0. 컬렉션 프레임워크
1) 핵심 인터페이스
— 상속도
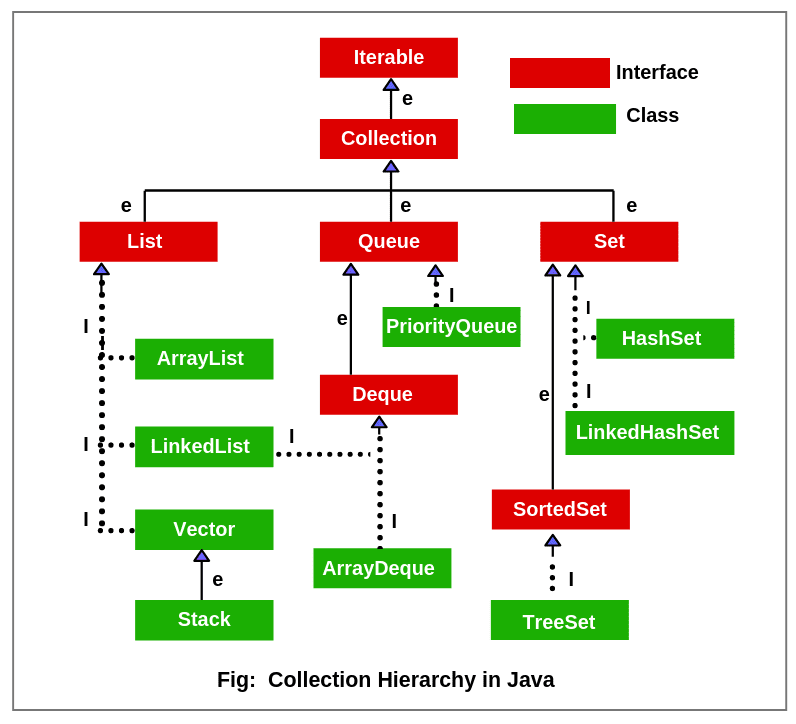
cf) Map (순서X, key:value, 중복X: 중복O)
— 메소드
| 메소드 | 설명 |
|---|---|
| boolean add(Object o) boolean addAll(Collection c) | 지정된 객체(o) 또는 Collection(c)의 객체들을 Collection에 추가 |
| void clear() | 모든 객체 삭제 |
| boolean contains(Object o) boolean containsAll(Collection c) | 포함 여부 |
| boolean equals(Object o) | 동일한 Collection인지 비교 |
| int hashCode() | Collection의 해시코드 반환 |
| boolean isEmpty() | Collection이 비어있는지 확인 |
| Iterator iterator() | Collection의 Iterator를 얻어서 반환 |
| boolean remove(Object o) | 지정된 객체를 삭제 |
| boolean removeAll(Collection c) boolean retainAll(Collection c) | 지정된 Collection에서 포함된 객체만을 남기고 다른 객체들은 Collection에서 삭제. 이 작업으로 Collection에 변화가 있으면 true를 아니면 false를 반환한다 |
| int size() | Collection에 저장된 객체의 개수를 반환 |
| Object[] toArray() | Collection에 저장된 객체를 객체배열로 반환 |
| Object[] toArray(Object[] a) | 지정된 배열에 Collection의 객체를 저장해서 반환 |
2) List
— 상속도
- List
- Vector
- Stack
- ArrayList
- LinkedList
- Vector
— 메소드
| 메소드 | 설명 |
|---|---|
| void add(int index, Object element) boolean addAll(int index, Collection c) | 지정된 위치에 객체 또는 컬렉션에 포함된 객체들을 추가 |
| Object get(int index) | 지정된 위치에 있는 객체를 반환 |
| int indexOf(Object o) | 지정된 객체의 위치를 반환 (List의 첫번째 요소부터 순방향으로 찾는다) |
| int lastIndexOf(Object o) | 역방향 |
| ListIterator listiterator() ListIterator listIterator(int index) | List객체에 접근할 수 있는 ListIterator 반환 |
| Object remove(int index) | 지정된 위치에 있는 객체를 삭제하고 삭제된 객체를 반환 |
| Object set(int index, Object element) | 지정된 위치에 객체를 저장 |
| void sort(Comparator c) | 지정된 비교자로 정렬 |
| List subList(int fromIndex, int toIndex) | 지정된 범위에 있는 객체를 반환 |
3) Set
— 상속도
- Set
- HashSet
- SortedSet
- TreeSet
4) Map
— 상속도
- Map
- Hashtable
- HashMap
- LinkedHashMap
- SortedMap
- TreeMap
— 메소드
| 메소드 | 설명 |
|---|---|
| void clear() | Map의 모든 객체를 삭제 |
| boolean containsKey(Object key) | 지정된 key객체와 일치하는 Map의 key객체가 있는지 확인 |
| boolean containsValue(Object value) | |
| Set entrySet() | Map에 저장되어있는 키-밸류 쌍을 Map.Entry 타입의 객체로 저장한 Set으로 반환한다 |
| boolean equals(Object o) | 동일한 Map인지 |
| Object get(Object key) | key에 대응하는 value 반환 |
| int hashCode() | |
| boolean isEmpty() | |
| Set keySet() | Map에 저장된 모든 key 객체를 반환 |
| Object put(Object key, Object value) | Map에 key - value로 연결하여 저장 |
| void putAll(Map t) | 지정된 Map의 모든 key-value 쌍을 추가한다. |
| Object remove(Object key) | 지정된 key 객체와 일치하는 key-value 객체를 삭제 |
| int size() | 키 밸류 쌍의 개수 |
| Collection values() | 모든 value 객체를 반환 |
values()의 리턴타입은 Collection인 반면 keySet()의 반환타입은 Set
-> 값은 중복을 허용하고 키는 중복을 허용하지 않기 때문
5) Map.Entry 인터페이스
Map 인터페이스의 내부 인터페이스 (key - value 쌍을 다루기 위해)
Map 인터페이스를 구현하는 클래스에서는 Map.Entry 인터페이스도 함께 구현해야함
— 메소드
| 메소드 | 설명 |
|---|---|
| boolean equals(Object o) | 동일한 Entry인지 |
| Object getKey() | Entry의 key 객체 |
| Object getValue() | Entry의 value 객체 |
| int hashCode() | |
| Object setValue(Object value) | Entry의 value 객체를 지정된 객체로 바꾼다 |
2. ArrayList
vector 개선, Object 배열
1) 메소드
| 메소드 | 설명 |
|---|---|
| ArrayList() | 크기가 10인 ArrayList 생성 |
| ArrayList(Collection c) | 주어진 컬렉션이 저장된 ArrayList 생성 |
| ArrayList(int intialCapacity) | 지정된 초기 용량을 갖는 ArrayList 생성 |
| boolean add(Object o) | ArrayList 마지막에 객체를 추가, 성공하면 true |
| void add(int index, Object element) | 지정된 위치에 객체를 저장 |
| boolean addAll(Collection c) | 주어진 컬렉션의 모든 객체를 저장 |
| boolean addAll(int index, Collecion c) | 지정된 위치부터 주어진 컬렉션의 모든 객체를 저장 |
| void clear() | |
| boolean contains(Object o) | 주어진 객체가 ArrayList에 포함되어 있는지 확인 |
| void ensureCapacity(int minCapacity) | ArrayList의 용량이 최소한 minCapacity가 되도록 한다 |
| Object get(int index) | 지정된 인덱스의 객체를 반환 |
| int indexOf(Object o) | 지정된 객체가 저장된 위치를 찾아 반환 |
| boolean isEmpty() | |
| Iterator iterator() | ArrayList의 Iterator 객체를 반환 |
| int lastIndexOf(Object o) | 객체가 저장된 위치를 역방향으로 검색해서 반환 |
| ListIterator listIterator() | ArrayList의 ListIterator를 반환 |
| ListIterator listIterator(int index) | ArrayList의 지정된 위치부터 시작하는 ListIterator를 반환 |
| Object remove(int index) boolean remove(Object o) boolean removeAll(Collection c) | |
| Object set(int index, Object element) | 주어진 객체를 지정된 위치에 저장 |
| int size() | |
| void sort(Comparator c) | 지정된 정렬기준으로 |
| List subList(int fromIndex, int toIndex) | 인덱스 사이에 저장된 객체 반환 |
| Object[] toArray() | 객체 배열로 |
| Object[] toArray(Object[] a) | |
| void trimToSize() | 빈 공간 없애기 |
import java.util.*;
public class Lab {
public static void main(String[] args) {
ArrayList list1 = new ArrayList<>(10);
list1.add(new Integer(5));
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
ArrayList list2 = new ArrayList<>(list1.subList(1, 4));
print(list1, list2);
// list1: [5, 4, 2, 0, 1, 3]
// list2: [4, 2, 0] -- subList(1, 4)니까 1 ~ 3 인덱스
Collections.sort(list1); // list1과 list2를 정렬한다
Collections.sort(list2); // Collections.sort(List l)
print(list1, list2);
// list1: [0, 1, 2, 3, 4, 5]
// list2: [0, 2, 4]
System.out.println("list1.containsAll(list2): " + list1.containsAll(list2));
// list1.containsAll(list2): true
// list1이 list2의 모든 요소를 포함하고 있음
list2.add("B");
list2.add(3, "A");
print(list1, list2);
// list1: [0, 1, 2, 3, 4, 5]
// list2: [0, 2, 4, A, B]
// add(obj)를 이용하여 새로운 객체를 저장
list2.set(3, "AA");
print(list1, list2);
// list1: [0, 1, 2, 3, 4, 5]
// list2: [0, 2, 4, AA, B]
// set(int idx, Object obj)로 다른 객체로 변경
// list1에서 list2와 겹치는 부분만 남기고 나머지는 삭제한다
System.out.println("list1.retainAll(list2): " + list1.retainAll(list2)); // true
print(list1, list2);
// list1: [0, 2, 4] -- list2와의 공통요소 이외에는 모두 삭제됨 - 변화가 있었으니 true
// list2: [0, 2, 4, AA, B]
// list2에서 list1에 포함된 객체들을 삭제한다. ★★★★★★★★★★
for (int i = list2.size() - 1; i >= 0; i--) {
if (list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
// list1: [0, 2, 4]
// list2: [AA, B]
}
static void print(ArrayList list1, ArrayList list2) {
System.out.println("list1: " + list1);
System.out.println("list2: " + list2);
System.out.println();
}
}- Collection은 인터페이스고 Collections는 클래스
- ★: 공통된 요소를 찾아서 삭제하는 부분
변수 i를 증가시켜가면서 삭제하면 한 요소가 삭제될 때마다 빈 공간을 채우기 위해 나머지 요소들이 자리이동을 하기 때문에 올바른 결과를 얻을 수 없다. 그래서 제어변수를 감소시켜가면서 삭제해야 자리이동이 발생해도 영향을 받지 않고 작업이 가능하다.
import java.util.ArrayList;
import java.util.List;
class Lab{
public static void main(String[] args) {
final int LIMIT = 10;
String source = "0123456789abcdefghijklmnopqrstuvwxyz";
int length = source.length();
List list = new ArrayList((length / LIMIT) + 10);
for(int i = 0; i < length; i+=LIMIT){
if(i+LIMIT < length)
list.add(source.substring(i, i+LIMIT));
else
list.add(source.substring(i));
}
for(int i = 0; i < list.size(); i++){
System.out.println(list.get(i));
}
}
}3. LinkedList
1) 배열과 비교
| 배열 | LinkedList |
|---|---|
| 간단, 읽기속도 빠름 | 배열의 단점 보완 |
| 크기 변경X, 비순차적 데이터의 추가, 삭제 시간 소요 높음 | 노드(요소): 다음 요소의 참조값 + 데이터 단방향 |
2) 메소드
| 메소드 | 설명 |
|---|---|
| boolean empty() | Stack이 비어있는지 알려준다 |
| Object peek() | Stack의 맨 위에 저장된 객체 반환 |
| void add(int index, Object element) | 지정된 index에 객체 추가 |
| boolean addAll(Collection c) | 주어진 컬렉션에 포함된 모든 요소를 LinkedList의 끝에 추가. 성공시 true, 실패시 false |
| boolean addAll(int index, Collection c) | 지정된 index에 주어진 컬렉션에 포함된 모든 요소를 추가 성공시 true, 실패시 false |
| void clear() | |
| boolean contains(Object o) | 지정된 객체가 LinkedList에 포함되었는지 알려줌 |
| boolean containsAll(Collecion c) | 지정된 컬렉션의 모든 요소가 포함되었는지 알려줌 |
| Object get(int index) | 지정된 위치의 객체 반환 |
| int indexOf(Object o) | 지정된 객체가 저장된 위치를 반환 |
| boolean isEmpty() | |
| Iterator listiterator() | ListIterator를 반환한다 |
| Iterator listiterator(int index) | 지정된 위치에서부터 시작하는 ListIterator를 반환 |
| Object remove(int index) | 지정된 위치의 객체를 LinkedList에서 제거 |
| boolean remove(Object o) | 지정된 객체를 LinkedList에서 제거 성공시 true, 실패시 false |
| boolean removeAll(Collection c) | 지정된 컬렉션의 요소와 일치하는 요소를 모두 삭제 |
| boolean retainAll(Collection c) | 지정된 컬렉션의 모든 요소가 포함되어 있는지 확인 |
| Object set(int index, Object element) | 지정된 위치(index)의 객체를 주어진 객체로 바꿈 |
| int size() | |
| List subList(int fromIndex, int toIndex) | LinkedList의 일부를 List로 반환 |
| Object[] toArray() | LinkedList의 첫번째 요소를 반환 |
| Object[] toArray(Object[] a) | LinkedList에 저장된 객체를 주어진 배열에 저장하여 반환 |
| Object element() | LinkedList의 첫번째 요소를 반환 |
| boolean offer(Object o) | 지정된 객체(o)를 LinkedList의 끝에 추가. 성공시 true, 실패시 false |
| Object peek() | LinkedList의 첫번째 요소를 반환 |
| Object poll() | 첫번째 요소를 반환, 성공시 true, 실패시 false |
| Object remove() | LinkedList의 첫번째 요소를 제거 |
| void addFirst(Object o) | LinkedList의 맨 앞에 객체(o)를 추가 |
| void addLast(Obejct o) | LinkedList의 맨 끝에 객체(o)를 추가 |
| Iterator descendingIterator() | 역순으로 조회하기 위한 DescendingIterator를 반환 |
| Object getFirst() | LinkedList의 첫번째 요소를 반환 |
| Object getLast() | |
| boolean offerFirst(Object o) | 맨 앞에 객체 o를 추가, 성t실f |
| boolean offerLast(Object o) | |
| Object peekFirst() | 첫번째 요소를 반환 |
| Object peekLast() | |
| Object pollFirst() | 첫번째 요소를 반환하면서 제거 |
| Object pollLast() | |
| Object pop() | removeFirst()와 동일 |
| void push(Object o) | addFirst()와 동일 |
| Object removeFirst() | |
| Object removeLast() | |
| boolean removeFirstOccurrence(Object o) | 첫번째로 일치하는 객체를 제거 |
| boolean removeLastOccurrence(Object o) |
add로 시작하는 메소드는 용량 초과 시 예외를 발생시키고, offer로 시작하는 메소드는 false를 리턴한다
3) DoubleLinkedList
LinkedList 보완
이전, 다음 데이터
4) ArrayList와 LinkedList
순차적인(=역순 삭제) 추가, 삭제 → ArrayList
중간 데이터 추가, 삭제 → LinkedList
다룰 데이터의 수가 변동되지 않는다면 → ArrayList
데이터의 수가 변동될 가능성이 있다면 → LinkedList
ArrayList: 읽기 빠름, 추가/삭제 느림, 비효율적 메모리 사용
LinkedList: 읽기 느림, 추가/삭제 용이, 데이터가 많을수록 접근성 하락
cf) 두 클래스를 조합해서 사용하는 방법도 가능
처음 데이터를 저장할 땐 ArrayList를 사용한 다음, 작업할 땐 LinkedList로 데이터를 옮겨서 작업하면 좋은 효율을 얻을 수 있음
import java.util.ArrayList;
import java.util.LinkedList;
class Lab{
public static void main(String[] args) {
ArrayList al = new ArrayList(1000000);
for(int i = 0; i < 1000000; i++){
al.add(i + "");
}
LinkedList ll = new LinkedList(al);
for(int i = 0; i < 1000; i++){
ll.add(500, "X");
}
}
}컬렉션 프레임워크에 속한 대부분의 컬렉션 클래스들은 변환 생성자를 제공하므로, 이를 이용하면 간단히 다른 컬렉션으로 데이터를 옮길 수 있다.
4. Stack과 Queue
1) 비교
| 스택 | 큐 |
|---|---|
| 마지막에 저장한 데이터를 가장 먼저 꺼냄 | 처음에 저장한 데이터를 가장 먼저 꺼냄 |
| LIFO(Last In First Out) | FIFO(First In First Out) |
| 순차적으로 데이터를 추가하고 삭제 → ArrayList같은 배열 기반의 컬렉션 | 배열기반 컬렉션을 사용하면 빈 공간을 채우기 위해 데이터의 복사가 발생하므로 비효율적 → LinkedList가 적합 |
2) Stack의 메소드
| 메소드 | 설명 |
|---|---|
| boolean empty() | Stack이 비어있는지 알려준다 |
| Object peek() | Stack의 맨 위에 저장된 객체를 반환. pop()과 달리 Stack에서 객체를 꺼내진 않음. 비었을 때 EmptyStackException 발생 |
| Object pop() | Stack의 맨 위에 저장된 객체를 꺼낸다. 비었을 때 EmptyStackException 발생 |
| Object push(Obejct item) | Stack에 객체를 저장 |
| int search(Object o) | Stack에서 주어진 객체를 찾아서 그 위치를 반환 못 찾으면 -1 |
배열과 달리 위치는 0이 아니라 1부터 시작
3) Queue의 메소드
| 메소드 | 설명 |
|---|---|
| boolean add(Object o) | 성공시 true 저장공간이 부족하면 IllegalStateException 발생 |
| Object remove() | Queue에서 객체를 꺼내 반환 비었으면 NoSuchElementException |
| Object element() | 삭제 없이 요소를 읽어온다. peek과 달리 Queue가 비었을 때 NoSuchElementException 발생 |
| boolean offer(Object o) | Queue에 객체를 저장. 성공시 true |
| Object poll() | 객체를 꺼내 반환. 비어있으면 null을 반환 |
| Object peek() | 삭제없이 요소를 읽어온다. 비어있으면 null을 반환 |
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
class Lab{
public static void main(String[] args) {
Stack st = new Stack();
Queue q = new LinkedList(); // Queue 인터페이스의 구현체인 LinkedList 사용
st.push("0");
st.push("1");
st.push("2");
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("== Stack ==");
while(!st.empty()){
System.out.println(st.pop()); // 2 1 0
}
System.out.println("== Queue ==");
while(!q.isEmpty()){
System.out.println(q.poll()); // 0 1 2
}
}
}cf) Stack은 클래스로 구현해서 제공 중이지만, 큐는 Queue 인터페이스로만 정의해놨을 뿐 별도의 클래스 X.
-> Queue 인터페이스를 구현한 클래스들 중 하나를 사용하면 됨
import java.util.EmptyStackException;
import java.util.Vector;
class MyStack extends Vector{
public Object push(Object item){
addElement(item);
return item;
}
public Object pop(){
Object obj = peek(); // 마지막에 저장된 요소 읽어옴
// 만약 Stack이 비어있으면 아래 peek() 메서드가 EmptyStackException을 반환한다
removeElementAt(size() - 1);
return obj;
}
public Object peek(){
int length = size();
if(length == 0){
throw new EmptyStackException();
}
// 마지막 요소 반환
return elementAt(length -1);
}
public boolean empty(){
return size() == 0;
}
public int search(Object o){
int i = lastIndexOf(o);
// 끝에서부터 객체를 찾는다
// 반환값은 저장된 위치(배열의 index)다.
if(i >= 0){ // 객체를 찾은 경우
return size() - i;
// stack은 맨 위에 저장된 객체의 index를 1로 정의하기 때문에 계산을 통해서 구한다
}
// 없으면 -1
return -1;
}
}4) 스택과 큐의 활용
- 스택: 수식계산, 수식괄호검사, 워드프로세서의 undo/redo, 웹 브라우저의 뒤로, 앞으로
- 큐: 최근 사용 문서, 인쇄작업 대기목록, 버퍼(buffer)
5) PriorityQueue
Queue 인터페이스의 구현체
우선 순위가 높은 것부터
Null 저장 X
6) Deque (Double Ended Queue)
양 끝 추가, 삭제
스택 + 큐
5. Iterator, ListIterator, Enumeration
컬렉션에 저장된 요소 접근에 사용되는 인터페이스
Enumeration ← Iterator의 레거시
ListIterator: Iterator의 기능 향상
1) Iterator
— Iterator의 메서드
| 메서드 | 설명 |
|---|---|
| boolean hasNext() | 읽어올 요소가 남아있는지 확인한다. 있으면 true |
| Object next() | 다음 요소를 읽어온다. |
| next() | 호출 전 hasNext()로 확인하는 게 안전 |
| void remove() | next()로 읽어온 요소를 삭제 |
참조변수의 타입을 ArrayList 등이 아니라 Collection 타입으로 하는 이유
Collection에 없고 ArrayList에만 있는 메서드를 사용하는 게 아니라면 Collection 타입의 참조변수가 효율적.
만약 ArrayList를 LinkedList로 바꿔야 한다면 선언문 하나만 변경하면 나머지 코드는 검토하지 않아도 되기 때문.
cf) Iterator it = map.entrySet().iterator();
2) ListIterator와 Enumeration
Iterator + 양방향 조회 → List에만 사용 가능
Enumeration 메서드는 생략
— ListIterator의 메소드
| 메소드 | 설명 |
|---|---|
| void add(Object o) | |
| boolean hasNext() | |
| boolean hasPrevious() | |
| Object next() | |
| Object previous() | |
| int nextIndex() | 다음 요소의 idx를 반환 |
| int previousIndex() | 이전 요소의 idx를 반환 |
| void remove() | next(), previous()로 읽어온 요소를 삭제 |
| void set() | next(), previous()로 읽어온 요소를 지정된 객체 o로 변경 |
import java.util.ArrayList;
import java.util.Collection;
import java.util.ListIterator;
class Lab{
public static void main(String[] args) {
ArrayList list = new ArrayList();
// ListIterator를 쓸 거기 때문에 Collection 타입 불가
for(int i = 1; i < 6; i++){
list.add(i + "");
}
ListIterator it = list.listIterator();
while(it.hasNext()){
System.out.println(it.next()); // 1 2 3 4 5
}
while(it.hasPrevious()){
System.out.println(it.previous()); // 5 4 3 2 1
}
}
}3) Iterator 구현
⭐️ Iterator의 메서드 중 add(), remove(), set(Object o)은 반드시 구현하지 않아도 됨
그렇다 하더라도 인터페이스로부터 상속받은 메서드는 추상메서드라 바디를 만들어줘야하므로 다음과 같이 처리한다
public void remove(){
throw new UnsupportedOperationException();
}호출하는 쪽에서 이 메소드가 바르게 동작하지 않는 이유를 알 수 없으므로 API를 확인하여 Exception 발생시켜줘야함.
(선언부 예외처리가 없는 이유는 UOE가 RuntimeException의 자손이기 때문)
6. 배열 복사
1) 배열 복사
- Arrays.copyof() : 배열 전체 복사, 새 배열로 반환
- Arrays.copyOfRange(): 일부 복사
2) 배열 채우기
- fill()
- setAll()
3) 정렬, 검색
- sort()
- binarySearch()
4) 기타
- equals(), toString(), deepEquals()
- deepToString()
5) asList(Object… a)
배열을 List에 담아 반환
크기변경 X
6) parallelXXX(), spliterator(), stream()
spliterator(): 작업 나눠 반환
stream(): 컬렉션 → stream
7. Comparator와 Comparable
Arrays.sort()를 호출하면 알아서 배열을 정렬하는 것처럼 보이지만, 사실 Character 클래스의 Comparable 구현에 의해 정렬된 것
Comparator, Comparable는 모두 인터페이스로 컬렉션을 정렬하는데 필요한 메서드를 정의하고 있음
→ Comparable 인터페이스를 구현한 클래스는 정렬이 가능하다는 것을 의미
Comparator: 내림차순 혹은 다른 기준
Comparable: 오름차순
Comparator, Comparable의 실제 소스
public interface Comparator{
int compare(Object o1, Object o2);
boolean equals(Object obj);
}
public interface Comparable{
public int compareTo(Object o);
}compareTo(): 두 객체가 같으면 0, 작으면 음수, 크면 양수를 반환하도록 구현해야 함
compare()도 마찬가지
equals(): 오버라이딩이 필요할 수도 있다는 걸 알리기 위해서 정의했을 뿐, 그냥 compare(Object o1, o2)만 구현하면 됨
import java.lang.reflect.Array;
import java.util.Arrays;
import java.util.Comparator;
class Descending implements Comparator{
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof Comparable && o2 instanceof Comparable){
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
// -1을 곱해서 기본 정렬방식의 역으로 변경한다.
// c2.compareTo(c1)도 가능
return c1.compareTo(c2) * -1;
}
return -1;
}
}
class Lab{
public static void main(String[] args) {
String[] strArr = {"cat", "Dog", "lion", "tiger"};
Arrays.sort(strArr); // String 클래스의 Comparable 구현에 의한 정렬
System.out.println("strArr = " + Arrays.toString(strArr));
// [Dog, cat, lion, tiger]
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구별 안 함
System.out.println("strArr = " + Arrays.toString(strArr));
// [cat, Dog, lion, tiger]
Arrays.sort(strArr, new Descending()); // 역순정렬
System.out.println("strArr = " + Arrays.toString(strArr));
// [tiger, lion, cat, Dog]
}
}⭐️ compare()의 매개변수가 Object 타입이기 때문에 compareTo()를 바로 호출할 수 없고, 먼저 Comparable로 형변환해야 함
8. HashSet
1) Set 대표
중복X, 순서X
중복을 제거하는 동시에 저장한 순서를 유지하고자 한다면 LinkedHashSet
2) 메서드
| 메서드 | 설명 |
|---|---|
| boolean add() | |
| boolean addAll() | 합집합 만들기 |
| void clear() | |
| Object clone() | 얕은 복사 |
| boolean contains() | |
| boolean containsAll(Collection c) | |
| boolean isEmpty() | |
| Iterator iterator() | |
| boolean remove() | |
| boolean removeAll() | |
| boolean retainAll(Collection c) | |
| int size() | |
| Object[] toArray() | |
| Object[] toArray(Object[] a) | 주어진 배열에 담음 |
import javax.swing.text.html.HTMLDocument;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
class Lab{
public static void main(String[] args) {
Set set = new HashSet();
int[][] board = new int[5][5];
for(int i = 0; set.size() < 25; i++){
set.add((int)(Math.random() * 50) +1 + "");
}
Iterator it = set.iterator();
for(int i = 0; i < board.length; i++){
for(int j =0; j < board[i].length; j++){
board[i][j] = Integer.parseInt((String)it.next());
System.out.print((board[i][j] < 10 ? " " : " ") + board[i][j]);
}
System.out.println();
}
}
}cf) 몇 번 실행해보면 같은 숫자가 비슷한 위치에 나온다. HashSet은 저장된 순서를 보장하지 않고 자체적인 저장방식에 따라 순서가 결정되기 때문. 이 경우에는 HashSet보다 LinkedHashSet이 더 나은 선택이다.
import java.util.HashSet;
class Lab{
public static void main(String[] args) {
HashSet set = new HashSet();
set.add(new String("abc"));
set.add(new String("abc"));
set.add(new Person("David", 10));
set.add(new Person("David", 10));
System.out.println(set);
}
}
class Person{
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Person){
Person tmp = (Person)obj;
return name.equals(tmp.name) && age == tmp.age;
}
return false;
}
@Override
public int hashCode() {
return Object.hash(name, age);
// int hash(Object... values)
}
@Override
public String toString() {
return name + ": " + age;
}
}HashSet의 add메서드는 새로운 요소를 추가하기 전에 기존에 저장된 요소와 같은 것인지 판별하기 위해 추가하려는 요소의 equals()와 hashCode()를 호출하기 때문에 equals()와 hashCode()를 목적에 맞게 오버라이딩 해야한다.
import java.util.HashSet;
import java.util.Iterator;
class Lab{
public static void main(String[] args) {
HashSet setA = new HashSet();
HashSet setB = new HashSet();
HashSet setHab = new HashSet();
HashSet setKyo = new HashSet();
HashSet setCha = new HashSet();
setA.add("1");
setA.add("2");
setA.add("3");
setA.add("4");
setA.add("5");
System.out.println("A = " + setA);
setB.add("4");
setB.add("5");
setB.add("6");
setB.add("7");
setB.add("8");
System.out.println("B = " + setB);
Iterator it = setB.iterator();
while(it.hasNext()){
Object tmp = it.next();
if(setA.contains(tmp)) {
setKyo.add(tmp);
}
}
it = setA.iterator();
while(it.hasNext()){
Object tmp = it.next();
if(!setB.contains(tmp)) {
setCha.add(tmp);
}
}
it = setA.iterator();
while(it.hasNext()){
setHab.add(it.next());
}
it = setB.iterator();
while(it.hasNext()){
setHab.add(it.next());
}
System.out.println("교집합: " + setKyo);
System.out.println("합집합: " + setHab);
System.out.println("차집합(A - B): " + setCha);
}
}3) 중복제거, 순서유지 → LinkedHashSet
9. TreeSet
- 이진검색 트리라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스.
- 정렬, 검색, 범위검색에 높은 성능을 보이는 자료 구조
- 이진 검색 트리의 성능을 향상시킨 레드-블랙트리로 구현되어 있음
- 중복X. 그러나 정렬된 위치에 저장
1) 노드
이진 트리(binary Tree)
각 노드에 최대 2개의 노드 연결 가능
루트라는 하나의 노드에서 시작해 계속 확장 가능
class TreeNode{
TreeNode left; // 왼쪽 자식 노드
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식 노드
}TreeSet에 저장되는 객체가 Comparable을 구현하던가 아니면 TreeSet에게 Comparator를 제공해서 두 객체를 비교할 방법을 알려줘야한다. 그렇지 않으면 예외 발생
데이터를 순차적으로 저장하는 게 아니라 저장위치를 찾아서 저장하고, 삭제하는 경우 트리의 일부를 재구성해야하므로 링크드 리스트보다 데이터의 추가, 삭제 시간은 더 걸린다. 대신 배열이나 링크드 리스트에 비해 검색과 정렬 기능이 더 뛰어나다.
2) 정리
모든 노드는 최대 두 개의 자식 노드를 가질 수 있다
왼쪽 자식 노드의 값을 부모노드의 값보다 작고 오른쪽 자식노드의 값은 부모노드의 값보다 커야한다.
노드의 추가, 삭제에 시간이 걸린다. (순차적으로 저장하지 않으므로)
검색(범위검색)과 정렬에 유리
중복된 값을 저장하지 못한다
3) 메서드
| 메서드 | 설명 |
|---|---|
| TreeSet() | |
| Treeset(Collection c) | |
| TreeSet(Comparator comp) | |
| TreeSet(SortedSet s) | 주어진 SortedSet을 구현한 컬렉션을 저장하는 TreeSet을 생성 |
| boolean add(Object o) | |
| boolean addAll(Collection c) | 지정된 객체(o) 또는 Collection(c)의 객체들을 추가 |
| Object ceiling(Object o) | 지정된 객체와 같은 객체를 반환 없으면 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| void clear() | 저장된 모든 객체를 삭제한다 |
| Object clone() | |
| Comparator comparator() | 정렬기준 반환 |
| boolean contains(Object o) | |
| boolean containsAll(Collection c) | |
| NavigableSet descendingSet() | 역순으로 정렬해서 반환 |
| Object first() | 첫번째 객체 반환 |
| Object floor(Object o) | 지정된 객체와 같은 객체를 반환 없으면 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| SortedSet headSet(Object toElement) | 지정된 객체보다 작은 값의 객체들을 반환 |
| NavigableSet headSet(Object toElement, boolean inclusive) | 지정된 객체보다 작은 값의 객체들을 반환 inclusive == true -> 같은 값의 객체도 포함 |
| Object higher(Object o) | 지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체 반환 없으면 null |
| boolean isEmpty() | |
| Iterator iterator() | |
| Object last() | |
| Object lower() | 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| Object pollFirst() | TreeSet의 첫번째 요소(제일 작은 값의 객체)를 반환 |
| Object pollLast() | TreeSet의 마지막 요소(제일 큰 값의 객체)를 반환 |
| boolean remove(Object o) | |
| boolean retainAll(Collection c) | |
| int size() | |
| Spliterator spliterator() | TreeSet의 spliterator를 반환 |
| SortedSet subSet(Object fromElement, Object toElement) | 범위검색의 결과를 반환, 끝 범위 포함X |
| NavigableSet subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) | 범위검색의 결과를 반환 fromInclusive true면 시작값 포함, toInclusive true면 끝값 포함) |
| SortedSet tailSet(Object fromElement) | 지정된 객체보다 큰 값의 객체들을 반환 |
| Object[] toArray() | 저장된 객체를 객체배열로 반환 |
| Object[] toArray(Object[] a) | 저장된 객체를 주어진 객체배열에 저장하여 반환 |
import java.util.Set;
import java.util.TreeSet;
class Lab{
public static void main(String[] args) {
Set set = new TreeSet();
for(int i = 0; set.size() < 6; i++){
int num = (int)(Math.random() * 45) + 1;
set.add(num);
}
System.out.println(set);
// [11, 13, 31, 39, 44, 45]
}
}
import java.util.Set;
import java.util.TreeSet;
class Lab{
public static void main(String[] args) {
TreeSet set = new TreeSet();
// subSet() 써야하므로 Set 타입 참조변수 불가
String from = "b";
String to = "d";
set.add("abc");
set.add("alien");
set.add("bat");
set.add("car");
set.add("Car");
set.add("disc");
set.add("dance");
set.add("dZZZZ");
set.add("dzzzz");
set.add("elephant");
set.add("elevator");
set.add("fan");
set.add("flower");
System.out.println(set);
// [Car, abc, alien, bat, car, dZZZZ, dance, disc, dzzzz, elephant, elevator, fan, flower]
System.out.println("range search: from " + from + " to " + to);
System.out.println("result1: " + set.subSet(from, to));
// result1: [bat, car]
System.out.println("result2: " + set.subSet(from, to + "zzz"));
// result2: [bat, car, dZZZZ, dance, disc]
}
}result1: 범위 검색에는 끝값은 포함되지 않으므로 c로 시작하는 단어까지만 포함되어 있음
result2: 끝범위인 d로 시작하는 단어까지 포함시키고자 한다면 끝범위에 'zzz' 등을 포함시키면 된다.
cf) 정렬순서: 코드값 => Car가 abc보다 앞에 위치 -> 대문자가 앞
10. HashMap과 HashTable
Vector : ArrayList = HashTable : HashMap
key : value
1) 메서드
| 메서드 | 설명 |
|---|---|
| HashMap() HashMap(int initialCapacity) HashMap(Map m) | |
| HashMap(int initialCapacity, float loadFactor) | 지정된 초기용량과 load factor의 HashMap 객체 생성 |
| void clear() | |
| Object clone() | |
| boolean containsKey(Object key) | |
| boolean containsValue(Object value) | |
| Set entrySet() | HashMap에 저장된 키와 값을 엔트리의 형태로 Set에 저장해서 반환 |
| Object get(Object key) | |
| Object getOrDefault(Object key, Object defaultValue) | 지정된 키의 value를 반환, 못 찾으면 기본값으로 지정된 객체 반환 |
| boolean isEmpty() | |
| Set keySet() | |
| Object put(Object key, Object value) | |
| void putAll(Map m) | |
| Object remove(Object key) | |
| Object replace(Object key, Object value) | 지정된 키의 값을 지정된 객체로 대체 |
| boolean replace(Object key, Object oldValue, Object newValue) | 지정된 키와 객체(oldValue)가 모두 일치하는 경우에만 새로운 객체로 대체 |
| int size() | |
| Collection values() | HashMap에 저장된 모든 값을 컬렉션의 형태로 반환 |
import java.util.HashMap;
import java.util.Scanner;
class Lab{
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234"); // 얘로 덮어씌워짐
Scanner sc = new Scanner(System.in);
while(true){
System.out.println("id와 pw를 입력하세요");
System.out.println("id: ");
String id = sc.nextLine().trim();
System.out.println("pw: ");
String pw = sc.nextLine().trim();
System.out.println();
if(!map.containsKey(id)){
System.out.println("입력하신 아이디는 존재하지 않습니다. 다시 입력하세요.");
continue;
}
if(!(map.get(id).equals(pw))){
System.out.println("비밀번호가 일치하지 않습니다. 다시 입력하세요.");
} else {
System.out.println("id와 비밀번호가 일치합니다.");
break;
}
}
}
}Iterator it = map.entrySet().iterator();
Map.Entry e = (Map.Entry)it.next();import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
class Lab{
static HashMap phoneBook = new HashMap();
public static void main(String[] args) {
addPhoneNo("친구", "이자바", "010-111-1111");
addPhoneNo("친구", "김자바", "010-222-2222");
addPhoneNo("친구", "김자바", "010-333-3333");
addPhoneNo("회사", "김대리", "010-444-4444");
addPhoneNo("회사", "김대리", "010-555-5555");
addPhoneNo("회사", "박대리", "010-666-6666");
addPhoneNo("친구", "이과장", "010-777-7777");
addPhoneNo("세탁", "010-888-8888");
printList();
}
// 그룹에 전화번호를 추가하는 메서드
static void addPhoneNo(String groupName, String name, String tel){
addGroup(groupName);
HashMap group = (HashMap) phoneBook.get(groupName);
group.put(tel, name);
}
// 그룹을 추가하는 메서드
static void addGroup(String groupName){
if(!phoneBook.containsKey(groupName))
phoneBook.put(groupName, new HashMap());
}
static void addPhoneNo(String name, String tel){
addPhoneNo("기타", name, tel);
}
// 전화번호부 전체 출력
static void printList(){
Set set = phoneBook.entrySet();
Iterator it = set.iterator();
while(it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
Set subSet = ((HashMap)e.getValue()).entrySet();
Iterator subIt = subSet.iterator();
System.out.println(" * " + e.getKey() + "[" + subSet.size() + "]");
while(subIt.hasNext()){
Map.Entry subE = (Map.Entry)subIt.next();
String telNo = (String)subE.getKey();
String name = (String)subE.getValue();
System.out.println(name + " " + telNo);
}
System.out.println();
}
}
}2) 해싱과 해시함수
(HashSet과 마찬가지로)서로 다른 두 객체에 대해 equals()로 비교한 결과가 true인 동시에 hashCode()의 반환값이 같아야 같은 객체로 인식
equals()를 오버라이딩해야 한다면 hashCode()도 오버라이딩해야 함
11. TreeMap
- 이진검색트리의 형태로 key: value 저장
- 검색, 정렬에 적합
- 검색에 관한 한 대부분의 경우에서 HashMap이 TreeMap보다 뛰어나므로 HashMap을 사용하는 것이 좋다.
- 범위 검색이나 정렬이 필요한 경우에는 TreeMap 사용
12. Properties
HashTable 상속 구현 (String, String)
setProperty()
getProperty()
list(): 모든 데이터 출력
13. Collections
컬렉션 동기화
변경불가 컬렉션 - 싱글톤 컬렉션
