멀티프로세서 스케줄링
멀티프로세서 스케줄링(multiprocessor scheduling)은 어려운 주제이므로 기본적인 내용만 다룰 것이다.
병행성(concurrency)에 대해 어느정도 공부를 한 후에 다루는 것이 가장 좋다.
멀티프로세서 시스템: 두 개 이상의 CPU를 가진 컴퓨터 시스템
- 원래는 고사양 컴퓨터에만 존재했는데, 멀티코어 프로세서가 대중화되면서 널리 쓰임
- 전통적인 응용프로그램은 하나의 CPU만 쓰기 때문에, CPU를 추가해도 속도가 빨라지지 않았음
- 이 문제를 해결하려면 응용프로그램을 병렬(parallel)로 실행되도록 해야함 (보통 쓰레드 사용)
- 응용프로그램뿐 아니라 운영체제도 멀티프로세서 스케줄링 문제에 직면함 -> 단일프로세서 스케줄링 원칙들을 멀티프로세서에서 동작하도록 확장할 수 있을까?
핵심 질문: 여러 CPU에 작업을 어떻게 스케줄 해야 하는가?
1. 배경: 멀티프로세서 구조
멀티프로세서 스케줄링에 대한 새로운 문제점을 이해하기 위해서는 단일 CPU 하드웨어와 멀티 CPU 하드웨어의 근본적인 차이에 대한 이해가 필요하다.
단일 CPU 시스템에는 하드웨어 캐시 계층이 존재
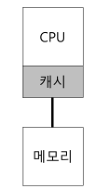
- 캐시는 메인 메모리에서 자주 사용되는 데이터의 복사본을 저장하는 작고 빠른 메모리 (메모리는 느리지만, 용량이 크고 저렴)
- 시간 지역성 (temporal locality): 데이터가 한 번 접근 되면 가까운 미래에 다시 접근되기 쉬움
- 공간 지역성 (spatial locality): 주소 x의 데이터를 접근하면 x 주변의 데이터가 접근되기 쉬움
여러 프로세서가 존재하고, 메인 메모리는 하나일 때
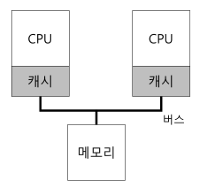
- 캐시 일관성 문제 (cache coherence): 두개의 서로 다른 프로세서는 각자 자신의 캐쉬를 통하여 메모리를 접근하게 되고, 주의하지 않으면 두 개의 다른 값을 갖게 된다.
- 예)
- CPU 1에서 어떤 주소 A(1000)를 읽음
- 캐시에 주소값 없으므로 메모리에서 가져오고, 캐시에도 등록
- 잘 쓰다가, A의 주소값 1000이 2000으로 바꾸는 일 발생!
- 이때 메모리에 직접 반영하는 것은 오래걸리므로 보통 나중에 하고, 캐시에 있는 것만 2000 으로 바꿈
- 운영체제가 프로그램의 실행을 중단하고 CPU 2로 이동하기로 결정
- 프로그램이 주소 A의 값을 가져오려고 하는데, 이번엔 CPU 2에 있는 캐시에서 살펴봄
- 없으므로 메모리에서 가져오려고 하는데, 아까 캐시의 값만 수정하고 메모리의 값은 여전히 1000임... 캐시 일관성 문제 발생!
- 하드웨어에서 메모리 주소를 계속 감시하면 되긴 함
- 캐시 데이터에 대한 변경이 발생하면, 캐시에서 삭제시키거나 갱신시키는 방법
- 예)
2. 동기화 문제
CPU들이 동일한 데이터에 접근할 때(특히, 갱신) 올바른 연산 결과를 보장하기 위해 락(Lock)과 같은 상호 배제를 보장하는 동기화 방법이 많이 사용된다.
-
락(Lock)이 없을 때 일어나는 문제
typedef struct __Node_t { int value; struct __Node_t *next; } Node_t; int List_Pop() { Node_t *tmp = head; // 이전 head를 기억 ... int value = head->value; // ... 값도 기억 head = head->next; // head 를 다음 포인터로 이동 free(tmp); // 이전 head 해제 return value; // head의 값을 반환 }- 두 쓰레드가 동시에 위의 루틴으로 진입한다고 가정
- 리스트는
[1,2,3,4]로 되어있다고 하자 - 쓰레드 1이
List_pop()을 하면 1이 나올 것 - 여기서 쓰레드 2도 List_pop()`을 하면 1이 나...
-
Lock을 사용하여 올바르게 동작하게 할 수 있지만, 성능 측면에서 CPU가 늘어날수록 연산이 매우 느려지게 됨
3. 캐시 친화성 문제
캐시 친화성(cache affinity) 문제
- 프로세스는 CPU에서 실행될 때 CPU 캐시와 TLB(Translation Lookaside Buffer)에 많은 양의 정보를 올려놓게 됨
- 다음번 프로세스가 실행될 때 동일한 CPU에서 실행되는 것이 유리함 (일부 정보가 해당 CPU 캐시에 존재하므로)
- 프로세스가 매번 다른 CPU에서 실행되면 실행할 때마다 필요한 정보를 캐시에 다시 탑재해야 되므로 성능 더 나빠질 것
멀티프로세서 스케줄러는 스케줄링 결정을 내일 때 캐시 친화성을 고려해야 함
4. 단일 큐 스케줄링 (SQMS)
단일 큐 멀티프로세서 스케줄링 (single queue mulitprocessor scheduling, SQMS)
- 기존의 단일 프로세서 스케줄링 방식을 그대로 사용하되, 기존 정책을 여러개의 CPU에서 동작하도록 함
- 예를 들어 CPU가 2개면, 실행할 작업 2개를 선택할 뿐임
- 단점 1: 확장성(scalablity)의 결여
- 스케줄러가 다수의 CPU에서 제대로 동작하게 하기 위해 코드에 일정 형태의 락(Lock)을 삽입한다.
- 락은 SQMS 코드가 단일 큐를 접근할 때(실행시킬 다음 작업을 찾을 때) 올바른 결과가 나오도록 한다.
- 락은 성능을 크게 저하시킬 수 있고, CPU 개수가 많아질수록 더 그렇다.
- 단점 2: 캐시 친화성 문제
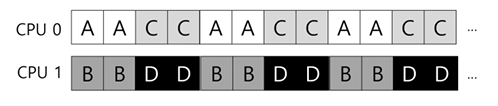
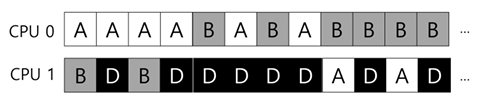
- 작업 A,B,C,D,E가 있고, 프로세서는 4개가 있다고 하자.
- 스케줄링 큐(공유 큐)는 그림과 같이 구성되어 있다고 가정

- 작업 스케줄을 아래와 같을 것
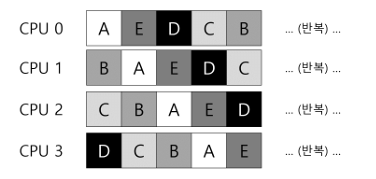
- 각 CPU는 공유 큐에서 다음 작업을 선택하기 때문에 각 작업은 CPU를 옮겨다니게 됨
- 이는 캐시 친화성 관점에서 보면 잘못된 것임
- 캐시 친화성 관점에서는 한 작업이 동일한 CPU에서 실행되는 것이 유리함
- SQMS 스케줄러가 가능한 한 프로세스가 동일한 CPU에서 재실행될 수 있도록 구성할 수 있기는 한데, 구현이 복잡함
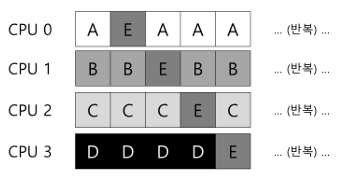
- E 빼고는 캐시 친화성 보존중
5. 멀티 큐 스케줄링(SQMS)
멀티 큐 멀티프로세서 스케줄링 (multi queue mulitprocessor scheduling, MQMS)
- SQMS와 달리 큐를 CPU마다 하나씩 두는 등 여러개의 스케줄링 큐를 두는 멀티프로세서 스케줄링 방식
- 2개의 CPU와 A,B,C,D 4개의 작업이 존자한다고 하면, 2개의 스케줄링 큐가 생길 것
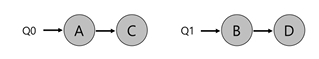
- 만약 각 CPU 별로 라운드 로빈 스케줄링을 한다면 다음과 같은 스케줄이 생성될 것
- MQMS는 SQMS에 비해 확장성이 좋다. CPU의 개수가 증가할 수 록 큐의 개수도 증가
-> 락과 캐시의 경합이 더이상 문제가 되지 않음
단점: 워크로드의 불균형(load imbalance)
- 한쪽 CPU에 작업이 몰리는 경우 워크로드의 불균형 발생
- 예 1
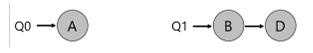
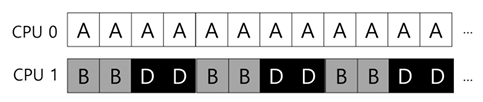
- 예 2


워크로드의 불균형 해결 방안: 작업을 이주시킴
- 이 경우엔 그냥 하나의 작업을 다른 큐로 옮기면 해결
- 이주 여러번 해야되는 경우
- 이주 한 번 하면 어차피 또 똑같은 상황이 됨
- 작업마다 번갈아가면서 이주를 여러번 시켜 해결
그렇다면 이주 필요 여부는 어떻게 결정?
작업 훔치기(work stealing)
- 작업 개수가 낮은 큐가 가끔씩 다른 큐에 훨씬 많은 수의 작업이 있는지 검사
- 만약 더 가득 차있으면 작업 몇개 훔쳐옴
- 큐를 너무 자주 검사하게 되면 높은 오버헤드로 확장성에 문제 생김
- 근데 또 검사 많이 안 하면 불균형을 초래할 수도 있음
6. Linux 멀티프로세서 스케줄러
O(1) Scheduler
- 우선순위 기반 스케줄러 (MLFQ와 유사)
- 프로세스의 우선순위를 시간에 따라 변경하여 우선순위가 가장 높은 작업을 선택하여 다양한 목적을 만족시킴
- 상호작용 우선시
- 멀티 큐 사용
CFS (Completely Fair Scheduler)
- 결정론적 비례배분 방식 (보폭 스케줄링과 유사)
- 멀티 큐 사용
BFS (Brain Fuck Scheduler)
- 비례배분 방식
- EEVDF(Earliest Eligible Virtual Deadline First) 방식, 복잡한 방식이라고 함...
- 단일 큐 사용
