빈 공간 관리 (Free Space Management)
핵심 질문: 빈 공간을 어떻게 관리하는가
- 관리하고 있는 공간이 고정 크기의 단위로 나뉜 경우엔 관리 쉬움
- 하지만 가변 크기의 요구를 충족시키긴 어려움
- 세그멘테이션으로 물리 메모리를 관리하는 운영체제에서는 필연적으로 외부 단편화 발생
- 단편화를 최소화하기 위한 전략 필요
1. 가정
이 논의의 대부분은 사용자 수준 메모리 할당기(allocator)의 발전 역사에 초점이 맞춰져있다.
논의를 위한 가정
malloc()과free()에서 제공하는 것과 같은 기본 인터페이스 가정
void *malloc(size_t size)<- 크기 정보 전달 ovoid free(void *ptr)<- 크기 정보 전달 x- 라이브러리가 관리하는 공간은 힙(heap)이며, 힙의 빈 공간을 관리하는 데에는 링크드리스트 사용
- 외부 단편화 방지에 중점
- 클라이언트에게 할당된 메모리는 다른 위치로 재배치 x
- 예를 들어
malloc()후free()하기 전까지 해당 힙 영역은 프로그램의 소유- 압축 사용 불가
2. 저수준 기법들
분할과 병합 (splitting & coalescing)
- 아래 그림과 같이 30바이트의 힙이 있다고 하자.

- 이 경우 힙의 빈 공간 리스트에는 2개의 원소가 있다.
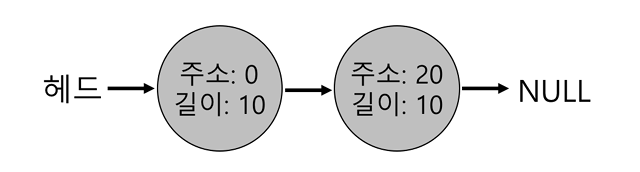
- 동적 할당 시 10 바이트가 넘는 모든 요청은 실패함
- 10 바이트의 요청은 두개의 빈 청크 중 하나 사용
- 그렇다면 10바이트 이하의 요청은? 분할 작업 수행!
- 분할 (splitting)
- 만일 1바이트의 요청이 들어오면, 요청을 만족시킬 수 있는 빈 청크를 찾음
- 찾은 빈 청크를 둘로 나눔
- 첫 번째 청크는 호출자에게 반환 (빈 공간 리스트에서 제외)
- 두 번째 청크는 리스트에 남음
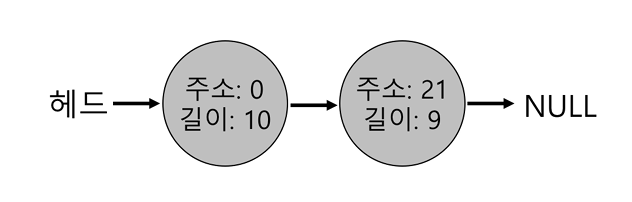
- 위 예에서는 주소 20을 반환하고 (청크1),
주소 21부터는 리스트에 남는다 (청크2)
- 최종적으로 빈 공간 리스트는 다음과 같은 모습
- 병합 (coalescing)
- 다시, 이 상황에서
free(10)하여 힙의 중간에 존재하는 공간을 반환한다고 하자 - 병합 없이 무지성으로 빈공간 리스트에 추가하는 경우 아래와 같은 모습일 것이다.
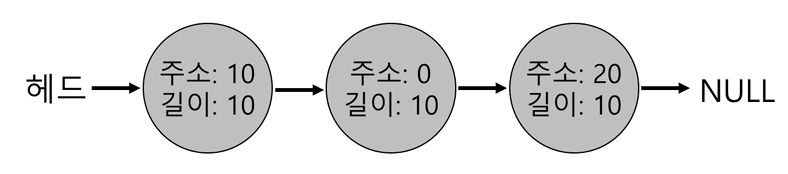
- 이러한 경우 10바이트보다 큰 요청을 받지 못함
(아무리 탐색해도 빈 공간 10 넘는 청크 없기 때문)
- 이러한 경우 10바이트보다 큰 요청을 받지 못함
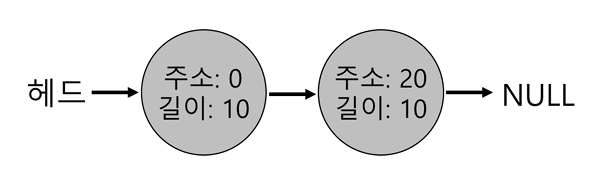
- 따라서 이러한 문제를 방지하기 위해 병합 사용
- 메모리 청크 반환 시 (
free), 해제되는 청크의 주소와 바로 인접한 빈 청크의 주소를 살펴본다. - 새로 해제된 빈 공간의 왼쪽 청크와 바로 인접해있다면 병합!
헤드->
(주소:0, 길이:10)->(주소:20, 길이:10)->NULL
헤드->(주소:0, 길이:10)->[주소:10, 길이:10]->(주소:20, 길이:10)->NULL
헤드 ->(주소:0, 길이:30)-> NULL
- 메모리 청크 반환 시 (
- 다시, 이 상황에서
할당된 공간의 크기 파악
대부분의 할당기는 추가 정보를 헤더(header) 블럭에 저장
- 헤더는 할당된 공간의 크기, 추가 포인터, 무결성 검사를 위한 숫자 등을 저장
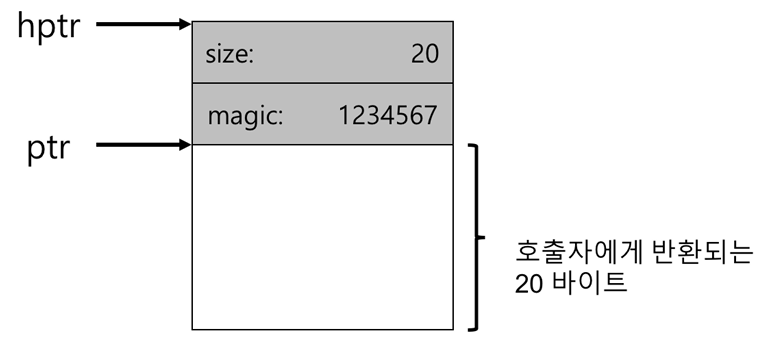
free()함수 속 헤더의 시작 위치 파악void free(void *ptr) { header_t *hptr = (void *)ptr − sizeof(header_t); ... }- 주의) 빈 영역의 크기는
헤더 크기 + 할당된 영역의 크기
빈 공간 리스트 내장
빈 공간의 리스트의 개념을 다루었는데, 이러한 리스트를 빈 공간에 어떻게 구현?
보통 새로운 노드를 위한 공간이 필요할 때 malloc()을 호출하지만, "메모리 할당 라이브러리 루틴"에서는 불가능하다.
대신 빈 공간 내에 리스트를 구축해야 한다.
4KB 크기 (4096 byte)의 메모리 청크가 있다 가정
- 즉, 힙의 크기가 4KB 이고, 이를 빈 공간 리스트로 관리하기 위해선 먼저 리스트를 초기화함
- 리스트의 각 노드는 아래와 같은 구조를 가짐
typedef struct __node_t { int size; struct __node_t *next; } node_t; - 처음엔
4KB - (헤더의 크기)의 항목 하나를 가짐
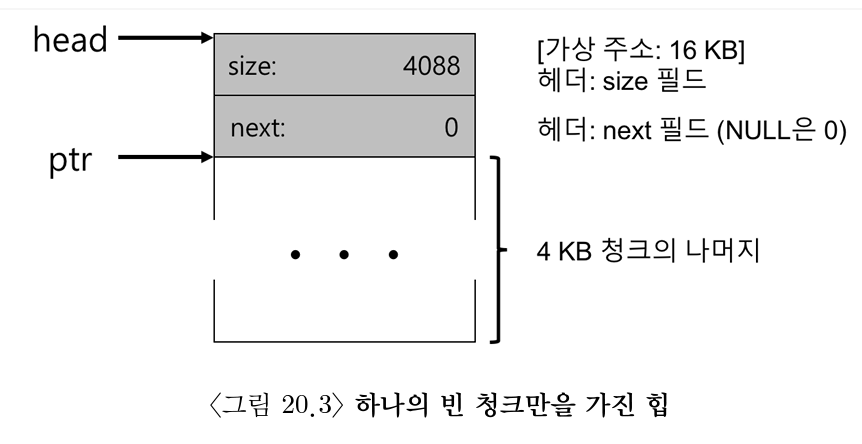
- 쉽게 말해, 빈 공간 리스트에
4KB - (헤더 크기)의 공간을 사용할 수 있다는 것 - 헤더 크기는 8바이트라 가정하자
- 쉽게 말해, 빈 공간 리스트에
- 이후 100바이트에 대한 요청이 오면
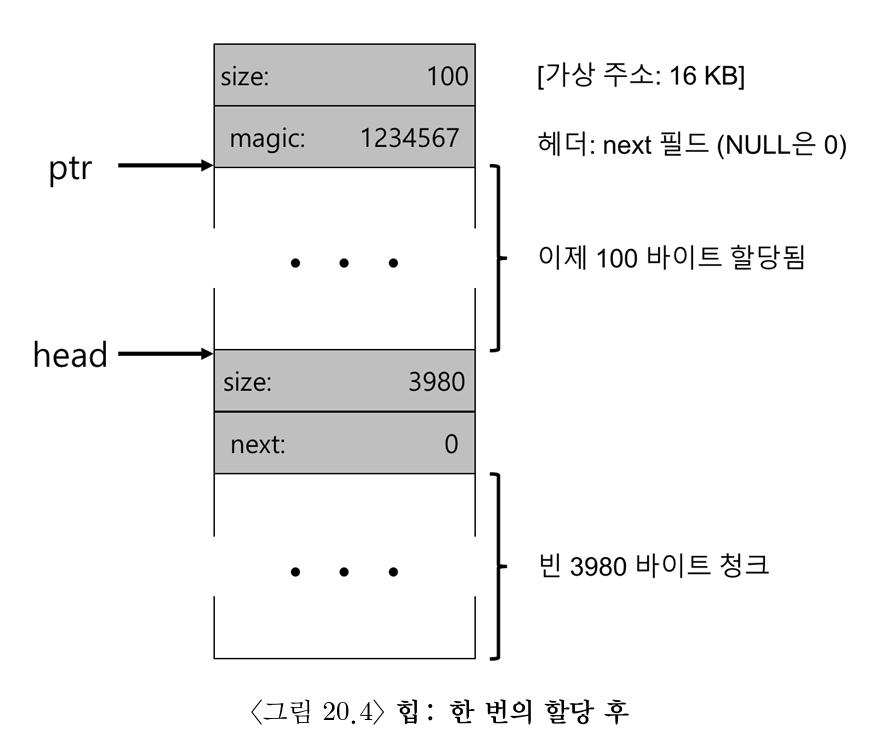
- 빈 청크 중 108바이트(=100바이트+헤더) 할당
- 할당 후 포인터(ptr) 반환
- 남은 빈 노드를 3980 바이트로 축소
- 100 바이트씩 할당된 3개의 공간이 존재하는 힙은 다음과 같이 구성되어 있다.
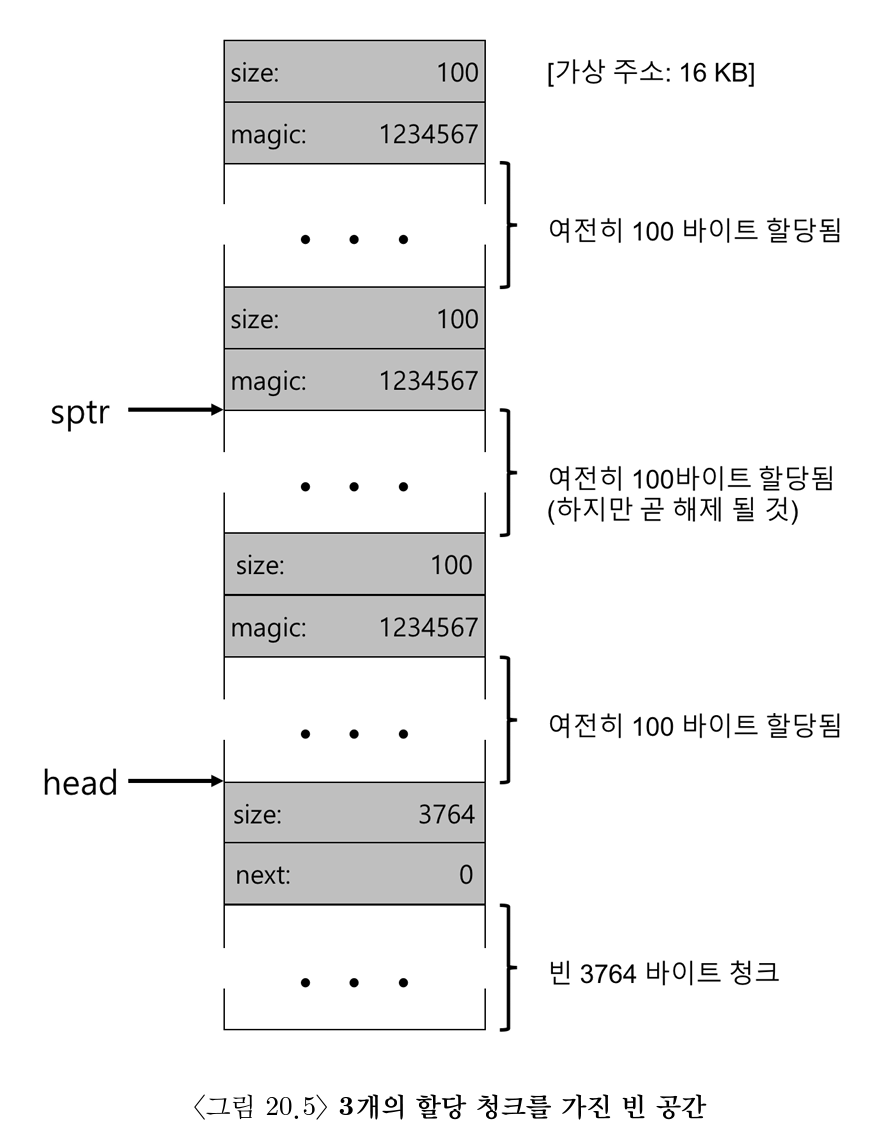
- 이때 가운데 청크를
free()해주면 아래와 같이 두 개의 청크로 단편화 된다
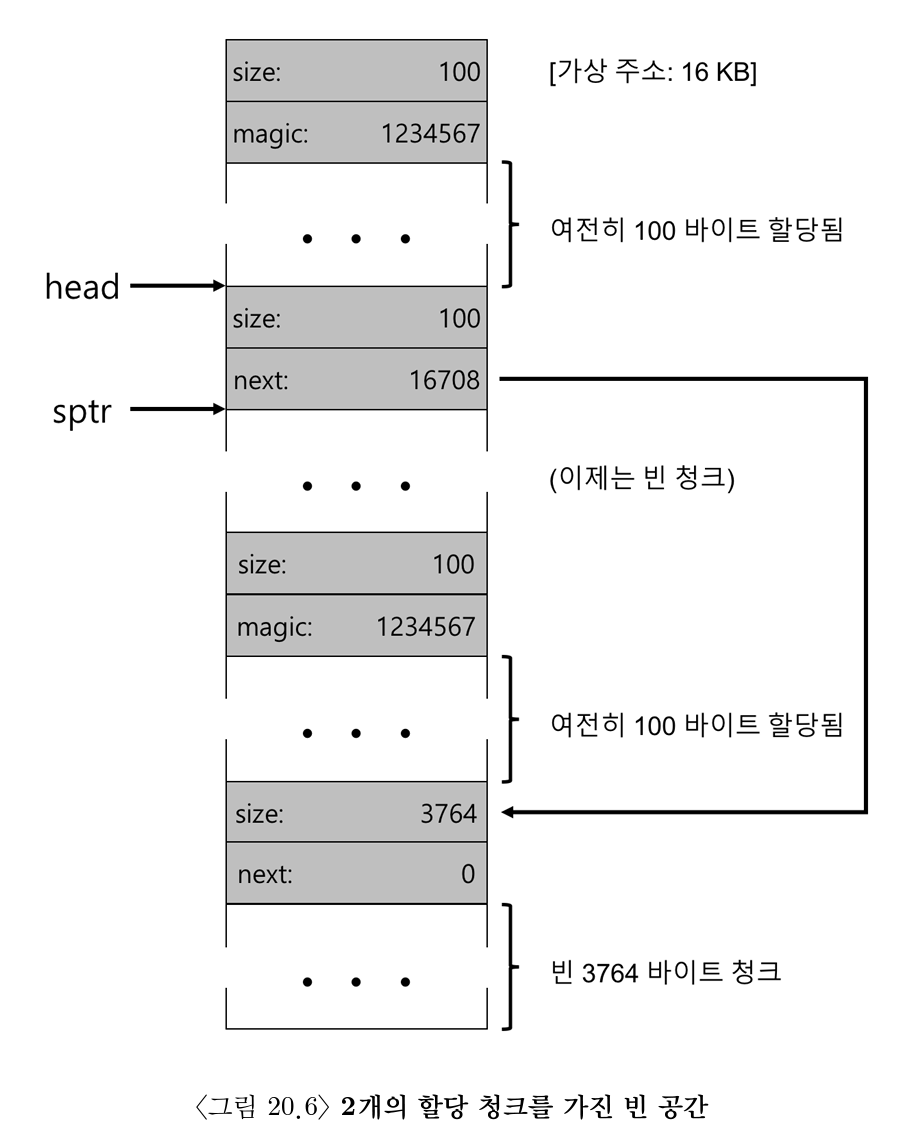
- 빈 공간 리스트의 첫 번째 원소는 100 바이트 크기의 빈 청크 (주소 = 16KB + 108 + 8 = 16500)
- 빈 공간 리스트의 두 번째 원소는 3764 바이트 크기의 커다란 빈 청크 (맨 아래)
- 만일 이후에 100 바이트 할당된 두 청크를 해제한다면?
-> 병합이 없는 경우 작은 단편으로 이루어진 빈 공간 리스트가 될 것이다.
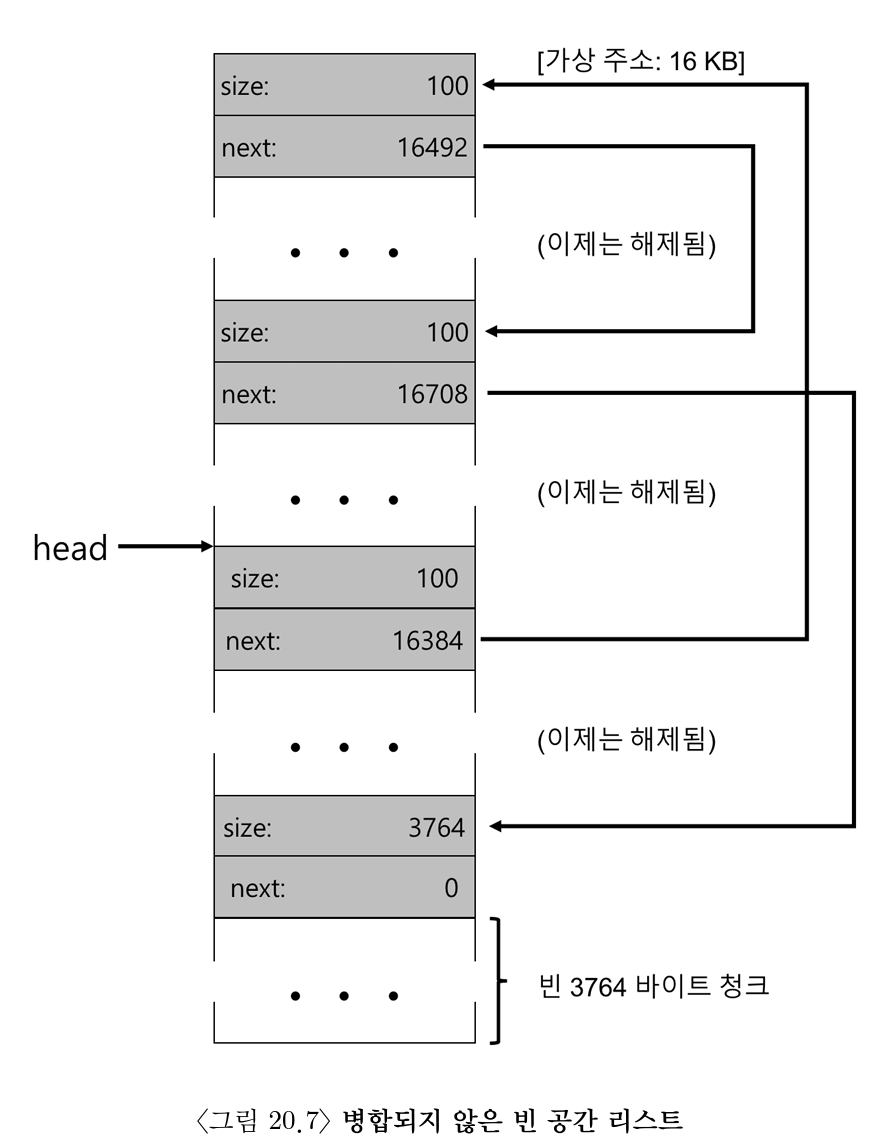
해결책: 리스트를 순회하면서 인접한 청크 병합
(병합이 완료되면 힙은 전체 하나의 큰 청크가 됨)
- 이때 가운데 청크를
힙의 확장
힙의 공간이 부족한 경우엔 어떻게?
- 쉬운 방법: 실패를 반환한다. (NULL 반환)
- 적은 크기의 힙으로 시작 -> 모두 소진 시 운영체제로부터 더 많은 메모리를 요청
- 할당기는 힙을 확장하기 위해 특정 시스템 콜(
sbrk) 호출 - 그런 후 확장된 영역에서 새로운 청크 할당
- sbrk 요청을 수행하기 위해 운영체제는 빈 물리 페이지를 찾아 요청 프로세스의 주소 공간에 매핑한 후, 새로운 힙의 마지막 주소를 반환한다.
- 할당기는 힙을 확장하기 위해 특정 시스템 콜(
3. 기본 전략
이상적인 할당기는 속도가 빨라야하고 단편화를 최소로 해야한다.
그러나 할당과 해제 요청은 프로그래머에 의해 결정되기 때문에, 입력에 따라 최선의 전략을 잘 선택해야한다.
최적 적합 (Best Fit)
- 빈 공간 리스트에 요청한 크기 이상의 빈 메모리 청크 탐색
- 후보자 그룹 중 가장 작은 크기의 청크 반환
- 즉, 들어갈 수 있는 빈 공간 중 제일 작은 곳에 들어감
- 한 번의 빈 공간 리스트 순회로 정확한 반환 블럭 찾을 수 있다.
- 하지만 해당 빈 블럭을 찾기 위해 항상 전체를 검색해야 한다.
- 이름과 달리 최악의 알고리즘
최악 적합 (Worst Fit)
- 빈 공간 리스트에서 가장 큰 빈 청크를 탐색
- 요청된 크기만큼 반환, 남은 부분은 빈 공간 리스트에 계속 유지
- 즉, 제일 큰 빈 공간 리스트에 들어감
- 최대한 큰 청크를 남기려고 시도
- 하지만 해당 빈 블럭을 찾기 위해 항상 전체를 검색해야 한다.
- 그리고 엄청난 단편화 + 큰 오버헤드
최초 적합 (First Fit)
- 빈 공간 리스트에 요청한 크기 이상의 빈 메모리 청크 탐색
- 발견한 최초의 블럭을 요청만큼 반환
- 즉, 들어갈 수 있으면 바로 들어감
- 빠르다. 리스트 전체 탐색 x
- 그러나 때때로 리스트의 시작에 크기가 작은 객체가 많이 생길 수 있음
- 할당기가 빈 공간 리스트의 순서를 관리하는 것이 쟁점
- 주소-기반 정렬: 리스트를 주소로 정렬하여 병합을 쉽게 하고, 단편화 감소
다음 적합 (Next Fit)
- 마지막으로 찾았던 원소를 가리키는 추가 포인터 유지
- 요청된 크기 이상의 빈 메모리 청크 탐색
- 찾으면 요청된 크기만큼 반환
- 즉, 마지막으로 찾은 원소를 기억했다가, 거기서부터 탐색
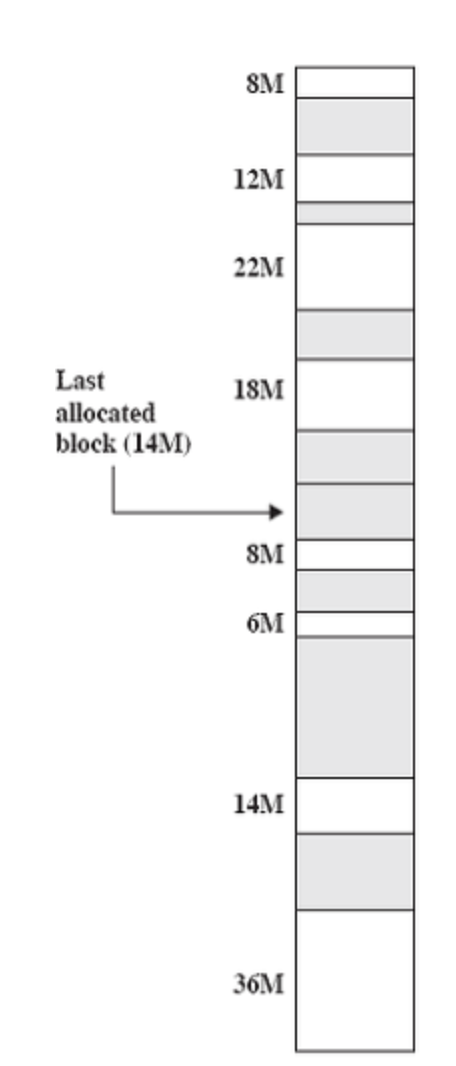
- 14M 짜리 블록을 마지막으로 찾았다고 가정, 해당 블록을 포인터로 가리킴
- 20M 크기의 요청이 들어오면, 포인터 이후부터 차례대로 탐색
- 8M, 6M, 14M짜리 블록을 지나, 36M짜리 블록에 도달하면 할당 가능하므로 이곳의 메모리를 반환
- 빈 공간 탐색을 리스트 전체에 더 균등하게 분산시키는 것이 목적
- 전체 탐색을 하지 않기 때문에 최초 적합의 성능과 비슷
4. 다른 접근법
위에서 설명한 기본적인 접근 방식 외에도 메모리 할당을 향상시키기 위한 다양한 알고리즘이 있다.
개별 리스트(segregated list)
- 특정 응용 프로그램이 한두 개의 자주 요청하는 크기가 있다면, 그 크기의 객체를 관리하기 위한 별도의 리스트를 유지하는 것
- 다른 모든 요청은 더 일반적인 메모리 할당기에 전달
- 요청된 크기의 청크만이 존재하기 때문에 단편화 가능성을 줄일 수 있음
- 또한 청크의 크기가 같아 복잡한 리스트 검색 없이 빠르게 할당과 해제 가능
문제점: 지정된 크기의 메모리 풀과 일반적인 풀에 얼만큼의 메모리 할당?
슬랩 할당기 (slab allocator)
- 특수 목적 할당기로, 개별 리스트의 문제를 해결
- 커널이 부팅될 때 커널 객체(락, 파일시스템 inode 등)를 위한 여러 객체 캐시 (object cache) 할당
- 객체 캐시는 지정된 크기의 객체들로 구성된 빈 공간 리스트이고 메모리 할당 및 해제 요청을 빠르게 서비스하기 위해 사용
- inode들로 구성된 객체 캐시
- 락 구조만을 담고 있는 객체 캐시 등
- 기존에 할당된 캐시 공간이 부족해지면 상위 메모리 할당기에게 추가 슬랩을 요청
- 슬랩 내 객체들에 대한 참조 횟수가 0이 되면 상위 메모리 할당기는 이 슬랩을 회수할 수 있음
- 슬랩 할당 방식은 빈 객체들을 사전에 초기화된 상태로 유지하여 오버헤드 감소 (초기화 및 반납 비용이 크므로 자주 하면 손해)
버디 할당
빈 공간의 합병을 간단히 하는 방법
이진 버디 할당기(binary buddy allocator)
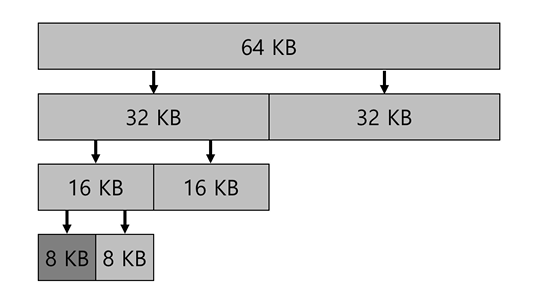
- 빈 메모리는 처음에 2^n 크기의 하나의 공간으로 생각된다 (여기서는 64)
- 메모리 요청이 발생하면, 요청을 충족시키는 최소의 공간이 될 때까지 2로 계속 분할
- 이 예에서는 7KB 크기의 요청이 들어와서 8KB가 될 때까지 분할
- 2의 거듭제곱 크기만큼의 블럭만 할당할 수 있으므로 내부 단편화 발생할 수 있음
- 블럭 해제 시, 해제를 한 블럭 옆에 있는 "버디" 블럭을 확인한다.
만일 비어있다면 두 블럭을 병합하고, 이 합병 과정을 재귀적으로 수행한다.- 위의 예에서 8KB 블럭을 빈 공간 리스트에 반환하면, 옆에 있는 "버디" 8KB 블럭을 확인하고, 비어있으면 합병한다.
- 이후 비어있으므로 16KB 블럭으로 합병하고, 또 옆에 있는 버디 16KB 블럭을 확인 (반복)
- 특정 블럭과 그 블럭의 버디는 주소가 한 비트만 차이가 난다.
-> 버디를 결정하는 것이 쉬움
기타 아이디어
확장성 문제
- 빈 공간들의 개수가 늘어남에 따라 리스트 검색이 매우 느려질 수 있음
- 균형 이진 트리, 스플레이 트리, 부분 정렬 트리와 같은 자료구조를 할당기에 적용하여 성능을 높일 수 있음
멀티프로세서를 위해 할당기 최적화
- Hoard memory allocator: 멀티프로세서 시스템을 위한 확장성이 좋은 Memory Allocator
- jemalloc: FreeBSD, NetBSD, MozillaFirefox, 및 Facebook에서 널리 사용 중

잘 읽었습니다. 좋은 정보 감사드립니다.