1. Shapely value란
- 아마도 shap 이라는 말의 시초가 되었을 shapely value 라는 값은 Shapely value 는 모델이 결과를 리턴하기까지 각각의 feature 가 끼친 기여도를 말한다.
e.g.
- 조건의 따른 아파트 가격을 구하는 모델을 생각해보자,
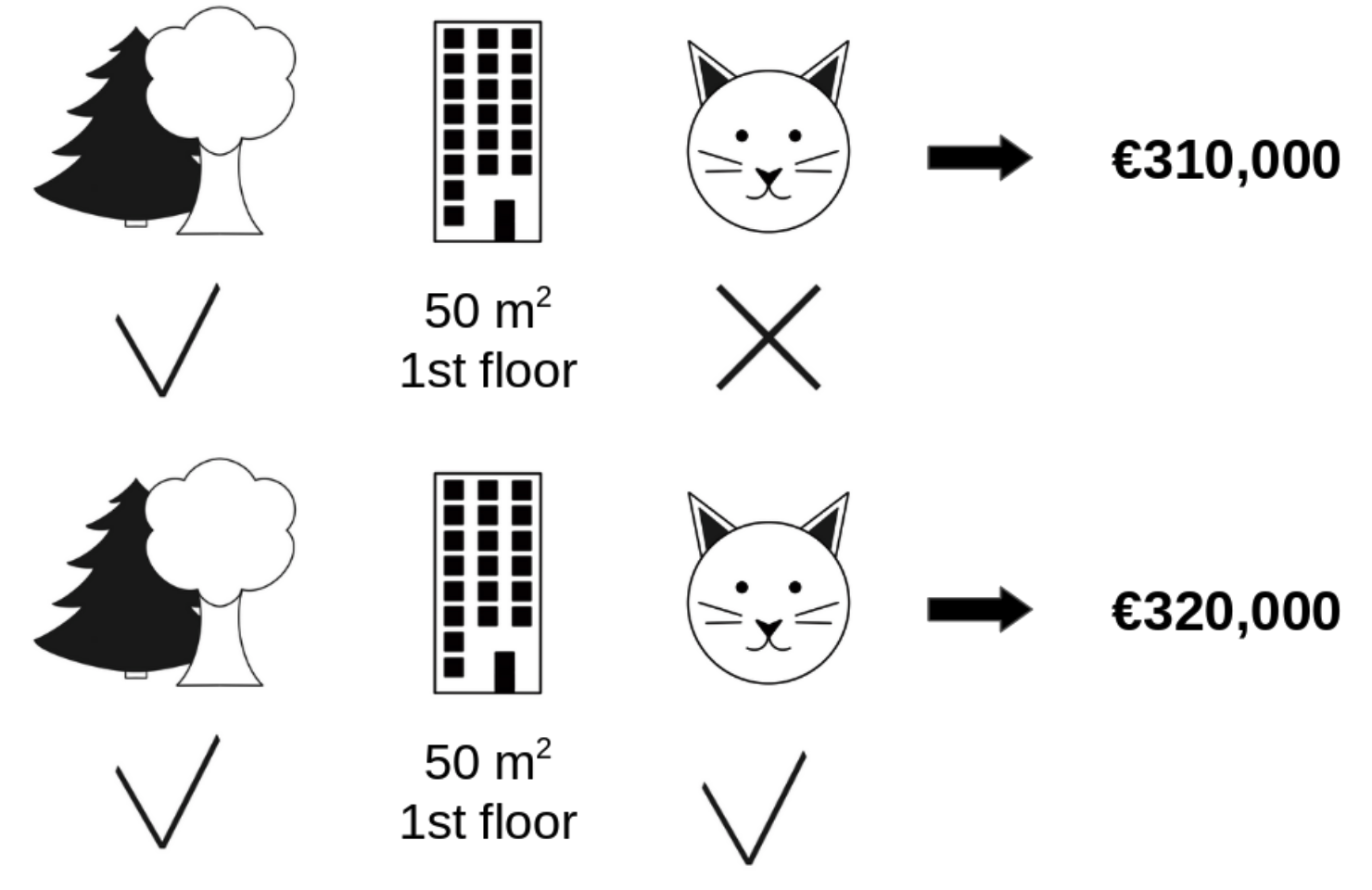
- 아파트 가격에 대한 네개의 조건이 있다. (공원근접여부), (층수), (크기), (고양이 키우기 가능여부)
- (공원근접), (층수1층), (크기50m^2)의 조건이 동일한 여러 아파트에 대해서 무작위로 여러 가격 예측값을 구해보면 (고양이 키우기 허용)의 기여도를 알 수 있게 될 것이다. (공원근접), (층수1층), (크기50m^2)의 조건이 동일한 경우 고양이가 금지된 아파트의 예측 가격이 310k 유로고, 고양이 키우는게 허용된 아파트는 320k 유로였다고 가정해보자.
- 이 경우 (고양이 키우기를 허용)라는 조건만 달라졌는데, 아파트 가격이 10k유로만큼 달라졌다고 볼 수 있을 것이다.
조합에 대한 고려
- 위에서 구한 예시는 나머지 feature 가 (공원근접), (층수1층), (크기50m^2)로 고정된 경우에 대한 (고양이 키우기 허용) feature 의 기여도이다.
- 이번엔 (공원근접x),(층수2층)를 조건으로 로 두고, 무작위로 여러 아파트들의 예측값을 확인해서 (고양이 키우기 허용)의 기여도를 살펴보자. 이때엔 고양이 키우기 조건이 달라져도 예측값이 동일하게 310k 였다고 가정해보자. (공원근접x),(층수2층)라는 feature 조합에, (고양이 키우기 허용)라는 조건은 영향은 미치지 않는다는걸 알 수 있다.
- shapely value 는 위에서와 같이 모든 가능한 조합들에 대해서 해당 feature 가 어떤 영향을 끼칠 수 있는지를 계산하고, 평균 낸 값이다. 즉, (고양이 키우기 허용) feature 의 shapely value 를 구하기 위해서는 가능한 다른 feature 들의 모든 조합을 고려해야하는 것이다.
2. Shapley value 구하기
모든 feature 조합에 대한 기여도 합산으로 shapely value 구하기
- 위의 예시에서 보았듯이, shapely value 는 위에서와 같이 모든 가능한 조합들에 대해서 해당 feature 가 어떤 영향을 끼칠 수 있는지를 계산하고, 평균 낸 값이다.
- 그렇기때문에 feature 의 수가 증가할수록, 해야할 연산의 수는 지수적으로 증가한다.
- 연산 시간을 조절하기 위해서는 가능한 feature 조합 중 몇개의 sample만 이용하는것이 해결책이 될 수 있다.
- 아래의 그림은 (고양이 허용)의 shapely value를 구하기 위해 계산해야하는 모든 feature 들의 조합들이다.)
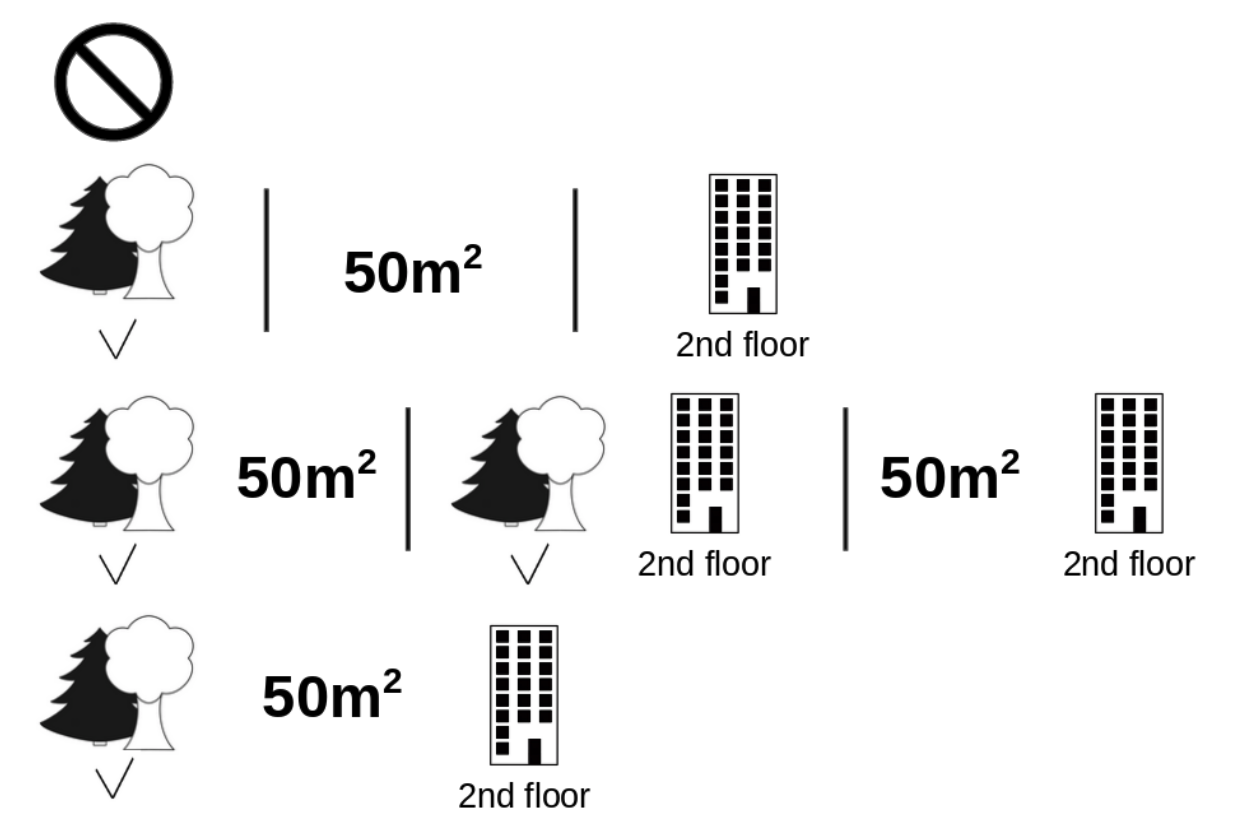
- 어떤 조건도 주지 않았을때
- (공원근접)
- (크기50m^2)
- (층수2층)
- (공원근접) && (크기50m^2)
- (공원근접) && (층수2층)
- (크기50m^2) && (층수2층)
- (공원근접) && (크기50m^2) && (층수2층) - 위의 조건들 각각에 대해 (고양이 키우기 허용)feature 가 끼치는 영향을 평균 낸 값이 우리가 구하고자 하는 shapley value 이다.
- 위 그림을 보면 decision tree를 쉽게 떠올릴 수 있는데, 이런 이유로 shapley value는 tree 기반 모델에서 최초로 제안됐다.
Approximation 으로 shapley value 구하기
- j번째 feature 에 대한 shapely value 는 데이터 셋에 대한 평균 예측 값과 비교하여, 이 feature가 추가되었을때에 관측치가 어떻게 달라지는지를 비교하여 기여도를 측정하게 된다. 그 구체화된 과정은 아래와 같다.

- 위와 같은 과정으로 approximation 된 shapely value 값을 얻을 수 있다. 요약하자면, 기여도를 구하고자하는 instance x (0부터 p까지의 feature 가 존재하는 데이터 element 하나) 기여도를 구하고 싶은 feature j(0부터 p까지의 feature중 하나) 가 있을때에, 여러 특성들의 랜덤한 조합 z를 구하고, 이 특성들과 함께 x에서의 feature j를 포함하여 계산한 예측값과, x에서의 feature j를 포함하지 않은채로 계산한 예측값의 차를 계산하는 과정을 M번 반복, 평균 내는 것이다.
3. Shapley value 로 모델 해석
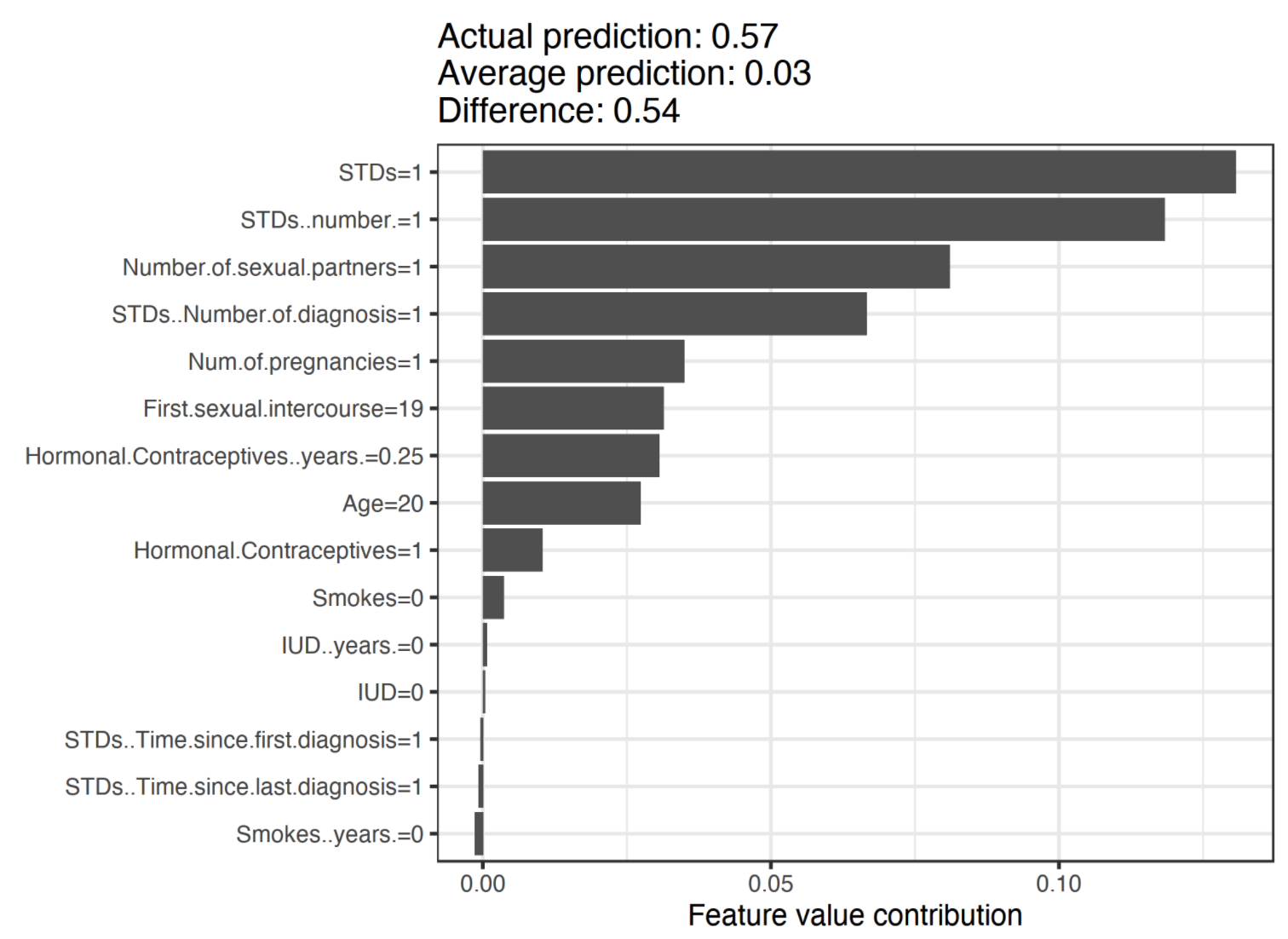
- 위의 그래프는 random forest 로 자궁 경부암 예측 모델을 만들었을때의 해석 결과다.
- 해당 여성의 데이터는 평균적인 예측 score 0.03보다 0.54 높은 0.57의 값을 보였고, 여러 feature 중 STDs라는 feature의 값이 1인 것이 이 예측에 가장 큰 기여를 했음을 알 수 있다.
shapley value 의 범위?
- 각 feature 의 shapley value 의 최대값과 최소값에 주목해보자. 하위 몇몇 feature 들은 0보다 작은 값을 갖고, 상위 몇몇 값은 0을 훨씬 넘어선 값을 갖는다.
- shapely value 의 의미는, 해당 feature 가 결과 output 이 얼마나 기여했는가, 즉, 해당 feature 로 인해 결과 score 가 얼마나 달라졌는가 이다. 그러므로 score 값을 낮추는데 기여한 feature 들은 0보다 작은값을, 높이는데 기여한 feature 들은 0보다 큰 값을 가질 수 있는 것이다.
4. Reference

data scientist