
히스토그램 스케일링 및 슬라이딩 수행하기
히스토그램 스케일링과 슬라이딩을 수행한다.
해결 과정 및 주요 코드에 대한 설명
def scaleHistogram(img, scaling_range):
hist = []
if (len(img.shape) == 2):
img = cv2.normalize(img, img, scaling_range[0], scaling_range[1], cv2.NORM_MINMAX)
temp = cv2.calcHist([img], [0], None, [256], [0, 256])
hist.append(temp)
else:
img = cv2.normalize(img, img, scaling_range[0], scaling_range[1], cv2.NORM_MINMAX)
for i in range(3):
temp = cv2.calcHist([img], [2-i], None, [256], [0, 256])
hist.append(temp)
return hist히스토그램 스케일링과 관련된 함수이다. 컬러 영상과 그레이스케일 영상을 모두 지원하기 위해 if문을 사용해 다르게 구현하였다. cv2.normalize 함수를 사용해 구현하였고, cv2.NORM_MINMAX 방법을 채택했다. 이후 cv2l.calcHist를 사용하여 히스토그램을 계산해낼 수 있도록 하였다.
def slideHistogram(img, slide):
hist = []
if (len(img.shape) == 2):
for x in range(0, img.shape[0]):
for y in range(0, img.shape[1]):
img[x, y] = img[x, y] + slide
if (img[x, y] > 255):
img[x, y] = 255
if (img[x, y] < 0):
img[x, y] = 0
temp = cv2.calcHist([img], [0], None, [256], [0, 256])
hist.append(temp)
else:
for i in range(3):
for x in range(0, img.shape[0]):
for y in range(0, img.shape[1]):
img[x, y, 2-i] = img[x, y, 2-i] + slide
if (img[x, y, 2-i] > 255):
img[x, y, 2-i] = 255
if (img[x, y, 2-i] < 0):
img[x, y, 2-i] = 0
temp = cv2.calcHist([img], [2-i], None, [256], [0, 256])
hist.append(temp)
return hist히스토그램 슬라이딩과 관련된 함수이다. 컬러 영상과 그레이스케일 영상을 모두 지원하기 위해 if문을 사용해 다르게 구현하였다. cv2에서 제공하는 함수를 사용하지 않고, 간단히 +연산을 통해 offset만큼 값을 증가 또는 감소시킬 수 있도록 하였다. 그리고, 0~255 범위를 넘어가는 픽셀값에 대해선 그에 맞게 적절히 코드상으로 처리해주었다.
ap = argparse.ArgumentParser()
ap.add_argument('-i', '--image', required=True, \
help = 'Path to the input image')
ap.add_argument('-t', '--histogram_type', \
type = int, default = 3, \
help = 'historgram type(1: grayscale, 3: color')
ap.add_argument('-r', '--range', type = int, \
nargs='+', default = [50, 150], \
help = "Range of the Scaling")
ap.add_argument('-s', '--slide', type = int, \
default = 50, help = "Default of the Sliding")
args = vars(ap.parse_args())
filename = args['image']
histogram_type = args['histogram_type']
scaling_range = args['range']
slide = args['slide']i로 이미지의 경로를 입력받는다. t로 받아온 값을 통해 컬러 영상, 그레이스케일 영상에 대해 다르게 영상처리를 진행한다. r에서는 스케일링 범위를 받아오고, s를 통해서는 슬라이딩에 필요한 offset 값을 받아온다. 받아온 값은 각각 filename, histogram_type, scaling_range, slide 변수에 저장한다.
실행 결과
-
python scale_slide_histogram.py —image ../imagess/pumpkin_dim.jpg 으로 명령을 주었을 경우
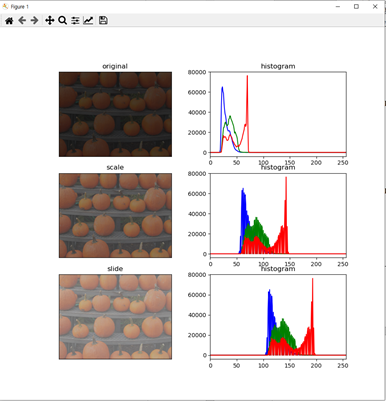
-
python scale_slide_histogram.py —image ../imagess/pumpkin_dim.jpg —range 0 255 —slide 10 으로 명령을 주었을 경우
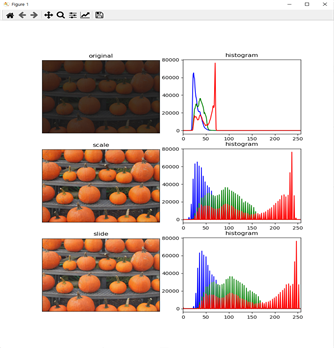
-
python scale_slide_histogram.py —image ../imagess/pumpkin_dim.jpg –t 1 으로 명령을 주었을 경우
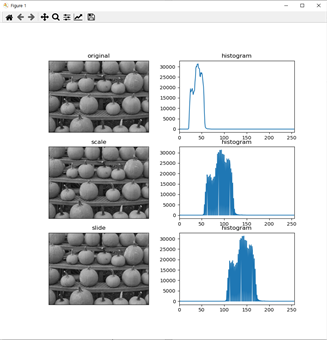
코드
자세한 코드는 Github에서 확인할 수 있다.
히스토그램 기반의 영상 검색 수행
구글을 사용하여 영상 데이터베이스를 구축하여 히스토그램 기반의 영상 검색을 수행한다.
해결 과정 및 주요 코드에 대한 설명
def calc_similarity(index):
similarity = {}
keylist = list(index.keys())
valuelist = list(index.values())
for i in range(0, 18):
his = cv2.compareHist(histq, valuelist[i], cv2.HISTCMP_INTERSECT)
similarity[keylist[i]] = his
result = []
result = sorted(similarity, key=lambda k: similarity[k], reverse=True)
return result딕셔너리 형태의 index를 리스트로 바꿔 for 문을 사용하기 용이하게 한다. 이를 위해 keylist와 valuelist 변수를 만들어 keys(), values()를 통해 리스트를 만든다. dataset을 18개로 만들었기 때문에 18번동안 for문을 돌리면서 compareHist를 사용해 히스토그램을 비교한다. 이후 가장 유사한 영상 6개만 출력하기 위해 sorted를 사용하여 정렬을 한다.
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory that contains the images we just indexed")
ap.add_argument("-i", "--index", required = True,
help = "Path to where we stored our index")
ap.add_argument("-q", "--query", required = True,
help = "Path to query image")
args = vars(ap.parse_args())d를 통해 데이터셋을 불러오고, I를 사용하여 index.idx 파일을 불러들여온다. 이후 –q를 사용하여 쿼리 영상의 경로를 읽어와 이를 코드에 적용시킨다.
실행 결과
-
python cbir_search.py —dataset ./dataset —index ./index/index.idx —query ./queries/dog10.jpg 으로 명령을 주었을 경우
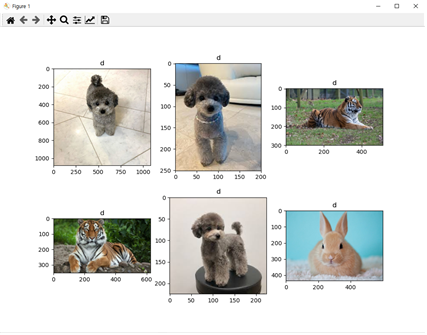
-
python cbir_search.py —dataset ./dataset —index ./index/index.idx —query ./queries/tiger10.jpg 으로 명령을 주었을 경우
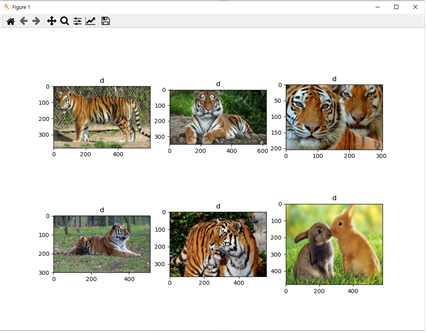
-
python cbir_search.py —dataset ./dataset —index ./index/index.idx —query ./queries/rabbit10.jpg 으로 명령을 주었을 경우
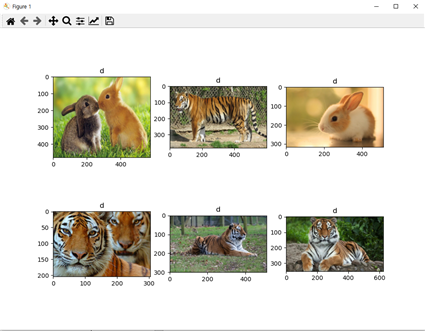
코드
자세한 코드는 Github에서 확인할 수 있다.
