hash란 고기나 감자같은 재료를 잘게 다져 만든 요리를 뜻한다. 유명한 감자 요리인 해시 브라운의 해시가 바로 이 hash이다.
컴퓨터 과학에서의 해시는 위의 사전적 의미와 비슷하게 입력 받은 데이터를 처리하고 그 결과로 완전히 달라진 모습의 데이터를 얻는 것을 의미한다.
해시는 해시 테이블, 암호화, 데이터 축약, 체크섬, 무작위화 함수 등 다양하게 활용된다.
해시 테이블(Hash Table)
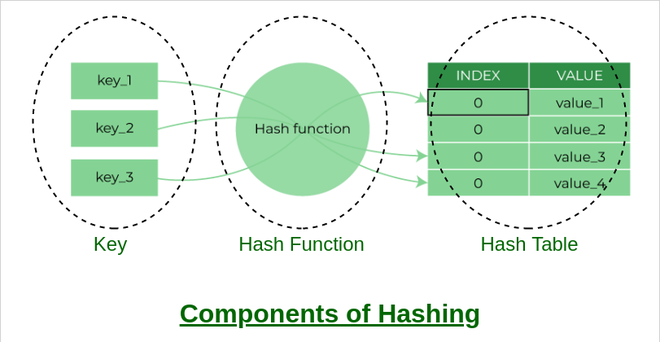
해시 테이블은 데이터의 해시 값을 테이블 내의 주소로 사용하는 자료구조로, 해시 맵(hash map)이라고도 한다.
데이터를 담을 테이블을 미리 크게 확보하고, 입력 받은 데이터를 해시 함수로 처리하여 테이블 내 주소를 계산하고 이 주소에 입력한 데이터를 저장하는 것이 해시 테이블이다.
이렇듯 간단한 해시 함수 연산만으로 빠르게 데이터에 접근할 수 있으므로 해시 테이블의 삽입, 삭제, 탐색 연산의 평균적인 시간 복잡도는 Θ(1)이다.
해시 테이블의 공간복잡도는 모든 상황에서 O(n)이다. 해시 테이블은 여유공간이 줄어들면 효율성이 떨어지기 때문에 실제로 해시 테이블에 저장된 데이터의 용량보다 메모리를 더 많이 확보해야 한다.
하지만 해시 테이블은 충돌(collision)이나 클러스터링(clustering) 문제를 피할 수 없기 때문에 최악의 시간 복잡도는 모든 연산에 대해 O(n)이 된다.
충돌이란 해시 함수가 서로 다른 입력에 대해 동일한 해시 값을 반환하여 해시 테이블 내의 주소가 충돌하는 문제를 말한다. 즉, 서로 다른 키 값 x,y가 있을 때, h(x)=h(y)인 경우를 의미한다.
클러스터링이란 해시 함수가 테이블 내의 주소를 고르게 사용하지 못하고 테이블 내의 일부 지역의 주소를 집중적으로 반환하여 데이터가 한쪽으로 치우치는 문제를 말한다.
충돌과 클러스터링 문제를 완벽하게 해결할 수 있는 알고리즘은 존재하지 않지만 여러 가지 기법을 활용하면 해시 테이블을 더 효율적으로 만들 수 있다.
해시 함수(Hash Function)
해시 함수는 해시 테이블 연산의 핵심으로, 입력 받은 데이터를 통해 테이블 내의 주소를 계산하는 함수이다. 해시 함수를 사용하는 것을 해싱(hashing)이라고 한다.
해시 함수 알고리즘은 매우 다양하며 최상의 분포를 제공하는 방법은 데이터의 유형에 따라 다르다.
성능이 좋은 해시 함수는 충돌을 최소화하고, 연산이 쉽고 빠르며, 해시 값이 균일한 분포가 되며, 사용할 키의 모든 정보를 이용한다.
가장 간단한 해시 함수 알고리즘으로는 나눗셈법, 곱셈법, 자릿수 접기 등이 있다.
나눗셈법(Hashing by division, 제산 잔여법)
h(x)=xmodm
나눗셈법은 가장 간단한 해시 함수 알고리즘으로, 입력 값 x을 해시 테이블의 크기 m으로 나눈 나머지를 주소로 사용하는 방법이다.
나눗셈법은 0부터 m−1 사이의 주소 반환을 보장한다.
나눗셈법을 쓸 경우 테이블 내 공간을 효율적으로 사용하기 위해서는 테이블의 크기를 소수로 정하는 것이 좋다고 알려져 있다. 특히 2의 제곱수와 거리가 먼 소수를 사용하면 효과적이다.
곱셈법(Hashing by multiplication)
h(x)=⌊m((xA)mod1)⌋
입력 값 x에 0보다 크고 1보다 작은 상수 A를 곱한 값의 소수부만 취한다(mod1).
그 소수부에 테이블의 크기 m을 곱하고 바닥함수(floor)를 적용한 값을 테이블의 주소로 사용한다.
곱셈법은 0부터 m−1 사이의 주소 반환을 보장한다.
나눗셈법처럼 테이블의 크기를 소수로 정할 필요는 없으며 일반적으로 2의 제곱수로 정한다.
곱셈법에서 테이블의 크기 m은 해시 값의 분포와 관련이 없지만 상수 A는 관련이 있다.
도널드 커누스에 따르면 황금비율 수의 역수((21+5)−1≈0.61803398)를 상수 A로 쓰는 것이 효율적이라고 한다.
중간 제곱법(mid-square)
h(x)=(x2/2m)mod2r
키 값이 정수인 경우 키 값을 제곱한 후 그 결과의 중간에 있는 r비트를 취해서 0에서 (2r−1)까지의 범위를 해시 값으로 사용하는 방법이다.
m은 키 값을 제곱한 결과에서 사용하지 않을 하위 비트의 크기이다.
모든 또는 대부분의 비트가 해시 연산에 기여하기 때문에 정수 키 값을 사용하는 경우 좋은 해시 함수이다.
자릿수 접기(Digits Folding)
나눗셈법과 곱셈법은 충돌과 클러스터링이 발생할 가능성이 높다. 자릿수 접기는 이러한 문제를 덜 일으키는 알고리즘 중 하나이다.
자릿수 접기는 숫자를 동일한 크기로 나눠서 각각의 수를 더한 값으로 해싱하는 것을 말한다. 이 역시 나눗셈법이나 곱셈법 처럼 일정한 범위 내의 해시 값을 얻을 수 있다.
예를 들어 8129335 라는 7자리의 십진수 정수가 있을 때, 각 자리의 수를 모두 더하면 31이 나온다. 8+1+2+9+3+3+5=31
두 자리씩 더하면 다음과 같다. 81+29+33+5=148
7자리의 십진수에 대해 한 자리씩 접기를 하면 최소 0에서 최대 63(7 * 9)까지의 해시 값을 얻을 수 있으므로 해시 값이 일정한 범위로 나온다는 것을 알 수 있다.
자릿수 접기는 문자열을 키로 사용하는 해시 테이블에 특히 잘 어울리는 알고리즘이다. 문자열의 각 문자는 아스키 코드같이 숫자로 변환할 수 있고, 이 값들을 각각 더해서 접으면 문자열을 깔끔하게 해시 테이블의 주소로 바꿀 수 있다.
충돌 해결 기법
해시 테이블의 충돌을 해결하는 방법은 크게 두 가지로 나뉜다.
첫 번째는 해시 테이블의 주소 바깥에 새로운 공간을 할당하여 해결하는 방법으로 개방 해싱(Open Hashing)이라고 한다.
두 번째는 주어진 해시 테이블의 공간 안에서 문제를 해결하는 방법으로 폐쇄 해싱(Closed Hashing)이라고 한다.
체이닝(Chaining)
체이닝은 개방 해싱이면서 폐쇄 주소법인 충돌 해결 기법이다. 폐쇄 주소법이란 밑에서 설명할 개방 주소법의 반대 개념으로, 해시 함수에 의해 만들어진 주소만 사용하는 방법을 의미한다.
체이닝은 해시 함수가 충돌을 일으키면 각 데이터를 해당 주소에 있는 연결 리스트에 삽입하여 문제를 해결하는 기법이다. 충돌이 일어날 때마다 데이터를 연결 리스트에 사슬처럼 엮는다고 하여 붙여진 이름이다.
체이닝 기반 해시 테이블에서 삽입 연산은 앞으로 발생할 충돌을 고려해서, 삭제와 탐색 연산은 이미 발생한 충돌을 고려해서 설계되어야 한다.
체이닝 기반 해시 테이블에서 탐색을 하려면 찾고자 하는 목표 값을 해싱하여 연결 리스트가 저장된 주소를 찾고, 그 주소에 있는 연결 리스트에 대해 순차 탐색을 실시하면 된다.
체이닝 기반 해시 테이블의 삽입 연산은 탐색과 비슷하다. 먼저 삽입될 데이터를 해싱하여 주소를 얻고, 그 주소에 있는 연결 리스트가 비어 있으면 데이터를 바로 삽입하고 그렇지 않다면 연결 리스트의 헤드 바로 앞에 삽입하고 삽입하는 데이터의 next 포인터를 기존에 있던 데이터로 연결한다.
가장 뒤가 아닌 앞쪽에 삽입하는 이유는 연결 리스트를 순차 탐색 할 필요가 없어서 효율적이기 때문이다. 삭제 연산은 연결 리스트에서 노드 하나를 삭제하는 방법과 동일하다.
체이닝 기법은 연결 리스트를 사용하기 때문에 결국 연결 리스트를 순차 탐색하게 되어 해시 테이블의 장점을 살리지 못한다는 문제점이 있다. 이 문제를 해결하려면 연결 리스트가 아닌 레드-블랙 트리 같은 성능이 더 좋은 자료구조를 활용해야 한다.
개방 주소법(Open Addressing)
개방 주소법은 폐쇄 해싱기법 중 하나로, 충돌이 일어날 때 원래의 해시 함수에 의해 만들어진 주소가 아니더라도 다른 주소를 사용할 수 있도록 허용하는 충돌 해결방법이다. 개방 주소법은 일반적으로 체이닝보다 효율적이다.
개방 주소법은 충돌이 일어나면 해시 테이블 내의 새로운 주소를 탐사(probe)하여 충돌된 데이터를 입력하는 방식으로 동작한다. 그러므로 개방 주소법에선 탐사 방법이 중요하다.
가장 간단한 탐사 방법으로는 선형 탐사(linear probing)가 있다. 충돌이 생기면 고정된 폭으로 주소를 계속 이동하여 비어 있는 주소를 찾아내면 그곳에 데이터를 입력하는 방법이다. 이 방법은 클러스터링이 많이 발생한다는 문제점이 있다.
선형 탐사를 개선한 방법으로 제곱 탐사(quadratic probing)가 있다. 기본적으로 선형 탐사와 같은 방법이지만 이동하는 거리가 고정된 게 아니라 제곱으로 늘어난다는 차이점이 있다. 하지만 제곱 탐사 또한 클러스터링 문제를 완전히 해결하진 못한다.
개방 주소법에서 클러스터링 문제를 해결하려면 결국 탐사할 주소의 규칙성을 없애야 한다. 이를 위해서 이중 해싱(double hashing) 기법이 있다. 이중 해싱은 두개의 해시 함수를 준비하여 첫번째 함수는 최초의 주소를 얻기위해 사용하고 두번째 함수는 충돌이 일어날 경우의 탐사 이동폭을 얻기 위해 사용하는 방법이다.
재해싱(Rehashing)
해시 테이블을 만들고 데이터를 입력할수록 테이블의 여유 공간은 줄어든다. 여유 공간이 줄어들수록 충돌이 자주 발생하며 탐색의 효율이 떨어지므로 이를 해결할 필요가 있다.
재해싱은 이러한 문제를 해결하는 방법 중 하나로, 해시 테이블의 크기를 늘리고 늘어난 해시 테이블의 크기에 맞춰 테이블 내의 모든 데이터를 다시 해싱하는 것이다.
재해싱은 오버헤드가 큰 방법이기 때문에 해시 테이블의 공간 사용량이 충분히 높은 경우에만 적용해야 한다.
해시 테이블에 저장된 데이터 개수를 해시 테이블의 크기(버킷의 개수)로 나눈 것을 로드 팩터(load factor)라고 한다. 일반적으로 로드 팩터가 70 ~ 80% 이상이면 해시 테이블의 성능이 급격히 떨어지기 때문에 재해싱이 필요하다.
개방 주소법과 재해싱을 활용하는 언어인 파이썬(CPython)의 경우 로드 팩터 기준을 0.66, 루비(Ruby)는 0.5로 설정하고 있다.