python multiprocessing(2)- multiprocessing 을 이용한 원주율 추정
1. 몬테카를로 방식의 원주율의 추정
-
몬테카를로 방식은 반복된 무작위 추출을 이용하여 함수의 값을 확률적으로 계산하는 방식의 알고리즘을 말한다. 이 방식을 통해 아래와 같이 원주율을 추정할 수 있다.

-
0부터 1사이의 random한 x,y값을 n번 구했을 때에 이 x,y가 위 그림의 원 내부에 있는 경우가 m 번이었다고 가정해보자. n이 매우 큰 숫자가 된다면, 사각형 넓이 1중에서 1/4짜리 원이 차지 하는 비율은 m/n라고 할 수 있을 것이다.
-
위 과정을 통해 1/4짜리 원의 넓이를 구하고, 1/4 원의 넓이 = 1/4 * pie * r^2의 식(원의 넓이는 pie*r^2)을 통해 원주율 pie 를 추정할 수 있다.
-
위의 과정에서 시간이 가장 오래 걸리는 작업은 무수히 많은 random x, y 의 값을 생성하는 과정일 것이다. 이 과정을 multiprocessing 을 통해 가속화 해보자.
2. python multiprocessing module 활용
- multiprocess로 돌릴 대상 함수(estimate_nbr_points_in_quarter_circle)
import os
import time
import random
def estimate_nbr_points_in_quarter_circle(nbr_estimates):
"""순수 파이썬을 사용해 단위 4분원 안에 들어간 점 개수를 세는 몬테 카를로 추정"""
print(f"""Executing estimate_nbr_points_in_quarter_circle
with {nbr_estimates:,} on pid {os.getpid()}\n""")
nbr_trials_in_quarter_unit_circle=0
for step in range(int(nbr_estimates)):
x=random.uniform(0,1)
y=random.uniform(0,1)
is_in_unit_circle=x*x+y*y<=1.0
nbr_trials_in_quarter_unit_circle+=is_in_unit_circle
return nbr_trials_in_quarter_unit_circle- main 함수
from multiprocessing import Pool
nbr_samples_in_total=1e8
nbr_parallel_blocks=6
pool=Pool(processes=nbr_parallel_blocks)#pool 에 작업자 수 명시
nbr_samples_per_worker=nbr_samples_in_total/nbr_parallel_blocks
print("Making {:,} samples per {} worker".format(nbr_samples_per_worker,
nbr_parallel_blocks))
nbr_trials_per_process=[nbr_samples_per_worker]*nbr_parallel_blocks # 각 작업자가 할 작업의 수를 list로
t1=time.time()
nbr_in_quarter_unit_circles=pool.map(estimate_nbr_points_in_quarter_circle, # multi로 실행할 함수
nbr_trials_per_process) # 각 작업자들이 가져갈 process 갯수 표시
t2=time.time()- output
Executing estimate_nbr_points_in_quarter_circle
with 16,666,666.666666666 on pid 3235
Executing estimate_nbr_points_in_quarter_circle
with 16,666,666.666666666 on pid 3238
Executing estimate_nbr_points_in_quarter_circle
with 16,666,666.666666666 on pid 3236
Executing estimate_nbr_points_in_quarter_circle
with 16,666,666.666666666 on pid 3237
Executing estimate_nbr_points_in_quarter_circle
with 16,666,666.666666666 on pid 3239
Executing estimate_nbr_points_in_quarter_circle
with 16,666,666.666666666 on pid 3240
Making 16,666,666.666666666 samples per 6 worker- 위의 결과로 원주율(pie) 추정
print(nbr_in_quarter_unit_circles)
pi_estimate=sum(nbr_in_quarter_unit_circles)*4/float(nbr_samples_in_total)
print("Estimated pi", pi_estimate)
print("Delta:", t2-t1)- output
[13088998, 13090624, 13088555, 13091653, 13093314, 13089257]
Estimated pi 3.14169604
Delta: 11.011059045791626시간에 따른 cpu 사용율을 확인해보자
- 물리코어 4개, 각 코어에 대응하는 hyper thread 가 4개인 경우 코어 수와 process 수를 변화시키면서 시간에 따른 cpu 사용율을 확인해보자.
(하이퍼쓰레드는 유휴상태인 물리코어에서 실행된다.)
1. 풀에 프로세스가 하나인 경우
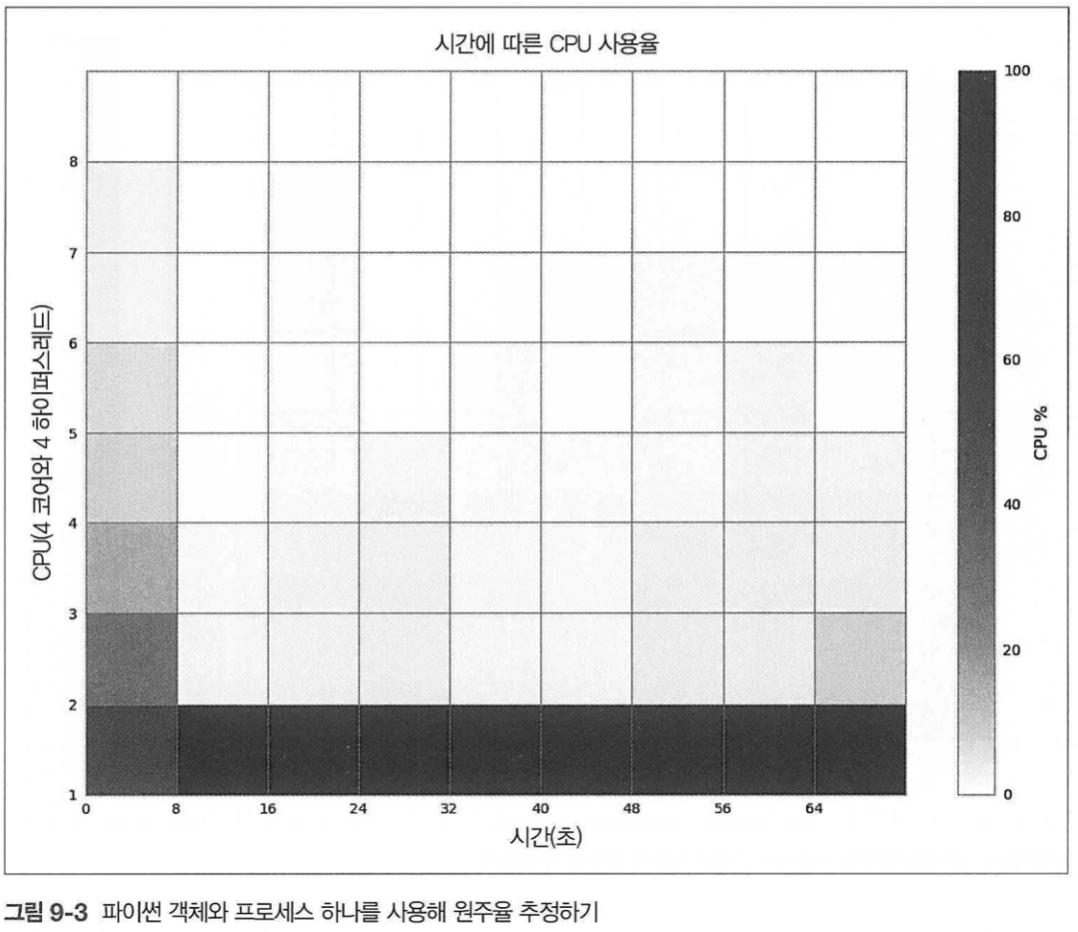
- 풀을 생성할 때 처음 몇초간 오버헤드가 있고 그 후 프로그램이 실행되는 동안 거의 100%에 가까운 cpu 사용률을 보인다.
- 프로세스 하나로 코어 하나를 100% 사용
2. 풀에 프로세스가 두개인 경우
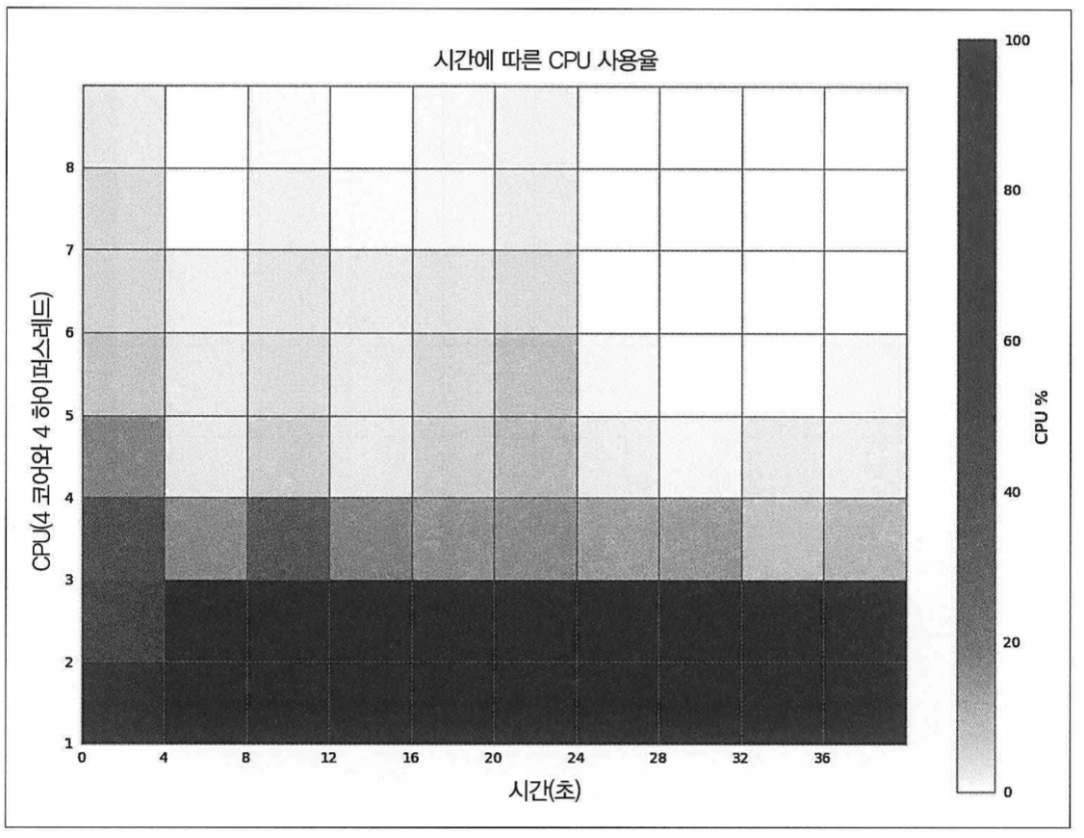
- 실행시간이 37초로, 1번에 비해서 실행시간이 거의 절반만큼 걸림.
- 두 cpu를 완전히 사용했다.
- 통신 등 다른 프로세스와의 경쟁 등이 없는 상태라서 새로운 계산자원을 거의 다 효율적으로 사용한 것
3. 풀에 프로세스가 4개인 경우
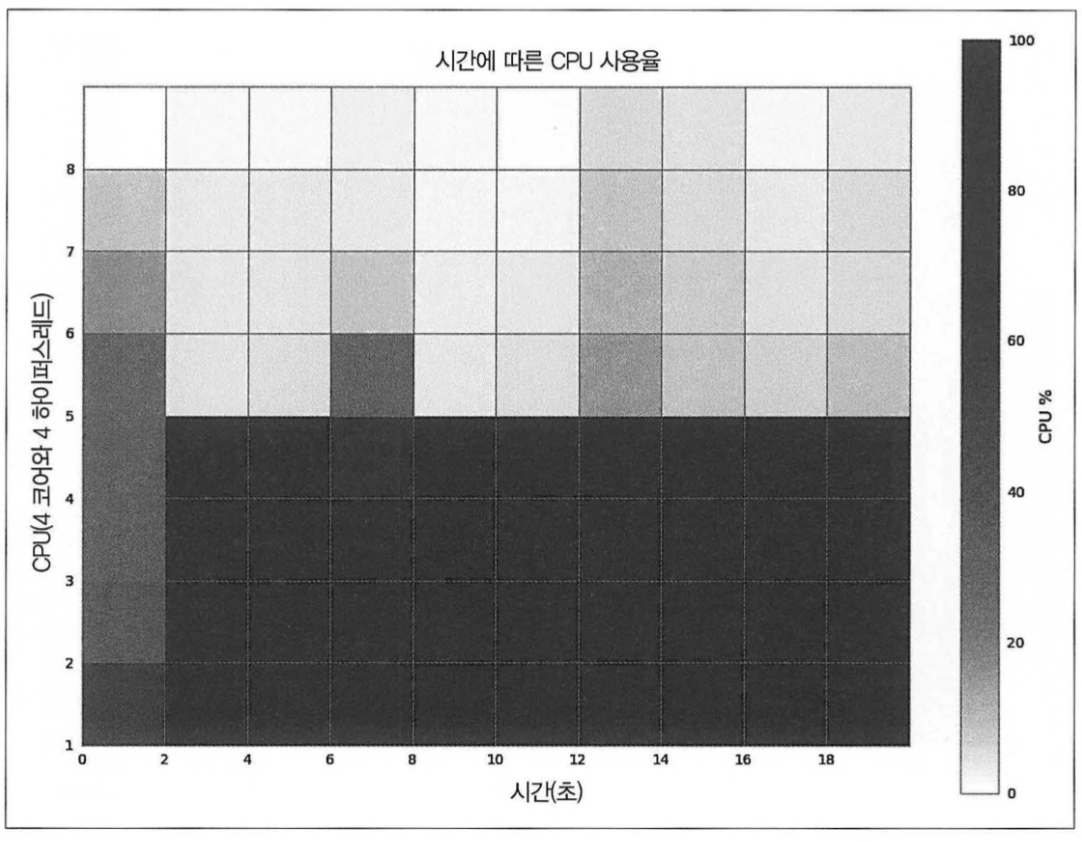
- 단일 프로세스버전의 약 1/4 의 실행시간
4. 풀에 프로세스가 8개인 경우
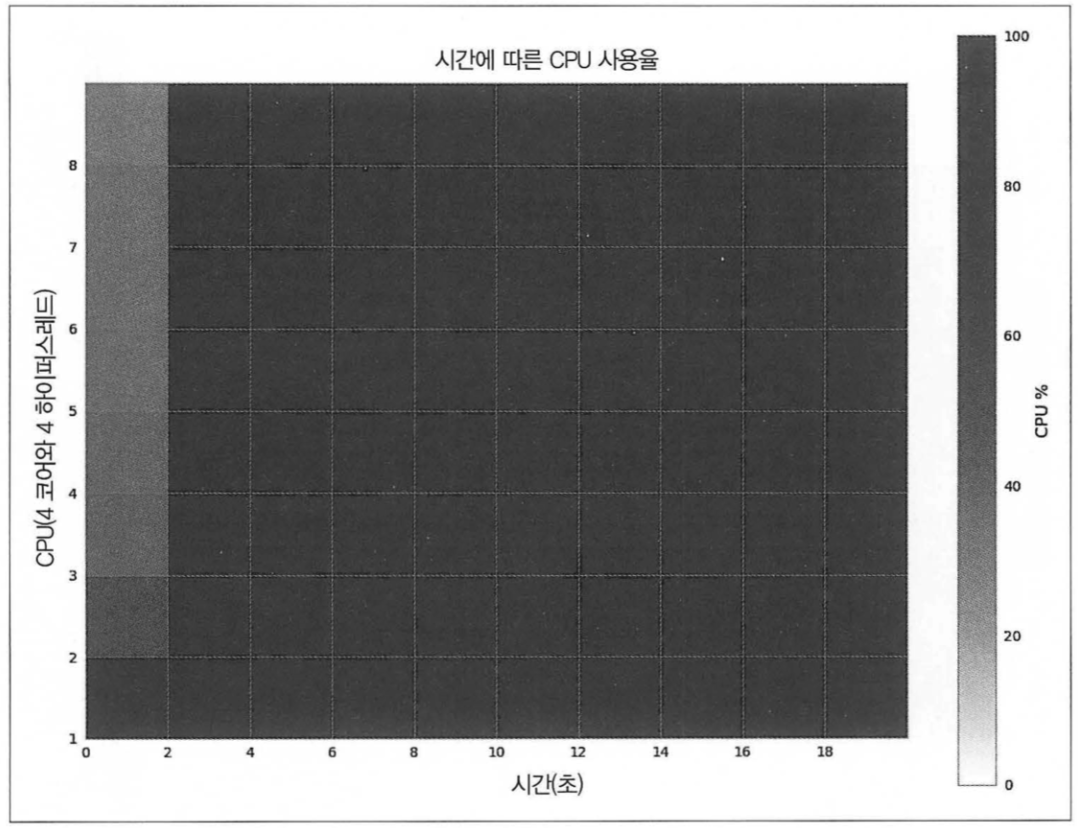
- 4개 썼을때 보다 미미하게 속도가 빨라졌다.
- 이미 물리코어 4개를 최대한 활용하기 때문에 하이퍼쓰레드 4개가 유휴 코어에서 뽑아낼 수 있는 계산 능력이 아주 조금 뿐이기 때문이다.
5. 프로세스 대신 쓰레드를 이용한 경우
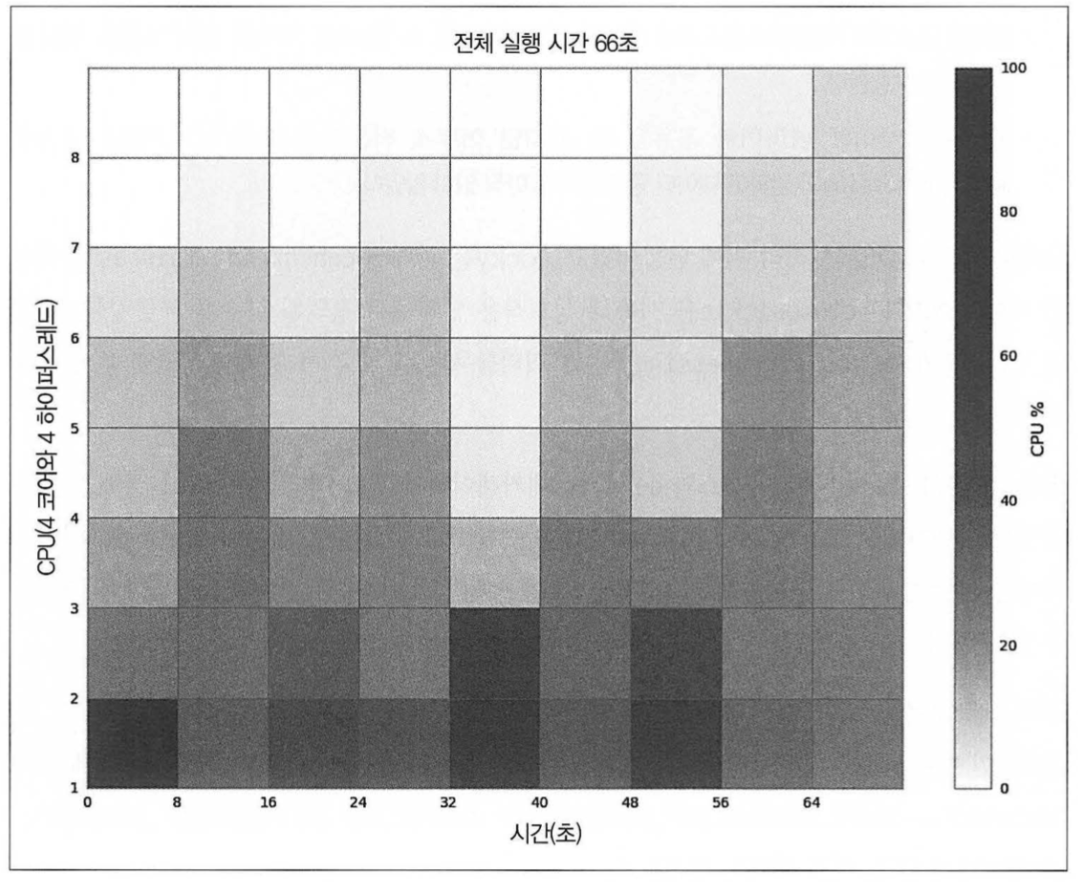
- 여러 cpu 를 사용하지만 각 cpu 가 부하를 조금씩만 나눠받게 된다 (1~4에서처럼 100% 사용하지는 못한다)
- GIL(Global Interpreter Lock) 없이 실행한다면 네개의 cpu 에서 100%의 사용률을 보일테지만, 실제로는(GIL이 있으니) 그렇지 못하다 -> 즉 python 에서는 GIL 탓에 일반적인 경우, 여러 쓰레드를 사용하더라도 성능 향상의 효과를 볼 수 없다.

data scientist