6주차는 Malloc기능을 직접 만들어보는 과제를 수행하였다.
Implicit
Implicit - 구현 코드 보기 : (util: 44, thru 12점)
implicit 까지는 CSAPP 교재 자체에 코드가 존재한다.
그냥 무작정 보고 하기엔 감이 오지 않아서 해당 코드를 보고 따라해보았다 (그 이후로 모든 코드를 베끼게 되는데..)
Malloc을 구현하기 위해서, 다음의 이슈들을 코드로 풀어내야 한다.
- 추적
: 가용 블록(free인)들을 어떻게 지속적으로 추적하는가? - 배치
: 새롭게 배치할 블록을 가용 블록들 중에서 무엇으로 선택하는가 ?(xxx- fit) - 분할
: 새롭게 블록을 할당한 이후, 블록의 나머지 부분을 어떻게 할것인가? - 연결
: 방금 free상태가 된 블록을 주변 블록과 어떻게 연결할 것인가?
아이디어 자체는 간단했지만, 이것을 코드로 풀어내는 과정이 어려웠다.
- 각 블록의 헤더에 사이즈와 할당 여부를 기록한다
- 일종의 헤더를 통해 사이즈만큼 타고가면서 블록들을 확인할 수 있기에, 일종의 연결리스트라고 볼 수 있다.- 앞서의 "추적"에 해당
- n 사이즈의 공간을 할당할 때마다 헤더에 써 있는 정보를 선형으로 검색해가며 n을 수용할 수 있는 공간을 찾는다
- n을 수용할 수 있는 공간이 나오는 즉시 탐색을 멈추고 해당 공간을 선택한다.
- 앞서의 "배치"에 해당한다, 가장 처음으로 만족되는 공간을 사용하기때문에 first-fit
방식. - 해당 공간에 원하는 사이즈만큼을 배치하고도, 다른 블록이 들어갈 공간이 남으면 이를 분할해준다
- 앞서의 "분할"에 해당 - 배치하려는 사이즈가 없어서 heap의 Program break를 증가시키거나, 특정 블록을 free 시켜주었을때에는, 앞/뒤의 또 다른 가용블록을 찾아서 이와 연결해준다.
- 이것이 "연결"에 해당- 이때 뒤 블록의 정보를 빠르게 확인하기 위해 경계태그인 푸터를 사용
할당할 블록을 찾기위해서 가용 블록을 검색하는 선형시간이 걸리고, 이때, 가용 블록만이 아닌 모든 블록을 탐색하기에, 효율적인 방법은 아니다.
실제로 util점수는 44점으로 그렇게 낮지 않은 데 비해서, 시간당 처리율을 나타내는 thru 점수가 18점으로 낮게 나왔다.
- 따라서 검색 방식을 next-fit으로 바꾸면, 꽤 높은 점수 상승을 볼 수 있다!!
Explicit
explicit - 구현 코드 보기(util 42, thru 40 점)
- 앞서와 달리, 가용 블록들을 실제 포인터를 가진 연결리스트를 통해 관리한다. 추적 방식에서 차이가 있다.
- 따라서, first-fit을 사용시, 선형 검색을 하는 것은 똑같다만, 검색하는 원소들의 수에서 이점이 있다.
- 일단은 가용 연결리스트의 시작점이 필요하다. 이를 전역 정적 변수로 선언해주자. 나는 free_listp로 두었다.
- 이때, 가용 연결리스트를 관리하기 위해서, bp위치에는 나의 이전 가용 블록으로 가는 SUCC 포인터를, bp+1워드 위치에는 이후 가용 블록으로 가는 PREC 포인터를 둔다. 그래서 최소 4워드가 필요하다(헤더, 푸터, 앞과 뒤 포인터)
- 나는 Insertion method에서 LIFO를 선택했기 때문에, 새로 생성된 가용 블록은 free 리스트의 맨 처음에 삽입한다.
- free block을 coalesce하는 과정에서 합쳐지는 블럭들을 연결리스트에서 제거해줘야 한다
next-fit에 대한 이해도 없이, explicit을 next-fit 으로 구현해보려고 애를 썼으나, segfault를 극복하지 못했다.
그냥 next-fit 한번 해봐야지 ~ 하고 시작한 일이 잘 마무리가 되지 않아서 힘들었다.
- 생각해보니 LIFO와 next-fit을 병행하면 LIFO를 사용하는 이유가 퇴색된다
- LIFO를 사용하는 이유는 최근에 사용된 블록들을 연결리스트의 앞에 둠으로써 블록의 free를 O(1)으로 유지하고, 최근 블록들을 먼저 검색하는 것이 목적인데, next-fit을 사용하면 해당 목적이 퇴색된다
- 굳이 explicit에 next-fit을 적용하려고 들지는 말자...(?)
Segregated
- 인터넷에 흔히 돌아다니는 98점짜리 코드를 보고, 이해해보려 했으나, asize를 120 기준으로 나눠주는 것과, RA태그의 존재 이유를 납득할 수가 없었다.
- 포기할까..하다가 해당 레포에 star를 찍은 사람들 중, 정글 선배님을 발견했는데, 이분은 RA태그를 빼고 코드를 작성했더라, 그래서 빼줬는데도 같은 점수가 나왔다. 아마 98점 고득점의 원인은 다른 부분이었을듯 하다.
- place함수에서 asize 120을 기준으로 앞, 뒤 할당 순서를 바꿔주는 부분도 이해가 가지 않아서 뺐다.. 이 부분은 제거해주니 점수가 조금 떨어졌다. 여기까지 이해해보는게 목표였는데 아쉽다.
Segregated free list - 구현 코드보기 : util 54, thru 40점
-
Explicit과 비슷하나, 연결리스트가 여러개 있고, 이 여러개 연결리스트의 배열을 추가적으로 관리해주면 된다
-
해당 코드에서는 2의 n제곱을 기준으로 연결리스트에 담을 사이즈를 구분해주었다.
-
예를 들면, 2^4 ~ 2^5 -1 바이트 까지 특정 연결리스트에서 관리해주는 식이다
-
그래서 malloc, 연결리스트에서 노드를 삽입 /삭제할 때 2개의 과정을 거쳐야한다.
- 원하는 size를 범위로 포함하는 연결리스트를 찾을때까지 seg_list 배열을 이동한다
- 해당 seg_list(오름차순으로 정렬된)를
뒤에서부터 탐색한다. 제일 큰 사이즈부터 탐색하는거다.
- 인줄 알았으나, 내 착각이었고, 그냥 오름차순으로 정렬된 연결리스트를 작은것부터 탐색하는게 맞다.
- 다만 방향은 뒤로(PREDECESSOR로)가는게 맞다.
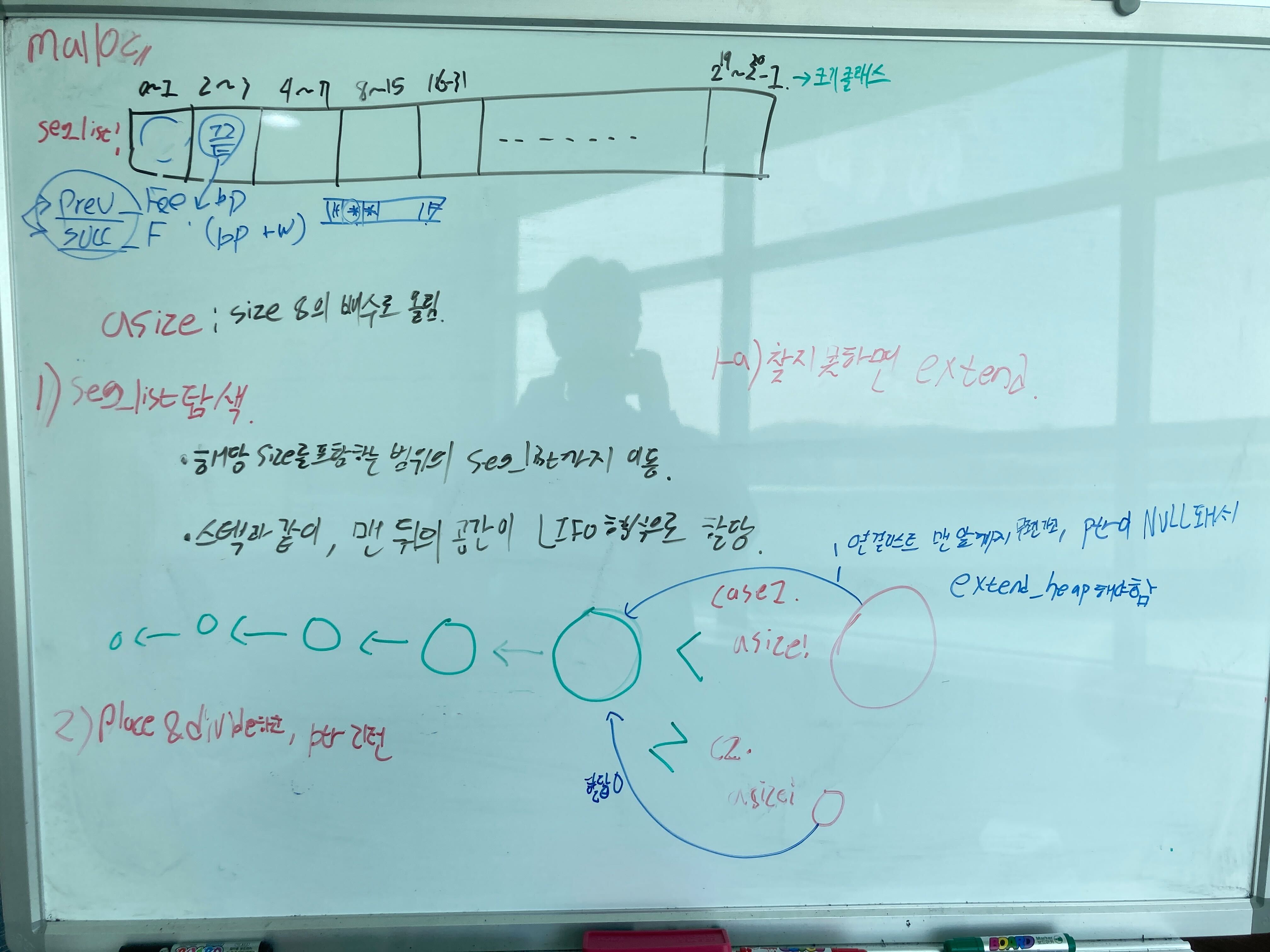
대강 이런식으로..
- 그니깐 이 그림도 틀린거다..
- 아무튼 이를 좀 개선해보고자 했으나.. segfault에 뚜드려 맞고 포기했다
- 사실 이번주 내내 이런 식이었다. 혼자는 못짜겠음 -> 남의 코드를 봄 -> 뭔가 맘에 안듬 -> 고쳐보려다가 실패함...
realloc부분도 이해하기가 쉽지 않았다.
- 다음 블록이 가용하지 않다면, malloc을 통해 공간을 따로 할당받고, 해당 위치에 기존 값들을 복사해준다
- 다음 블록이 가용하거나 재할당하려는 현재 블럭이 힙의 마지막에 위치할때가 문제다
- 현재 + 다음 블럭의 크기가 재할당하려는 사이즈보다 크다면 그냥 그만큼을 블럭의 사이즈로 잡아주면 된다
- 현재 + 다음 블럭의 크기가 재할당하려는 사이즈보다 작다면, extend를 때려준다
- CHUNKSIZE(2의12승) 과 부족한 크기를 비교해서, 무엇이 더 크냐에 따라서 extend의 크기가 결정되는 방식이다.
코드에서는 해당부분인데, 어쩌다보니 주석을 잔뜩 달아놨다.
/* Check if next block is a free block or the epilogue block */
if (!GET_ALLOC(HDRP(NEXT_BLKP(ptr))) || !GET_SIZE(HDRP(NEXT_BLKP(ptr)))) { // 현재 ptr 다음 블록이 free이거나 에필로그 블록
/* 1. 다음 블록을 사용하는 경우 */
/* remainder: 현재 블록에 가용한 다음 블럭의 크기를 더한것에서, 새로 할당할 사이즈를 뺀 것 */
remainder = GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr))) - new_size;
if (remainder < 0) { // ,...?
extendsize = MAX(-remainder, CHUNKSIZE); // remainder의 역수와 CHUNKSIZE중 더 큰것 만큼
if (extend_heap(extendsize) == NULL) // 힙을 연장해줌
return NULL;
remainder += extendsize; // 연장한만큼 remainder에 더해준다
}
delete_node(NEXT_BLKP(ptr));
/* 경우에 따른 블럭의 크기 */
// if ptr+next 크기 >= new_size:
// ptr + next 블럭 사이즈만큼 사이즈 잡아줌
// if -remainder > CHUNK && ptr+next 크기 < new_size 크기:
// ptr + next - new + (-ptr - next + new) + new_size = new_size 만큼 사이즈 잡아줌
// elif -remainder < CHUNK && ptr+next 크기 < new_size 크기:
// ptr + next - new_size + CHUNK + new_size = ptr + next + CHUNKSIZE 만큼 사이즈 잡아줌
PUT(HDRP(ptr), PACK(new_size + remainder, 1));
PUT(FTRP(ptr), PACK(new_size + remainder, 1));
} else { // 다음 블록이 할당블록
/* 2. 다음 블록을 사용하지 않는 경우 */
new_ptr = mm_malloc(new_size - DSIZE); // 헤더,푸터만큼의 사이즈 빼고 새로 할당해줌
memcpy(new_ptr, ptr, new_size);
mm_free(ptr);
}(밑 사진은 그냥 그린게 아까워서...)
잡설
- 이번주는 내가 생각해서 코드를 작성한게 거의 없다. 개념을 공부하고, 구현하려고 딱 앉으니까 생각나는게 아~무것도 없어서 다른사람들 코드를 좀 봤다.
- 남의 코드를 한번 보니까 그 이후로 멈출수가 없더라..
- 구현하는 범위를 줄이더라도, 내 힘으로 해결했어야 하는게 맞는건지, 아니면 남의 코드 보고 이해하고 조금씩 고쳐보려고 하는게 맞는건지, 솔직히 잘 모르겠다.
- 다음주..다음주는 잘해보자..
