I/O 장치
본론(영속성)에 들어가기에 앞서 먼저입력/출력 장치의 개념을 소개하고 운영체제가 이 장치들과 상호 작용하는 방법을 알아보자.
핵심 질문 : 어떻게 I/O를 시스템에 통합할까
- 시스템에 I/O를 어떻게 통합해야 하는가? 일반적인 방법은 무엇인가?
- 어떻게 효율적으로 통합할 수 있을까?
1. 시스템 구조
논의를 시작하기 위해 일반적인 시스템 구조를 살펴보자.
시스템 구조 모형
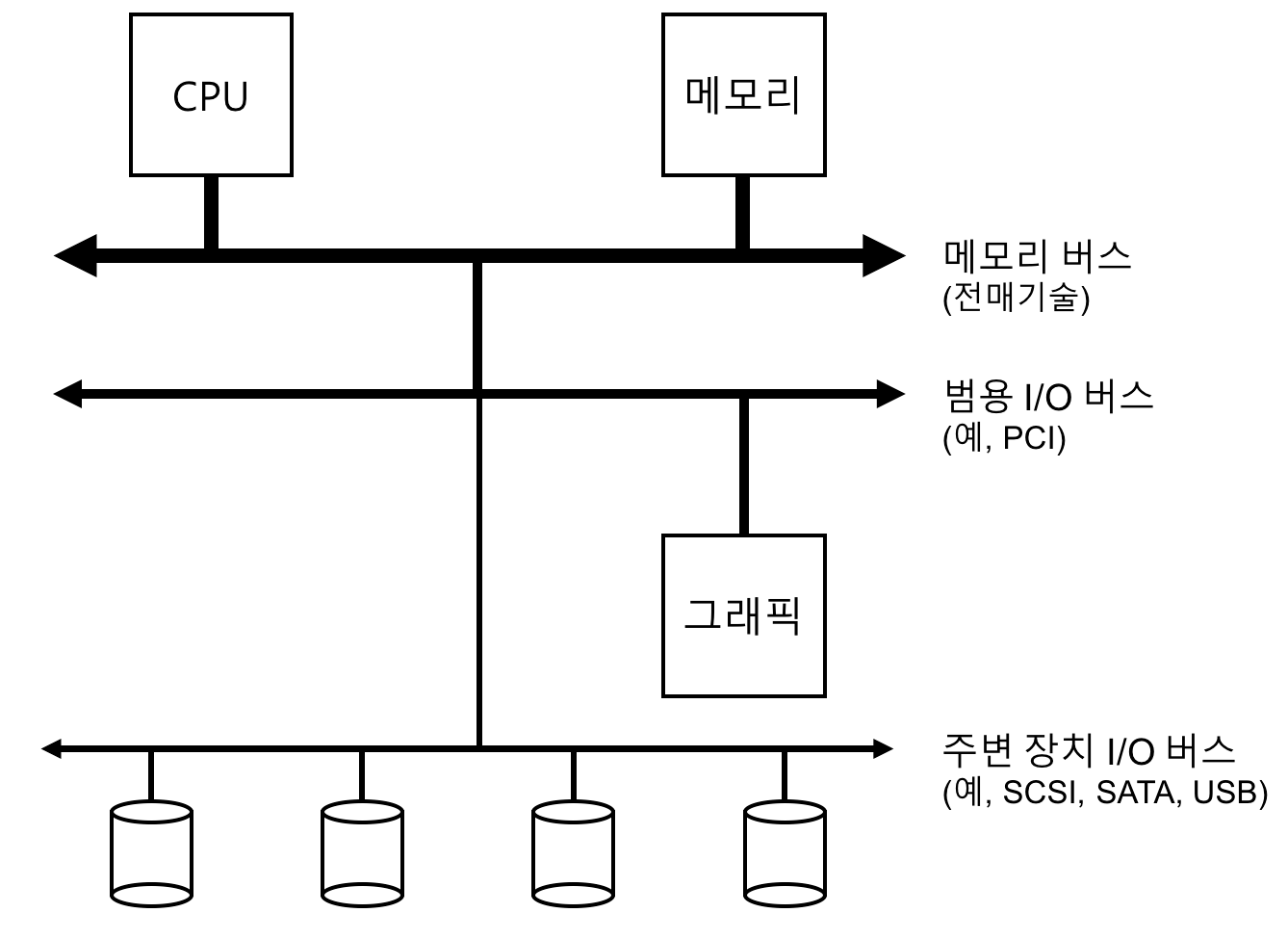
- 메모리 버스: CPU와 주메모리를 연결해주는 버스
- 범용 I/O 버스: 그래픽이나 다른 고성능 I/O 디바이스들을 연결하는 버스
- 많은 현대 시스템에서는 PCI 버스 (또는 PCI 파생 버스)를 사용하고 있다.
- 주변장치용 버스: 디스크, 마우스와 같이 느린 디바이스들이 연결되는 버스
- SCSI, SATA, USB 등 사용
- 시스템이 이러한 계층 구조를 갖는 이유는 물리학적인 이유와 비용 때문이다.
- 버스가 고속화되려면 길이가 짧아야 하는데, 그런 고속 메모리 버스는 여러 디바이스들을 수용할 공간이 없다.
- 고성능 버스는 비싸다.
현대 시스템 구조 모형 (Intel Z270 칩셋)
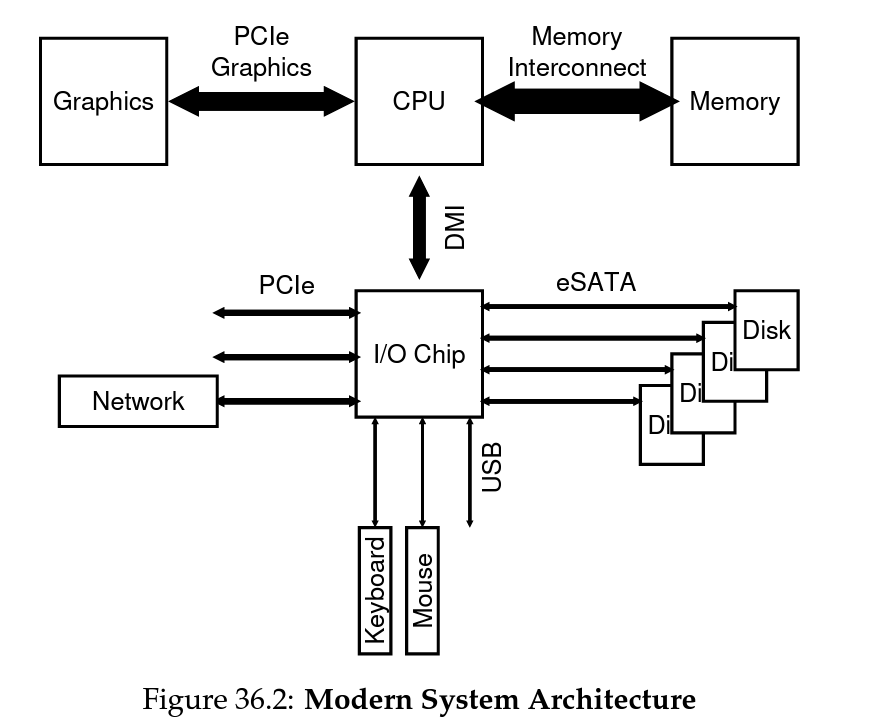
- CPU는 메모리, 그래픽카드와 가장 가까이에 존재하고 있음
- 이는 그래픽 관련 작업(디스플레이, 게임 등)의 중요도가 높아졌음을 의미
- I/O Chip
- 인텔의 자사 DMI(Direct Media Interface)로 CPU와 연결되어 있다.
- I/O 칩을 통해 나머지 디바이스들(네트워크, 하드웨어 디바이스, 디스크 등)과 연결됨
2. 표준 장치 (A Canonical Device)
가상의 표준 장치를 살펴보고 이 장치를 효율적으로 활용하기 위해 필요한 것은 무엇인지 알아보자.
표준장치
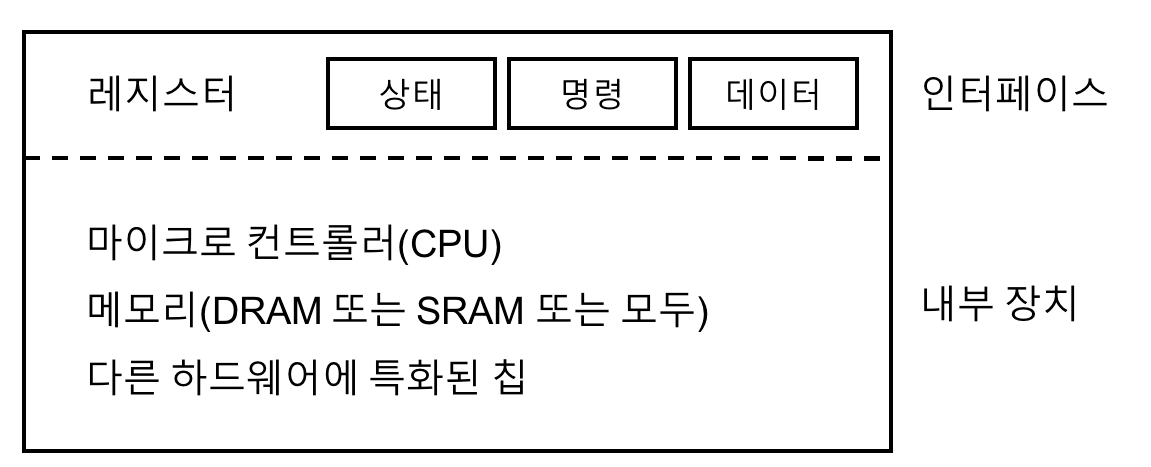
- 인터페이스
- 시스템의 다른 구성 요소에게 제공하는 하드웨어 인터페이스
- 하드웨어 인터페이스를 제공하여 시스템 소프트웨어가 동작을 제어할 수 있도록 해야한다.
- 모든 하드웨어 디바이스들은 특정한 상호 동작을 위한 방식과 명시적인 인터페이스를 갖고 있다.
- 내부 구조(장치)
- 시스템에게 제공하는 디바이스에 대한 추상화를 정의한다.
- 매우 단순한 디바이스들은 하나 또는 몇 개의 하드웨어 칩을 사용하여 구현
- 복잡한 디바이스는 CPU와 범용 메모리, 그리고 디바이스에 특화된 칩들을 사용하여 목적에 맞는 동작을 하게끔 한다.
- 최신 RAID 컨트롤러는 수십만줄에 달하는 펌웨어(firmware)라는 소프트웨어가 하드웨어 내부의 동작을 정의하고 있다.
- 시스템에게 제공하는 디바이스에 대한 추상화를 정의한다.
3. 표준 방식 (The Canonical Protocol)
위에서 보인 단순화된 디바이스의 인터페이스는 세 개의 레지스터로 구성되어 있다.

- 상태(status) 레지스터: 디바이스의 현재 상태를 읽을 수 있다.
- 명령어(command) 레지스터: 디바이스가 특정 동작을 수행하도록 요청할 때 사용한다.
- 데이터(data) 레지스터: 디바이스에 데이터를 보내거나 받을 때 사용한다.
이 레지스터들을 읽거나 쓰는 것을 통해 운영체제는 디바이스의 동작을 제어할 수 있다.
이번에는 디바이스가 운영체제를 대신하여 특정 동작을 할 때에 운영체제와 디바이스 간에 일어날 수 있는 상호 동작의 과정을 살펴보자. 이 경우 다음과 같은 방식을 따른다.
while (STATUS == BUSY)
; // 디바이스가 바쁜 상태가 아닐 때까지 대기
데이터를 DATA 레지스터에 쓰기
명령어를 COMMAND 레지스터에 쓰기
(그러면 디바이스가 명령어를 실행한다)
while (STATUS == BUSY)
; // 요청을 처리하여 완료할 때까지 대기- 폴링(polling) - 반복적으로 디바이스의 STATUS 레지스터를 읽어 명령의 수신 가능 여부 확인
- DATA 레지스터에 데이터 전달
(데이터 전송에 메인 CPU가 관여하는 경우를 programmed I/O라고 한다) - COMMAND 레지스터에 명령어 기록 -> 디바이스가 명령어 실행
- 처리를 완료했는지 확인하는 폴링 반복문을 돌면서 기다린다. (성공 or 실패)
이 방식은 잘 동작하지만 폴링을 사용한다는 점에서 매우 비효율적이다.
폴링의 단점
- 폴링은 루프를 도는 동안 다른 프로세스에게 CPU를 양도하지 않는다.
- 입출력 장치는 매우 느리고, 대기중에 특별히 따로 하는 일이 없지만 CPU 시간을 많이 소모하게 된다.
핵심 질문 : 폴링 사용 비용을 어떻게 피하는가
어떻게 하면 자주 폴링을 하지 않으면서 운영체제가 디바이스의 상태를 확인할 수 있고, 디바이스를 관리하는 CPU의 오버헤드를 줄일 수 있을까?
4. 인터럽트를 이용한 CPU 오버헤드 개선
인터럽트
- 운영체제는 입출력 작업을 요청한 프로세스를 블록 시키고 CPU를 다른 프로세스에게 양도한다. (폴링 대신 인터럽트!)
- 디바이스가 작업을 끝마치고 나면 하드웨어 인터럽트를 발생시켜 인터럽트 핸들러(interrupt handler)를 실행한다.
- 인터럽트 핸들러: 운영체제 코드의 일부로, 입출력 요청의 완료, I/O를 대기 중인 프로세스 깨우기 등을 담당한다.
- CPU 연산과 I/O의 중첩 - 사용률을 높이는 핵심 방법

- 프로세스 1의 요청이 디스크에서 처리되는 동안에, 운영체제는 프로세스 2를 CPU에서 실행시킨다.
- 만약 인터럽트 없이 폴링을 한다면, I/O 요청이 디스크에서 처리되는 동안에 CPU에선 폴링을 하여 CPU 시간의 낭비가 발생한다.
팁 : 인터럽트가 폴링보다 항상 좋은 것은 아니다
- 인터럽트을 사용하면 연산과 I/O 작업을 중첩시킬 수 있지만 느린 디바이스에 대해서만 타당한 접근법이다.
- 만약 대부분의 작업이 한 번의 폴링만으로 끝날 정도로 매우 빠른 디바이스인 경우, 문맥 교환 비용이 인터럽트가 제공하는 장점을 넘어서게 된다.
- 즉, 빠른 디바이스에선 폴링이 좋은 방법이 될 수 있다.
- 네트워크 환경에선 인터럽트를 사용하지 않는다.
- 네트워크 패킷마다 인터럽트가 발생되는데, 이 경우 인터럽트만 처리하다가 다른 요청을 처리하지 못하게 되는 livelock에 빠질 수 있다.
- 이 경우 폴링을 사용하면 웹 서버가 패킷 도착을 검사하기 전에 사용자 요청들을 좀 더 처리할 수 있어 인터럽트보다 효율적이다.
하이브리드 방식
- 짧은 시간동안만 폴링을 하다가, 처리가 완료되지 않으면 인터럽트를 사용하는 방식
병합(coalescing) 방식
- CPU에 인터럽트를 전달하기 전에 잠시 기다렸다가 인터럽트를 발생시킨다.
- 기다리는 동안에 다른 요청들도 끝나기 때문에 여러 번 인터럽트를 발생시키는 대신 인터럽트를 한 번만 CPU에 전달하게 된다.
- 이 방법으로 인터럽트 처리의 오버헤드를 줄일 수 있다.
- 물론, 너무 오래 기다리면 요청에 대한 지연 시간이 늘어나기 때문에 시스템의 절충 시간을 찾아야 한다.
5. DMA를 이용한 효율적인 데이터 이동
많은 양의 데이터를 디스크로 전달하기 위해 programmed I/O(PIO)를 사용하면 CPU가 또 다시 단순 작업 처리에 소모된다.

- 프로세스 1이 실행 도중에 어떤 데이터를 디스크에 기록하려고 한다.
- 그래서 I/O를 발생시켜서 명시적으로 데이터를 메모리에서 디스크로 한 워드씩 복사한다 (그림에서 c로 표기).
- 복사가 완료되면 디스크에서 I/O의 처리를 시작하고, 마침내 CPU를 다른 작업 처리에 사용할 수 있게 된다.
핵심 질문 : 어떻게 PIO의 오버헤드를 줄이는가
PIO를 사용하면 CPU는 너무 많은 시간을 데이터를 디스크에서 또는 디스크로 이동하는 데 사용한다. 이 작업을 어떻게 줄일 수 있으며 CPU를 더 효율적으로 활용하는 방법은 무엇인가?-> DMA 방식을 사용하자
직접 메모리 접근 방식(Direct Memory Access, DMA)
- DMA 엔진은 시스템 내에 있는 특수 장치로서 CPU의 간섭없이 메모리와 디바이스 간에 전송을 담당한다.
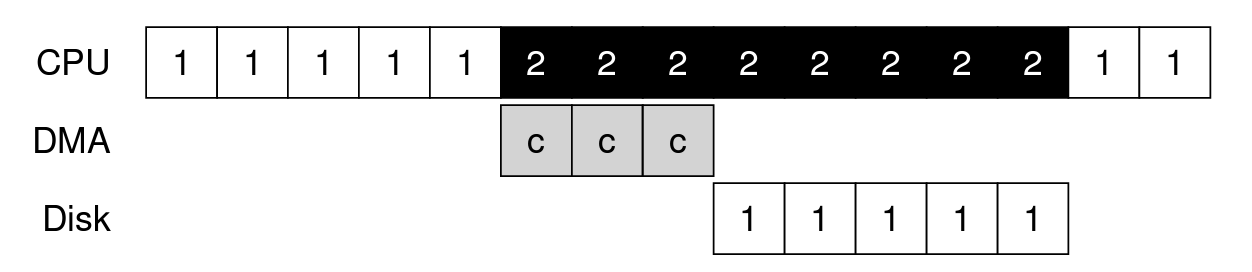
- 운영체제는
메모리 상의 데이터 위치,전송할 데이터의 크기,대상 디바이스와 같은 정보를 DMA 엔진에 넘겨준다. - 이후 데이터의 복사 작업은 DMA 컨트롤러가 처리한다.
- 프로세스 1이 다시 실행하기 전에 프로세스 2가 더 많은 CPU를 사용할 수 있다.
- 운영체제는
6. 디바이스와 상호작용하는 방법
디바이스와 운영체제가 실제로 어떻게 정보를 교환하는지 알아보자.
1. I/O 명령을 명시적으로 사용
- x86의 경우
in과out명령어를 사용하여 디바이스들과 통신 - 이 명령어들은 대부분 특권 명령어 (previledge instruction)들이다.
- 즉, 운영체제를 디바이스를 제어하는 역할을 하고, 운영체제만이 디바이스들과 직접 통신할 수 있다.
- 그런데 만약 어떤 사용자 프로그램이 허점을 이용하여 디바이스의 제어권을 갖게된다면? 큰일 난다.
2. Memory mapped I/O 사용
- 하드웨어는 디바이스의 레지스터들이 마치 메모리 상에 존재하는 것처럼 만든다.
- 특정 레지스터를 접근하기 위해서 운영체제는 해당 주소에 load(읽기) 또는 store(쓰기)를 하면 된다.
- 하드웨어는 load/store 명령어가 주 메모리를 향하는 대신 디바이스로 연결되도록 한다.
근데 두 방식 모두 대단히 큰 장점은 없고, 둘다 현재도 쓰인다고 한다...
7. 운영체제에 연결하기: 디바이스 드라이버
최종적으로 다룰 문제는 서로 다른 인터페이스를 갖는 장치들과 운영체제를 연결시키는 가능한 일반적인 방법을 찾는 것이다.
핵심 질문 : 어떻게 장치 중립적인 운영체제를 만드는가
어떻게 하면 운영체제를 장치 중립적으로 만들고, 장치와의 상호작용을 위한 상세 내용을 운영체제로부터 숨길 수 있을까?
디바이스 드라이버를 이용한 추상화
- 운영체제 최하위 계층의 일부 소프트웨어는 장치의 동작 방식을 알고 있어야 한다.
- 이 소프트웨어를 디바이스 드라이버(device driver)라고 한다.
- 장치와의 상세한 상호작용은 그 안에 캡슐화 되어있다.
- 리눅스 파일 시스템 소프트웨어 계층
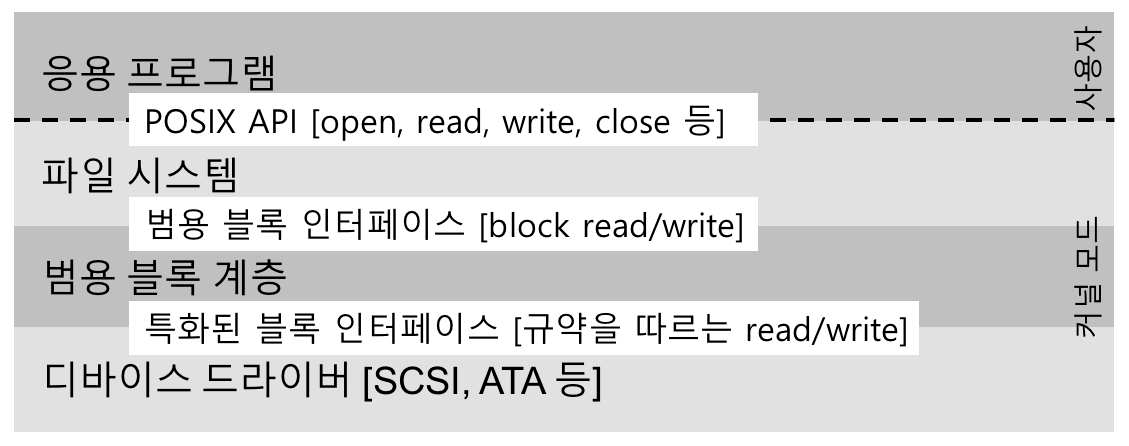
- 응용 프로그램 및 파일 시스템은 어떤 디스크를 사용하는지 전혀 모름
- 파일 시스템 - 범용 블록 계층에 블럭
read/write요청을 할 뿐이다. - 범용 블럭 계층 - 적절한 디바이스 드라이버로 받은 요청을 전달한다.
- 디바이스 드라이버 - 특정 요청을 디바이스에 내리기 위해 필요한 일들을 처리한다.
- 캡슐화의 단점
- 특수 기능이 많은 디바이스가 있다고 할 때, 커널이 범용적인 인터페이스만을 제공한다면 특수 기능을 사용할 수 없게 된다.
참고) 운영체제 코드의 70%가 디바이스 드라이버를 위한 코드이다.
- 어떤 디바이스를 시스템에 연결하든, 디바이스 드라이버가 필요하다.
- 때문에 시간이 흐름에 따라 디바이스 드라이버 코드가 커널 코드의 대부분을 차지하게 되었다.
8. 사례 연구: 간단한 IDE 디스크 드라이버
IDE 디스크 드라이브를 살펴보자.
IDE 디스크는 시스템에 다음과 같은 4개의 레지스터로 이루어진 단순한 인터페이스를 제공한다.
- 레지스터 종류:
Control,Command block,Status,Error - 이 레지스터들은 (x86의)
in과outI/O 명령어를 사용하여 특정 "I/O 주소들"(아래의0x3F6와 같은)을 읽거나 씀으로써 접근 가능하다.
// IDE 인터페이스
Control Register:
Address 0x3F6 = 0x80 (0000 1RE0): R=reset , E=0 means "enable interrupt"
Command Block Registers:
Address 0x1F0 = Data Port
Address 0x1F1 = Error
Address 0x1F2 = Sector Count
Address 0x1F3 = LBA low byte
Address 0x1F4 = LBA mid byte
Address 0x1F5 = LBA hi byte
Address 0x1F6 = 1B1D TOP4LBA: B=LBA , D=drive
Address 0x1F7 = Command/status
Status Register (Address 0x1F7):
7 6 5 4 3 2 1 0
BUSY READY FAULT SEEK DRQ CORR IDDEX ERROR
Error Register (Address 0x1F1): (check when Status ERROR==1)
7 6 5 4 3 2 1 0
BBK UNC MC IDNF MCR ABRT T0NF AMNF
BBK = Bad Block
UNC = Uncorrectable data error
MC = Media Changed
IDNF = ID mark Not Found
MCR = Media Change Requested
ABRT = Command aborted
T0NF = Track 0 Not Found
AMNF = Address Mark Not Found- 디바이스와 상호작용하기 위한 기본 방식
- 디바이스가 준비될 때까지 대기: 드라이브가 사용 중이지 않고
READY상태가 될 때까지 Status 레지스터 (0x1F7) 를 읽는다. - Command 레지스터에 인자 값 쓰기: 섹터의 수와 접근해야 할 섹터들의 논리 블럭 주소(LBA), 그리고 드라이브 번호를 Command 레지스터(
0x1F2-0x1F6)에 기록한다.- IDE는 두 개의 드라이브만 지원하기 때문에 드라이브 번호는 마스터인 경우
0x00, 슬레이브인 경우0x10이다.
- IDE는 두 개의 드라이브만 지원하기 때문에 드라이브 번호는 마스터인 경우
- I/O 시작: Command 레지스터에 읽기/쓰기를 전달한다. READ-WRITE 명령어를 Command 레지스터에 기록한다 (
0x1F7). - (쓰기의 경우) 데이터 전송: 드라이브의 상태가 READY이고 DRQ일 때까지 기다린다. 이후 데이터 포트에 데이터를 기록한다.
- DRQ: Drive Request for data, 데이터를 위한 드라이브 요청
- 인터럽트 처리
- 간단한 방법: 각 섹터가 전송되었을 때마다 인터럽트를 처리
- 좀 더 복잡한 방법: 일괄처리가 가능하도록 만들어서, 모든 전송이 완료되었을 때 최종적으로 한 번만 인터럽트를 발생
- 에러 처리: 각 동작 이후에 Status 레지스터를 읽는다. 만약 ERROR 비트가 설정되어 있다면 Error 레지스터를 읽어서 상세 정보를 확인한다.
- 디바이스가 준비될 때까지 대기: 드라이브가 사용 중이지 않고
대부분의 프로토콜은 xv6 IDE 드라이버에 나타나 있으며, (초기화 이후에) 네 개의 기본 함수를 통하여 동작한다.
// xv6 IDE 디스크 드라이버 (단순화한 버전)
static int ide_wait_ready() {
while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY))
; // 드라이브가 바쁘지 않을 때까지 반복문 수행
}
static void ide_start_request(struct buf *b) {
ide_wait_ready();
outb(0x3f6 , 0); // 인터럽트 발생
outb(0x1f2 , 1); // 섹터는 몇 개?
outb(0x1f3 , b−>sector & 0xff); // 여기에 LBA 기록. . .
outb(0x1f4 , (b−>sector >> 8) & 0xff); // . . . 여기도
outb(0x1f5 , (b−>sector >> 16) & 0xff); // . . . 여기도!
outb(0x1f6 , 0xe0 | ((b−>dev&1)<<4) | ((b−>sector>>24)&0x0f));
if(b−>flags & B_DIRTY){
outb(0x1f7 , IDE_CMD_WRITE); // 이것이 WRITE 명령어
outsl(0x1f0 , b−>data , 512/4); // 데이터도 전송!
} else {
outb(0x1f7 , IDE_CMD_READ); // 이것이 READ (데이터 없음)
}
}
void ide_rw(struct buf *b) {
acquire(&ide_lock);
for (struct buf **pp = &ide_queue; *pp; pp=&(*pp)−>qnext)
; // 큐를 순회
*pp = b; // 요청을 맨 뒤에 추가
if (ide_queue == b) // q가 비었다면
ide_start_request(b); // 디스크에 req를 보냄
while ((b−>flags & (B_VALID|B_DIRTY)) != B_VALID)
sleep(b , &ide_lock); // 완료를 대기
release(&ide_lock);
}
void ide_intr() {
struct buf *b;
acquire(&ide_lock);
if ( ! ( b−>flags & B_DIRTY) && ide_wait_ready() >= 0)
insl(0x1f0 , b−>data , 512/4); // READ 라면: 데이터를 가져오기
b−>flags |= B_VALID;
b−>flags &= ~B_DIRTY;
wakeup(b); // 대기중은 프로세스를 깨우기
if ((ide_queue = b−>qnext) != 0) // 다음의 요청을 시작
ide_start_request(ide_queue); // (존재한다면)
release(&ide_lock);
}동작을 위한 4개의 기본 함수
ide_rw()- 대기 중인 다른 요청들이 있다면 요청을 큐에 삽입한다.
- 대기중인 요청이 없으면 디스크에 직접 명령한다(
ide_start_request()를 통해). - 어느 경우건 요청이 처리 완료되기를 기다리며 호출한 프로세스는 재운다.
ide_start_request()- 요청을 디스크로 내려 보낸다. (쓰기의 경우에는 데이터도 함께 보낸다)
- x86의
in과out명령어가 장치 레지스터를 읽거나 쓰는 데 각각 사용된다.
ide_wait_ready()- 요청을 명령하기 전에 드라이브가 준비가 되었는지 확인한다.
ide_intr()- 인터럽트가 발생하였을 때 호출된다.
- 장치에서 데이터를 읽고 (쓰기가 아닌 읽기 요청인 경우) I/O가 종료되기를 기다리는 프로세스를 깨운다.
- 그리고 더 많은 요청이 I/O 큐에 있다면
ide_start_request()를 이용하여 다음 요청 처리를 시작한다.
9. 역사상의 기록
DMA를 어느 기계가 먼저 도입했는가?
- DYSEAC 이라는 기계?
- IBM SAGE가 시초?
근데 사실 누가 먼저 도입했는가는 중요하지 않고, 이 초기 기계를 만들 때부터 I/O 지원이 필요해졌다는 것이 더 중요하다.
인터럽트와 DMA 그리고 관련된 개념들은 빠른 CPU와 느린 장치들의 특성을 활용한 결과물이다.
10. 요약
- 두 가지 기술인 인터럽트와 DMA는 장치의 효율을 높이기 위해 도입되었다.
- "명시적 I/O 명령어"와 "메모리 맵 I/O"를 사용하여 장치의 레지스터에 접근할 수 있다.
- 디바이스 드라이버의 개념을 소개하면서 하위 계층의 세부적인 내용을 운영체제가 캡슐화 할 수 있으며, 이를 활용하여 운영체제의 나머지를 장치 중립적으로 구현할 수 있다는 것을 보였다.
