질문거리
스트림 도입부
데이터를 그룹화하고 처리할 때 컬렉션 사용.
데이터베이스에서는 선언형으로 이와 같은 연산을 표현할 수 있다.
SELECT name FROM diches WHERE calorie < 400-> 어떻게 필터링할 것인지에 관한 코드를 구현하지 않아도 된다.(반복자 누적자 등을 이용할 필요가 없다. 구현은 자동으로 된다.)
SQL 질의 언어에서는 우리가 기대하는 것이 무엇인지 직접 표현할 수 있다.
성능을 개선하려면 멀티코어 아키텍처로 병렬처리를 할 수 있어야 한다.
4.1 스트림이란 무엇인가?
자바8 API에 새로 추가된 기능
스트림 API의 특징
- 선언형 : 더 간결하고 가독성이 좋아진다.
- 조립할 수 있음 : 유연성이 좋아진다.
- 병렬화 : 성능이 좋아진다.
기존 자바 코드와의 비교
기존의 자바코드
List<Dish> lowCaloricDishes = new ArrayList<>();
for(Dish dish : menu){
if(dish.getCalories()< 400){
lowCaloricDishes.add(dish)
}
}
Collections.sort(lowCaloricDishes, new Comparator<Dish>(){
public int compare(Dish dish1, Dish dish2){
return Integer.compare(dish1.getCalories, dish2.getCalories());
}
});
List<String> lowCaloricDishesName = new ArrayList<>();
for(Dish dish : lowCaloricDishes){
lowCaloricDishesName.add(dish.getName());
}stream을 사용한 최신 코드
import static java.util.Comparator.comparing;
import static java.util.stream.Collectors.toList;
List<String> lowCaloricDishesName =
menu.stream()
.filter(dish -> dish.getCalories() < 400)
.sorted(comparing(Dish::getCalories))
.map(Dish::getName)
.collect(toList());parallelStream을 사용해서 멀티코어 아키텍쳐에서 병렬로 실행
List<String> lowCaloricDishesName =
menu.paralleStream()
.filter(dish -> dish.getCalories() < 400)
.sorted(comparing(Dish::getCalories))
.map(Dish::getName)
.collect(toList());스트림 API는 매우 비싼 연산이다.
4.2 스트림 시작하기
스트림 정의
데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소
연속된 요소
컬렉션과 마찬가지로 스트림은 특정 요소 형식으로 이루어진 연속된 값 집합의 인터페이스를 제공한다.
컬렉션은 자료구조이므로 시간과 공간의 복잡성과 관련된 요소 저장 및 접근 연산이 주를 이룬다. 반면 스트림은 filter, sorted, map처럼 표현 계산식이 주를 이룬다. 즉, 컬렉션의 주제는 데이터고, 스트림의 주제는 계산이다.
소스
스트림은 컬렉션, 배열, I/O 자원 등의 데이터 제공 소스로부터 데이터를 소비한다.
데이터 처리 연산
스트림은 함수형 프로그래밍 언어 or 데이터베이스와 비슷한 연산을 지원한다. 연산은 순차적으로 또는 병렬적으로 실행할 수 있다.
두가지 중요 특징
파이프라이닝
스트림 연산 대부분은 스트림 연산끼리 연결해서 커다란 파이프라인을 구성할 수 있도록, 스트림 자신을 반환한다. 그 덕분에 게으름, 쇼트서킷 같은 최적화도 얻을 수 있다(5장 설명)
내부 반복
반복자를 이용해서 명시적으로 반복하는 컬렉션과 달리 스트림은 내부 반복을 지원한다.
지금까지의 설명을 예제로 확인해보자
import static java.util.stream.Collectors.toList;
List<String> threeGhighCaloricDishNames =
menu.stream()
.filter(dish -> dish.getCalories() > 300)
.map(Dish::getName)
.limit(3)
.collect(toList());- 메뉴에서 스트림을 얻는다.
- 파이프라인 연산 만들기. 첫 번째로 고칼로리 요리를 필터링한다.
- 요리명 추출
- 선착순 세 개만 선택
- 결과를 다른 리스트로 저장
- 결과는 [pork, beef, chicken]이다.
- 마지막 collect를 호출하기 전까지 menu에서 무엇도 선택되지 않으며 출력 결과도 없다.
4.3 스트림과 컬렉션
공통점
컬렉션과 스트림 모두 연속된 요소 형식의 값을 저장하는 자료구조의 인터페이스를 제공한다.
여기서 연속된이라는 말은 순차적으로 값에 접근한다는 것을 의미한다.
차이점
데이터를 언제 계산하느냐가 스트림과 컬렉션의 차이다. 컬렉션은 현재 자료구조가 포함하는 모든 값을 메모리에 저장하는 자료구조이다. 즉, 컬렉션의 모든 요소는 컬렉션에 추가하기 전에 계산되어야 한다.
반면 스트림은 이론적으로 요청할 때만 요소를 계산하는 고정된 자료구조다. 사용자가 요청하는 값만 스트림에서 추출한다!(사용자는 이것이 어떻게 이뤄지는지 알 수 없다.)
4.3.1 딱 한 번만 탐색할 수 있다.
탐색된 스트림 요소는 소비된다. 한번 탐색한 요소를 다시 탐색하려면 초기 데이터 소스에서 해로운 스트림을 만들어야 한다.(만약 데이터 소스가 I/O채널이라면 소스를 반복해서 사용할 수 없으므로 새로운 스트림을 만들 수 없다.)
List<String> title = Arrays.asList("Java","In","Action");
Stream<String> s = title.stream();
s.forEach(System.out::println);
s.forEach(System.out::println);위 코드에서는 한번 스트림을 사용했기 때문에 오류가 난다.
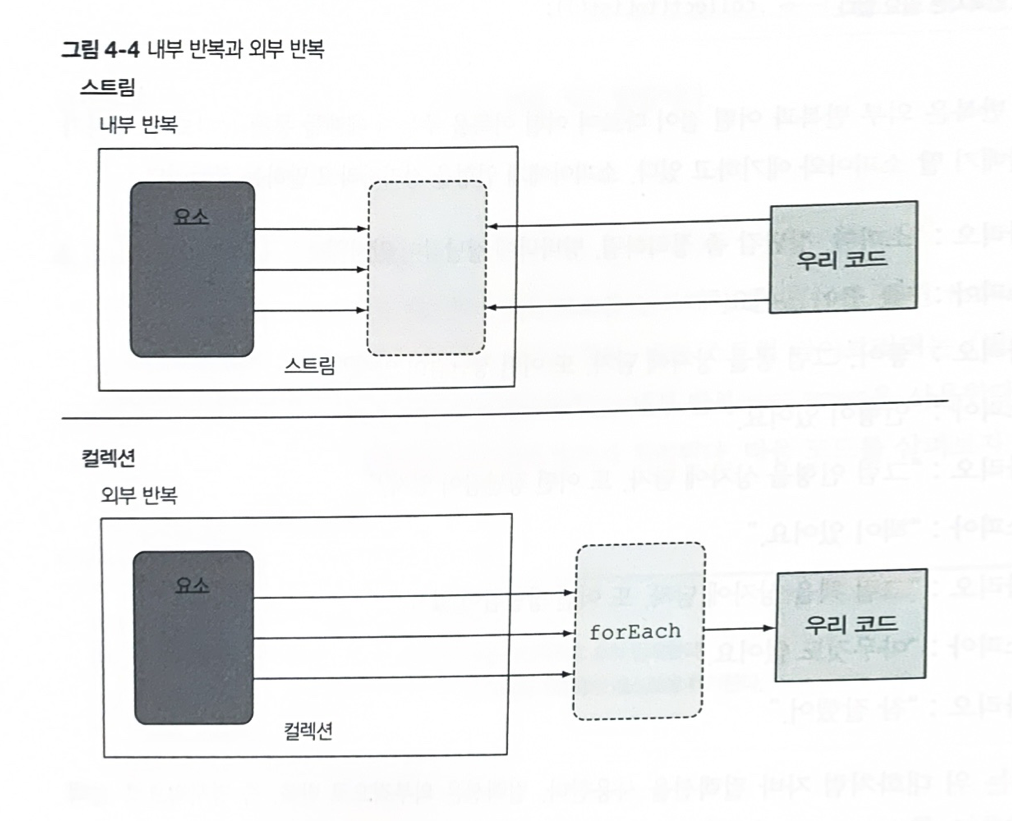
4.3.2 데이터 반복 처리 방법 : 외부 반복과 내부 반복
컬렉션 인터페이스를 사용하면 사용자가 직접 요소를 반복해야한다. 이를 외부 반복이라고 한다.
반면 스트림 라이브러리는 (반복을 알아서 처리하고 결과 스트림값을 어딘가에 저장해주는) 내부반복을 사용한다. 함수에 어떤 작업을 수행할지만 지정하면 모든 것이 알아서 처리된다.
컬렉션 : 내부적으로 숨겨진 반복자를 사용한 외부 반복
List<String> names = new ArrayList<>();
Iterator<String> iterator = menu.iterator();
while(iterator.hasNext()){
Dish dish = iterator.next();
names.add(dish.getName());
}컬렉션: for-each루프를 이용하는 외부 반복
List<String> names = new ArrayList<>();
for(Dish dish : menu){
names.add(dish.getName());
}스트림 : 내부반복
List<String> names = menu.stream()
.map(Dish::getName)
.collect(toList());파이프라인을 실행하는데 반복자가 필요 없다!
내부 반복의 장점
- 코드가 간결해지고, 선언적이게 변한다.
- 병렬성 구현을 자동으로 관리해준다.(캡슐화 ??? , IoC???)
- 최적화된 처리를 할 수 있다.
4.4 스트림 연산(=캡슐화 되서 제공되는 기본 연산자)
기본 분류
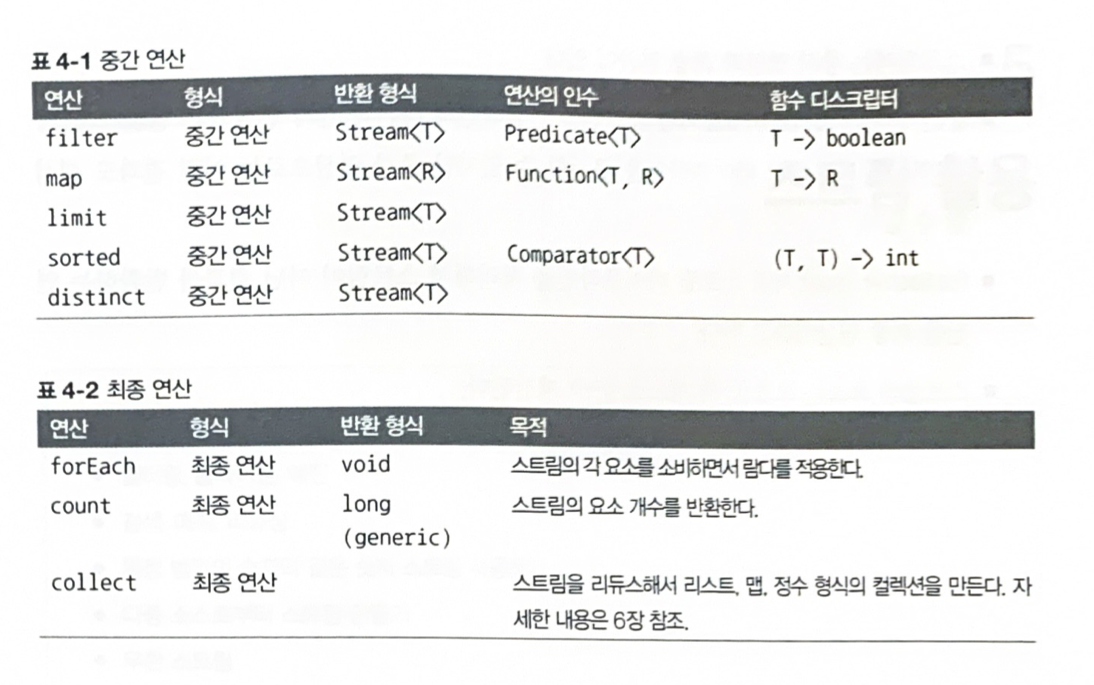
1. 중간 연산(intermediate operation)
2. 종결 연산(terminal operation)
4.4.1 중간 연산
filter나 sorted 같은 중간 연산은 다른 스트림을 반환한다. 따라서 여러 중간연산을 연결해서 질의를 만들 수 있다. 중간연산의 중요한 점은 최종 연산을 스트림 파이프라인에 실행하기 전까지는 아무 연산도 수행하지 않는다는 것, 즉 게으르다(lazy)는 것이다.
lazy한 것이 무엇인지 확인해보자.
List<String> names = menu.stream()
.filter(dish -> {
System.out.println("filtering " + dish.getName());
return dish.getCalories() > 300;
})
.map(dish -> {
System.out.println("mapping " + dish.getName());
return dish.getName();
})
.limit(3)
.collect(toList());
System.out.println(names);출력결과
filtering pork
mapping pork
filtering beef
mapping beef
filtering chicken
mapping chicken
[pork, beef, chicken]
쇼트서킷(limit) + 루프 퓨전(filter + map)이 적용된다.
4.4.2 최종 연산
보통 최종 연산에 의해서 List, Integer, void 등 스트림과 다른 결과가 반환된다.
4.4.3 스트림 이용하기
스트림 이용과정은 다음과 같이 세가지로 요약할 수 있다.
데이터소스
중간 연산
최종 연산
정리 도표

큰 도움이 되었습니다, 감사합니다.