스케줄링: Multi-level Feedback Queue (MLFQ)
작업의 실행 시간에 대한 선행 정보 없이 대화형 작업의 응답 시간을 최소화하고 동시에 반환 시간을 최소화하는 스케줄러를 어떻게 설계할 수 있는가?
Multi-level Feedback Queue (MLFQ)
- Compatible Time-Sharing System에 사용됨
- MLFQ가 해결하고자 하는 문제
- 짧은 작업을 먼저 실행시켜 "반환시간" 최적화
- SJF, STCF 알고리즘은 실생시간 정보를 필요로 하지만, 실제론 실행시간을 미리 알 수 없음
- 대화형 사용자를 위해 "응답시간" 최적화
- RR 알고리즘은 응답시간을 최적화하지만, 반환시간은 거의 최악
- 짧은 작업을 먼저 실행시켜 "반환시간" 최적화
핵심질문: 프로세스에 대한 정보 없이 스케줄링 하는 방법은?
프로세스에 대한 선행 정보 없이 "반환시간"과 "응답시간"을 최소화하는 스케줄러를 설계할 수 있을까?
MLFQ: 기본규칙
MLFQ
- 여러 개의 큐(queue)로 구성, 각각 다른 우선순위 배정
(높은 우선순위 큐에 존재하는 작업부터 선택) - 큐에는 둘 이상의 작업이 존재할 수 있고, 라운드 로빈(RR) 스케줄링 알고리즘이 사용됨
(한 큐 안의 작업들은 모두 같은 우선순위) - MLFQ는 각 작업에 고정된 우선순위를 부여하는 것이 아니라 각 작업의 특성에 따라 동적으로 우선순위 부여
- 어떤 작업이 키보드 입력을 기다리며 반복적으로 CPU 양보 -> 해당 작업에 높은 우선순위 부여
- 어떤 작업이 긴 시간동안 CPU를 집중적으로 사용 -> 해당 작업에 낮은 우선순위 부여
- 즉, MLFQ는 작업이 진행되는 동안 작업의 정보를 얻고, 이 정보를 이용하여 미래 행동을 예측!
MLFQ 규칙
규칙 1: Priority(A) > Priority(B) 이면, A 실행 (B는 실행 x)
규칙 2: Priority(A) = Priority(B) 이면, A와 B는 RR 방식으로 실행
(보통 응답시간 중요한 작업이 우선순위 높음)
시도 1: 우선순위의 변경
아래 그림에서 A,B는 짧은 실행시간을 갖는 대화형 작업 (응답시간 중요),
C,D는 많은 CPU 시간을 요구하지만 응답시간은 별로 안 중요한 작업이라 볼 수 있다.
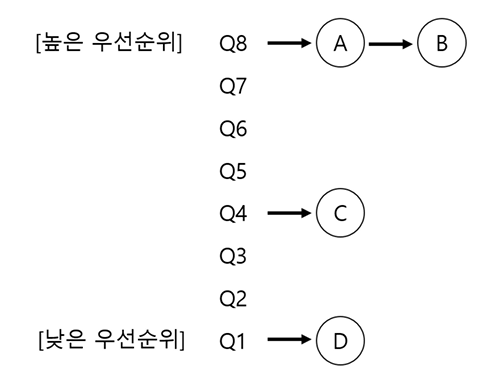
- 우선순위가 높은 A와 B가 RR방식으로 실행됨
- 그러나 C,D는 규칙 1에 의해 실행되지 않음
- 따라서 작업의 우선순위를 어떻게 바꿀 것인지 결정해야 함
-> 즉, 작업이 존재할 큐를 결정하는 것과 같음
MLFQ 규칙
규칙 3: 작업이 시스템에 진입하면, 가장 높은 우선순위의 큐에 놓여진다
규칙 4a: 주어진 타임 슬라이스를 모두 사용하면 우선순위 낮아짐 (한 단계 아래 큐로 이동)
규칙 4b: 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위 유지
예시 상황
- 한 개의 긴 실행시간을 가진 작업
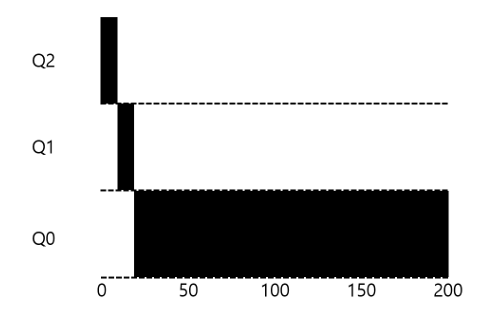
- 처음 진입시 높은 우선순위의 큐에 놓여짐 (규칙3)
- 작업 시간이 길어 타임 슬라이스를 모두 사용 -> 우선순위 낮아짐 (규칙4a)
- 긴 실행시간을 가진 작업 + 짧은 작업
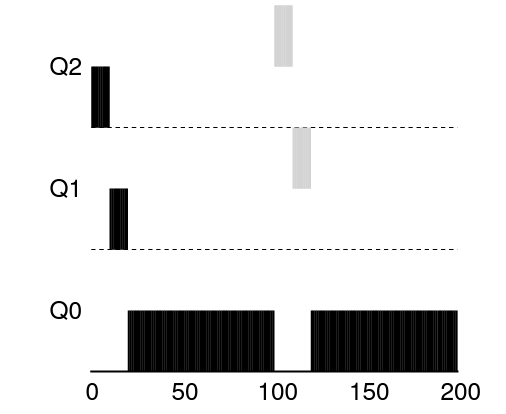
- 긴 작업은 이미 실행중, 100초 쯤에 짧은 작업이 도착
- 짧은 작업은 처음 진입하므로 높은 우선순위 큐에 놓여짐
- 2 타임 슬라이스 정도면 완료되는 짧은 작업이므로, 바닥의 큐에 도착하기 전에 종료
- 긴 작업 마저 처리
여기서 알 수 있는 MLFQ의 주요 목표
- 스케줄로는 작업이 짧은지 긴지 알 수 없음
- 만약 정말로 짧은 작업이면 빨리 실행되고 바로 종료될 것
- 그게 아니라 긴 작업이라면, 해당 작업은 자연스럽게 아래 큐로 이동하게 되고 스스로 긴 작업임을 증명하게 됨
-> 이 방법으로 MLFQ는 SJF에 근사할 수 있음
- 입출력 작업
규칙 4b를 활용, 프로세스가 타임슬라이스를 소진하기 전에 프로세서를 양도하면 우선순위 유지
- 대화형 작업이 자주 입출력을 수행
- 타임슬라이스가 종료되기 전에 CPU 양도 -> 동일 우선순위 유지
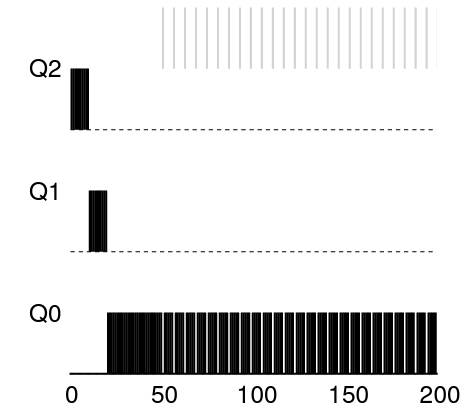
- 회색 프로세스는 대화형 작업, 입출력을 수행하기 전 1ms만 실행
- CPU를 계속 양도하므로 MLFQ는 회색 작업을 높은 우선순위로 유지
- 검정색은 긴 배치형 작업, CPU를 계속 선점하고 타임 슬라이스를 다 소진하므로 낮은 우선순위
현재 MLFQ의 문제점
-
기아 상태 (starvation) 발생
- 너무 많은 대화형 작업이 존재하면, 그 작업들이 모든 CPU 시간을 소모
- 따라서 긴 실행시간의 작업은 CPU시간을 할당 받지 못함
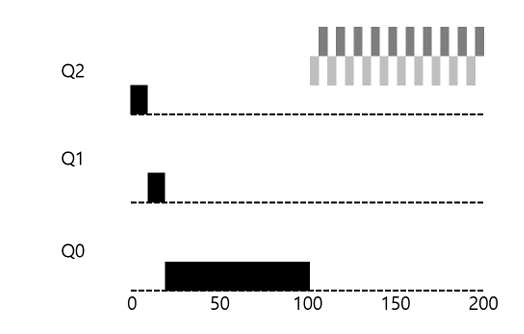
- 긴 작업(검은색)은 두 개의 짧은 작업(회색)들이 오면 실행되지 못하고 굶어 죽음
-
프로그램이 스케줄러를 속여 CPU 독점 가능
- 타임 슬라이스가 끝나기 전에 아무 파일을 대상으로 입출력 요청하여 CPU를 양도
- 그러면 같은 큐에 머무를 수 있고 높은 퍼센트의 CPU 시간 획득
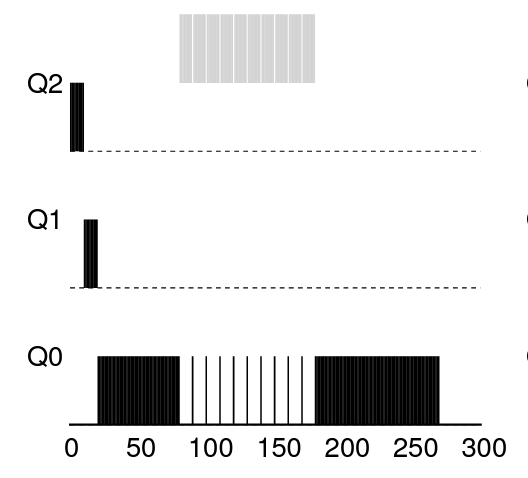
- 이런 식으로 회색 작업이 꼼수로 CPU 독점 가능
- 타임 슬라이스 99% 쯤에 입출력 요청하여 CPU 양도
- CPU 양도하긴 했으므로, 규칙 4b에 의해 우선순위 유지
-
프로그램은 시간의 흐름에 따라 특성이 변할 수 있음
- 예를 들어 CPU 위주의 작업이 대화형 작업으로 바뀔 수도 있음
- 현재 구현 방식으로는 대화형 작업으로 바뀌었을 때 우선순위 높일 수 없음
시도 2: 우선순위의 상향 조정
MLFQ 규칙
규칙 5: 일정 기간S가 지나면, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
주기적으로 모든 작업의 우선순위를 상향 조정 (boost)
- 모두 최상위 큐로 보내버림
- 기아 문제를 방지 가능 (문제점 1 해결)
- 대화형 작업으로 바뀌어도 괜찮음 (문제점 3 해결)
- (다양한 방법 있지만 가장 간단한 방법 사용하는 것)
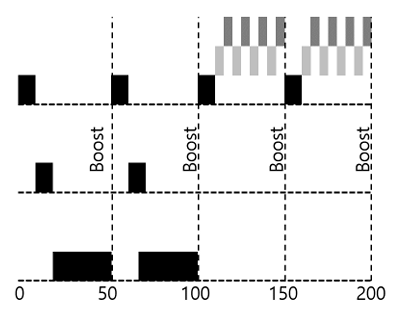
- 50ms 마다 상향(boost) (
S = 50ms) - 긴 작업(검은색)도 굶어 죽지 않고 꾸준히 실행됨
(50ms에 한번씩은 실행 보장) - 원래같았으면 짧은 작업들(회색)들이 CPU를 독점하여 긴 작업이 굶어죽었을 것
- 만약 긴 작업이 갑자기 대화형으로 바뀌어도 문제 없음, 우선순위가 높아졌으므로
- 50ms 마다 상향(boost) (
- 적절한
S값 설정이 중요- 너무 크면 기아 상황 발생
- 너무 작으면 대화형 작업이 적절한 양의 CPU 시간을 사용할 수 없게 됨
- 부두 상수임 (결정하기 어렵다는 뜻)
시도 3: 더 나은 시간 측정
그렇다면...
프로그램이 스케줄러를 속여 CPU를 독점(문제 2) 하는 것은 어떻게 해결?
사실 이 문제의 원인은 규칙 4a, 4b 때문이다.
규칙 4a: 주어진 타임 슬라이스를 모두 사용하면 우선순위 낮아짐 (한 단계 아래 큐로 이동)
규칙 4b: 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위 유지
위의 두 규칙 때문에 프로그램이 불순한 목적으로 우선순위를 높게 유지할 수 있게 된다.
해결 방법은 MLFQ의 각 단게에서 CPU 총 사용 시간을 측정하는 것이다.
MLFQ 규칙 (규칙 4 재정의)
규칙 4: 주어진 단계에서 CPU 시간 할당량을 소진하면 우선순위는 낮아진다.
(CPU를 몇번 양도하였는지 상관없음)
- 스케줄러는 현재 단계에서 프로세스가 소진한 CPU 사용 시간을 저장
- 프로세스가 타임 슬라이스에 해당하는 시간을 모두 소진하면 우선순위 낮아짐 (낮은 큐로 강등)
- 타임 슬라이스를 한번에 소진하든, 짧게 여러번 소진하든 상관 없이 시간 모두 소진하면 강등
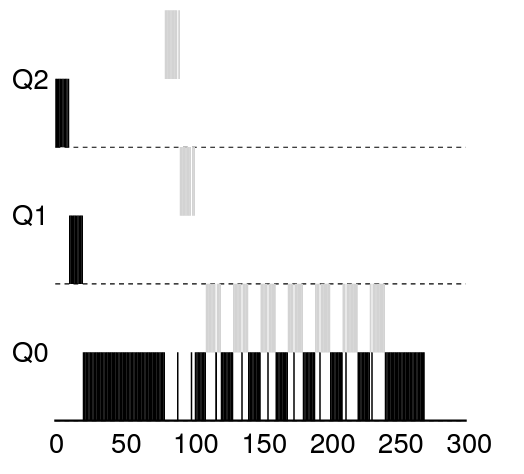
- 이번에는 CPU 사용 시간 할당량이 존재하는 경우
- 회색 작업(꼼수 프로그램)이 타임 슬라이스 소진 직전에 입출력 요청을 해도, 다음 타임 슬라이스에서 CPU 사용 시간 할당량을 소진해버림
- 그리하여 자연스럽게 우선순위 낮아져 CPU 독점을 막을 수 있음
MLFQ 규칙
규칙 1: Priority(A) > Priority(B) 이면, A 실행 (B는 실행 x)
규칙 2: Priority(A) = Priority(B) 이면, A와 B는 RR 방식으로 실행
(보통 응답시간 중요한 작업이 우선순위 높음)
규칙 3: 작업이 시스템에 진입하면, 가장 높은 우선순위의 큐에 놓여진다.
규칙 4: 주어진 단계에서 CPU 시간 할당량을 소진하면 우선순위는 낮아진다.
(CPU를 몇번 양도하였는지 상관없음)
규칙 5: 일정 기간
S가 지나면, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
MLFQ 조정과 다른 쟁점들
MLFQ에 대한 쟁점들
- 몇 개의 큐가 필요한가?
- 큐당 타임 슬라이스의 크기는 얼마로?
- 상향 조정(boost)는 몇초에 한 번?
-> 조정, 최적화 쉽지 않음... 워크로드 계속 조정해 나가면서 균형점 찾아야함
-
큐 별로 다른 타임 슬라이스
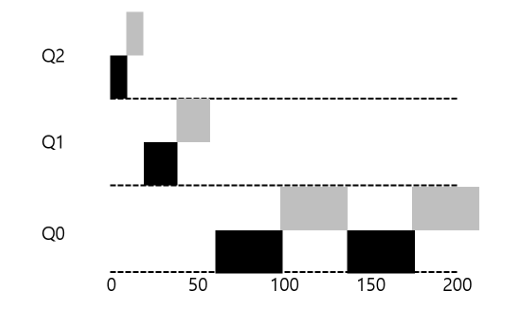
- 보통 높은 우선순위의 큐에는 대화형 작업으로 구성되므로, 짧은 타임 슬라이스 사용
- 낮은 우선순위의 큐에서는 CPU 중심의 작업들을 포함하므로, 긴 타임 슬라이스 사용
-
Sloaris의 MLFQ 구현
- 시분할 스케줄링을 하기 쉽게 잘 구현함
- 프로세스의 우선순위가 일생 동안 어떻게 변하는지 결정 테이블 제공
- 큐 개수: 60개 (기본값)
- 타임 슬라이스의 길이: 20ms ~
- 상향 조정 빈도: 약 1초에 한 번
- 이 테이블 수정해서 스케줄러의 동작 방식을 바꿀 수 있음
-
운영체제 작업을 위한 우선순위 예약
- 가장 높은 우선순위를 운영체제 작업을 위해 예약
- 일반적인 사용자 작업은 시스템 내에서 가장 높은 우선순위를 얻을 수 없게 만듦
- 가장 높은 우선순위는 오직 운영체제 작업들만 가질 수 있음
- 일부 시스템은 사용자가 우선순위를 정할 수 있도록 허용
(nice명령어로 우선순위 높이거나 낮출 수 있음)
MLFQ 규칙
규칙 1: Priority(A) > Priority(B) 이면, A 실행 (B는 실행 x)
규칙 2: Priority(A) = Priority(B) 이면, A와 B는 RR 방식으로 실행
(보통 응답시간 중요한 작업이 우선순위 높음)
규칙 3: 작업이 시스템에 진입하면, 가장 높은 우선순위의 큐에 놓여진다.
규칙 4: 주어진 단계에서 CPU 시간 할당량을 소진하면 우선순위는 낮아진다.
(CPU를 몇번 양도하였는지 상관없음)
규칙 5: 일정 기간
S가 지나면, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
문제
https://github.com/remzi-arpacidusseau/ostep-homework/tree/master/cpu-sched-mlfq
에 있는 mlfq.py를 실행시켜보며 문제를 해결해보자
문제 1
두 개의 작업과 두 개의 큐를 무작위로 구성하여 실행시켜 보시오.
각 문제에 대한 MLFQ실행 추적을 계산하시오.
문제를 쉽게 하기 위해 각 작업의 길이를 제한하고 입출력은 하지 않는다고 가정하시오.
./mlfq.py -j 2 -n 2 -m 10 -M 0 -c
문제 2
이 장의 예제를 재현하려면 스케줄러를 어떻게 실행해야 하는가?
- 한 개의 긴 실행시간을 가진 작업
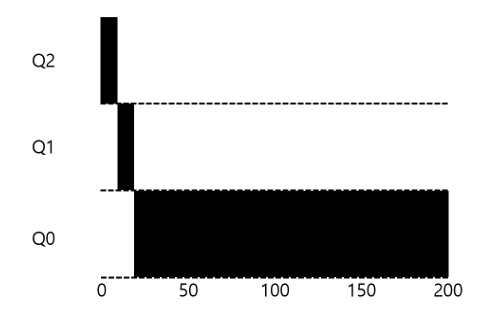
./mlfq.py -n 3 -l 0,200,0 -c
- 긴 실행시간을 가진 작업 + 짧은 작업
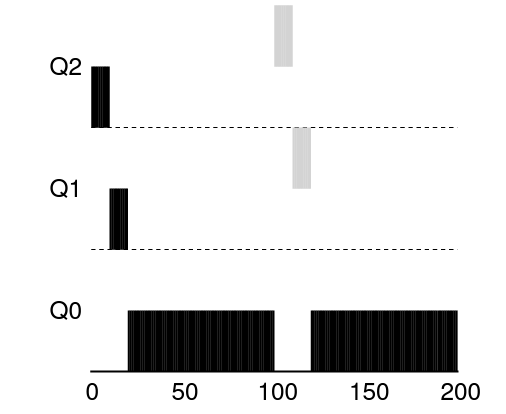
./mlfq.py -n 3 -l 0,200,0:100,20,0 -c
- 입출력 작업
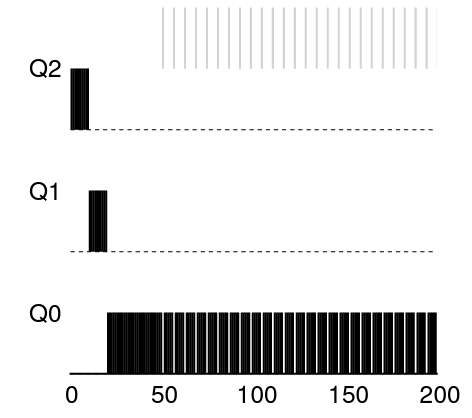
./mlfq.py -n 3 -l 0,200,0:50,15,1 -i 9 -c
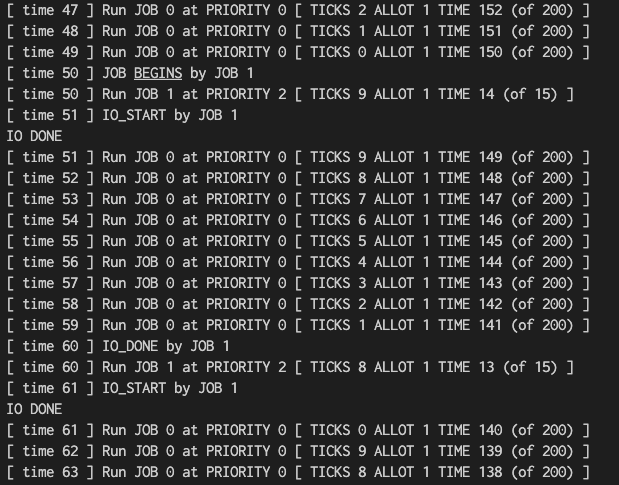
- time 0~49: JOB 0 만 Q0에서 돌아감 (처음엔 Q2였지만, 천천히 강등)
- time 50: JOB 1이 실행되고 IO 작업을 요청
- time 51~59: JOB 1은 IO 요청을 하므로 CPU를 사용하지 않음, 그래서 다시 JOB 0 실행
- time 60: JOB 1이 아까 요청한 IO 작업이 완료되고, 새로운 IO 작업을 요청함
... 반복...
문제 3
라운드 로빈 스케줄러처럼 동작시키려면 스케줄러의 매개변수를 어떻게 설정해야 하는가?
- 큐를 하나만 사용하면 되므로
-n 1옵션을 넣어준다
문제 4
두 개의 작업과 스케줄러 매개변수를 가진 워크로드를 고안하시오.
두 작업 중 하나의 작업은 옛날 규칙 4a 및 4b를 이용(-S플래그)하여 스케줄러를 자신에게 유리하게 동작하도록 만들어 특정 구간에서 99%의 CPU를 차지하도록 고안해야한다.
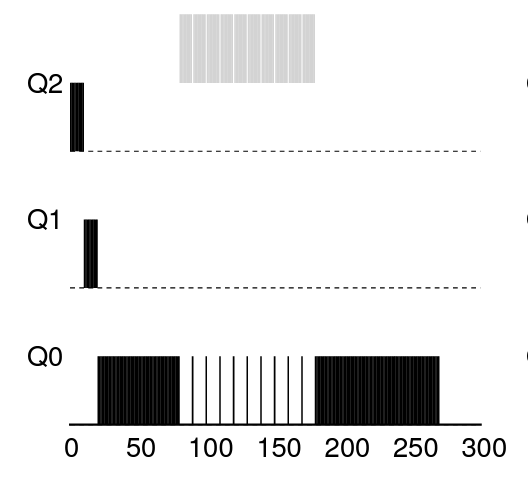
./mlfq.py -n 3 -l 0,200,0:50,90,9 -i 1 -S -c- 그림과 완전히 일치하지는 않지만, time 50~149 구간에서 CPU를 90% 차지하는 프로세스(JOB 1)을 만든다.
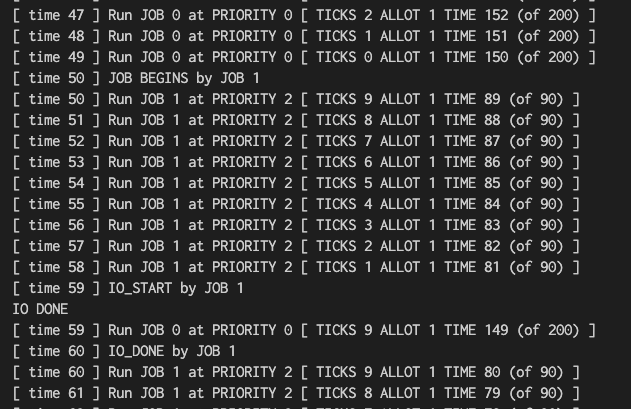
- time 0~49: JOB 0 만 Q0에서 돌아감 (처음엔 Q2였지만, 천천히 강등)
- time 50~58: JOB 1이 실행
- time 59: JOB 1이 IO 요청
- time 60~68: JOB 1에서 요청한 IO 작업이 1 time만에 완료되고, 다시 JOB 1의 CPU 중심 작업 수행
... 반복...
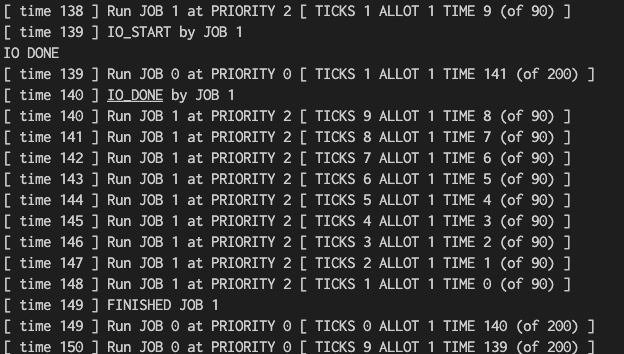
- 이후 time 149까지 Q2에 머문 것을 확인할 수 있다.
문제 5
가장 높은 우선순위 큐의 타임 퀀텀의 길이가 10ms인 시스템이 있다고 하자.
하나의 장기 실행(및 잠재적인 기아 위험) 작업이 적어도 5%의 CPU를 사용할 수 있도록 보장하려면 얼마나 자주 가장 높은 우선순위로 이동(-B플래그)시켜야 하는가?
- 하나의 작업만이 존재하고, 총 작업 시간이 200ms 라고 하자
- 200ms의 5%는 10ms, 최소 10번은 부스팅 되어야 함
- 따라서 20ms에 한 번씩 부스팅 하면 5%의 CPU를 사용할 수 있도록 보장받을 수 있다.
./mlfq.py -n 3 -l 0,200,0 -B 20 -c
문제 6
스케줄링에서 제기되는 질문 중 하나는, 입출력이 방금 종료된 작업은 큐의 어느 쪽에 추가해야 하는가이다.
플래그-I 가 시뮬레이터의 이 행동 양식을 변경한다.
몇 개의 워크로드를 가지고 실험하여 이 플래그의 영향을 확인할 수 있는지 보라.
./mlfq.py -l 0,20,9:0,30,12 -s 1 -c -i 0 -S
- JOB 0: 0초에 시스템 도착, 총 20초 소요, 9초에 한번 IO 요청
- JOB 1: 0초에 시스템 도착, 총 30초 소요, 12초에 한번 IO 요청
- random seed는 1, IO 시간은 0초 소요
- -S 시그널 붙었으므로 CPU 중간에 양도하면 우선순위 유지
따라서 JOB 0과 JOB 1이 IO 요청을 할 때마나 번갈아 실행됨
./mlfq.py -l 0,20,9:0,30,12 -s 1 -c -i 0 -S -I
- JOB 0: 0초에 시스템 도착, 총 20초 소요, 9초에 한번 IO 요청
- JOB 1: 0초에 시스템 도착, 총 30초 소요, 12초에 한번 IO 요청
- random seed는 1, IO 시간은 0초 소요
- -S 시그널 붙었으므로 CPU 중간에 양도하면 우선순위 유지
- -I 시그널 붙었므므로 IO 동작을 완료하면, 해당 작업을 큐의 제일 앞으로 위치시켜 먼저 실행되도록 함
따라서 JOB 0에서 IO 요청을 해도 JOB 1으로 전환되지 않고, JOB 0이 계속 CPU를 사용
