
✨ 데이터베이스 조작이 편해지는 ORM
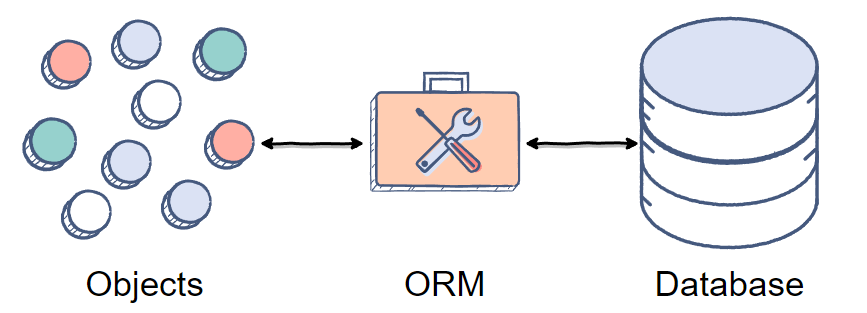
ORM이란 Object-Relational-Mapping의 약자로, 자바의 객체와 데이터베이스를 연결하는 프로그래밍 기법이다.
ORM이 있다면 데이터베이스의 값을 마치 객체처럼 사용할 수 있다. 쉽게 말해 SQL을 전혀 몰라도 자바 언어로만 데이터베이스에 접근해서 원하는 데이터를 받아 올 수 있는 것이다. 즉, 객체와 데이터베이스를 연결해 자바 언어로만 데이터베이스를 다룰 수 있게 하는 도구를 ORM이라고 한다.
ORM의 장점
- SQL을 직접 작성하지 않고 사용하는 언어로 데이터베이스에 접근할 수 있음
- 객체지향적으로 코드를 작성할 수 있기 때문에 비즈니스 로직에만 집중할 수 있음
- 데이터베이스 시스템이 추상화되어 있기 때문에 MySQL에서 PostgreSQL로 전환한다고 해도 추가로 드는 작업이 거의 없음 -> 즉, 데이터베이스 시스템에 대한 종속성이 줄어듦
- 매핑하는 정보가 명확하기 때문에 ERD에 대한 의존도를 낮출 수 있고 유지보수할 때 유리함
그렇다면 단점은?
- 프로젝트의 복잡성이 커질수록 사용 난이도가 올라감
- 복잡하고 무거운 쿼리는 ORM으로 해결이 불가능할 때가 있음
ORM의 종류
DBMS에도 여러 종류가 있는 것처럼 ORM에도 여러 종류가 있다. 자바에서는 JPA를 표준으로 사용한다.
JPA란 무엇일까?
JPA란 Java Persistence API이다. 자바에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스를 말한다.
JPA는 인터페이스이므로 실제 사용을 위해서는 ORM 프레임워크를 추가로 선택해야 한다. 대표적으로는 하이버네이트(Hibernate)를 많이 사용한다.
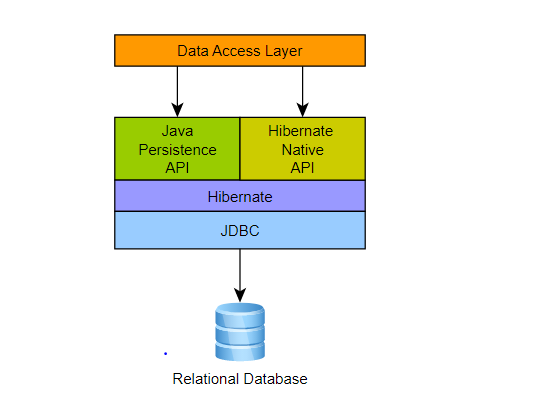
하이버네이트는 또 뭔데?
하이버네이트는 JPA 인터페이스를 구현한 구현체이자 자바용 ORM 프레임워크이다.
내부적으로는 JDBC API를 사용한다. 하이버네이트의 목표는 자바 객체를 통해 데이터베이스 종류에 상관없이 데이터베이스를 자유자제로 사용할 수 있게 하는 것이다!
즉 정리하자면, JPA는 자바 객체와 데이터베이스를 연결해 데이터를 관리하는 역할, 하이버네이트는 그러한 JPA의 인터페이스를 구현하는 역할을 한다.
💡 엔티티 매니저에 대해 알아보자!
이번에는 JPA의 중요한 컨셉 중 하나인 엔티티 매니저와 영속성 컨텍스트를 알아보자.
엔티티
엔티티란 데이터베이스의 테이블과 매핑되는 객체이다.
데이터베이스의 테이블과 직접 연결된다는 특징이 있어, 일반 객체와 구분하여 부른다. 즉 엔티티는 객체이긴 하지만 데이터베이스에 영향을 미치는 쿼리를 실행하는 객체인 셈이다.
엔티티 매니저
엔티티 매니저는 엔티티를 관리해 데이터베이스와 애플리케이션 사이에서 객체를 생성, 수정, 삭제하는 등의 역할을 한다. 이러한 엔티티 매니저를 만드는 곳이 엔티티 매니저 팩토리이다.
스프링 부트는 내부에서 엔티티 매니저 팩토리를 하나만 생성해서 관리하고 @PersistenceContext 또는 @Autowired 어노테이션을 사용해 엔티티 매니저를 사용한다.
@PersistenceContext
EntityManager em; // 프록시 엔티티 매니저 -> 필요할 때 진짜 엔티티 매니저 호출여기서 프록시 엔티티 매니저를 사용하는 이유는 뭘까?
스프링 부트는 기본적으로 빈을 하나만 생성해서 공유하므로 동시성 문제가 발생할 수 있다. 그래서 필요할 때 데이터베이스 트랜잭션과 관련된 실제 엔티티 매니저를 호출하는 것이다. 사실 이건 Spring Data JPA에서 관리하므로 개발자가 직접 생성하거나 관리할 필요는 없다..! 😀
영속성 컨텍스트
엔티티 매니저는 엔티티를 영속성 컨텍스트에 저장한다는 특징이 있다. 영속성 컨텍스트는 엔티티를 관리하는 가상의 공간이다. 이것이 있어서 데이터베이스에서 효과적으로 데이터를 가져올 수 있고, 엔티티를 편하게 사용할 수 있다!
영속성 컨텍스트의 특징
1차 캐시
영속성 컨텍스트는 내부에 1차 캐시를 가지고 있다. 이로 인해 캐시된 데이터를 조회할 때에는 데이터베이스를 거치지 않아도 매우 빠르게 데이터를 조회할 수 있다.
쓰기 지연
트랜잭션을 커밋하기 전까지는 데이터베이스에 실제로 질의문을 보내지 않고 쿼리를 모았다가 트랜잭션을 커밋하면 모았던 쿼리를 한 번에 실행한다. 이를 통해 적당한 묶음으로 쿼리를 요청할 수 있어 데이터베이스 시스템의 부담을 줄일 수 있다.
변경 감지
트랜잭션을 커밋하면 1차 캐시에 저장되어 있는 엔티티의 값과 현재 엔티티의 값을 비교해서 변경된 값이 있다면 변경 사항을 감지해 변경된 값을 데이터베이스에 자동으로 반영한다. 이를 통해 마찬가지로 적당한 묶음으로 쿼리를 요청할 수 있고, 시스템의 부담을 줄일 수 있다.
지연 로딩
쿼리로 요청한 데이터를 애플리케이션에 바로 로딩하는 것이 아니라 필요할 때 쿼리를 날려 데이터를 조회한다.
이러한 특징들로 인해 데이터베이스의 접근을 최소화해 성능을 높일 수 있다는 게 큰 장점이다! ✌
👌 스프링 데이터와 스프링 데이터 JPA
스프링 데이터
스프링데이터는 비즈니스 로직에 더 집중할 수 있게 데이터베이스 사용 기능을 클래스 레벨에서 추상화했다. 스프링 데이터에서 제공하는 인터페이스를 통해서 스프링 데이터를 사용할 수 있다.
이 인터페이스에서는 CRUD를 포함한 여러 메소드가 포함되어 있으며, 알아서 쿼리를 만들어 준다. 이외에도 페이징 처리 기능, 메소드 이름으로 쿼리 자동 빌딩 기능 등 많은 장점이 있다. 추가로 각 데이터베이스의 특성에 맞춰 기능을 확장해 제공하는 기술도 제공한다.
그중 스프링 데이터 JPA에 대해 살펴보자.
스프링 데이터 JPA
스프링 데이터 JPA란?
스프링 데이터의 공통적인 기능에서 JPA의 유용한 기술이 추가된 기술이다.
스프링 데이터 JPA에서 제공하는 메소드를 간단히 코드와 함께 알아보자.
MemberService.java
package me.ansoohyeon.springbootdeveloper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class MemberService {
@Autowired
MemberRepository memberRepository;
public void test(){
// 생성(Create)
memberRepository.save(new Member(1L, "A"));
// 조회(Read)
Optional<Member> member = memberRepository.findById(1L); // 단건 조회
List<Member> allMembers = memberRepository.findAll(); // 전체 조회
// 삭제(Delete)
memberRepository.deleteById(1L);
}
}🔎 이전에 작성했던 코드 속 어노테이션 분석해 보기!
Member.java
package me.ansoohyeon.springbootdeveloper;
import jakarta.persistence.*;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
@NoArgsConstructor(access = AccessLevel.PROTECTED) // 기본 생성자
@AllArgsConstructor
@Getter
@Entity // 엔티티로 지정
public class Member {
@Id // id 필드를 기본키로 지정
@GeneratedValue(strategy = GenerationType.IDENTITY) // 기본키를 자동으로 1씩 증가
@Column(name = "id", updatable = false)
private Long id;
@Column(name = "name", nullable = false) // name이라는 not null 컬럼과 매핑
private String name;
}만약 @Entity 어노테이션에서 테이블을 지정하고 싶다면 아래와 같이 name 파라미터 값을 지정하면 된다.
@Entity(name = "member_list") // 'member_list'라는 이름을 가진 테이블과 매핑
public class Article{
(생략)
}자동키 생성 설정 방식
- AUTO : 선택한 데이터베이스 dialect에 따라 방식을 자동으로 선택(기본값)
- IDENTITY : 기본키 생성을 데이터베이스에 위임(=AUTO_INCREMENT)
- SEQUENCE : 데이터베이스 시퀀스를 사용해서 기본키를 할당하는 방법
- TABLE : 키 생성 테이블 사용
@Column 어노테이션 속성
- name : 필드와 매핑할 컬럼 이름 -> 설정하지 않으면 필드 이름으로 자동 지정
- nullable : 컬럼의 null 허용 여부 -> 설정하지 않으면 true(nullable)
- unique : 컬럼의 유일한 값(unique) 여부 -> 설정하지 않으면 false(nonunique)
- columnDefinition : 컬럼 정보 설정 -> default 값을 설정할 수 있음
