0. The Spectrum of Languages in Computer Science.
딥러닝이 각광받기 시작하면서 BOW 모델들이 많이 개발되었다. 이 모델들은 모두 단어 벡터를 가지고 입력값과 hidden layer, 출력값을 다루게 된다. 하지만 딥러닝 이전에는 언어학적 지식이 CS 분야에 많이 활용되었다. 촘스키 위계를 이용하거나 여러 문법적 구조를 트리 형태로 구현하는 등의 모습이었다.
- The snowboarder is leaping over a mogul
- A person on a snowboard jumps into the air
위의 두 문장에서 snowboarder와 person on a snowboard는 사실 동일한 뜻이다. 하지만 BOW 모델에서 여러 단어가 복잡하게 얽혀 가지는 하나의 의미를 파악하기 위해서는 단순히 워드 벡터들을 평균내거나, max pooling하거나, 혹은 특별한 토큰을 만들어서 그 토큰의 벡터를 가지고 오는 등의 방법이 있다. 하지만 어떤 방법은 너무 단순하고, 어떤 방법은 복잡하지만 활용도가 떨어진다. 언어학적 구조를 이용해서 단어들을 구나 절 단위로 파악할 수 있다면, BOW 모델이 가지는 이러한 한계를 극복할 수 있을 것이다. 그리고 이렇게 딥러닝과 트리구조 혹은 언어학적 구조를 합치고자 하는 것이 이번 강의의 내용이다.
1d Conv를 이용하는 방법이 있을 수 있다. 하지만 Conv는 고정된 크기의 필터를 가지지만, 구나 절은 매우 변동적인 단어 갯수를 가지고, 또 구나 절이 다시 통합하는 식으로 매우 복잡하게 작용한다.
사람이 위의 person on a snowboard를 이해할 때 어떻게 하는지 생각해보자. 우선, 각각의 단어의 뜻을 알고 있어야 한다. 그 이후에 각 단어의 뜻을 조합하는 어떤 규칙 혹은 지식을 이용해 뜻을 조합하여 구나 절의 뜻을 파악하게 된다. 언어학에선 이를 Compositionality(합성성)이라고 한다고 한다. 형태소의 결합으로 단어의 의미가 생성되고, 단어의 결합으로 구와 절의 의미가 생성된다. 이때 여러가지 복잡한 규칙과 휴리스틱이 개입된다.
하지만 합성성은 언어에만 존재하지 않는다. 우리가 엔진의 구조를 이해하려고 할때도, 각각의 요소들(실린더, 크랭크, 나사 등등)이 어떤 역할인지 우선 이해하고, 그 요소들이 큰 단위에서 어떻게 작동하는지 이해하게 된다. 엔진 역시 합성성을 통해 이해되고, 우리가 활용한다. 더 나아가면 또다른 NN의 큰 분야인 Vision도 결국 합성성에 의존하고 있다.

위 사진을 우리가 볼 때, 성 앞에 사람들이 모여있는 모습을 보게 된다. 하지만 성은 결국 여러 요소로 이루어져 있고, 성 외의 요소 역시 여러 하위요소로 이루어져있다는 것을 알 수 있다. 즉, 세부 요소들이 합쳐져 큰 요소를 이루어나가는 합성성을 보이고 있다.
즉, 인공지능이, 혹은 컴퓨터의 언어 이해라는 것은 세부 요소에 대한 이해를 기반으로 큰 요소들을 이해하는 과정이 될 것이다.

놈 촘스키의 인간과 동물이 차이점이 재귀적 인식을 통한 개념의 확장이라는 복잡한 이야기는 뒤로 미뤄두더라도, 인간이 사용하는 언어는 필연적으로 재귀적인 구조를 가지고 있다는 것은 분명한 점이다.

위와 같은 하나의 문장은 여러 개의 명사구로 이루어져 있고, 명사 구 안에는 명사와 전치사 등의 다양한 요소를 가지고 있다. 위 문장의 일부를 풀어서 표현해보면, 결국 트리구조가 될 것이다. 아래와 같이.

(다른 문장인 것은 신경쓰지 말도록 하자.)
1. Building on Word Vector Space Models
이번 수업에선 트리 구조를 생성할 수 있는 NN 모델을 다루고자 한다면, 기존의 워드 벡터 공간에 구나 절을 표현할 수 있어야 한다는 말과 같다. 어떻게 하면 구나 절을 기존의 워드 벡터 공간에 맵핑할 수 있을까?
다시 위에서 언급한 합성성의 두가지 요소를 떠올려보자. 1) 각 단어의 의미를 이해하고, 2) 단어들을 어떻게 결합할 지 알아야 한다. 즉, 1) 각 단어의 워드 벡터를 구하고 2) 구한 워드 벡터를 모델이 연산하여 구나 절의 벡터를 만들어낸다.

모델은 결국 주어진 단어들의 구문 구조에 따라 연산하여 구나 절 벡터를 구하게 되는 것이다. 이를 위해선 문장의 구문 구조를 분석한 결과가 필요한 것은 자명하다.
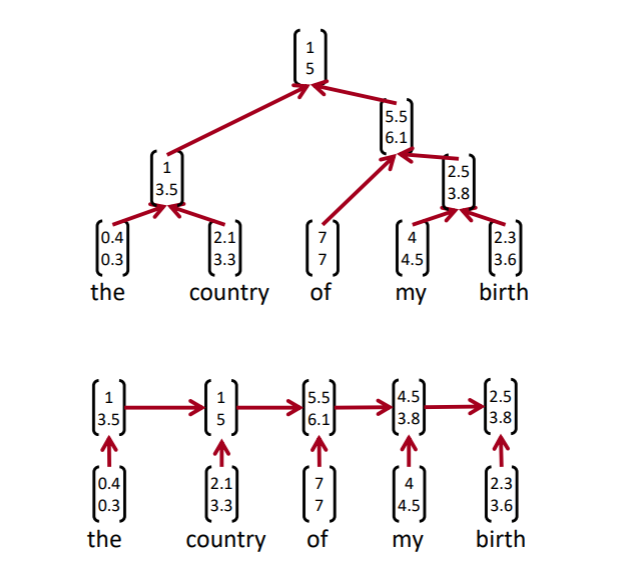
RNN과 재귀적 형태의 모델을 비교해보면, 다른 점이 분명하다. RNN은 방향성을 띄고 있기 때문에 각 hidden state들은 결국 이전의 모든 단어들의 정보를 일부 담고 있게 된다. 그래서 현재 hidden state이 과연 어느 단어들의 정보를 담고 있는지 확실하게 말할 수 없고, 특정 구의 hidden state을 얻을 수 없다. 하지만 재귀적 형태의 모델은 트리 구조를 가지고 있기 때문에, 분명하게 원하는 구나 절의 벡터를 얻을 수 있게 된다.
1.1. Model Structure
모델의 하나의 단계에서 수행하는 구조는 아래 그림과 같다.

두 단어를 입력값으로 하고, 점수와 벡터를 출력값으로 하는 NN이 모델이다. 이때 점수는 입력된 두 단어가 서로 구성성분으로 합칠 수 있는지에 대한 점수이고, 벡터는 두 단어를 합칠 경우 생성될 벡터이다. 그리고 이 과정을 bottom-up으로 반복해 나간다. 모든 단어 쌍에 대해 점수를 계산하고, 가장 점수가 높은 단어 쌍을 합하여 구나 절을 만들고, 다시 이를 반복하여 생성하게 된다.
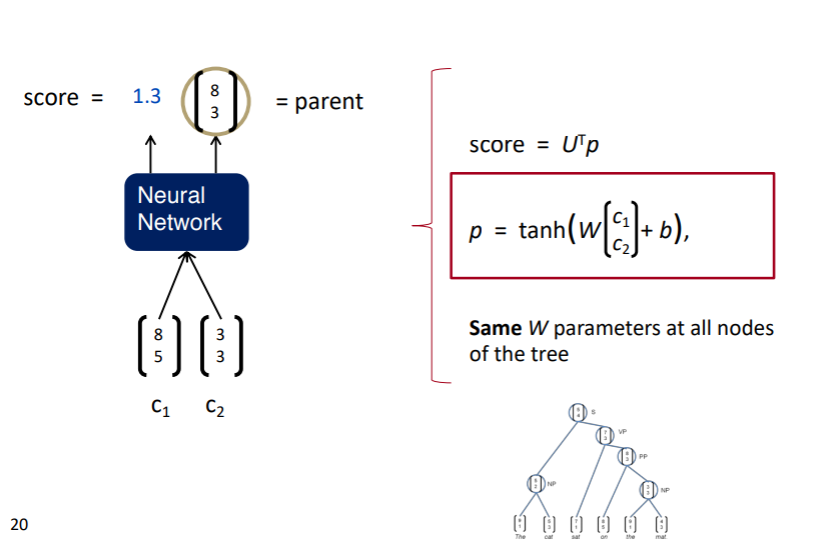
이러한 모델 구조는 약간의 문제점이 있는데, 기존의 트리 구조 탐색 알고리즘의 경우 정도의 시간복잡도를 가질 수 있었다. 구문 분석이 진행됨에 따라 조합 될 수 있는 구문의 경우의 수가 줄어들기 때문이다. 하지만 NN 기반의 이러한 모델은 실제로 가능한 구문 후보 중에 하나를 선택하는 것이 아니라, 단순히 한 쌍의 집합이 합쳐질 수 있는지를 계산하기 때문에, 재귀적으로 계산이 진행되어도 연산량이 줄어들지 않는다. 그래서 매닝 교수의 논문에선 빔서치를 사용했다고 한다.
1.2. Backpropagation in Tree
추후에 수정
2. Syntactically-Untied RNN
처음에 제안한 TreeRNN의 문제는 너무 모델이 단순했다는 점에 있었다. 두 단어의 관계를 파악하는데 하나의 weight matrix 혹은 hidden layer는 충분할 리가 없었다. 더군다나 두 단어의 관계를 파악할 때, FFNN 구조는 전혀 효과적이지 못하다. 단순히 두 단어 벡터를 concat하고 weight matrix를 곱하게 되면, 사실상 두 단어 벡터는 서로 주고 받는 요소가 없게 된다. 또한, 두 단어의 관계는 다른 단어를 통해서 파악될 때도 있다.
그래서 Syntactically-Untied RNN에서는 두가지 요소를 도입했다.
- 1) 구문분석은 Context-Free Grammer에 맡긴다. 즉, NN은 더이상 구문분석을 수행하지 않는다.
- 2) weight matrix는 문법 요소에 따라 다르게 구성한다. 즉, 형용사-명사, 동사-부사 결합 등 다양한 문법 요소 결합 시 각각 다른 weight matrix를 사용한다.
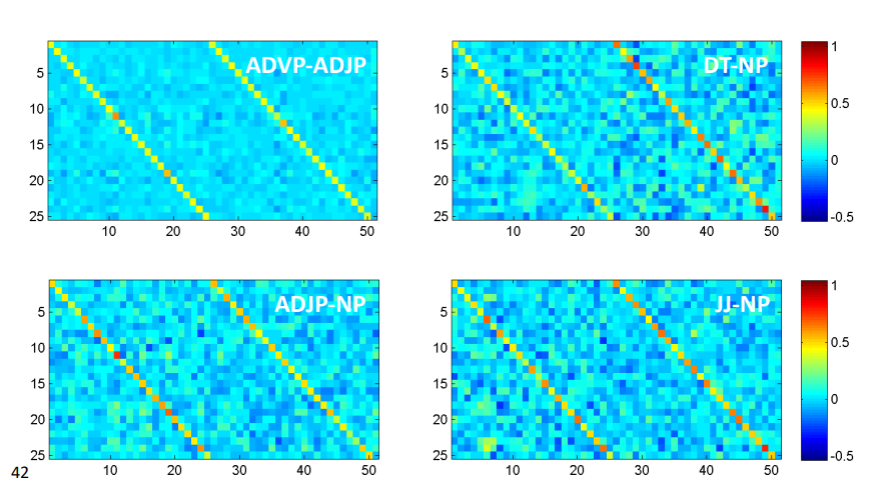
이렇게 학습한 weight matrix를 시각화 해보면 흥미로운 점을 볼 수 있다.

위의 그림은 명사구-접속사의 weight matrix이다. 두 단어의 concat matrix가 입력값이므로 초기값은 대각 성분을 1로 한 weight matrix를 옆으로 두개 붙여 사용했다고 한다. 이때, 명사구 쪽에 가중치가 더 크게 잡혀있는 것을 볼 수 있다. 오른쪽 그림은 인칭대명사-명사구인데, 이때도 역시 의미적으로 중심이 되는 명사구에 가중치들이 더 큰 것을 볼 수 있다.
실제로 모델이 잘 작동하는지 보기 위해 비슷한 문장을 뽑아보았다.

실제로 비슷한 문장들을 잘 뽑아내고 있는 모습이다.
3. Compositionality Through Recursive Matrix-Vector Spaces
하지만 이는 여전히 충분하지 않다. "very good"이라는 단어에서 very는 거의 의미가 없는 단어이다. 그 자체로 어떤 의미를 가지기 보다, very 뒤에 나오는 단어의 의미를 강화하게 된다. 이렇게 단어 그자체로는 의미가 없지만, 다른 단어에 어떤 작용을 하는 operator들은 두 단어 벡터를 concat해서 weight matrix를 곱해주는 현재의 모델에선 충분하게 사용되지 못한다. 이를 해결하기 위해선 이러한 operator들은 벡터로 여기기보다 그 자체로 weight로 여길 필요가 있었다. 하지만 어떤 단어들이 operator로 작동한다고 해야 할지 모호하다. 그래서 모델 구조가 아래와 같이 이루어지게 되었다.
3.1 Model Structure
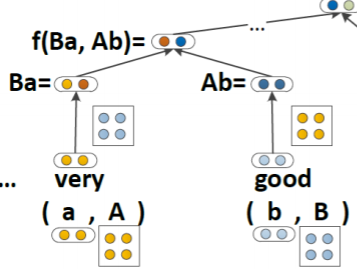
모든 단어는 vector meaning과 matrix meaning을 가지게 된다. 그리고 vector들은 다른 단어의 matrix와 곱해져서 NN의 입력값으로 사용된다. 즉, 모든 단어를 의미 부분과 operator 부분으로 나눈 것이다. 이렇게 만들어진 vector는 기존의 모델들과 마찬가지로 concat되어 부모 노드의 벡터를 만들게 되고, matrix들은 concat되어 이를 처리하는 matrix와 곱해져 부모 노드의 행렬을 만들게 된다.
하지만 문제점은 분명했다.
- 1) word vector와 곱하기 위해 만든 matrix는 너무 커서, 연산량을 위해 word vector의 크기를 줄일 수 밖에 없었다.
- 2) 부모 노드의 matrix를 얻는 방법이 너무 단순하다. 이게 어떤 방식인지 도통 내 입장에선 이해가 되지 않을 정도로 나이브해 보였다.
3-1. Sentiment Analysis
감성 분석은 문장의 긍부정과 같은 극성을 판별하는 태스크이다. 일반적인 모델은 전체 문장의 극성만 판단하게 되는데, 트리 구조를 활용하게 되면, 더 다양한 분석이 가능해진다.

위 사진은 각 문장의 긍부정을 트리구조의 모델을 이용해서 판별한 구조이다. 이때 트리구조를 사용했기 때문에, 전체 문장 뿐 아니라 각 구나 절의 긍부정도 살펴볼 수 있는 것이 특징이다. 특히, 대부분의 단어들이 긍부정과 관련이 없기 때문에, 중립으로 판별되어 대부분의 노드가 흰색으로 되어 있는 모습을 볼 수 있다. 그렇다면 이렇게 구문분석의 결과를 감성분석에 활용한다면, 더 풍부한 정보를 모델이 볼 수 있기 때문에, 성능이 좋아지지 않을까?
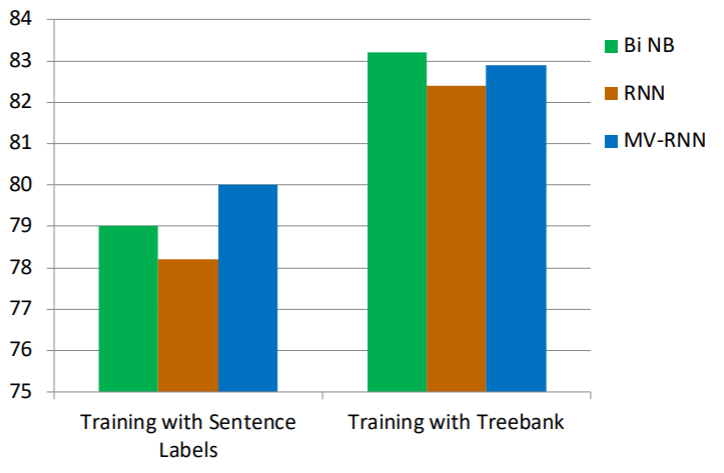
실제로 그랬다. 단순히 문장 레이블을 활용한 것보다 Treebank를 이용해 구문분석의 결과를 이용해 감성분석을 하자 성능이 4%p 이상 상승한 모습을 보인다.
4. Recursive Neural Tensor Network
위 모델을 개선하려면 어떤 방식이 가능할까? 행렬을 지워버리면 될 것이다. 이를 위해 이번 모델은 두 단어가 서로 영향을 끼치면서, 벡터만 사용하도록 구조를 변경했다.
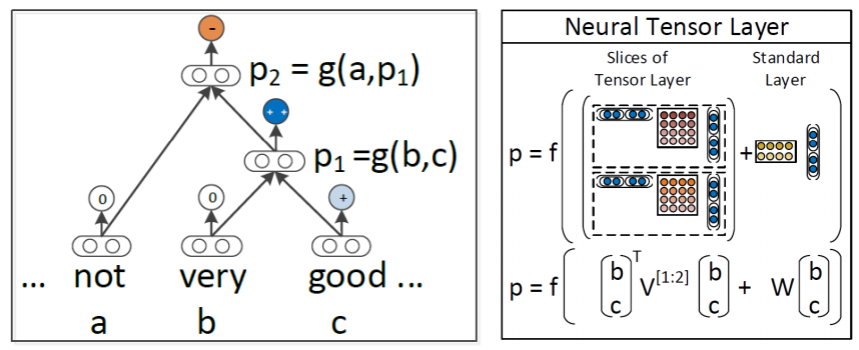
이때 두 벡터의 중간에서 연산되는 weight는 2d의 행렬이 아니라 다른 2d 행렬 두개를 사용해 만들고 이를 concat하여 일종의 attention처럼 작용되었다.
이렇게 모델을 구성하자, 감성분석에서 처음으로 반어법을 사용한 표현을 제대로 이해하기 시작했다. 이전의 모델들은 단어의 감성을 그대로 가져오는 경향이 있어서 It's definitely not dull과 같은 문장을 제대로 판별하지 못했지만, 이 모델은 제대로 판별했다.

그 결과 위와 같이 압도적인 성능을 보이게 되었다.
5. Conclusion
하지만 나는 솔직히 이 수업 전까지 트리 구조를 활용한 모델에 대해 거의 들어보지 못했다. 그 이유는 다음과 같다고 한다.
- 단순히 모델의 벡터 차원을 키우기만 해도 위에서 언급한 태스크들을 잘 수행한다고 한다. 굳이 복잡하게 dynamic programming을 사용할 이유가 사라진 것이다.
- CNN, RNN과 다르게 트리 구조를 가지게 되면, 연산과정에서 행렬 모양이 달라지거나, 계산해야 할 것들이 계속 변화하게 된다. dynamic programming이니 당연히 그럴 수 밖에 없다. 하지만 이렇게 되면 GPU를 사용한 연산에서 불리해진다고 한다.
하지만 이런 트리 구조 모델링은 다른 분야에서 활발히 사용되고 있다고 한다. 물리학 분야에서 활용되고 있거나 기계어 번역에서 활용된다고 예시를 보여주셨다. 특히 기계어는 자연어에 비해 구문 구조가 매우 분명하기 때문에 잘 활용될 수 있다고 한다.
