
1. DB의 특징 (발전) 4가지
1) 관계형(SQL) -> 비관계(NOSQL)
- 발전 : "유연", "확장", "고성능", "가용성" 등으로 발전
- 정형 데이터 -> 비정형 데이터로 확장
- 관계를 KEY로 연결 -> 규칙이 없음.
2) 고전 SQL의 한계
- 복잡한 쿼리 및 스키마 유연 X
- 수평확장 X (수직 확장만)
- 설계 후 정규화 어려움
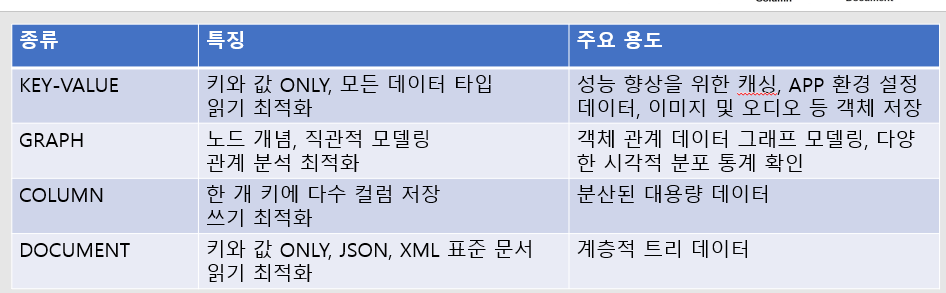
3) 빅데이터 처리 : NOSQL
- 쿼리 단순, 스키마 X, 조인 X, 외래키 X
- 구조적 질의 언어 없음, 관계 X : 유연성 있다.
- 종류 : KEY, 그래프, 도큐먼트, 컬럼
< 용어 정리 >
< 데베 발전과정 >
파일 시스템 -> 데이터베이스 관리 시스템(DBMS)등장 ->
1세대: 네트워크 DBMS, 계층 DBMS ->
2세대: 관계 DBMS ->
3세대: 객체지향 DBMS, 객체관계 DBMS ->
4세대: NoSQL, NewSQL
2. SQL구문 (중복제거, 정렬, NULL값 검사 패턴 검사 등
a. DDL : 데이터 정의어 -> 설계/관리 단계
ALTER(테이블의 속성 내용 수정), CREATE, DROP, RENAME, TRUNCATE, COMMENT
-
객체를 생성, 수정, 삭제하는 명령으로 이런한 명령문을 통틀어 DDL.
-
객체 종류 : 테이블, 뷰, 시퀀스, 인덱스 등
b. DML : 데이터 조작어 -> 주요 읽기 - 빈도 가장 높음
UPDATE(TABLE 내용 수정), INSERT, DELETE, MERGE, CALL, EXPLAIN PLAN, LOCK TABLE
- 데이터베이스에서 데이터를 검색하고, 행을 삽입/수정/삭제 하는 명령문이다. 데이터 조작어라고함.
c. DCL : 데이터 제어 언어 -> 주요 쓰기 -빈도 낮음
GRANT, REVOKE
- 데이터 베이스와 그 안의 구조에 대한 엑세스 권한을 부여하거나 회수하는 명령문을 DCL이라고 함.
d. TCL : 트랜잭션 제어 언어 -> 튜닝/최적화 단계 -선택
DDL, DML, DCL, TCL 실무에 필요한 쿼리 문법들임.
- 트랜잭션 제어 명렁어 : DML문으로 인한 데이터 변경 작업은 논리적인 작업 단위인 트랜잭션으로 묶일 수 있으며, 이러한 트랜잭션을 제어하는 명령어 이다.
1) 중복 제거 : GROUP BY, DISTINCT
1-1) GROUP BY
- 중복을 제거한다. 추가로 정렬(Filesort)
- 특정 그룹에 대한 출력이 필요 할 때!
1-2) DISTINCT
- 나도 분명 중복을 제거한다. BUT 정렬 X, GROUP BY 보다 빠름
2) 정렬 ORDER BY DESC, ORDER BY ASC
3) NULL값 검사 :
- SELECT 1 IS NULL, 1 IS NOT NULL
* 1은 NULL이다? NO, 1은 NULL이 아니다. OK
- SELECT 1 = NULL, 1 <> NULL, 1 < NULL, 1 > NULL
* 참고 : 산술 연산자를 직접 사용할 수 없다. 모두 NULL만 출력
- SELECT 0 NOT NULL, 0 IS NOT NULL, "IS NULL", "IS NOT NULL"
* IS NOT NULL을 활용하요 NULL검사를 한다! 기억!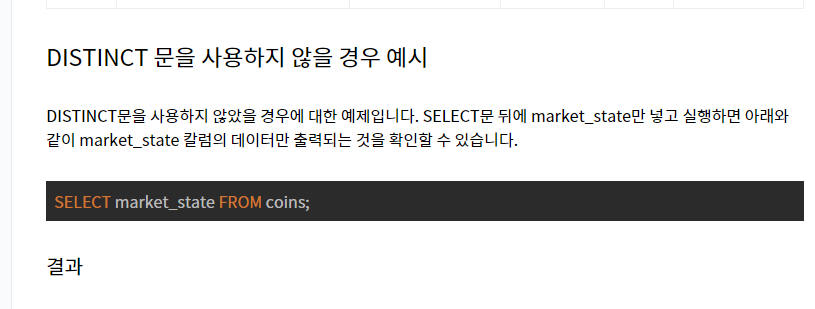
4) 패턴 검사
-
기존 유닉스와 유사한 정규패턴 사용
-
SELECT FROM pet WHERE name LIKE 'b%';
이름이 b로 시작하는 동물을 pet테이블에서 찾아라
-
SELECT FROM pet WHERE name LIKE '%fy';
이름이 fy로 끝나는 동물을 선택
-
SELECT FROM pet WHERE name LIKE '_ _ _ _ _';
이름이 5개 문자가 포함된 동물을 선택
< 정리 >
1) 중복제거 : GROUP BY, DISTINCT
2) ORDER BY DESC/ASC : DESC = 오름차순(숫자가 큰거부터), ASC = 내림차순(숫자가 작은거 부터)
3) NULL 체크는 IS NOT NULL로 한다.
4) 'a%', '%b', '_ _ _' == a부터 시작하는거, b로 끝나는거, 단어가 3개인거
3. Apache 시작/재시작/정지
1) 그룸 IDE -> 터미널 -> apt-get update
apt-cache search apache2
apt-get install apache2 -> Y
service apache2 start 시작
service apache2 stop 정지
service apache2 restart 재시작
2) MYSQL DB 설치 및 확인
apt-get search mysql
apt-get install msql-server
db 실행/정지/재시작
service mysql start/stop/restart
4. AUTO_INCREMENT 특징과 초기화
-
AUTO_INCREMENT 는 일반적으로 기본키를 생성하는 방법으로 삽입할 때마다 키를 1씩 증가 시키는 순차번호이다.
-
AUTO_INCREMENT는 "다중 데이터 베이스 (다중 DB)"에서 동기화 되지 않은 삽입으로 인해 데이터 일관성에 "문제"가 생길 수 있다.
-
AUTO_INCREMENT는 KEY를 예측할 수 있어 "SQL INJECTION"공격에 취약 할 수 있으므로, 사용에 주의해야한다.
-
다중 DB 환경에서는 "데이터 일관성"을 위해 128빝 숫자로 이루어진 식별자인 "UUID"를 키로 사용할 수 있다.
< 정리 >
AUTO_INCREMENT ?? ->
-
기본 키 고유 식별자 활용가능
-
순서 번호이다.
-
데이터 삽입하면 자동 증가
CREATE TABLE
animals(
idmediumint(9) NOT NULL,
namechar(30) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
INSERT INTOanimals(id,name) VALUES
(1, 'dog'),
(2, 'cat'),
(3, 'penguin'),
(4, 'lax'),
(5, 'whale'),
(6, 'ostrich');
덤프된 테이블의 인덱스
테이블의 인덱스animals
ALTER TABLEanimals
ADD PRIMARY KEY (id);
ALTER TABLEanimals
MODIFYidmediumint(9) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=102;
<
이렇게 테이블 설정 했기 때문에
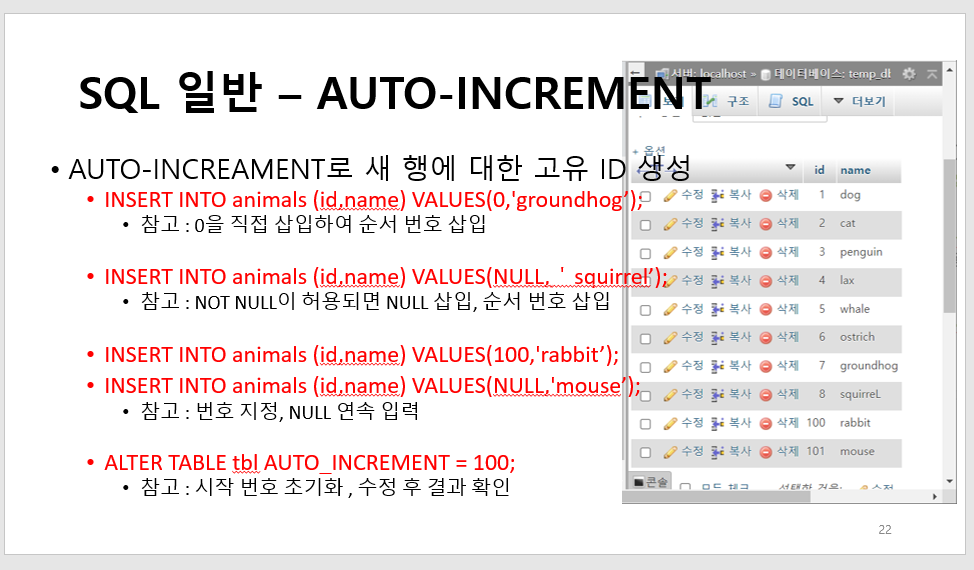
데이터 이렇게 넣으면
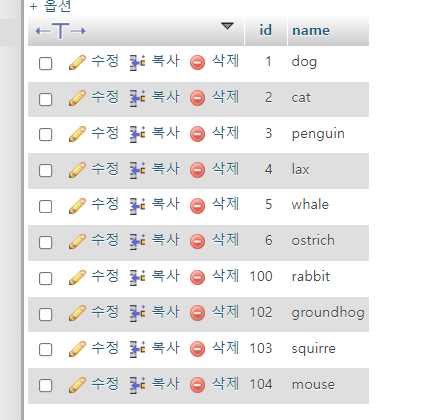
이런식으로 나옴.
5. DB종류 별 특징과 요구사항
- 관계형 SQL
정형 데이터
관계를 KEY로 연결
복잡한 쿼리 및 스키마 유연성 X
수평확장 X (수직 확장만)
* 설계후 정규화 어려움 - NOSQL
유연, 확장, 고성능, 가용성으로 발전함
비정형 데이터 사용
규칙이 없음
쿼리가 복잡하지 않고 스키마 유연성 O
설계후 정규화 어렵지 않다.
쿼리 단순, 스키마 X, 조인 X, 외래키 X
구조적 질의 언어 없음, 관계 X => 유연성 올라감
종류 : 키, 그래프, 도큐먼트, 컬럼

6. MYSQL 접속방법
1) service apaceh2 start
2) service mysql start
3) 현재 자신의 컨테이너
https://starkshn97.run.goorm.io/phpmyadmin으로 접속
4) root 계정 입력, password입력하면 접속 완료
7. SQL 함수 (시간, 개수, 최대값, 최소값)
-
시간
* (SYS)DATE, COUNT, MAX, MIN * TIMESTAMPDIFF(YEAR, BIRTH, DATE)
-
개수
* COUNT(*) 뭐 이런식으로 씀 -
최대값
* MAX -
최소값
* MIN
8. PHP를 위한 URL 재작성 방법
a2enmod rewrite
9. MYSQL 내부 데이터베이스 4가지
1) information_schema : DB 메타 정보(개념 스키마)
- 읽기 전용, 테이블 이름, 컬럼, 타입, 권한등
2) mysql
- 외부 스키마 및 계정 관련, 이벤트/기능/플러그인 등
3) performance_schema
- 내부 실행 검사 : 쿼리 분석 및 해석 체크, 락/싱크로 등
- 주요 모니터링 : 이벤트, 함수, 정렬 등
4) phpmyadmin
5) sys
- 실행중 스키마 내부 로그 요약 및 리포팅
10. SQL 사용자 변수 (선언 및 초기화, 세션 동작 특징)
SET @변수명 := 값;
11. MYSQL 패스워드 암호화 방식
사용자 계정 패스워드 -> 기본암호화
SHA1 또는 SHA2 해시 알고리즘 적용, password()함수
DB에 저장된 실제 암호는 암호화 (단방향) 문자열
보안상 완벽하지 않다! -> 왜?-> 패스워드 무작위 대입 -> 해시 값 추출 가능성
최근 8.0 최신 버전(보안 강화됨)
SHA1 -> SHA2 버젼으로 업그레이드
암호화 방식은 SHA2이다.
12. 서버 RELOAD(캐시 삭제)
flush privileges;
13. 보안 정책 강화 후 기본 정책
1) MYSQL DB의 패스워드 정책 살펴보기
- SHOW VARIABLES LIKE "%password%"
2) 정책 주요 내용( 버전 마다 상이 )
-
기본 패스워드 주기, 만료, 알고리즘 등
-
SHA2 자동 생성 및 관련 정보
3) 지금 패스워드 123123
-> 문제된다.
4) 기억하자
- 123123으로 저장 안됨 -> 암호화 돠어서(SHA2방법으로) 저장됨.
< 정리 >
쉬운 패스워드 앞으로는 생성 불가
8글자이상, 대소문자, 숫자, 특수문자 1개 이상 포함
14. SQL 제약 조건 UPDATE, DELTE 설정 차이
SQL 제약조건 : NOT NULL, 기본키, 왜래키 등으로 모두 데이터 무결성을 지키기 위해 입력 값을 검사하는 규칙을 의미한다.
UPDATE : 테이블의 내용 수정(DML) 단순히 데이터를 수정 한다.
DELETE : 테이블의 내용을 삭제한다.
15. UPDATE와 ALTER의 차이점
둘 다 내용을 수정한다는 "공통점" 존재
BUT "차이점"은
UPDATE -> 테이블의 내용 수정 : DML 데이터 조작어 -> 주요 읽기 - 빈도 가장 높음
즉, 단순히 데이터를 수정한다.
ALTER -> 테이블의 속정의 내용을 수정 : DDL : 데이터 정의어 -> 설계/관리 단계
죽, 필드, 데이터 유형, 키, 제약 조건 등을 수정한다.
<결론>
ALTER는 테이블의 구조도 변경한다. 훨씬 권한이 높다.
16. 일반 사용자 계정을 생성하는 이유
일반 사용자 계정의 필요성
Root 계정 로그인은 위험하다. 세션 보안!
17. MYSQL엔진 방식의 종류
1) 공통 : SQL 처리엔진 + 스토리지 엔진
- 쿼리 분석 및 최적화 - S/W 제어
- 디스크 저장 - H/W 읽기/쓰기
2) INNODB 엔진 (default)
-
실시간 제어(기본)
-
용량 : 64TB, 외래키 지원, 클러스터 인덱스, 데이터 캐시 등
3) MYISAM 엔진
- 읽기, 트랜잭션 X
4) Memory 엔진
- 빠른 속도, 저장 X
5) Archive 엔진
- 쓰기, 삭제와 수정 X (로그 수집)
6) CSV 엔진
- 외부 데이터 교환
7) Federated 엔진
- 원격 서버 연결
8) Blackhole 엔진
- 복잡한 복제, 감사 로깅
[ 내부 지원 엔진 확인하기 ]
SHOW engines;
18. MYSQL메모리 관련 주요 변수
MYSQL 메모리 구조와 할당
1) 글로벌 메모리 영역 + 세션(커넥션) 메모리 영역
-
글로벌 메모리 : OS에서 설정 할당, 모든 쓰레드 공유
-
로컬 메모리 : 쿼리 처리에 따라 할당, 쓰레드 공유 X, 클라 독립
2) 주요 변수
-
innodb_buffer_pool_size : 데이터 및 인덱스 캐싱
-
innodb_additional_mem_pool_size : 데이터 사전 및 구조 캐싱
-
innodb_log_buffer_size : 로그 버퍼 캐싱
19. 데이터의 종류
-
정형 데이터 : 행과 열을 갖는 표준 데이터베이스와 같이 관계형 스키마로 구성된 데이터를 간단한 질의문을 통해 원라는 정보를 획득해 사용함 ex) 데이터 베이스, 스프레드 시트, 시트 등
-
반정형 데이터 : 고정된 스카미를 갖지 않는 정형 데이터로 데이터에 레코드 및 필드와 같은 구조를 갖기 위해 태그나 인덱스 사용 ex) 시스템 로그, 센서 데이터, HTML등
-
비정형 데이터 : 구조화 되지 않은 임의의 형식 ex) 이미지, 동영상, 이메일, 문서 등
20. RDB의 한계
복잡한 쿼리 및 스키마가 유연하지 못하다.
수평 확장이 불가능하고 수직 확장만 가능하다.
설계 후 정규화 어렵다.
관계형 데이터 베이스 이기때문에 그렇다.
관계형 DB의 특징이
2주차 PPT에서

이렇게 설명을 해주었었다.
21. 테이블 구조 확인(터미널)
꼭 확인해야됨!
GUI를 제공하지 않는 서버 기반 환경
-
그룸 IDE 하단 리눅스 터미널에서 확인 하는 방법
- mysqladmin version- mysqladmin variables
-
접속하여 내부 상태 확인
- mysqladmin -uroot -p version
-
데이터 베이스만 확인
- mysqlshow -uroot -p
-
데이터 베이스 내 테이블까지 확인
- mysqlshow mysql -uroot -p
< 정리 >
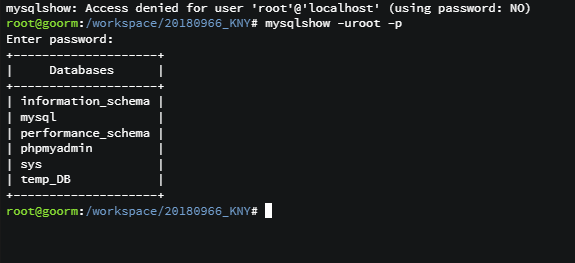
이렇게 데이터 베이스 뭐 있는지 확인 가능
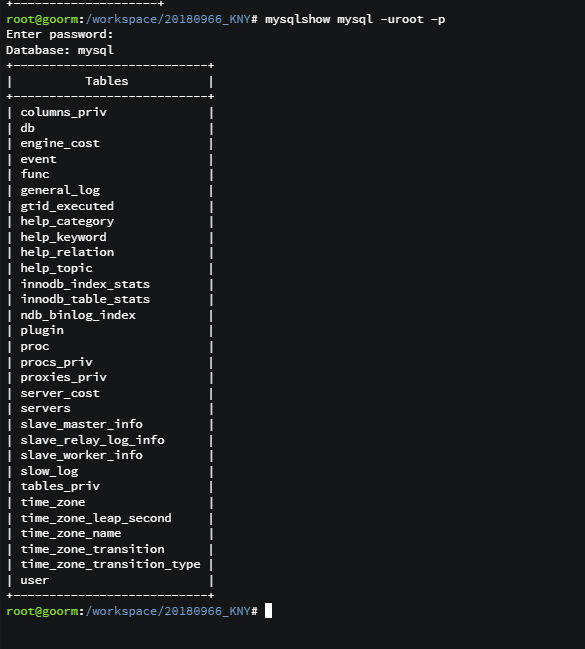
이거는 mysql이라는 DB의 테이블 확인한것임
22. 내장 데이터 타입(사진, 동영상, 문서)

1) MYSQL의 데이터 타입
-
CHAR, VARCHAR, TEXT, DATe, TIME 등
-
BLOB : 사진, 동영상, 문서등 대용량 이진 데이터 저장
2) MYSQL의 다양한 내장 함수
- 일반적 : 검색과 문자열, 수학/날짜/시간, 제어 흐름 및 보안등
< 요약 >
"BLOB"
23. 사용자 생성 및 패스워드 지정
1) 현재 MYSQL에 존재하는 계정 확인
- MYSQL -> user 테이블 확인 (root, phpmyadmin)
2) 일반 사용자 계정 필요성
- Root 계정 로그인은 위험하다. 세션 보안!
3) 데이터 베이스마다 접속 계정을 생성해야 한다.
4) phpmyadmin -> sql -> 직접입력 DB생성!
- CREATE DATABASE temp_db;
5) 생성된 DB확인
Mysql DB의 -> user테이블 확인
6) phpmyadmin -> sql이동
- CREATE USER 'guest'@'localhost' IDENTIFIED BY '12345678'(나는 123123으로함)
PASSWORD EXPIRE NEVER;
7) 생성된 계정은 ㅇㄷ?
- 생성된 guest 계정은 ㅇㄷ?
- mysql -> user테이블 확인 ㄱㄱ
8) temp_db에는 user테이블이 없다.
- 기본적으로 mysql db가 선택되어 있는 것이다.
- 예 ) use mysql;
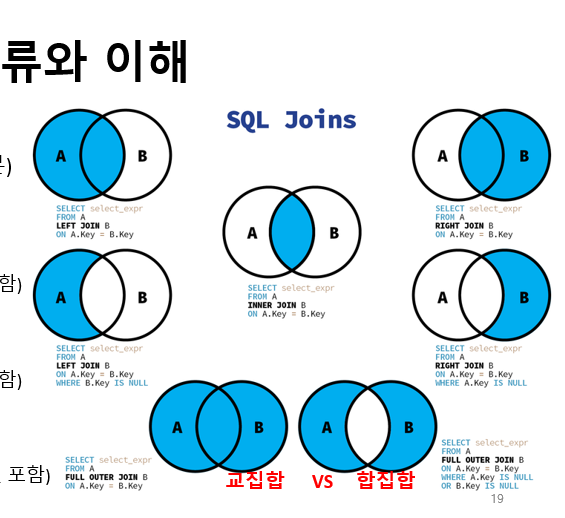
24. SQL 조인(셀프, INNER, LEFT)
JOIN을 사용하는 이유 : 서브쿼리 방식은 매우 느려질 수 있다.
5.0 이후 서브쿼리 성능 크게 개선 BUT 같은 기준으로 비교젹 INNER JOIN이
연산 효율성이 높아서.
- 셀프
SELECT p1.name, p1.sex, p2.name, p2.sex, p1.species
FROM pet AS p1 INNER JOIN pet AS p2
ON p1.species = p2.species
AND p1.sex = 'f' AND p1.death IS NULL
AND p2.sex = 'm' AND p2.death IS NULL;
-> pet에 살아있는 종의 암컷, 수컷 쌍을 출력
INNER JOIN
- 교집합 출력
- 공통된 부분을 출력한다.
- 쿼리 성능 제일 빠름
LEFT JOIN
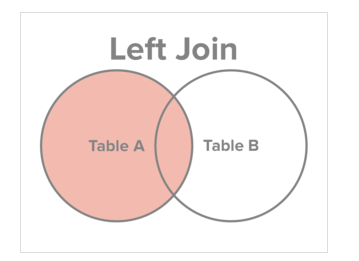
- 공통 + 왼쪽
- 공통 제외 + 왼쪽(오른쪽은 NULL 포함)
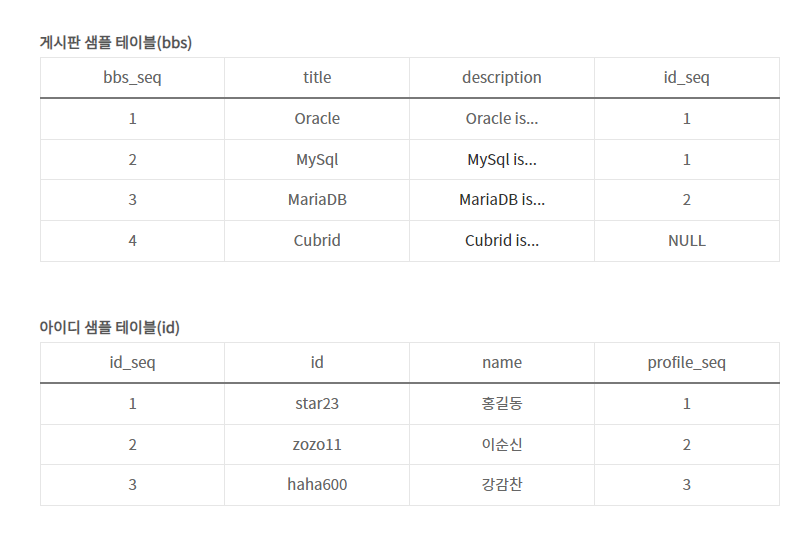
두개의 테이블이 있으면
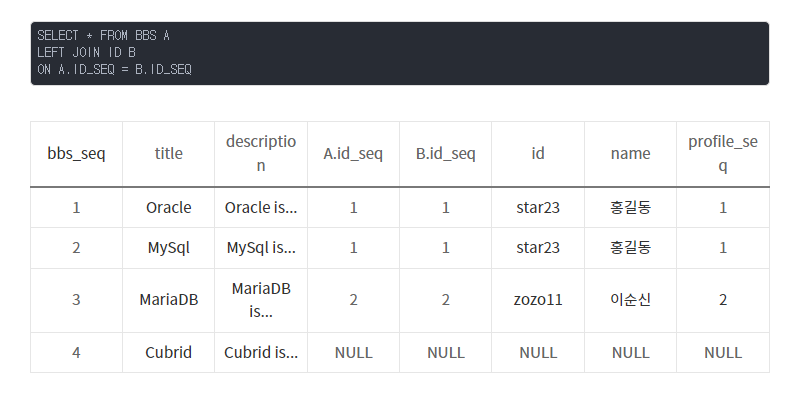
쿼리 실행하면 화면 처럼 나오게된다.
25. MYSQL의 주요 설정 파일 이름
1) 서버 내부 저장 경로
-
그룸 IDE 하단 터미널 창 : cd경로로 확인 가능
-
usr/share/mysql 뭐 이런식
2) 파일 구성
-
주요 실행 파일
-
/usr/bin/mysql 내에 대부분 존재
* Mysql(클라), mysqld(서비스용), mysqldump(백업) 등 다양한 파일 존재 -
!주요 설정 파일!
* /etc/mysql/my.cnf -> 다른 위치로 이동- /etc/mysql/mysql.conf.d -> mysqld.cnf (실제 설정 파일이다.!)
3) 설정 파일 열어보기
- cat /etc/mysql/mysql.conf.d/mysqld.cnf
* cat은 파일 내용을 출력하는 명령어이다.
4) 주요 환경 설정
-
tkdydwk, pid, 포트, 데이터, 임시 폴더 등
-
튜닝 관련 설정
* 키, 접속자, 쓰레드, 캐시 등
5) 생성된 DB는 ㅇㄷ?
- cd/var/lib/mysql
6) Mysql 내부 살펴보기
- Frm : 구조, idb : 데이터 및 인덱스 정의
- MYD : 실제 데이터, MYI : 실제 인덱스 정보
7) 전체 INNODB 테이블 확인
-
phpmyadmin접속 후 확인
-
SEELCT tablespace_name, file_name, file_type from information_schema.files;
< 정리 >
SQL 주요 설정 파일 이름은
주요 설정 파일
/etc/mysql/my.cnf -> 다른 위치로 이동
/etc/mysql/mysql.conf.d -> mysqld.cnf (실제 설정 파일!)
mysqld.cnf (실제 설정 파일!)
26. SQL 기본키와 외래키 구분, 역할
1) 테이블에서 KEY란?
- 고유 식별자이다.
2) 고유 값 = 유일
- 일반적 : 테이블 마다 존재, 고객번호/도서 번호등등
3) 기본키와 외래키
-
기본키 : 대표 키, 고유 식별자, 다중 키 가능
* 참고 : NULL값 허용 안한다. 수정이 어렵ㅏ. -
외래키 : 기본키를 참조, 테이블의 관계를 연결 할 때 사용!!
* 참고 : 다중 그룹 가능, 도메인 반드시 동일, NULL && 중복 허용
관계형 데이터 모델에서 "외래키" 는 참조 되는 관계의 기본키와 대응되어 참조 관계를 표현한다.
관계에 "외래키"가 존재한다면, "외래키"값 중 적어도 하나는 주 관계에 속한 튜플의 "기본키" 값과 같거나 완전한 NULL이어야 한다.
테이블 내에 "기본키"로 정의되는 속성은 NULL값을 허용하지 않으며, 모든 튜플에서 유일해야 하며, "외래키"로 참조될 수도 있다.
"제약 조건"은 NOT NULL, 기본키, 외래키 등으로 모두 "데이터 무결성"을 지키기 위해 입력 값을 검사하는 "규칙"을 의미한다.
"제약 조건"은
INSERT INTO parent (id) VALUES (1);
하면 parent의 기본키인 id에 1이 들어감
그런데
INSERT INTO child (id, parent id) VALUES(2, 2);
를 하게 되면 ERROR발생하는데
현재 child테이블을 parent의 기본키인 id를 참조하는데
parent의 id값이 1이기때문에 child에서 2, 2라는 값을 넣어줄 수 없다.
또한

DELETE FROM parent WHERE id = 1;이 안되는 이유는
"개체 무결성"을 유지해야 하기 때문이다.
1) "개체 무결성"이란?
-
하나의 테이블에는 적어도 하나의 키가 존재해야한다.
-
기본키는 절대 NULL일 수 없다.
2) "참조 무결성"이란?
- 외래키는 NULL 이거나 반드시 기본키 값을 사용(참조)해야 한다.
3) 도메인 무결성
- 특정 속성은 도메인에 속한 값이어야한다.
4) 기타
- NULL무결성 : 특정 속성이 NULL일 수 없다.
문제 정리
4주차
MYSQL 패스워드 보안 정책 적용 후 기본 보안 수준

보안정책 적용하면
보안 정책 적용 쉬운 패스워드 앞으로는 생성 불가
참고 : LOW - 8글자, HIGH – 사전 파일로 엄격한 검사
5주차

1) MYSQL의 주요 설정 파일 경로와 파일명 : 파일명은 mysqld.conf인가? mysqld.cnf이다.
SQL 주요 설정 파일 이름은
주요 설정 파일
/etc/mysql/my.cnf -> 다른 위치로 이동
/etc/mysql/mysql.conf.d -> mysqld.cnf (실제 설정 파일!)
mysqld.cnf (실제 설정 파일!)2) Process id의 약자, 말 그대로 프로세스 아이디이다.
3) mysql의 default엔진은 : INNODB이다. mysql에 엔진이 7~8가지 종류가 있는데
INNODB의 특징은 "트랜잭션"을 지원하는데 최적화 되어있다.
4) SQL에서 특정 행의 중복제거 DISTINCT
5) ORDER BY DESC
6) DATETIME
7) IS NOT NULL로 검사를 한다.
6주차

1) NULL 체크를 할 때 "산술 연산자를 직접 사용할 수 없다"
- <>, != 는 "같지 않음"을 나타낸다.
2) '%'이다
-
'%a'일경우 a로 끝나는 문자
-
'a%'일경우 a로 시작하는 문자
-
'__' 일경우 단어가 두개인 문자
3) COUNT함수이다.
4) GROUP BY는 그룹으로 묶어 중복을 제거하고 정렬해준다.
GROUP BY는 특정 그룹에 대한 조건을 HAVING문으로 조건 추가가 가능하다.
DISTINCT는 그룹으로 묶지 않고, 정렬은 하지 않는다.
5) GROUP BY로 묶은 것을 SEELCT에서 명시하지 않은 경우 에러 발생
6) INNER JOIN의 특징 ? => "교집합"
SELECT pet.name, TIMESTAMPDIFF(YEAR, birth, date) AS age, remark
FROM pet INNER JOIN event
ON pet.name = event.name
WHERE event.type = 'born';
7) FROM 구문에서 두 테이블을 JOIN한다.
ON 구문으로 name일치 시킴
7주차

1) MAX, MIN
2) 서브쿼리와 조인의 차이점
조인과 서브쿼리는 때로 동이란 결과를 얻기도함.
상황에 따라 다름.
서브 쿼리는 복잡한 SQL 쿼리문에 사용이 많이 된다.
반면, 조인은 여러개의 쿼리를 필요로 하지않는다.
조인의 역할은 2개 혹은 그 이상의 테이블을 연결하고, 연결한 테이블로부터 필요한 열을 조회할 수 있도록 한다.
이둘의 데이터를 추출하기 위한 "접근 방식"이 다르다.
서브쿼리의 성능 개선으로 속도가 빨리지기는 했지만
동일한 조건일 경우 아직 조인이 속도가 더 빠르다.
왜?? =>
3) INNER JOIN은 교집합인 부분을 가져올 수 있고
LEFT조인은 차집합인 부분을 가져올 수 있다.
4) 사용자 정의 변수는
SELECT @min_price := MIN(price), @max_price := MAX(price)
FROM shop;
이렇게 사용이 가능하고
SELECT *
FROM shop
WHERE price = @min_price OR price = @max_price;
위와 동일한 결과를 출력한다.
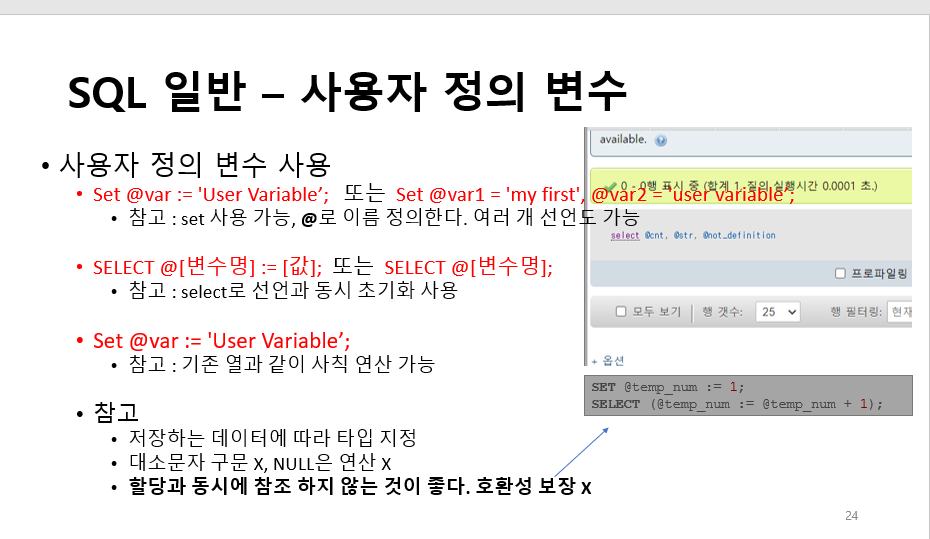
조건식에 정의를 해준다(대입 X, 비교 O)
"사용자 정의 변수"는 현재 쿼리에서만 사용가능한 "세션" 또는 동적 변수이다.
따라서 SET @name := '홍길동';
5)
-
:= => SET, UPDATE, SELECT로 값 할당
-
= => SET, UPDATE 이외 비교연산자로 사용
6) "사용자 정의 변수"는 현재 쿼리에서만 사용가능한 "세션" 또는 동적 변수이다.
-> "참"
7) 관계를 생성한다 (부모 - 자식)
8) "제약 조건 해제"
"제약 조건 해제" 두가지 옵션 -> "참조 데이터 무결성"
ON UPDATE CASCADE, ON DELETE CASCADE
* 두 옵션으로 해제가능, SQL파일 다시 살펴보자!
“한국인이 운영하는 유대인 공부법 맛집”