
📝 함수
컬럼의 값을 읽어서 연산한 결과를 반환
-> 함수는 SELECT절, WHERE절, ORDER BY, GROUP BY, HAVING 사용 가능
- 종류: 단일행 함수 / 그룹 함수
💡 단일행(SINGLE ROW) 함수
N개의 값을 읽어서 N개의 결과 반환
✏️ LENGTH(문자열 | 컬럼)
문자열 길이 반환
SELECT LENGTH('HELLO WORLD') FROM DUAL;
-- 12글자인 이메일만 조회
SELECT EMAIL, LENGTH(EMAIL) FROM EMPLOYEE
WHERE LENGTH(EMAIL) = 12;✏️ INSTR('문자열' | 컬럼명, '찾을 문자', [찾을 위치 시작 위치, [순번]])
지정한 위치부터 지정한 순번째로 검색되는 문자의 시작 위치를 반환
-- 문자열에서 맨 앞에 있는 B 위치 조회
SELECT INSTR('AABAACAABBAA', 'B') FROM DUAL;
-- 문자열에서 5번째부터 검색해서 맨 앞에 있는 B의 위치 조회
SELECT INSTR('AABAACAABBAA', 'B', 5) FROM DUAL;
-- EMPLOYEE 테이블에서 사원명, 이메일, 이메일 중 "@" 위치 조회
SELECT EMP_NAME, EMAIL, INSTR(EMAIL, '@')
FROM EMPLOYEE;✏️ SUBSTR('문자열' | 컬럼명, 잘라내기 시작할 위치 [, 잘라낼 길이])
컬럼이나 문자열에서 지정한 위치부터 지정된 길이만큼 문자열을 잘라내서 반환
-> 잘라낼 길이 생략 시 끝까지 잘라냄
-- EMPLOYEE 테이블에서 사원명, 이메일 중 아이디만 조회 sun_di@or.kr
SELECT EMP_NAME, SUBSTR(EMAIL, 1, INSTR(EMAIL, '@') -1 ) 아이디
FROM EMPLOYEE
ORDER BY 아이디;✏️ TRIM([옵션] '문자열' | 컬럼명 [FROM '문자열' | 컬럼명] )
주어진 컬럼이나 문자열의 앞, 뒤, 양쪽에 있는 지정된 문자를 제거
-> (보통 양쪽 공백 제거에 많이 사용)
- 옵션 : LEADING(앞쪽), TRAILING(뒤쪽), BOTH(양쪽, 기본값)
SELECT ' K H ', TRIM(' K H ') FROM DUAL; -- 양쪽 공백 제거( 중간 미포함)
SELECT '---KH---', TRIM(TRAILING '-' FROM '---KH---') FROM DUAL;
-- BOTH 또는 생략 시 : 양쪽 '-' 기호 제거
-- LEADING : 앞쪽만 제거
-- TRAILING : 뒤쪽만 제거💡 숫자 관련 함수
✏️ ABS(숫자 | 컬럼명)
절댓값 반환
SELECT ABS(10), ABS(-10) FROM DUAL;✏️ MOD(숫자 | 컬럼명, 숫자 | 컬럼명)
나머지 값 반환
-- EMPLOYEE 테이블에서 사원의 월급을 100만으로 나눴을 때 나머지 조회
SELECT EMP_NAME, SALARY, MOD(SALARY, 1000000)
FROM EMPLOYEE;✏️ ROUND(숫자 | 컬럼명 [, 소수점 위치])
반올림
SELECT 123.456, ROUND(123.456) FROM DUAL; -- 소수점 첫째 자리에서 반올림
SELECT 123.456, ROUND(123.456, 1) FROM DUAL; -- 소수점 첫째 자리까지 출력 == 소수점 둘째 자리 반올림
SELECT 123.456, ROUND(123.456, 2) FROM DUAL;
SELECT 123.456, ROUND(123.456, 0) FROM DUAL; -- 소수점 첫째 자리에서 반올림
SELECT 123.456, ROUND(123.456, -1) FROM DUAL; -- 소수점 0번째 자리에서 반올림
SELECT 123.456, ROUND(123.456, -2) FROM DUAL; -- 소수점 -1번째 자리에서 반올림✏️ CEIL(숫자 | 컬럼명)
올림
✏️ FLOOR(숫자 | 컬럼명)
내림
-> 둘 다 소수점 첫째 자리에서 올림/내림 처리
SELECT 123.5, CEIL(123.5), FLOOR(123.5) FROM DUAL;✏️ TRUNC(숫자 | 컬럼명 [, 위치])
특정 위치 아래를 버림(절삭)
SELECT TRUNC(123.456, 1), TRUNC(123.456, -1)
FROM DUAL;- 버림, 내림의 차이점
SELECT TRUNC(-123.5), FLOOR(-123.5)
FROM DUAL;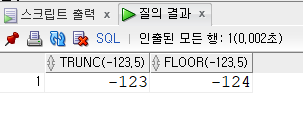
💡 날짜(DATE) 관련 함수
✏️ SYSDATE
시스템의 현재 시간(년, 월, 일, 시, 분, 초)을 반환
SELECT SYSDATE FROM DUAL;✏️ SYSTIMESTAMP
SYSDATE + MS 단위 추가
SELECT SYSTIMESTAMP FROM DUAL;✏️ MONTHS_BETWEEN(날짜, 날짜)
두 날짜의 개월 수 차이 반환
SELECT ROUND( MONTHS_BETWEEN(SYSDATE, '2022/02/21') ) || '개월' AS 수강기간 FROM DUAL;
-- EMPLOYEE 테이블에서
-- 사원의 이름, 입사일, 근무 개월 수, 근무 햇수 조회
SELECT EMP_NAME, HIRE_DATE,
'근무 ' || CEIL ( MONTHS_BETWEEN(SYSDATE, HIRE_DATE) ) || '개월 차' "근무 개월 수",
'근무 ' || CEIL ( MONTHS_BETWEEN(SYSDATE, HIRE_DATE) / 12 ) || '년 차' "근무 햇수"
FROM EMPLOYEE;✏️ ADD_MONTHS(날짜, 숫자)
날짜에 숫자만큼의 개월 수를 더함
SELECT ADD_MONTHS(SYSDATE, 4) +7 FROM DUAL;✏️ LAST_DAY(날짜)
해당 달의 마지막 날짜를 구함
SELECT LAST_DAY(SYSDATE) FROM DUAL;
SELECT LAST_DAY('2023/04/01') FROM DUAL;✏️ EXTRACT
년, 월, 일 정보를 추출하여 리턴
EXTRACT(YEAR FROM 날짜)
년도만 추출
EXTRACT(MONTH FROM 날짜)
월만 추출
EXTRACT(DAY FROM 날짜)
일만 추출
-- EMPLOYEE 테이블에서 각 사원의 이름, 입사 년도, 입사 월, 입사 일 조회
SELECT EMP_NAME 이름,
EXTRACT(YEAR FROM HIRE_DATE) "입사 년도",
EXTRACT(MONTH FROM HIRE_DATE) "입사 월",
EXTRACT(DAY FROM HIRE_DATE) "입사 일"
FROM EMPLOYEE
WHERE EXTRACT(MONTH FROM HIRE_DATE) = 1;💡 형변환 함수
문자열(CHAR), 숫자(NUMBER), 날짜(DATE)끼리 형변환 가능
✏️ TO_CHAR (문자열로 변환)
TO_CHAR(날짜, [포맷])
날짜형 데이터를 문자형 데이터로 변경
TO_CHAR(숫자, [포맷])
숫자형 데이터를 문자형 데이터로 변경
[패턴]
- 9 : 숫자 한 칸을 의미, 여러 개 작성 시 오른쪽 정렬
- 0 : 숫자 한 칸을 의미, 여러 개 작성 시 오른쪽 정렬 + 빈칸 0 추가
- L : 현재 DB에 설정된 나라의 화폐 기호
SELECT TO_CHAR(1234, '9999999') FROM DUAL;
SELECT TO_CHAR(1234, '00000') FROM DUAL;
SELECT TO_CHAR(1000000, '9,999,999') FROM DUAL; -- 자릿수 구분
SELECT TO_CHAR(1000000, 'L9,999,999') FROM DUAL; -- 화폐 기호
SELECT TO_CHAR(1000000, '$9,999,999') FROM DUAL; -- 화폐 기호
-- 직원들의 급여를 '\999,999,999' 형식으로 조회
SELECT TO_CHAR(SALARY, 'L999,999,999')
FROM EMPLOYEE;[날짜에 TO_CHAR 적용]
- YYYY : 년도 / YY : 년도 (짧게)
- RRRR : 년도 / RR : 년도 (짧게)
- Y : 현재 세기 (21세기 == 20XX년 == 2000년대)
- R : 1세기 기준으로 절반(50년) 이상이면 이전 세기(1900년대) / 절반(50년) 미만이면 현재 세기(2000년대) - MM : 월 / DD : 일
- AM 또는 PM : 오전/오후 표시
- HH : 시간 / HH24 : 24시간 표기법
- MM : 분 / SS : 초
- DAY : 요일(전체) / DY : 요일(요일명만 표시)
SELECT SYSDATE, TO_CHAR(SYSDATE, 'DY AM HH24:MI:SS') FROM DUAL;
-- 직원들의 입사일을 '2017년 12월 06일 (수)' 형식으로 출력
SELECT EMP_NAME, TO_CHAR(HIRE_DATE, 'YYYY"년" MM"월" DD"일" "("DY")"') 입사일
FROM EMPLOYEE;
--> 년, 월, 일은 오라클에 등록된 날짜 표기 패턴이 아니라서 오류
--> 기존에 없던 패턴 추가 시 ""(쌍따옴표)로 감싸줘서 문자열 그대로를 출력하게 함✏️ TO_DATE (날짜로 변환)
TO_DATE(문자형 데이터, [포맷])
문자형 데이터를 날짜로 변경
TO_DATE(숫자형 데이터, [포맷])
숫자형 데이터를 날짜로 변경
-> 지정된 포맷으로 날짜를 인식함
SELECT '2023-05-17', TO_DATE('2023-05-17') FROM DUAL;
SELECT TO_DATE('20100103') FROM DUAL;
SELECT TO_DATE(20100103) FROM DUAL; -- 숫자도 가능
SELECT TO_DATE('041030 143000', 'YYMMDD HH24MISS') FROM DUAL;
SELECT TO_CHAR( TO_DATE('041030 143000', 'YYMMDD HH24MISS'), 'YYYY/MM/DD HH24"시 "MI"분"' ) FROM DUAL;
-- EMPLOYEE 테이블에서 각 직원이 태어난 생년월일 조회
SELECT EMP_NAME, TO_DATE(SUBSTR(EMP_NO, 1, 6), 'RRMMDD') 생년월일 FROM EMPLOYEE;
SELECT TO_DATE('19490115', 'RRRRMMDD') FROM DUAL;✏️ TO_NUMBER (숫자 형변환)
TO_NUMBER(문자데이터, [포맷])
문자형 데이터를 숫자 데이터로 변경
SELECT '1,000,000' + 10 FROM DUAL;
SELECT TO_NUMBER('1,000,000', '9,999,999') + 10 FROM DUAL;💡 NULL 처리 함수
✏️ NVL(컬럼명, 컬럼값이 NULL일 때 바꿀 값)
NULL인 컬럼값을 다른 값으로 변경
-- EMPLOYEE테이블에서 이름, 급여, 보너스, 급여*보너스 조회
SELECT EMP_NAME, SALARY, NVL(BONUS, 0), SALARY * NVL(BONUS, 0)
FROM EMPLOYEE;✏️ NVL2(컬럼명, 바꿀값1, 바꿀값2)
해당 컬럼의 값이 있으면 바꿀값1로 변경, 해당 컬럼이 NULL이면 바꿀값2로 변경
-- EMPLOYEE 테이블에서
-- 기존 보너스를 받던 사원의 보너스를 0.8로
-- 보너스를 받지 못했던 사원의 보너스를 0.3으로 변경하여
-- 이름, 기존 보너스, 변경된 보너스 조회
SELECT EMP_NAME, BONUS, NVL2(BONUS, 0.8, 0.3)
FROM EMPLOYEE;[연습 문제]
-- EMPLOYEE 테이블에서 사원명, 입사일-오늘, 오늘-입사일 조회
-- 단, 입사일-오늘의 별칭은 "근무일수1",
-- 오늘-입사일의 별칭은 "근무일수2"로 하고
-- 모두 정수(내림)처리, 양수가 되도록 처리
SELECT EMP_NAME 사원명,
FLOOR( ABS(HIRE_DATE - SYSDATE) ) 근무일수1,
FLOOR( ABS(SYSDATE - HIRE_DATE) ) 근무일수2
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 사번이 홀수인 직원들의 정보 모두 조회
SELECT * FROM EMPLOYEE
--WHERE SUBSTR(EMP_ID, -1, 1) IN ('1','3','5','7','9');
WHERE MOD(EMP_ID, 2) = 1;
-- EMPLOYEE 테이블에서 근무 년수가 20년 이상인 직원 정보 조회
SELECT * FROM EMPLOYEE
WHERE EXTRACT(YEAR FROM SYSDATE) - EXTRACT(YEAR FROM HIRE_DATE) >= 20;
-- EMPLOYEE 테이블에서
-- 직원명과 주민번호를 조회
-- 단, 주민번호 9번째 자리부터 끝까지는 '*'문자로 채움
-- 예 : 홍길동 771120-1******
SELECT EMP_NAME, SUBSTR(EMP_NO, 1, 8) || '******' 주민번호
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서
-- 직원명, 직급코드, 연봉(원) 조회
-- 단, 연봉은 보너스가 적용된 1년치 급여 + ₩57,000,000 으로 표시
SELECT EMP_NAME, JOB_CODE,
-- (급여 + (급여 * 보너스) * 12
TO_CHAR((SALARY + (SALARY * NVL(BONUS, 0)))*12, 'L999,999,999') "연봉(원)"
FROM EMPLOYEE;
SELECT EMP_NAME, JOB_CODE,
-- 급여 * (1 + 보너스) * 12
TO_CHAR(SALARY * (1 + (NVL(BONUS, 0))) * 12, 'L999,999,999') AS "연봉(원)"
FROM EMPLOYEE;💡 선택 함수
여러 가지 경우에 따라 알맞은 결과를 선택할 수 있음
✏️ DECODE
DECODE(계산식 | 컬럼명, 조건값1, 선택값1, 조건값2, 선택값2, ... , 아무것도 일치하지 않을 때)비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과 값 반환
일치하는 값을 확인(자바의 SWITCH와 비슷함)
-- 직원들의 성별 구분하기
SELECT EMP_NAME, DECODE(SUBSTR(EMP_NO, 8, 1), '1', '남', '2', '여')
FROM EMPLOYEE;
-- 직원의 급여를 인상하고자 한다
-- 직급코드가 J7인 직원은 급여의 10%를 인상하고
-- 직급코드가 J6인 직원은 급여의 15%를 인상하고
-- 직급코드가 J5인 직원은 급여의 20%를 인상하며
-- 그 외 직급의 직원은 급여의 5%만 인상한다.
-- 직원 테이블에서 직원명, 직급코드, 급여, 인상급여(위 조건)을 조회하세요
SELECT EMP_NAME, JOB_CODE, SALARY,
DECODE(JOB_CODE, 'J7', SALARY * 1.1,
'J6', SALARY * 1.15,
'J5', SALARY * 1.2,
SALARY * 1.05) 인상급여
FROM EMPLOYEE;✏️ CASE
CASE WHEN 조건식 THEN 결과값
WHEN 조건식 THEN 결과값
ELSE 결과값
END비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과값 반환
조건은 범위 값 가능
-- 성별 구분
SELECT EMP_NAME,
CASE
WHEN SUBSTR(EMP_NO, 8, 1) = '1' THEN '남자'
WHEN SUBSTR(EMP_NO, 8, 1) = '2' THEN '여자'
END 성별
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 사번, 사원명, 급여를 조회
-- 급여가 500만원 이상이면 '고급'
-- 급여가 300~500만원이면 '중급'
-- 그 미만은 '초급'으로 출력처리하고 별칭은 '구분'으로 한다.
-- 부서코드가 'D6'인 직원만 조회
-- 직급코드 오름차순 정렬
SELECT EMP_ID, EMP_NAME, SALARY,
CASE
WHEN SALARY >= 5000000 THEN '고급'
WHEN SALARY >= 3000000 THEN '중급'
ELSE '초급'
END 구분
FROM EMPLOYEE
WHERE DEPT_CODE = 'D6'
ORDER BY JOB_CODE;