0. Intro
최근 몇년간 NLP를 휩쓴 모델 두 가지만 이야기해보라고 하면 단연 GPT 시리즈와 BERT를 꼽을 것이다. BERT는 특유의 NLU 친화적인 모델구조로 인해 다양한 태스크에 쉽게 적용될 수 있어 무척 많은 연구들이 쏟아져 나왔다. 이에 비해 GPT의 경우 OpenAI라는 기업이 가진 자본력 덕분에 모델 자체의 표현력이 높아 그대로 상업적으로 활용되는 경우들이 생겼다. 이는 재작년에 발표된 GPT-3가 정말 말도 안되는 zero-shot 능력을 보여주면서 정점에 달했다고 생각한다.
이번에 다룰 GPT-1은 개인적으로 Transformer를 이요한 Pretrain의 문을 연 기념비적인 논문이라고 생각한다. 그 이전에도 ELMo나 그 외의 다양한 (그 당시) 대량의 코퍼스로 학습한 (그 당시) 대형 사전학습 모델들이 있었지만, 제대로 Pretrained Big Model의 시대를 알린 것은 GPT-1이라 생각하기 때문이다. 왜 GPT-1이 그러한 시작을 알릴 수 있었는지 하나씩 살펴보도록 하자.
1. Related Work
우선 논문이 발표되던 2018년으로 돌아가보자. 2017년 Attention Is All You Need 논문이 발표된 이후 다양한 태스크에서 Transformer를 활용하려는 노력이 있었고, 실제로 Transformer 구조가 단순히 기계 번역 뿐 아니라 무척 다양한 NLP 태스크에 효과적이라는 것이 밝혀졌었다.
또한, 데이터셋 부족을 극복하기 위해 다양한 비지도, 준지도 학습 방법론들이 나오고 있었다. 우리가 흔히 아는 Word2Vec 역시 비지도 학습의 일종으로 사전에 학습한 word embedding을 모델의 초기값으로 활용하는 사전학습 방법론이라 볼 수 있다. 또한, ELMo를 비롯한 다양한 논문들에서 LM을 기반으로 한 사전학습을 거친 모델이 다양한 태스크에서 좋은 성능을 보인다고 알려져있었다.
즉, 사전학습이 효과적이며, 이때 LM을 사용하는 관점은 당시에도 존재했다.
2. Framework
하지만 이를 Transformer 구조를 이용해서 실험한 논문이 없었던 것 같다. 이에 Transformer 구조를 활용하여 LM을 사전학습 태스크로 하는 모델을 구성한 것이 GPT-1이라 할 수 있다. 이때, LM은 별도의 input text가 존재하지 않기 때문에 Transformer에서 Encoder가 필요없어지고, 그래서 GPT는 Transformer Decoder로만 구성되어 있다. 논문에는 별도로 식이 적혀 있지만, 기존의 Transformer Decoder 구조와 정확히 동일하기 때문에 굳이 적지는 않겠다.
2-1. 2-Stage Training Procedure
GPT-1은 pretain-finetune 의 과정을 2 stage training procedure라 설명하고 있다. 그 과정은 다음과 같다.
- Pretrain
Transformer Decoder를 이용해 대량의 레이블이 없는 코퍼스를 이용해 LM으로 사전학습 시킨다. - Finetune
pretrain된 모델을 각 태스크에 맞게 input과 label로 구성된 코퍼스에 대해 지도학습을 진행한다. 이때 아래와 같이 GPT-1의 output()을 다운스트림 태스크에 적절하도록 선형변환 후 소프트맥스에 태운다. 그리고 이를 태스크에 맞는 loss()와 auxiliary objective인 LM loss()를 결합하여 구성한다.
2-2. Task Specific Input Trasnformation
이때 Pretrain은 LM으로 진행되었기 때문에, 각 Downstream task와 input의 모양이 다를 수밖에 없다는 문제점이 있다. 예를 들어 LM은 연속된 문장들을 그냥 GPT-1에 태우면 되지만, 두 문장 간 유사도를 측정해야하는 태스크의 경우 두 문장을 어떻게 GPT-1에 실어야 하는지에 대한 고민이 발생하게 된다. GPT-1은 각 태스크의 input을 GPT-1에 실을 수 있도록 Input을 다음과 같이 변형했다고 한다.
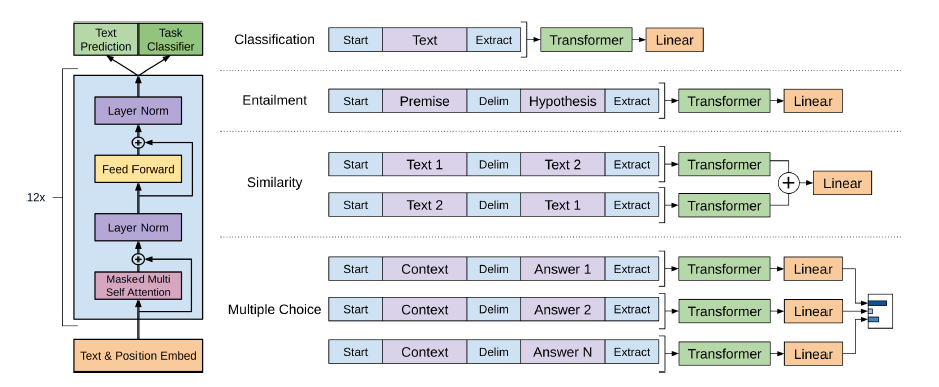
- Classification : 분류하고자 하는 문장을 GPT-1에 그냥 통과시킨다. 그리고 얻은 마지막 토큰(<\s> 토큰이 생성될 위치)의 output을 classification layer에 실었다고 한다.
- Entailment : <s>Premise$Hypothesis<\s>의 형태로 입력하고, 마지막 토큰의 output을 linear layer에 실었다.
- Similarity : Entailment와 다르게 비교하고자 하는 두 문장이 어떤 순서로 입력되어야 하는지에 대한 규칙이 존재하지 않는다. 그러므로 각 문장의 순서를 바꿔서 두 번 실고, 두 개의 마지막 토큰 output을 element-wise sum하여 linear layer에 실었다.
- Multiple Choice : Context를 먼저 넣고 각 후보 Answer를 뒤에 넣어 얻은 마지막 토큰의 output을 linear와 softmax layer에 순차적으로 실었다.
이때, 마지막 토큰의 output을 사용해서 classification을 수행하는 이유가 있다. GPT-1은 Transformer의 Decoder만 사용하기 때문에 앞에서 뒤로만 정보가 흐르게 된다. 즉, 문장의 모든 토큰의 정보를 처리할 수 있는 토큰은 문장의 제일 마지막 토큰이 유일한 것이다. 그러므로 이 토큰의 정보를 이용해서 classification을 진행하게 된다.
이와 같은 구조를 통해 얻을 수 있는 장점은 다음과 같다.
- 모델 구조의 변형이 없다.
논문에 의하면 이전의 사전학습 모델들은 finetune 시 모델 구조를 변형해야 하는 문제점이 있었다고 한다. 하지만, GPT-1은 GPT-1의 모델 구조를 전혀 건들이지 않아 finetuning이 매우 용이하다. - 추가되는 파라미터의 수가 매우 적다.
위와 연결되는 이야기인데, 모델 구조를 변형하지 않고, input의 형태를 변형하고, linear layer를 마지막에 추가하는 아주 간단한 추가작업 수행되기 때문에 finetuning 시점에서 random하게 초기화된 initial weight이 매우 적다.
3. Experiment
3-1. Setup
GPT-1은 BooksCorpus dataset으로 pretrain이 되었다. 이는 ELMo와 유사한 데이터셋을 이용한 것인데, 다른 점이라고 한다면, ELMo는 문장을 모두 섞어서 input의 긴 길이에서 오는 long term depency를 학습하기 어렵지만, GPT-1은 7000여 건의 다양한 책의 문장들을 이어서 사용하기 때문에 long term dependency를 학습할 수 있다는데 있다고 한다.
기본적인 구조는 vanilla Transformer와 동일하다. model dim이나 ffnn dim을 조금 늘린 차이 밖에 없다. 모델 학습 시 l2 regularization을 사용하고, gelu로 활성화함수를 변경했다. 또한, Transformer는 sinusoidal positional encoding을 사용한 것에 비해 GPT-1은 learnable positional encoding을 사용했다. 그외에 finetuning 시 대부분의 코퍼스에서 3 에포크만으로 충분히 학습될만큼 빠르게 학습이 종료되었다고 한다.
3-2. Experiment Result
실험 결과는 다음과 같다.
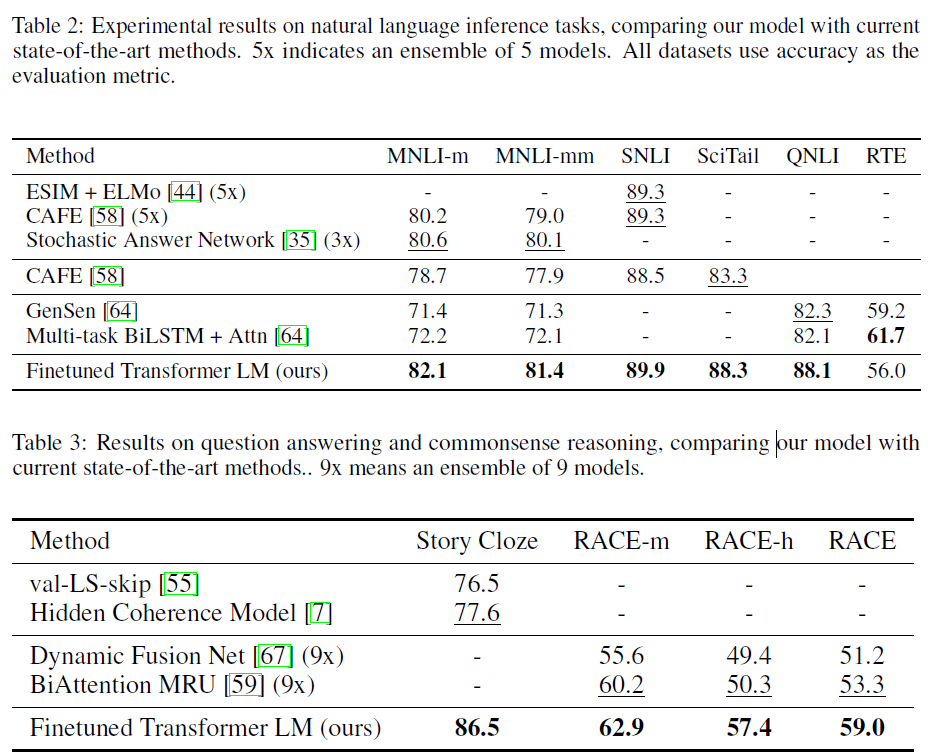
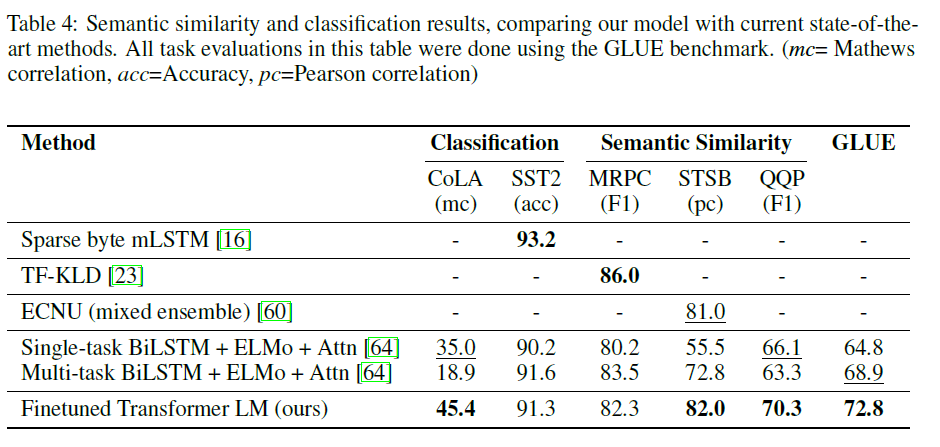
GPT-1은 총 12개의 코퍼스 중 9개에서 SOTA를 달성하는 놀라운 성능을 보였다고 한다. 특히 각 코퍼스마다 태스크에 맞게 설계된 모델들이 존재함에도 이를 뛰어넘거나 비등한 성능을 보이는 것은 괄목할만한 성능이라 생각한다.
구체적으로 논문에서는 그 이유에 대해 사전학습을 통해 다음과 같은 요소를 학습했다고 서술하고 있다.
- 사전학습을 통해 문장의 모호성을 다루고 다수의 문장에서 정보를 추출하는 기능
- 길이가 긴 문서를 효과적으로 다루는 기능
- 여러 개념을 재구조(rephrase)하고, 부정문이나 문법적 모호성을 다루는 기능
- 언어에 내재되어 있는 편향을 학습
사실 이 부분에 대해선 각 태스크에 대한 성능을 평가하면서 모델이 이와 같은 요소를 학습했다고 서술하고 있기 때문에 설득력은 떨어진다고 본다. 다만 이후 다수의 논문에서 실제로 GPT-1이나 BERT가 언어의 편향이나 문법적, 의미적 구조를 학습했다고 분석하기 때문에 틀린 말은 아닐 것이다.
4. Experiment
위에서 본 것처럼 GPT-1은 실제로 여러 다운스트림 태스크에서 3 에포크 내외의 비교적 적은 학습에도 불구하고 훌륭한 성능을 보여주고 있다. 실제로 이러한 성능 향상이 사전학습에서 오는 이점인지 살펴보도록 하자.
4-1. Impact of Number of Layers Transferred
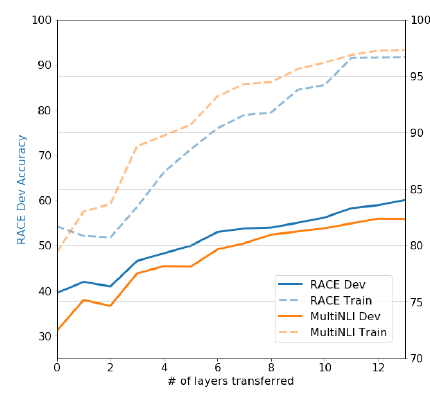
위 그림은 pretrained GPT-1의 레이어 사용 정도에 따른 다운스트림 태스크 성능이다. 왼쪽으로 갈 수록 input에 가까운 적은 레이어만 사용한 경우이고, 오른쪽으로 갈 수록 output에 가까운 레이어까지 사용한 경우이다. 한눈에 봐도 알 수 있듯이, pretrained layer를 많이 쓸수록 다운스트림 태스크에서도 성능이 올라가는 모습을 보이고 있다. 즉, pretrained model의 레이어는 다운스트림 태스크를 해결하는데 유용한 함수로서의 기능을 충분히 해내고 있는 모습이다.
4-2. Zero-shot Behavior
GPT-2와 GPT-3에서는 주로 few-shot부터 zero-shot까지 모델이 pretrained된 상태에서 다운스트림 태스크를 수행할 수 있는 방법론을 많이 다룬다. 이는 GPT-1에서도 여전히 나타나고 있다.
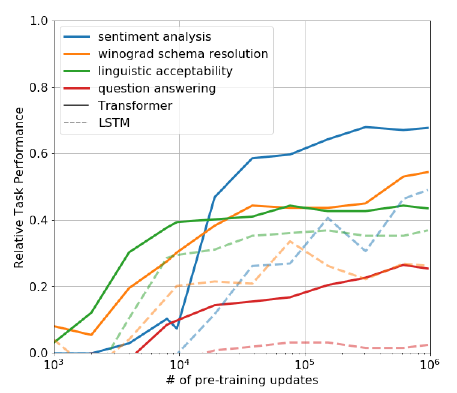
위 그림은 GPT-1을 pretrain 시킨 정도에 따라 finetuning 하지 않고도 어느정도의 다운스트림 태스크에 대한 성능을 보이는지 보여주고 있다. 즉, pretrain 과정이 실제 다운스트림 태스크에 직접적인 도움이 되는지 보여주는 것이다.
그림을 살펴보면 LSTM을 사용해서 pretrain 시킨 것보다 Transformer Decoder를 사용한 GPT-1이, pretrain을 시키면 시킬수록 다양한 태스크에서 점차 성능이 나아지는 모습을 볼 수 있다. 이를 정리하면 다음 두가지 결론이 도출된다.
- Transformer의 attention 구조가 LSTM에 비해 transfer에 탁월하다.
- LM이라는 pretrain이 실제 여러 downstream task를 해결하는데 도움이 된다.
이에 대해 GPT-2, 3에선 프롬프트라는 개념을 통해 자세히 이야기하고 있는데. GPT-1에선 단순히 input의 형태를 일부 변형하여 zero-shot, 즉 finetuning을 가하지 않고 해결하는 모습을 보여주고 있다. 이는 모델 뒤에 linear or softmax layer를 붙이는 등의 행위 없이 온전히 LM으로 sentiment analysis, QA 등의 문제를 해결했다는 의미이다. 각 태스크마다 어떤 식으로 input을 변형하고 예측값을 뽑았는지는 다음과 같다.
- Linguistic Acceptability : 출력 토큰의 average token log-probability를 이용하여 thresholding으로 예측
- Sentiment analysis : 문장의 마지막에 "very"라는 단어를 추가하고 마지막 예측 값을 positive와 negative라는 단어로 제한했을 때의 확률로 감성 예측
- Question Answering : Context와 Question을 입력으로 하여 생성되는 문장들 중에 가장 average log-probability가 높은 문장으로 예측
5. Conclusion
개인적으로 GPT-1은 ELMo와 BERT의 사이에 있는 논문이 아닐까 한다. ELMo가 pretrain을 통한 LM의 개념을 제시했다면, GPT-1는 LM을 Transformer 구조에 적용하여 Transformer가 Pretrain에 매우 적합한 모델임을 밝히고 이를 finetuning하는 프레임워크를 완성했다고 본다. BERT는 여기서 더 나아가서 NLU에 있어 LM은 불필요한 inductive bias(단방향 모델링)을 가지고 있다는 점을 개선하여 양방향 모델링이 가능하도록 MLM을 제시한 것 같다.
GPT-1의 대략적인 구조나 논리는 논문을 읽기 전에도 여러 자료를 통해 알고 있었지만, zero-shot setup에 대해 GPT-2 이전에도 제시했던 것은 처음 접했다. OpenAI는 GPT-1, 2, 3 등으로 이어지는 흐름을 통해 아마 보다 일반화된 pretrained language model을 제시하려고 하는 것 같은데, 그 시작점으로 이 논문이 제시된 것 같다는 느낌을 받았다.
