페이징: 더 빠른 변환 (TLB)
페이징은 잘못 설계하면 상당한 성능 저하를 가져올 수 있다.
- 페이징은 프로세스 주소공간을 고정 크기의 페이지로 나누고, 각 페이지의 실제 위치(매핑 정보)를 메모리에 저장
- 매핑 정보를 저장하는 자료구조를 페이지 테이블이라고 함
- 근데 이 페이지 테이블이 잡아먹는 메모리 공간이 매우 크고
- 그리고 페이지 테이블 접근을 위한 메모리 읽기 작업의 비용이 매우 커 성능 저하를 유발함
- 모든 load/store 명령어 실행이 추가적인 메모리 읽기를 수반한다고 생각하면, 굉장한 성능저하가 있을 것
핵심 질문: 주소 변환 속도를 어떻게 향상할까?
- 주소 변환을 어떻게 빨리 할 수 있을까?
- 페이징에서 발생하는 추가 메모리 참조를 어떻게 피할 수 있을까?
- 어떤 하드웨어가 추가로 필요할까?
- 운영체제는 어떤 식으로 개입?
운영체제의 실행 속도를 개선하려면 하드웨어의 도움을 받아야 한다. 따라서 주소 변환을 빠르게 하기 위한 Translation-Lookaside Buffer (TLB)를 도입할 것이다.Translation-Lookaside Buffer (TLB)
- TLB는 칩의 메모리 관리부(MMU)의 일부이며, 자주 참조되는 가상 주소-실주소 변환 정보를 저장하는 하드웨어 캐시이다.
- 주소-변환 캐시(address-translation cache)가 좀 더 적합한 명칭
- 가상 메모리 참조 시, 하드웨어는 먼저 TLB에 원하는 변환 정보가 있는지 확인
- 만약 있다면 페이지 테이블에서 검색을 하지 않고 변환을 빠르게 수행
1. TLB의 기본 알고리즘
아래의 TLB 동작 과정에서 주소 변환부는 단순한 선형 페이지 테이블로, TLB는 하드웨어로 관리되는 TLB로 구성되어 있다.
//가상 주소에서 VPN 추출
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
// TLB에 VPN 있는지 확인
(Success , TlbEntry) = TLB_Lookup(VPN)
if (Success == True) { // TLB 히트
if (CanAccess(TlbEntry.ProtectBits) == True) {
Offset = VirtualAddress & OFFSET_MASK
// TLB Entry에 있는 PFN 추출 가능, 물리 주소로 만들기
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
// 메모리 접근
AccessMemory(PhysAddr)
}
else
RaiseException(PROTECTION_FAULT)
}
else { // TLB 미스
// 페이지 테이블 항목(PTE)의 주소 형성
PTEAddr = PTBR + (VPN * sizeof(PTE))
// 페이지 테이블에 접근
PTE = AccessMemory(PTEAddr) // <- 많은 시간 소요!
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else {
// 해당 변환 정보를 TLB로 삽입
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
// TLB 갱신되었으므로 명령어 재실행
RetryInstruction()
}
}- 가상 주소에서 VPN 추출
- TLB에 VPN이 있는지 확인
- 있으면 TLB 히트!
-> TLB Entry에 변환값이 존재하므로 PFN 추출 가능
-> PFN과 오프셋을 합쳐 물리 주소 만들기
-> 물리 주소로 메모리에 접근 - 없으면 TLB 미스..
-> PTE 주소를 만들고 페이지 테이블에 접근 (많은 시간 소요됨)
-> 해당 변환 정보(PTE)를 TLB에 삽입
-> 다음번 명령어 실행때는 TLB에 변환정보가 있으므로, 메모리 참조가 빠르게 처리됨
- 있으면 TLB 히트!
TLB 역시 "주소 변환 정보가 대부분의 경우 캐시에 있다"는 가정을 전제로 만들어졌다.
- TLB는 프로세싱 코어와 가까운 곳에 위치
- 매우 빠른 하드웨어로 구성되기 때문에, 주소 변환 작업은 그다지 부담스러운 작업이 아님
- 반면, TLB 미스가 발생하면 페이징 비용 커지므로, TLB 미스가 발생하는 경우를 최대한 피해야 한다.
2. 예제: 배열 접근
TLB 작동 과정을 좀 더 명확히 알아보자. 이 예제에서는 간단한 가상 주소 트레이스를 대상으로 TLB로 인한 성능 개선을 알아볼 것이다.
- 가상 주소 100번지부터 10개의 4바이트 크기의 정수 배열
- 가상 주소 공간의 크기: 8비트
- 페이지 크기: 16바이트 (4비트 오프셋)
- 가상 주소는 4비트 VPN(16개의 가상 페이지들을 표현)과 4비트 오프셋(한 페이지는 16바이트)으로 구성
- 16개의 페이지로 구성된 가상 주소 공간
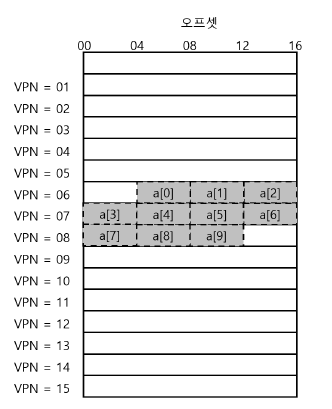
- 배열의 첫 항목
a[0]은VPN=06, 오프셋=04에서 시작 - 이 배열을 반복문으로 한번 순회한다고 하자
for (i = 0; i < 10; i++) sum += a[i]; - 처음
a[0]에 접근
-> VPN=06 추출
-> TLB 검색 (처음엔 TLB 완전히 초기화되어있다 가정)
-> TLB 미스
-> VPN 06번의 물리 페이지 번호를 찾아 TLB 갱신 a[1],a[2]에 접근할 때는 TLB 히트 (a[0]과 같은 페이지)a[3]에 접근할 때에는 TLB 미스
-> VPN 07번의 물리 페이지 번호를 찾아 TLB 갱신
=> 이후a[4~6]에 접근할 때에는 TLB 히트
- 배열의 첫 항목
- 이처럼 TLB는 공간 지역성(spatial locality)로 인해 성능 개선 가능
- 배열의 항목들이 페이지 내에 서로 인접해 있기 때문에, 페이지에서 첫 번째 항목을 접근할 때만 TLB 미스가 발생
- 페이지의 크기가 크면 TLB 미스 횟수가 줄어든다
- 페이지 접근 시 한 번의 미스만 발생하기 때문
- 일반적인 경우 페이지는 4KB
- 만약 예제 프로그램이 루프 종료 후에도 배열을 사용한다면, 모든 주소 변환 정보가 TLB에 탑재되어 있으므로 성능 더 좋아짐
- TLB가 모든 주소 변환 정보를 저장할 정도로 크다면 시간 지역성(temporal locality)로 인해 히트율이 높아짐
- 시간 지역성: 한번 참조된 메모리 영역이 짧은 시간 내에 재 참조되는 현상을 일컫는다.
다른 캐시와 마찬가지로, TLB의 성공 여부는 프로그램의 공간 지역성과 시간 지역성 존재 여부에 달려있다.
3. TLB 미스는 누가 처리할까
1. 하드웨어에서 처리 (CISC)
- Complex Instruction Set Computers
- 운영체제 개발자들이 이상한 방법을 많이 써서 하드웨어 개발자들이 그들을 신뢰할 수 없었기에, TLB 미스를 하드웨어가 처리하도록 설계
- 하드웨어에서 이를 처리하려면 페이지 테이블에 대한 명확한 정보를 가지고 있어야 함
(page-table base register를 통해 메모리 상 위치 파악) - 미스 발생 시 하드웨어가 하는 일
1) 페이지 테이블에서 원하는 페이지 테이블 엔트리 찾기
2) 필요한 변환 정보 추출
3) TLB 갱신
4) TLB 미스가 발생한 명령어 재실행 - 인텔 x86 CPU가 하드웨어로 관리되는 TLB의 대표적인 예
- x86 CPU는 멀티 레벨 페이지 테이블을 사용 (다음 장에 계속)
2. 소프트웨어에서 처리 (RISC)
- Reduced Instruction Set Computing
- 소프트웨어 관리 TLB를 사용
- 미스 처리 과정
1) TLB에서 주소 찾는 것 실패
2) 하드웨어는 예외 시그널 발생
3) 예외 시그널 받은 운영체제는 명령어 실행을 중지
4) 실행 모드를 커널 모드로 변경하여 커널 코드 실행 준비
5) 트랩 핸들러 실행하여 페이지 테이블에서 변환 정보 찾기
6) 트랩 핸들러가 특권 명령어(privileged instruction) 사용하여 TLB 갱신 후 return
7) 트랩 핸들러에서 리턴 후 하드웨어가 명령어 재실행 - 소프트웨어 처리 방식의 장점
- 유연성 - 하드웨어 변경 없이 페이지 테이블 구조 변경 가능
- 단순함 - 미스 발생 시 하드웨어는 별로 할 일 없음
(예외 발생 시 운영체제의 TLB 미스 핸들러가 나머지 일 처리)
시스템 콜 호출 트랩 핸들러 vs TLB 미스 처리 트랩 핸들러
- 시스템 콜 호출 시 사용되는 트랩 핸들러
- 트랩 핸들러에서 리턴 후 시스템 콜을 호출한 명령어의 "다음" 명령어를 실행
- 일반적인 프로시저 콜과 동일하게 프로시저를 호출한 다음 라인부터 실행
- TLB 미스 처리 트랩 핸들러
- 트랩에서 리턴하면 트랩을 발생시킨 명령을 "다시" 실행, 재실행 시 TLB 히트 발생
- 트랩 발생 시 운영체제는 Program Counter 값을 저장하여 트랩 핸들러 종료됐을 때 다시 실행
- 운영체제는 트랩 발생 원인에 따라 현재 명령어의 PC값 혹은 다음 명령어의 PC값을 저장해야 함
TLB 미스 핸들러를 실행할 때, TLB 미스가 무한 반복되지 않도록 주의
- TLB 미스 핸들러를 접근하는 과정에서 TLB 미스가 발생하는 상황
- TLB 미스 핸들러를 물리 메모리에 위치시켜 해결 가능
- 이 경우 해당 TLB 미스 핸들러는 unmap 되어 있으며 주소 변환이 필요 없다.
- 연결(wired) 변환으로 해결
- TLB의 일부를 핸들러 코드 주소 저장용으로 영구 할당
- 이 경우 TLB 핸들러는 항상 TLB에서 히트
4. TLB의 구성: 무엇이 있나?
하드웨어 TLB의 구성
- 일반적인 TLB는 32, 64, 128개의 엔트리를 가짐
- 완전 연관(flully associative) 방식으로 설계됨
- 완전 연관 방식에서 변환정보는 TLB 내에 어디든 위치 가능, 원하는 변환 정보를 찾는 검색은 TLB 전체에서 병렬적으로 수행
- TLB의 구성 -
VPN | PFN | other bits- 각 항목마다 VPN, PFN가 있음
- 하드웨어 측면에서 TLB는 완전 연관 캐시
(변환 주소를 찾을 때 하드웨어는 TLB의 각 항목을 동시에 검색) other bits- valid bit: 유효성 여부
- protection bit: 접근(R/W/X) 여부
- address-space identifier: 주소 공간 식별자
- dirty bit 등
5. TLB의 문제: 문맥 교환
TLB를 사용하게 되면 프로세스 간 (주소 공간들로 인해) 문맥 교환 시, 새로운 문제가 등장한다.
- TLB에 있는 가상주소-물리주소 간의 변환 정보는, 그것을 탑재시킨 프로세스에서만 유효
- 새 프로세스에서 이전에 실행하던 프로세스의 변환 정보를 사용하지 않도록 해야함
- 두 프로세스 P1, P2의 TLB 예시
- P1의 페이지 테이블 내용:
VPN=10 -> PFN=100 - P2의 페이지 테이블 내용:
VPN=10 -> PFN-170 -
VPN PFN valid prot 10 100 1 rwx -- --- 0 --- 10 170 1 rwx -- --- 0 --- - 이 경우 VPN 10에 대한 변환 정보가 두개 존재하는 것
- 그러나 어떤 프로세스를 위한 항목인지 알 길이 없음...
- P1의 페이지 테이블 내용:
핵심 질문: 문맥 교환 시 TLB 내용을 어떻게 관리?
문맥 교환 시 실행될 프로세스에게는 이전 프로세스가 사용한 TLB 정보는 의미가 없다.
문맥 교환 시 기존 TLB 내용을 비우는 방법
- TLB의 valid bit을 모두 0으로 설정하기
- 확실한 방법이지만, 새 프로세스 실행될 때 TLB 미스가 발생
- 문맥 교체가 빈번히 발생한다면 성능에 큰 부담
주소 공간 식별자(address space identiier, ASID) 필드를 추가
- 모두 0으로 바꾸는 대신, ASID 필드를 추가하여 TLB의 내용을 보존
- 8비트의 작은 프로세스 식별자
-
VPN PFN valid prot ASID 10 100 1 rwx 1 - - 0 - - 10 170 1 rwx 2 - - 0 - - - ASID 쓰려면, 하드웨어는 현재 어떤 프로세스가 실행중인지 파악해야 함
- 이를 위해 문맥 전환시, 운영체제는 새로운 ASID 값을 정해진 레지스터에 탑재
공유 페이지
- TLB의 두 항목이 매우 유사한 경우
-
VPN PFN valid prot ASID 10 101 1 r-x 1 - - 0 - - 50 101 1 r-x 2 - - 0 - - - 두 개의 다른 VPN을 갖는 두 개의 다른 프로세스들의 두 항목이 동일한 물리 페이지를 가리킴
- 코드 페이지를 공유하는 경우에 발생할 수 있음
6. Issue: 교체 정책
모든 캐시가 그러하듯이 TLB에서도 캐시 교체(cache replacement) 정책이 매우 중요하다. TLB에 새로운 항목을 탑재할 때, 현재 존재하는 항목 중 하나를 교체 대상으로 선정해야 한다. 어느 것을 선택해야 할까?
핵심 질문 : TLB 교체 정책은 어떻게 설계하는가
TLB에 새로운 항목을 추가할 때 어떤 항목을 교체해야 할까? 목표는 미스율을 줄여 (또는 히트 비율을 증가시켜서) 성능을 개선하는 것이다.
최저 사용 빈도(least-recently-used, LRU)
- 지역성을 최대한 활용하는 것이 목표
- 사용되지 않은지 오래된 항목일수록, 앞으로 사용될 가능성 낮음 = 교체 대상으로 적합
랜덤 정책- 교체 대상을 무작위로 정함
- 잘못된 결정을 내리기도 하지만, 예상치 못한 예외 상황의 발생을 피함
- LRU 같은 경우에, 용량 n인 TLB에 n+1개의 페이지들에 대해 반복문 수행하면 최악의 TLB 미스 생성
- 그에 반해 랜덤의 경우 훨씬 잘 작동
7. 실제 TLB
MIPS R4000이라는 프로세서를 예로 삼아 실제 TLB가 어떻게 생겼는지 알아보자

- 32비트 주소 공간
- 4KB 페이지
VPN 19비트, 오프셋 12비트, 남은 1비트는 사용자인지 커널인지 판단 - PFN 24비트 할당
따라서 64GB(개의 4KB 페이지들)의 물리 메모리 지원 가능 - 중요 비트들
- 전역 비트(G): 프로세스들 간에 공유되는 페이지를 위해 사용
- ASID 필드를 위한 8비트 할당 - 운영체제는 ASID로 주소공간 구분
- 일관성 비트(C): 하드웨어에 어떻게 캐시되어있는지 판별해주는 3개의 비트
- 더티 비트(D): 페이지 갱신 시 세팅3
- 유효 비트(V): 항목에 유효한 변환정보 존재하는지 나타냄
- 마지막 64번째 비트는 사용하지 않는다
- MIPS의 TLB들은 일반적으로 32개 또는 64개의 항목으로 구성
- 대부분은 사용자 프로세스들이 사용
- 몇 개는 운영체제를 위해 예약 (wired 레지스터 등)
- TLB 갱신을 위한 명령어
TLBP: 특정 변환 정보 존재하는지 탐색TLBR: TLB 항목의 내용을 레지스터로 읽는데 사용TLBWI: 특정 TLB 항목 교체TLBWR: 임의의 TLB 항목 교체- 이 명령어들은 특권 명령어로 실행권한(privileged)을 가지고 있어야 함
