보스턴 집값 예측 데이터를 활용해서 Gradient Descent를 구현해보았다.
# sklearn에서 더이상 boston 데이터셋을 지원하지 않아서, 아래의 방법을 통해서 데이터를 로드해야한다.
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = pd.DataFrame(np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]))
target = pd.DataFrame(raw_df.values[1::2, 2])
# 간단한 모델 구현을 위해서 RM(방의 계수), LSTAT(하위계층 비율)의 컬럼을 사용할 예정이다.
print(data[[5,12]])
print(target.head())
구현 하고자하는 모델의 구조
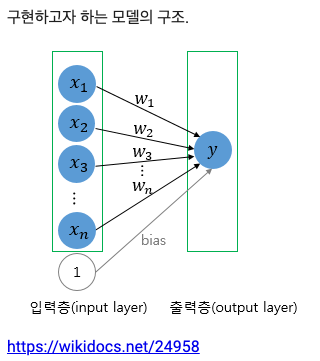
# 모델 입력전 데이터 전처리
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
sc_data = pd.DataFrame(scaler.fit_transform(data[[5,12]]), columns=['RM','LSTAT'])
sc_target = pd.DataFrame(scaler.fit_transform(target), columns=['target'])Numpy를 활용하여 구현해보기
# numpy로 Perceptron 구성해보기
# 가중치 값 선언하기
w1 = np.zeros((1,))
w2 = np.zeros((1,))
bias = np.zeros((1,))
print(w1.shape, w2.shape, bias.shape)
epoch = 1000
learning_rate = 0.01
for i in range(epoch):
# 예측값 계산하기
y_pred = sc_data['RM'].values * w1 + sc_data['LSTAT'].values * w2 + bias
# 실제값 예측값 차이 계산
diff = sc_target['target'].values - y_pred
# MSE 값 계산
mse_loss = np.mean(np.square(diff))
# mse loss 편미분하여 update 값 구하기
w1_update = -2/len(sc_target) * np.sum(sc_data['RM'].values * diff)
w2_update = -2/len(sc_target) * np.sum(sc_data['LSTAT'].values * diff)
bias_update = -2/len(sc_target) * np.sum(diff)
# learning_rate를 곱하여 가중지 업데이트 진행
w1 = w1 - learning_rate * w1_update
w2 = w2 - learning_rate * w2_update
bias = bias - learning_rate * bias_update
if i % 100 == 0 :
print(f'epoch : {i} loss : {mse_loss}')
print(f'최종 파라미터 값 : w1 = {w1}, w2 = {w2}, bias = {bias}')
# 학습 결과로 예측해보기
pred = sc_data['RM'].values * w1 + sc_data['LSTAT'].values * w2 + bias
sc_target['numpy_pred'] = pred
sc_target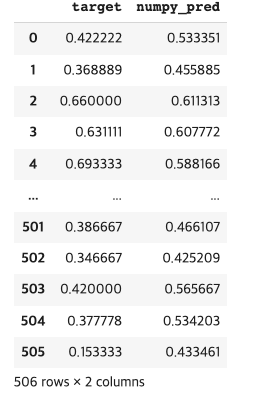
Tensorflow를 활용하여 구현해보기
# Tensorflow를 활용하여 구현해보기
import tensorflow as tf
from tensorflow.keras import Sequential, layers
model = Sequential([
layers.Dense(1, bias_initializer='zeros', activation=None, input_shape=(2,))
])
model.compile(optimizer='Adam',loss = 'mse', metrics=['mse'] )
model.fit(sc_data[['RM','LSTAT']], sc_target['target'], epochs=1000)
model.weights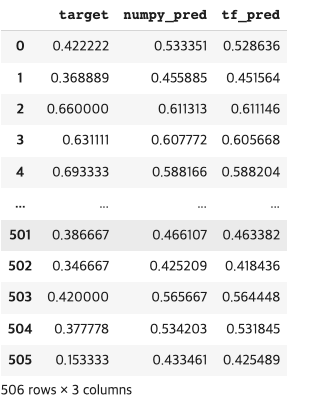
tf_pred = model.predict(sc_data[['RM','LSTAT']])
sc_target['tf_pred'] = tf_pred
sc_target
