Redundant Array of Inexpensive Disk (RAID)
디스크를 사용할 때 개선되면 좋은 점
- 속도: I/O 작업은 느리기 때문에 전체 시스템의 병목이 되기도 함
- 용량: 많으면 좋음
- 안정성: 디스크 고장 시 백업 없으면 데이터 손실
핵심 질문: 대용량이면서 빠르고 신뢰할 수 있는 디스크를 어떻게 만들까?
- 대용량, 고속의, 신뢰할 수 있는 저장 시스템을 어떻게 만들까?
- 핵심 기술은?
- 서로 다른 접근법들의 절충안은?
Redundant Array of Inexpensive Disk (RAID)
- 여러 개의 디스크를 병렬로 처리하여 고속이면서 대용량의 신뢰할 수 있는 디스크 시스템을 만드는 방식
- RAID는 외면적으로 하나의 디스크 처럼 보인다.
- 내부적으로 여러 개의 디스크, 메모리, 프로세서로 이루어져 있다.
- 장점
1. 성능: 디스크 여러 개를 병렬적으로 사용하면 I/O시간이 크게 개선된다.
2. 용량: 여러 개의 디스크를 사용하여 용량이 더 크다.
3. 신뢰성: 데이터 중복(redundancy) 기술을 사용하여 디스크 중 하나가 고장나도 고장이 없던 것처럼 동작할 수 있다. - 위와 같은 장점들을 투명하게(transparently) 제공한다.
- 호스트 시스템은 RAID를 그저 거대한 하나의 디스크로 인식한다.
- 따라서 소프트웨어 변경없이 디스크를 RAID로 바꿀 수 있다는 것
이다. - 운영체제와 클라이언트 응용 프로그램은 변경 없이 계속 동작할 수 있고, 이러한 투명성은 RAID의 확산력(deployability)을 크게 개선시켰다.
1. 인터페이스와 RAID의 내부
RAID의 인터페이스
- 파일 시스템에게 RAID는 크고 빠르고 신뢰할 수 있는 디스크로 보인다.
- RAID도 선형적인 블럭들의 배열로 보이며 파일 시스템 (또는 다른 클라이언트) 이 각 블럭을 읽거나 쓸 수 있다.
- I/O 요청 동작
- 파일 시스템이 RAID에 논리적 I/O를 요청한다.
- RAID는 내부에서 어떤 디스크(또는 디스크들)를 접근해야 요청을 완료할 수 있는지 계산한다.
- 하나 또는 그 이상의 물리적 I/O를 발생시킨다.
- 서로 다른 디스크에 2개의 복사본을 유지하는 미러링 기법의 RAID의 경우, 하나의 논리적 I/O에 대해 두 개의 물리적 I/O를 실행해야 한다.
RAID의 내부
- RAID 시스템은 보통 별도의 하드웨어 박스 형태로 되어 있으며 호스트와 SCSI나 SATA와 같은 표준 인터페이스로 연결된다.
- 마이크로 컨트롤러: RAID의 작업을 지시하는 펌웨어 실행
- 휘발성 메모리: 블럭 읽기/쓰기용 버퍼 (ex. DRAM)
- 비휘발성 메모리: 쓰기를 안전하게 버퍼링하기 위한 용도로 사용
- 전용 논리 회로: 패리티 계산을 위한 용도
2. 결함 모델
RAID는 특정 종류의 결함을 파악하고 이를 복구하도록 설계되어 있다. 그렇기 때문에 설계시 어떤 종류의 결함에 대비를 해야 하는지를 파악하는 것이 매우 중요하며, 따라서 결함 모델(fault model)이 필요하다.
고장 시 멈춤(fail-stop) 결함 모델
- 이 모델에서 디스크는
정상 작동이거나멈춤둘중 하나의 상태로 있다고 가정한다.- 동작중인 디스크에는 모든 블럭을 읽거나 쓸 수 있다.
- 멈충 상태의 디스크는 완전히 사용 불가능하다.
- 단점: 디스크가 고장나면 쉽게 파악할 수 있다고 가정하지만, 실제로 쉽지 않음
논의를 위한 가정
- 디스크 섹터내용이 망가지는 것과 같은 “조용한” 고장들에 대해서는 고려하지 않는다.
- 디스크에서 한 블럭만 접근할 수 없는 고장에 대해서도 고려하지 않는다.
3. RAID의 평가 방법
이제 곧 보게 되겠지만 RAID를 구성하는 몇 가지 방법이 있다. 각 구성 방법은 서로 다른 특성을 갖고 있기 때문에 여러 방법 간의 장점과 단점을 이해하기 위해서는 평가 수단이 필요하다.
RAID 설계 평가 기준
- 용량
B개의 블럭을 갖는N개의 디스크 -> RAID의 유효 용량은N*B- 각 블럭에 대해 두 개의 복사본을 갖는다면 -> RAID의 유효 용량은
N*B/2 - 다른 기법(예, 페리티 기반 기법)은 그 사이의 값을 갖는다.
- 신뢰성
- 몇 개의 디스크 결함을 감내할 수 있는가?
- 이번 논의에서는 하나의 디스크만 고장날 수 있다고 가정
- 성능
- 성능은 배열이 처리해야 할 워크로드에 따라 크게 달라진다.
- 따라서 성능 평가 이전에 일반적인 워크로드를 제시할 것이다.
이제 3개의 중요한 RAID 설계를 살펴볼 것이다.
- RAID 레벨 0: 스트라이핑
- RAID 레벨 1: 미러링
- RAID 레벨 4/5: 패리티를 이용한 공간 절약
4. RAID 레벨 0: 스트라이핑
참고로 스트라이핑 방식은 중복 저장을 하지 않기 때문에 RAID 레벨이 아니지만, 성능과 용량에 대한 훌륭한 상한 기준을 나타내기 때문에 이해하고 넘어갈 만하다.
RAID 레벨 0: 스트라이핑
- 가장 간단한 스트라이핑은 다음 그림과 같이 블럭들을 여러 디스크에 걸쳐서 줄을 긋는 것처럼 저장한다.

- 디스크 배열의 블럭들을 라운드 로빈 방식으로 디스크를 가로질러 저장한다.
- 스트라이프(stripe): 한 행에 있는 블럭들 (블럭 0,1,2,3)
- 꼭 한 블럭 단위(4KB)로 배치할 필요는 없다.

- 이런식으로 두 블럭마다 다음 디스크로 넘어가도록 배치할 수도 있다.
- 해당 배열의 청크 크기는 8KB
청크 크기
청크 크기는 RAID의 성능에 큰 영향을 준다.
작은 청크 크기
- 많은 파일들이 여러 디스크에 걸쳐 스트라이프 된다.
(스트라이프 수 많아짐) - 하나의 파일을 읽고 쓰는 데 병렬성이 증가한다.
- 블럭의 위치를 여러 디스크에서 찾아야 하므로 위치 찾기 시간이 늘어난다.
- 왜냐하면 요청 처리 시간은 여러 디스크에 걸친 요청들 중에 가장 오래걸린 찾기 시간에 의해 결정되기 때문이다.
큰 청크 크기
- 파일 내의 병렬성은 줄어든다.
(스트라이프 수 적음) - 따라서 높은 처리 성능을 얻으려면 여러 요청을 병행하게 실행해야 한다.
- 위치 찾기 시간은 줄어든다.
- 예를 들어, 파일이 작아 단일 청크에 저장이 된다면, 요구되는 위치 찾기 시간은 한 디스크에서 그 위치를 찾는 시간과 동일
이후의 논의에서는 청크 크기는 한 블럭의 크기 (4KB) 로 가정한다. 또한 논의를 간단하게 하기 위해 청크의 크기를 한 블럭으로 가정한다.
RAID-0 분석 (1)
- 용량:
N개의 디스크에서 스트라이핑의 유효 용량은N*B - 신뢰성: 어느 디스크라도 고장나면 전체 데이터가 손실된다.
- 성능: 병렬로 사용자의 I/O 요청을 처리할 수 있기 때문에 모든 디스크가 활용된다.
RAID의 성능 평가하기
RAID의 성능을 분석하기 위해 두 가지 다른 성능 척도를 고려해야 한다.
- 단일 요청의 지연 시간
- 하나의 I/O를 처리하는 데 걸리는 RAID의 지연 시간에 대한 이해는,
한 번의 논리적 I/O 동작을 처리할 때의 병렬성 정도를 파악하는 데 도움이 된다.
- 하나의 I/O를 처리하는 데 걸리는 RAID의 지연 시간에 대한 이해는,
- 정상 상태(steady state)에서의 처리성능(throughput)
- 병행 요청의 전체적인 대역폭을 말한다.
- 고성능을 요하는 환경에서 RAID가 주로 사용되기 때문에 안정 (stable) 상태에서의 대역폭은 매우 중요하며 우리 분석의 주요 초점이다.
논의를 위해 순차와 랜덤 워크로드의 두 가지 유형만 있다고 있다고 가정한다.
- 순차 워크로드
- 워크로드가 연속된 큰 청크의 형태로 RAID에 요청된다.
- 예를 들어, 1MB 크기의 요청이 블럭
B에서 시작하여B+1MB에서 끝나면 순차적이라고 본다. - 큰 파일에서 키워드를 찾는 경우 등 흔히 발생된다.
- 랜덤 워크로드
- 크기가 작은 요청이며 또한 디스크의 여러 불특정 위치를 접근한다고 가정한다.
- 예를 들어 논리주소 10에서 첫 번째 블럭을 접근하고, 다음 논리주소는 550000, 그다음은 20100 ...
- DBMS의 트랜젝션과 같은 중요 워크로드에서 이와 같은 접근 패턴을 보여 중요하다.
순차 워크로드 vs 랜덤 워크로드
- 순차 워크로드
- 디스크가 가장 효율적으로 동작한다.
- 탐색과 회전 지연이 짧아 대부분의 시간을 데이터 전송에 사용한다.
- 랜덤 워크로드
- 대부분의 시간을 탐색과 회전을 기다리는 데 사용되고 상대적으로 적은 시간이 데이터 전송에 사용된다.
- 일반적으로 순차 워크로드의 전송속도(
SMB/s)가 랜덤 워크로드의 전송속도(RMB/s)보다 매우 크다. (S>>>>R) - 예제)
- 디스크 평균 탐색 시간: 7ms
디스크 평균 회전 시간: 3ms
디스크 전송 속도: 50MB/s - 순차 워크로드 10MB 전송시 속도
S계산- 탐색 + 회전 시간 = 10ms
- 전송 시간 = 10MB / 50MB/s = 0.2초 = 200ms
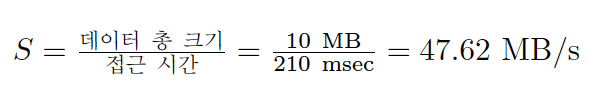
- 랜덤 워크로드 10KB 전송시 속도
R계산- 탐색 + 회전 시간 = 10ms
- 전송 시간 = 10KB / 50MB/s = 0.195ms
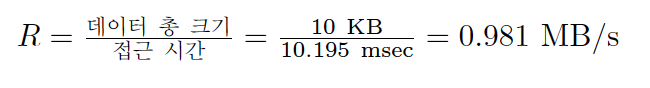
- 디스크 평균 탐색 시간: 7ms
RAID-0 분석 (2)
- 지연 시간 측면
- 한 블럭에 대한 요청의 지연 시간은 하나의 디스크에 대한 요청의 지연 시간과 거의 동일하다.
- RAID-0은 받은 요청을 디스크 중 하나에게 전달하는 것뿐이기 때문이다.
- 정상 상태에서의 처리성능(throughput) 측면
- 정상 상태에서의 대역폭 측면에서 시스템의 최대 대역폭을 기대할 수 있다.
- 순차 워크로드 처리성능 = (디스크 수)
S= `N S` - 랜덤 워크로드 처리성능 = 모든 디스크를 다 사용 가능하므로
N * R
5. RAID 레벨 1: 미러링
RAID 레벨 1: 미러링
- 미러링을 사용하는 시스템에서는 각 블럭에 대해서 하나 이상의 사본을 둔다.
- 각 사본은 서로 다른 디스크에 저장되어야 하고, 이렇게 함으로써 디스크 고장에 대처할 수 있게 된다.
- RAID-10 방식 예제 (혹은 RAID 1+0 방식)

- 위 예제에서는 디스크 0과 1이 동일한 값을 갖고 디스크 2와 3이 동일한 값을 갖는다.
- 데이터는 미러링 된 쌍들에 대해서 스트라이핑을 적용하였다.
- 미러링(RAID 1) 후 스트라이핑(RAID 0)을 하므로 RAID-10 방식
- 읽기 시 원본을 읽을지 사본을 읽을지 선택할 수 있다.
- 쓰기 시 신뢰성을 유지하기 위해 두 블럭에 대해 데이터를 모두 갱신해야 한다.
RAID-1 분석
- 용량: 미러링 레벨이 2라면 유효 용량은 `N*B/2
- 신뢰성: 미러링 레벨이 2라면, 한 개의 디스크 고장은 확실히 감내할 수 있다.
- 최대 N/2 개의 고장까지 감내 가능
- 성능
- 지연 시간 측면
- 읽기: 단일 읽기 요청의 지연 시간은 단일 디스크에서 읽는 경우의 지연 시간과 동일하다.
- RAID-1이 하는 일은 두 벌의 사본 중에 하나의 디스크로 요청을 전달하는 것이기 때문이다.
- 쓰기: 평균적으로 하나의 디스크에 쓰는 시간보다는 조금 더 길다.
- 쓰기 요청이 완료되기 위해서는 두 개의 디스크로 전달된 쓰기가 모두 종료되어야 한다.
- 하지만 RAID-1에 요청된 쓰기는 물리적으로 두개의 쓰기연산이 종료될 때까지 대기해야 한다.
- 그 지연시간은 두 개의 요청 중 최악의 탐색과 회전 지연 시간에 의해 결정된다.
- 읽기: 단일 읽기 요청의 지연 시간은 단일 디스크에서 읽는 경우의 지연 시간과 동일하다.
- 처리성능 측면
- 순차 워크로드
- 읽기: 각 디스크의 관점에서는 블럭을 건너 뛰어야 하고, 블럭 위를 회전하는 동안엔 유용한 대역폭을 제공하지 않으므로, 대역폭은 절반이다. (
N*S/2) - 쓰기: 두 번의 물리 쓰기가 필요하므로 대역폭은 절반이다. (
N*S/2)
- 읽기: 각 디스크의 관점에서는 블럭을 건너 뛰어야 하고, 블럭 위를 회전하는 동안엔 유용한 대역폭을 제공하지 않으므로, 대역폭은 절반이다. (
- 랜덤 워크로드
- 읽기: 모든 디스크에 읽기를 다 요청할 수 있기 때문에 얻을 수 있는 최대의 대역폭을 얻을 수 있다. (
N*R) - 쓰기: 각 논리 쓰기는 두 번의 물리 쓰기로 바뀌어야 하기 때문에 모든 디스크가 사용이 되더라도 사용자는 모든 대역폭의 반만 얻을 수 있다. (
N*R/2)
- 읽기: 모든 디스크에 읽기를 다 요청할 수 있기 때문에 얻을 수 있는 최대의 대역폭을 얻을 수 있다. (
- 순차 워크로드
- 지연 시간 측면
6. RAID 레벨 4: 패리티를 이용한 공간 절약
RAID 레벨 4: 패리티
- 중복성을 추가하여 저장 공간의 낭비를 극복한 RAID 방법 (대신 성능이 조금 떨어진다).

- 각 데이터 스트라이프마다 해당 스트라이프에 대한 중복 정보를 담고 있는 패리티 블럭 (
Pn) 하나씩 추가한다. - 고장 판별 및 감내
- XOR 함수를 이용하면 특정 블럭이 고장나도 데이터를 복구할 수 있다.

- 위 상황에서 C2의 첫번째 행의 값이 깨졌다고 하자.
- C0, C1, C3는 각각 0,0, 1의 값을 가질 것이다.
- 이때 패리티가 0이므로 (=1의 개수가 짝수개), C2의 값은 1임을 알 수 있다.
- XOR 함수가 RAID의 패리티가 정확하게 동작하기 위해서 반드시 유지해야 하는 불변량을 충족시켜준다.
- XOR 함수를 이용하면 특정 블럭이 고장나도 데이터를 복구할 수 있다.
- 각 데이터 스트라이프마다 해당 스트라이프에 대한 중복 정보를 담고 있는 패리티 블럭 (
RAID-4 분석
- 용량: 패티리 정보를 하나 사용하므로
(N-1) * B - 신뢰성: 오직 하나의 디스크 고장을 감내할 수 있다.
- 성능
- 지연 시간 측면
- 읽기: 단일 읽기 요청의 지연 시간은 단일 디스크에서 읽는 경우의 지연 시간과 동일하다.
- 쓰기: 쓰기 요청 한 개의 지연 시간은 읽기 2번과 쓰기 2번이 필요하다.
- 전체 지연 시간: 읽기와 쓰기가 병렬적으로 처리될 수 있기 때문에, 전체 지연 시간은 한 개의 디스크 요청의 두 배 정도이다.
- 처리성능 측면
- 순차 워크로드
- 읽기:
(N − 1) * S - 쓰기:
(N − 1) * S
- 읽기:
- 랜덤 워크로드
- 읽기:
(N − 1) * R - 쓰기:
R/2- 랜덤 쓰기 요청은 패리티 디스크로 인해서 순차적으로 처리된다. (small-write 문제)
- 패리티 디스크는 논리 I/O 당 읽기 1회와 쓰기 1회의 두 개의 I/O 를 처리해야 한다.
- 읽기:
- 순차 워크로드
- 지연 시간 측면
7. RAID 레벨 5: 순환 패리티
패리티로 인해 발생하는 small-write 문제를 해결하기 위해 패리티 블럭은 순환(rotate)시키는 방식이다.
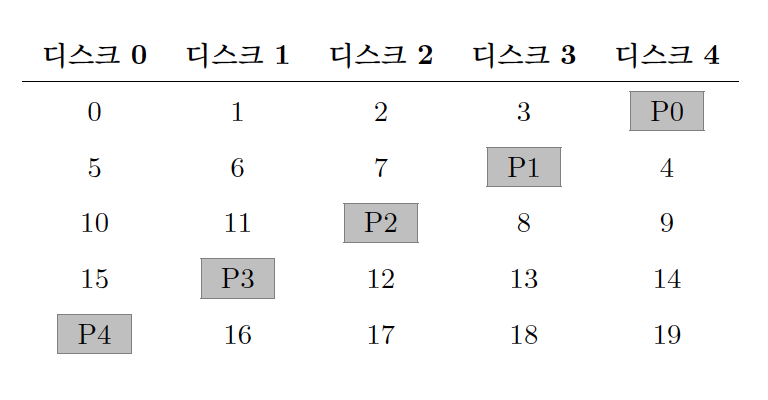
RAID-5 분석
RAID-4와 대부분이 동일하다.
- 용량, 신뢰도 동일
- 순차 읽기/쓰기 성능 동일
- 랜덤 읽기 성능 약간 더 좋음 (모든 디스크 다 활용 가능)
- 랜덤 쓰기 성능 훨씬 좋음 (요청들을 병렬적으로 처리할 수 있기 때문)
- 예를 들어, 블럭 1번, 10번에 쓰기 요청 -> 디스크 0(P0), 2(P2)에 패리티 요청
8. RAID 비교 : 정리
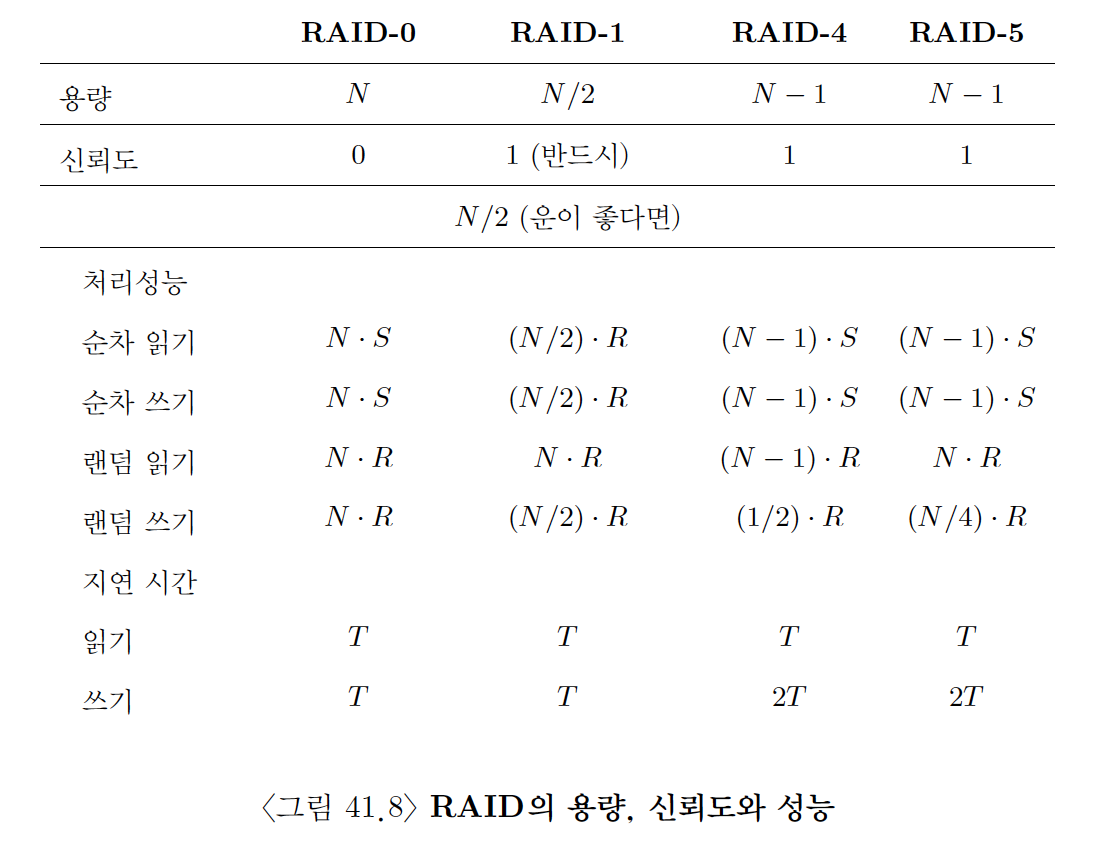
9. RAID와 관련된 다른 흥미로운 주제들
- 대체용 스페어 (hot spare)
- 잠재된 섹터 오류(latenet sector error)
- 블럭 훼손 (block corruption)
- 소프트웨어 RAID
