작업자간 일치도(IAA, Inter-Annotator Agreement)
모델이 학습할 수 있을만큼 충분한 양의 데이터를 제작하기 위해서는 혼자가 아닌 여럿이서 함께 데이터를 제작해야만 할 것이다.
하지만 데이터 제작 및 레이블링 과정에서는 사람의 주관이 들어가는 경우가 많고,
모호한 레이블링 기준으로 인해 사람마다 약간씩 다른 기준으로 레이블링을 진행했을 수 있다.
이러한 실수 또는 데이터 레이블링 방식의 차이를 확인하고,
레이블링 후 데이터의 품질을 확인하기 위해 작업자간에 레이블링을 얼마나 비슷한 기준으로 했는지를 평가하는 방법이 바로 작업자간 일치도(IAA)평가이다.
IAA는 여러가지 방법으로 평가될 수 있겠지만 대표적인 방법으로는 크게 두 가지가 존재한다.
1. Kappa 계수
1) Cohen's Kappa
-
Cohen이 1968년에 제안한 계수
-
두 관찰자 간의 측정 범주 값에 대한 일치도(agreement)를 측정하는 방법
-
두 관찰자 사이의 일치도 : Cohen's Kappa / 세 관찰자 이상 일치도 : Fleiss Kappa
-
Cohen's Kappa계수를 사용할 경우 자료의 조건
- 명목 척도 또는 서열 척도로 측정된 범주형 데이터이어야 함
- 검사자(혹은 검사 방법) 내의 범주는 반드시 동일해야 함
- 두 평가자에게 모두 관측된 데이터이어햐 함
- 두 평가자는 서로 독립
-
Cohen's Kappa 계수 공식 :
가 '2명의 평가자 간 일치 확률'이고,
가 ' 우연히 두 평가자에 의하여 일치된 평가를 받을 비율'이라고 하면, 값은 다음과 같이 구해진다. -
예시)
-
아래와 같이 긍정/부정 데이터를 평가자 A와 B가 레이블링을 진행했다고 하자.
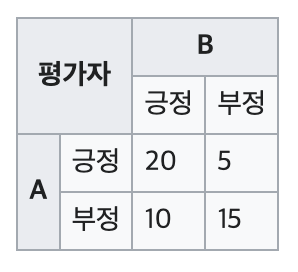
-
'2명의 평가자 간 일치 확률'='둘 다 같은 레이블을 고른 경우의 비율'은 다음과 같다.
-
'우연히 두 평가자에 의하여 일치된 평가를 받을 비율'()를 구하기 위해서는 각 평가자의 긍정 확률값과 부정 확률값을 구해야 한다.
-
평가자 A의 긍정 확률값
-
평가자 A의 부정 확률값
-
평가자 B의 긍정 확률값
-
평가자 B의 부정 확률값
-
따라서 평가자 A와 B가 동시에 긍정으로 레이블링할 확률()은 다음과 같다.
-
또한 평가자 A와 B가 동시에 부정으로 레이블링할 확률()은 다음과 같다.
-
'우연히 두 평가자에 의하여 일치된 평가를 받을 비율'()은 '우연히 두 평가자 모두 긍정을 줄 확률'과 '우연히 두 평가자 모두 부정을 줄 확률'을 더한 것이므로
이다.
-
-
따라서 Cohen's Kappa 계수는
이다.
-
-
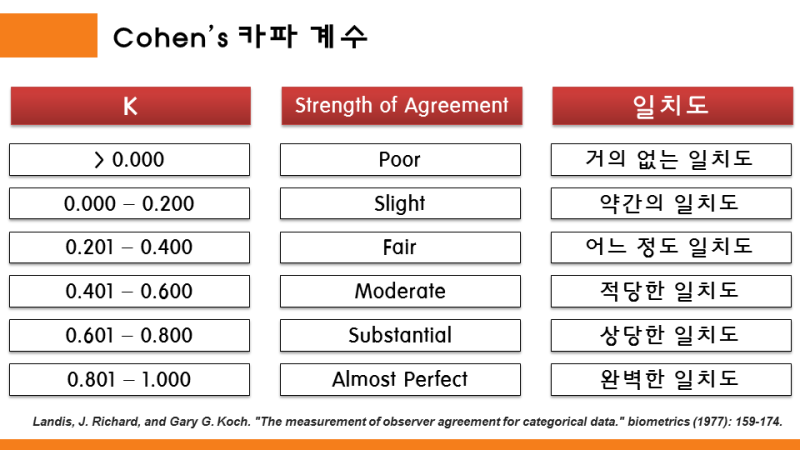
Cohen's Kappa 계수 등급
2) Fleiss Kappa(TACRED)
-
Cohen's Kappa 계수가 '두 관찰자 사이의 일치도'를 평가하는 척도인 반면, Fleiss Kappa는 세 관찰자 이상 존재할 때에도 일치도를 평가할 수 있는 척도이다.
-
Kappa 계수를 구하는 식은 Cohen's Kappa와 동일하지만, 평가자가 늘어나면서 와 를 구하는 식이 달라진다.
-
여기에서 는 '데이터에 대해 평가자들이 일치하는 정도'의 평균을 의미하고, 는 '우연히 작업자 간 동일한 범주로 평가할 확률'을 의미한다. 각각에 대해 필요한 식을 하나씩 정리해보자.
-
이 'total number of subjects(평가해야 할 대상, 데이터 개수)'이고, 이 '평가자 인원수(각 데이터 별 평가 개수)', 그리고 가 'labeling 범주의 개수(category 종류의 개수)'라고 하자.
-
또한 은 번째 데이터를 의미하고, 는 번째 category를 의미하며,
는 번째 데이터를 번째 범주로 분류한 평가자의 수를 의미한다. -
먼저, ('우연히 작업자 간 동일한 범주로 평가할 확률')을 구해보자.
-
우선 번째 범주로 분류된 데이터의 비율을 구한다면 식은 아래와 같다.
-
이러한 범주는 총 개 존재하므로 우리는 를 다음과 같이 구할 수 있을 것이다.
-
-
다음으로, ('데이터에 대해 평가자들이 일치하는 정도'의 평균)을 구해보자.
-
번째 데이터에 대해 평가자들이 일치하는 정도를 구하는 식은 다음과 같다.
-
는 각 데이터에 대한 평가자의 일치도인 의 평균에 해당되므로 아래와 같이 표현된다.
-
-
예시) 14명()의 평가자(데이터 제작자)가 있고, 총 10개()의 데이터를 레이블링한다고 하자. 구분할 범주의 개수는 5개()이다.

-
-
(표의 각 셀 값의 총합) = 14 * 10 = 140
-
첫번째 카테고리로 분류된 경우의 비율
-
2번째 데이터에서 평가자(데이터 제작자)가 일치하는 정도
-
을 구하기 위해 의 합을 구한다.
-
최종적으로 Kappa 계수를 구하면 다음과 같다.
-
-
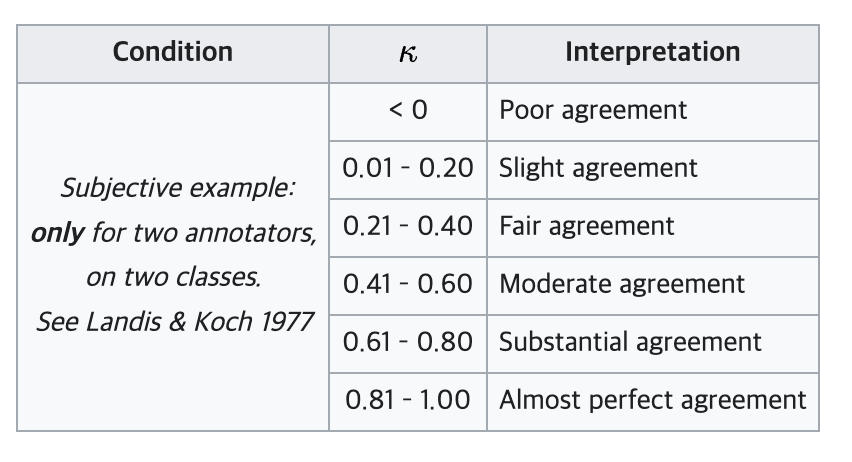
Fleiss' Kappa 계수 등급은 다음과 같이 표현된다. (Cohen's Kappa 계수 등급과 동일하다.)
-
코드(https://github.com/Shamya/FleissKappa/blob/master/fleiss.py)
def fleissKappa(rate,n): """ Computes the Kappa value @param rate - ratings matrix containing number of ratings for each subject per category [size - N X k where N = #subjects and k = #categories] @param n - number of raters @return fleiss' kappa """ N = len(rate) k = len(rate[0]) print("#raters = ", n, ", #subjects = ", N, ", #categories = ", k) checkInput(rate, n) #mean of the extent to which raters agree for the ith subject PA = sum([(sum([i**2 for i in row])- n) / (n * (n - 1)) for row in rate])/N print("PA = ", PA) # mean of squares of proportion of all assignments which were to jth category PE = sum([j**2 for j in [sum([rows[i] for rows in rate])/(N*n) for i in range(k)]]) print("PE =", PE) kappa = -float("inf") try: kappa = (PA - PE) / (1 - PE) kappa = float("{:.3f}".format(kappa)) except ZeroDivisionError: print("Expected agreement = 1") print("Fleiss' Kappa =", kappa) return kappa
2. Krippendorff's (KLUE)
- Krippendorff에 의해 제안된 평가자 간 신뢰도를 측정하는 통계적 측정값이다.
- 코더 간 일치 측정, 평가자 간 신뢰도, 주어진 단위 세트에 대한 코딩(레이블링) 신뢰도 등에 사용

이거 설명을 들엉하는데요 수정님!?!?!?!?!?ㅎ_ㅎ