🗄️ Lambda(람다)
개요
람다식은 익명 함수를 생성하기 위한 식으로 java에서 함수형 프로그래밍을 위해 지원하게 되었다.
문법
// 1. 기본 작성
(타입 매개변수) -> { ... }
// 2. 매개변수가 1개 일 때, 매개변수 () 생략가능
매개변수 -> { ... }
// 3. 매개변수가 2개 이상이고, 리턴문만 존재할 때는 return을 생략가능
(매개변수1, 매개변수2) -> 리턴값;
(num1, num2) -> {return num1 + num2} // return문만 존재하므로
(num1, num2) -> num1 + num2 // return 생략가능, 중괄호도 생략
// 4. 매개변수가 2개 이상이고, 실행문을 실행하고 결과값을 리턴할 경우
(매개변수1, 매개변수2) -> { ... };함수형 인터페이스
"단 하나의 추상 메서드만을 포함하는 인터페이스"
자바에서 메서드를 사용하려면 객체를 먼저 생성하고 그 객체로 메서드를 호출해야 한다. 클래스에서 공통적으로 사용하는 메서드가 있다면 클래스마다 메서드를 정의해야 하는 번거로움이 있다. 이를 해결하기 위해 람다식을 사용한다.
문법
@FunctionalInterface
public interface FunctionalInterfaceTest {
public void test(); // 매개 변수가 없는 람다식
// public void test(int x); // 매개 변수가 있는 람다식
}
public class Main {
public static void main(String[] args) {
FunctionalInterfaceTest test;
test = () -> {
System.out.println("test");
}
}
test.test(); // "test" 출력
}메서드 레퍼런스
"람다식에서 불필요한 매개변수를 제거하는 것이 목적"
(x, y) -> Math.max(x, y);
==
Math::max;
- 정적 메서드를 참조할 경우
-클래스 :: 메서드 - 인스턴스 메서드를 참조할 경우
-참조변수 :: 메서드 - 생성자 참조
-클래스::new
🎛️ Stream(스트림)
"배열, 컬렉션의 저장 요소를 하나씩 참조해서 람다식으로 처리할 수 있도록 해주는 반복자"로 선언형("어떻게 수행"하는지보다 "무엇"을에 더 관심)으로 데이터 소스를 처리할 수 있다.
특징
- 람다식으로 요소 처리 코드를 제공
import java.util.*;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
List<Integer> arr = Arrays.asList(1,2,3,4,5);
// 짝수들만 출력
arr.stream()
.filter(a -> a % 2 == 0) // 람다식으로 요소 처리
.forEach(a -> System.out.println(a));
}
}- 내부 반복자를 사용하므로 병렬 처리가 쉬움
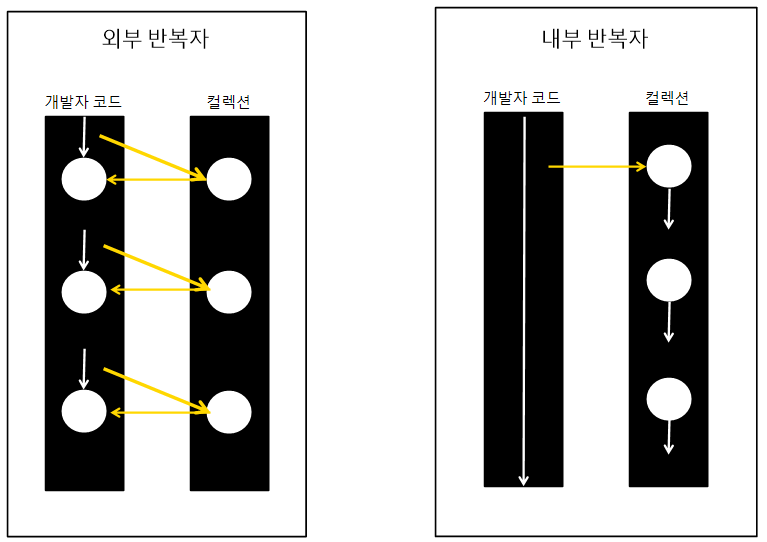
외부 반복자 : 개발자가 코드로 직접 컬렉션의 요소를 반복해서 가져오는 패턴
내부 반복자 : 컬렉션 내부에서 요소들을 반복시키고 요소당 처리해야할 코드만 제공
내부 반복자를 사용해서 얻는 이점은 컬렉션 내부에서 요소를 어떻게 반복시킬 것인가는 컬렉션에게 맡겨 두고, 요소 처리 코드에만 집중할 수 있다. 멀티 코어 CPU를 최대한 활용하기 위해 요소들을 분배시켜 병렬 작업을 할 수 있게 도와주므로 외부 반복자보다 효율적으로 요소를 처리할 수 있다. (병렬 스트림을 사용하기 위해서는 스트림의 parallel() 메서드를 사용한다.)
- 중간 연산과 최종 연산 가능
중간 연산 : 매핑, 필터링, 정렬 수행
최종 연산 : 반복, 카운팅, 평균 총합 등의 집계를 수행
파이프라인 구성
데이터의 필터링, 매핑, 정렬, 그루핑 등의 중간 연산과 합계, 평균, 카운팅, 최대 / 최소값 등의 최종 연산을 파이프라인(pipelines)으로 해결

중간 스트림이 생성될때 요소들이 바로 중간 연산을 수행하는 것이 아니라 최종 연산이 시작되기 전까지는 지연된다. 최종 연산이 시작되면 중간 스트림에서 연산이 되고 최종 연산까지 오게 된다. 중간 연산 메서드들은 중간 연산된 스트림을 리턴한다.
생성, 중간 연산, 최종 연산
생성
Collection 인터페이스에서 stream()이 정의되어 있다. 배열의 경우에는 Stream의 of 메서드 또는 Arrays의 stream 메서드를 이용한다.
| 리턴 타입 | 메서드(매개변수) | 소스 |
|---|---|---|
| Stream | java.util.Collection.Stream(), java.util.Collection.parallelSream( ) | 컬렉션 |
| Stream, IntStream, LongStream, DoubleStream | Arrays.stream(T[]), Arrays.stream(int[]), Arrays.stream(long[]), Arrays.stream(double[]), Stream.of(T[]), IntStream.of(int[]) LongStream.of(long[]), DoubleStream.of(double[]) | 배열 |
| IntStream | IntStream.range(int, int), IntStream.rangeClosed(int, int) | int 범위 |
| LongStream | LongStream.range(long, long), LongStream.rangeClosed(long, long) | long 범위 |
☠️ 주의점
- 스트림은 데이터를 읽기만 할 뿐 변경하지 않는다(Read-Only)
- 스트림은 일회용이다.
중간 연산
- filter() : 조건에 맞는 요소 필터링
- distinct() : 중복 제거
- map() : 기존의 Stream 요소들을 대체하는 요소로 구성된 새로운 Stream 형성
- flatMap() : 여러 개의 Stream 요소들을 하나의 Stream 요소로 변환하여 새로운 Stream 생성, map()과 기능은 동일
- sorted() : 정렬, 내림차순으로 정렬할때는 Comparator.reverseOrder() 추가
- peek() : 연산 결과 확인, 하나의 스트림에 여러번 사용 가능/forEach()는 스트림의 요소를 소모하므로 한번만 호출 가능
최종 연산
한번 만 연산 가능
- forEach() : 하나씩 출력할때 사용
- match() : 일치 여부를 판단해서 boolean으로 리턴
- allMatch() : 모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하는지 조사
- anyMatch() : 최소한 한 개의 요소가 매개값으로 주어진 Predicate의 조건을 만족하는지 조사
- noneMatch() : 모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하지 않는지 조사 - sum(), count(), max(), min(), average() : 집계해서 결과값 리턴
- reduce() : 다양한 집계 결과물을 만들수 있다. 누적 값, 3개의 매개변수 받을 수 있다.
- Identity: 계산을 수행하기 위한 초기값
- Accumulator: 각 요소를 계산한 중간 결과를 생성하기 위해 사용
- Combiner: 병렬 스트림(Parlallel Stream)에서 나누어 계산된 결과를 하나로 합치기 위한 로직
Arrays.stream(intArr).map(el -> el*2).reduce(0, (a,b) -> a+b); - collect() : Stream의 최종 연산 결과물을 콜렉션 형태로 반환할 때 사용
Optional<T>
Optional은 NullPointerException(NPE), 즉 null 값으로 인해 에러가 발생하는 현상을 객체 차원에서 효율적으로 방지하고자 도입되었다.
연산 결과를 Optional에 담아서 반환하면, 따로 조건문을 작성해주지 않아도 NPE가 발생하지 않도록 코드를 작성할 수 있다.
모든 타입의 객체를 담을 수 있는 래퍼(Wrapper) 클래스이다.
Optional 객체 생성
Optional 객체를 생성하려면 of() 또는 ofNullable()을 사용한다. 참조변수의 값이 null일 가능성이 있다면 ofNullable()을 사용한다.
ptional<String> opt1 = Optional.ofNullable(null);
Optional<String> opt2 = Optional.ofNullable("123");
System.out.println(opt1.isPresent()); //Optional 객체의 값이 null인지 여부를 리턴합니다.
System.out.println(opt2.isPresent());참조변수를 기본값으로 초기화
empty() 메서드를 사용한다.
Optional<String> opt3 = Optional.<String>empty();Optional 객체 값 가져오기
get() 메서드를 사용한다. 참조변수의 값이 null일 가능성이 있다면 orElse() 메서드를 이용하여 default 값을 설정할 수 있다.
ptional<String> opt1 = Optional.of("test");
System.out.println(opt1);
System.out.println(opt1.get()); // test
String nullName = null;
String name = Optional.ofNullable(nullName).orElse("test");
System.out.println(name); // testCollection VS Stream
| Collection | Stream | |
|---|---|---|
| 기본 컨셉 | 특정 자료구조로 데이터를 저장 | 데이터 가공 처리 |
| 데이터 수정 여부 | 데이터 추가/삭제 가능 | 데이터 추가/삭제 불가, 읽어서 소비 |
| Iteration 형태 | 외부 반복 | 내부 반복 |
| 탐색 횟수 | 여러번 탐색 가능 | 한번만 탐색 가능 |
| 데이터 처리 방식 | Eager(즉시) | Lazy(지연) 그리고 Short-circuit(단락 평가) |
복잡한 데이터 가공 처리에는 스트림을 사용한다. Eager와 Lazy의 핵심 차이는 Eager는 메모리에 전체를 한번에 올려서 처리하지만 Lazy는 필요할 때에만 조금씩 올리면서 처리한다. 따라서 Lazy는 대용량 데이터를 처리할 때 성능적인 측면에서 이점이 있다.
