python standard library 참고 사이트

시퀀스(sequence)
값이 연속적으로 이어진 자료형
값 not in 시퀀스객체 출력-> true or false
- 슬라이스slice
a[2:8:3] 인덱스 2부터 3씩 증가시키면서 인덱스 7까지 가져옴
[시작:끝][:17] -> 0부터16까지 출력됨 [:] -> 모두출력
List , 배열[]
-
(Mutable) 값 변경 가능
파이썬의 자료구조 형태중 하나
순서가 있는 수정가능한 객체의 집합
대괄호[]로 작성되어지며, 리스트 내부의 값은 콤마(,)로 구분
추가,수정,삭제가능
변수명 = [요소1,요소2...]
e=[1,2,['hi','hello']] 리스트안에 리스트도 넣을 수 있음 -
값 찾을때
print(days(변수)[1(찾고자하는 인덱스 숫자)]) -> wed
print("Mon(찾을값)" in days(변수)) -> True or False
print(len(days)) -> 5
print(type(변수)) -> list or tuple or String or int.... -
인덱싱(indexing)
무언가를 가리킨다는 의미
리스트[start 인덱스:end 인덱스] 끝 전 값이 출력됨 -
리스트[인덱스] 인덱스에 위치한값 반환
list2 = [1,2,3,4,5]
print(list2[3])
출력-> 4
list3 = ['a','b','c']
print(list3.index('c'))
출력-> 2
temp = [1,2,['a','b','c']]
print(temp[2][1])
출력->b -
-1은 뒤에서부터 순서를 셈
-
.append(값)
맨 뒤에 값 추가
list3=[0,3,4,5,2]
list3.append(4)
출력->0,3,4,5,2,4 -
리스트에 10 추가하기 ex)
a.append(10) == a.insert(len(a), 10) == a[len(a):] = [10] #리스트 끝에서부터 시작하겠다는 의미 -
.insert(인덱스,값)
인덱스 위치에 값 추가
list3=[0,1,2,3,4]
list3.insert(1,5)
출력->0,5,1,2,3,4]
insert(len(리스트), 요소) list 끝에 요소를 추가 -
extend
list 연결하여 확장 -
.replace("a", "b")
원래 들어있던 a를 b로 교체 -
split()
문자열 자료형을 띄어쓰기 또는 해당기호 기준으로 짤라서 리스트로 만듦 -
list값 수정/변경
변수[0값] = 변경할 값 -
마지막 값을 반환 후 리스트에서 제거
변수명.pop()
list3=['a','b','c']
list3.pop()
출력->c
list3 출력->a,b
-
list 값 삭제
del 이용
del 변수명[값] 해당 숫자만 삭제됨
del 변수명[처음:끝] -
.remove(문자값) 해당 문자만 삭제됨
-
clear 리스트의 모든 요소 삭제
-
list 오른차순 정렬
.sort() 본체의 리스트를 정렬해서 변환, data type이 동일해야함
.sorted() 본체리스트는 두고, 정렬한 새로운 리스트를 반환 -
list 순서 역순으로 뒤집기
-
.reverse()
list값을 내림차순으로 정렬
reverse = False 오름차순 정렬 -
리스트의 값 개수 반환(확인)
변수명.len(list)
list3 = [1,2,3]
len(list3)
출력->3 -
count 문자열의 갯수출력
-
i = [0,1,2,3,17,18,19] 를 만들기
i for i in range(20)
if i <= 3 or i >= 17 -
3차원 리스트 만들기
리스트 = [[[값,값], [값,값]], [[값,값], [값,값]], [[값,값], [값,값]]]
리스트[높이인덱스][세로인덱스][가로인덱스] = 값
[[[0 for a in range(3)] for v in range(4)] for depth in range(2)]
튜플 Tuple
-
파이썬의 자료구조 형태중 하나
순서가 있는 집합
소괄호()로 작성되며, 튜플의 내부값은 콤마,로 구분
추가,수정,삭제 불가능
튜플명 = (요소1,요소2,요소3...) -
인덱스에 위치한 값 반환
튜플[인덱스]
변수명[값] 해당 순번에 있는 값 출력
출력->값 -
start인덱스 부터 end 인덱스 바로값 까지 반환(start<=값<end)
변수명[:값] 처음부터 값전까지
변수명[값1:값2] 값1부터 값2 전 까지
변수명[값:] 값1부터 값 끝까지
변수명[::값3] 값3만큼의 간격을 띄어서 출력 -
튜플 값의 개수 확인
len(tuple)
tuple3 = (0,1,2,3,('a','b','c'),5)
len(tuple3)
출력-> 6 -
list와 tuple의 공통점
타입과 상관없이 일련의 요소(element)를 갖을 수 있다
요소의 순서를 관리한다
list와 tuple의 차이점
리스트는 가변적(mutable)이며, 튜플은 불변적(immutable)
리스트는 요소가 몇 개 들어갈지 명확하지 않은 경우에 사용 (수정이 되기 때문)
튜플은 요소 개수를 사전에 정확히 알고 있을 경우에 사용 (수정이 불가하기 때문) -
in: 찾고자 하는 값이 포함되어 있으면 True (부분 문자/숫자 찾을때 유리)
not in : 찾고자 하는 값이 포함되어 있지 않으면 True
값 in 문자열 값 not in 문자열
값 in list 값 not in list
값 in tuple 값 not in tupl -
str1 = "파이썬 쵝오"
print ("파이썬" in str1)
출력-> True
print ("파이썬" not in str1)
출력-> False
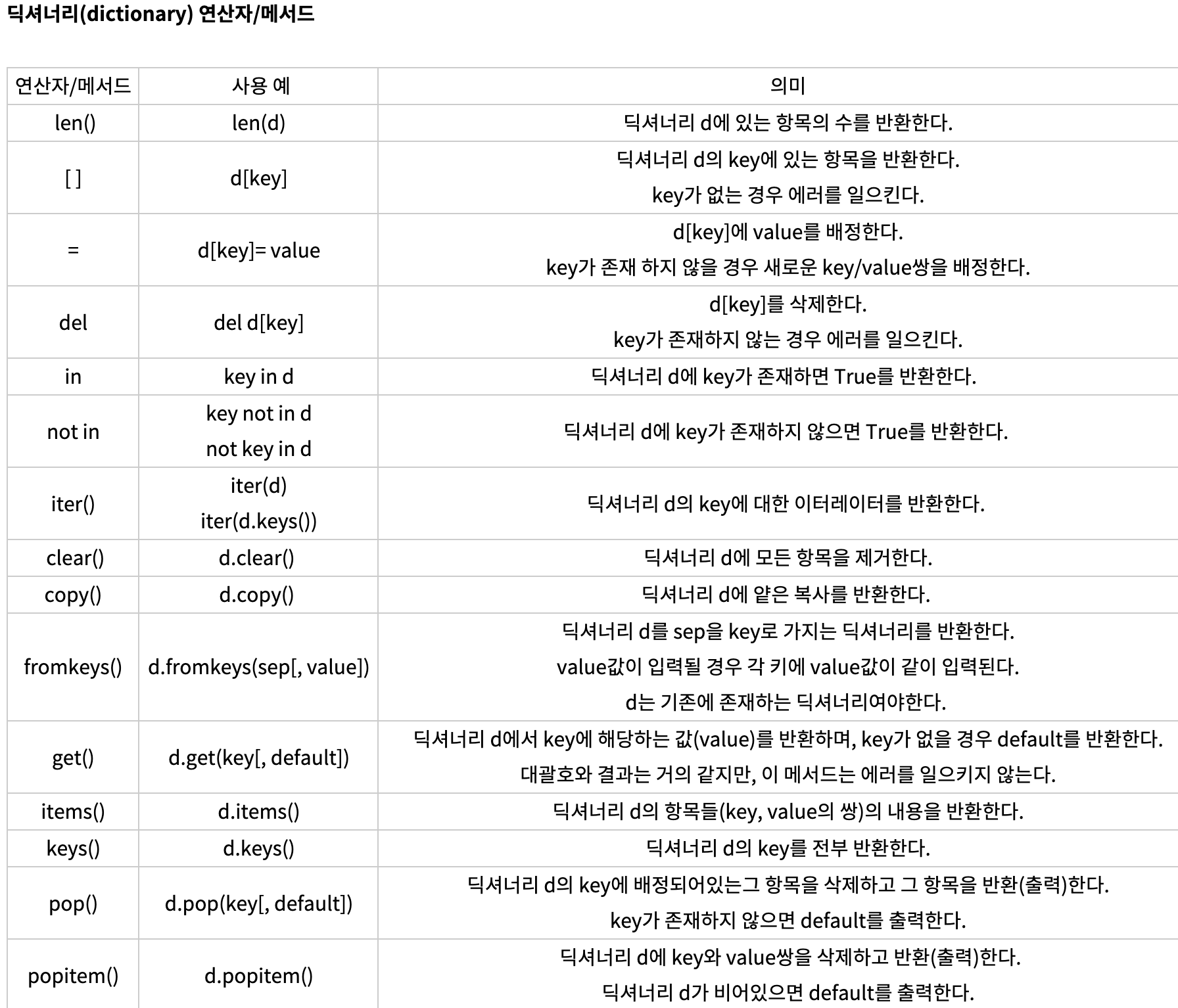
딕셔너리(dictionary)
-
단어 그대로 해석하면 사전이라는 뜻
"peolpe"이라는 단어는 "사람", "baseball"은 "야구"에 부합되듯이dictionary는 key와 value를 한쌍으로 갖는 자료형
딕셔너리 타입은 immutable(불변)한key와 mutalble(변화가능)한 value로 맵핑 되어있는 순서가 없는 집합
사전처럼 키로 검색해서 값을 볼 수 있음
hash 라고도 함
키는 중복되면 안됨 -
딕셔너리명 = {key:Value, Key:Value,...}
key에는 변수명 사용하고, value에는 변하는 값과 변하지 않는 값 모두 사용가능
a = {"name":"MH"}
c = {1:5,2:3} -
딕셔너리 값 추가
딕셔너리명[key] = value -
키-값 쌍 추가
.setdefault() / 키만 지정하면 값에 None이 출력 (= .update()로 써도 똑같은값 출력됨)
없는 키에 접근했을 경우 에러남
.setdefaultdict() 는 없는 키에 접근하더라도 에러가 발생하지 않으며 기본값을 반환함
from collections import defaultdict # collections modul에서 defaultdict을 가져옴
a = defaultdict(int) #int로 기본값 생성 -
키의 값 수정, 키가 없으면 키-값 쌍 추가
변수.update() / 키가 문자열일때: x.update(a = 90) 키가 숫자일때: .update({1:'a', 1:9})
등 사용할때 구글링 해보고 사용하기 타입마다 쓰는 방법 다름
setdefault는 키-값 쌍 추가만 할수있고, 이미 들어있는 키의 값은 수정할 수 없다
update는 키-값 쌍추가와 값수정 모두 가능 -
딕셔너리 값 삭제
del딕셔너리명[key]
키-값 쌍 삭제
.pop('key') -
딕셔너리 값 찾기
print(딕셔너리명[key])
딕셔너리명.get(keyname) -> 해당 키의 값만 출력 -
키-값 쌍을 모두 가져옴
.items() -
딕셔너리 key만 가져오기
딕셔너리명.keys() -
딕셔너리 value만 가져오기
딕셔너리명.values() -
키와 벨류 모두 출력하기
print(a.items())
출력-> [(키,벨류), (키,벨류)] -
print(a.get(4)) (4가 dict에 없는상황)
-> none
print(a.get(4, '없음')) (4가 dict에 없는상황)
-> 없음 -
for문 활용
for 키, 값 in 변수.items():
print(키, 값)
출력-> name MH
age 20
phone 010-3334-5555
-
for문 활용2
{키: 값 for 키, 값 in 딕셔너리}
x = {key: value for key, value in dict.fromkeys(변수).items()}
x = {key: value for key, value in x.items() if value != 20}
-> 값으로 키를 같이 삭제하고 싶을때, 딕셔너리에서 값 20의 키와 값을 삭제 -
딕셔너리 in 키워드 사용 (키 찾기)
key in 딕셔너리명 (~in은 딕셔너리의 키에 한해서 동작한다)
출력->True or False -
.zip() 두 그룹의 데이터를 서로 엮어줌
-
딕셔너리 모두 지우기
딕셔너리명.clear() -
같은 딕셔너리를 두개로 만드려면 copy이용
a = b.copy()
완전히 복사하려면 import copy 후 a = copy.deepcopy(b) 함수 사용

집합 자료형
-
집합에 관련된 것들을 쉽게 처리하기위해 만들어짐
중복 불가능
순서가 없다 (unordered)
set 가 집합이라는 의미 -
a = set([1,2,3]) 리스트형
a = {1,2,3} 중괄호
둘다 출력이 같음 -
중복을 없애고 싶을때
a = [1,2,2,3,3] 중복이 있는 리스트
newList = list(set(1)) 집합으로 중복을 제거
print (newList) -
문자열을 집합으로 감싸면 하나씩 쪼개서 출력됨.
문자열도 중복을 없음
a = set("Hello")
-> {'o', 'l', 'e', 'H'} -
변경할수 없는 세트
a = frozenset(range(0)) -
세트에 값 추가하기
.add(값) -
값 삭제하기
.remove(값) 해당 값을 삭제하고 그 값이 없으면 에러발생
.pop() 첫번째 값을 삭제하고 그 값이 없으면 에러발생
.discard(값) 해당 값을 삭제하고 그 값이 없어도 그냥 넘어감
.clear() 모든 값 삭제 -
len(세트명) 세트길이를 구함
-
for문 사용
a = {i for i in 'apple'} # i로 세트생성, i 유일한 문자만 하나씩 꺼냄, 문자열 'apple'
print(a) -> {'l', 'p', 'e', 'a'} -
for문과 if문 사용
a = {i for i in 'pineapple' if i not in 'apl'} # apl을 제외한 문자로 세트생성
print(a) -> {'e', 'i', 'n'}
