분류

머신 러닝은 아주 간단하게 말해서 데이터를 받아온 기계가 자체적으로 무언가의 처리를 통해 학습을 하고 의사 결정을 하는 행위 전반을 의미한다.

예를 들어 이미지를 받아온 인공지능이 자체적인 연산을 통해 그게 개인지 고양이인지를 분류하는 작업이 될 수 있겠다.
그럼 그 중에서 Representative Learning 은 뭐가 다를까. Representative Learning 은 머신러닝 대비 인공지능이 조금 더 똑똑하다.
가령 위의 이미지의 강아지와 고양이의 생김새를 구분한다고 가정해보자. 이 때 Representative Learning 은 그냥 강아지와 고양이의 사진만 엄청 많이 주면 알아서 각각의 특징을 추출해내고 학습하는 것을 성공한다.
그러나 머신러닝은? 고양이와 강아지의 귀 모양은 어떻게 다르고, 크기는 어떻게 다르고, 혀는 어떻게 다르고 등등 온갖 것들을 전부 추출해서 학습을 시켜야 한다. 한마디로 알아서 다 해주는 Representative Learning 과 달리 순수 머신러닝은 개귀찮다.

그럼 딥러닝은 어떨까. Representative Learning 이 갖고 있는 본질적 한계는 바로 학습을 하는 레이어가 고작 하나라는 것이다.
그러나 레이어 하나라는 건 다른 말로 말하자면 수많은 특징들을 다 배우는 데에는 한계가 크다는 의미이고, 따라서 레이어를 여러 겹 쌓아서 더 복잡한 내용을 배우게 하고 싶다. 이걸 Deep Learning 이라고 지칭한다.
물론 이는 정확한 설명은 아니다. 맨 위의 그림과 같이 머신러닝과 Representative Learning, 딥러닝은 포함 관계에 가까우니까. 그러나 내가 이해한 바로는 그렇다.
학습 과정

딥러닝 모델의 학습은 Back Propagation 을 통해 이루어진다. 식은 위와 같지만, 간단하게 말하자면 아래와 같다.
레이어는 특징 학습의 한 단계라고 정의할 수 있다. 그리고 레이어를 누적시킬 수록 새로운 특징들을 추가로 학습하고, 그 배운 내용을 중첩시키며 보다 복잡한 과제를 수행할 수 있다.
그런데 학습을 다 끝내고 잘 배웠나 확인해보니까 오류들이 섞여있는 것이다. 그럼 우리는 한 단계씩 돌아가면서 뭘 잘못 이해한 건가 확인하고, 오류들을 조금씩 조금씩 수정해준다. 그게 Back propagation 이다.
이 과정을 수차례 반복하고 나면 결국 학습 성과가 정답에 한없이 가까울 것이다. 그것이 바로 학습의 목표라고 할 수 있다.
그러나 한 단계 전으로 돌아가는 게 말이 쉽지, 복잡한 학습 과정 상에서는 내가 지금 잘못 배운 내용이 정확히 어디에서 꼬인 건지 파악하는 게 까다롭다. 이를 수행하기 위해서는 미분식이 사용된다.
그렇기 때문에 딥러닝 학습에는 미분이 가능한지가 매우 중요하다. 만약 미분을 못 한다면 그건 곧 학습이 사실상 불가능이라는 뜻으로, 우회해서라도 미분을 할 수 있도록 만들고는 한다.
Convolutional Network
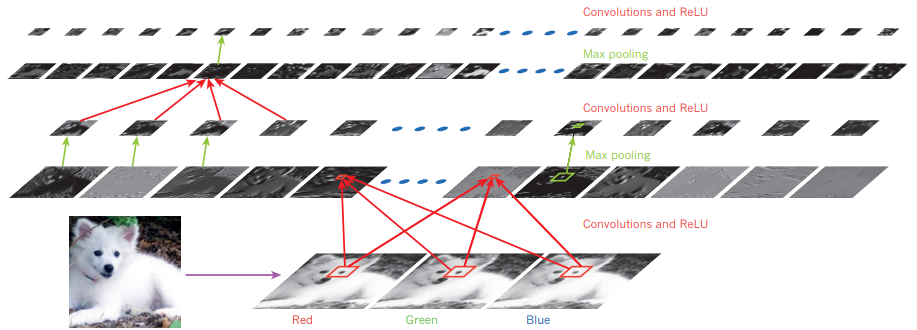
Convolution 이란 이미지와 같은 array 에 필터를 적용하기를 반복하여 특징을 추출한 다음, 그 특징들을 대상으로 다시 한 번 필터를 적용하는 식으로 더 넓은 범위로 뻗어나가며 그 대상이 갖고 있는 특성을 알아내는 것이다.
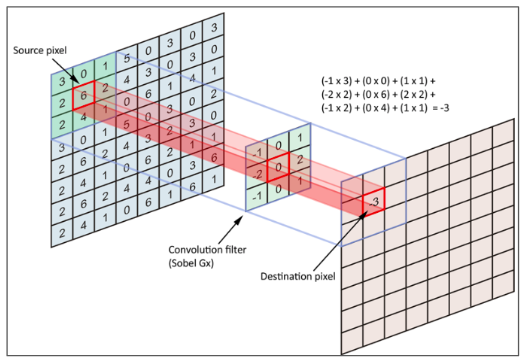
위 이미지는 적용하는 필터가 작동하는 방식의 예시이다. source pixel matrix 를 이미지의 픽셀 값이라고 가정할 때, 그 위를 필터가 지나가면서 특징 값을 추출해낸다.
이미지의 어디의 특징을 추출하든 간에 동일한 필터 값을 사용하기 때문에 동일 사물이 다른 위치에 있다고 해서 별개의 이미지로 인식하는 일은 잘 없다. 가령 어떤 이미지에서 왼쪽에 있던 강아지가 다른 이미지에서 오른쪽에 있다고 해서 강아지가 아니라고 인식되지는 않는다는 뜻이다.
위의 필터를 몇 차례 더 적용하기를 반복하게 되면 그 array 의 특징 값들을 낱낱이 파악할 수 있다.
Recurrent Neural Network
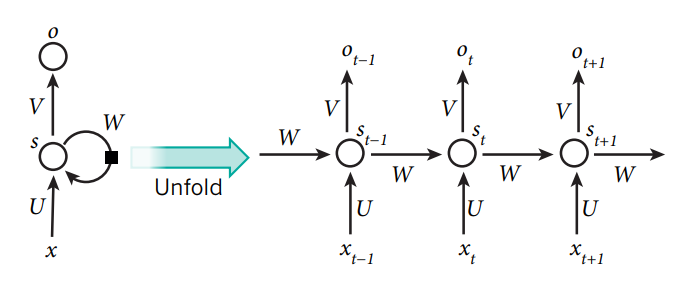
Sequential data 를 처리하는 방법의 일종이다. 일반적으로 문자열을 처리할 때 쓰인다.
여기서 x_(t-1), x_t 등에서는 일반적으로 sequence 의 각 값이 들어간다. 문장을 예시로 들게 되면 단어, 혹은 문자 하나가 입력 값으로 들어가는 것이다.
그러면 해당 값을 학습을 한 다음, 그 학습한 값과 다음에 들어오는 input 값을 종합하여 다시 한 번 학습하기를 반복하며 긴 sequence 를 원활히 학습할 수 있다.
그러나 여기서 중요한 한계점이 나오는데, 가령 사람이 순차적으로 100개의 단어를 듣고 암기하라는 과제를 받는다고 해보자. 그럼 마지막 단어는 잘 기억하겠지만 초반에 들은 단어들은 기억을 하지 못할 가능성이 클 것이다.
동일 현상이 RNN 에도 발생한다. 별도의 처리를 해주지 않는다면 sequence 가 진행될수록 이전에 들어온 값의 영향력은 미미해지는데, 이를 gradient descent 라고 지칭한다. 그리고 이 문제를 해결하기 위해서 lstm, gru 등의 다양한 방법이 나오게 된다.
마무리
딥러닝의 정의와 관련된 주요 연구 과제들을 복습할 수 있었던 논문이었다.
그러나 이와 별개로 해당 논문의 contribution 은 나한테는 그리 확실하게 다가오지는 않는다. 물론 Review 논문의 어쩔 수 없는 한계인 것 같기도 하지만. 그래도 꽤 흥미롭게 읽었다.
