정의
Hash Function을 이용하여 변환한 Hash를 Index로 삼아 Key와 Value를 저장하는 자료 구조
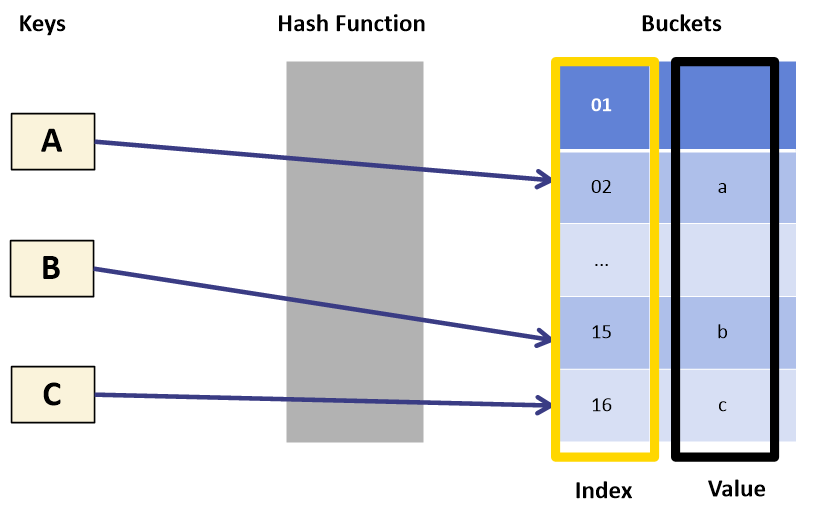
특징
- 저장, 삭제, 검색 과정은 평균적으로 O(1)의 시간복잡도를 가진다.
- Hash collision(해시 충돌)의 가능성이 있으며 Hash Function의 의존도가 높다.
- Hash collision이 발생한다면 모든 index를 찾아야 하기 때문에 O(n)의 시간복잡도를 가진다.
- Hash Function이 복잡하다면 Hash를 만드는데 많은 시간이 소요
대표적인 Hash Algorithm
- Division Method : Number Type의 키를 저장소의 크기로 나눈 나머지를 이용해 index로 설정하는 방법, 저장소의 크기를 소수로 정하고 2의 제곱수로 먼 값을 사용하는 것이 효과가 좋다.
- Digit Folding : 키의 문자열을 ASCII 코드로 바꾸고 그 값을 합해 index로 사용하는 방법, index가 저장소의 크기보다 크다면 Division Method 적용 가능
- Multiplication Method : 숫자로 된 Key 값 K와 0과1 사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같이 계산한 값을 사용
h(k) = floor(m (k A - floor(k * A))) - Universal Hashing : 다수의 해시함수를 만들어 특정한 장소에 넣어두고, 무작위로 해시함수를 선택해 해시(hash)값을 만드는 기법
Hash Collision 해결
1. 개방 연결볍(Open Addressing)
hash collision이 발생하면 다른 index에 해당 자료를 삽입하는 방식
- Linear Probing
현재 중복된 index로부터 고정된 숫자만큼 이동하여 비어있는 저장소를 찾아 value를 저장 - Quadratic Probing
현재 중복된 index로부터 이동할 숫자를 제곱으로 사용하는 방식
처음 충돌이 발생하면 (12) 만큼 이동하고 또 충돌이 발생하면 (22) 만큼 계속해서 제곱을 이용하여 빈 공간을 찾음 - Double Hashing Probing
하나의 Hash Function에서 충돌이 발생하면 미리 지정해둔 다른 Hash Function을 이용
2. 분리 연결볍(Seprate Chaining)
동일한 index에 대해 Linked List 또는 Tree 등의 자료구조를 활용하여 데이터의 주소를 저장하는 방법
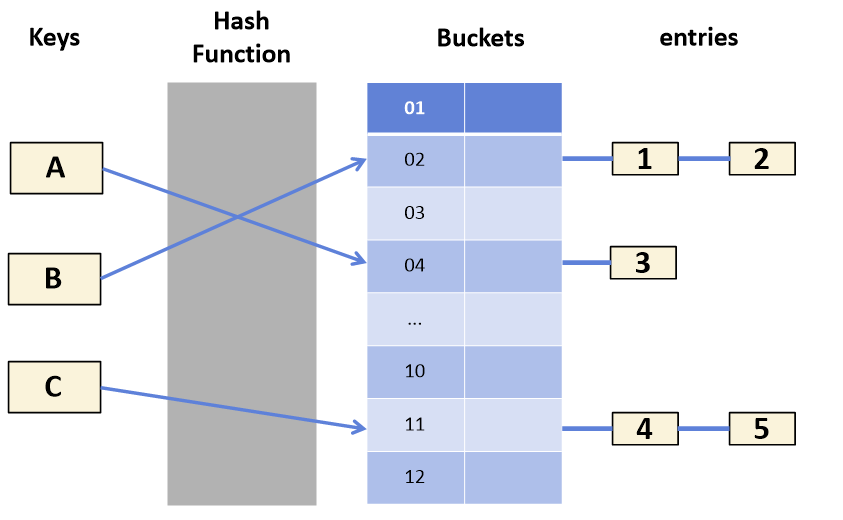
구현이 간단하며 데이터를 쉽게 삭제할 수 있지만 중복으로 저장되는 데이터가 많아지면 동일한 버킷에 연결되는 데이터가 많아져서 검색의 효율성이 감소한다.
3. 저장소 확장(Resize)
저장소의 크기가 작다면 불필요한 메모리를 줄일 수 있지만 Hash Collision이 발생하여 개방 연결법이나 분리 연결법을 사용해도 성능상 손실이 발생한다. 실제 Java에서 사용되는 HashMap은 key-value 데이터 개수가 일정 이상이 된다면(저장소의 75% 이상 사용) 저장소의 크기를 두배 늘린다.
Hash Table의 실사용 예제
- Blockchain
- Domain -> DNS 변환
- Address Book(주소록)
