Non Clustered
1
2 3 4
Clustered
1
2 3 4
Heap Table [ {page} {page} ]
북마크 룩업
Leaf Page 탐색은 여전히 존재하기 때문
[레벨, 종족] 인덱스 (56, 휴먼)
이럴 경우 (56, 휴먼)이 하나만 있는게 아니라 엄청 여러개가 나올 수 있어서
이럴 때 인덱스의 컬럼 순서가 중요하다는 것이다.
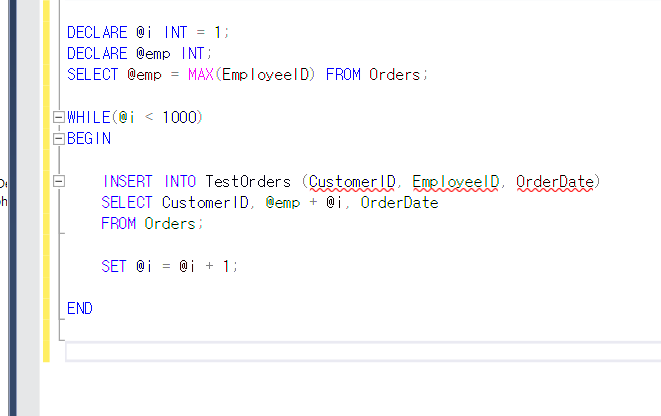
일단 이까지 만들어 놓고 추가를 해주도록 하자.
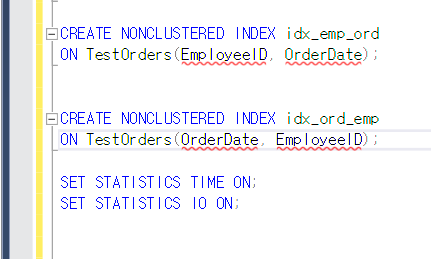
그리고 뭐가 더 빠른 인덱스인지 확인하기 위해 인덱스 두개 만든다.
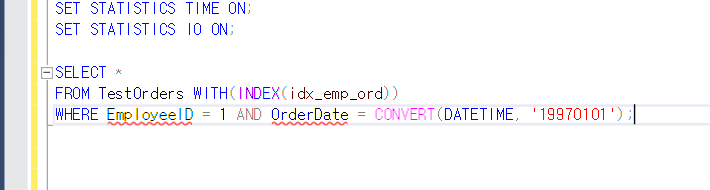
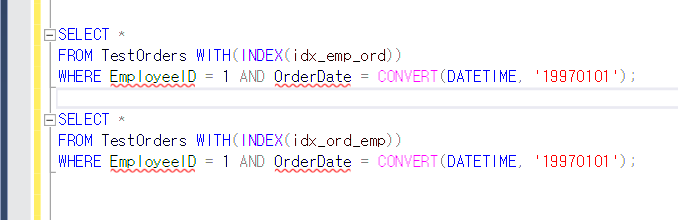
이렇게 한 후 두개를 실행해보면
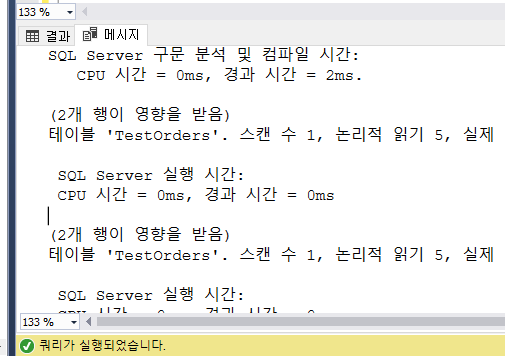
논리적 읽기 수는 정확히 일치한다.
그러면 이게 왜 똑같이 나왔는지 중요하니까
직접 살펴보도록 하자.

결론은 이렇게 한다고해서 큰 성능 차이는 없다.
그런데
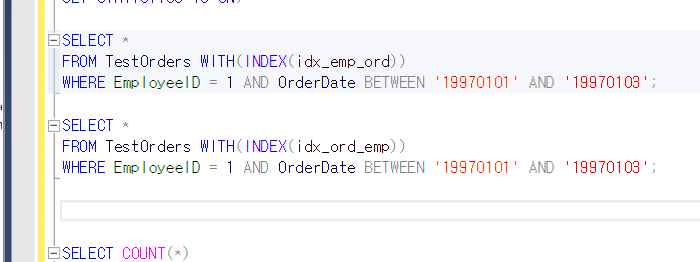
이렇게하고 메세지보면은

논리적 읽기 수가 거의 3배까지 차이가난다!
이게
idx_emp_ord는 emp순으로 먼저 찾은다음에 OrderDate를 보는 반면
idx_ord_emp는 orderdate부터 쭈루루루루릭 다 찾고
그다음 EmployeeID를 보기때문이다.
정리
복합 Index ( a, b, c )로 구성되있을 때, 선행에 BETWEEN 사용 == 후행은 인덱스 기능 X
a 에서 BETWEEN을 사용했으면 b, c는 더이상 index기능을 사용못하는 것.
그래서 BETWEEN을 사용할꺼면 후행에다가 (b, c)에다가 잘 걸어 줘야한다.
IN LIST
BETWEEN 범위가 작을 때 사용
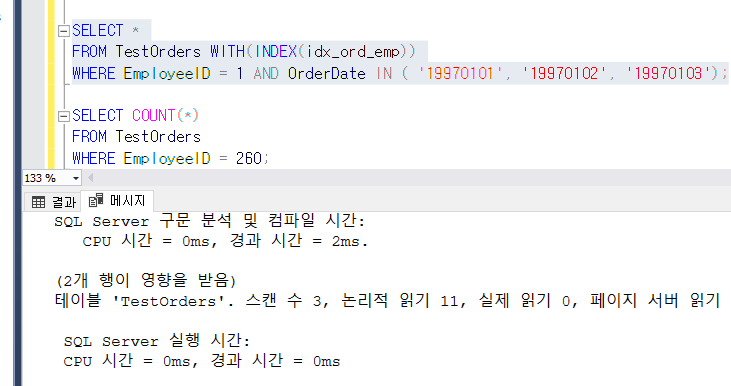
논리적 읽기가 11번을 줄어듦
그런데
IN LIST를 할 떄도 무작정 하는 게 아니다.
오늘의 결론
복합 컬럼 인덱스 (선행, 후행) 순서가 영향을 줄 수 있음
BETWEEN, 부등호 (<, >) 선행에 들어가면 후행은 인덱스 기능 상실함.
BETWEEN 범위가 작으면 IN LIST사용하면 좋을 때가 있다.

https://cjbworld.tistory.com/ <- 이사중