서론
이펙티브 자바 + 각종 책이나 영상에서 주워들은 Tip들 정리 + 내 생각
생성자 대신 정적팩토리메서드 패턴 고려
정적 팩토리 메서드를 고려하면 생성자에 비해 여러가지 장점을 가질 수 있다.
-
이름을 가질 수 있다.
하나의 시그니처로는 생성자를 하나만 만들 수 있기 때문에 생성자에 넘기는 매개변수와 생성자 자체만으로 반환될 객체의 특성을 제대로 설명할 수 없다. (생성자는 만들면 보통 클래스 이름과 동일하게 만들어야 한다) 반면 정적 팩터리 메서드는 이러한 제약이 없다 -
호출될 때마다 인스턴스를 새로 생성하지 않아도 된다.
따라서 싱글톤 패턴을 만들 때 유용하게 사용할 수 있다. -
반환 타입의 하위 타입 객체를 반환할 수 있다.
-
입력에 따라 매번 다른 클래스의 객체를 반환할 수 있다.
정적 팩터리 메서드는 반환 타입의 하위 타입이기만 하면 어떤 클래스의 객체를 반환하든 상관없다. 반환할 객체의 클래스를 자유롭게 선택할 수 있기 때문에 유연함을 가진다. 이러한 유연함 덕분에 클라이언트는 실제 구현 클래스가 무엇인지 몰라도 된다. -
리턴하는 객체의 클래스가 public static 팩토리 메소드를 작성할 시점에 반드시 존재하지 않아도 된다.
단점의 경우
-
정적 팩터리 메서드만 제공하면 하위 클래스를 만들 수 없다.
상속을 하기 위해서는 public이나 protected 생성자가 필요하다. 따라서 정적 팩터리 메서드만 제공하게되면 (public 또는 protected 생성자 없이 static public 메소드만 제공하는 클래스) 하위 클래스를 만들 수 없게 된다는 단점이 있다. 또한, 컬렉션 프레임워크 유틸리티를 상속할 수 없다는 것도 단점이 될 수 있다. -
개발자가 찾기 어렵다.
자바독을 보면, SpringApplication static method 주석을 달아야 한다. summary 없다.
생성자에 매개변수가 많다면 빌더 패턴 고려
static 팩토리 메소드와 public 생성자 모두 매개변수가 많이 필요한 경우에 불편해진다. 이러한 해결방안으로
- 점층적 생성자 패턴
- 자바 빈즈 패턴
- 빌더 패턴
점층적 생성자 패턴: 매개변수의 개수가 많아지면 클라이언트 코드를 작성하거나 읽기 어려워진다. 또한 실수로 매개변수의 순서를 바꿔 생성했을 경우에 런타임에 엉뚱한 동작을 수행할 수 있고 찾기 어려운 버그를 유발할 수 있다.
자바 빈즈 패턴: 매개변수가 없는 생성자로 객체를 만든 후, setter로 원하는 매개변수의 값을 설정하는 방식이다. 점층적 생성자 패턴에 비해 인스턴스를 만들기 쉽고, 더 읽기 쉬운 코드를 만들 수 있지만, 단점이 있다.
- 객체가 완전히 생성되기 전까지는 일관성이 무너진 상태에 놓이게 된다.
- 일관성이 무너지면서 클래스를 불변으로 만들 수 없게 된다.
- 하나의 객체를 만들기 위해 여러 개의 메서드가 호출된다.
이런 단점을 보완하기 위해 java script에는 Freezing이라는 기능이 있다. Object.feeze() 메서든느 객체를 얼려 버린다는 의미로 객체에 새로운 속서을 추가할 수 없고, 객체에 원래 존재하던 속성을 제거할 수 없으며, 객체 속성, 열거 가능하성, 설정가능성, 값쓰기 가능성을 변경 할수 없게 만든다는 것을 의미한다. (Read는 가능한데, Write는 불가능한 상태) 하지만 자바에는 메서드를 찾을 수 없다..
위 두 가지의 방법에 대한 대안이 될 수 있다. 점층적 생성자 패턴의 안정성과 자바 빈즈 패턴의 가독성을 겸비한 것이 빌더 패턴이다. 각 setter 메서드는 자신을 반환하기 때문에 연쇄적으로 호출할 수 있다. 이를 플루언트 API(fluent API) 혹은 메서드 연쇄(method chaining)라 한다.
박싱된 기본타입 대신 기본타입을 사용하라
박싱 된 기본 타입은 식별성을 가지므로 == 연산자로 비교할 경우 서로의 레퍼런스를 비교하게 된다. 즉, 같은 값을 가졌다 해도 false, 또한 NullPointerException 이 발생할 수 있다. 메모리, 시간 성능에서도 뒤떨어진다.. 박싱된 기본 타입을 써야 될 시점은
- 컬렉션의 원소, 키, 값으로 사용 - 컬렉션은 기본 타입을 담을 수 없으므로
- 리플렉션을 통해 메서드를 호출할 때
그 외에도 뭐 null을 하나의 상태로 간주하고 로직을 짰을 때 쓰기 편한 점은 있다. 물론 이게 좋은 설계인지는 모르겠지만
객체들간의 의존관계는 적을수록 좋다.
물론 케바케이고 실제로 디자인 패턴 중에 의존관계를 한 곳에 몰아넣는 패턴도 있지만, 일반적으로 객체들간 의존관계가 많으면 많을수록 어플리케이션의 복잡도는 늘어나기 마련이다. 가장 좋은 설계는 아예 의존관계 없이 독립적으로 실행가능한 컴포넌트로 만드는 게 좋겠지만. 그건 불가능하다고 치고, 디펜더시가 걸려있는 상황에서는 적어도 직접 의존객체 자원을 명시(합성)하는 것보다, 인터페이스나 프록시 객체를 통해서 느슨하게 연결짓는 게 좋다. 요것도 의존자원을 생성자나 다른 팩토리 메서드를 통해서 주입 받는 방식으로, 아니면 이벤트 리스너를 통해서, 이벤트를 전파시키는 방법을 사용하거나(대신 이러면 디버깅하기 좀 까다로워지겠지..)
맴버변수는 적을 수록 좋다.
위의 이야기와 연결되는 이야기인 것 같은데, 하나의 객체의 상태가 많으면 많을수록, 반대로 이야기하면 그 객체에 대한 책임이 과하다는 이야기가 될 수 있다. 또 생각해보자면 모듈화가 잘 안 됐다는 말이 될 수 도 있는데, 모듈을 잘게 잘게 쪼개는 것이 항상 좋은 방향은 아니겠지만, (인생의 진리는 케바케) 일반적으로는 너무하다 싶을 정도로 잘게 쪼개는 게 나중을 생각하면 더 편해질 가능성이 크더라. 개인적으로 한 객체가 가지는 맴버변수는 최대 3개 이하여야 한다고 생각하고 관계를 설계하는데, 쉽지는 않다.
자원 직접 명시보다 의존관계 주입
스프링의 DI 컨테이너는 위의 팁을 잘 구현하게끔 해준다. 이건 너무 중요하지만 흔한 팁이므로 생략.
정적 유틸리티 클래스 주의
자바는 언어 특징 상 코드를 짜기 위해 클래스를 강제한다. 클래스의 강점이 상태(변수)와 행위(함수)를 한 곳에 관리하게 해준다는 건데, 자바의 이런 특징 때문에, 아무런 상태도 가지지 않는 유틸리티 펑션들의 모음도 클래스를 가지도록 강제하게 된다. 개인적으로 자바처럼 클래스를 강제하는 게 조금 답답하게 느껴지긴 한다. 요런 부분은 다른 언어들이 조금 더 세련되게 느껴지긴 하지만... 암튼 이런 자바의 특징에 익숙치 않은 사람들은, 정적 유틸리티 클래스들을 즐겨 생성하고 사용하고 하는데, 자바의 객체지향적인 원칙과 조금 어울리지 않는 코드작성방식이라 생각한다. 하지만 나도 즐겨 사용하고, 꼭 나쁜 방식은 아니라고 생각한다. 암튼 책에서는 사용하는 자원에 따라 동작이 달라지는 클래스에는 정적 유틸리티 클래스나 싱글턴 방식이 적합하지 않다고 한다.
상속보다 합성
구현 클래스(인터페이스 상속이 아닌) 상속은 다형성과 함께 코드를 재사용할 수 있는 강력한 수단이지만, 실제로 코드 재사용의 목적으로 사용시, 여러가지 문제를 야기할 수 있다. 가장 큰 문제는 슈퍼클래스의 public 메소드를 서브 클래스가 사용하지 않음에도 불구하고 그대로 물려받는데에 있다. 그래서 서브 클래스에서 의도하지 않는 동작을 수반할 수 있게 되며 이는 객체지향 원칙 중 하나인 캡슐화를 위반하게 된다. 더불어 상속 관계는 컴파일 타임에 결정되고 고정되기 때문에, 런타임 시점에서 변경할 수 없다. 이처럼 상속관계에 있는 클래스는 결합도가 높아지므로, 유연한 설계를 고려하기 힘들어진다. 더불어, 자바의 상속은 다이아몬드 상속문제 때문에 다중상속이 불가능하도록 강제되었다. 이렇게 됨으로써, 하나의 기능을 추가하기 위해 필요 이상으로 많은 수의 클래스를 추가해야 하는 경우가 발생할 수 있는데, 이를 가리켜 클래스 폭발(class explosion) 문제 또는 조합의 폭발(combinational explosion) 문제라고 부른다. 리스코프 치환 원칙은 상속받은 자식 클래스는 부모 클래스를 대체할 수 있는 경우에만 상속을 해야 한다고 명시하고 있다. 자식 클래스가 부모 클래스를 대체 할 수 있는 경우는 부모 클래스의 외부로 노출되는 메소드를 자식 클래스에서도 같은 의미로 제공되어야 한다는 것을 의미한다. 상속은 항상 리스코프 치환 원칙에 의거해, 신중하게 설계해야 될 것이다.. 신중한 고려가 존재하지 않는다면 상속을 금지하는 것도 하나의 방법이다.
추상클래스보다 인터페이스
추상클래스나 인터페이스나 클래스에 대한 미완성 설계도이며, 인스턴스화 할 수 없다는 점에서 비슷한 면들이 많다. 자바는 클래스에 대해 단일 상속만 지원하니, 추상클래스 방식은 새로운 타입을 정의하는 데 있어 커다란 제약을 안게 되는 셈이다. 더군다나 자바 8 이후로는 디폴트 메서드까지 지원하게 되어, 더욱 더 추상클래스를 사용할 의미가 사라지게 되었다. 반면 인터페이스는 추상클래스와 달리 계층구조가 없는 타입 프레임워크를 만들 수 있다. 그렇다고 디폴트 메서드를 남발하진 말자. 인터페이스에 디폴트 메서드를 사용할 때는 심사숙고해야한다. 디폴트 메서드는 컴파일에 성공하더라도 기존 구현체에 런타임 오류를 일으킬 수 있다. 인터페이스를 통해 유연한 설계가 가능하지만, 그 인터페이스 명세자체는 신중하게 설계해야 한다.
인터페이스는 타입을 정의하는 용도로만 사용
이 지침에 맞지 않는 예로 상수 인터페이스가 있다. 메서드 없이 static final 필드로만 가득 찬 인터페이스인데, 클래스 내부에서 사용하는 상수는 외부 인터페이스가 아니라 내부 구현에 해당한다. 따라서 상수 인터페이스를 구현하는 것은 이 내부 구현을 클래스의 API로 노출하는 행위다. 또 클라이언트 코드가 내부 구현에 해당하는 이 상수들에 종속되게 한다.(뜨끔!!) 책의 대목을 읽으면서 가슴 한 켠이 굉장히 찔렸다. 본인은 상수 인터페이스를 매우 즐겨쓰는 편에 속하며, 오히려 하드코딩을 방지하는 좋은 패턴이라고 생각했음에 말이다! 상수를 공개할 목적이라면 더 합당한 선택지는 특정 클래스나 인터페이스와 강하게 연관된 상수라면, 그 클래스나 인터페이스 자체에 추가하면 된다. 열거 타입으로 나타내기 적합한 상수라면 열거타입으로 만들어 공개하면 된다.
태그달린 클래스보다 클래스 계층구조 활용
생략..
맴버 클래스는 되도록 static
다른 클래스 안에 정의된 중첩 클래스는 자신을 감싼 바깥 클래스에서만 쓰여야 하며, 그 외의 쓰임새가 있다면 톱레벨 클래스로 만들어야 한다. 중첩 클래스 종류는 정적 맴버 클래스, 비정적 맴버 클래스, 익명 클래스, 지역 클래스 이렇게 4가지로 나뉜다. 정적 맴버 클래스는 다른 클래스 안에 선언되고, 바깥 클래스의 private 맴버에도 접근할 수 있다는 점 빼면 일반 클래스와 똑같다. 반면 비정적 맴버 클래스의 인스턴스는 바깥 클래스의 인스턴스와 암묵적으로 연결된다. 그래서 비정적 맴버 클래스 인스턴스는 this를 사용해 바깥 클래스 인스턴스의 메서드를 가져오거나 참조를 가져올 수 있다.(클래스명.this) 따라서 중첩 클래스 인스턴스가 바깥 인스턴스와 독립적으로 존재할 수 있다면 정적 맴버 클래스로 만들어야 한다. 비정적 맴버 클래스는 바깥 인스턴스 없이 생성할 수 없기 때문이다. 맴버 클래스에서 바깥 인스턴스에 접근할 일이 없다면 무조건 static을 붙여서 정적 맴버 클래스로 만들어두자. static을 안 붙이면 바깥 인스턴스로부터 숨은 외부 참조를 갖게 되어, 시간과 공간이 더 소비된다. 심각한 문제는 가비지 컬렉션이 바깥 클래스의 인스턴스를 수거하지 못하는 메모리 누수가 발생할 수 있다.
톱레벨 클래스는 한 파일에 하나만
소스 파일 하나에 톱레벨 클래스를 어랴 개 선언한다 하더라도 자바 컴파일러는 불평하지 않는다. 하지만 중복 클래스가 존재하고, static 필드를 건드릴 때 컴파일러에게 어느 소스 파일을 먼저 건네주냐에 따라 결과가 달라지기 때문에 분리를 시켜줘라.
// Utensil.java
class Utensil {
static final String NAME = "pan";
}
class Dessert {
static final String NAME = "cake";
// Dessert.java
class Utensil {
static final String NAME = "pot";
}
class Dessert {
static final String NAME = "pie";
public class Main {
public static void main(String[] args) {
System.out.println(Utensil.NAME + Dessert.NAME);
}
}javac Main.java Utensil.java 의 명령으로 컴파일을 수행하면 "pancake"가 출력될 것이고 javac Dessert.java Main.java 명령으로 컴파일을 수행하면 "potpie"가 출력될 것이다.
배열보다는 리스트를 활용
배열은 공변, 제네릭은 불공변.. 배열 타입 Sub가 Super의 하위 타입이라면 배열 Sub[ ]은 배열 Super[]의 하위타입이 된다. 이왕이면 제네릭 타입으로 만들고,
https://www.youtube.com/watch?v=PtM44sO-A6g&ab_channel=%EC%B5%9C%EB%B2%94%EA%B7%A0
한정적 와일드카드를 사용해 API 유연성을 높여라
유연성을 극대화하려면 원소의 생산자나 소비자용 입력 매개변수에 와일드카드 타입을 사용하라. 메서드 선언에 타입 매개변수가 한 번만 나오면 와일드카드로 대체하라.

제너릭 메소드는 static이 가능하다.
https://devlog-wjdrbs96.tistory.com/201
제네릭과 가변인수를 함께 쓸 때는 신중하라
가변인수 메서드를 호출하면 가변인수를 담기 위한 배열이 자동으로 하나 만들어진다. 가변인수 기능은 배열을 노출하여 추상화가 완벽하지 못하고 배열과 제네릭의 타입 규칙이 서로 다르다. 제네릭 varargs 매개변수는 타입 안전하지 않지만 허용된다. 메서드에 제네릭 varargs 매개변수를 사용하고자 한다면, 먼저 그 메서드가 타입 안전하지 확인하고, @SafeVarargs 애너테이션을 달아 사용하는데 불편함이 없게 하자.
굳이 가변인자를 제네릭 리스트로 받을 거면 이렇게 하자
public void doSomething(Integer... args){
List<Integer> ints = Arrays.asList(args);
}https://stackoverflow.com/questions/9863742/how-to-pass-an-arraylist-to-a-varargs-method-parameter
타입 안전 이종 컨테이너를 고려
토비의 봄 TV 2회 - 수퍼 타입 토큰
https://www.youtube.com/watch?v=01sdXvZSjcI&ab_channel=TobyLee
int 상수 대신 열거 타입을 사용
자바의 열거 타입은 완전한 형태의 클래스라서, 다른 언어의 열거 타입보다 훨씬 강력하다. 열거 타입 자체는 클래스이며, 상수 하나당 자신의 인스턴스를 하나씩 만들어 public static final 필드로 공개한다. 열거타입은 기본 private 생성자로 고정되어 있으므로, 사실상 final 이며 싱글톤이다. 이 싱글턴은 리플렉션으로도 뜷을 수 없어서 안전성이 보장된다. 하나의 완전한 클래스이기 때문에, 임의의 메서드나 필드를 추가할 수 있고 임의의 인터페이스를 구현하게 할 수도 있다.
명명 패턴보다 어노테이션을 사용하라
명명패턴으로 작동하는 프레임워크나 툴이 있다. 대표적으로 Junit은 3까지는 테스트 메서드 이름을 test로 시작하게끔 했다. 오타가 나거나, 실수로 이름을 잘 못 지으면, 이 메서드를 무시하고 지나치기 때문에 개발자는 테스트가 통과했다고 오해할 수 있다.
if 문 대신 다형성
변경 가능성 최소화
불변 클래스란 그 인스턴스 내부 값을 수정할 수 없는 클래스를 말한다. 일반적으로 불변 객체를 생성하기 위해서는 다음과 같은 규칙에 따라 클래스를 생성해야 한다.
- 클래스를 final로 선언하라 (클래스 확장 X)
- 모든 클래스 변수를 private와 final로 선언하라
- 객체를 생성하기 위한 생성자 또는 정적 팩토리 메소드를 추가하라
- 참조에 의해 변경가능성이 있는 경우 방어적 복사를 이용하여 전달하라
설사 위의 조건을 모두 다 따랐다고 치더라도, 클래스 내부의 변수가 킅래스 타입일 경우, 그 클래스 내부의 변수들까지 final이 아닌 이상 불변성을 보장하지는 못한다. 불변 객체는 근본적으로 스레드 안전하여 따로 동시성 이슈를 신경쓸 필요가 없다. 따라서 안심하고 공유할 수 있으며, 적극적으로 재활용이 가능하다. 다만 값이 다르면 반드시 독립된 객체로 만들어야 하는데, 값의 가짓수가 많다면, 이들을 모두 만드는 데 큰 비용을 치뤄야 한다. 불변으로 만들 수 없는 클래스는 변경할 수 있는 부분을 최소한으로 줄이자. 변경이 안 되야할 것 같은 변수들은 대충 다 final을 붙이자. 다만 final class의 경우 상속이 안 돼서, 스프링에서 cglib 를 통해서 다이나믹 프록시 객체를 생성할 수 없는 거 아닌가? 이 부분은 함 나중에 공부해봐야겠다.
try-finally 보다는 try-with-resources
생략
다 쓴 객체참조를 해제하라
자바는 객체 참조 해제를 가비지 컬렉터가 담당하기 때문에 원론적으로 개발자가 객체의 소멸을 신경쓸 필요는 없다. 하지만 실제로는 가비지 컬렉터가 아주 똑똑하지는 않으므로, 개발자가 신경쓰지 않는다면 얼마든지 메모리 누수가 발생할 수 있다. 책에서 예시로 든 잘못 설계한 Stack 클래스는, Stack에서 꺼내진 객체들은 앞으로 다시는 쓰지 않는다 하더라도, 가비지 컬렉터가 회수하지 않는다. 객체 참조 하나를 살려두면 가비지 컬렉터는 그 객체뿐 아니라, 그 객체가 참조하는 모든 객체를 회수해가지 못한다. 해법은 해당 참조를 다 썼을 때 명시적으로 null 처리를 해주는 거다. 더 나은 방안은 그 참조를 담은 변수를 유효 범위 바깥으로 밀어내는 것이다. 일반적으로 자기 메모리를 직접 관리하는 클래스는 항시 메모리 누수에 주의해야 된다. 캐시 역시 메모리 누수를 일으키는 주범이다. 메모리 누수의 세번째 주범은 리스너 혹은 콜백이라 부르는 것이다. 클라이언트가 콜백을 등록만 하고, 명확히 해지하지 않는다면 콜백은 계속 쌓여갈 것이다.
익명 클래스보다는 람다
자바의 단점이라면 단점?이라고 부를 수 있는 게 function이 그 자체로 일급 시민이 아니라는 점이다.
프로그래밍에서 1급 시민이란 다음의 조건을 충족하는 것을 말한다.
변수에 담을 수 있다.
함수의 인자로 전달할 수 있다.
함수의 반환값으로 전달할 수 있다.
그래서 자바 8 이전에는 함수 타입을 표현할 때 추상메서드를 하나만 담은 인터페이스를 사용했다. 이런 인터페이스의 인스턴스를 함수객체라고 하여, 특정 함수나 동작을 나타내는 데 썼다. 함수 객체를 만드는 데 주요 수단은 익명 클래스였으나, 자바 8에 와서 추상메서드 하나짜리 인터페이스는 특별한 의미를 인정받았다. 함수형 인터페이스의 지위를 인정받게 되어, 이 인터페이스의 인스턴스를 람다식으로 표현할 수 있게 된 거다. 타입 추론을 활용하여 기존 익명클래스의 코드를 훨씬 단축할 수 있게 됐다. 람다는 작은 함수 객체를 아주 쉽게 표현할 수 있어 자바로 함수형 프로그래밍을 쉽게 흉내낼 수 있다. 다만 주의해야할 점은, 람다는 이름이 없고 문서화도 못 한다. 따라서 코드 자체로 동작이 명확히 설명되지 않거나 코드 줄 수가 많아지면 람다를 쓰지 말아야 한다. 람다는 세 줄을 넘어가면 가독성이 급격히 안 좋아진다. 람다의 등장으로 익명 클래스의 설 자리는 크게 좁아졌지만, 아직 대체 불가능한 영역은 있다. 첫번째, 추상 클래스의 인스턴스를 만들 때 람다를 쓸 수는 없다. 이 경우는 익명클래스를 사용해야 하며 비슷하게 추상 메서드가 여러개인 인터페이스의 인스턴스를 만들 때도 익명클래스를 쓸 수 있다. 마지막으로, 람다는 자신을 참조할 수 없다. 람다에서 this 키워드는 바깥 인스턴스를 가리킨다. 반면 익명클래스에서의 this는 자기 자신을 가리킨다. 그래서 함수 객체가 자기자신을 참조해야 한다면 익명클래스를 사용해야 한다. 아래 영상은 이런 람다와 익명클래스의 차이점을 잘 설명해준다.
모던 자바 (자바8) 못다한 이야기
람다보다는 메서드 참조
람다보다 더 간결하게 만들 수 있는 수단은 메서드 참조가 있다. 람다로 구현했을 때 너무 길거나 복잡하면 메서드 참조가 좋은 대안이 될 수 있다. 즉 람다로 작성할 코드를 새로운 메서드에 담은 다음, 람다 대신 그 메서드 참조를 사용하는 식이다. 메서드 참조에는 기능을 잘 드러내는 이름을 지어줄 수 있고, 친절한 설명을 문서로 남길 수 도 있다.
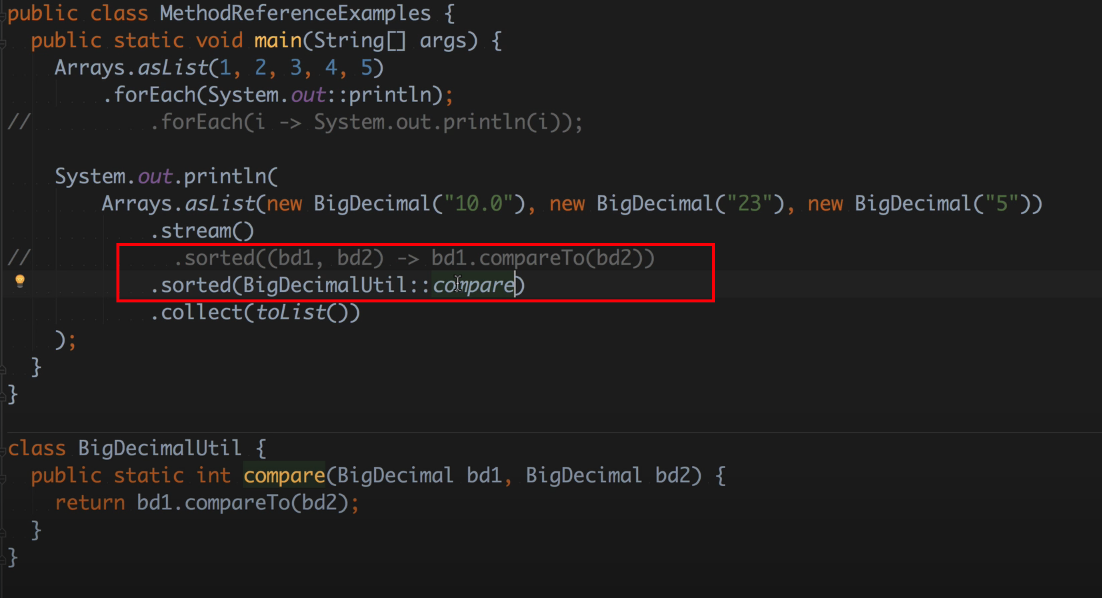
본인은 메서드 참조를 잘 사용하지 않는 편이다. 일단 너무 생소하고, 가독성도 안 좋다고 생각해서.. 내가 익숙하지 않아서이겠지만..
람다로는 불가능하나 메서드 참조로 가능한 유일한 예는 제네릭 함수 타입 구현이다.
interface G1 {
<E extends Exception> Object m() throws E;
}
interface G2 {
<E extends Exception> String m() throws Exception;
}
interface G extends G1,G2{}
G g = String::new; //가능!!
<F extends Exception> ()->String throws F; //불가능
표준 함수형 인터페이스를 사용해라
함수형 인터페이스를 직접 만들 수 있지만 이미 잘 작성된 표준 인터페이스가 라이브러리에 있다. java.util.function 패키지를 보면 다양한 용도의 표준 함수형 인터페이스가 담겨있다. 필요한 용도에 맞는 게 있다면 직접 구현하지 말고, 표준 함수형 인터페이스를 활용하라. 직접 만든 함수형 인터페이스에는 항상 @FunctionalInterface 애너테이션을 사용하자. 이 어노테이션을 사용하는 이유는 프로그래머의 의도를 명시하는 것으로서 크게 3가지 목적이 있다.
- 해당 클래스의 코드나 설명문서를 읽는 이에게 이 인터페이스가 람다용으로 설계된 것임을 알려주기
- 해당 인터페이스가 추상 메서드를 오직 하나만 가지도록 컴파일러가 강제
- 그 결과 유지보수 과정 중 누군가 실수로 메소드를 추가하는 걸 막아준다.
자바도 람다를 지원하기 때문에, API를 설계할 때 항상 람다도 염두에 두어야 한다.
스트림은 주의해서 사용
스트림을 과용하면 프로그램이 읽거나 유지보수하기 어려워진다. 확실히 스트림에 익숙하나 안 익숙하나를 떠나서, 가독성에 문제가 생기긴 하는 것 같다. 그래도 굉장히 유용한 툴이긴 분명하다. 그리고 잘은 모르지만 스트림을 통해서 알고리즘 문제를 풀어나갈 때 자꾸 시간복잡도에서 탈락하는 경우가 많은데.. 성능면에서 어떤 이슈가 있나? 아니면 걍 내가 잘 못 쓰고 있는 건 지도...
스트림에서 부작용 없는 함수를 사용하라
스트림은 함수형 프로그래밍에 기초한 패러다임이다. 스트림에서 각 변환단계는 이전 단계의 결과를 받아 처리하는 순수함수여야 한다. 순수 함수는 오직 입력만이 결과에 영향을 주는 함수를 말한다. 이렇게 하려면 스트림 연산에 건네는 함수 객체는 모두 사이드 이펙트가 없어야 한다. 본인은... 이 팁을 잘 적용하지 못하고 있다.. 스트림 상에서 외부 상태를 수정하는 람다를 자주 실행하고 있으며, 개인적으로 전혀 생각하지 못했던 부분이다. 책에서 지적하고 있던 문제점이 정확히 내 코드와 일치하는 부분을 보고 마음 한 켠이 많이 찔린다.. 하지만 수집기(collect)로도 해결하기 어려운 까다로운 연산을 처리하는 데에 있어서 순수 함수 형태로는 무리가 가긴 하는데.. 요럴 때는 stream api 를 쓰지 말아야 하나?
// Stream을 잘못 쓴 예시
Map<String, Long> freq = new HashMap<>();
try (Stream<String> words = new Scanner(file).tokens()){
words.forEach(word -> {
freq.merge(word.toLowerCase(), 1L, Long::sum);
});
}
// 다른 가변 상태를 참조하지 않는 stream api의 올바른 사용예시
Map<String, Long> freq;
try (Stream<String> words = new Scanner(file).tokens()){
freq = words.collect(groupingBy(String::toLowerCase, counting()))
}
반환 타입으로는 스트림보다 컬렉션이 낫다.
스트림은 iteration을 지원하지 않는다.. 나는 그것보다 다른 언어와 달리 인덱스를 지원하지 않는다는 게 더 짜증난다.. 자바의 for each도 list의 index를 지원해주지 않기 때문에 우회해서 확인해야 한다.. 이거는 좀 고쳐줄 수 없나...
// Stream<E>를 Iterable<E>로 중개해주는 어댑터
public static <E> Iterable<E> iterableOf(Stream<E> stream){
return stream::iterable;
}
// 어댑터 메서드를 사용해 반복
for (ProcessHandle p : iterableOf(ProcessHandle.allProcesses())) {
// 처리 로직
}
// Iterable<E>를 Stream<E>로 중개해주는 어댑터
public static Iterable<E> streamOf(Iterable<E> iterable){
return StreamSupport.stream(iterable.spliterator(), false);
}
스트림 병렬화는 주의해서 적용해라
.. 생략
https://jjingho.tistory.com/97?category=903320
매개변수가 유효한지 검사하라
public 메서드가 아니라면 단언문(assert)를 사용할 수 있다.
private static void sort(long a[]. int offset, int length){
assert a != null;
assert offset >= 0 && offset <= a.length;
assert length >= 0 && length <= a.length - offset;
}assert는 Java4부터 지원하며 자신이 단언한 조건이 무조건 참이라고 선언한다. 즉, 실행되는 문장이 참(true)이라면 그냥 지나가고, 거짓(false)이라면 AssertionError가 발생한다.
assert는 런타임에 아무런 효과가 없고 성능 저하도 없다.
적시에 방어적 복사본을 만들라
자바는 개발자가 포인터를 직접 다루지 않으니, 메모리 충돌 오류에서 비교적 안전하다. 자바로 작성한 클래스는 시스템의 다른 부분에서 무슨 짓을 하든 불변식이 지켜지기 때문이다. 하지만 완전히 안전한 건 아니니 클라이언트가 불변식을 깨트릴려고 노력한다고 가정하고 방어적으로 프로그래밍해야 한다. 불변 클래스를 만들었다고 쳐도, 내부 맴버변수가 참조형(클래스 타입)일 때 그 내부의 변수들까지 final 이 아닌 이상 불변성을 지킬 수 없다. 대표적인 예시가 자바의 Date 클래스이다. 외부 공격으로부터 인스턴스 내부를 보호하려면 생성자에서 받은 가변 매개변수 각각을 방어적으로 복사해야 한다.
public final class Period {
private final Date start;
private final Date end;
/**
* @param start 시작 시각
* @param end 종류 시각; 시작 시각보다 뒤여야 한다.
* @throws IllegalArgumentException 시작 시각이 종료시각보다 늦을때 발생한다.
* @throws NullPointerException start나 end 가 null 이면 발생한다.
*/
public Period(Date start, Date end) {
if (start.compareTo(end) > 0)
throw new IllegalArgumentException(
start + "가" + end + "보다 늦다.");
this.start = start;
this.end = end;
}
...getter setter 생략
}
// Period 인스턴스의 내부를 공격
Date start = new Date();
Date end = new Date();
Period p = new Period(start, end);
end.setYear(78); //P의 내부를 변경했다!
/**
방어적 복사본
*/
//생성자 매개변수의 방어적 복사본
public Period(Date start, Date end) {
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
if (start.compareTo(end) > 0)
throw new IllegalArgumentException(
start + "가" + end + "보다 늦다.");
}
// 수정한 접근자 - 가변 필드의 방어적 복사본을 만든다.
public Date start() {
return new Date(start.getTime());
}
public Date end() {
return new Date(end.getTime());
}
오버로딩은 신중히 사용하라
public class CollectionClassifier {
public static String classify(Set<?> s) {
return "집합";
}
public static String classify(List<?> lst) {
return "리스트";
}
public static String classify(Collection<?> c) {
return "그 외";
}
public static void main(String[] args) {
Collection<?>[] collections = {
new HashSet<String>(),
new ArrayList<BigInteger>(),
new HashMap<String, String>().values()
};
for (Collection<?> c : collections)
System.out.println(classify(c));
}
}
결과는 "그 외" 가 3번 연달아 출력한다. 그 이유는 오버로딩 같은 경우, 어느 메서드를 호출할지가 컴파일타임에 정해지기 때문이다. 컴파일 타임에는 for문 안의 c는 항상 Collcation 타입이다. 런타임에는 타입이 매번 달라지겠지만, 호출할 메서드를 선택하는 데 영향을 주지 못한다. 오버라이딩처럼 동적 바인딩 되는 것과는 다르다. 이를 해결하려면 instanceof로 명시적으로 검사를 수행하거나, 오버라이딩 해줘야 한다.
public static String classify(Collection<?> c) {
return c instanceof Set ? "집합" :
c instanceof List ? "리스트" : "그 외";
}
//오버라이딩
class Wine {
String name() { return "포도주"; }
}
class SparklingWine extends Wine {
@Override String name() { return "발포성 포도주"; }
}
class Champagne extends SparklingWine {
@Override String name() { return "샴페인"; }
}
public class Overriding {
public static void main(String[] args) {
List<Wine> wineList = List.of(
new Wine(), new SparklingWine(), new Champagne());
for (Wine wine : wineList)
System.out.println(wine.name());
}
}
일반적으로 매개변수 수가 같을 때는 다중정의를 피하는 게 좋다.
만약 다중정의를 피할 수 없는 상황이라면 헷갈릴 만한 매개변수는 형변환하여 정확한 다중정의 메서드가 선택되도록 하자.
가변인수는 신중히 사용
인수 개수가 일정하지 않은 메서드를 정의해야 한다면, 가변인수가 필요하다. 인수가 1개 이상이어야 하는 가변인수 메서드에서 인수를 0개 받을 수 있도록 설계하는 것은 좋지 않다. 요 문제는 매개변수를 2개 받도록 강제하면 해결된다.
static int min(int firstArg, int... remainingArgs) {
int min = firstArg;
for (int i = 1; i < args.length; i++)
if (args[i] < min)
min = args[i];
return min;
}성능에 민감한 상황이라면 가변인수가 걸림돌이 될 수 있다. 가변인수 메서드는 호출될 때마다 배열을 새로 하나 할당하고 초기화하기 때문이다.
가변인수의 유연성이 필요하지만, 성능에 대한 비용을 감당할 수 없는 상황이라면 다중정의를 통해 해결할 수 있다.
null이 아닌, 빈 컬렉션이나 배열을 반환
null을 반환하는 메서드를 작성하면 클라이언트 입장에서 항상 방어 코드를 넣어줘야 한다. 이럴 경우 빈 컬렉션을 반환하는 것을 고려해볼 수 있다.
public List<Cheese> getCheeses() {
return cheesesInStock.isEmpty() ? Collections.emptyList()
: new ArrayList<>(cheesesInStock);
}
비어있는 불변 컬렉션을 반환하는 Collections.emptyList()를 활용하면 매번 같은 빈(empty) 컬렉션을 반환할 수 있다. 불변 객체는 자유롭게 공유해도 안전하기 때문에 성능 최적화가 가능해진다.
배열을 사용할 때도 마찬가지이다. null을 반환하지 말고 길이가 0인 배열을 반환하자.
public Cheese[] getCheeses() {
return cheesesInStock.toArray(new Cheese[0]);
}
//성능 최적화가 신경쓰인다면 길이 0짜리 배열을 캐싱해두고 반환하자
private final static Cheese [] EMPTY_CHEESE_ARRAY = new Cheese[0];
public Cheese[] getCheeses() {
return cheesesInStock.toArray(EMPTY_CHEESE_ARRAY);
}
Optional을 사용하면 안 되는 경우(안티 패턴)
1. 컬렉션, 스트림, 배열, 옵셔널 같은 컨테이너 타입은 옵셔널로 감싸면 안 된다.
예를 들어, Optional<List<T>>를 반환하기보다는 빈 List<T>를 반환하는 게 좋다. 빈 컨테이너를 반환하면 클라이언트에 옵셔널 처리 코드를 넣지 않아도 된다.
2. 박싱 된 기본 타입을 담은 옵셔널을 반환하면 안 된다.
박싱 된 기본 타입을 담는 옵셔널은 기본 타입 자체보다 무거울 수 밖에 없다. 따라서 자바 API는 int, long, double 전용 옵셔널을 제공한다. 바로 OptionalInt, OptionalLong, OptionalDouble이다. 이렇게 대체제까지 존재하니 박싱된 기본 타입을 담은 옵셔널을 반환하는 일은 없도록 하자.
3. Optional을 컬렉션의 키, 값, 원소나 배열 원소로 사용하지 말자
Optional을 맵의 값으로 사용하면 절대 안 된다. 만약 사용한다면 Map안에 키가 없다는 사실을 나타내기 모호한 상황이 발생한다.
전통적인 for문보다 for-each문 사용
컬렉션이 중첩되는 경우
// before
enum Suit { CLUB, DIAMOND, HEART, SPADE}
enum Rank { ACE, DEUCE, THREE, FOUR, FIVE, SIX, SEVEN, EIGHT, NINE, TEN, JACK, QUEEN, KING}
static Collection<Suit> suits = Arrays.asList(Suit.values());
static Collection<Rank> ranks = Arrays.asList(Rank.values());
List<Card> deck = new ArrayList<>();
for(Iterator<Suit> i = suits.iterator(); i.hasNext();) {
for(Iterator<Rank> j = ranks.iterator(); j.hasNext();) {
// 오류 발생!! i.next()가 너무 많이 호출됨.
deck.add(new Card(i.next(), j.next()));
}
}
// after
enum Suit { CLUB, DIAMOND, HEART, SPADE}
enum Rank { ACE, DEUCE, THREE, FOUR, FIVE, SIX, SEVEN, EIGHT, NINE, TEN, JACK, QUEEN, KING}
static Collection<Suit> suits = Arrays.asList(Suit.values());
static Collection<Rank> ranks = Arrays.asList(Rank.values());
List<Card> deck = new ArrayList<>();
for(Suit suit : suits) {
for(Rank rank : ranks) {
deck.add(new Card(suit, rank));
}
}
//반복자를 사용해야 하는 경우 전통적인 for문을 사용하자.
for (Iterator<Element> i = c.iterator(); i.hasNext();) {
Element e = i.next();
... // e와 i를 사용한다.
}
for-each 문은 Iterable 인터페이스를 구현한 객체라면 무엇이든 순회할 수 있다.
Iterable을 구현하는 것은 까다롭지만, 원소들의 묶음을 표현하는 타입을 작성해야 한다면 Iterable을 구현을 고려해보자.
정확한 답이 필요하다면 float와 double은 피하라
금융 계산에 정확한 결과를 원한다면 BigDecimal, int, long을 사용해야 한다.
리플렉션과 어노테이션을 이용한 메타프로그래밍 자제
리플렉션을 통한 메타 프로그래밍을 처음 접했을 때의 희열?을 기억한다. 어노테이션을 사용해서 런타임 시점에 전혀 연관이 없어보이던 객체들의 관계를 맺어주고, 로직을 실행해주는 게 얼마나 신기했던가.. 그동안 자바를 공부하면서 느껴보지 못했던 신선함이며 내가 자바를 좋아하게 된 계기이기도 하다. 물론 다른 언어에도 이런 기능을 가지고 있겠지만, 당시에 나는 몰랐으니까.. 자바의 리플렉션 기능은 아주 강력하다. Class 객체가 주어진다면, 아니 그 이름만 알고 있더라도, 메타 데이터를 통해 접근해서, 그 클래스의 생성자, 메서드, 필드 인스턴스를 가져올 수 있으며 조작할 수 있으며 심지어 컴파일 당시에 존재하지 않던 클래스도 이용할 수 있다. 다만 책에서도 지적했듯이 여러가지 단점들도 동시에 존재한다.
- 컴파일 타입 검사가 주는 이점을 누릴 수 없다.
어노테이션은 어떤 타입 정보가 아니다. 단지 메타 데이터일 뿐이지, 어떤 특정 행위를 규정하지 않는다. 행위는 이 어노테이션을 사용한 프레임웤이나 라이브러리 내부에 정의된 코드를 통해 동작한다. 그래서 타입을 기반으로 코드가 올바르게 동작할 거 라는 것을 검증할 수 없다. - 리플렉션을 이용하면 코드가 지저분하고 장황해진다.
솔직히 무슨 말인지 잘 이해는 안 간다. 내가 메타 프로그래밍이 좋다고 느꼈던 것도, 어노테이션으로 뒷단의 로직들은 관례로 감추고 개발자는 비즈니스 로직에만 집중할 수 있게 해주는 점 아니었던가. 하지만 조금 다른 식으로 이해하면 이해가 간다. 어노테이션 자체가 리플렉션에 대한 개념이 없으면 코드를 이해하기 어렵게 만든다. (설사 알고 있더라도..) 일단 자바의 기본 캡슐화 은닉성 같은 것들 다 쌩깔 수 있으며, 어노테이션 자체만으로 코드가 어떻게 돌아가는지 확인할 방법이 없다. 내가 스프링부트를 처음 배웠을 때도 이와 같은 감정이었는데, 부트는 어노테이션과 리플렉션을 활용한 메타 프로그래밍으로 범벅이 되어있다. 처음 배우면 당췌 코드가 어떻게 돌아가는지 확인할 방법이 없다. 이 어노테이션을 붙이면 이런 기능을 한다는데 그래서 어떻게? 그리고 어노테이션을 활용한 뒷단의 코드들 자체는 로직이 장황해질 수 있다. 또한 어노테이션끼리 확장?(어노테이션에 또 다른 어노테이션이 연속해서 붙어있는 경우) 얘가 어떻게 동작할지 클래스나 인터페이스처럼 확신할 수가 없다.. - 성능이 떨어진다.
당근 런타임 상에서 동적으로 타겟팅이 결정되는 리플렉션 api는 성능상 후질 수 밖에 없다. 컴파일 시 코드를 생성하는 lombok과 같은 어노테이션 프로세서를 활용하는 이야기는 별개이다. - 테스트가 어렵다.
어노테이션은 그 자체로 동작하는 코드가 아니다. 어노테이션을 활용하여 어떤 부가적인 기능을 수행하는 메타 프레임웤 위에 올려야지만 동작한다. 흔히 사용하는 @RequestMapping 같은 것도, 그 자체로 테스트할 수 가 없다. 스프링 컨텍스트를 통째로 올리고, mock 오브젝트를 활용하든지 해서 호출해봐야지만 정상작동하는지 테스트할 수 있다. - 자바 문법을 파괴한다.
앞서 이야기했듯이 리플렉션을 활용하면 자바 문법에서 구현한 캡슐화 , 은닉성, 등등을 다 우회해서 접근할 수 있다. 이로 인해, 원래는 동작하지 않아야하는 로직들을 수행할 수 있게 되고, 이는 이해하기 어렵고 오해하기 쉬운 코드를 양성하게 된다.
책에서는 리플렉션은 아주 제한된 형태로만 사용하길 추천한다.
컴파일 타임에는 알 수 없는 클래스를 사용하는 프로그램을 작성한다면 되도록 리플렉션은 객체 생성에만 사용하고 사용할 때는 인터페이스로 참조해 활용하자.
참고: https://www.youtube.com/watch?v=BFjrmj4p3_Y&ab_channel=OracleKorea
네이티브 메서드는 신중히 사용하라
자바 네이티브 인터페이스는 자바 프로그램이 C나 C++같은 네이티브 프로그래밍 언어로 작성한 메서드를 호출하는 기술이다. 네이티브 메서드가 주로 사용된 경우는 아래와 같은 3가지이다.
- 윈도우 레지스트리 같은 플랫폼 특화 기능을 사용한다.
- 네이티브 코드로 작성된 기존 라이브러리를 사용한다.
- 성능 개선을 목적으로 성능에 결정적 영향을 주는 부분만 따로 네이티브 언어로 작성한다.
이제는 성능을 개선으로 네이티브 메서드를 사용하는 것은 거의 권장하지 않는다.
- 자바가 성숙해지면서 플랫폼의 기능들을 흡수하고 있다.
플랫폼 특화 기능을 사용하려면 네이티브 메서드가 필요하다. 하지만 자바 언어가 발전해가면서 OS와 같은 하부 플랫폼의 기능들을 점차 흡수하고 있다. 따라서 네이티브 메서드를 사용하기 전, 자바 라이브러리가 제공하고 있는 기능인지 먼저 확인해보자. 단, 자바에서 제공하지 않는 기능이라면 네이티브 메서드를 사용해야 한다.
- 성능 개선을 목적으로 사용해왔지만, 이제 자바도 충분히 빠르다.
자바 초기 시절에는 네이티브 메서드와 비교했을 때 엄청난 성능 차이를 보였지만, JVM이 발전해오면서 이 간극이 좁혀졌다. 즉, 이제 네이티브 메서드로 볼 수 있는 성능 개선 효과가 줄어들었다. 다만, 고성능의 다중 정밀 연산이 필요하다면 네이티브 메서드를 통해 GMP를 사용하는 걸 고려해도 좋다.
반면 네이티브 메서드에는 심각한 단점이 있다. C나 C++ 같이 개발자가 직접 메모리 주소에 접근 자유도가 높은 언어로부터 오는 메모리 훼손의 위험성이 있으며, 네이티브 언어는 자바보다 플랫폼 종속성이 높아 이식성도 낮아진다. 디버깅도 어려울뿐더러, 가비지 컬렉터가 추적하지도 못한다. 자바와 네이티브 사이의 경계를 오갈 때마다 비용이 발생하기 때문에 잘 못 사용하다가는 속도가 오히려 떨어질 수도 있다.
최적화는 신중히 해라
성능 때문에 견고한 구조를 희생하지 말자. 빠른 프로그램보다 좋은 프로그램을 만들어야 한다. 좋은 프로그램은 개별 구성요소의 내부를 독립적으로 설계할 수 있다. 따라서 시스템의 나머지에 영향을 주지 않고도 각 요소를 다시 설계할 수 있다. 프로그램 구현상 성능 이슈는 나중에 최적화로 해결할 수 있지만, 아키텍처 구조상 성능 이슈는 시스템 전체를 다시 만들어야 할 수 도 있다. 성능에 신경쓰지 말고 설계를 하라는 의미가 아니라, 성능 때문에 api 구조를 왜곡하는 건 매우 안 좋은 생각이라는 뜻이다. 좋은 프로그램을 만들다 보면 성능은 자연스럽게 따라온다.
예외는 진짜 예외 상황에만 사용하라
예외를 제어 흐름용으로 사용하지 말자. 예외를 제어 흐름용으로 사용하면 표준 관용구보다 훨씬 느리다.
복구할 수 있는 상황에는 검사 예외를, 프로그래밍 오류에는 런타임 예외를 사용하라
자바는 문제 상황을 알리는 타입(throwable)으로 검사 예외(checked Exception), 런타임 예외(Runtime Exception), 에러 이렇게 3가지를 제공한다. 호출하는 쪽에서 복구하리라 예상되는 상황이면 검사 예외를 던져라. 검사 예외를 던지면 호출자가 그 예외를 catch로 처리하거나, 더 바깥으로 전파하도록 강제된다. 따라서 메서드 선언에 포함되는 예외는 해당 메서드를 호출했을 때 발생할 수 있는 유력한 결과를 나타낸다. 즉, API 설계자는 API 사용자에게 검사 예외(checked Exception)를 넘겨주어 그 상황에서 복구하라고 요구한 것이다.
비검사 throwable은 두 가지로, 런타임 예외와 에러로 나뉜다. 프로그램에서 비검사 예외를 던진다는 것은 복구가 불가능하거나 더 실행해봐야 잃는 게 많다는 의미다. 프로그래밍 오류를 나타낼 때는 런타임 예외를 사용하자. 복구될 수 있는 상황인지 아닌지는 API 설계자가 확신하기 어렵다면 비검사 예외를 던지는 편이 더 났다.
에러는 보통 JVM 자원 부족, 불변식 깨짐 등 더 이상 수행할 수 없는 상황을 나타낼 때 사용한다. 구현하는 비검사 예외(UnChecked Exception)는 모두 RuntimeException의 하위 클래스여야 한다. Error는 상속하지 말아야 할 뿐 아니라, throw 문으로 직접 던지는 일은 없어야 한다. (AssertionError는 제외) Exception, RuntimeException, Error를 상속하지 않고 throwable을 만들어 사용할 수 있지만, 절대 그런 짓은 하지 말자
가능한 한 실패 원자적으로 만들라
호출된 메서드가 실패해도 해당 객체는 메서드 호출 전 상태를 유지하는 특성을 실패 원자적이라고 한다.메서드를 실패 원자적으로 만들기 위해선,
-
메서드를 불변 객체로 설계한다. 불변 객체는 태생이 실패 원자적이며 객체가 불안정한 상태에 빠지는 일은 생기지 않는다. 메서드가 실패하면 새로운 객체가 만들어지지 않을 뿐이다.
-
가변 객체를 다루는 메서드를 실패 원자적으로 만들기 위한 가장 쉬운 방법은 수행에 앞서 매개변수의 유효성을 체크한다.
-
실패 가능성 있는 코드는 객체의 상태 변경 코드보다 앞에 배치한다.
-
객체의 임시 복사본으로 작업이 성공하면 원래 객체와 교체한다.
-
발생한 실패를 가로채는 복구 코드를 작성하고 이전 상태로 되돌린다.
공유 중인 가변 데이터는 동기화해 사용하라
멀티스레드 사용시 항상 동시성 이슈를 신경써야 한다. 자바는 동기화를 지원해주는 강력한 모니터 도구를 제공해준다. (synchronized) 동기화는 배타적 실행을 막는 용도뿐 아니라, 동기화된 메서드나 블록에 들어간 스레드가 같은 락(lock)의 보호하에 수행된 모든 이전 수정의 최종 결과를 보게 해준다. 스레드 사이의 안정적인 통신에 꼭 필요하다. volatile 한정자를 사용하면 배타적 수행과는 상관없지만 항상 가장 최근에 기록된 값을 읽게 됨을 보장한다.
다만 synchronized는 비용이 있는 편으로 동기화 문제를 해결하는 가장 좋은 대안은 불변 데이터만 공유하거나 가변 데이터를 공유하지 않는 것이다. 가변 데이터라면 단일 스레드에서만 사용하도록 하자.
effectively immutable(final)을 활용하는 것도 방법이다. JVM 내부적으로 스레드 세이프를 보장하기 위해 변수 캡처를 활용하는 것인데 좀 더 자세한 설명은 이따 생각나면 적겠다..
스레드보다는 동시성 유틸리티를 애용하라
스레드를 직접 다루는 것을 삼가자. java.util.concurrent 동시성 유틸리티는 실행자 프레임워크, 동시성 컬렉션, 동기화 장치 이렇게 세 범주로 나눌 수 있다. 실행자 프레임워크(Executor Framework)는 인터페이스 기반의 유연한 태스크 실행 기능을 담고 있다. 스레드를 직접 다루면 스레드가 작업 단위와 수행 매커니즘 역할을 모두 수행하지만, 실행자 프레임워크를 사용하면 작업 단위와 실행 매커니즘이 분리된다. 우리가 직접 스레드를 직접 작성하고 튜닝하는 것보다 잘 만들어진 동시성 패키지를 활용하는 것이 낫다. 동기화 장치의 경우도 wait와 notify는 올바르게 사용하기 아주 까다로우니 CountDownLatch와 같은 고수준 동시성 유틸리티를 사용하자. 컬렉션 객체같은 경우도 내가 직접 동기화 처리를 해주는 게 아니라, 제공해주는 동시성 컬렉션들을 활용하자.
자바 직렬화의 대안을 찾아라
직렬화의 근본적인 문제는 공격 범위가 너무 넓고, 지속적으로 더 넓어지기 때문에 방어하기 어렵다는 점이다. ObjectInputStream의 readObject() 메서드는 Serializable 인터페이스를 구현한 클래스패스 안에 거의 모든 타입의 객체를 만들어 낼 수 있다. 바이트 스트림을 역직렬화하는 과정에서 이 메서드는 그 타입들 안의 모든 코드를 수행할 수 있고, 이로 인해 그 타입들의 코드 전체가 공격 범위에 들어가게 된다.
그냥 자바 직렬화를 쓰지 말자. 새로운 시스템에 자바 직렬화를 써야 할 이유가 없다. 객체와 바이트 시퀀스를 변환해주는 다른 메커니즘이 많이 있기 때문이다. 자바 직렬화의 위험성을 회피하면서 다양한 플랫폼 지원, 우수한 성능, 풍부한 지원 도구 등을 제공하는 다른 방식의 매커니즘 방식을 크로스-플랫폼 구조화된 데이터 표현이라 한다. 대표적으로 JSON과 프로토콜 버퍼(Protocol Buffers)가 있다.
Serializable을 구현할지를 신중히 결정해야 한다. 쉽게 선언할 수 있지만, 구현할 때는 꽤나 신경 써야 할 부분이 많다. 한 클래스의 여러 버전이 상호작용하거나, 신뢰할 수 없는 데이터에 노출될 가능성이 있다면 Serializable은 구현은 아주 신중하게 이뤄져야 한다.
context 넘기기
thread local
일반적인 프로그래밍 규약
- 메서드 이름을 신중히 짓자
- 편의 메서드를 너무 많이 만들지 말자
- 매개변수 목록은 짧게 유지하자 (특히 같은 타입의 매개변수가 여러개 나오는 게 문제) - 최대 4개 이하
- 줄이는 Tip
- 여러 메서드로 쪼갠다. 쪼개진 메서드는 원래 매개변수 목록의 부분집합을 받는다. 메서드가 너무 많아질 수 도 있지만 오히려 직교성을 높여 메서드 수가 줄여주는 효과를 줄 수 도 있다.
- 매개변수 여러개를 묶어주는 도우미 클래스를 만든다. 일반적으로 이런 도우미 클래스는 정적 맴버 클래스
- 객체 생성에 사용한 빌더패턴을 메서드 호출에 응용
-
매개변수의 타입으로는 클래스보다 인터페이스가 더 낫다.
-
지역변수의 범위를 최소화하자
- 변수를 미리 선언하지 말고, 처음 쓰일 때 선언
- 선언과 동시에 초기화.
- 메서드를 작게 유지하고 한 가지 기능에 집중
- 일반적으로 통용되는 명명규칙을 따르자.
- 명명규칙에 일관성이 있어야 한다. 설사 자기만의 일관성이 있다고 하더라도, 혼자 일하는 거 아닌 이상 일반적으로 통용되는 명명규칙을 따르는 게 이득이다.
- guard clause
https://www.youtube.com/watch?v=ZzwWWut_ibU&list=PLiLLi47PCMPjvVIba_5Tzl--QqblJkpnZ&index=8&ab_channel=FlutterMapp
자바 환경변수 손쉽게 변경
https://blog.naver.com/writer0713/221266129828
e.printStackTrace() 보다는 로거 사용
try {
process();
} catch (IOException e) {
//e.printStackTrace()
log.error("fail to process file", e);
}
로깅 프레임워크를 이용하면 파일을 쪼개는 정책을 설정할 수 있고, 여러 서버의 로그를 한곳에서 모아서 보는 시스템을 활요할 수도 있습니다. log.error()메서드에 Exception객체를 직접 넘기는 e.printStackTrace()처럼 Exception의 스택도 모두 남겨줍니다. 에러의 추적성을 높이기 위해서는 e.toString()이나 e.getMessage()로 마지막 메시지만 남기기보다는 전체 에러 스택을 다 넘기는 편이 좋습니다
https://www.slipp.net/questions/350
자바 프로그래머가 자주 실수 하는 10가지
https://bestalign.github.io/translation/top-10-mistakes-java-developers-make-1/
https://bestalign.github.io/translation/top-10-mistakes-java-developers-make-2/
일반 배열을 ArrayList로 변환하기
List<String> list = Arrays.asList(arr);
Arrays.asList()는 Arrays의 private 정적 클래스인 ArrayList를 리턴한다. java.util.ArrayList 클래스와는 다른 클래스이다. java.util.Arrays.ArrayList 클래스는 set(), get(), contains() 매서드를 가지고 있지만 원소를 추가하는 매서드는 가지고 있지 않기 때문에 사이즈를 바꿀 수 없다. 진짜 ArrayList를 받기 위해서는 다음과 같이 변환하면 된다:
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(arr));
진짜 충격적이었던 사실.. 나만 몰랐던 것이었을까...
자바 9에 추가된 간단하게 불변컬렉션 지원해주는 of()메서드를 사용하자
List.of(), Set.of(), Map.of()초심자가 저지르기 쉬운 DB 코딩 실수 3가지
https://www.youtube.com/watch?v=n85UzIReFjY&ab_channel=%EC%B5%9C%EB%B2%94%EA%B7%A0
슈퍼 DTO 사용 금지
조금 귀찮아도 각 메서드에 맞는 별도 파라미터 타입을 정의하는 게 더 좋은 길이다. 이 부분은 정말 공감이 많이 가는 이야기다. HashMap으로 던지는 건 정말 최악이고, 그보다 덜 최악은 슈퍼 DTO를 만드는 것이다. (그나마 슈퍼 DTO는 적어도 이 어플이 어떤 필드를 사용하는지 대략적으로 감은 잡을 수 있으니까...) 뜬금없는 이야기지만, ORM을 사용하면 위의 팁을 적용하기 좀 수월해지는 느낌이 있다.
https://www.youtube.com/watch?v=MIYwej-VodE&ab_channel=%EC%B5%9C%EB%B2%94%EA%B7%A0
DB 유령읽기 주의
@Trasaction을 걸었다고 치더라도, DB 격리 수준이 기본적으로는 REPEATABLE READ인 경우가 많기 때문에, 유령읽기 현상을 막을 수는 없다.
https://catch-me-java.tistory.com/60?category=438116
로그를 잘 찍자
로그는 정말정말 중요하다.. 지금은 주먹구구식으로 하고 있지만 언젠가 로그 모니터링 시스템을 꼭 도입해야겠다.
https://www.youtube.com/watch?v=HxzlJWMcHng&t=668s&ab_channel=%EB%B0%B1%EA%B8%B0%EC%84%A0
어떤 분의 레거시 코드 개선경험
https://blog.sogoagain.com/posts/2020/continuous-improvement-legacy/
Jackson 어노테이션 사용법
https://github.com/cheese10yun/blog-sample/tree/master/jackson
@TransactionalEventListener를 고려..
https://sabarada.tistory.com/188
후기
책의 내용을 소화하려면 한참 곱씹어서 읽어야겠다. 읽은대로 업로드는 계속 할 거다..
