0. Intro
이번에 다뤄볼 논문은 pointer generator라고 불리는 논문이다. arxiv 게재 기준으로 2017년에 나온 꽤 오래된 논문이지만(2017년 논문을 오래됐다고 할 때마다 이게 맞나 싶다...) summarization 분야나 연구실에서 하고 싶은 DST(Dialogue State Tracking, 추후에 포스팅해보자) 분야에서 여전히 유의미하게 사용되고 있는 것 같아 리뷰하게 되었다.
우선 2017년 기준으로 당시의 상황은 다음과 같다.
- summarization 분야에서 abstractive 방법론들이 등장하기 시작했다. 즉, rnn류 모델로 유의미하게 요약문을 "생성"할 수 있는 실마리를 찾았다.
- 하지만 기존의 방법론은 (1) 중요한 정보를 찾지 못하거나 (2) 반복적으로 특정 단어를 생성해내는 문제점이 있었다.
- 아직 트랜스포머가 발표되기 전이라, rnn 기반의 seq2seq으로 모델들이 활발히 연구되고 있었다.
또한, summarization task에 대해 간단히 서술해보면 다음과 같다.
- Extractive Summarization : 주어진 문서에서 중요 문장 k개를 고르는 태스크
- Abstractive Summarization : 주어진 문서에서 정보를 조합하여 요약문을 "생성"하는 태스크
상대적으로 extractive summ.은 쉬운 태스크에 속한다. 주어진 문장 중에 중요 문장을 고르는 classification에 가까운 태스크이기 때문이다.
상대적으로 어려운 abstractive summ.이 유의미한 이유는 여러 정보를 조합하고, 문서에 주어지지 않은 실제 세계의 지식을 활용하여 요약문을 생성하기 때문에 더 그럴듯한 결과물을 얻을 수 있기 때문이다.
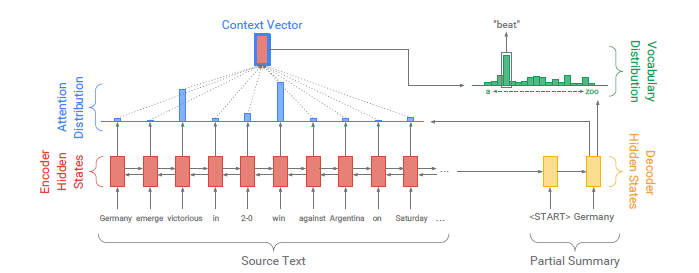
위에서도 이야기했듯이 번역 태스크를 고려하여 발표된 다양한 seq2seq with attention모델들이 abstractive summ.에서도 성과를 나타내기 시작했다. 직관적으로 생각해도 attention을 사용하면 요약문 생성 시 각 타임 스텝마다 문서에서 중요한 정보들을 취사선택해서 가져올 수 있기 때문에 abstractive summ.에 적합한 모델이라고 할 수 있다.
하지만 seq2seq with attention 모델들 역시 몇가지 문제점을 안고 있다.
- 몇가지 정보들에 지나치게 집중한다는 점
- 반복적으로 동일한 단어를 생성한다는 점
- Out-Of-Vocabulary 문제.
pointer-generator는 일종의 하이브리드 방법론을 통해 abstractive 태스크를 수행하지만, extractive한 성격을 띄는 모델이다. 이를 통해 기존의 번역 태스크에 적합하게 설계된 seq2seq with attention과 달리 보다 summarization 태스크에 적합한 모델이 될 수 있었다. 하나씩 자세히 살펴보도록 하자.
1. Seq2Seq with attention
seq2seq with attention 모델은 이전에 반다나우 어텐션 모델을 다루면서 한번 살펴본적이 있다. 여기에서 확인하기 바란다. seq2seq with attention에 대한 자세한 설명은 해당 게시글로 갈음하겠다.
이 장에선 seq2seq with attention 모델이 summ. 태스크에 완벽히 적합하지 못한 이유를 중점적으로 살펴보자.
주의 논문을 읽고 나름대로 생각한 뇌피셜임.
seq2seq with attention은 기본적으로 번역 태스크를 염두에 두고 만들어진 모델이다. 번역 태스크는 source text와 target text가 다른 언어로 이루어져 있다. 즉, source의 토큰들을 그래도 output으로 끌고 올 수 없다. 인코더에서 source의 정보를 가공하고, 이를 디코더에서 적절하게 가져와 target text를 만들어내는 것이 중요하다.
이를 위해 seq2seq with attention에선 디코더에서 인코더의 각 시점에 대한 attention dist.를 생성하고, 이에 맞추어 인코더 정보를 가져오는 방식을 취하고 있다.
하지만 summarization 태스크는 기본적으로 source text와 target text가 동일한 언어로 되어있다. 즉, source의 토큰을 output으로 그대로 가져와도 된다. summarization의 진정한 문제는 source에서 어떤 토큰을 output으로 가져올지 선택하는 문제이다. 아무리 abstractive summarization이라 하더라도 대부분의 토큰은 source와 동일할 것이기 때문이다.
즉, seq2seq with attention은 abstractive summarization 문제를 너무 복잡하게 풀고 있다. 문장을 밑바닥부터 생성할 필요가 없이, source에서 가져올 방법을 고민하면 되는데, scratch부터 생성하고 있는 것이다.
2. Pointer-Generator
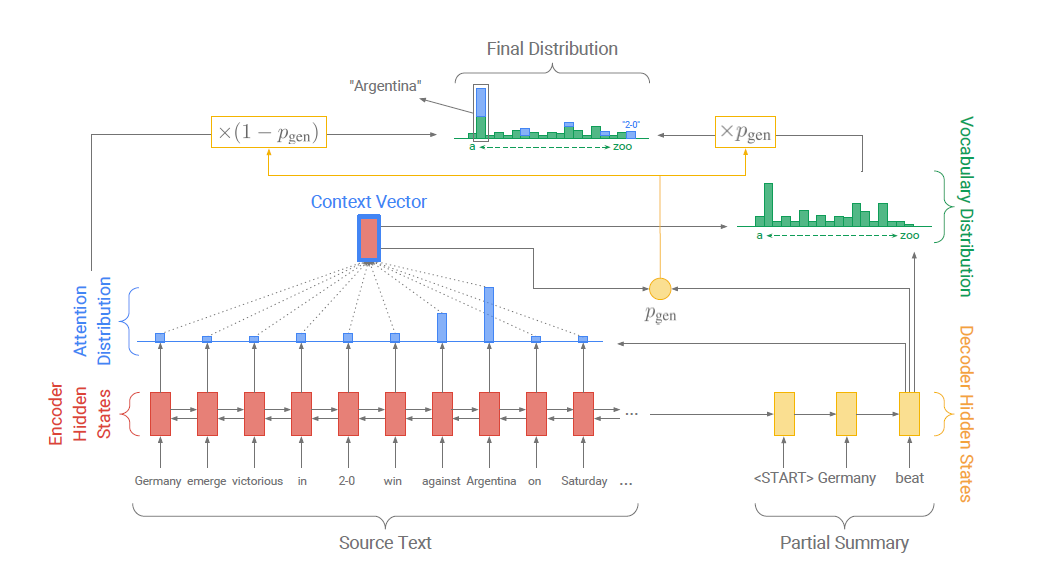
그래서 pointer-generator 모델은 다음 두가지 방법론을 혼합한 하이브리드 방식을 취하고 있다.
- pointing : source에서 어떤 토큰을 복사하여 output으로 내보낼지 정하는 작업
- generating : 고정된 vocab에서 어떤 토큰을 생성할지 선택하는 작업
구체적으로 어떻게 두 방법론을 혼합하고 있는지 하나씩 살펴보도록 하자.
2-1. seq2seq with attention
기본적으론 dnn을 이용해 유사도 함수를 근사하는 seq2seq with attention 구조를 차용하고 있다.
notation은 다음과 같다.
- : learnable parameters
- : encoder hidden state
- : decoder hidden state
- : context vector
2-2. generation probablity
pointer-generator는 다음과 같이 각 시점마다 generatrion probablity를 구하게 된다.
여기서 는 decoder의 input이다.
그리고 이렇게 구한 generation probablity는 문장 생성 or 원문 복사를 선택하는 "soft switch"로서 다음과 같이 역할하게 된다.
이를 그림을 통해 살펴보면 아래와 같다.
-
바다나우 어텐션을 통해 attention dist.를 생성한다.
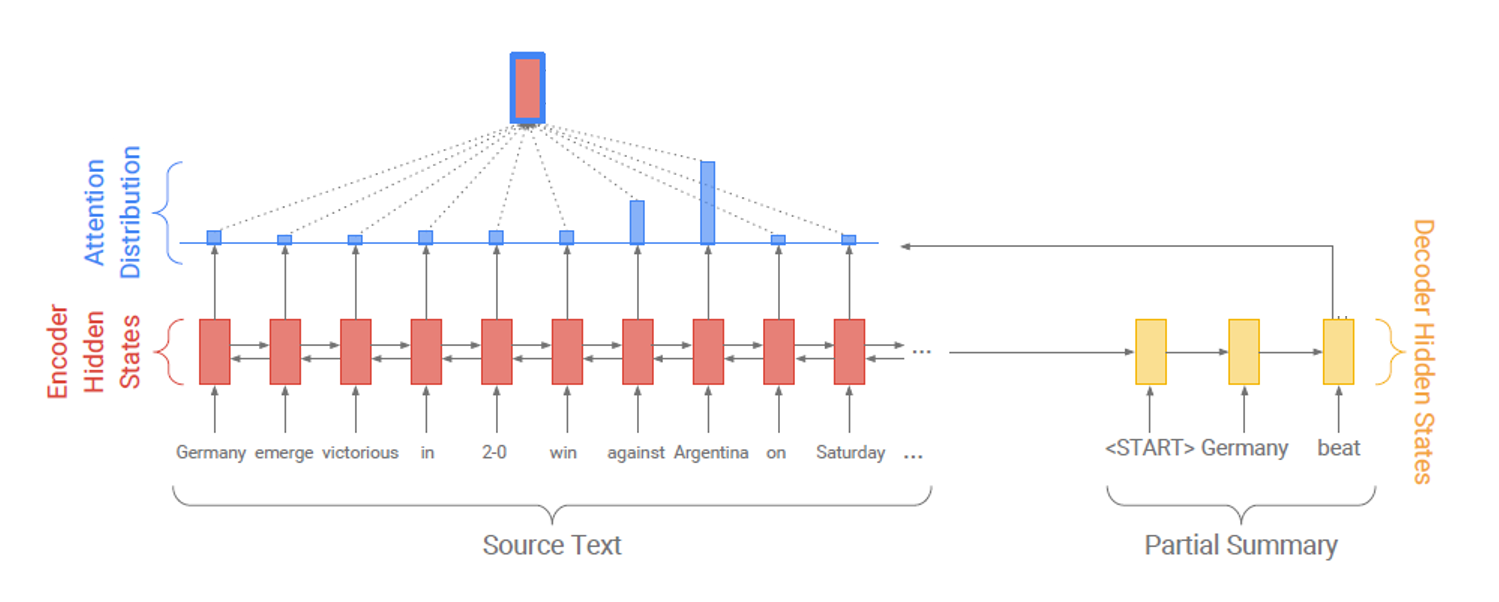
-
seq2seq with attention처럼 attention dist.와 decoder hidden state를 이용하여 디코더 현재 시점의 vocab dist.를 생성한다. 즉, 기존 seq2seq attention에서 예측하는 토큰의 확률 분포이다.
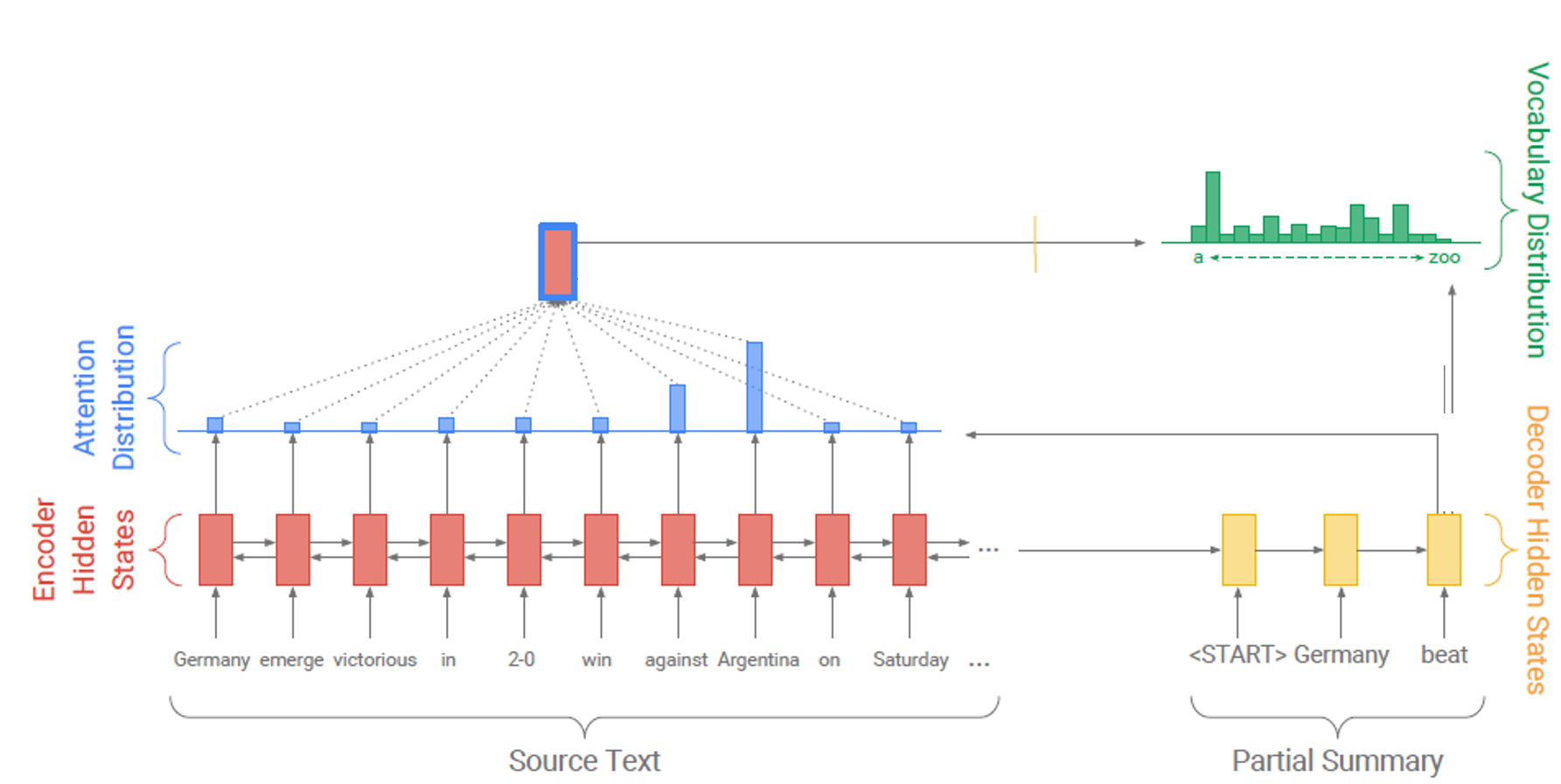
-
attention dist., vocab dist. decoder input을 통해 을 생성한다.
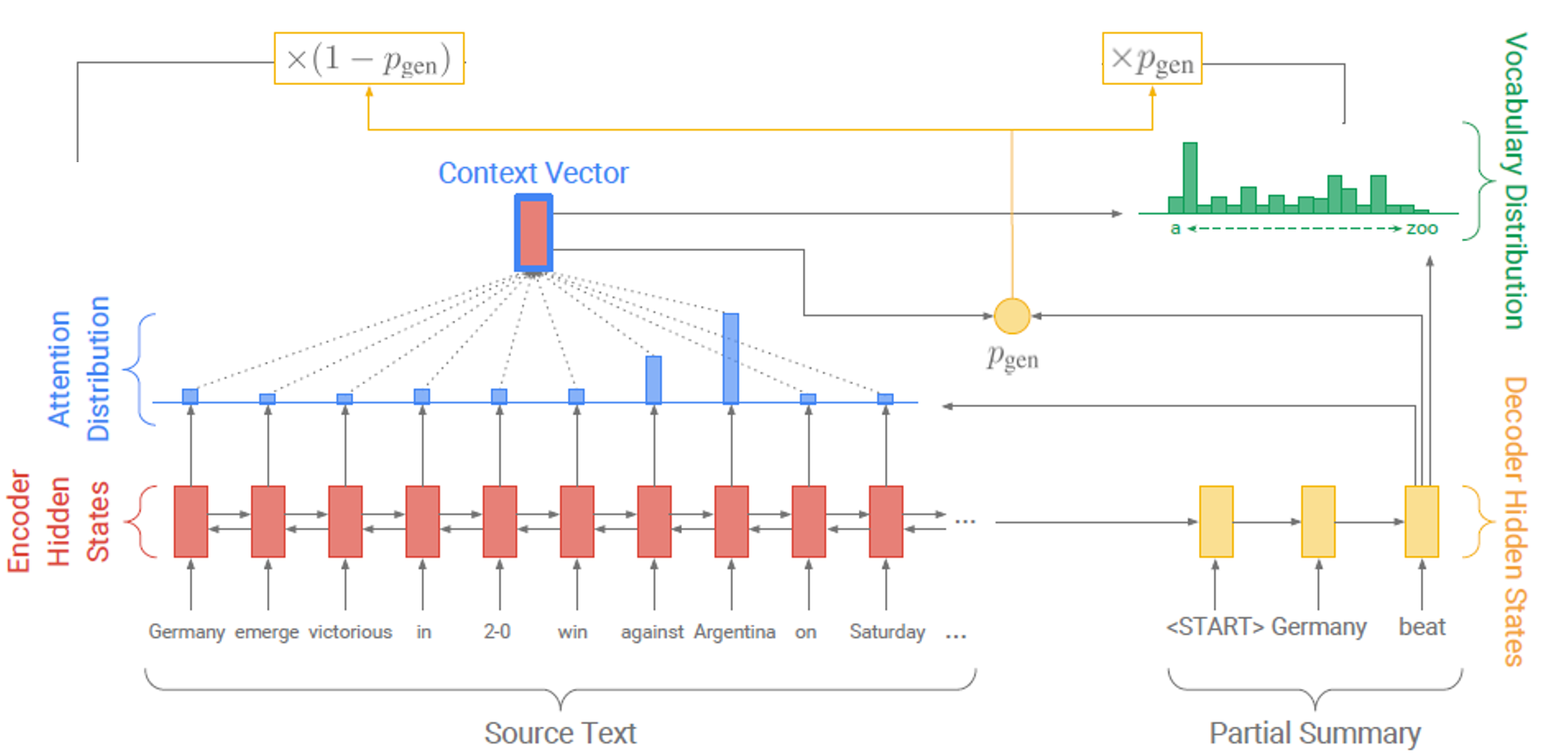
-
을 통해 attention dist.와 vocab dist.를 합친다.
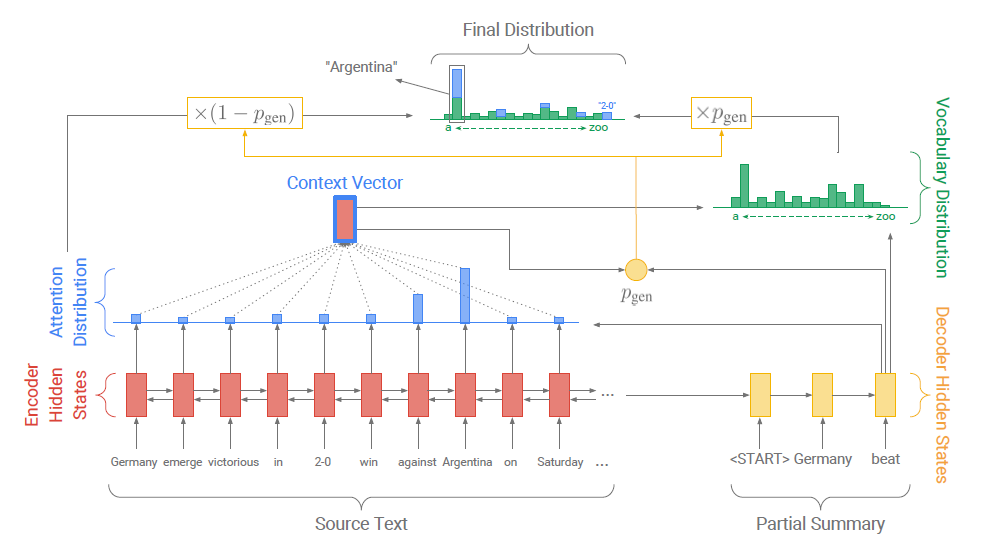
이때 주의할 점이 4의 과정에서 vocab dist.는 전체 vocab에 대한 확률 분포인 반면, attention dist.는 input sequence의 각 토큰에 대한 확률 분포라는 점이다. 즉, 두 분포가 동일하지 않다. 그래서 기존의 vocab dist.에 input sequence에 등장한 토큰에 대해서만 각각 attention dist.를 더해주게 되는 것이다.
즉, attention을 많이 준 input sequence의 토큰을 soft coping하여 최종 출력 분포에 사용하고 있는 것이다.
2-3. OOV Handling
본 논문에서는 반복적으로 pointer-generator가 oov 문제를 해결하고 있다고 하는데, 논문 자체에는 이와 관련해 구체적인 내용이 없다. 그래서 논문 repository에서 확인해보니 다음과 같았다.
- 우선 vocab의 크기를 (실제 vocab size + OOV용 예비 vocab)으로 구성한다.
- 매 배치마다 (frequency 등을 기준으로) oov로 처리되는 토큰들을 임시로 oov용 id를 부여한다. 이때 다른 oov token은 다른 oov id로 배정이 된다.
- 모델의 입력값으로 oov id 역시 임베딩 되어 들어간다.
- 실제 decoder에서 생성하는 vocab dist.에선 oov를 처리할 수 없으므로 oov id에 해당하는 확률값을 모두 0으로 처리한다.
- 이렇게 했을 경우에도 decoding 시 기존 vocab에 없는 토큰을 copy해야 한다고 판단하면 이 되어 완전히 source text에서 해당 oov token이 copy되게 된다.
이때 주의할 점은 매 배치마다 새로이 oov token id가 만들어진다는 점이다. 즉, 1번 미니배치에선 oov1 = Jaehee일 수 있지만 2번 미니배치에선 oov1 = Eunjee 일 수 있는 것이다.
실제로 이러한 매커니즘으로 copy 여부를 제대로 판단되는 것이 의아한데, 일단 이러한 방식으로 돌아간다고 한다.
2-4. Coverage Mechanism
특정 단어의 반복은 seq2seq 모델이 고질적으로 겪는 문제라고 한다. 특히 다수의 요약문을 생성하는 태스크에서는 그 정도가 심해진다.

위에서 볼 수 있듯이 기존 모델은 nigeria 토큰을 반복적으로 생성해버리면서 생성문의 질이 급격히 떨어지게 된다.
이를 극복하기 위해 pointer-generator는 covergae mechanism을 도입했다. coverage mechanism은 단어의 반복에 패널티를 부여하는 매커니즘인데 자세히 살펴보자.
우선, 다음과 같이 매 시점마다 생성되는 attention dist.를 이용해 sequence-wise하게 dist.를 합하게 된다.
직관적으로 생각해보면, 이를 통해 는 decoder가 모든 시점에서 attention을 가한 source text의 unnormalized dist.일 것이다. 즉, decoder가 자주 높은 attention을 가한 source text의 token은 에서 높은 값을 가지게 된다.
그리고 이를 attention mechanism에 활용해서 식을 아래와 같이 수정한다.
이를 통해 다음 시점에 대해 attention을 수행할 때 지금까지 어떤 source token에 얼마나 attention을 주었는지 정보를 주게 된다. 이는 모델이 attention을 동일한 위치에 반복적으로 주는 행동을 회피할 수 있도록 도와준다.

실제로 coverage mechanism까지 적용한 최종 요약문에선 적용하지 않은 poinet-generator에서 나타나는 "in the northeast part of nigeria라는 문구의 반복이 사라진 모습을 볼 수 있다.
2-5. Loss Function
이것이 유의미해지려면 역시나 반복에 대한 loss를 구성해서 패널티를 부여해야 할 것이다. 이는 다음과 같다.
여기서 i는 토큰의 인덱스이다.
이때 covloss의 upper bound가 일 것이다. 즉, 지금 시점에 i=3인 토큰에 대해 이전보다 큰 attention을 주면 c가 더해질 것이고, 이전 시점의 attention의 합이 더 크다면(대부분의 상황) a를 더해주게 될 것이다.
이는 기계번역 분야에서 이미 사용되던 loss라고 하는데, 이에 대한 가정은 번역 시 one-to-one alignment가 형성될 것이다 라고 한다.
summarization 시에도 one-to-one까진 아니겠지만, source의 일부만 output으로 align되어야 하므로 비슷한 맥락이라고 볼 수 있다. align되는 시점에는 큰 attention을 가하고, 이외의 시점에는 매우 작은 attention이 가해져서 peak가 매우 높은 분포를 띄어야 하기 때문이다.
최종적인 loss function은 다음과 같다.
3. Experiment
3-1. Dataset
실험을 위한 데이터셋으론 CNN/Daily Mail 데이터셋이 사용되었다. 이야기할만한 부분은 실제 단어를 entity로 치환(The United Nations -> @entity5)한 데이터셋 역시 존재했지만, 저자들은 본인 모델에 자신이 있었는지 원 데이터를 이용했다고 한다(실제론 그냥 두 버전 다 해봤을 것 같기는 하다.). 2017년까지만 해도 얼마나 모델 성능이 부족했는지 알 수 있는 부분인 것 같다.
3-2. Scores
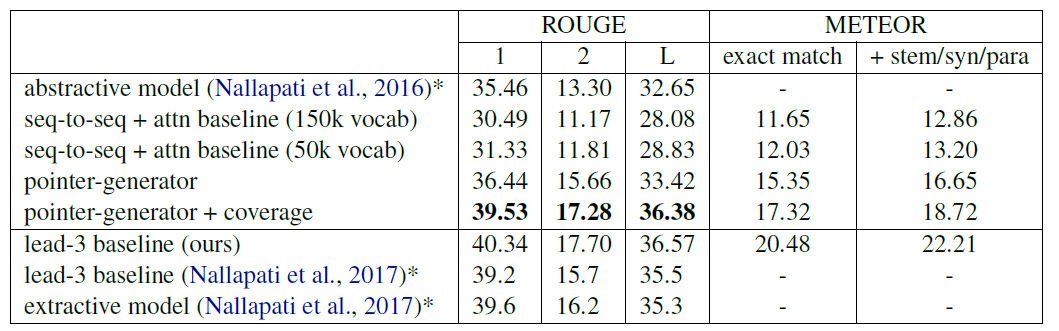
실험 내용을 살펴보면 위와 같은데, 우선 하이퍼 파라미터는 다음과 같다.
- hidden states dimension : 256
- embedding dimension : 125
- vocabulary size : 50k
여기서 특이할 점은 아마 이 시점의 모델들은 대부분 subword 기반이 아닌 토크나이저를 사용하기 때문에 150k와 같이 상당히 큰 보캡 사이즈를 가지게 되는데, 이 모델은 비교적 작은 50k로 이루어져있다는 점이다. 이는 coping mechanism을 통해 oov에 비교적 능동적으로 대응할 수 있어서라고 한다.
또한 기존의 seq2seq with attention 모델과 비교하면 추가되는 파라미터가 적다는 이점 역시 존재한다. pointer 부분은 을 계산하기 위해 필요한 파라미터가 필요하고, coverage는 attention score 계산에 를 추가하기 위한 파라미터만 필요하기 때문이다.
학습과정에선 초기에는 truncation을 많이 가해서 문장의 앞부분만 가지고 학습하고, 이후로 점점 truncation을 줄이는 방식이 효과적이었다고 한다.
또한, coverage 부분이 없을 경우에 모델이 문구를 반복하는 경향이 나타났다고 한다. coverage 부분은 모델의 본 학습시에는 학습시키지 않고, 학습이 종료된 이후에 추가적으로 학습시켰는데, 그 이유는 처음부터 coverage가 함께 학습될 경우 전체 모델의 학습에 방해가 되었기 때문이라고 한다. coverage를 본 모델 학습 이후에 사용하면서 loss가 0.5에서 0.3으로 하락했다고 한다.
4. Results
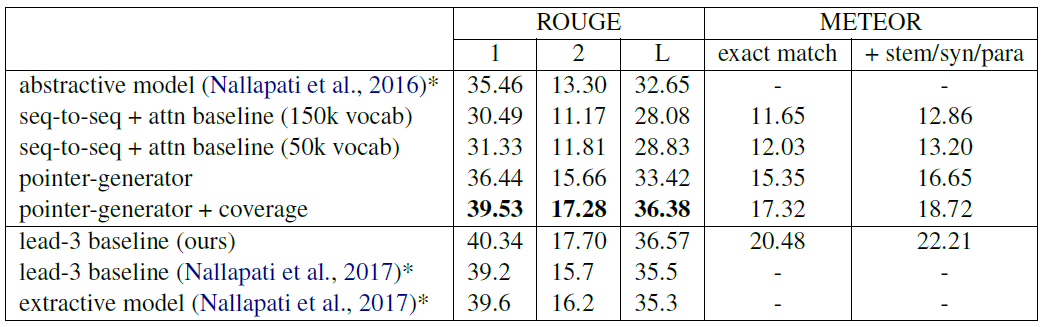
간단히 말해 SOTA를 달성했다.
이전에 발표된 모델 중 동일 데이터셋을 이용해 학습한 모델은 2017년에 발표된 SummaRuNNer(Nallpati et al.)와 2016년에 동일저자가 발표한 Abstractive Summ용 모델 뿐이었다. ROUGE를 기준으로 Nallpati의 2016년 모델과 다음 두가지 모델을 비교했다.
- 실제 abstractive summ label로 학습한 모델
- 각 문서의 제일 앞 3문장을 summarization label로 간주하고 학습한 모델
그 결과 Nallpati 2016 < 제일 앞 3문장 < 실제 label 학습 순으로 성능이 좋았다.
실험에서 사용한 baseline model과의 비교에서 ROUGE와 METEOR에서 모두 pointer-generator가 우위를 점하는 모습이었다.
질적 비교를 해보면 다음과 같다.
베이스라인 모델은 (1) 거의 등장하지 않는 단어를 자주 등장하는 단어로 대체해서 생성하기도 하고 (2) 팩트 요소들을 부정확하게 생성하기도 했다. 또한, OOV 문제 역시 제대로 다루지 못하고 있는 모습이었다.
그에 반해 pointer-generator는 단어 반복의 문제는 거의 말끔히 해소해서, 질적으로나 메트릭 적으로나 훨씬 나은 모습을 보여주었다.
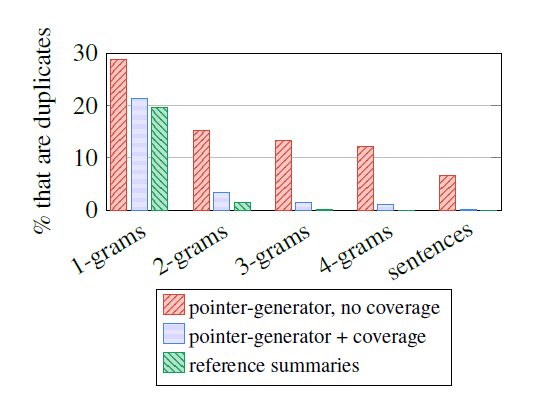
위의 사진에서도 coverage가 없는 모델의 경우 단어 반복의 문제가 심해서 심지어 문장 단위로도 나타나지만, Coverage를 도입한 모델의 경우 실제 label과 비슷하게 단어 반복의 문제가 해소된 모습이다.
4-1. Why is so Bad?
하지만 coverage까지 넣은 pointer generator마저도 extractive summ.을 수행하는 SummaRuNNer나, 문서의 앞 3문장을 학습한 pointer-generator. 모델보다는 성능이 약간 좋지 못했는데, 이는 몇가지 해석이 필요하다고 하고 있다.
- 학습 데이터인 CNN/Daily Mail는 뉴스 데이터이기 때문이다. 뉴스 데이터는 대부분 두괄식으로 작성되기 때문에 초기 3문장을 학습하는 것이 효율적일 수 있다는 것이다. 실제로 초기 400토큰만 이용해서 학습을 진행하는 것이 800토큰을 이용한 것보다 성능이 좋았다고 한다.
- ROUGE와 task 특성 때문이다. ROUGE는 정확히 일치하는 연속된 토큰에 대해서만 점수를 부여하기 때문에 abstractive model보단 extractive model이 훨씬 성능이 좋을 수밖에 없다. 또한, 평균 34개의 문장 중 중심 문장 3개를 고르는 것이 매 토큰을 새로 생성하는 것보다 쉬운 태스크일 수 밖에 없다. 이는 요약 태스크가 결국 원문의 토큰을 많이 가져오는 것에 기인하기도 한다.
2번에 대해 보완하기 위해 정확히 일치하는 토큰 뿐 아니라 유사어나 어근 등에도 점수를 부여할 수 있는 METEOR score 역시 계산해보았다고 한다. 그 결과 기존의 성능보다 1 포인트 높은 점수를 얻을 수 있엇다고 한다. 즉, abstractive를 통해 유사어 등이 생성되는 성향이 어느정도 있다는 이야기다.
다만 METEOR로 계산하여도 초기 3문장을 이용해 학습한 pointer generator가 더 성능이 높았는데, 이는 결국 두괄식 문장이 많은 데이터 구조에 기인한다고 봐야할 것이다.

실제로 논문 뒤의 예시 중 하나를 살펴보면, reference에도 원문의 초기 단어들이 많이 등장하는 것을 볼 수 있다. 또한 노란 쉐이드가 모델의 coverage 점수인데, 모델이 attention을 많이 가한 단어들이다. 앞쪽에 많이 몰려 있는 것을 볼 수 있다.
4-2. How Abstractive is the model?
그럼 copy 매커니즘이 abractive한 특성을 정말 줄이고 있는지 확인해보자.
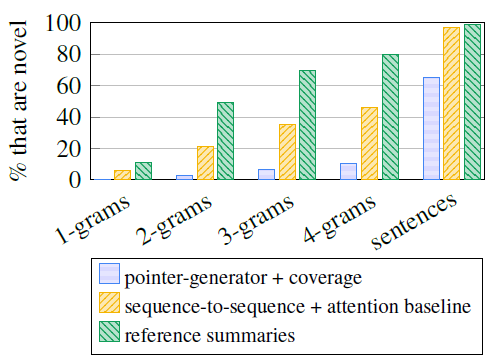
위 그림은 원문에 없는 단어를 얼마나 생성했는지 비율을 보여주고 있다. 우려와는 다르게 오히려 pointer - generator 모델이 새로 만들어내는 토큰이 많다. 위 그림은 원문에서 복사하고 있는 토큰의 수를 보여주는데, 오히려 pointer generator가 baseline 모델이나 ref 보다 낮은 비율을 보이고 있는 것을 알 수 있다.
이를 통해 pointer generator가 원문에서 필요한 단어를 선택하고, 설명구나 미사여구를 제거하고 있는 것을 알 수 있다.
의 크기로도 모델의 abstractive 정도를 가늠할 수 있는데, 학습 초기에는 0.3에서 시작해서 점차 상승하면서 0.53으로 수렴하는 모습을 보였다고 한다. 그러니까 초기에는 대부분의 토큰을 copy하는 작업으로 만들었지만, 이후에는 절반정도만 copy했다는 것이다. inference 시에는 이 많이 줄어서 0.17밖에 되지 않았다고 한다. 이는 학습 시에는 ref에서 어느정도의 supervision을 얻지만 test에서는 supervision이 없기 때문일 것이라고 논문에서는 이야기하고 있다.
하지만 test 시에도 문장 초기나 원문과 다르게 문장을 잘라서 종료하는 마침표 등의 불확실성이 높은 작업을 수행할 때는 이 순간적으로 치솟는 모습을 볼 수 있었다고 한다. 즉, copy할 순간과 generate할 순간을 모델이 잘 파악하고 있다.
rnn 기반의 모델이지만 copy 매커니즘을 적절하게 도입한 것이 신기한 것 같다. 다만 OOV를 다루는 부분에서 설명이 조금 미흡하기도 하고, 저렇게 굳이 OOV를 다뤄야 하는것인지, BPE와 같은 subword tokenizing이 대세가 된 지금에도 유효한 방법론일지는 의문이다.
