하드웨어, 운영체제 등 수많은 요소에 의해 바뀔 수 있다.
2. 수행 시간이 다양한 입력에 대한 실행 시간을 반영하지 못한다.
알고리즘의 수행 시간을 측정하는 기준
반복문이 지배한다.
짧은 거리를 달릴 때는 자전거가 빠를 수 있는 것처럼, 입력의 크기가 작을 때는 박복 외의 다른 부분들이 갖는 비중이 클 수 있지만. 입력의 크기가 커지면 커질수록 반복문이 알고리즘의 수행 시간을 지배하게 된다.이때 반복문의 수행 횟수는 입력의 크기에 대한 함수로 표현한다.
아래 코드를 보면, N번 수행되는 반복문이 두 개 겹쳐져 있으므로, 반복문의 가장 안쪽은 항상 N의 제곱번 실행되므로, 이 알고리즘의 수행 시간은 N의 제곱이다.
//주어진 배열 A에서 가장 많이 등장하는 숫자를 반환한다.
//만약 두 가지 이상 있을 경우 아무것이나 반환한다.
int majority1(const vector<int>& A) {
int N = A. size();
int majority = -1, majorityCount = 0;
forlint 1= 0; 1<N; ++1) {
//A에 등장하는 Ali의 수를 센다.
int V = Alil, count = 0;
for(int j = 0; j < N; ++j) {
if(A[il == V) {
++count;
}
//지금까지 본 최대 빈도보다 많이 출현했다면 답을 갱신한다.
if (count > majorityCount) {
majorityCount = count;
majority = V;
}
}
return majority;
}위에 비교하여, 아래의 반복문은 하나는 N번 수행되고, 다른 하나는 100번 수행되므로 전체 반복문의 수행 횟수는 N+100이 된다. 그런데 n이 커지면 커질수록 후자의 반복문은 수행 시간에서 차지하는 비중이 줄어들게 된다.따라서, 궁극적으로 이 알고리즘의 수행시간은 N이다.
/A의 가 워소가 0부터 100 사이의 갔임 경우 가장 많이 등장하는 숫자를 반환한다.
int majority2 (const vector<int>& A) {
int N = A.size();
vector<int> count (101, 0);
for(int i = 0; i < N; ++i) {
count [A[i]]++;
//지금까지 확인한 숫자 중 빈도수가 제일 큰 것을 majority에 저장한다.
int majority = 0;
for (int i = 1; i <= 100; ++i) {
if (count [i] > count [majority]) {
majority = i;
return majority;
}그러면 대표적인 수행 시간의 형태를 살펴보면서 알고리즘 효율성 분석의 에제를 보자.
4.2. 선형 시간 알고리즘
다이어트 현황 파악 : 이동 평균 계산하기
이동 편균(moving average): 주식의 가격, 연간 국내 총생산(GDP), 여자친구의 몸무게 등 시간에 따라 변화하는 값들을 관찰할 때 유용하게 사용할 수 있는 통계적 기준
M-이동 평균은 마지막 M개의 관찰 값의 평균으로 정의된다.
아래 그림이 1년 동안의 다이어트 기록이라고 사정하자. 각 점은 해당 월에 측정한 몸무게이고, 점선은 지난 세 달 간의 이동 평균이다.
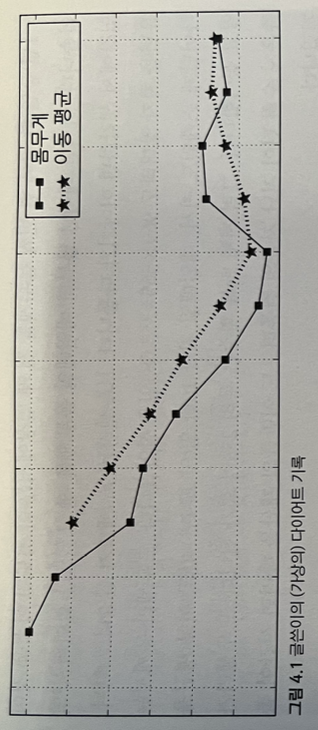
현재 값이 이동 평균 밑에 있는 대부분의 점들에서는 살이 잘 빠지고 있으며, 9월과 10월에는 실제로 몸무게가 는것을 알 수 있다. N개의 측정치가 주어질 때 매달 M달 간의 이동 평균을 계산하는 프로그램을 짜보면, 각 위치에서 지난 M개 측정치의 합을 구하고, 이를 m으로 나누면 된다. 아래 코드를 얻을 수 있다. 이때 이 코드의 수행 시간은 두 개의 for문에 의해 지배된다.
j를 사용하는 반복문은 랑상 M번 실행되고 i를 사용하는 반복문은 N-M+1번 실행되므로, 전체 반복문은 M(N-M+1)=NM-M*M+M번 반복된다, N=12,M=13이면 반복 횟수는 30번이 된다.
코드4. 3이동평균구하기
1/ 실수배일A가주어진때, 각위치에서의1.이동평균값을구한다.
vector<doubles movingAverage1(constvector<double>&A ,i n tM){
vector<double>r e t ;
int N = A.size);
f o r ( i n t i = M-1; i < N; # i ) {
double partialSum = 0;
f o r ( i n t j = 0 ; j < M; # * j )
partialSum +=Ali-jl;
ret.push_back(partialSum/ M);
}
return ret;
}위 코드에서 하나로 묶여있던 두 개의 반복문을 분리하여, 반복문의 수행 횟수를 M-1+(N-M+1) = N 로 줄인 코드이다.
선형시간에 이동 평균 구하기
vector<doubles movingAverage2(const vector<doubles&A ,i n tM ){vector«doubles ret; i n tN = A.size();
doublepartialSum =0 ; for(inti =0 ;i <M-1; #1)
partialSum+=A l i ) ; for(int1=M-1;1 <N;#i){
partialSum+= A l i ; ret.push_back(partialSum/ M ) ;
partialSum- = A[i-M+1); r e t u r nr e t ;}위 코드의 수행 시간은 N에 정비례한다. N이 두 배 커지면 실행도 두 배 오래 걸리고, 반으로 줄어들면 수행 시간도 반으로 줄어든다.
선형 시간 (linear time) 알고리즘 : 입력의 크기에 대비해 걸리는 시간을 그래프로 그려 보면 정확히 직선이 되는 것
선형 시간에 실행되는 알고리즘은 좋은 알고리즘인 경우가 많다. 주어진 입력을 최소한 한 번씩 보기라도 하려면 선형 시간이 걸릴 수 밖에 없기 때문이다.
4.3. 선형 이하 시간 알고리즘
성형 전 사진 찾기
입력으로 주어진 자료에 대해 미리 알고 있는 지식을 활용할 수 있다면, 선형 시간보다 빠르게 동작하는 알고리즘을 짤 수 있다.
예) A군이 언제 성형했는지를 가능한 한 정확하게 알려면, 몇 장의 사진을 확인해봐야 할까?
가장 좋은 방법은 남은 사진들을 항상 절반으로 나눠서 가운데 있는 사진을 보는 것이다. 총 10만장의 사진 중 가운데이 있는 5만 번째 사진을 확인해보자. 이 사진이 코를 성형하지 않은 상태라면 이 전의 사진은 볼 이유가 없으므로 우리는 뒤의 5만장만 확인하면 된다. 이렇게 반복하자보면 대략 열입공 장의 사진만을 확인하면 성형한 시점을 알 수 있다.
이때 봐야 하는 사진의 장수를 N에 대해 표현하면, N을 계속 절반으로 나눠서 1이하가 될 때까지 몇 번이나 나눠야 하는지로 알 수 있는데, 이것을 나타내는 함수가 log이다.
log(아래첨자2)를 사용하면 매번 절반씩 나누니 밑이 2인 log(아래 첨자2)를 사용하면 된다. 따라서 확인해야 하는 사진은 대략 logN이라고 할 수 있다.
선형 이하 시간 (sublinear time) 알고리즘 : 입력의 크키가 커지는 것보다 수행 시간이 느리게 증가하는 알고리즘
이진 탐색
binsearch(A[], x) = 오름차순으로 정렬된 배열 A[]와 찾고 싶은 값 x가 주어질 때 A[i-1]<x<=A[i]인 i를 반환한다. 이때 A[-1]=-oo, A[N] = oo로 가정한다.binsearch함수:배열 A[]에서 x를 삽입할 수 있는 위치 중 가장 앞에 있는 것을 반환하는 함수
배열이나 리스트에서 i 번째 위치에 새 원소를 삽입한다는 것은 i 번째와 그 이후의 원소들을 뒤로 한 칸씩 밀어내고 들어간다는 뜻이다. 따라서 A[]에 x가 존재하는 경우, 이 함수는 첫 번쨰 x의 위치를 반환하고,없는 경우 x보다 큰 첫 번째 원소를 반환한다.
각 원소의 값은 해당 사진에서 A군이 성형 했을 경우 1로, 성형을 하지 않았을 경우 0으로 하면, A는 {0,0, ..., 0, 0, 1, ... , 1, 1}이 된다. binsearch()을 이용해 여기에서 A[i-1]<1<=A[i]인 i를 찾으면 1의 첫번째 위치를 알 수 있다. 결과적으로 i-1번 사진과 i번 사진 사이에 성형을 했다는 것을 알 수 있다.
그래도 선형 시간 아닌가요?
위 설명대로라면 binsearch()의 입력을 만들기 위해서는 결국 사람이 모든 사진을 보면서 성형 이전인지 여부를 판단해야 한다고 생각하지만, 그렇지 않다. 그 이유는
1. A[]를 실제로 계산해서 갖고 있을 필요가 없다.
가운데 있는 것들에 대해서만 필요할 때 게산을 하면 된다.
binsearch()에 A[]를 인자로 넘기는 것이 아니라, i가 주어질 때 A[i]의 값을 직접 계산하는 콜백함수를 제공하면 된다.
콜백 함수란? 인자로 다른 함수에 전달되어 특정 이벤트가 발생하거나 특정 조건이 충족되었을 때 실행되는 함수이다.
2. 사진을 다운받고 정렬해두는 과정이 있으면, 턱 성형을 언제했는지 알아볼때도 다시 열입공장의 사진만 확인해서 알 수 있다.
구현
5.2절에서 다시 살펴보2자
4.2.지수 시간 알고리즘
다항식: 변수 N과 N의 제곱, 그 외 N의 거듭제곱들의 선형 결합으로 이루어진 식
다항 시간 알고리즘 : 반복문의 수행 횟수를 입력 크기의 다항식으로 표현할 수 있는 알고리즘
다항 시간 안에 포함되는 알고리즘 간에 엄청나게 큰 시간 차이가 날 수 있다.
N이나 N제곱도 다항 시간이지만, N의 6제곱도, N의 42제곱도 다항시간이기 때문이다.
따라서 이 알고리즘이 다항 시간이라고 말하는 것만으로는 빠른지 알기 어렵다. 하지만, 다항 시간 알고리즘이 다른 시간 알고리즘보다 빠른 건 사실이다.
알러지가 심한 친구들
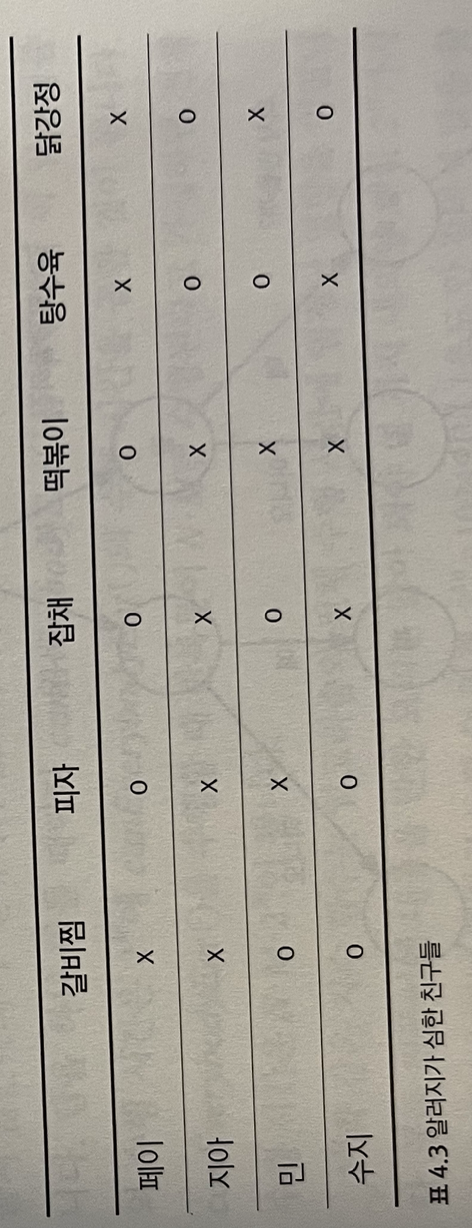
집들이에 N명의 친구를 초대하려 한다. 할 줄 아는 M가지의 음식 중 무엇을 대접해야 할까를 고민하는데, 친구들은 알러지 때문에 못 먹는 음식이 있다.
아래 표와 같은 형태로 만들 중 라는 음식의 목록과, 해당 음식을 못 먹는 친구들의 목록이 있다. 각 친구가 먹을 수 있는 음식이 최소한 하나씩은 있으려면 최소 몇 가지의 음식을 해야할까?
모든 답 후보를 평가하기
이 문제에는 여러 개의 답이 있을 수 있다.
만들 수 있는 음식의 모든 목록을 만드는 과정을 여러 개의 결정으로 나누면 자연스럽다. 우선 첫 번째 요리를 만들지 말지 결정하고, 그 다움에 두 번째 요리를 만들지 말지를 결정한다. 이 과정을 아래 그림처럼 그려 볼 수 있다. 맨 위의 동그라미 안에 쓰인 텅 빈 목록부터 시작해서, 각 음식을 만들지 말지를 선택해 나간다. 맨 윗층에는 갈비찜을 만들지 여부를 결정한다. 다음 층에서는 피자를 만들지 여부를 결정한다. 아래 그림에서는 생략했지만. 그림의 맨 끝까지 내려가 보면 마지막 층에서는 존재 가능한 모든 목록을 만나게 딘다. 마지막으로 모든 친구들이 식사할 수 있는 목록들만을 골라낸 뒤 가장 음식의 수가 적은 목록을 찾으면 된다.
위와 같은 알고리즘을 구현하는 가장 쉬운 방법이 바로 재귀 호출을 이용하는 것이다. 이때 재귀 함수는 그림에서의 한 상태를 입력받아 이 상태 밑에 달린 모든 후보들을 검사하고 이 중 가장 좋은 답을 반환하는 역할을 한다.
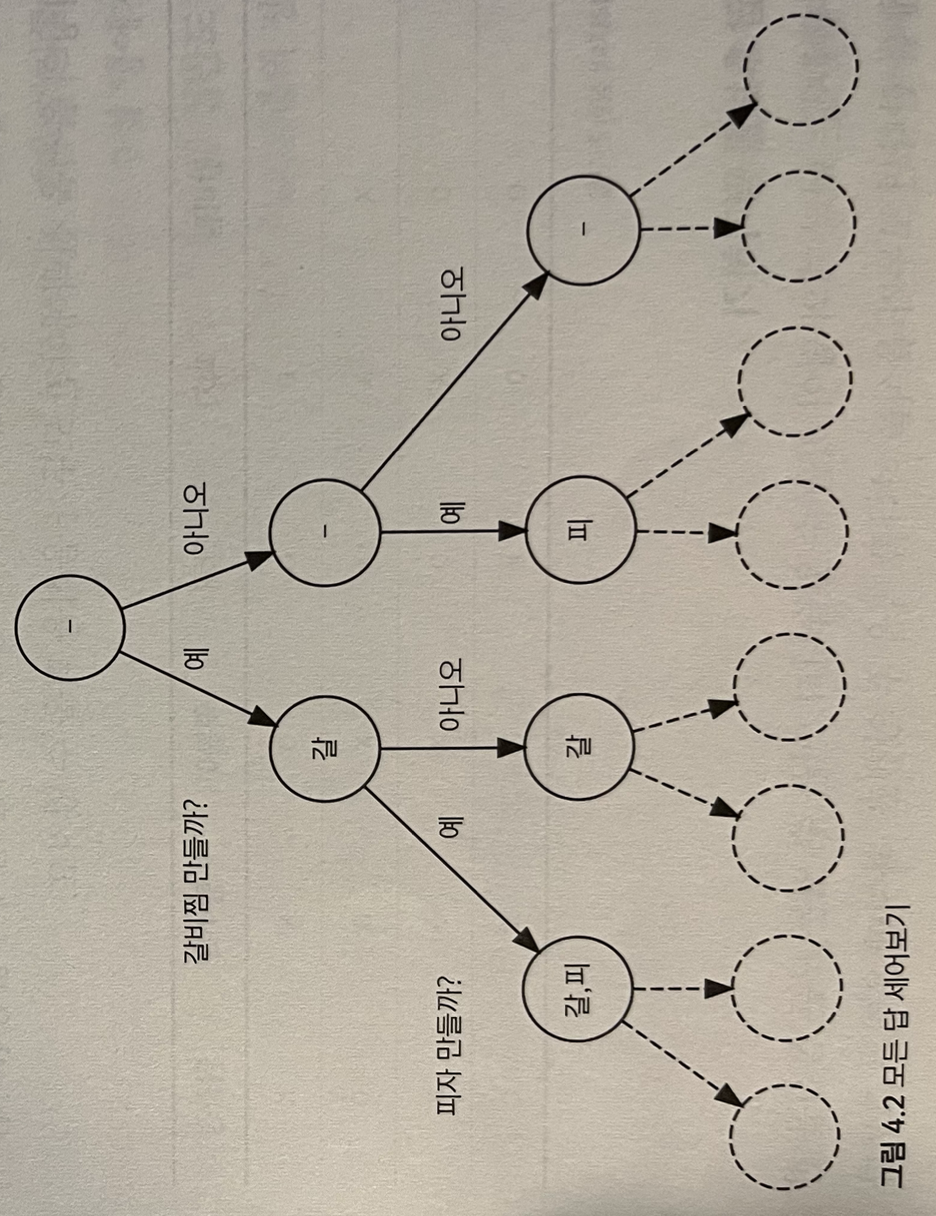
selectMenu()는 지금까지 만들기로 정한 메뉴와 몇 번 음식을 결정할 차레인지를 입력받아 가능한 모든 메뉴를 하나씩 시도해본다.
코드4 . 5 음식메뉴정하기
const int INF = 987654321; / / 이메뉴로모두가식사할수있는지여부를반환한다. bool canEverybodyEat(const vector<ints&menu); / / 요리할수있는음식의중류수 i n tM;
/ / f0 d 번째음식을만들지여부를결정한다. i nselectMenu(vector<int>& menu, int food) { / / 기저사례:모든음식에대해만들지여부를진정했을때 i f(food ==M) {
i f(canEverybodyEat(menu)) return menu.s i z e ) ; / / 아무것도못먹는사람이있으면아주큰값을반환한다. return INF;
/ / 이음식을만들지않는경 우의답을계산한다. i n t r e t = selectMenu(menu, food+1);
menu.push_back(food);
r e t= min(ret, selectMenu(menu, food+1)); menu.pop_back();
return ret;
지수 시간 알고리즘
전체 걸리는 시간 : M가지의 음식을 만든다, 만들지 않는다의 두 선택지가 있으므로 만들 수 있는 답은 모두 2의 M승 가지이다.
답을 하나 만들 때마다 canEverybodyEat()을 수행하니 이 알고리즘의 수행 시간은 2의 M에 canEverybodyEat()의 수행 시간을 곱한 것이 된다. canEverybodyEat()을 수행할 때 반복문이 NM번 수행된다고 가정하면 전체 수행 시간은 NM*2의 M승이 된다.
2의 M승과 같은 지수함수는 알고리즘의 전체 수행 시간에 큰 영향을 끼친다.
지수 시간에 동작한다: N이 하나 증가할 때마다 걸리는 시간이 배로 증가하는 알고리즘
집합 덮개 (set cover) : 지수 시간보다 빠른 알고리즘을 찾지 못한 문제들
소인수 분해의 수행 시간
입력으로 주어지는 숫자의 개수가 아닌, 그 크기에 따라 수행 시간이 달라지는 알고리즘들 또한 지수 수행 시간을 가질 수 있다.
4.5. 시간 복잡도
시간 복잡도 : 가장 널리 사용되는 알고리즘의 수행 시간 기준으로, 알고리즘이 실행되는 동안 수행하는 기본적인 연산(더 작게 쪼갤 수 없는 최소 크기의 연산)의 수를 입력의 크기에 대한 함수로 표현한 것
기본적인 연산의 예
- 두 부호 있는 32비트 정수의 사칙연산
- 두 실수형 변수의 대소 비교
- 한 변수에 다른 변수 대입하기
기본적인 연산이 아닌 예 - 정수 배열 정렬하기
- 두 문자열이 서로 같은지 확인하기
- 입력된 수 소인수 분해하기
시간 복잡도가 높다는 말 : 입력의 크기가 증가할 때 알고리즘의 수행 시간이 더 빠르게 증가한다는 말 -> 시간 복잡도가 낮다고 해서 언제나 더 빠르게 동작하는 것은 아니다.
입력의 크기가 충분히 작을 때는 시간 복잡도 높은 알고리즘이 더 빠르게 동작할 수도 있다.
예) 두 알고리즘 A와 B, 입력의 크기 N에 대해 A는 10240+35logN, B는 2N의 제곱의 시간이 걸린다고 하면, A는 N에 의해 좌우되는 반복 부분만 살펴보면, 선형 이라 시간임을 알 수 있다. 반면, B는 전형적인 다항 시간의 알고리즘이다. 알고리즘 A의 속도는 입력의 크기가 증가해도 거의 변하지 않기 때문에, 전체적인 맥락에서는 알고리즘이 B보다 더 빠르지만, N=10일 경우에는 알고리즘 B가 훨씬 빠르다. 따라서, 문제에서 해결할 입력의 크기가 매우 작을 경우 시간 복잡도는 큰 의미를 갖지 못할 수 있다.
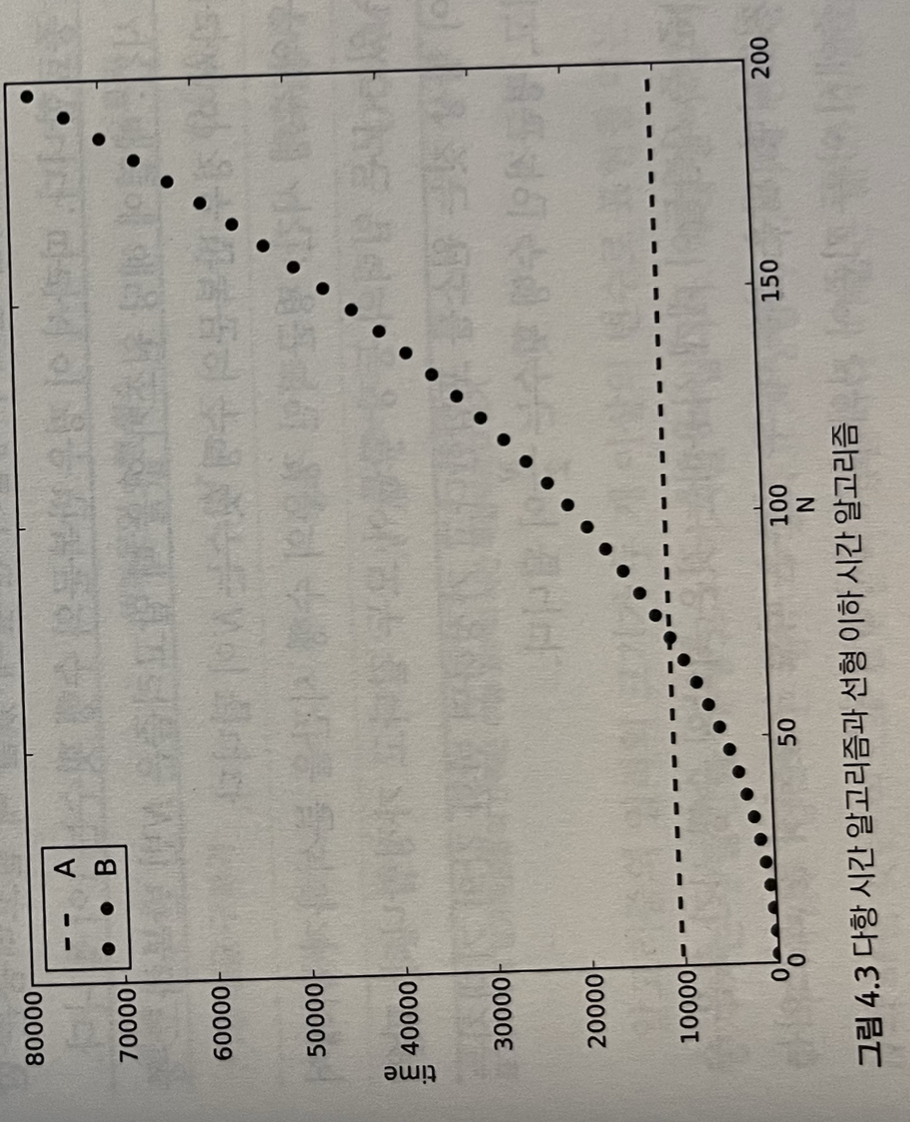
입력의 종류에 따른 수행 시간의 변화
입력의 종류에 따라 수행 시간이 달라지는 경우를 고려하기 위해 최선/최악의 경우, 평균적인 경우에 대한 수행 시간을 각각 따로 계산한다.
코 드4 . 7 선 형당 색
i n tfirstIndex(const vectorsintas array,
int element) { for(int i = 0; 1 < array.size(); ++i) if(array[ i ) ==element)
returni ;
return -1;}- 최선의 수행 시간 : 찾으려는 원소가 배열의 맨 앞에 있을 때 알고리즘은 한 번 실행되고 종료된다. 따라서 이 경우 반복분의 수행 횟수는 1이 된다.
- 최악의 수행 시간 : 배열에 해당 원소가 없을 때 알고리즘은 N번 반복하고 종료한다. 이 경우 반복문의 수행 횟수는 N이 된다.
- 평균적인 경우의 수행 시간 : 존재할 수 있는 모든 입력의 등장 확률이 모두 같다고 가정해야 한다. 만약 주어진 배열이 항상 찾는 원소를 포함한다고 가정하면 반환 값의 기대치는 대략 N/2가 되고, 평균적인 수행 횟수는 N/2가 된다.
점근적 시간 표기 : O 표기
대문자 O 표기법 (Big-O Notation): 주어진 함수에서 가장 빨리 증가하는 항만을 남기고 나머지는 다 버리는 표기법
반복문의 수행 횟수에서 상수를 뗀 것과 비슷함

알고리즘의 입력의 크기가 두 개 이상의 변수로 표현될 때는 그중 빨리 증가하는 항들만을 떼 놓고 나머지를 버린다.
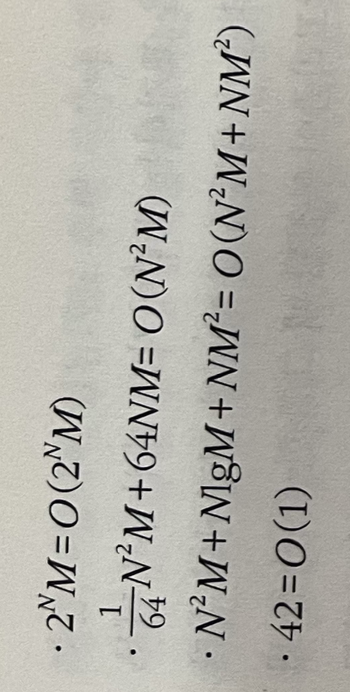
상수 시간(constant-time) 알고리즘 : 알고리즘이 입력의 크기와 상관없이 항상 같은 시간이 걸리는 알고리즘
O표기법을 쓸 때 알고리즘의 시간 복잡도는 반복문에 의해 결정됨
따라서, 이 장에서 가장 깊이 중첩된 반복문의 수행 횟수를 게산했던 것은 실질적으로는 수행 시간의 O표기를 계산한 것이다.
O표기법의 의미
시간 복잡도 분석 연습
시간 복잡도의 분할 상환 분석
4.6. 수행 시간 어림짐작하기
주먹구구 법칙
주먹국 법칙은 주먹구구일 뿐이다
- 시간 복잡도가 프로그램의 실제 수행 속도를 반영하지 못하는 경우
- 반복문의 내부가 복잡한 경우
- 메모리 사용 패턴이 복잡한 경우
- 언어와 컴파일러의 차이
- 구형 컴퓨터를 사용하는 이유
실제 적용해 보기
- O(N의 3승) 알고리즘 : 크기 2560인 입력까지를 1초 안에 풀 수 있다. 2560의 3승 = 약 160억
- O(N의 2승) 알고리즘 : 크기 40960인 입력까지를 1초 안에 풀 수 있다. 40960의 2승 = 약 16억
- O(NlogN) 알고리즘 : 크기가 대략 2천만인 입력까지를 1초 안에 풀 수 있다. 약 5억
- O(N) 알고리즘 : 크기 약 1억 6천만인 입력까지를 1초 안에 풀 수 있다.
1초 내에 수행할 수 있는 반복문의 수행 횟수가 알고리즘 간에 최대 100배까지 차이나는 것을 알 수 있다.
4.7. 계산 복잡도 클래스 : P, NP, NP-완비
문제의 특성 공부하기
- 정렬 문제: 주어진 N개의 정수를 정렬한 결과는 무엇인가?
- 부분 집합 합 (subset sum)문제 : N개의 수가 있을 때 이 중 몇 개를 골라내서 그들의 합이 S가 되도록 할 수 있는가?
난이도의 함정
계산 복잡도에서 흔히 말하는 '어려운 문제'들의 정의
- 정말 어려운 문제를 잘 골라서 이것을 어려운 문제의 기준으로 삼는다.
- 앞으로는 기준 문제만큼 어렵거나 그보다 어려운 문제들, 다시 말해 '기준 이상으로 어려운 문제들'만을 어렵다고 부른다.
환산(reduction)
두 문제의 난이도를 비교하기 위한 기법
한 문제를 다른 문제로 바꿔서 푸는 기법NP 문제, NP 난해 문제
SAT 문제(satisfiability problem): N개의 불린 값 변수로 구성된 논리식을 참으로 만드는 변수 값들의 조합을 찾는 문제
예) 불린 값 변수 a,b,c로 구성된 다음 논리식은 세 변수의 값이 특정 조합을 이루어야 만족된다.
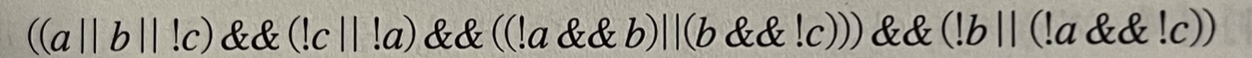
SAT문제는 모든 NP문제 이상으로 어렵다.
NP 문제 : 답이 주어졌을 때 이것이 정답인지를 다항 시간 내에 확인할 수 있는 문제
예) 부분 집합 합 문제 -> 부분 집합 합 문제의 답이 주어졌을 때 이것이 원래 집합의 부분 집합인지, 그리고 원소들의 합이 S인지 다항 시간에 쉽게 확인할 수 있다.
SAT가 모든 NP 문제 이상으로 어렵다는 말은 SAT를 다항 시간에 풀 수 있으면 NP문제들은 전부 다항 시간에 풀 수 있다는 말이다. 이런 속성을 갖는 문제들의 집합 : NP-난해(NP-H)
