인공 신경망
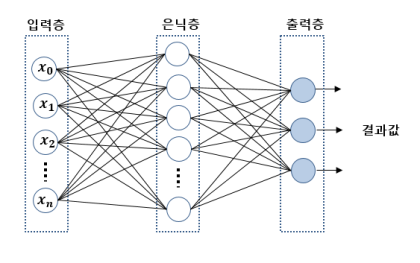
인공신경망(Artificial Neural Network)이란, 소프트웨어적으로 인간의 뉴런 구조를 본떠 만든 기게학습의 모델로서 인공지능을 구현하기 위한 기술 중 하나의 형태이다.
인간의 시각이나 청각을 본떠 만든 알고리즘으로 몇개의 층위를 만들어서 그안에 세포를 집어넣는 형태를 띄고 있다.
기본적으로 다층 퍼셉트론(Multi Layer Perceptron,MLP)를 기반으로 딥러닝이 구성되어있는데,
일반적으로 입력층,은닉층,출력층으로 구분되어 있다. 은닉층은 1개 혹은 그 이상으로 구성될 수 있으며, 해당 은닉층이 2개 이상의 경우에 심층신경망(Deep Neural Network,DNN)으로 불리며, 단층 퍼셉트론으로는 해결 할 수 없던 문제를 Layer 층을 늘림으로써 퍼셉트론의 조합과 확장으로 해결을 할 수 있습니다.
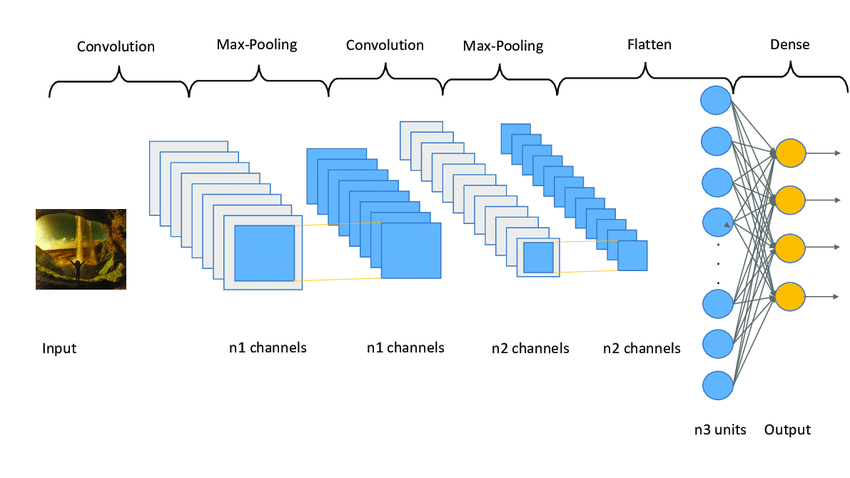
합성곱 신경망(CNN, Concolution Neural Network)
1989년 인간의 시신경 구조를 모방하여 만들어진 인공신경망의 알고리즘으로, 다수의 COnvolution Layer로 부터 Feature map을 추출하고 Subsampling(Pooling)을 통해 차원을 축소하여, Feature map에서 중요한 부분을 가져온다. 주로 Classification, semantic segmentation 등 computer vision분야에서 사용하고 있으며, 적은 연산량과 높은 성능을 보이고 있다.
기본적으로 합성곱 신경망 (이하 CNN)은 다음과 같은 구조의 순서로 이루어져 있다.
Convolution Layer
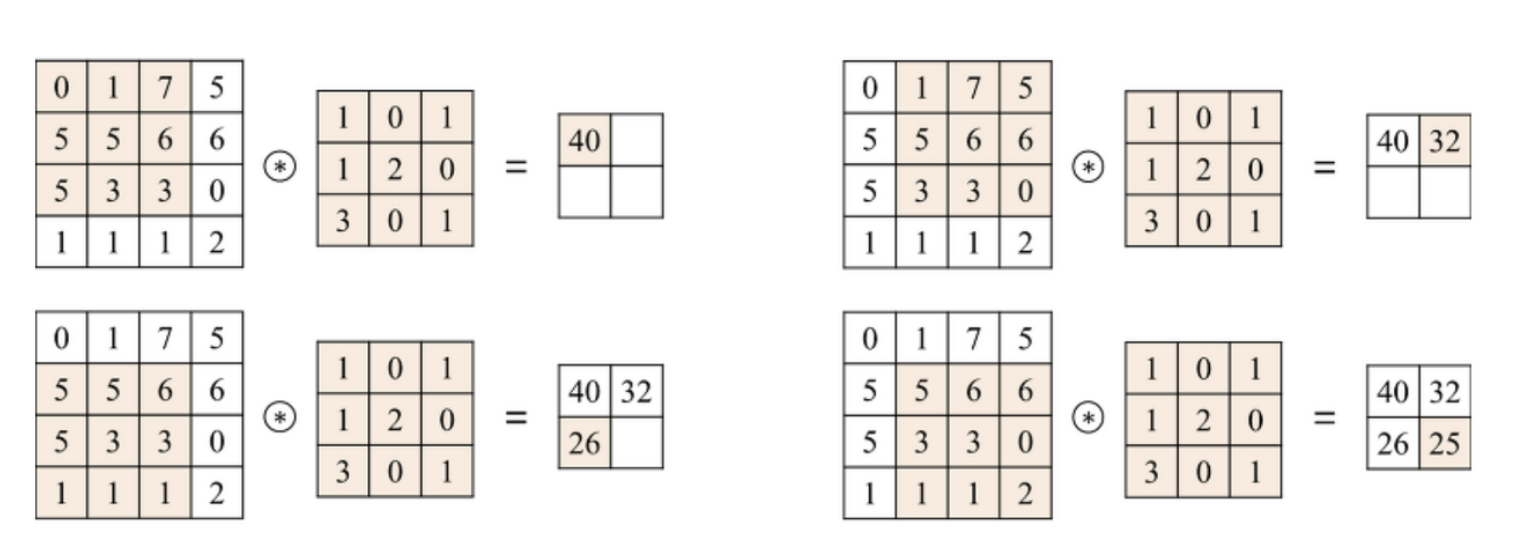
위의 사진과 같이 이미지가 있다고 하면, 이미지의 Width와 Height외에, 추가적으로 사진이 (R,G,B)형식이라면 3개의 channel이 (R,G,B,α)형식이라면 4개의 channel으로 형성된 이미지이다.
해당 이미지에 필터를 적용하여 필터의 channel 만큼 Feature map을 형성한다.
여기서 추가적으로 stride(필터의 이동량)를 주어 건너 띄는 식으로의 학습을 진행하는 데, 이를 추가함으로써 계산량을 줄일 수 있다.
왼쪽의 사진은 stride=1일 경우이고, 오른쪽의 사진은 stride=2일 때의 사진이다.
Pooling Layer
subsampling layer으로 불리기도 하는 Pooling layer는 최적화 파라미터의 개수를 줄이기 위함으로 알려져 있습니다.
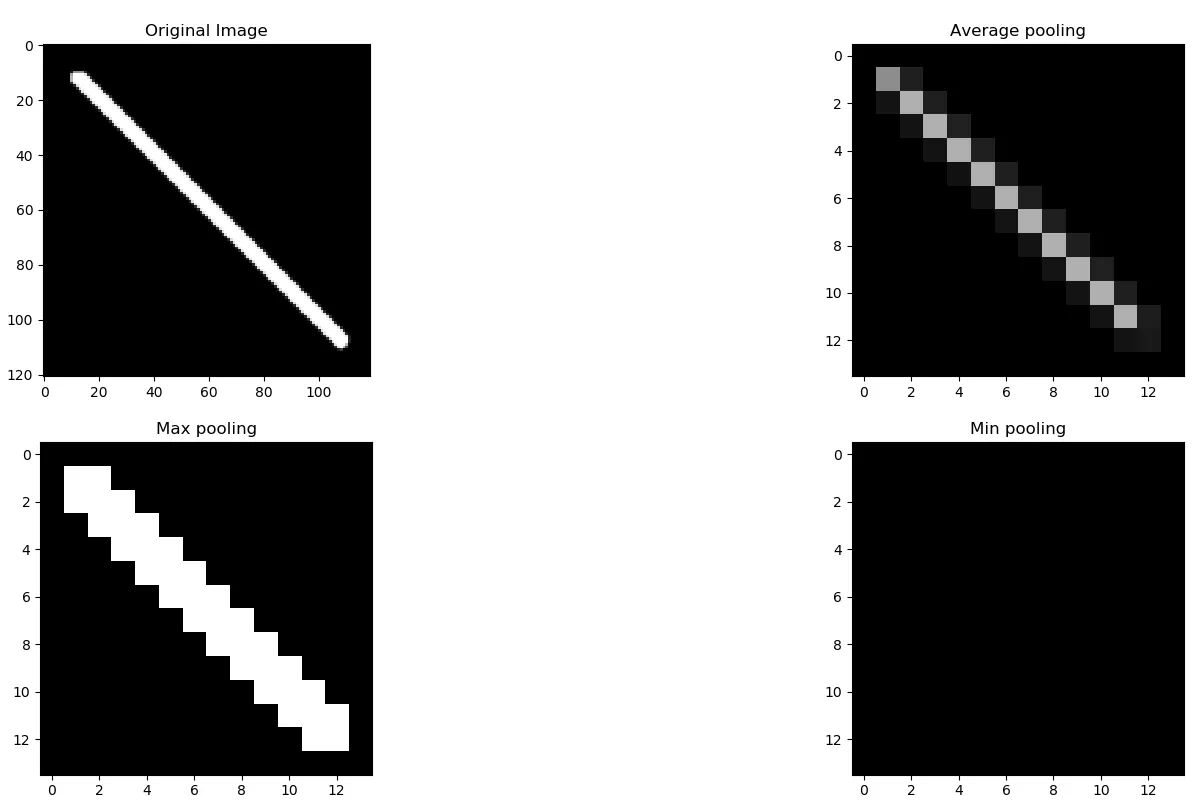
주로 Average Pooling과 Max Pooling으로 나누어져 있는데,
Max Pooling은 해당 사진의 가장 두드러지는 모습을 Average Pooling에 비해 잘 담을 수 있기 때문에, 해당 학습을 진행할 때 MaxPooling을 사용하여, 설계를 진행하였습니다.MaxPooling vs AveragePooling
- MaxPooling은 해당 사진의 가장 두드러지는 특징을 담고 있다. 따라서 Classification 분야에서는 두드러지는 특징을 담아야 하는 경우가 많으므로, 주로 MaxPooling이 사용됩니다.
- AveragePooling은 Classification보다 Object Detection에서 움직임 등을 압축할 때 소실하지 않도록 분산의 개념을 이용하여 사용하는 경우가 많습니다.
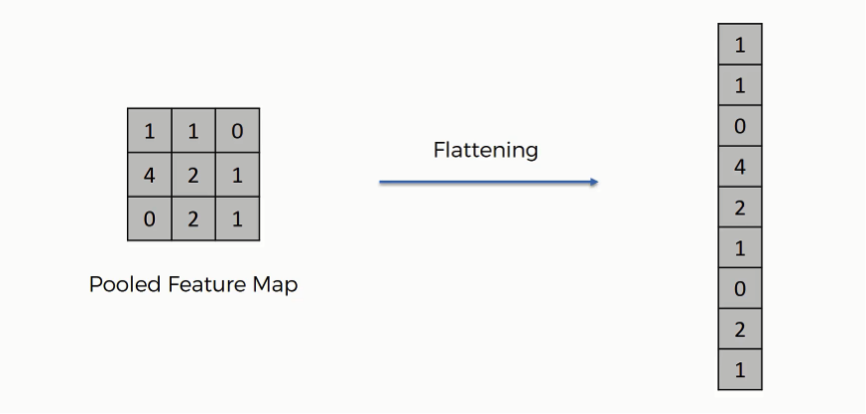
Flatten Layer
합성곱 신경망은 여러 개의 필터를 가지고 있고 합성곱 층의 결과 역시 일반적으로 선형이 아닌 2차원 배열(행렬) 이상의 데이터 형태이므로, 이를 1차원으로 Flatten시켜서 Fully-connected layer로 입력시켜 주는 Layer 입니다.
Classification에서 Convolution Layer를 통해 width와 height를 1로 만드는 경우에는 생략하기도 합니다.
Dense Layer
Fully Connected Layer라고도 불리는 Dense Layer는
와 같이 분류 모델에서 주로 사용하는 Layer로서 이미지 분석의 입력을 취하여 정확한 라벨을 예측하기 위해 가중치를 적용하고, 각 라벨에 대한 최종 확률을 제공하는 Layer이다.
다시말해 앞서 Convolution Layer와 Pooling Layer의 프로세스 결과를
취하여 이미지를 정의된 라벨로 분류하는 Layer이다.
주로 활성화함수(RELU, Tanh 등)으로 뉴런을 활성화 시키고, 결과를 분류기 SoftMax함수를 통해 분류한다.
데이터 셋
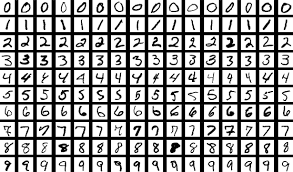
MNIST 손글씨 Data
MNIST 데이터베이스 (Modified National Institute of Standards and Technology database)는 손으로 쓴 숫자들로 이루어진 대형 데이터베이스이며, 다양한 화상 처리 시스템을 트레이닝하기 위해 일반적으로 사용된다.
이 데이터베이스는 기초적인 기계 학습 분야의 트레이닝 및 테스트에 널리 사용된다
6만장의 Train Image와 1만장의 Test Image로 이루어져 있으며, 각각 28x28크기의 gray scale(1차원)이미지 이다.

학습
해당 구조와 일부 LeNet-5 구조를 참고하여 모델을 작성해 보자!라이브러리 선언 (1)
# 라이브러리 선언 import tensorflow as tf import matplotlib.pyplot as plt import os from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D from tensorflow.keras.layers import Flatten, Dense, ZeroPadding2D학습을 Tensorflow Keras 필요한 라이브러리를 호출한다.
Model.add()를 사용하여 모델을 쌓아가는 구조로 시행할 예정이므로
Sequential 역시 호출하여 계층구조를 쌓아가는 구조를 만들 수 있다.모델 선언
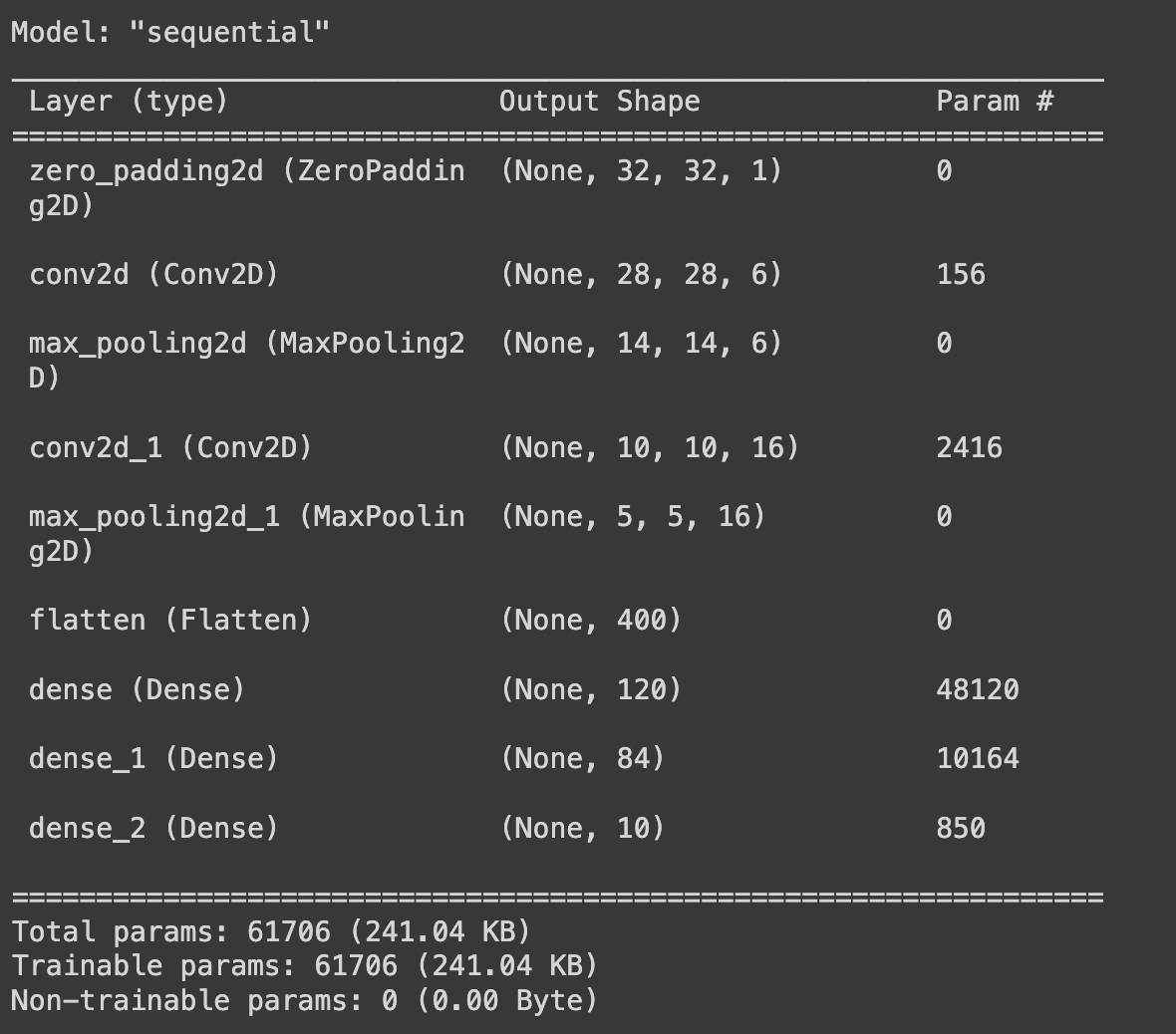
# LeNet 5 모델의 파라미터 일부 사용 (Tensorflow Keras) : Model을 쌓아 가는 구조를 통해 작성:Sequential, add()를 사용해 Layer를 쌓아감 model = Sequential() model.add(ZeroPadding2D(padding=2)) model.add(Conv2D(filters=6, kernel_size=5, padding="valid", strides=1, activation="relu")) model.add(MaxPooling2D(pool_size=2, strides=2)) model.add(Conv2D(filters=16, kernel_size=5, padding="valid", strides=1, activation="relu")) model.add(MaxPooling2D(pool_size=2, strides=2)) model.add(Flatten()) model.add(Dense(units=120, activation="relu")) model.add(Dense(units=84, activation="relu")) model.add(Dense(units=10, activation="softmax")) model.build(input_shape=(None,28,28,1)) model.summary() # 모델의 요약을 볼 수 있음.Keras는
model.summary()를 통해 모델의 전체적인 구조를 요약하여, 파라미터 개수, Feature map의 크기 등을 확인할 수 있음
데이터 셋 호출 및 모델 학습
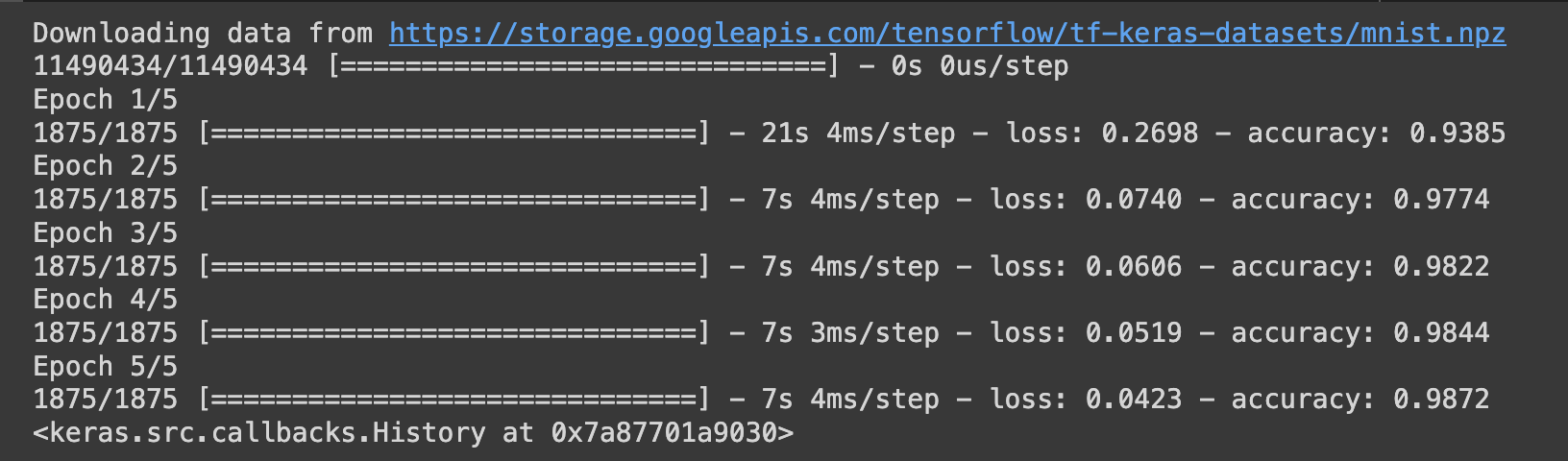
# Test Data set (MNIST의 손글씨 데이터를 불러옴) import tensorflow_datasets as tfds (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() print(x_train.shape) # (28,28)크기의 (60000,28,28) 6만장의 사진을 학습시킴 (정확하게는 model내부에 padding이 되어 (32,32,1)사진 학습을 진행) print(y_train.shape) # 정답은 0~9까지의 숫자 하나기 때문에, 60000,1 크기의 배열 # optimizer=Adam, loss function: sparse_categorical_crossentropy 레이블이 정수형태로 표현되는 경우, 주로 사용함 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) test_loss, test_acc = model.evaluate(x_test, y_test) # Test Data evaluate print(test_acc) # 정확도 출력이미지의 크기는 (28,28) channel은 1으로 gray scale 이미지임을 확인할 수 있고, Train image는 6만장으로 이루어 져 있는 것을 확인할 수 있다.
model.compile()을 통해 학습의 optimizer와 loss function, 오차 행렬의 방식을 지정가능하고,
model.fit()을 통해 에폭을 지정하여 학습을 진행한다. 에폭은 학습의 횟수로 가볍게 시행하기 위해 5회의 epoch설정하였다.
Keras는 history를 통해 학습의 정확성, 진행상태, loss 등을 제공한다.
또한model.evaluate()를 통해 Test Data에 적용하여, Test Data Set에 대한 정확도,loss가 어느정도 나오는 지 확인할 수 있다.
검증
# 필자가 쓴 필체도 확인해 보기 위해 PIL을 통해 이미지 불러오기 위한 라이브러리. from PIL import Image import numpy as np # Colab환경에서 시행하기 때문에 Drive Mount필요 from google.colab import drive drive.mount("/content/drive") # 이미지를 import하고 image = Image.open('/content/drive/MyDrive/project3_num/num10.png') # Keras는 numpy와 연동가능한 장점이 있음 image = np.array(image) # 흑백사진으로 바꿈 (원래 그림판에서 그린 것이기 때문에 3차원임.) # 정확하게는 흑백사진으로 바꾼것은 아니고, 흰색은 (255,255,255), 검정은 (0,0,0)이므로 한 가지 배열만을 가져오면 되기 때문 image=image[:,:,0] plt.imshow(image) # 이미지 확인 print(image.shape)
와 같이 "5"라는 입력을 넣은 것으로 확인하였다. 해당 그림이 제대로 출력이 5가 나오는 지 확인해보고 그 과정을 한번 출력하여 보자.
출력 확인
# 오픈 소스에서 가져온 Keras 모델에서 컨볼루션레이어의 출력 값을 볼 수 있는 함수 def visualize_conv_layer(model, layer_name, test_image): layer_output=model.get_layer(layer_name).output intermediate_model=tf.keras.models.Model(inputs=model.input,outputs=layer_output) intermediate_prediction=intermediate_model.predict(test_image.reshape(1,28,28,1)) print(np.shape(intermediate_prediction)) fig,ax=plt.subplots(1,intermediate_prediction.shape[3],figsize=(32,10)) for i in range(intermediate_prediction.shape[3]): ax[i].imshow(intermediate_prediction[0, :, :, i], cmap='gray') # 오픈소스에서 가져온 Keras 모델에서 Dense 레이어의 출력 값을 볼 수 있는 함수. def visualize_dense_layer(model, layer_name, test_image): layer_output=model.get_layer(layer_name).output intermediate_model=tf.keras.models.Model(inputs=model.input,outputs=layer_output) intermediate_prediction=intermediate_model.predict(test_image.reshape(1,28,28,1)) print(np.shape(intermediate_prediction)) fig,ax=plt.subplots(figsize=(50,10)) ax.imshow(intermediate_prediction, cmap='gray')Convolution Layer 1
# 0는 Zeropadding만 한 상태기 때문에, (28,28,1)-> (32,32,1) # Convolution Layer 첫번째 conv_1의 출력 이미지를 출력 model.layers[1]._name='conv_1' print(model.layers[1].name) visualize_conv_layer(model, 'conv_1', image)
이와 같이 첫 번째 Convolution Layer를 통과한 사진은 Feature map 정도는 기존의 형태를 어느정도 갖고 있으며, 설정한 필터의 개수 6개로 channel이 6개임을 확인할 수 있고, 모델요약에서 서술되었듯이 (32,32)의 사진이 (28,28)크기의 Feature map을 띄게 되었다.
MaxPooling Layer 2
# Convolution Layer conv_2의 출력 이미지를 출력 model.layers[2]._name='conv_2' print(model.layers[2].name) visualize_conv_layer(model, 'conv_2', image)
위에서 나온 Feature map을 Maxpooling한 결과를 갖고 있다. 가로 세로는 (28,28)에서 (14,14)로 절반 줄어들었고, 이에 따라 픽셀의 Max값만 기록됨으로써 앞서 나온 Feature map의 특징이 두드러지게 표현되었다.
Convolution Layer 3
# Convolution Layer conv_3의 출력 이미지를 출력 model.layers[3]._name='conv_3' print(model.layers[3].name) visualize_conv_layer(model, 'conv_3', image)
Feature map의 형태가 앞서 나온 형태에 비해 알아보기 매우 힘든 형태로 변화됨. 가로세로는 (10,10)으로 줄어들었고, channel은 16개로 늘어났다.
MaxPooling Layer 4
# Convolution Layer conv_4의 출력 이미지를 출력 model.layers[4]._name='conv_4' print(model.layers[4].name) visualize_conv_layer(model, 'conv_4', image)
앞의 나온 Feature map을 Maxpooling한 형태로 가로세로는 (10,10)에서 (5,5)로 줄어들었고 channel은 16을 유지하고 있다.
Flatten Layer 5
# Dense Layer 출력 (Flatten) 이미지를 출력 model.layers[5]._name='Flatten' print(model.layers[5].name) visualize_dense_layer(model, 'Flatten', image)
잘 보이지 않을 수 있으나 앞서 나온 Feature map을 일차원 배열로 쭉 펴놓은 상태로, (5,5)크기의 Feature map 16channel이기 때문에, 5x5x16=400으로 400크기의 일차원배열이 형성된다.
Dense Layer 6
# Dense Layer 출력 (activation=relu인 Layer 1번째) 이미지를 출력 model.layers[6]._name='Dense_1' print(model.layers[6].name) visualize_dense_layer(model, 'Dense_1', image)
Dense Layer 첫 번째로 RELU함수를 통해 뉴런을 활성화 시켜 Fully Connected된 Feature map이다.
120개의 Unit으로 설정하였기 때문에, 출력 배열의 크기도 120인 것을 확인할 수 있다. 파라미터의 수를 최대한 LeNet-5와 비슷한 파라미터를 사용하기 위해 해당 레이어를 독자적으로 추가하였다.Dense Layer 7
# Dense Layer 출력 (activation=relu인 Layer 2번째) 이미지를 출력 model.layers[7]._name='Dense_2' print(model.layers[7].name) visualize_dense_layer(model, 'Dense_2', image)Dense Layer 두 번째로 해당 레이어 역시 RELU함수를 통해 뉴런을 활성화시켜 Fully Connected하는 레이어 이다.
입력 유닛은 120으로 출력은 84개의 유닛을 반환하는 Layer로서 기본적으로 84개의 출력을 설정한 이유는 7x12의 비트맵을 가지는 아래의 ASCII set의 해석을 용이하게 하기 위해 설정하였다고 알려져 있다.
Dense Layer 8 (OUTPUT)
# Dense Layer 출력 (activation=Softmax Layer) 값을 출력 -> 정답 출력 model.layers[8]._name='Softmax_1' print(model.layers[8].name) visualize_dense_layer(model, 'Softmax_1', image)
해당 레이어는 Softmax 분류기를 통해 이미지를 Classification한 배열의 확률을 시각화한 것으로써 사진을 보게 되면 5에 하얀색으로 표현되는 것을 볼 수 있다.
이는 정답을 바로 언급하는 것이 아닌 각각의 확률을 표현하는 것으로 만약 애매한 결과를 가지고 있다면, 회색과 같은 색상이 나타나기도 한다.출력 결과
#테스트 이미지를 reshape하고 모델에 넣어 예측. x_test=image.reshape((-1,28,28,1)) predict_x=model.predict(x_test) # 정답은 배열의 최댓값으로 출력 res=np.argmax(predict_x,axis=1) print(res)
Test이미지를 모델에 넣어 model.predict()를 통해 정답을 예측하는 과정이다.
해당 predict_x에서 나온 출력 배열의 최댓값의 index를 반환하는 형식으로 정답을 유추하고 있으며, 해당 결과 역시 "5"라는 값을 정상적으로 반환하고 있다.


전체 코드
# 라이브러리 선언 import tensorflow as tf import matplotlib.pyplot as plt import os from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D from tensorflow.keras.layers import Flatten, Dense, ZeroPadding2D # LeNet 5 모델 사용 (Tensorflow Keras) : Model을 쌓아 가는 구조를 통해 작성, add()를 사용해 Layer를 쌓아감 model = Sequential() model.add(ZeroPadding2D(padding=2)) model.add(Conv2D(filters=6, kernel_size=5, padding="valid", strides=1, activation="relu")) model.add(MaxPooling2D(pool_size=2, strides=2)) model.add(Conv2D(filters=16, kernel_size=5, padding="valid", strides=1, activation="relu")) model.add(MaxPooling2D(pool_size=2, strides=2)) model.add(Flatten()) model.add(Dense(units=120, activation="relu")) model.add(Dense(units=84, activation="relu")) model.add(Dense(units=10, activation="softmax")) model.build(input_shape=(None,28,28,1)) model.summary() # Test Data set (MNIST의 손글씨 데이터를 불러옴) import tensorflow_datasets as tfds (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() # optimizer=Adam, loss function: sparse_categorical_crossentropy 레이블이 정수형태로 표현되는 경우, 주로 사용함 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) print(x_train.shape) # (28,28)크기의 (60000,28,28) 6만장의 사진을 학습시킴 (정확하게는 model내부에 padding이 되어 (32,32,1)사진 학습을 진행) print(y_train.shape) # 정답은 0~9까지의 숫자 하나기 때문에, 60000,1 크기의 배열 test_loss, test_acc = model.evaluate(x_test, y_test) # Test Data evaluate print(test_acc) # 정확도 출력 # 필자가 쓴 필체도 확인해 보기 위해 PIL을 통해 이미지 불러오기 위한 라이브러리. from PIL import Image import numpy as np # Colab환경에서 시행하기 때문에 Drive Mount필요 from google.colab import drive drive.mount("/content/drive") # 이미지를 import하고 image = Image.open('/content/drive/MyDrive/project3_num/num10.png') # Keras는 numpy와 연동가능한 장점이 있음 image = np.array(image) # 흑백사진으로 바꿈 (원래 그림판에서 그린 것이기 때문에 3차원임.) # 정확하게는 흑백사진으로 바꾼것은 아니고, 흰색은 (255,255,255), 검정은 (0,0,0)이므로 한 가지 배열만을 가져오면 되기 때문 image=image[:,:,0] plt.imshow(image) # 이미지 확인 print(image.shape) # 오픈 소스에서 가져온 Keras 모델에서 컨볼루션레이어의 출력 값을 볼 수 있는 함수 def visualize_conv_layer(model, layer_name, test_image): layer_output=model.get_layer(layer_name).output intermediate_model=tf.keras.models.Model(inputs=model.input,outputs=layer_output) intermediate_prediction=intermediate_model.predict(test_image.reshape(1,28,28,1)) print(np.shape(intermediate_prediction)) fig,ax=plt.subplots(1,intermediate_prediction.shape[3],figsize=(32,10)) for i in range(intermediate_prediction.shape[3]): ax[i].imshow(intermediate_prediction[0, :, :, i], cmap='gray') # 오픈소스에서 가져온 Keras 모델에서 Dense 레이어의 출력 값을 볼 수 있는 함수. def visualize_dense_layer(model, layer_name, test_image): layer_output=model.get_layer(layer_name).output intermediate_model=tf.keras.models.Model(inputs=model.input,outputs=layer_output) intermediate_prediction=intermediate_model.predict(test_image.reshape(1,28,28,1)) print(np.shape(intermediate_prediction)) fig,ax=plt.subplots(figsize=(50,10)) ax.imshow(intermediate_prediction, cmap='gray') # 0는 Zeropadding만 한 상태기 때문에, (28,28,1)-> (32,32,1) # Convolution Layer 첫번째 conv_1의 출력 이미지를 출력 model.layers[1]._name='conv_1' print(model.layers[1].name) visualize_conv_layer(model, 'conv_1', image) # Convolution Layer conv_2의 출력 이미지를 출력 model.layers[2]._name='conv_2' print(model.layers[2].name) visualize_conv_layer(model, 'conv_2', image) # Convolution Layer conv_3의 출력 이미지를 출력 model.layers[3]._name='conv_3' print(model.layers[3].name) visualize_conv_layer(model, 'conv_3', image) # Convolution Layer conv_4의 출력 이미지를 출력 model.layers[4]._name='conv_4' print(model.layers[4].name) visualize_conv_layer(model, 'conv_4', image) # Dense Layer 출력 (Flatten) 이미지를 출력 model.layers[5]._name='Flatten' print(model.layers[5].name) visualize_dense_layer(model, 'Flatten', image) # Dense Layer 출력 (activation=relu인 Layer 1번째) 이미지를 출력 model.layers[6]._name='Dense_1' print(model.layers[6].name) visualize_dense_layer(model, 'Dense_1', image) # Dense Layer 출력 (activation=relu인 Layer 2번째) 이미지를 출력 model.layers[7]._name='Dense_2' print(model.layers[7].name) visualize_dense_layer(model, 'Dense_2', image) # Dense Layer 출력 (activation=Softmax Layer) 값을 출력 -> 정답 출력 model.layers[8]._name='Softmax_1' print(model.layers[8].name) visualize_dense_layer(model, 'Softmax_1', image) #테스트 이미지를 reshape하고 모델에 넣어 예측. x_test=image.reshape((-1,28,28,1)) predict_x=model.predict(x_test) # 정답은 배열의 최댓값으로 출력 res=np.argmax(predict_x,axis=1) print(res)
