본 글은 최원영 저 "아파치 카프카 애플리케이션 프로그래밍 with 자바"를 기반으로 작성되었습니다.
저자 github 주소
https://github.com/bjpublic/apache-kafka-with-java
프로듀서 API
앞선 포스트에서 카프카를 설치하고 로컬 터미널에서 브로커로 토픽을 생성하여 레코드를 전송하는 것까지 실행해보았다.
이번에는 Java를 이용하여 카프카 클라이언트 라이브러리의 프로듀서 API를 이용하여 프로듀서 애플리케이션을 만들어 실행해보려 한다.
IntelliJ를 이용하여 실행하였다.
우선 New Project 버튼을 통해 simple-kafka-producer라는 이름으로 프로젝트를 생성한다. 여기서 빌드 자동화 도구(Java, Maven, Gradle etc.) 중에서 Gradle을 선택하여 진행한다.
build.gradle 수정
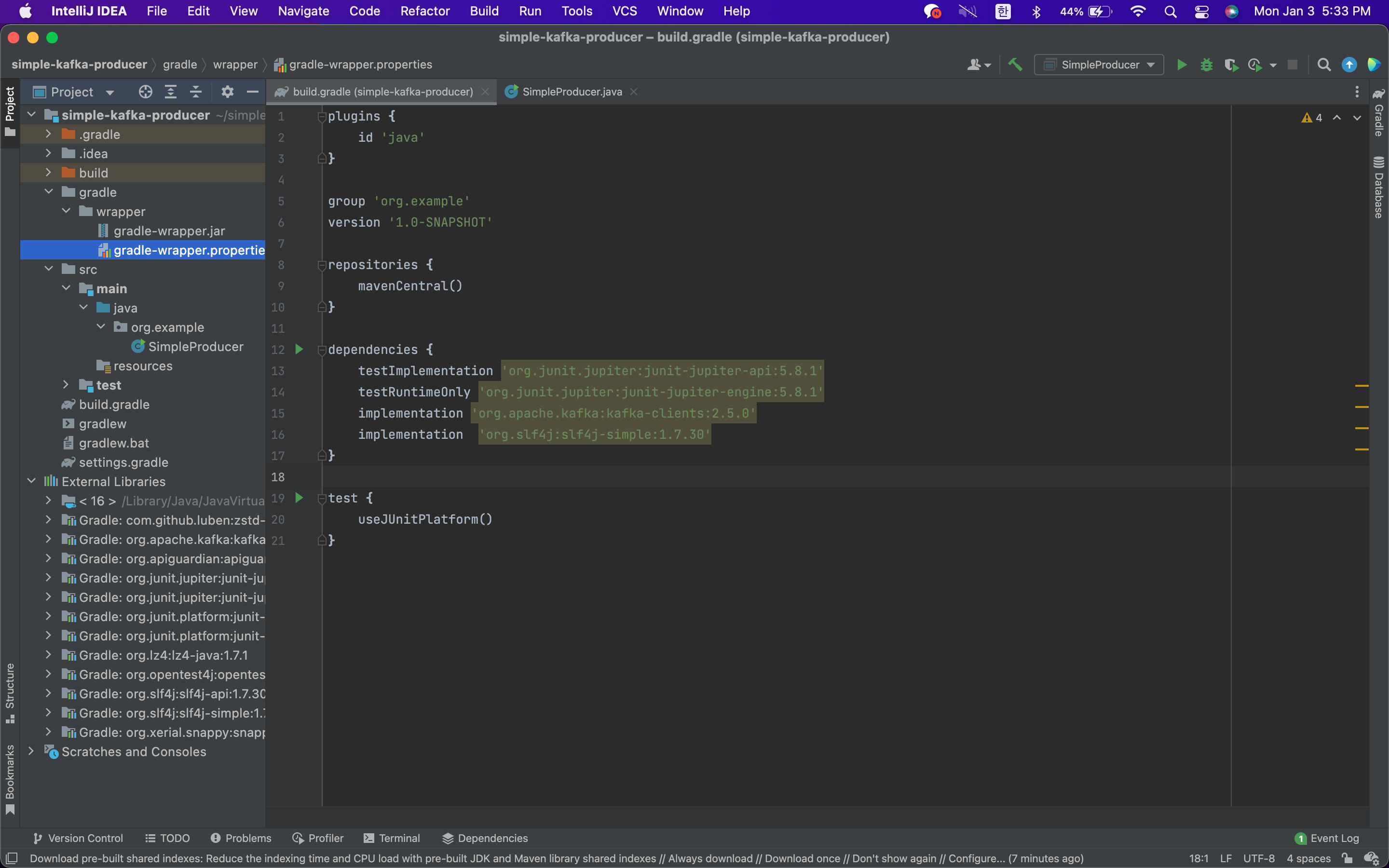
다른 부분은 모두 괜찮을 것이지만, dependencies 부분을 수정해줘야 한다. 책에는
compile 'org.apache.kafka:kafka-clients:2.5.0'
compile 'org.slf4j:slf4j-simple:1.7.30'이라고 되어있으나 현재 시점(2022/01/03) 기준으로 JDK 16을 사용하고 가장 최근 IntelliJ 버전 및 Gradle 7.1 버전에서는 무슨 이유에서인지 compile 메서드가 없다고 나오면서 오류를 출력했다.
compile 명령어를 implementation으로 바꿔주니 잘 작동했다.
implementation 'org.apache.kafka:kafka-clients:2.5.0'
implementation 'org.slf4j:slf4j-simple:1.7.30'위의 코드를 buil.gradle파일의 dependencies 부분에 추가해주고 리프레시를 해주면 External libraries에 kafka와 slf4j 라이브러리가 잘 설치된 것을 확인할 수 있다.
Producer class 작성
저자의 github에 필요한 소스코드가 모두 올라와있다. 직접 가서 확인해보는 것도 좋을 것 같다.
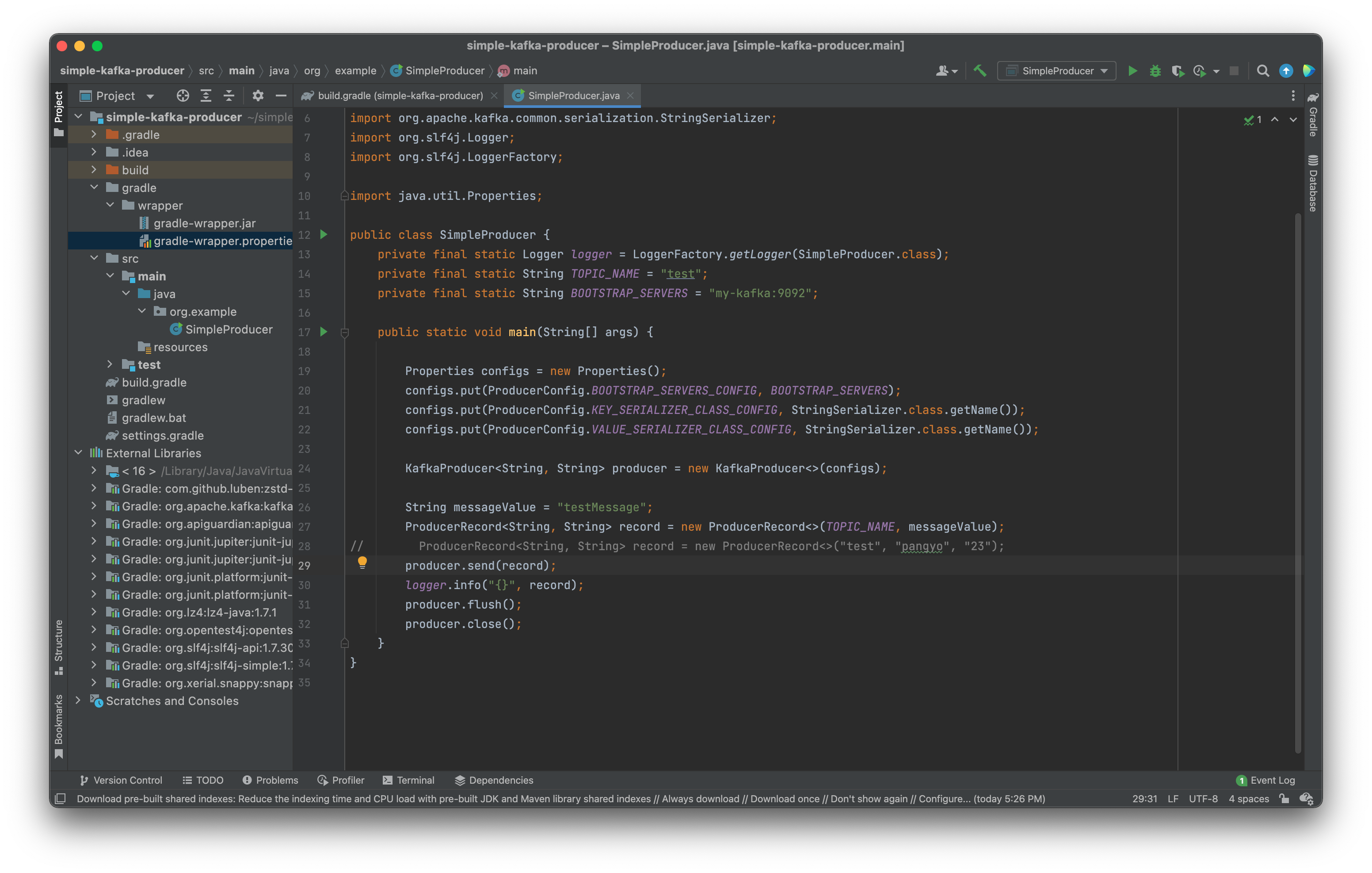
simple-kafka-producer/src/main/java 폴더 안에 org.example 패키지를 하나 생성하고 그 안에 SimpleProducer class 파일을 생성하였다.
본인의 패키지에 맞게 package 코드 부분을 수정한 이후, TOPIC_NAME을 보내려는 토픽 이름으로 수정하고 BOOTSTRAP_SERVERS 상수의 "my-kafka"부분을 본인의 서버 IP에 맞게 수정해주면 잘 작동한다.
// package name can be modified
package org.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
public class SimpleProducer {
private final static Logger logger = LoggerFactory.getLogger(SimpleProducer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "my-kafka:9092";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
String messageValue = "testMessage";
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, messageValue);
producer.send(record);
logger.info("{}", record);
producer.flush();
producer.close();
}
}"test"이란 이름의 토픽에 키값이 null이고, value값이 "testMessage"인 레코드를 전송하였다.
키 값을 지정해주고 브로커로 보내고 싶다면,
ProducerRecord<String, String> record = new ProducerRecord<> ("topic", "key", "value");이런 식으로 키 값을 인자로 넣어줄 수 있다.
토픽의 몇 번 파티션으로 보낼지 정해주고 싶다면,
ProducerRecord<String, String> record = new ProducerRecord<> ("topic", "partitionNo", "key", "value");이런 식으로 파티션 번호를 인자로 넣어줄 수 있다.
Custom Partitioner
KafkaProducer 객체에 따로 Custom Partitioner 클래스를 넣어주지 않는다면, Kafka 2.4.0 버전부터는 디폴트 값으로 UniformStickyPartitioner가 들어가게 된다.
이전의 RoundRobinPartitioner의 단점을 보완한 파티셔너로, 데이터가 배치로 모두 묶일 때까지 기다렸다가 배치로 묶인 데이터를 모두 동일한 파티션에 전송하는 방식이다.
Custom Partitioner 클래스를 작성하고 싶다면 카프카 클라이언트에서 제공하는 Partitioner 인터페이스를 구현하여 커스텀 클래스를 구현해야 한다. 그 이후 구현된 클래스를 Kafka producer 객체의 인자에 넣어주는 방식으로 Custom Partitioner 구현이 가능하다.
커스텀 예시(저자의 github에 올라와 있는 코드)
package org.example;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.InvalidRecordException;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes,
Cluster cluster) {
if (keyBytes == null) {
throw new InvalidRecordException("Need message key");
}
if (((String)key).equals("Pangyo"))
return 0;
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void configure(Map<String, ?> configs) {}
@Override
public void close() {}
}위와 같이 커스텀 클래스를 만들어 producer 클래스 파일의 Properties 객체에 put 메서드로 인자를 추가해준다.
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);참고로 위의 예시는 "Pangyo"라는 문자열이 key값으로 들어오면 무조건 0번 파티션에 저장하는 커스텀 파티셔너 클래스이다.
브로커 정상 전송 여부 확인하는 프로듀서
KafkaProducer의 send() 메서는 Future 객체를 반환한다. get()메서드를 사용하여 Future 객체를 RecordMetadata 클래스로 받아오면 보낸 데이터의 결과를 동기적으로 받아올 수 있다.
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, messageValue);
RecordMetadata metadata = producer.send(record).get();
logger.info(metadata.toString());비동기적으로 전송 결과를 받아오기 위해서는 Callback 인터페이스를 구현하는 콜백프로듀서 클래스를 작성해야 한다.
동기 vs. 비동기
동기적으로 매번 전송결과를 받아오게 되면 속도가 느려질 수 있다. 브로커의 전송 결과에 대한 응답을 매번 기다려야 하기 때문이다.
그렇지만 비동기적이 항상 좋은 것도 아니다. 데이터의 순서가 중요한 경우 사용하면 안 된다. 비동기로 결과를 기다리는 동안 다음 차례의 데이터의 전송이 성공하고 앞서 보낸 데이터의 결과가 실패할 경우 재전송으로 인해 데이터 순서가 역전될 수 있기 때문이다.
따라서 상황에 알맞게 사용해야 한다.
