이번 장에서는 뉴스 피드 시스템 설계 문제를 살펴볼 것이다. 페이스북에서 설명하는 뉴스 피드(news feed)는, 홈 페이지 중앙에 지속적으로 업데이트되는 스토리들이라고 볼 수 있다. 그 내용으로는 사용자 상태 정보 업데이트, 사진, 비디오, 링크, 팔로워, 페이지, 좋아요 등을 포함한다.
문제 이해 및 설계 범위 확정
요구사항
- 지원 환경: 모바일 앱과 웹을 둘 다 지원
- 주요 기능: 사용자 뉴스 피드 페이지에 스토리 업로드, 친구들이 올리는 스토리 조회 가능
- 뉴스 피드 정렬기준: 시간 흐름 역순으로 정렬
- 사용자 최대 친구 수: 5000명
- 트래픽 규모: 매일 1000만명 방문
- 컨텐츠 형식: 이미지, 비디오 등 미디어 파일을 스토리로 업로드 가능
개략적 설계안 제시
설계안은 피드 발행과 뉴스 피드 생성의 두 가지 부분으로 나뉘어서 생각해볼 것이다.
- 피드 발행: 사용자가 스토리를 포스팅 시 해당 데이터를 캐시와 DB에 기록, 새 포스팅은 친구의 뉴스 피드에도 전송
- 뉴스 피드 생성: 모든 친구의 포스팅을 시간 흐름의 역순으로 모아서 생성
뉴스 피드 API
뉴스 피드 API는 HTTP 프로토콜 기반으로 상태 정보 업데이트, 뉴스 피드 조회 등 다양한 작업을 수행할 수 있어야 한다. 가장 중요한 두 API인 피드 발행과 피드 읽기 API를 살펴보자.
피드 발행 API
POST /v1/me/feed
- params
- content(body): 포스팅 내용
- Authorization 헤더: API 호출 인증용
- content(body): 포스팅 내용
피드 읽기 API
GET /v1/me/feed
- params
- Authorization 헤더: API 호출 인증용
- Authorization 헤더: API 호출 인증용
피드 발행
피드 발행 시스템의 개략적 형태는 다음과 같을 것이다. 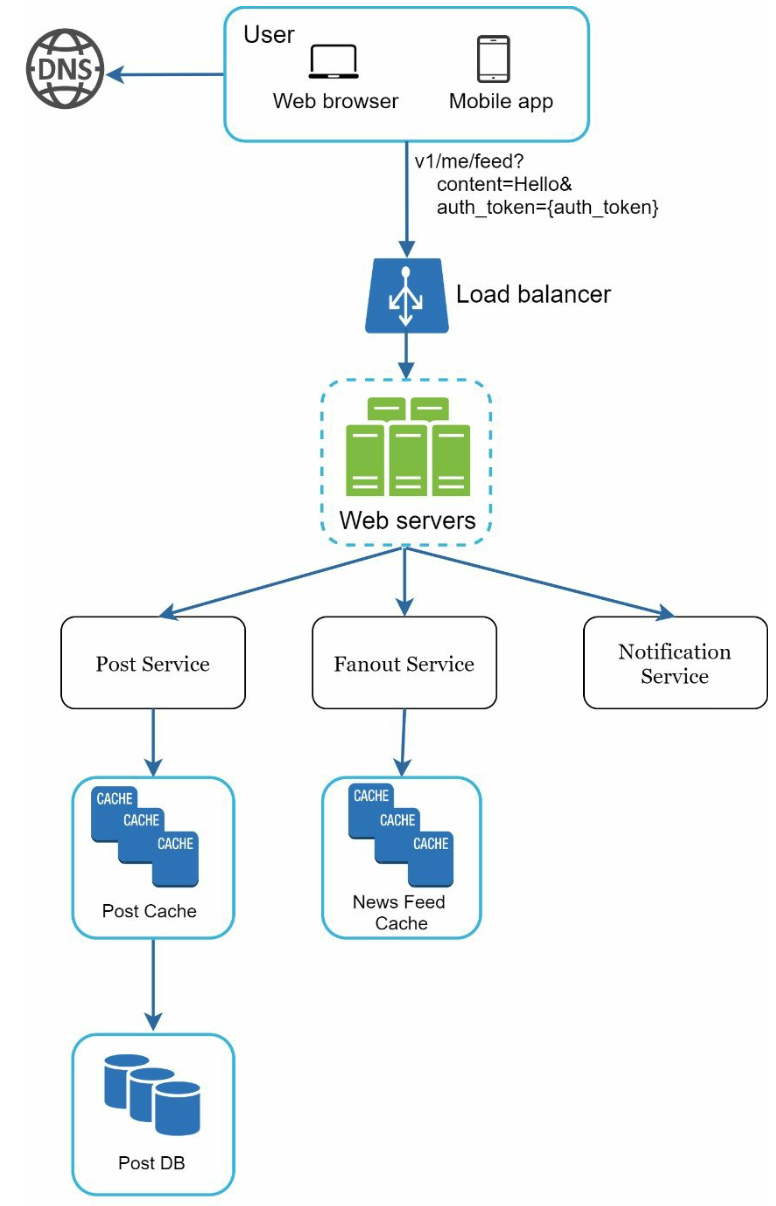
- 사용자: 웹 또는 앱에 새 포스팅을 올리는 주체로,
POST /v1/me/feedAPI 사용 - 로드밸런서: 트래픽을 웹 서버로 분산
- 웹 서버: HTTP 요청을 내부 서비스로 중계
- 포스팅 저장 서비스: 새 포스팅을 DB와 캐시에 저장
- 포스팅 전송 서비스: 새 포스팅을 친구의 뉴스 피드에 push (뉴스 피드 데이터는 캐시에 보관하여 속도 향상)
- 알림 서비스: 친구들에게 새 포스팅이 올라왔음을 알리거나, 푸시 알림 전송 역할
뉴스 피드 생성
사용자가 보는 뉴스 피드가 생성되는 개략적인 형태는 다음과 같을 것이다.
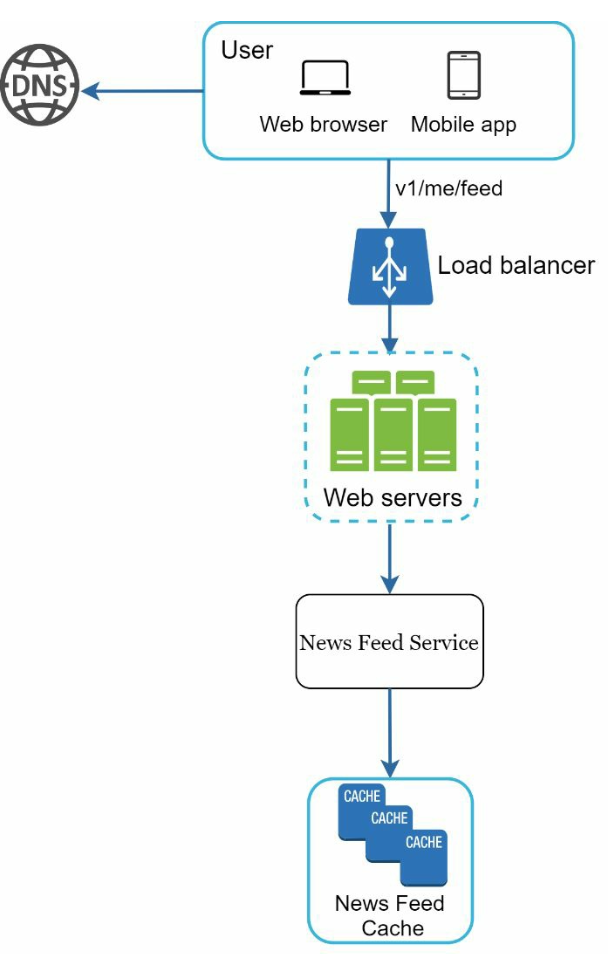
- 사용자: 뉴스 피드를 읽는 주체로,
GET /v1/me/feedAPI 사용
- 로드밸런서: 트래픽을 웹 서버로 분산
- 웹 서버: 트래픽을 뉴스 피드 서비스로 전송
- 뉴스 피드 서비스: 캐시에서 뉴스 피드를 가져오는 서비스
- 뉴스 피드 캐시: 뉴스 피드를 렌더링할 때 필요한 피드 ID 보관
상세 설계
피드 발행 흐름 상세 설계
대부분의 컴포넌트는 개략적 설계안에서 다룬 정도로 충분하여, 웹 서버와 포스팅 전송 서비스(fanout service)에 초점을 맞췄다.
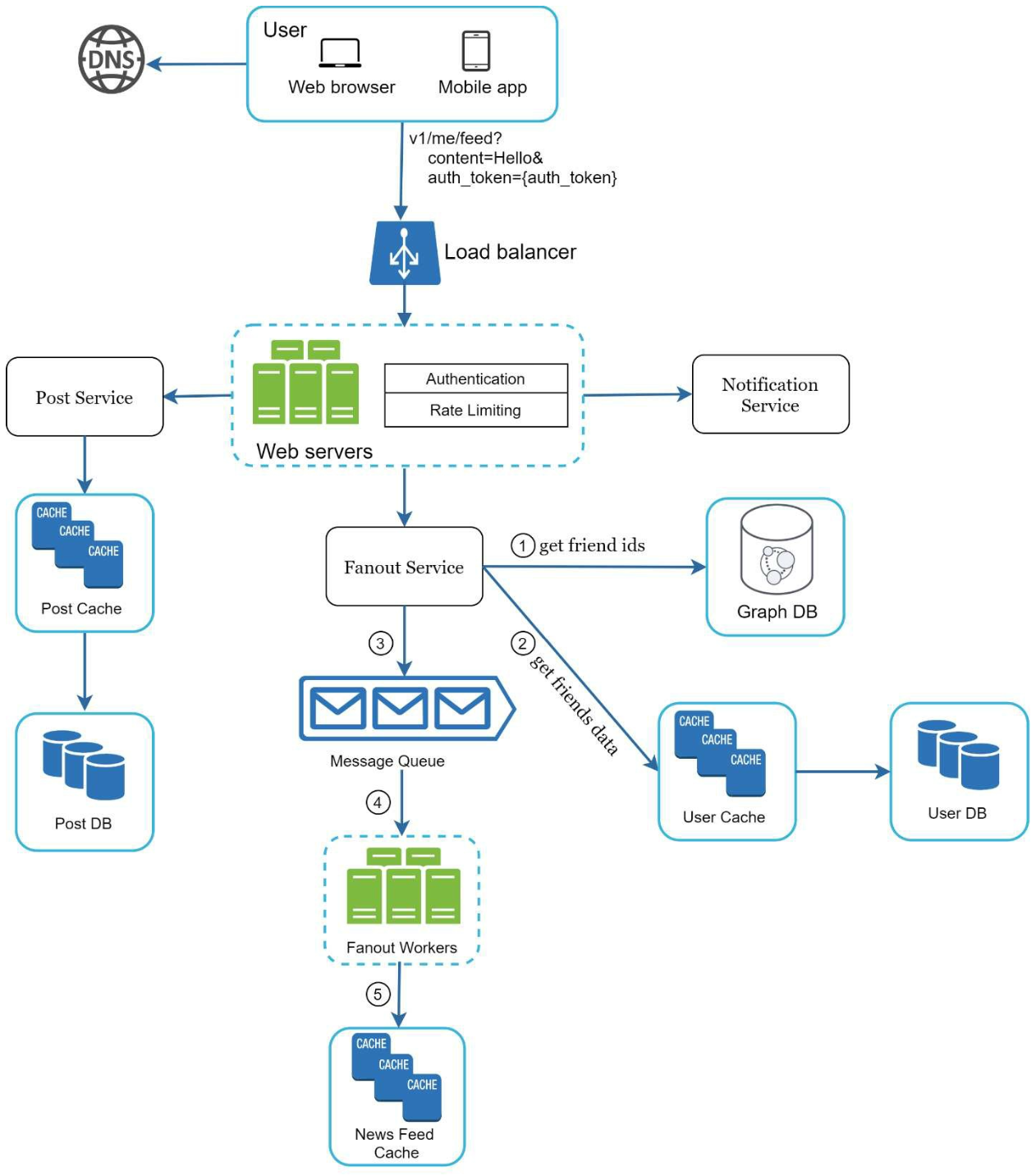
- 웹 서버
- 웹 서버는 클라이언트와 통신할뿐만 아니라 인증이나 처리율 제한 기능도 수행
- 올바른 인증 토큰을 Authorization 헤더에 넣고 API 호출
- 스팸 및 유해 컨텐츠가 자주 올라오는 것을 방지하기 위해 특정 기간 동안 올릴 수 있는 포스팅 수에 제한
- 올바른 인증 토큰을 Authorization 헤더에 넣고 API 호출
- 웹 서버는 클라이언트와 통신할뿐만 아니라 인증이나 처리율 제한 기능도 수행
- 포스팅 전송(팬아웃) 서비스
- 팬아웃(fanout): 어떤 사용자의 새 포스팅을 그 사용자와 친구 관계에 있는 모든 사용자에게 전달하는 과정
- 쓰기 시점 팬아웃 모델(push model): 새로운 포스팅을 기록하는 시점에 뉴스 피드 갱신
- 뉴스 피드 실시간 갱신, 친구 목록에 있는 사용자에게 즉시 전송
- 새 포스팅이 기록되는 순간에 뉴스 피드가 이미 갱신되므로(pre-computed) 빠른 읽기 가능
- 친구가 많을수록 친구들의 뉴스 피드를 갱신하는 데 많은 시간이 소요될 수 있음 (핫키 문제)
- 서비스를 자주 이용하지 않는 사용자의 피드까지 갱신하므로 컴퓨팅 자원 낭비
- 뉴스 피드 실시간 갱신, 친구 목록에 있는 사용자에게 즉시 전송
- 읽기 시점 팬아웃 모델(pull model): 피드를 읽는 시점(홈페이지나 타임라인 로딩 시점 등)에 뉴스 피드 갱신
- 비활성화된 사용자나 서비스에 거의 로그인하지 않는 사용자의 경우, 로그인 전까지 컴퓨팅 자원 소모하지 않음
- 데이터를 친구 각각에 푸시하지 않으므로 핫키 문제가 발생하지 않음
- 뉴스 피드를 읽는 데 많은 시간이 소요될 수 있음
- 비활성화된 사용자나 서비스에 거의 로그인하지 않는 사용자의 경우, 로그인 전까지 컴퓨팅 자원 소모하지 않음
- 팬아웃(fanout): 어떤 사용자의 새 포스팅을 그 사용자와 친구 관계에 있는 모든 사용자에게 전달하는 과정
읽기 시점 팬아웃 모델은 위 그림에서 팬아웃 서비스가 없는 그림이 될 것으로 추정된다.
- 발행 시점에 뉴스 피드 캐시를 갱신할 필요가 없기 때문이다.
- 추가 조사 필요
본 설계안의 경우 쓰기 시점 팬아웃 모델과 읽기 시점 팬아웃 모델을 결합하여 장점을 취하고 단점을 버리는 전략을 취하도록 하겠다.
- 빠르게 뉴스 피드를 가져올 수 있도록 절충하는 방법
- 대부분의 사용자의 경우 → 피드 업로드 시 뉴스 피드를 즉시 갱신하는 push model 사용
- 친구나 팔로어가 아주 많은 사용자의 경우 → 읽기 시점 피드를 갱신하는 pull model 사용
- 대부분의 사용자의 경우 → 피드 업로드 시 뉴스 피드를 즉시 갱신하는 push model 사용
- 안정 해시를 통해 요청과 데이터를 보다 고르게 분산하여 핫키 문제를 줄일 수 잇음
앞서 제시한 상세 설계안에서 팬아웃 서비스에 관한 부분에 대해서 집중적으로 살펴보자.
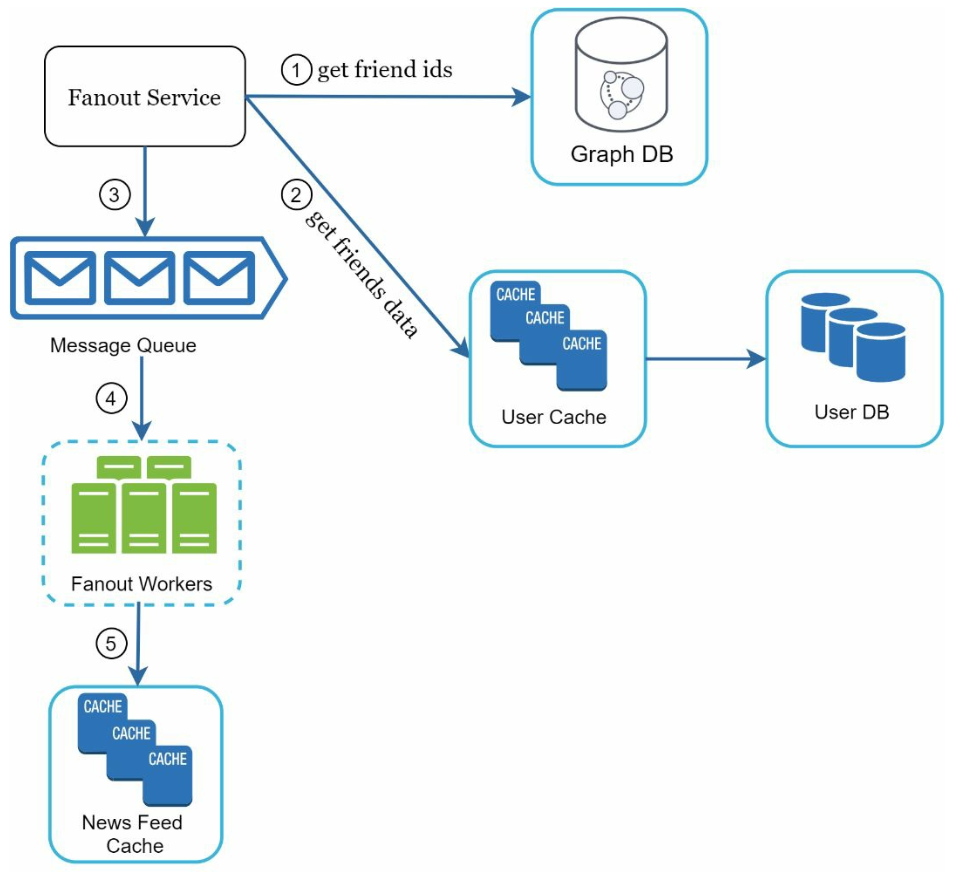
팬아웃 서비스 동작 과정
- 그래프 DB에서 친구 ID 목록을 가져옴 (친구 관계나 친구 추천 관리용으로 적합)
- 사용자 정보 캐시에서 친구 정보를 가져오고, 사용자 설정(숨김처리 등)에 따라 친구 중 일부를 제외
- 친구 목록과 새 스토리의 포스팅 ID를 메시지 큐에 넣음
- 팬아웃 작업 서버가 뉴스 피드 데이터를 캐시에 넣음
- 뉴스 피드 캐시는
<포스팅ID, 사용자ID>의 순서쌍만을 보관 - 메모리 절약을 위해 최소화 및 크기 제한
- 대부분의 사용자는 최신 스토리를 보려고 하기 때문에 캐시 미스가 날 확률은 낮음
- 뉴스 피드 캐시는
피드 읽기 흐름 상세 설계
뉴스 피드를 읽는 과정 전반의 상세 설계안은 다음과 같다.
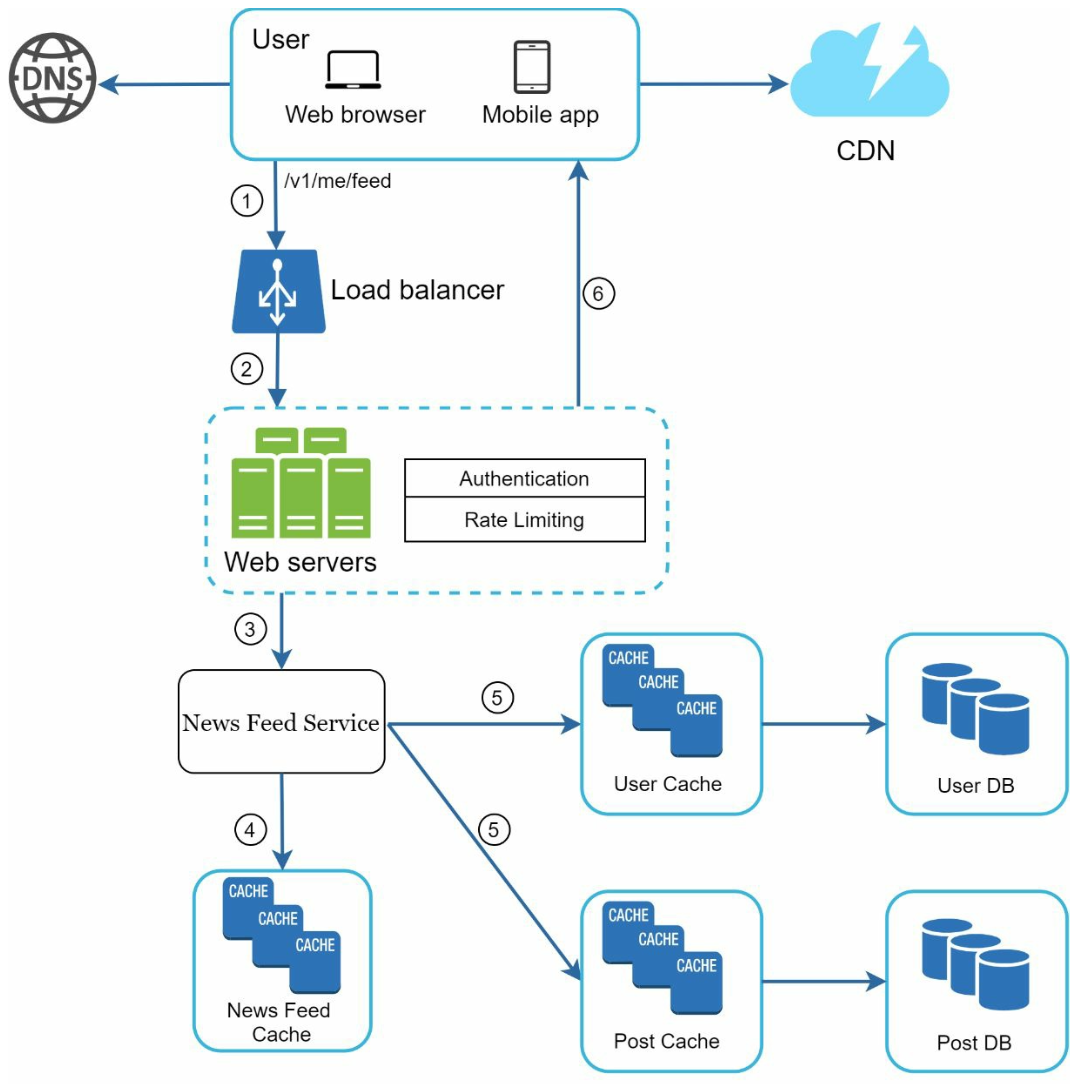
클라이언트가 뉴스 피드 읽는 과정
- 사용자가 뉴스 피드 읽기 요청 전송
GET /v1/me/feed - 로드 밸런서가 요청을 웹 서버 중 하나로 보냄
- 웹 서버는 피드를 가져오기 위해 뉴스 피드 서비스 호출
- 뉴스 피드 캐시에서 포스팅 ID 목록을 가져옴
- 뉴스 피드에 표시할 사용자 이름, 사용자 사진, 포스팅 콘텐츠, 이미지 등을 사용자 캐시와 포스팅 캐시에서 가져와 완전한 뉴스 피드 생성
- JSON 형태로 뉴스 피드를 클라이언트에 전송
캐시 구조
캐시는 뉴스 피드 시스템의 핵심 컴포넌트로, 다음과 같이 5 계층으로 나눌 수 있다.
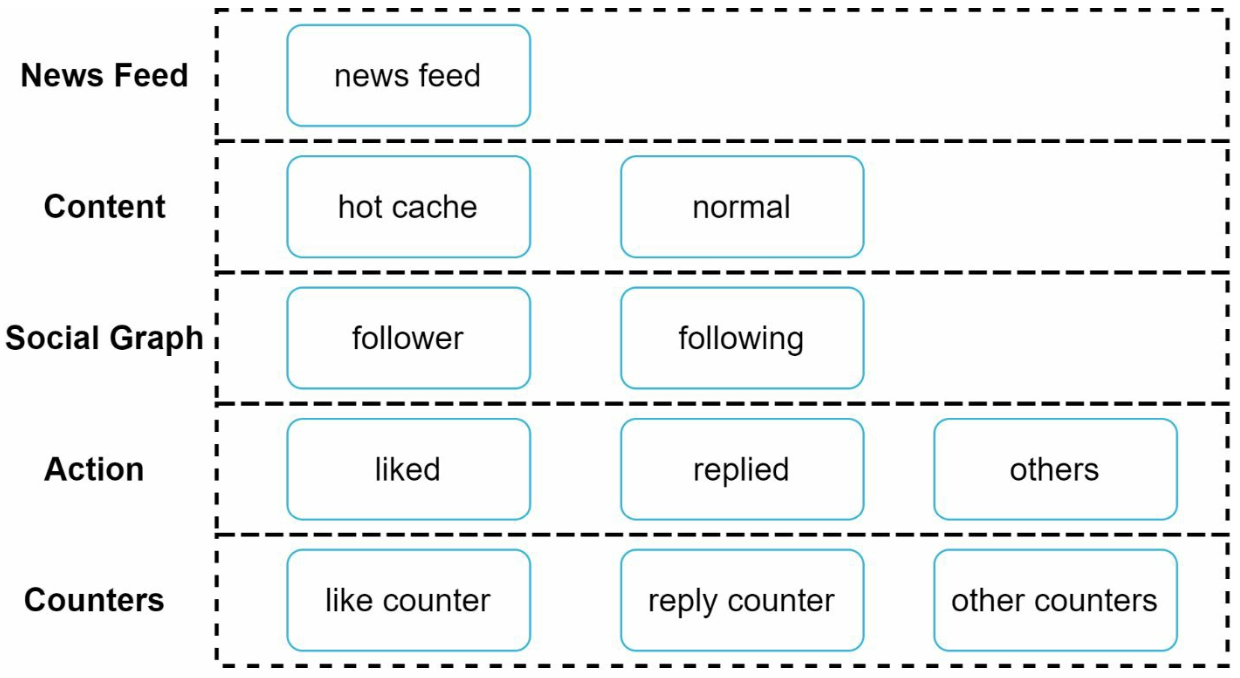
- 뉴스 피드: 뉴스 피드의 ID 보관
- 컨텐츠: 포스팅 데이터 보관, 인기 콘텐츠는 따로 보관
- 소셜 그래프: 사용자 간 관계 정보 보관
- 행동: 포스팅에 대한 사용자의 행위(좋아요, 답글 등)에 관한 정보 보관
- 횟수: 좋아요, 답글 수, 팔로어 수 등 정보 보관
마무리
추가 논의 주제
- 웹 계층을 무상태로 운영하기
- 가능한 많은 데이터를 캐시할 방법
- 여러 데이터 센터 지원
- 메시지 큐를 사용하여 컴포넌트 사이의 결합도 낮추기
- 핵심 메트릭에 대한 모니터링 (트래픽 몰리는 시간대의 QPS, 새로고침 지연시간 등)
