평가 지표
분류 평가 지표
- 정확도 : Accuracy
- 정밀도 : Precision
- 재현율 : Recall
- F1 점수 : F1 Score
- PR Curve, AP Score
- ROC, AUC Score
전체, 양성과 음성에 따른 분류
Confusion-Matrix
- 전체 대상 : Accuracy
from sklearn.metrics import accuracy_score
accuracy_score(정답, 모델예측값)
- 불균형 데이터 셋의 경우 Accuracy가 높게 측정될 수 있으므로 평가지표로 Accuracy만 사용하면 안된다
Confusion Matrix
- 실제 값(정답)과 예측 한 것을 표로 만든 평가표
confusion_matrix(정답, 모델예측값)
 출처 : https://www.researchgate.net/figure/Confusion-Matrix-for-Binary-Classification-7_fig1_350487701
출처 : https://www.researchgate.net/figure/Confusion-Matrix-for-Binary-Classification-7_fig1_350487701
- (예측 맞았는지 틀렸는지)(예측)
- TP(True Positive) : 양성으로 예측했는데 맞은 개수
- TN(True Negative) : 음성으로 예측했는데 맞은 개수
- FP(False Positive) : 양성으로 예측했는데 틀린 개수, 음성을 양성으로 예측
- FN(False Negative) : 음성으로 예측했는데 틀린 개수, 양성을 음성으로 예측
- 양성 예측력 평가지표
- Recall/Sensitivity(재현율/민감도)
from sklearn.metrics import recall_score
recall_score(y 실제값, y 예측값)
- Precision(정밀도)
- PPV(Positive Predictive Value)
from sklearn.metrics import precision_score
precision_score(y 실제값, y 예측값)
- F1 점수
- 정밀도와 재현율의 조화평균 점수
- 비슷할수록 recall, precision 둘 다 좋다고 판단할 수 있는 근거
from sklearn.metrics import f1_score
f1_score(y 실제값, y 예측값)
- classification_report()
- Accuracy와 각 class가 Positive일 때의 recall, precision, f1-score를 한번에 보여주는 함수
from sklearn.metrics import classification_report
result = classification_report(y_train, pred_train)
- 음성 예측력 평가지표
- Specificity(특이도)
- TNR(True Negative Rate)
- TN/(TN+FP)
- Fall out(위양성률)
- FPR (False Positive Rate)
- (1-특이도)
Confusion-Matrix 시각화
1. matplot
import matplotlib as mpl
plt.figure(figsize=(7,7))
ax = plt.gca()
plot_confusion_matrix(dummy_model,
X_test,
y_test,
display_labels=['neg-9X','pos-9O'],
cmap=plt.cm.Blues,
values_format='d',
ax=ax
)
- sklearn
from sklearn.metrics import ConfusionMatrixDisplay
plt.figure(figsize=(7,7))
ax = plt.gca()
cm = confusion_matrix(y_test, pred_test_dummy)
disp = ConfusionMatrixDisplay(cm,
display_labels=['Not 9', '9'])
disp.plot(cmap='Blues', ax=ax)
plt.show()
재현율(Precision) - 정밀도(Recall) 관계성
- 데이터에서 파악하는 값이 pos가 중요한지 neg가 중요한지에 따라 선택여부 갈림
- 두 가지 모두 좋은 경우가 Best
- 재현율이 더 중요한 경우
- TP/(TP+FN)
- FN(False Negative)를 낮추는데 초점
- 실제 Positive 데이터를 Negative 로 잘못 판단하면 업무상 큰 영향이 있는 경우
- ex) 암환자
- 정밀도가 더 중요한 경우
- TP/(TP+FP)
- FP(False Positive)를 낮추는데 초점
- 실제 Negative 데이터를 Positive 로 잘못 판단하면 업무상 큰 영향이 있는 경우
- pos일 확률에 대한 임계값(Threshold) 변경을 통한 변환
- Threshold : 극단적으로 치우치면 안된다
- 임계값 증가 ==> pos 예측 기준 높아 pos 예측 확률(P) 감소
- 정밀도 분모 감소 ==> 정밀도 증가
- 재현율 분자 감소 ==> 재현율 감소
- 임계값 감소 ==> pos 예측 기준 낮아 pos 예측 확률(P) 감소
- 정밀도 분모 증가 ==> 정밀도 감소
- 재현율 분자 증가 ==> 재현율 증가
==> 반비례 관계
참고)
PR Curve(Precision Recall Curve-정밀도 재현율 곡선)와 AP Score(Average Precision Score)
- PR Curve
- Positive 확률 0~1사이의 모든 임계값에 대하여 재현율(recall)과 정밀도(precision)의 변화를 이용한 평가 지표
- X축에 재현율, Y축에 정밀도를 놓고 임계값이 1 → 0 변화할때 두 값의 변화를 나타내는 선그래프
- AP Score
- PR Curve의 성능평가 지표를 하나의 점수(숫자)로 평가
- PR Curve의 선아래 면적을 계산한 값으로 높을 수록 성능이 우수
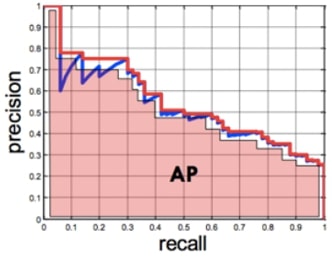
- AP Score
from sklearn.metrics import average_precision_score
result = average_precision_score(정답, pos 확률)
from sklearn.metrics import PrecisionRecallDisplay
plt.figure(figsize=(8,6))
ax = plt.gca()
disp = PrecisionRecallDisplay(precision, recall,
average_precision=result)
disp.plot(ax=ax)
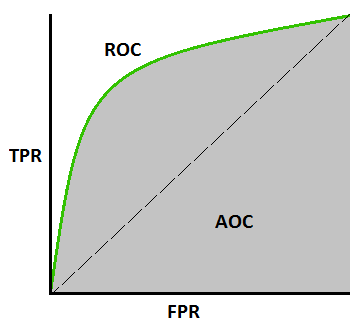
ROC curve(Receiver Operating Characteristic Curve)와 AUC(Area Under the Curve) score
- ROC Cruve
- 위양성률(FPR, X축) - 재현율(TPR, Y축), 임계값 관계 그래프
- 임계값, FPR 변화에 따른 TPR의 변화 그래프
- FPR과 TPR은 비례 형태
- FPR =0, TPR =1 완벽한 모델
- 이는 실제 음성을 양성으로 예측할 확률 0%( ==> 음성을 음성으로 예측), 실제 양성 중 양성예측 100%
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
fprs, tprs, threshold = roc_curve(y값, 예측확률)
score = roc_auc_score(y값, 예측확률)
from sklearn.metrics import RocCurveDisplay
disp1 = RocCurveDisplay(fpr=fpr_model, tpr=tprs_model, roc_auc=auc_model, estimator_name='tree')
disp1.plot(ax=ax)
