
객관식 10(4지 선다), 주관식 5(단답형) : 총 30점 만점
9주차 인덱스와 프로시저
DDL, DML, DCL, TCL
-
DDL : 데이터 정의어 ( 설계/관리 )
CREATE, ALTER, DROP, RENAME, TRUNCATE, COMMENT
-
DML : 데이터 조작어 ( 빈도 가장 높음 )
SELECT, INSERT, UPDATE, DELETE, MERGE
-
DCL : 데이터 제어 언어 ( 빈도 낮음 )
GRANT, REVOKE
-
TCL : 트랜잭션 제어 언어
COMMIT, ROLLBACK, SAVEPOINT
1. 인덱스란?
빠른 검색을 위한 참조 데이터
ex) SELECT 문에서 키는 인덱스 -> 키없는 검색 "풀스캔"
많은 데이터 속에서 "인덱스"를 통해 필요한 데이터를 성능부화를 적게 일으키고 찾을 수 있다.
(데이터가 적다면 안 사용해도 된다.)
2. 인덱스의 종류
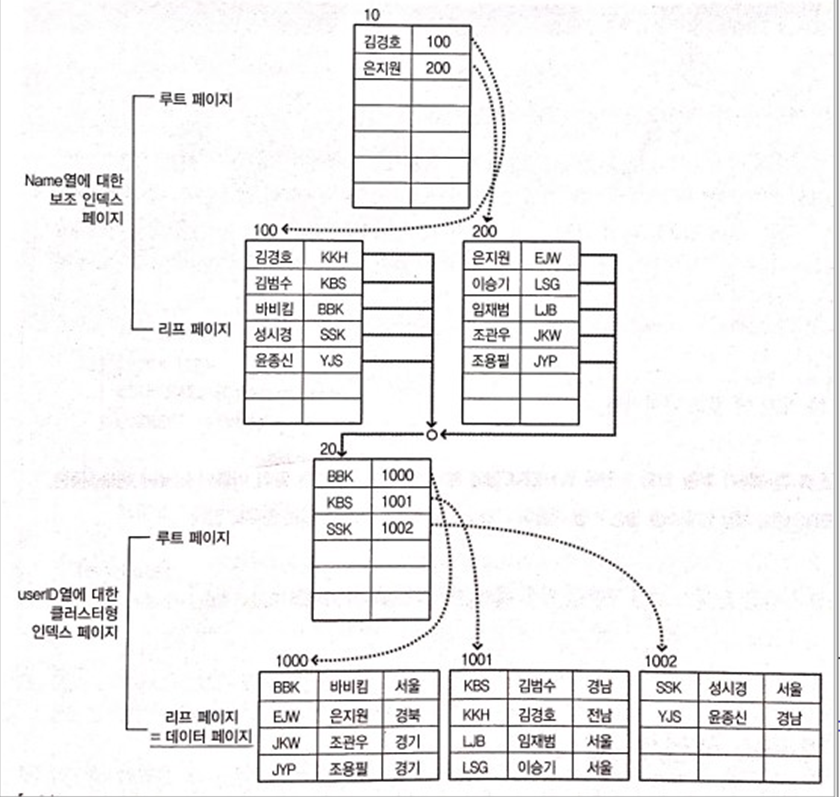
1. 클러스터형
ID 1개 = 클러스터형 인덱스
2. 비 클러스터형
로그인 키, 닉네임, 이메일 3개 = 보조(비 클러스터) 인덱스
3. 알고리즘 지원 : INNO DB = B + TREE(기본)
mysql의 기본 알고리즘은 INNO DB이다 == B TREE이다.
INNODB는 mysql의 "스토리지 엔진"의 한 종류인데 가장 많이 사용하는 것임.
4. 클러스터 인덱스 동작 방식
클러스터형 인덱스 동작(검색에서 속도 효율적)
인덱스 키 기준 오름차순 정렬(루트, 리프), 최소 2번 검색
루트, 리프 = 데이터 페이지(참고 : 노드)
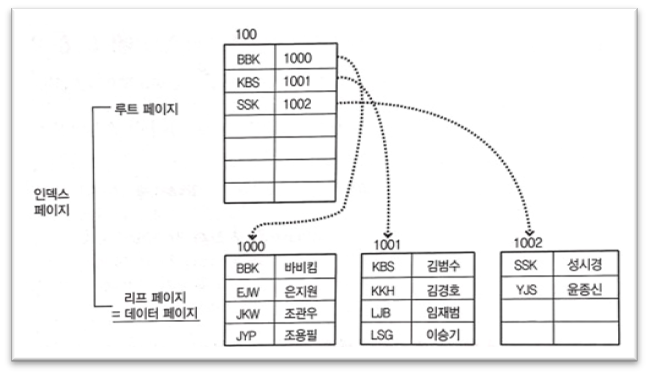
5. 비 클러스터 인덱스 동작 방식
루트, 리프, 데이터 페이지(별개), 최소 3번 검색
리프가 데이터가 위치한 주소값
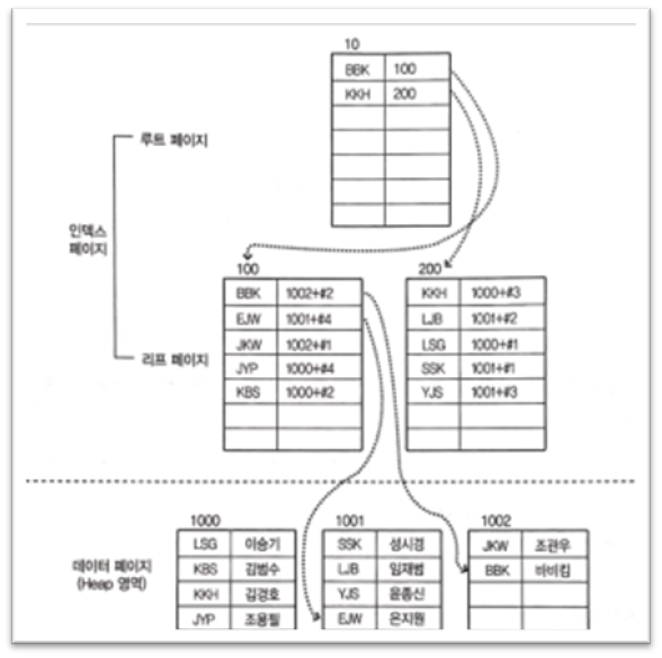
6. 클러 + 비 클러 인덱스 혼합이 일반적
앞서 WP_USER는 혼합이다. 동작 과정이 복잡해진다. (코멘트 링크 참조)
7. BUT
삽입/수정/삭제 동작시
- 클러 : 재정렬로 비용이 "비효율적"
- 비 클러 : 데이터 페이지 내용 삽입/수정/삭제 => 페이지 분할이 생기지 않음
8. 쿼리 실행
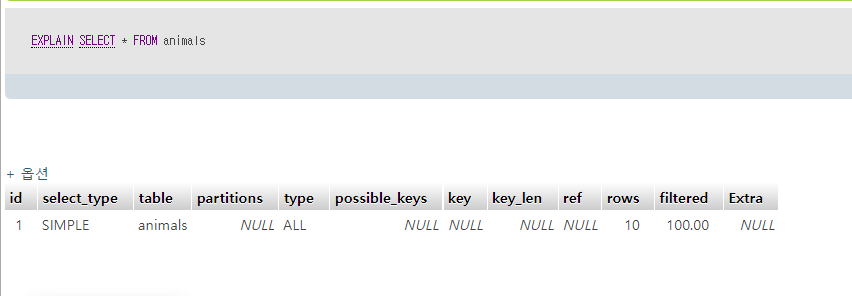
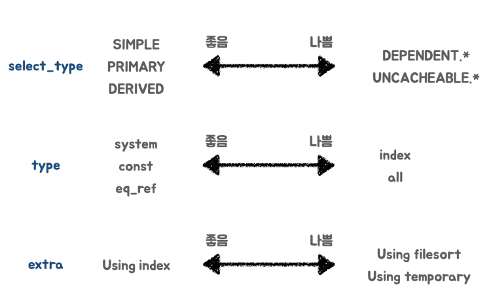
type = ALL
풀스캔이다.
possible_key : 선택된 키 => 없다.
9. 부분 검색
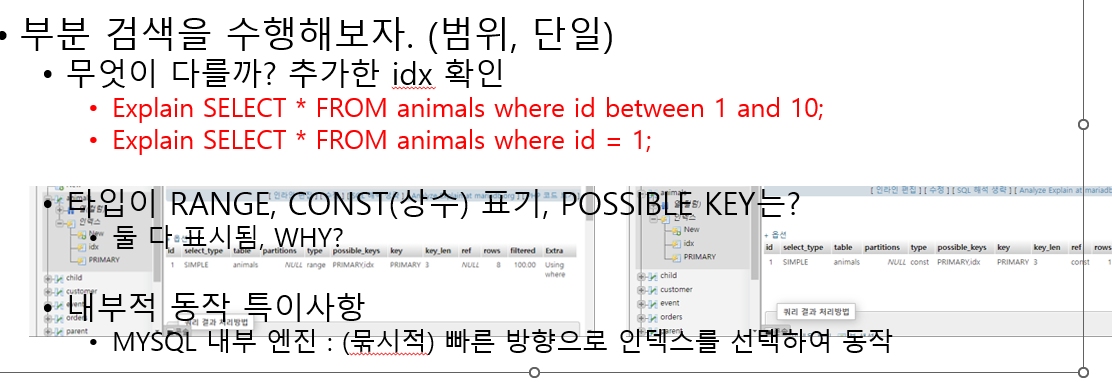
해당 빨간줄 쿼리 실행했을 경우
-
범위로 쿼리 실행할 시
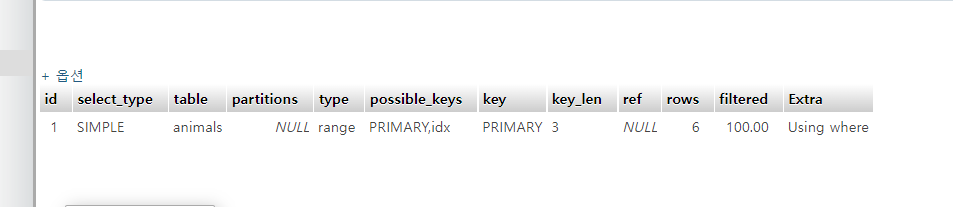
-
단일로 쿼리 실행할 시
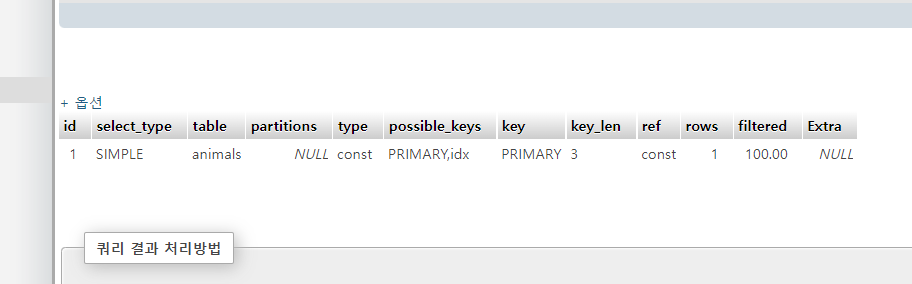
type이 range, const가 나오고
ref가 NULL, const로 나온다.
Extra도 다름
내부적 동작 특이사항
MYSQL 내부 엔진 : (묶시적) 빠른 방향으로 인덱스를 선택하여 동작
10. REF, POSSIBLE KEY ?
-
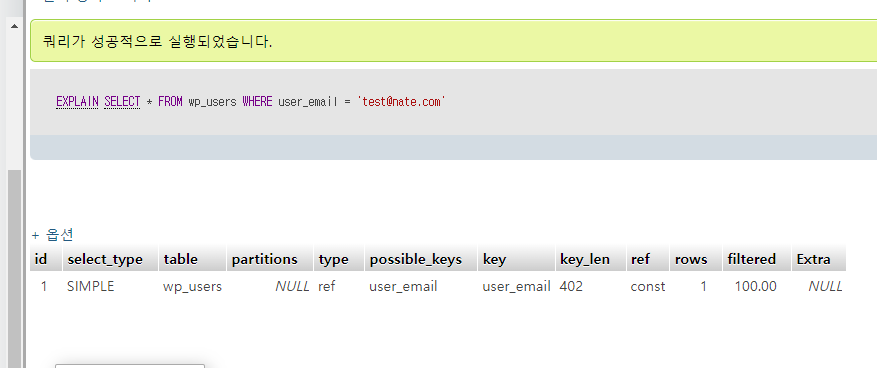
ref : 여러행을 검색할 가능성이 있는 접근 ( 이메일의 모든 열 읽음 )
-
중요! : 인덱스로 설정된 컬럼 이름을 검색할 때 -> 인덱스 키 활용됨.
MYSQL은 단일 const 다음으로 REF로 접근이 일반적
단일 검색이라 ref가 const임
범위였으면 range 이였을 것이다.
11. 주의 사항!
데이터베이스에서 가장 접근이 많고, 용량이 큰 테이블만 사용
추가/수정/삭제 = 인덱스도 갱신되어 "성능이 떨어질 수 있다".
인덱스 관리에 대한 비용 부담 문제가 존재한다.
인덱스 필드도 char, int가 varchar에 비해 더 빠름
문제 Q/A – 인덱스와 왜래키
객관식 : 테이블 설계 시 인덱스와 관련된 설명으로 부적절한 것 ?
1. INNODB 엔진은 기본 B-Tree(B+TREE) 인덱스로 되어있음
맞는 설명이다.
2. 외래키 설정되어 있는 경우 인덱스가 없으면 삽입/삭제/수정에 부하가 생김
삽입/삭제/수정 할 경우 인덱스는 "재정렬"을 하기 때문에 비효율적이다.
3. 인덱스의 수는 제한이 없으나, 너무 많이 만들면 오히려 성능 부하가 발생
맞는 말이다.
4. 조회(SELECT)는 일반적으로 인덱스가 유리
맞는 말이다.
ID 1개 = 클러스터형 인덱스
클러스터형 인덱스 동작(검색에서 속도 효율적)
인덱스 키 기준 오름차순 정렬(루트, 리프), 최소 2번 검색
루트, 리프 = 데이터 페이지(참고 : 노드)
이기때문에
실습 : TEMP_DB의 CHILD 테이블은 왜래키가 설정되어 있다.
1. 기본키는 인덱스로 동작했다. 왜래키는 인덱스로 동작할까?
2. 확인 : EXPLAIN으로 parent_id를 검색해보자.
3. 타입 :
4. POSSIBLE KEY :
11. 프로시저와 함수
-
함수 : 복잡한 쿼리문을 미리 구현하고, 한번에 수행(캐싱)할 수 있다.
-
구조적, 리턴 값 활용 부분은 동일, 차이점은?
- 핵심은 client, Server의 의존 처리 차이 -
속도 : CLIENT보다 Server가 빠르다.
프로시져는 단독으로 수행,
함수는 단독으로 수행하지 않는다. => 분산되어있음
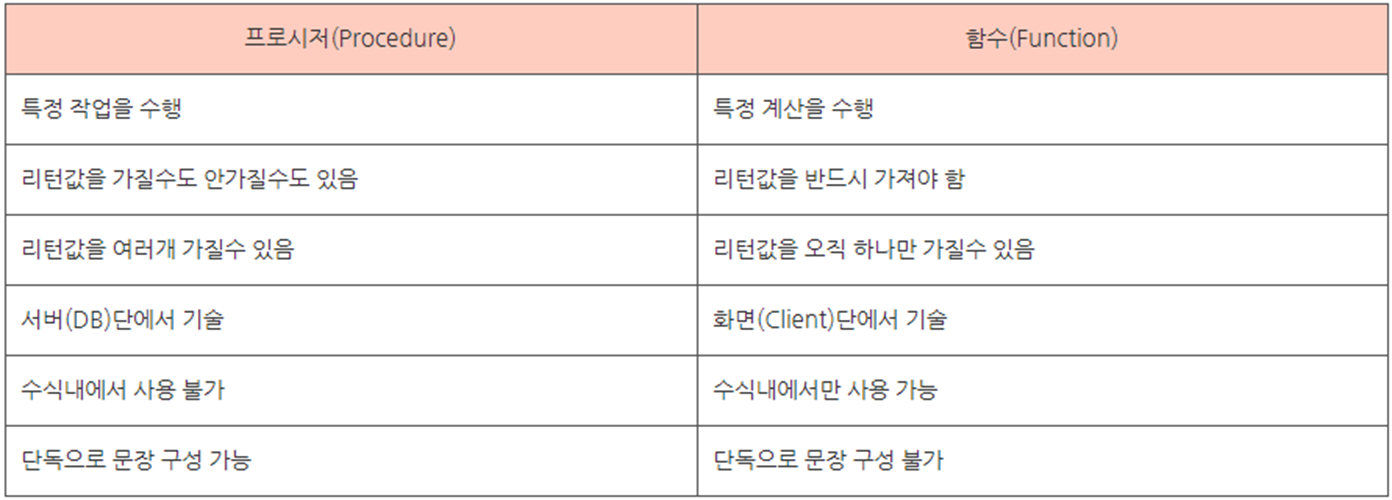
12. 함수 (변수 선언과 초기화)
함수(function)부터 살펴보자. ( IF 조건문)
이름과 나이를 입력 받아 결과를 리턴하는 예제
출력 방법 : select 함수명(인자1, 인자2);
삭제 방법 : drop function 함수명;
참고 : CONCAT (문자열 합차는 함수)
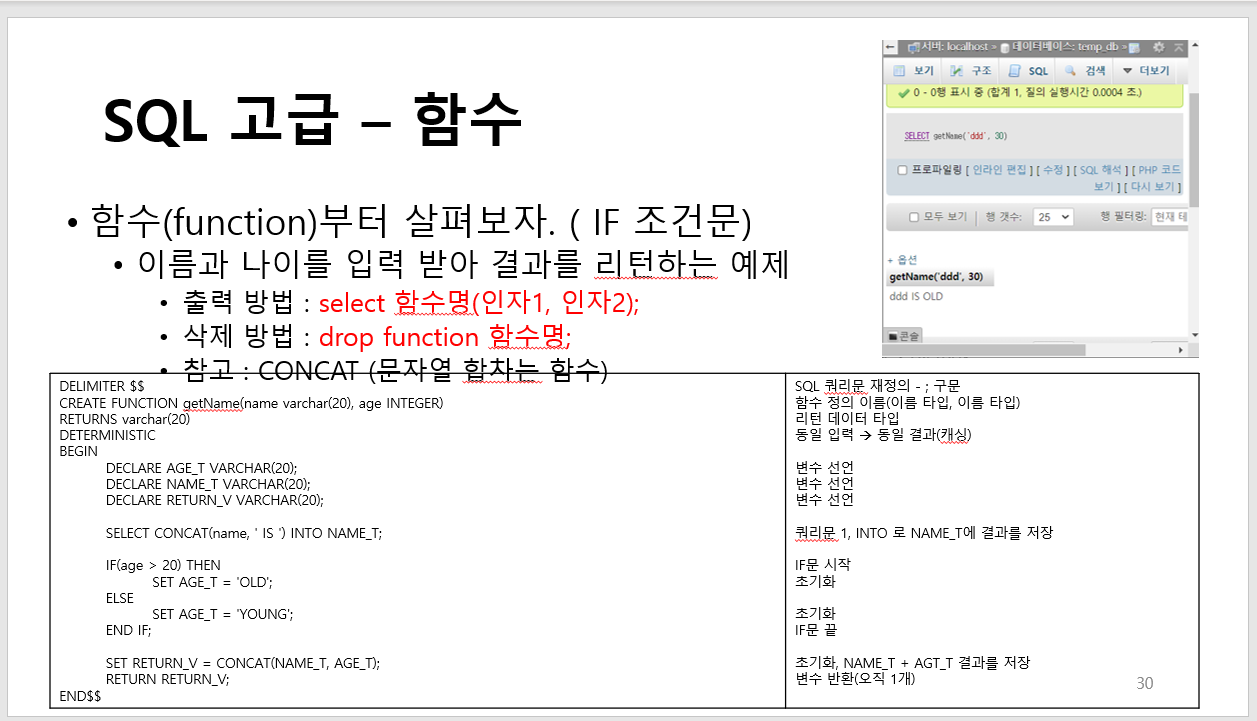
13. 프로시져
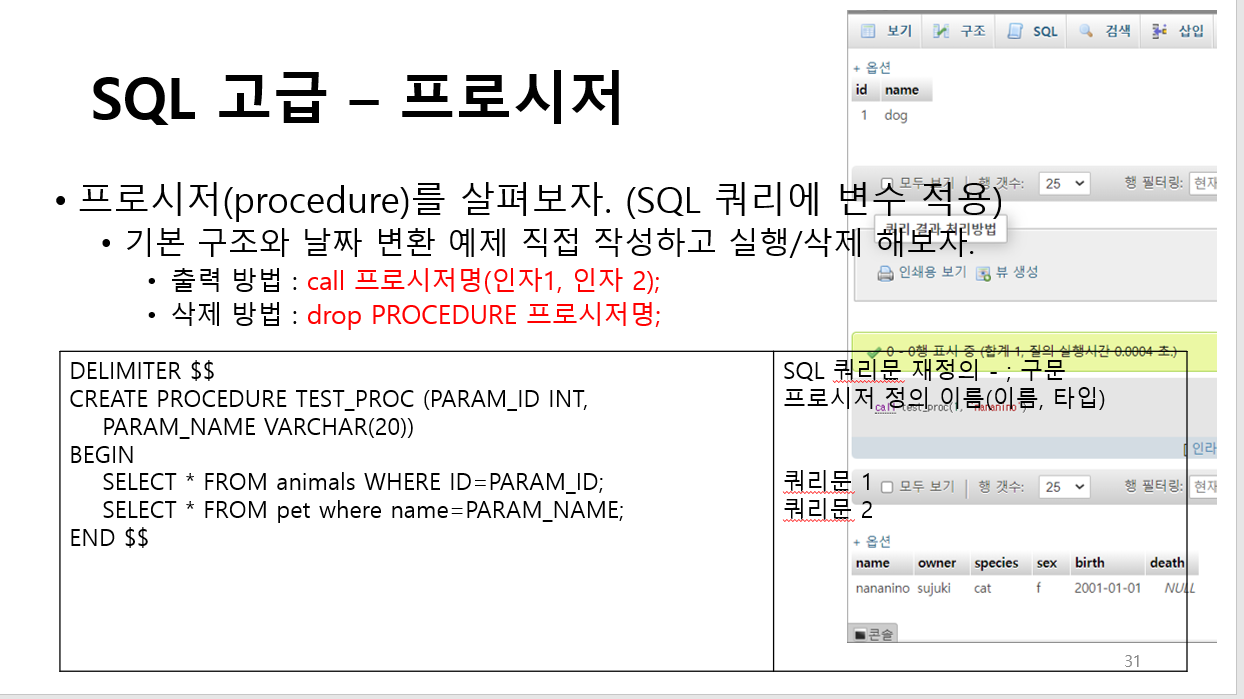

14. 프로시져의 전용 매개변수
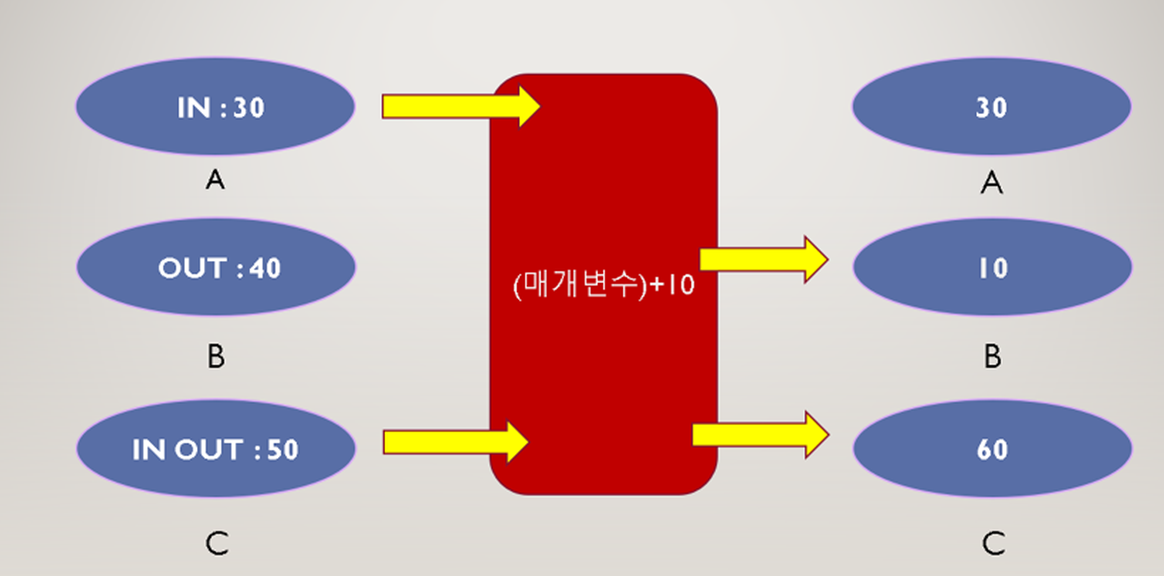
1. IN(기본)
A : 30은 내부에서 40을 RETURN하고 끝, A값은 유지
2. OUT
B:40은 내부에 전달되지 않고, 0 + 10 결과만 B에 저장
3. IN + OUT
C:50은 내부에 전달, 결과도 C에 전달
프로시저 살펴보기

-
방향 : 기본설정은 IN
-
보안 타입 : DEFINER(기본) - 함수도 보안 기능 존재
-
INVOKER : 실행하는 사용자의 권한
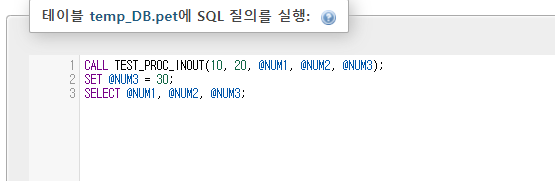
이렇게 실행하면
INOUT인 @NUM3는 값을 전달받고 그대로 출력해준다.
문제 Q/A – 함수/프로시저 작성하기
1. 객관식 : ( ) 는 다수의 SQL 쿼리를 서버측에 저장(캐시)하여 실행 할 수 있는 방식이다. 문제는 DB 언어마다 문법이 상이하여 호환성에 문제가 발생할 수 있다. 이는 ( )을 저하 시키는 원인이 될수 도 있기 때문에, 사용에 주의해야 한다.
프로시져, 성능
2. 주관식 : 사용자가 입력한 숫자에 대한 구구단을 출력하는 함수 또는 프로시저를 작성하고, 실행하시오. (이중 WHILE, SELECT 활용)
DELIMITER $$
CREATE PROCEDURE TEST_GUGU()
BEGIN
DECLARE i INT;
DECLARE j INT;
SET i = 1;
WHILE ( i < 10 ) DO
SET gugu = ''
SET k = 1;
WHILE ( k < 10) DO
SET gugu = CONCAT (gugu, " ", i, '*', k, '=', i * k);
SET k = k + 1;
END WHILE;
SET i = i + 1;
INSERT INTO GUGUDAN VALUES (gugu);
END WHILE;
END $$
10주차 프로시저와 함수
-
공통
복잡한 "쿼리"를 미리 구현하고, 한번에 수행(캐싱)이 가능
-
차이점
Client에 의존 처리 하는지 Server에 의존 처리 하는지
Client에 의존 처리 = Function, Server에 의존 처리 = Procedure -
속도
프로시져 > 함수
WHY?
프로시져는 단독으로 수행
내부에 모든 문장 존재 (Server)
내장 함수 사용시 성능 저하 문제 가능성 존재
함수는 단독 또는 부분식 => 로직이 "분산"되어있음함수, 테이블등을 참조한다. (Client)
호출 방법 차이
-
함수 : SELECT 이름
-
프로시저 : CALL 이름
날짜 입력받고 반환하기
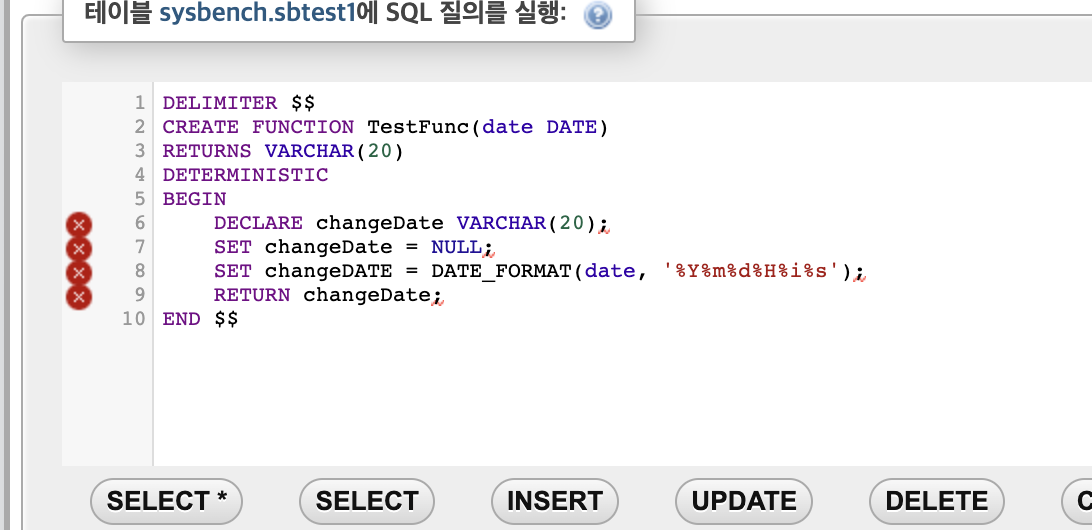
이름 입력받고 반환하기
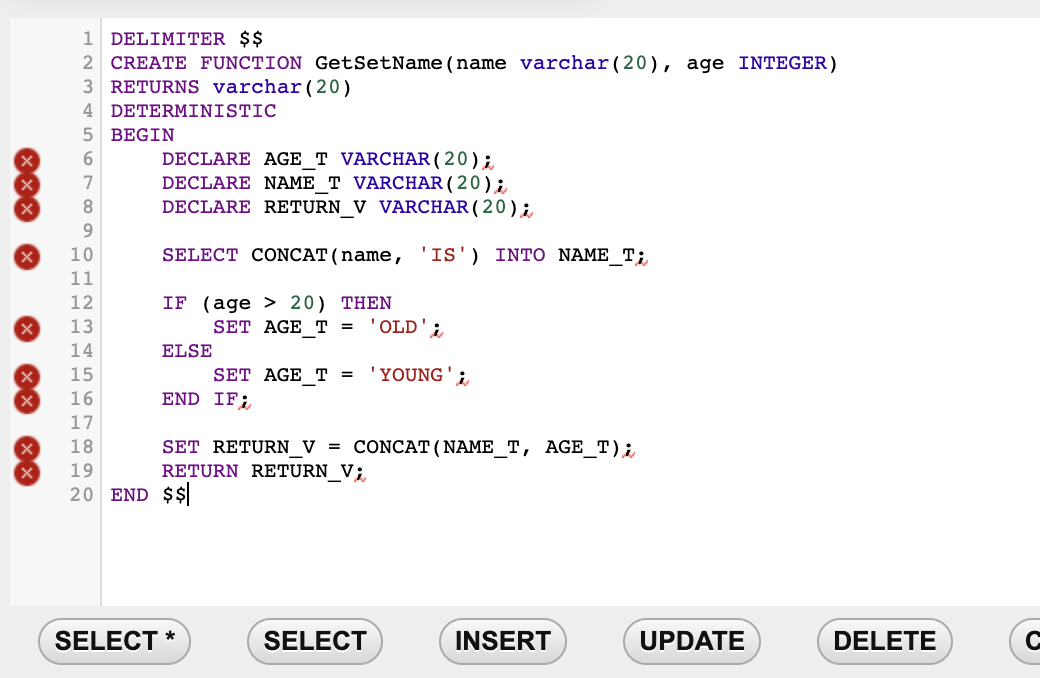
인자로 name varchar(20), age integer 입력받고
declare age_t, name_t, return_v 선언해주고
if 문에 따라 old or young 을 concat(name, 'is') INTO NAME_T
해준다.
그리고 다시 CONCAT(NAME_T, AGE_T); 해주고 마무리.
문제 : 함수 이름입력 받는 함수 작성

name VARCHAR(20),
RETURNS
BEGIN
DECLARE input VARCHAR(20),
SET input = admin is not good,
RETURN input
프로시저
-
목록 확인하기
SHOW PROCEDURE status;
-
구조 확인하기
SHOW CREATE PROCEDURE 이름
-
삭제하기
DROP PROCEDURE 이름
-
CALL 프로시저이름(인자1, 인자2)
문제 : gugu dan 프로시저 작성

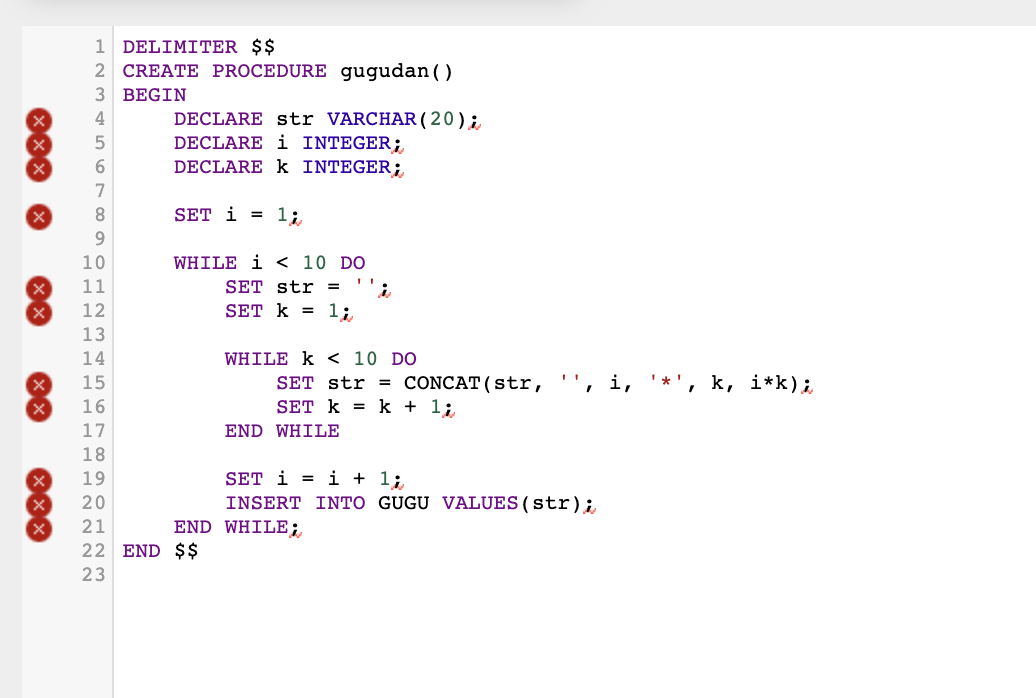
이렇게 해주도록 하자.
SQL 고급 - 프로시져
프로시져의 전용 매개변수 3가지 (3가지 방식)
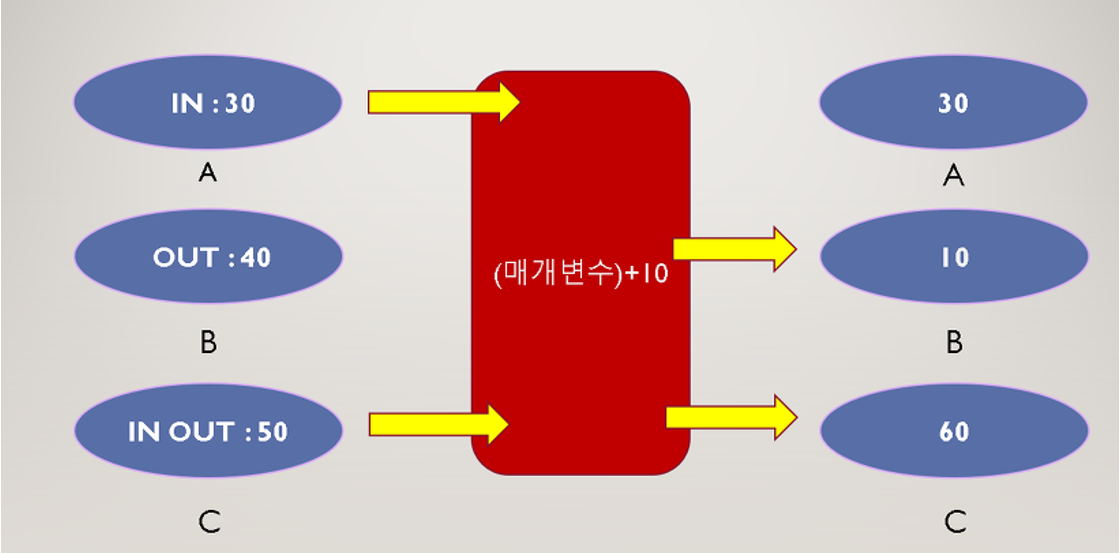
IN (default)
복사본 사용, 원본 값 유지
OUT
새로운 값 RETURN
값이 내부에 전달되지 않고 0 + 10만 전달
INOUT
IN + OUT
값이 내부에도 전달 및 외부에도 전달

현재 이 프로시져의 rst1이 out 인 경우
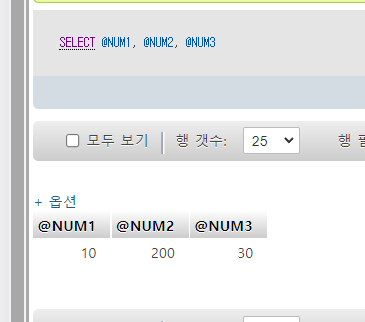
SET @NUM3 = 30;
CALL TEST_PROC_INOUT(10, 20, @NUM1, @NUM2, @NUM3);
SELECT @NUM1, @NUM2, @NUM3;
하면 출력값이
10 200 240인데

rst1 -> IN으로 수정할 경우
SET @NUM3 = 30;
CALL TEST_PROC_INOUT(10, 20, @NUM1, @NUM2, @NUM3);
SELECT @NUM1, @NUM2, @NUM3; 똑같이 실행하면
NULL 200 240 나온다! 왜=>

왜? => IN 경우는 복사본을 사용을 하고 원본값은 유지를 한다.
쿼리를 실행할 경우 @NUM1에 아무런 값을 전달해주지 않았다.
SET @NUM3 = 30; == 값 할당해줌 (IN + OUT)
@NUM2의 경우는 out이라 내부에는 전달되지않고 새로운 값을 리턴하기에
SELECT @NUM1, @NUM2, @NUM3할 경우
NULL, 200, 240이 나온다.
프로시저 살펴 보기
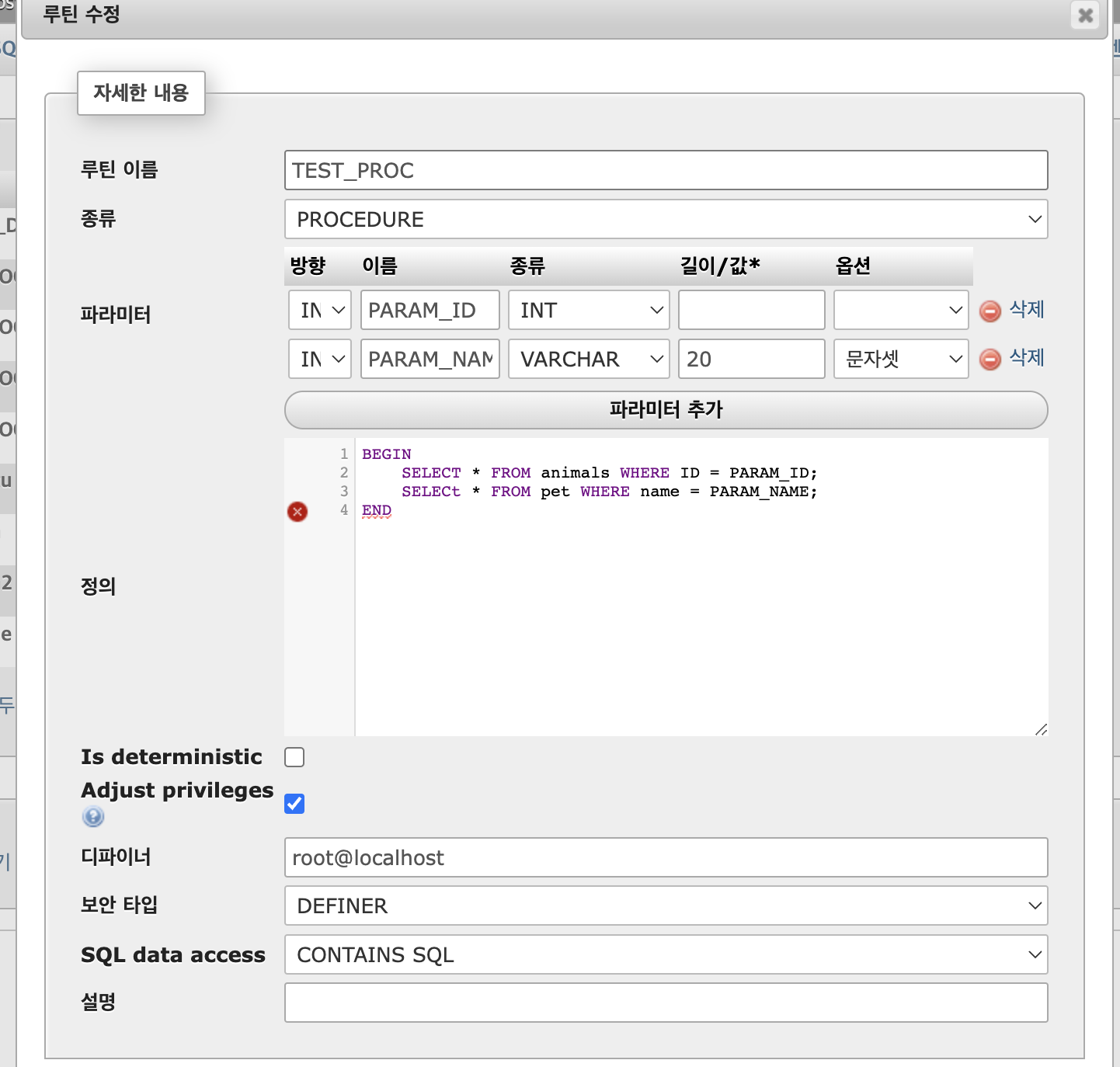
temp_db -> 프로시져 -> 수정하기
방향은 IN(기본설정은 IN이다) 함수의 경우 IN만 존재함.
보안타입 : DEFINER(기본)
11주차 SQL 성능 분석 및 최적화
sysbench를 통한 성능 분석
-
내부 .lua 스크립트를 직접 사용
스크립트 내부에는 DB 접속, 테스트 방식, 쿼리문 등을 포함
ls/usr/share/sysbench // lua 스크립트 목록 확인
OLTP 9개 종류 (read only와 read write가 일반적) -
각 실행 파일 이름 별 도움말 제공
sysbench oltp_read_only help => 읽기 전용
sysbench oltp_read_write = 읽고 쓰기 -
lua 제공 파일의 설정을 기반으로 벤치마크 수행
(11주차 ppt p14 이해가 잘 안감)
- lua 내부 설정 파일 보기
설정마다 모두 옵션, 테스트 쿼리가 조금씩 차이가 존재한다.
(lua스크립트는 테스트 방식이라서)
=> lua설정 파일의 공통 셋팅은?
cat oltp common.lua
공통 셋팅 : POINT 조회 10회, 쿼리 범위 100개
-
read 동작 (주요 조회 SELECT)
간편조회 : SIMPLE, 더하기 : SUM, 정렬 : ORDER, 중복제거 : DISTINCT
-
write 동작
인덱스 업데이트 : INDEX UPDATE
인덱스(NONE) 업데이트
삭제/삽입 : DELETE/INDERT
성능분석
-> phpmyadmin으로 이동후 쿼리 터미널창에
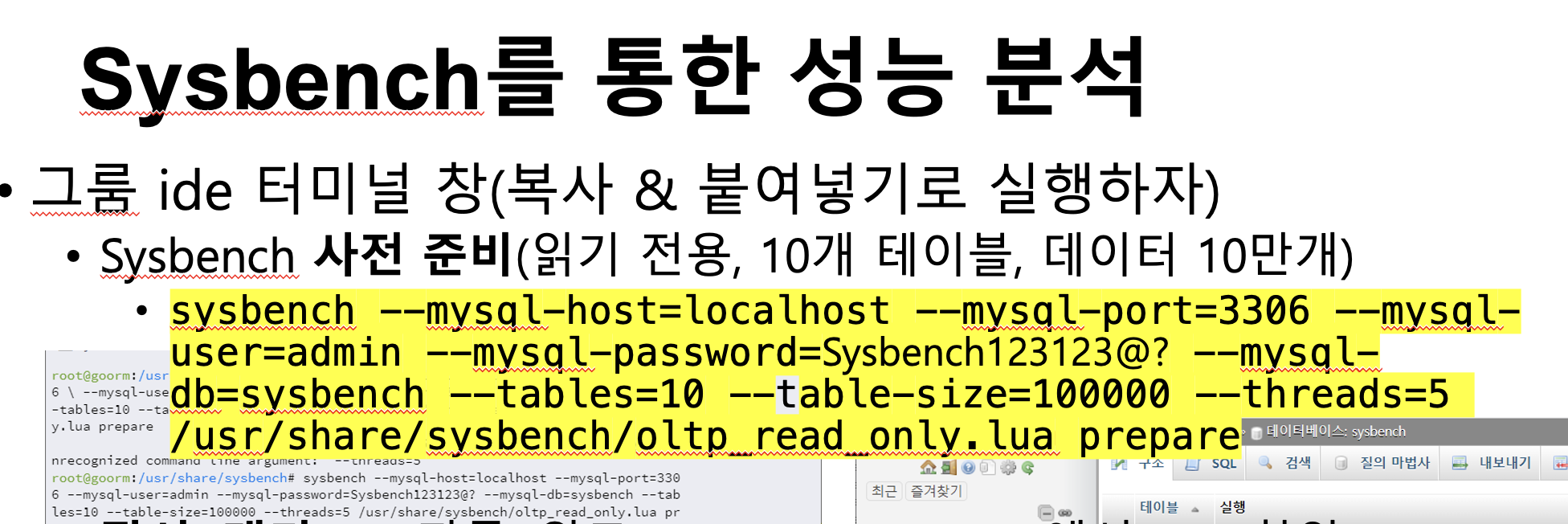
이렇게하면 10개의 테이블을 만드는데
테이블당 크기는 100000인것을 prepare한다는 말이다.
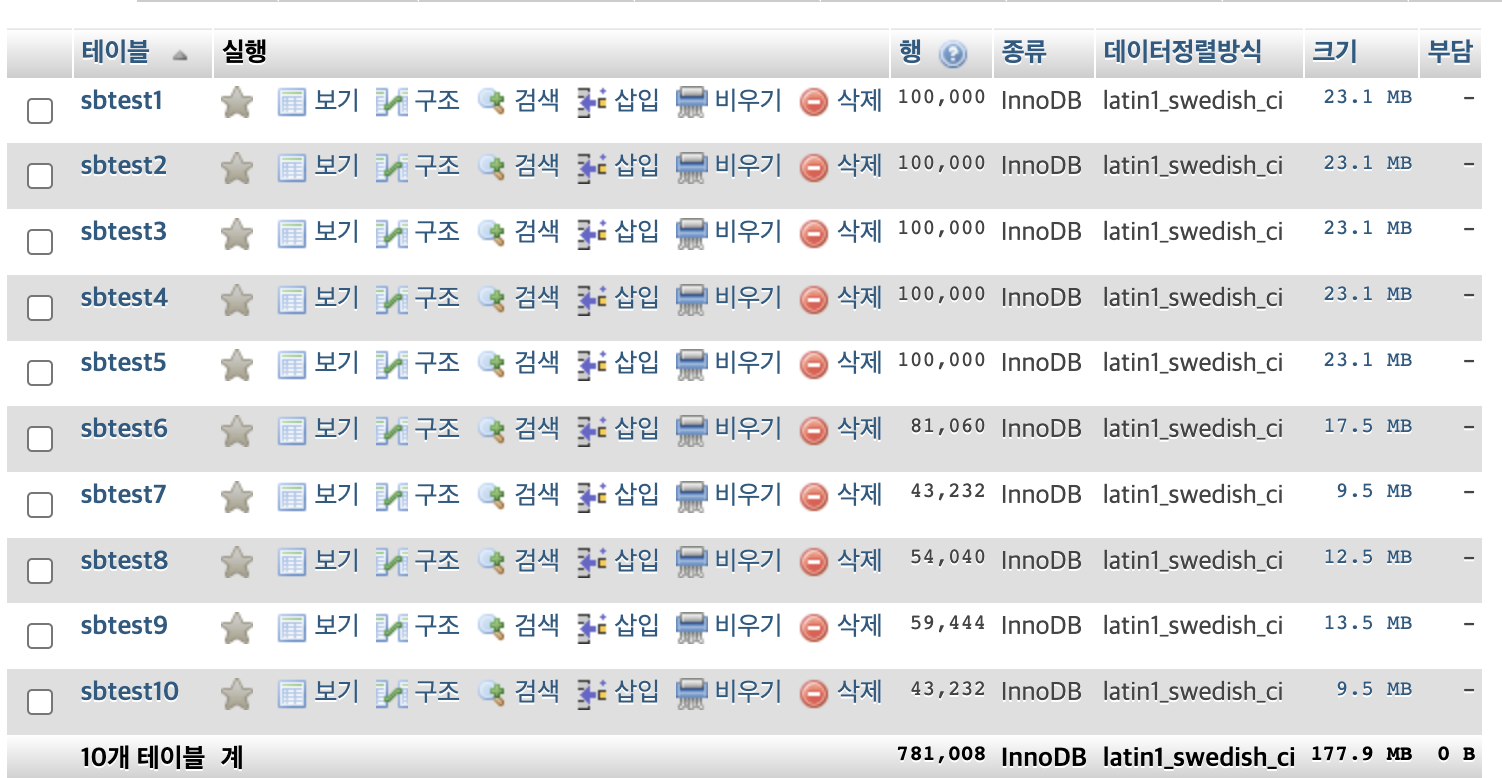
테이블 내부 구조를 살펴보자.
기본키, 인덱스, 자동 증가 세팅 확인
테이블 개수 : 10개
데티어 개수 : 10만개 기준 23mb?
(근데 sbtest7부터 10만개가 아님..? -> 왜??)
문제

- 테이블 1개 백만사이즈 만들어서 30초로 실행을 하면
10개 각각 10만개 30초 기준으로는
전체 쿼리 수행 횟수 : 10초 기준 19408, 30초 기준 60096
읽기 : 16982, 52584, 쓰기 : 없음
이정도인데
100만개 1개일 경우는
전체 쿼리 30초 기준 56000정도 (5만 중반정도)

또한 10만개일 경우 23.1MB였는데 100개일 경우 230.1MB이다.
따라서 읽기 전용기준 테이블은 "분산"과 "통합"중에
"통합"이 더 효율적이다.
최적화 SELECT
- DB의 최적화 핵심 = 조회 성능 개선
SELECT 문 검색은 쿼리문 호출 비중이 가장 높다.
최적화를 위한 주요 고려사항
-
SQL문 최적화
- 풀스캔 범위 최소화
- 기본 인덱스 설정
- 함수 인덱스
- SQL 구문 세부
-
데이터 베이스 구조
-
INNO DB 엔진
-
메모리 테이블
-
버퍼링 및 캐싱
이거 성능을 비교해볼려면 최적화 전/후 직접 테스트 및 비교밖에 답이 없다.
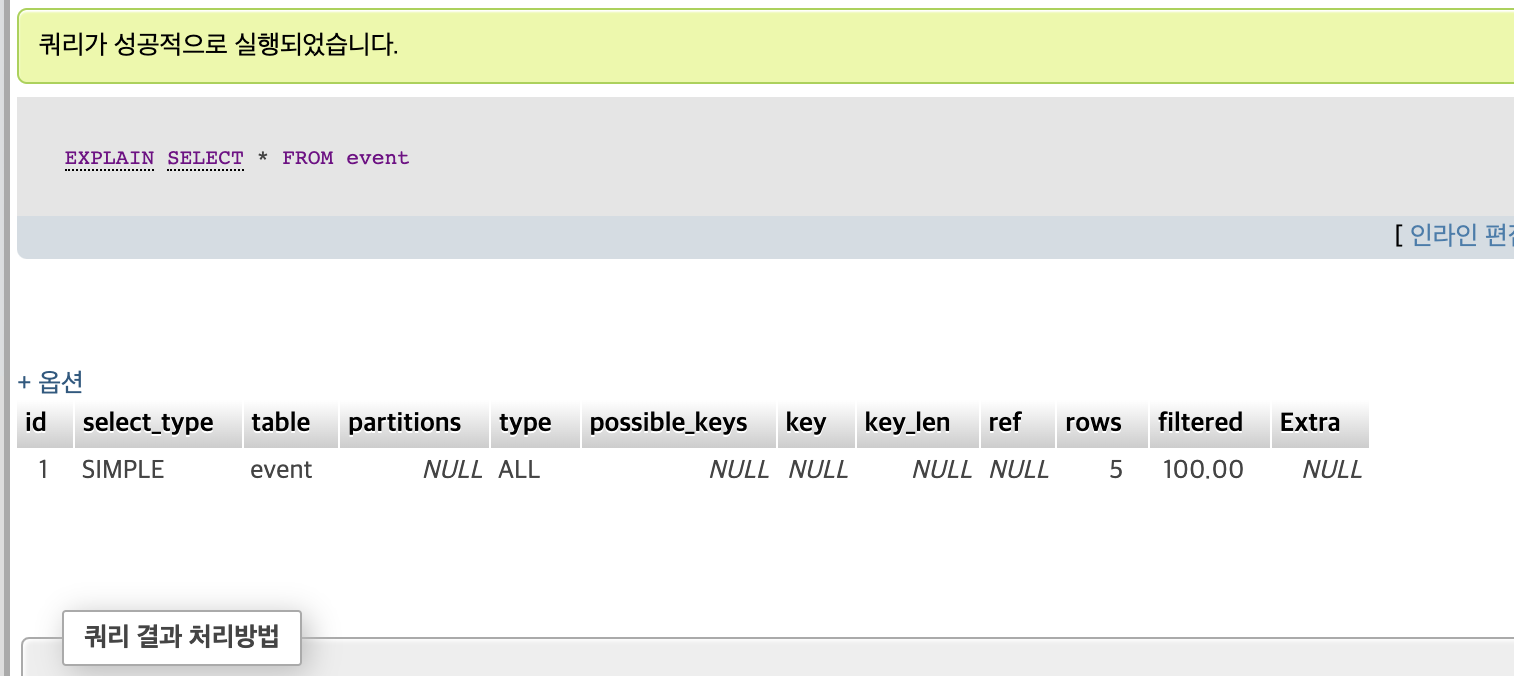
현재 temp_db의 event테이블의 경우
key = NULL이고 type = ALL(풀 스캔), ref = NULL 상태이다.
따라서
-
- 키가 없다 => 최소 KEY 설정
이후 WHERE절 추가하거나 SELECT 범위를 최소화 한다.
연선자는 자제 (INDEX 사용 불가)
- 키가 없다 => 최소 KEY 설정
-
- 키를 설정하자
event테이블의 name을 KEY로 설정
- 키를 설정하자
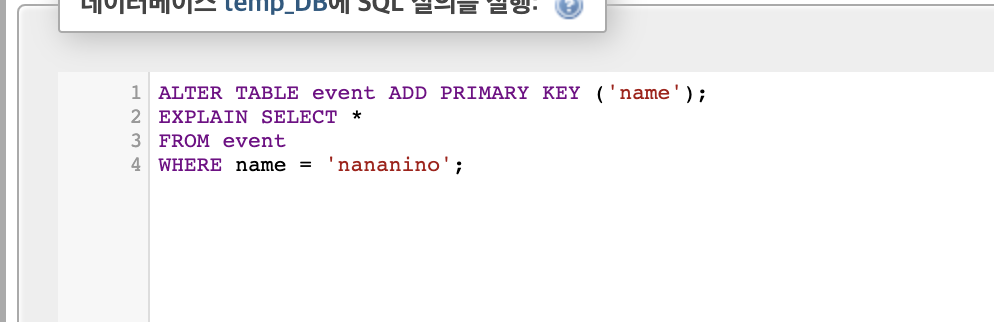
그러면 실행해주면
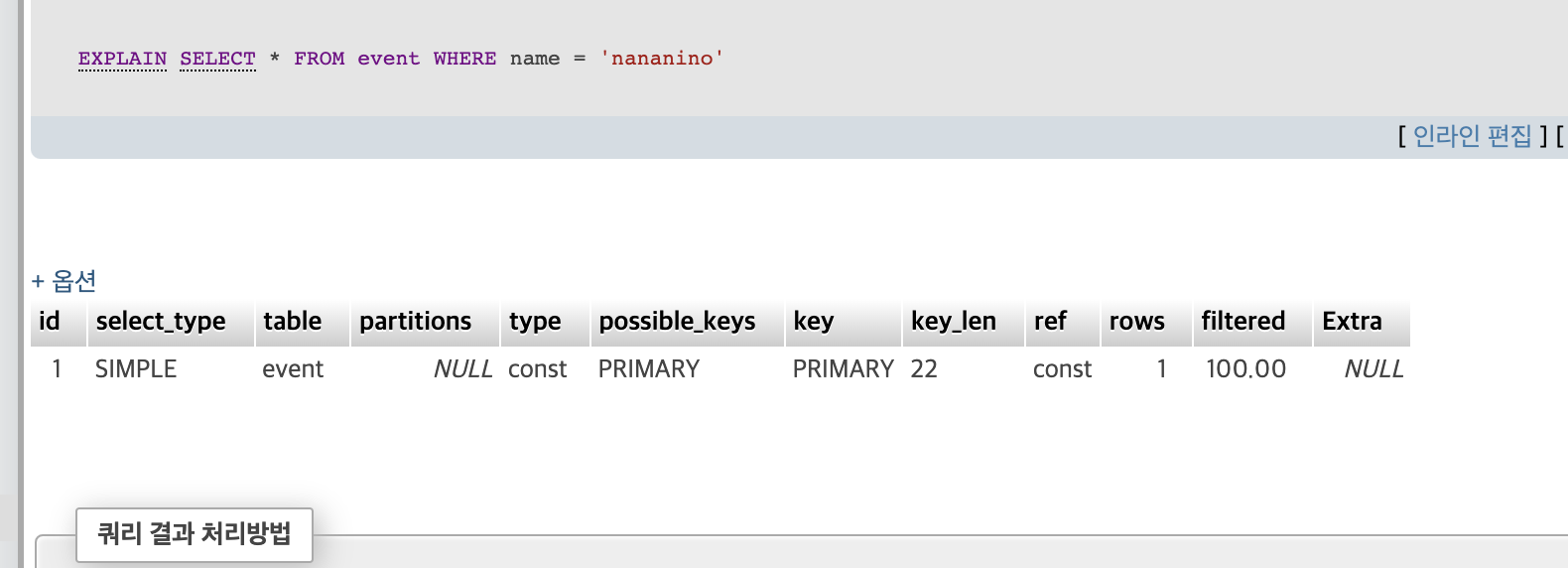
type = const, key = primary, ref = const
풀스캔은 언제??
전체 레코드의 25%이상 조회를 할 경우에
기본 인덱스

인덱스는 신중하게 결정해야한다.
인덱스는 수정없는 읽기 전용 테이블에 단일 인덱스가 적절하다.
불필요한 인덱스는 제거하자.
함수 인덱스

함수는 INDEX를 지원하지 않는다.
따라서 함수 INDEX를 직접 생성해야한다.
alter table temp_function add key idx_create_time(create_time);
인덱스 생성후 EXPLAIN 확인
explain select * from temp_function where create_time>='2020-07-01' and create_time<date_add('2020-07-01',INTERVAL 1 day);
SQL 구문 세부 (WHERE, GROUP, ORDER의 INDEX 사용)
- WHERE 절의 INDEX 동작
비교연산자 (크거나 작거나 등) 이외 AND가 적절하다.(OR 연산자는 ㄴㄴ)
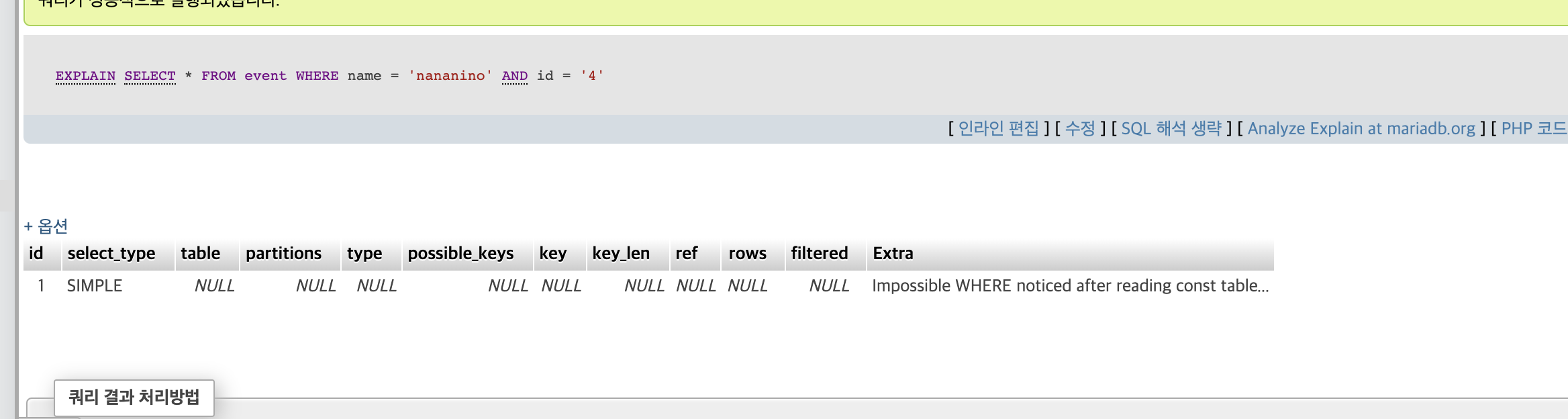
AND 일 경우
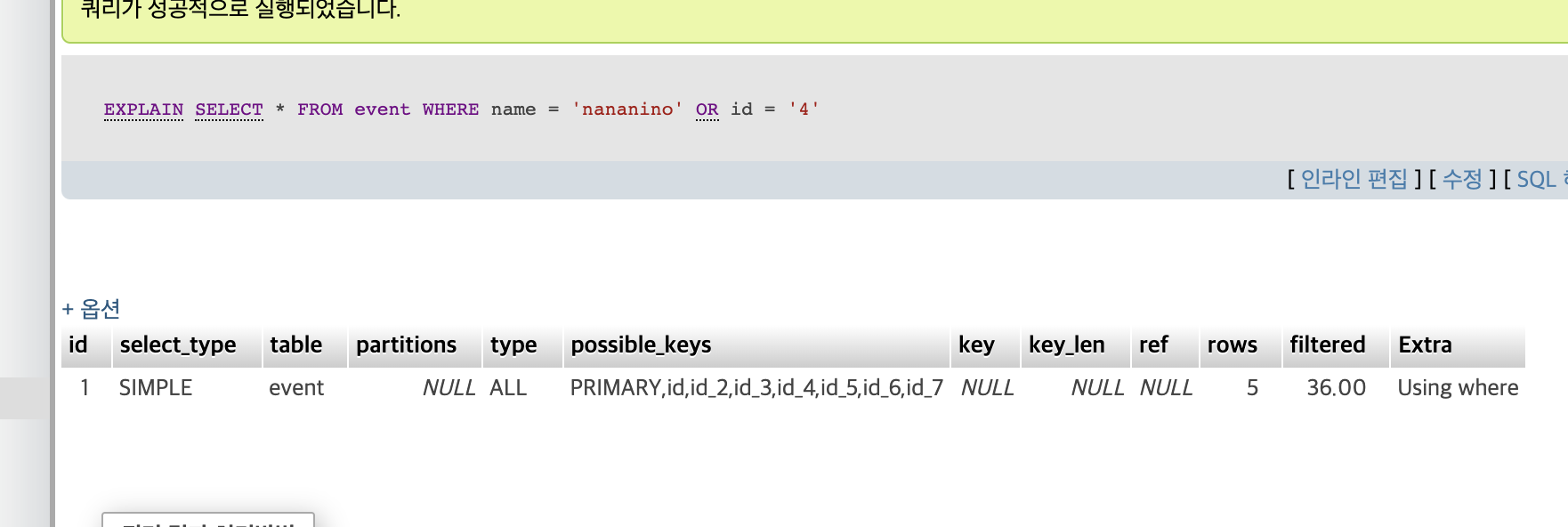
OR일 경우

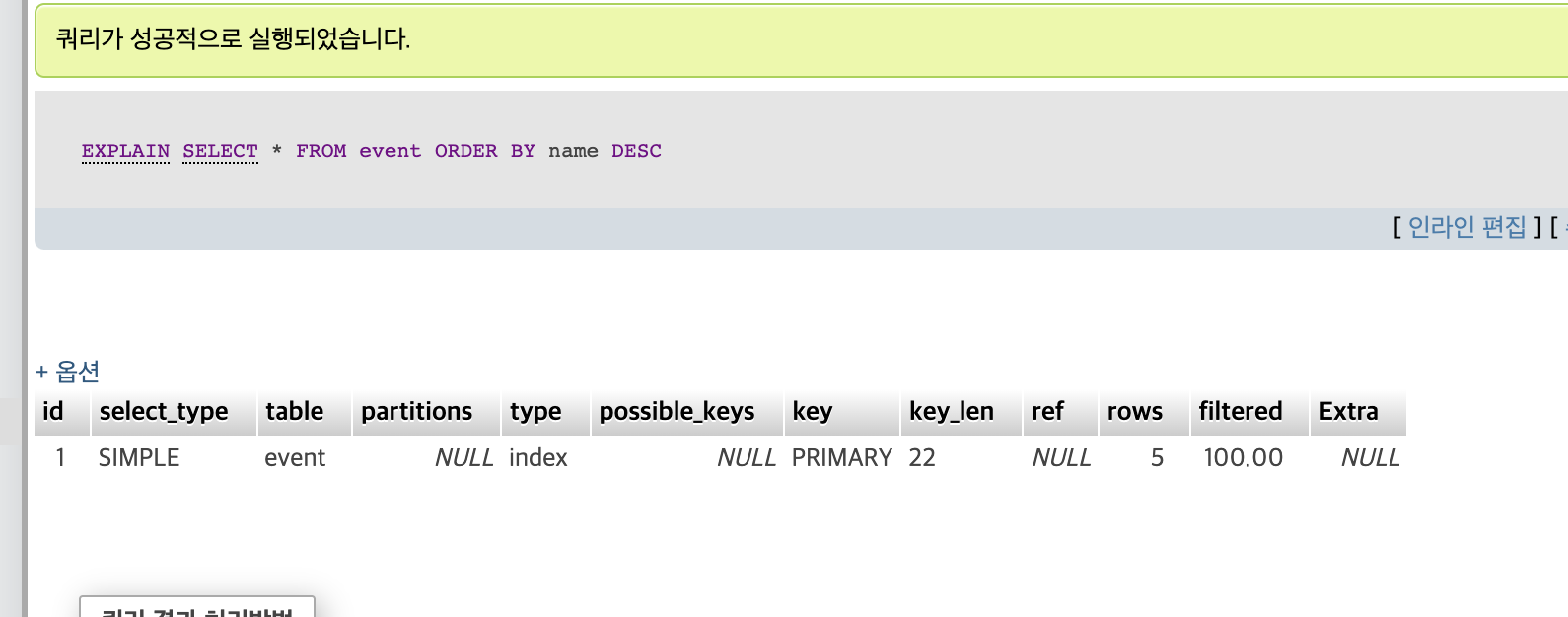
단일 정렬할 시 type = index인데
다중 정렬을 하면 인덱스로 동작을 하지 않는다.
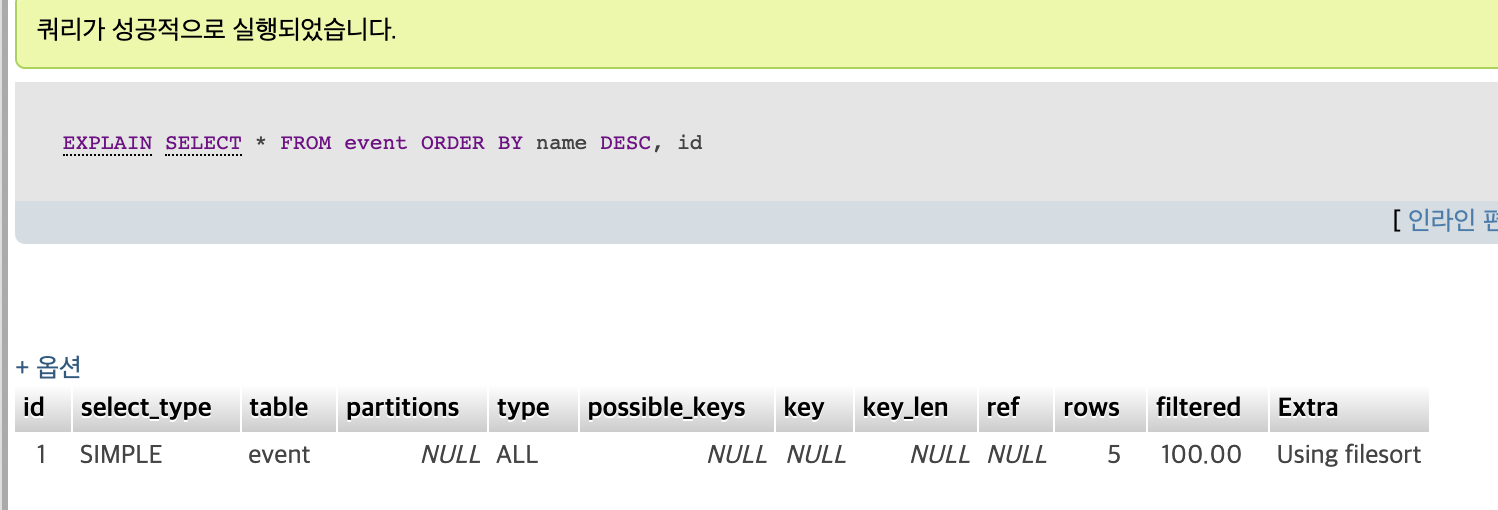
type = ALL => 풀스캔으로 동작을 한다.
공통
WHERE, GROUP, ORDER은 모두 상수 값 원본을 사용해야한다.
11주차 문제
1. Insert, Update, Delete 등과 같은 DML 작업은 테이블의 내부 ( ) 설정이 오히려 성능이 떨어트릴 수 있다
https://cano721.tistory.com/m/77 (참고)
레코드(ROW)가 추가/수정/삭제 되면 생성된 INDEX도 동기화 해주기 때문에
이 동기화 비용 때문에 성능이 떨어질 수 있다.
2. 인덱스는 테이블에 인덱스를 생성하지 않아도 되고 여러 개를 생성해도 된다. 기본 인덱스 알고리즘은 B+TREE 이다. ( 참 / 거짓 )
참
3. 인덱스를 역 스캔하는 방식은?
- INDEX FULL SCAN
- INDEX RANGE SCAN
- INDEX UNIQUE SCAN
- INDEX RANGE SCAN DESCENDING
4번
4.
정수형 데이터타입인 COL1(인덱스)에 대해 가장 효율적인 쿼리문은?
- WHERE COL1 LIKE '5%'
- WHERE COL1 IS NOT NULL
- WHERE COL1 <> 10
- WHERE COL1 = 100
-
WHERE 우선순위
WHERE 절은 "테이블내의 모든 행을 검색하는 대신 검색 조건을 지정하여 사용자가 원하는 행들만 검색하는 기능"이다.WHERE 조건식은 단일 조건식과 복수 조건식이 있다.
연산의 우선순위는 비교연산자 (=, !=, <>, >, >=, <, <=) SQL연산자(BETWEEN, IN, LIKE, IS NULL), NOT, AND, OR 순이다. -
LIKE '%'
검색조건을 설정할 때 LIKE '%검색어%' 를 사용해야 할 경우가 있는데 변수 앞에 '%' 를 사용하면 해당 칼럼에 Index를 설정했다 하더라도 FULL SCAN을 한다.
-
인덱스 사용할 수 없는 경우
조건절에 자주 등장하는 칼럼이라고 판단하여 최적화된 인덱스를 생성했다 하더라도, Index를 사용할 수 없는 상황이 발생하는데 대표적인 경우가 칼럼의 내외부 변형, IS NULL, IS NOT NULL을 사용한 비교, 여러 칼럼에 대한 OR조건 사용, 부정형(NOT, <>, !=, NOT EXISTS) 비교, 그리고 위에 언급한 LIKE 검색시 변수 앞에 %를 사용하는 경우이다.
따라서 우선순위가 가장 높은 4번이 정답이다.
12주차
11주차까지 배운것을 토대로
"프로 파일링"이라는 것을 할텐데
쿼리에서
EXPLAIN SELECT * FROM sbtest 이 쿼리에
WHERE 절을 붙은 것과 안 붙인것의 프로파일링 그래프를 보면서
어디에서 시간이 많이 걸리고 안걸리는지 확인을 하며 비교해보는 시간이다.
EXPLAIN문
Sending Data 시간을 프로파일링 하지 않는다.
- 먼저 구름 터미널창에 1개 10만 size 만들어주고
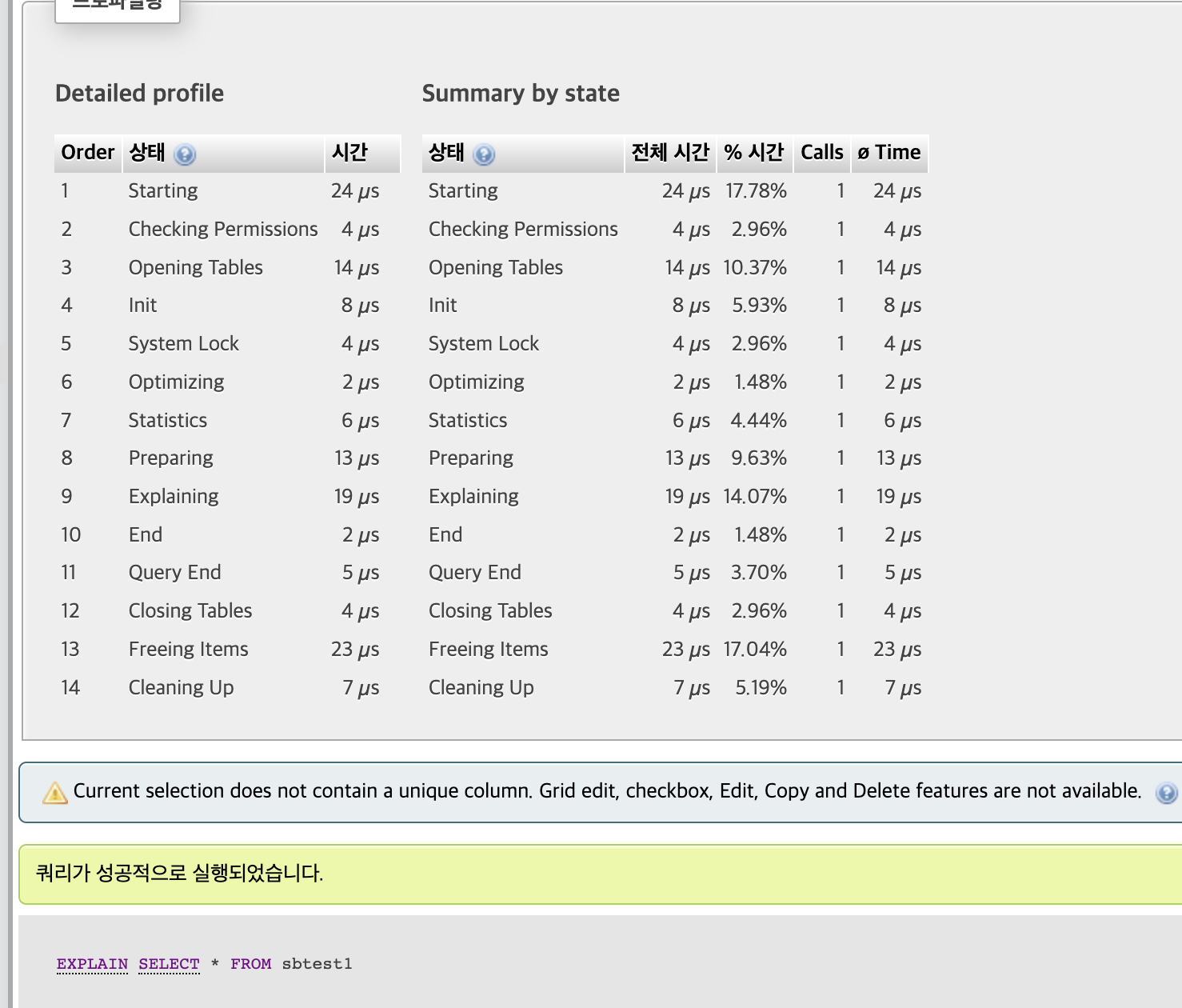
- "실행 계획"을 살펴본다.
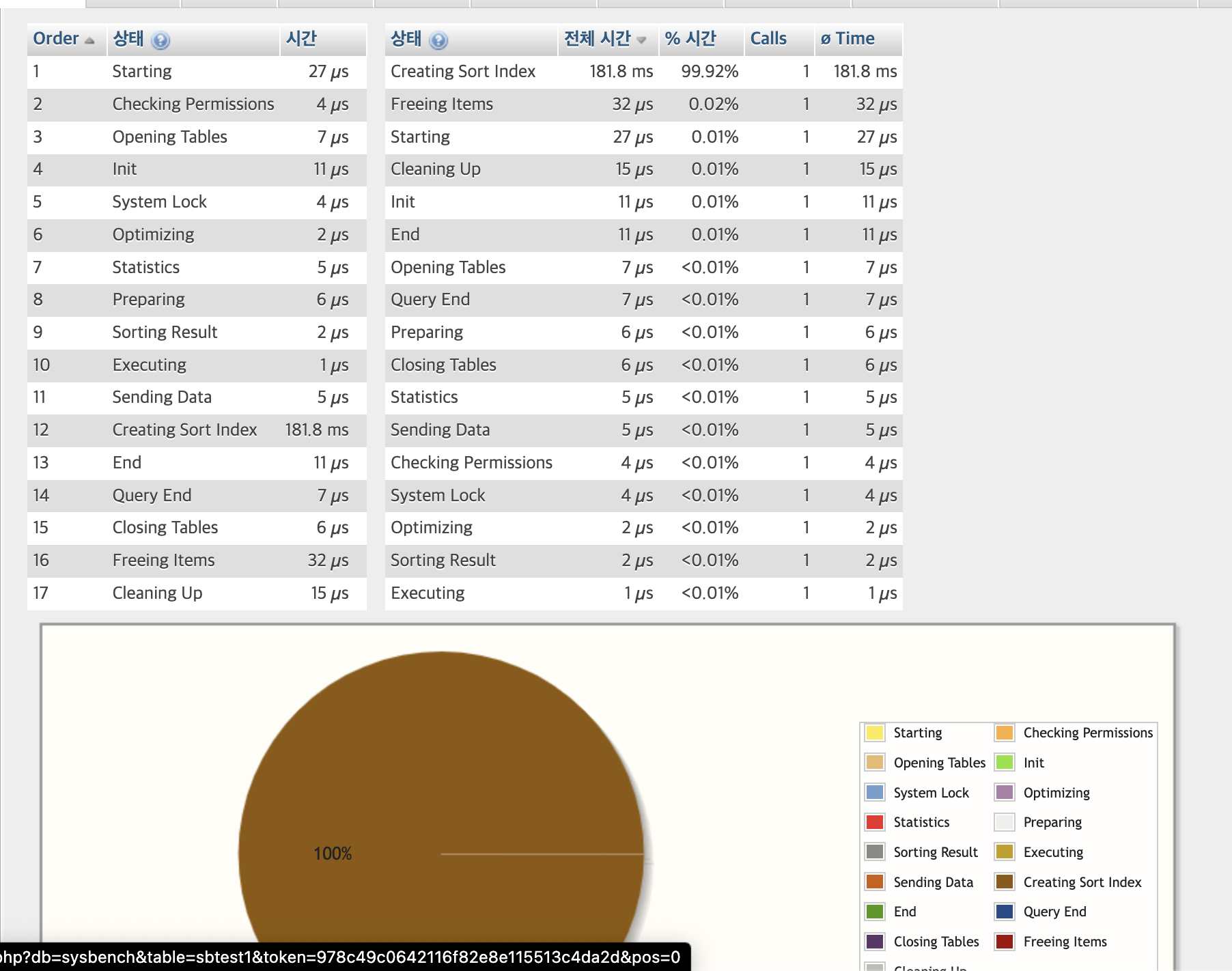
1번 Starting 과 13번이 높다.
그러면 EXPLAIN 없애고 실행해보도록 하자.
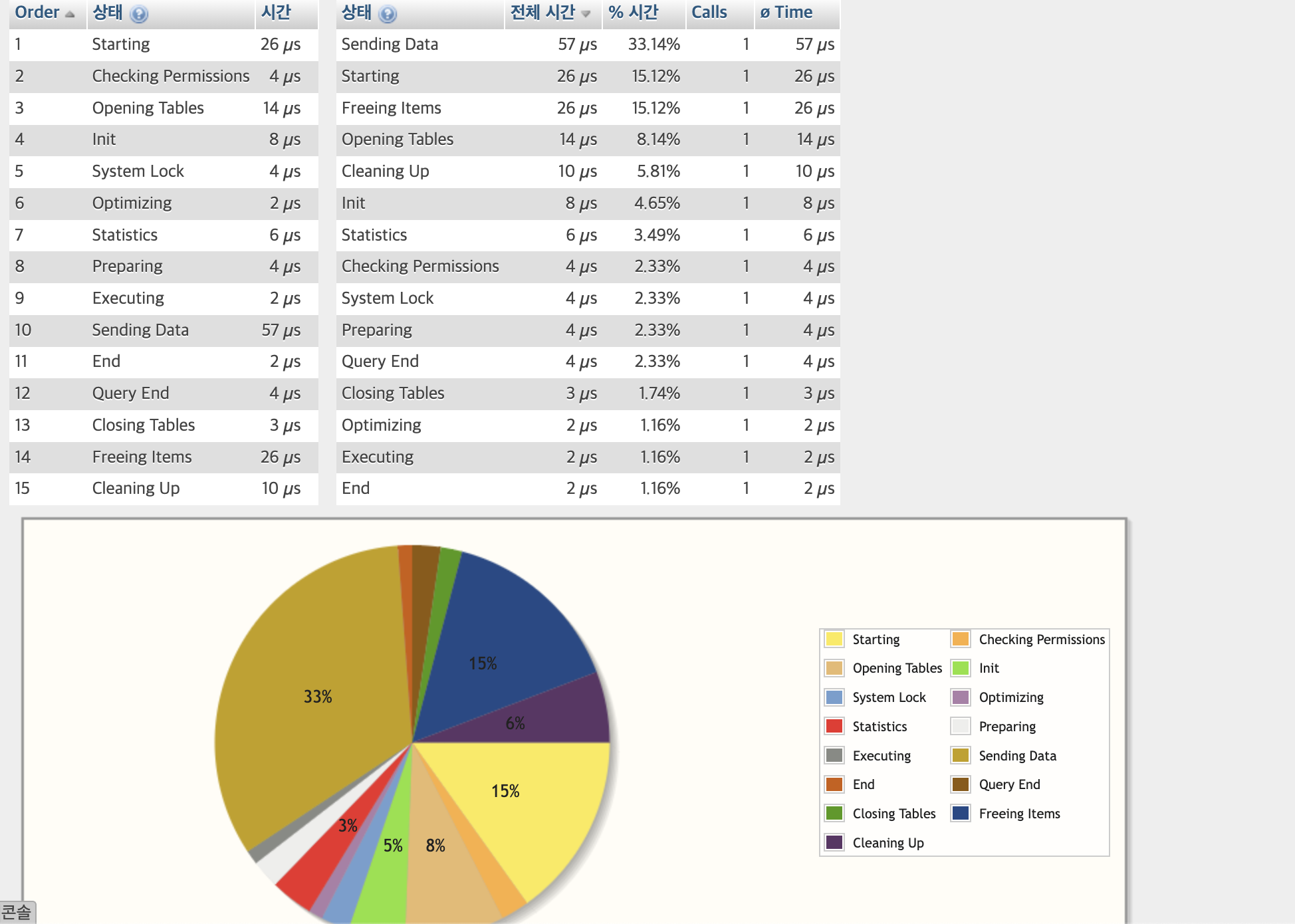
1번과 10번 Sending Data부분이 가장 시간이 많이 걸렸다.
단일 스캔으로 수정
SELECT * FROM
sbtest1WHERE ID = 1
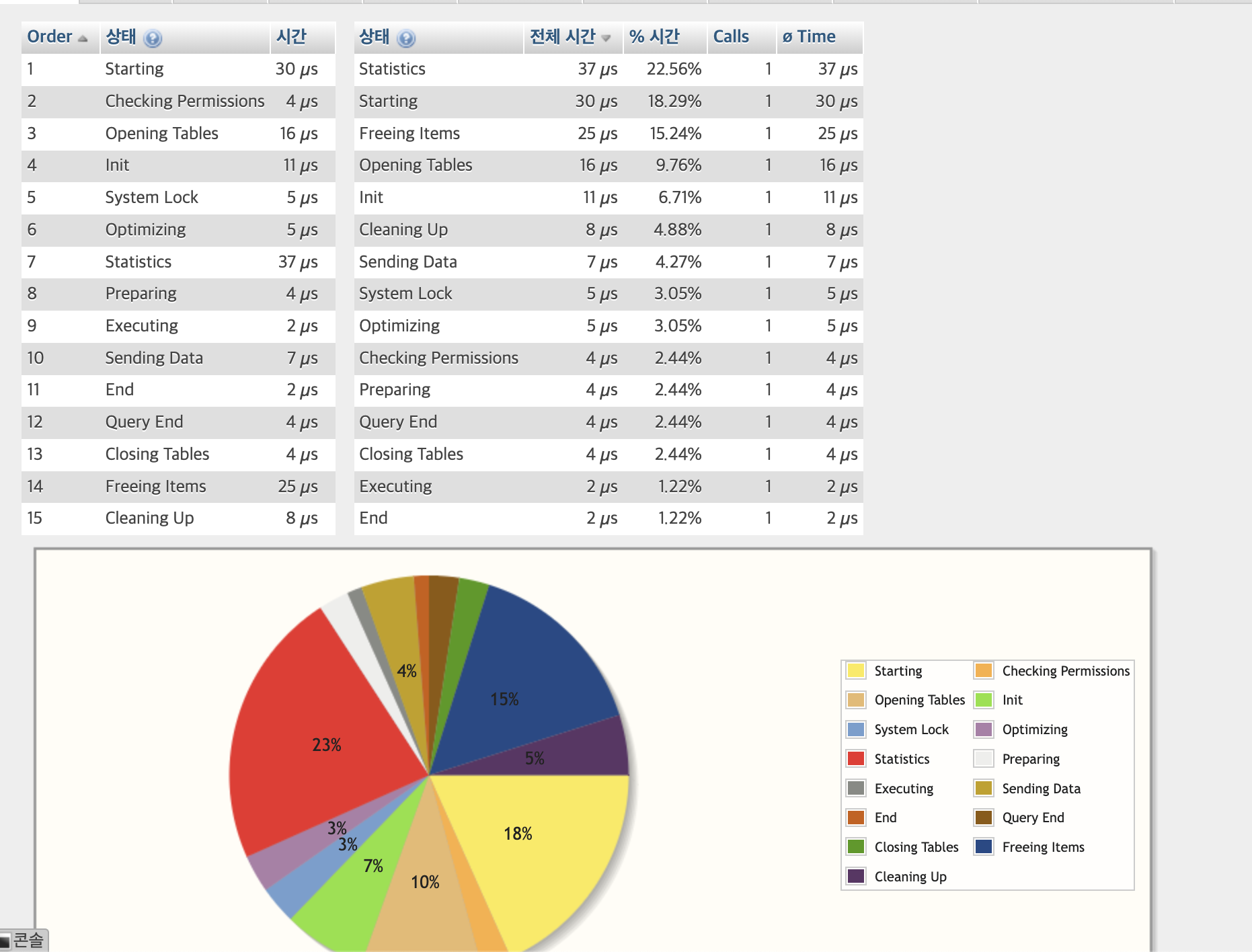
살펴보면은
1번인 Starting은 여전히 시간비중이 높고
10번은 존나 줄어듦, 반면에 7번항목이 늘어남!
7번 Statistics
단일 INDEX 요청으로 통계 정보 업데이트 시간이 요구 됨.
14번 항목
자원 해제에 비교적 시간이 추가 요구됨.
SQL 쿼리문 정렬로 수정하기
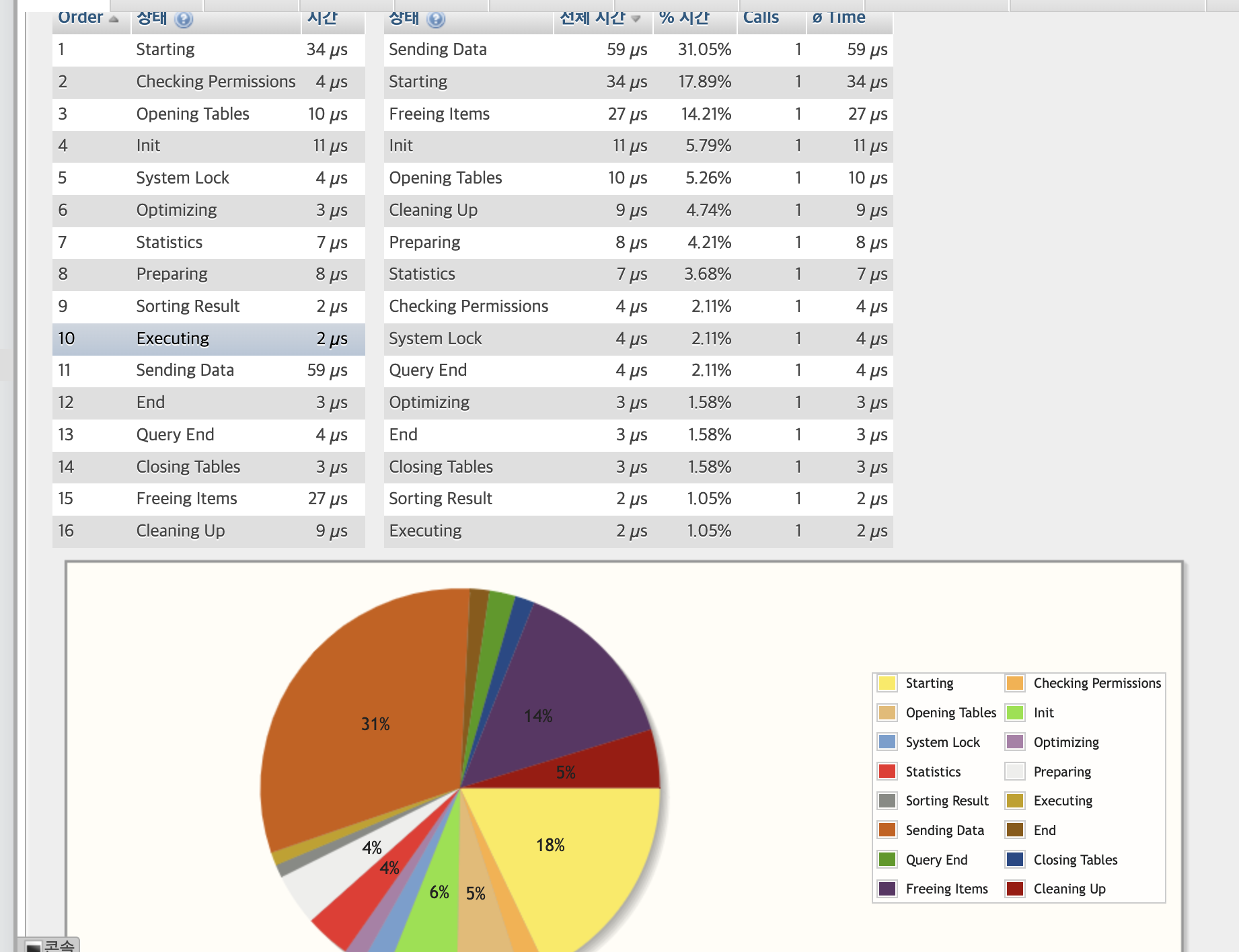
1,3 공통적으로 시간 많이 듦.
9번항목 Executing
인덱스로 지정된 행 (== ID)는 정렬에 드는 시간 비용이 크지 않다.
11번 항목
INDEX 타입은 풀 스캔과 같이 데이터 전송 시간 비중이 높다.
SQL 쿼리문 다중 정렬로 수정하기
SELECT * FROM `sbtest1` ORDER BY ID DESC;수행하면
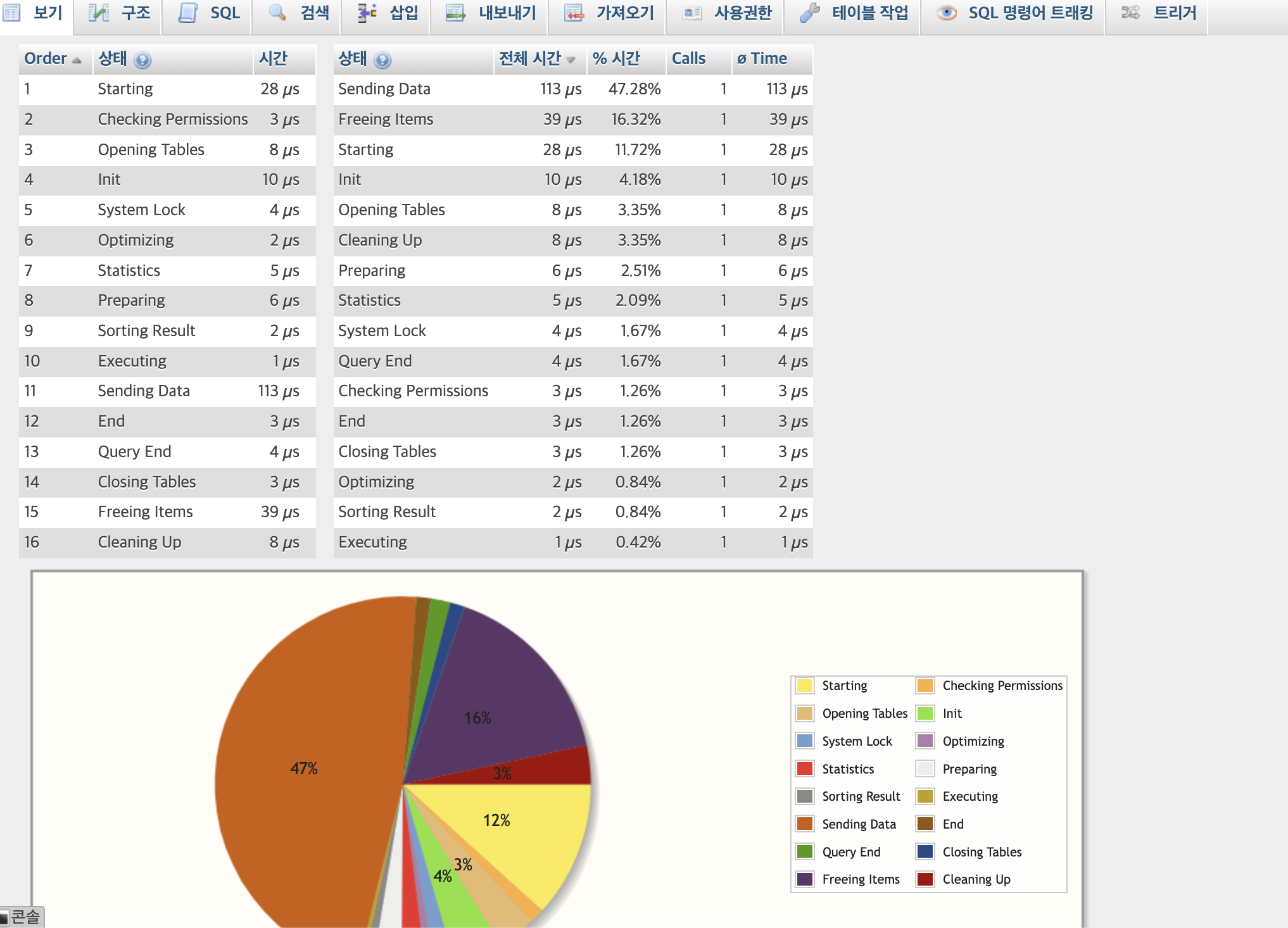
11번 항목 엄청큰 비율 차지 하게됨.
SELECT * FROM `sbtest1` ORDER BY ID DESC, K ASC;를 하게되면
CREATING INDEX
INDEX로 지정되지 않은 행은 새로운 정렬을 시도하면, 엄청나게 큰 시간 비용을 요구한다. 데이터 전송보다도 훤씬 비중이 높은 것을 알 수 있다.
SQL 쿼리문 다중 정렬 (범위 작게)
SELECT * FROM `sbtest1`
WHERE ID BETWEEN 10 AND 100
ORDER BY ID, K ASC;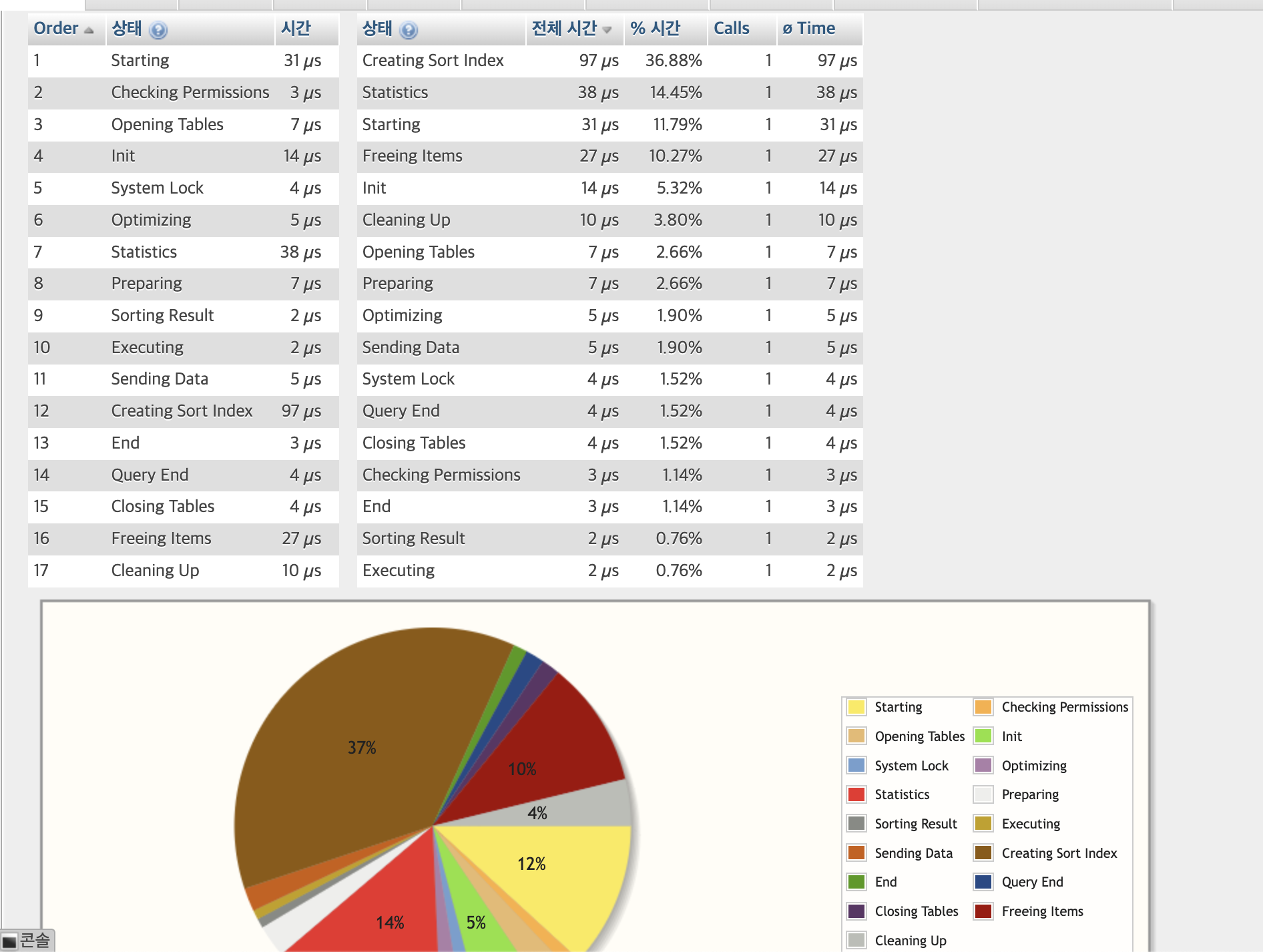
9번 : 인덱스로 지정된 행은 정렬에 드는 시간비용이 크지않다.
12번 항목 Creating Sorting Index : 인덱스 미지정 행은 스캔의 범위를 좁혀도 정렬의 시간 비중이 ㅈㄴ 크다.
SQL 쿼리문 그룹화로 수정하기(2행이상)
SELECT K, ID FROM `sbtest1` GROUP BY K, ID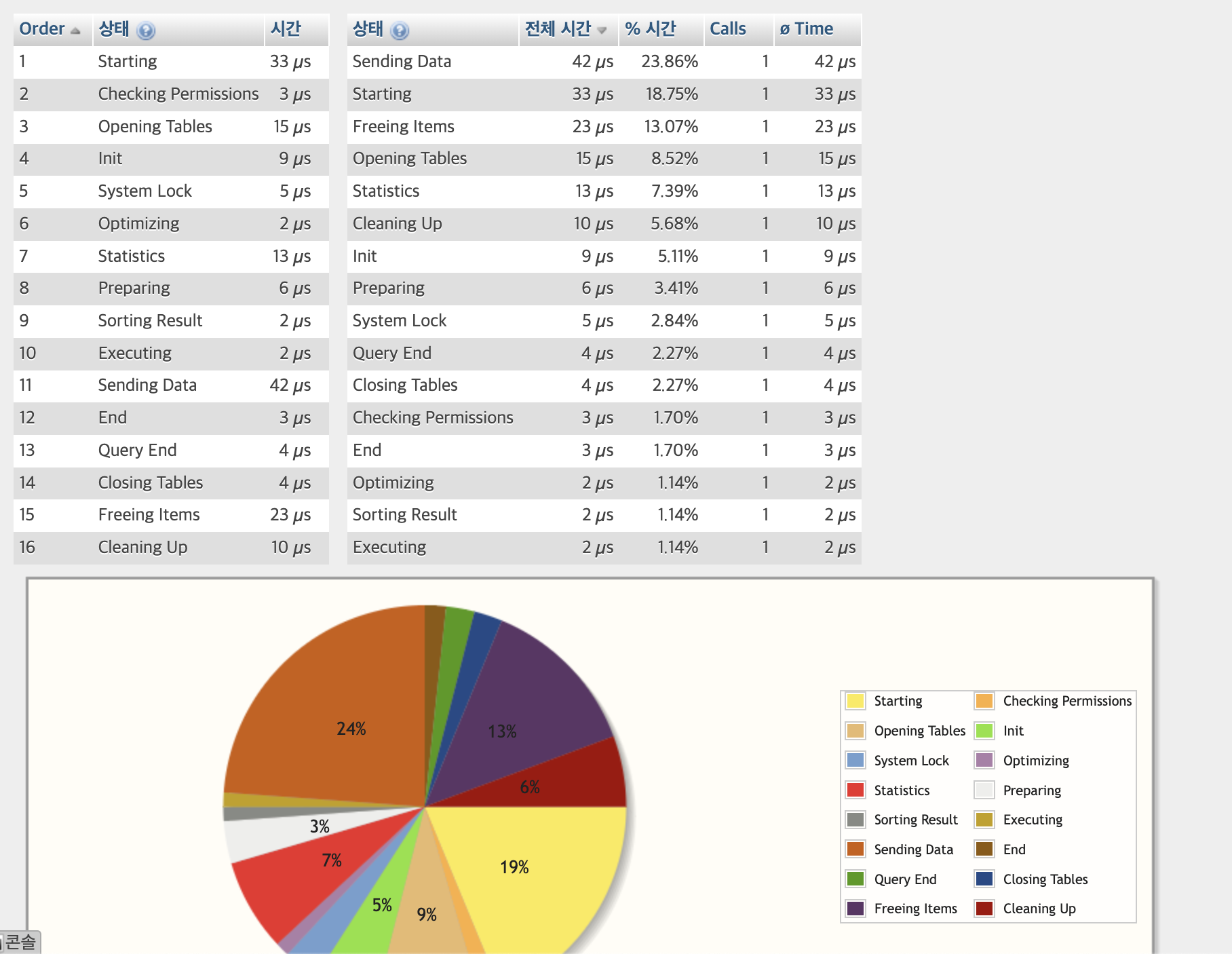
9번 항목 : 인덱스로 지정된 행은 그룹화 시간 많이 안듦
11번 Sending Data : 인덱스로 지정되지 않은 행을 그룹화 하는 경우 "풀스캔" 발생
=> 풀스캔 요청/응답 과 같은 시간 비중이 높다.
SQL 쿼리문 정리
0. SQL 쿼리문 전체 조회
SELECT * FROM sbtest1Starting, Opening : 테이블 접근/열기 비중이 높다.
Sending Data : 전체 데이터 요청/응답에 시간 비중이 높다.
1. SQL 쿼리문 단일로
SELECT * FROM sbtest1 WHERE ID = 1;Starting, Opening : 쿼리에 상관없이 공통적으로 비중 높다.
Statistics : 단일(인덱스) 요청으로 통계 정보 업데이 시간이 요구된다.
Sending Data : 단일 데이터 요청/응답의 비중이 크게 감소
Freeling Items : 자원 해제에 비교적 시간이 추가 요구됨.
2. SQL 쿼리문 정렬로 수정
SELECT * FROM sbtest1 ORDER BY ID DESC;Starting, Opening : 쿼리에 상관없이 공통적으로 비중 높다.
Sorting Result : 인덱스로 지정된 행은 정렬에 시간 비중 높지 않다.
Sending Data : 인덱스 타입은 풀스캔과 같이 데이터 전송에 시간 비중높다.
3. SQL 쿼리문 다중 정렬로 수정
SELECT * FROM `sbtest1` ORDER BY ID DESC K ASC;Sorting Result : 인덱스로 지정된 행은 정렬에 시간 비중 높지 않다.
Creating Sort Result : INDEX로 지정되지 않은 행은 새로운 정렬을 시도하면 엄청나게 큰 시간비용을 요구한다. 데이터 전송보다도 훨씬 높다.
4. SQL 쿼리문 다중 정렬(범위 작게)
SELECT * FROM `sbtest1` WHERE ID BETWEEN 10 AND 100 ORDER BY ID, K ASCSorting Result : 인덱스로 지정된 행은 시간 비용 높지 않음.
Creating Sort Result : 인덱스 미지정 행은 스캔의 범위를 좁혀도 정렬의 시간 비중이 매우 크다.
5. SQL 쿼리문 그룹화로 수정하기(2행이상)
SELECT K, ID FROM `sbtest1` GROUP BY K, ID!Sorting Result : 인덱스로 지정된 행은 그룹화에 드는 시간 비용이 크지 않다.
Sending Data : 인덱스로 지정되지 않은 행을 그룹화 하는 경우 "풀 인덱스 스캔"이 발생한다. => 풀스캔은 요청/응답과 같이 시간 비중이 높다.
12주차 문제

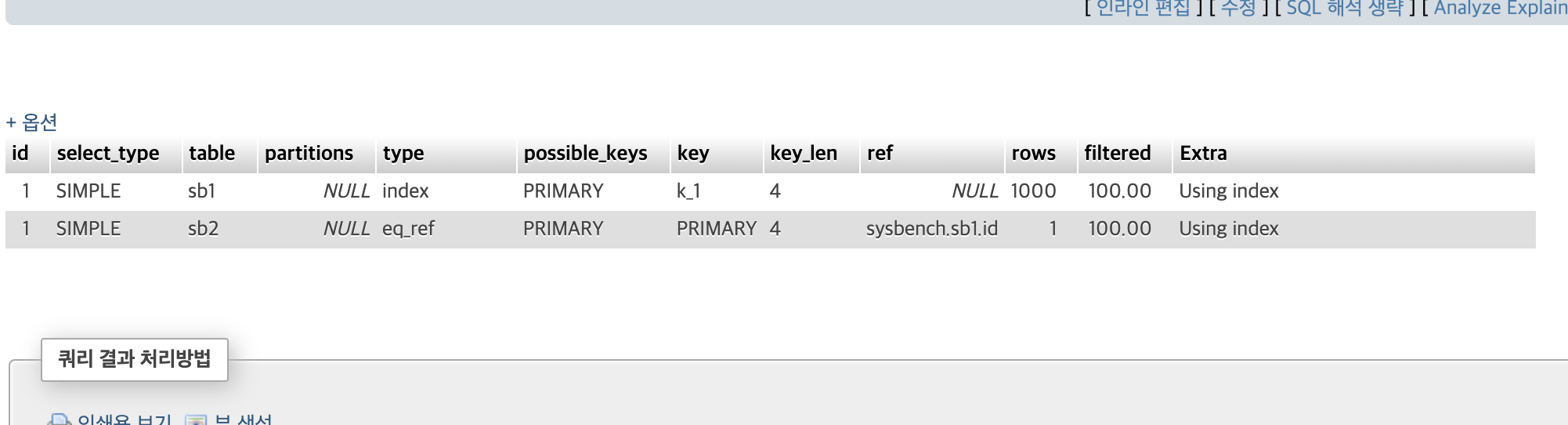
문제의 쿼리 실행을 하면
sb1의 경우
type = index,
ref = NULL,
Extra = Using Index
sb2의 경우
type = eq_ref
ref = sysbench.sb1.id
Extra = Using Index
이다.
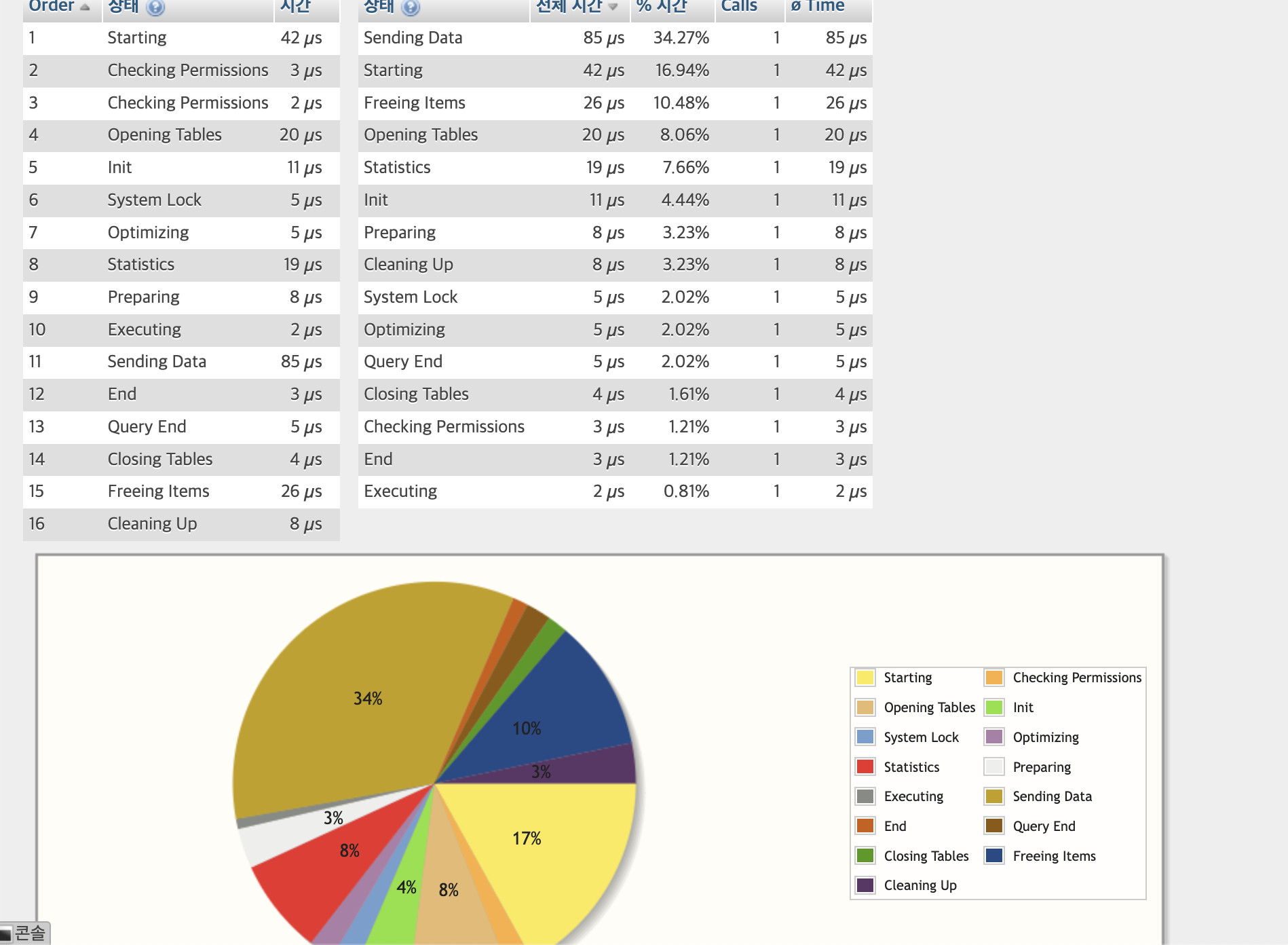
알수 있는 것은 인덱스 타입은 풀스캔과 같이 데이터 전송에 시간 비중이 높은 것을 알 수 있다.
13주차 구조 최적화
행의 크기와 열의 갯수 제한
행 : 크기 제한 65,535 바이트, 열 : 4096개수 제한
성능 : 작은 데이터 타입과 길이를 선택해야한다.
PROCEDURE ANALYSE() 기능 - 1
SELECT * FROM `animals` PROCEDURE ANALYSE()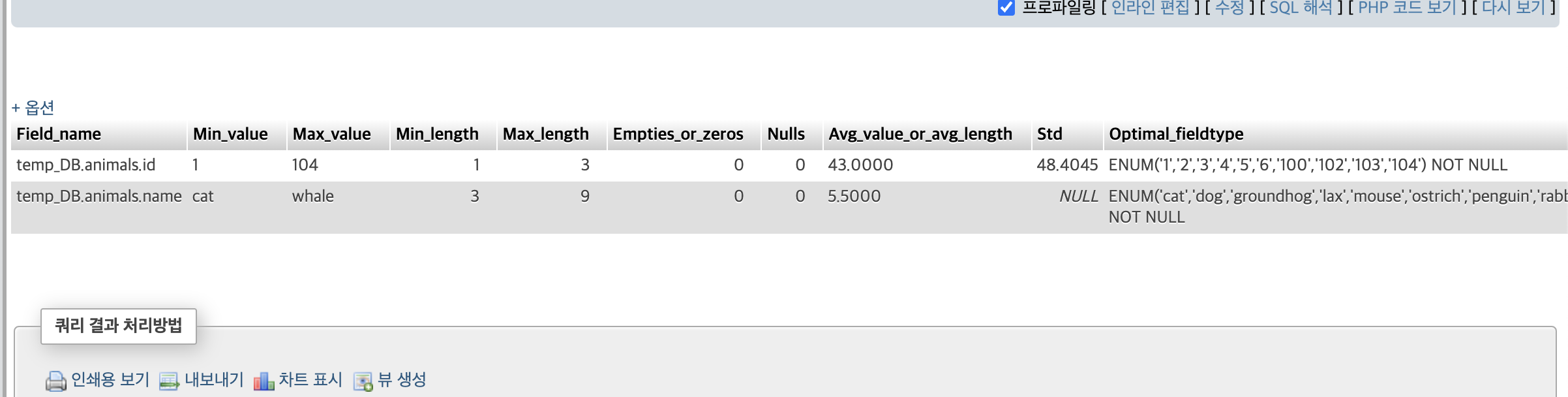
해당 쿼리 실행할 경우 optional fieldtype이라고 추천 타입인데
이것이 ENUM으로 되어있는데
mysql에서 자체적으로 데이터가 작으니까 이게 효율적이라 ENUM타입을 추천하고 있는 것이다.
그런데 문제가
관계 X, 유일, 변하지 않는 작은 범위 값 저장 용도
예) 남, 여 / 오전, 오후 / 예, 아니오 등
근데 대부분 테이블에서 ENUM은 찾아볼 수 없다.
데이터 변경/재사용 어려움, DB 호환성, 최적화 성능 낮음 등
PROCEDURE ANALYSE 기능 - 2
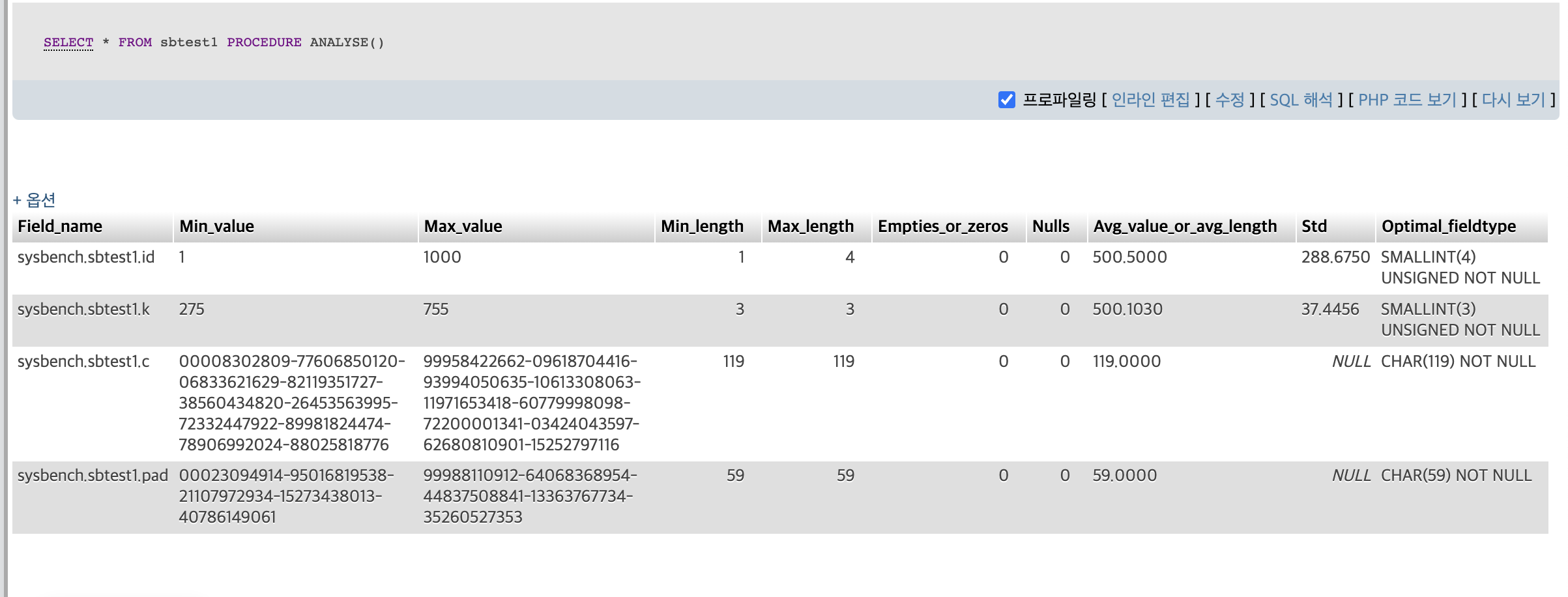
sysbench DB의 sbtest1테이블은
테이블 크기를 최적화 -> 값, 크기 등을 고려 -> INT, CHAR 추천함.
데이터 타입의 선택이 중요하다.
정수, 문자열 데이터형 종류도 다양하다.
최적의 데이터 타입 선택?
숫자형 ( 다양한 길이 )
- 고유 정보(일반적 : 키) 문자열보다 숫자 타입 권장
인덱스 및 JOIN등에서 숫자형이 문자열보다 빠르다.
문자 및 문자열 (VARCHAR : 65535 BYTE제한)
자주 변경되는 고정 크기 COLUMN은 CHAR 사용 권장
8K 이하 COL은 지정된 크기의 VARCHAR 사용 권장
A BLOB - 이진 데이터 (기본 : 65535 바이트 제한)
페이지 압축
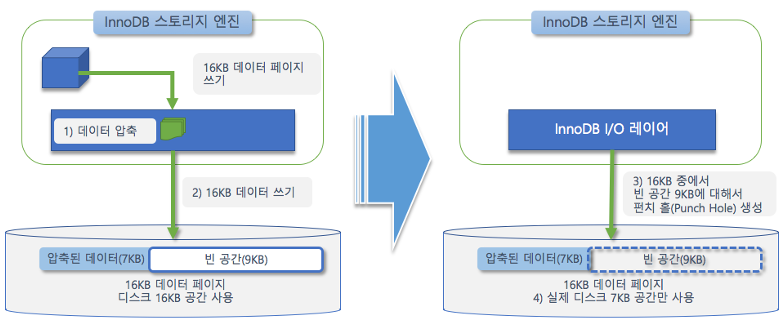
-
내부 엔진 수준에서 동작 (버퍼 풀)
압축이 해제된 상태로 데이터 페이지를 관리
Zlib, LZ4 등의 압축 방식 제공 -
BUT
운영체제별 파일 시스템 지원 필요 -> 활용도가 떨어진다.
-
temp_DB -> animals 테이블을 내보내기로 SQL 파일을 백업한다.
-
temp_DB -> animals 테이블 크기 확인 -> 압축후 크기는?
ALTER TABLE animals COMPRESSION = 'zlib';
optimize TABLE animals;테이블 압축
-
페이지 압축보다 활용도가 높다. (운영체제 지원 유무 X)
쿼리 처리 성능 저하 가능
데이터 변경이 많은 경우 압축률이 떨어진다.
현재 엔진 페이지 기본크기 = 16KB 이하로 설정가능 -
temp_DB -> 앞서 설명한 animal2 테이블 생성
이름만 바꾸고 데이터 삽입
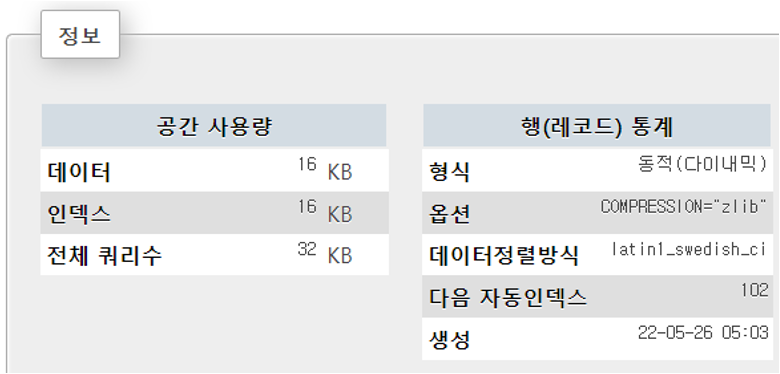
alter table animals2 ROW_FORMAT=COMPRESSED KEY_BLOCk_SIZE=8;
optimize table animals2;확인하면

데이터 16KB -> 8KB, 인덱스 16KB -> 8KB, 전체 쿼리수 32KB -> 16KB 로 줄어듦
INDEX
짧은 이름, NOT NULL, 삽입/UPDATE 쿼리에 사용 ㄴㄴ
JOIN
짧은 이름, 동일한 데이터 타입
데이터 타입이 다르면 INDEX 효율 안나온다.
이부분 부터 무슨말?
구조 최적화 - 다중 테이블
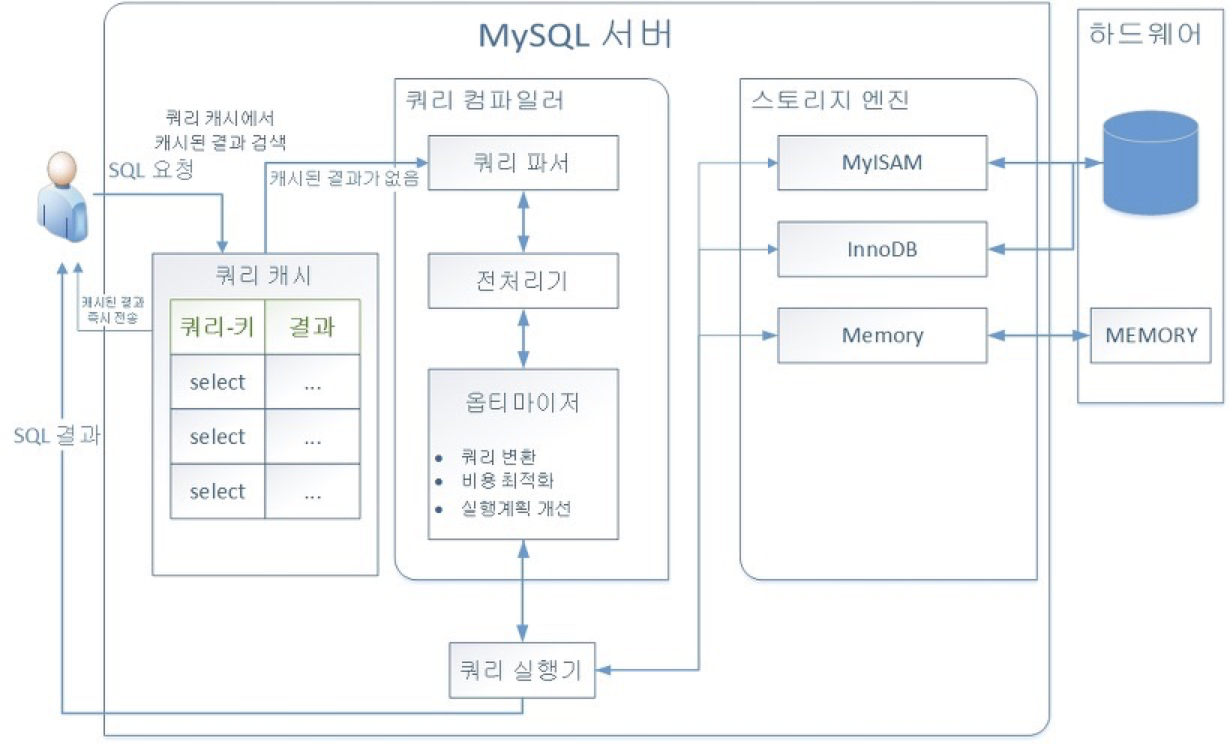
다중 쿼리 캐시 수행 - SELECT에 다수 호출
- 캐싱된 쿼리 (Parsing, Optimizing, Executing) 단계 패스
- 설정확인
- 캐시 용량 : 바이트 단위
- 테이블 열기 캐시 제한 용량
- 테이블 캐시 상태 확인과 삭제
상태 확인
SHOW STATUS LIKE '%Qcache'
삭제
RESET QUERY CACHE
구조 최적화 - 내부 임시 테이블
임시 테이블? SELECT에 최적화된 쿼리 캐시와 반대
-
UNION 구문, 서브쿼리, 조인, INSERT SELECT 에서 생성
-
세션 종료 또는 연결이 종료되면
자동으로 삭제되는 테이블, BUT
삭제를 보장하지는 않기 때문에 명시적으로 삭제가 필요함. -
INSERT, UPDATE의 경우 임시테이블이 더 빠르다.
SELECT는 일반 테이블이 더 빠름.
13주차 문제
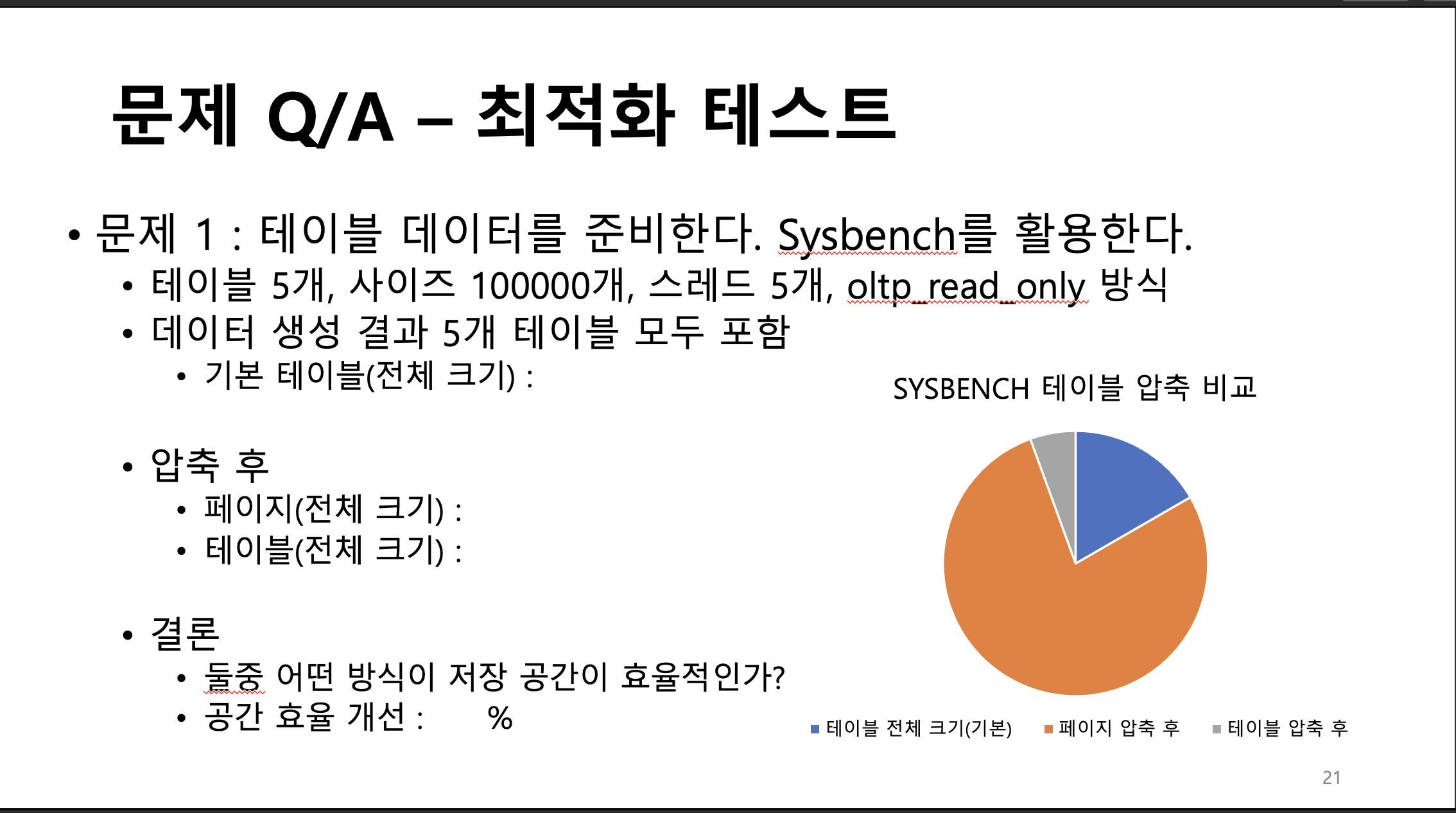
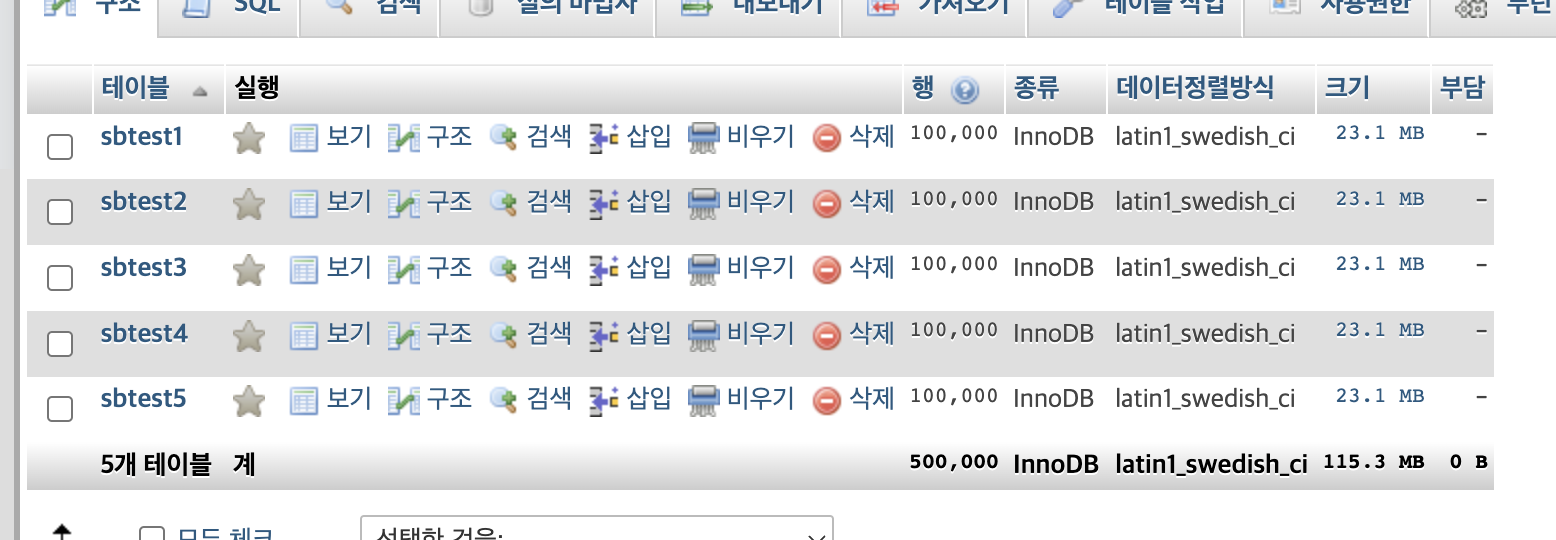
크기는 각 테이블당 23.1MB이다.
-
전체 크기는 23.1 * 5 MB
-
압축후
sbtest1 페이지 압축
ALTER TABLE sbtest1 COMPRESSION = 'zlib';
OPTIMIZE TABLE sbtest1;로 sbtest1 압축하니까
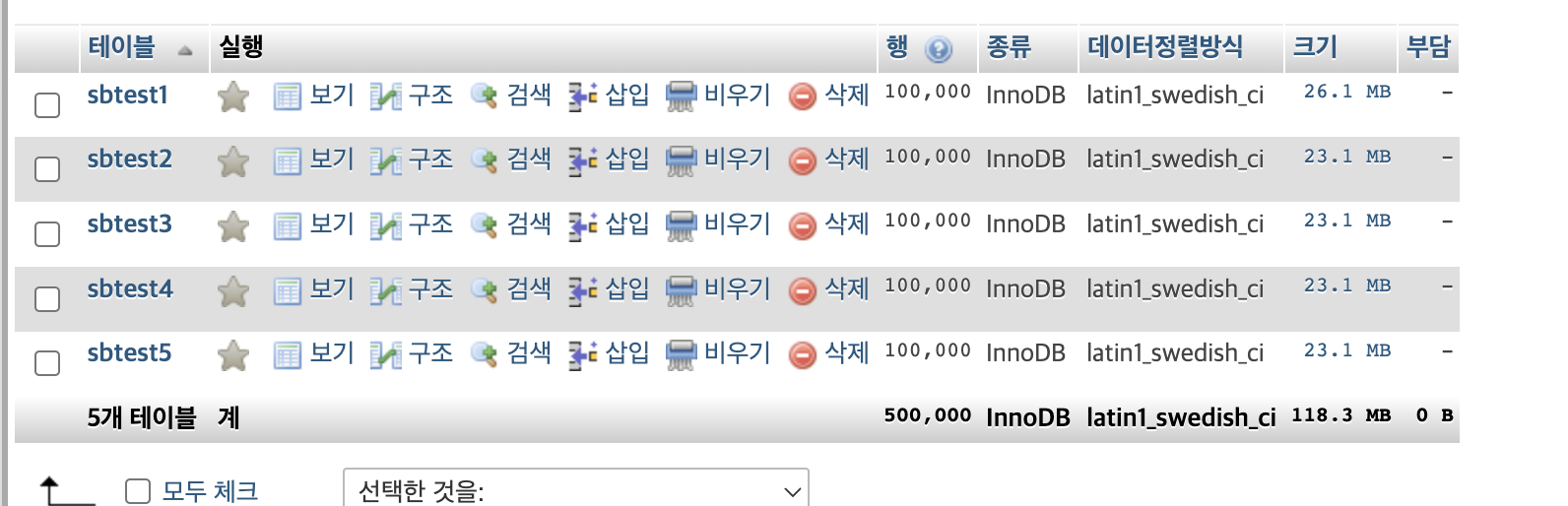
26.1MB로 더 늘어남! ㅅㅂ??
sbtest2 테이블 압축
alter table sbtest2 ROW_FORMAT=COMPRESSED KEY_BLOCk_SIZE=8;
optimize table sbtest2;하였을 경우
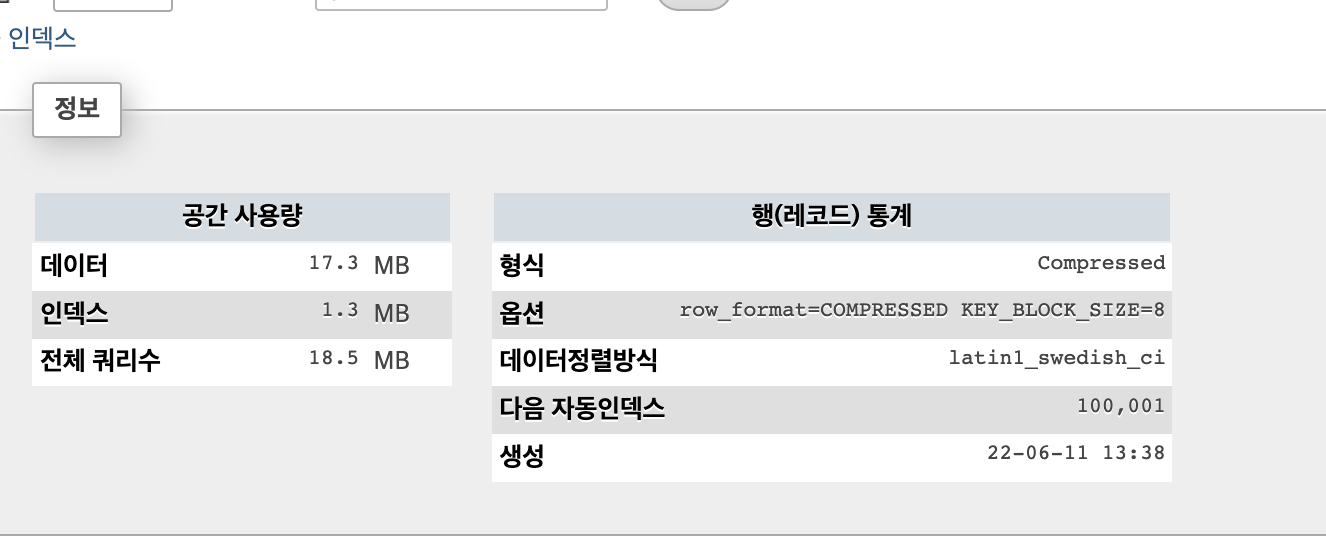
이렇게 줄어듦
알 수 있는 사실
페이지 압축보다 테이블 압축이 더 좋고
테이블 압축이 훨씬더 많이 압축 해준다.
- 페이지(전체) = 26.1 * 5 MB
- 테이블(전체) = 18.5 * 5 MB
최종 정리
9주차 ~ 10주차
인덱스와 프로시저
함수 : client (복합), 프로시져 : server (단독)
함수 : 리턴값 반드시 존재, 프로시저 : 리턴값 없어도 됨.
프로시저 매개 변수 3가지
- IN, 2. OUT, 3. INOUT
-
IN : 원본 값유지
-
OUT : return값만 전달해줌
-
INOUT : 원본값과 리턴값 둘다 유지
11주차 SQL 성능분석 및 최적화
-
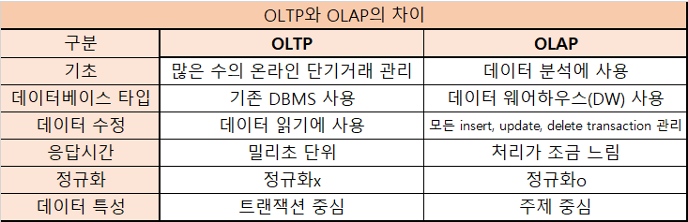
OLTP vs OLAP
기초 : 많은 수의 온라인 단기 거래 vs 데이터 분석에 사용
데이터 베이스 타입 : 기존 DBMS vs 데이터 웨어하우스
데이터 수정 : 데이터 읽기에 사용 vs 모든 insert, update, delete, transcation
응답 시간 : 밀리초 단위 vs 처리가 조금 느림
데이터 특성 : 트랜잭션 단위 vs 주제 중심. -
읽기 전용 기준 테이블은 뭐가 더 효율적?
"분산"과 "통합"중에 => "통합"이 더 효율적 이다.
100size 1개 테이블과 10만 size 10개 테이블 중에 읽는 호율 따졌을 경우. -
SELECT 최적화
SQL문 최적화
- 풀 스캔 범위 촤소화
- 기본 인덱스 설정
- 함수 인덱스
- SQL 구문 세부
데베 구조
INNO DB엔진
메모리 테이블
버퍼링 및 캐싱
테이블에 키가 없다면 키를 설정해야함
-
풀스캔은 WHEN?
=> 전체 레코드 25%이상일 경우 type = ALL -
인덱스는 신중하게 사용!
수정이 없는 읽기 전용 테이블에 단일 인덱스가 적절하다.
insert/update/delete와 같은 수정 작업을 하면 생성된 인덱스도 동기화를 해주기 때문에 동기화 비용으로 성능이 저하될 수도 있다. -
함수는 INDEX를 지원하지 않는다. => 함수 INDEX 직접 생성
-
WHERE COL1 LIKE '%5', IS NOT NULL, <> 10, COL1 = 10
효울 적인것은? => WHERE COL1 = 10이다.
'='가 운선순위가 가장 높다.
12주차 : 프로 파일링
- EXPLAIN은 Sending Data를 보여주지 않음 => 실행 계획만 보여준다.
13주차
임시테이블은 INSERT / UPDATE 가 일반테이블보다 좋음
SELECT는 일반 테이블이 좋음
