
오늘 살펴볼 논문은 How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings 라는 논문이다. 이름이 무척 긴데, 사실 이름 안에 모든 내용이 담겨 있다.
0. Intro
BERT, ELMo, GPT와 같이 pretrained LM들의 output은 input으로 사용된 각 토큰의 contextualized embedding이라고 많이들 간주한다. word2vec이나 glove와 같은 기존의 임베딩 기법들이 static word embedding이라 한다. 이는 word2vec이나 glove가 각 단어를 하나의 임베딩 벡터로 맵핑하는데 기인한다. 다시말해 단어가 등장한 주변 환경(맥락)과 관계없이 "정적(static)"으로 임베딩 벡터를 생성한다는 의미이다.
이와 대조적으로 BERT, ELMo, GPT 등은 학습 과정이 (Masked) LM이기 때문에 모델이 자연어의 문법/의미적 구조를 처리할 수 있다고 간주한다(이에 대해선 바로 다음 논문에서 다뤄볼 예정이다.). 그리고 그결과 출력되는 각 output vector는 입력 토큰이 사용된 맥락이 반영된 말 그대로 contextualized embedding이다.
직관적으로 이는 맞는 말인 것 같다. 하지만 언제까지고 직관에만 의존할 수 없고, 우리는 가능한 수준에선 엄밀하게 따질 필요가 있다고 생각했다. 그리고 LM이 임베딩을 처리하는 과정을 엄밀하게 검증하는 과정을 한번 보면서 어떻게 하면 추상적 개념을 검증할 수 있는지 볼 수 있을 것 같아서 이 논문을 리뷰하게 되었다.
사설이 길었는데, 요약하면 이 논문은 2019년 기준으로 많이 언급되는 pretrained LM인 BERT, ELMo, GPT가 어떻게 입력된 문장을 처리하여 contextualized embedding을 생성하고, 그 과정에서 생성된 결과물인 임베딩 벡터에 맥락이 반영된 수준을 살펴보았다. 그리고 이를 isotropic과 anisotropic이라는 생소한 개념을 이용해 설명하고 있다. 하나씩 이야기해보자.
1. Isotropic vs Anisotropic
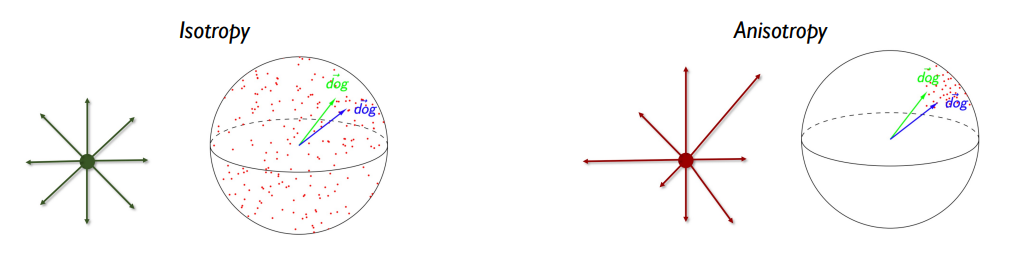
두 개념은 이 논문을 이해하는데 있어 중요하다. 하지만 정확히 알고 있진 않기 때문에 추상적으로나마 파악하고 넘어가도록 하자.
우선 Isotropic이란 벡터가 주어진 공간에서 모든 방향으로 존재하는 상황을 의미한다. 임베딩에 대입해보면 주어진 보캡의 임베딩 벡터들이 사방팔방으로 향해 있는 상황이다.
이와 반대로 Anisotropic은 벡터가 주어진 공간에서 특정 방향으로만 향해 있어서 일종의 cone 형태를 이루고 있는 것을 말한다. 임베딩에 대입하면 주어진 보캡의 임베딩 벡터들이 단어 간의 유사도와 관계없이 모두 비슷한 방향으로 향하고 있는 상황이다.
이상적인 상황이라면 임베딩 벡터는 Isotropic해야 한다. 그래야 각 단어의 의미가 명확히 구분되고, 유사한 단어는 서로 가깝게, 영 뚱딴지인 두 단어는 서로 멀리 분포하게 될 것이다. 만약 Anisotropic하게 임베딩 벡터가 분포해 있다면, 단어의 의미/문법적 유사도와 관계없이 모든 단어들이 가깝게 분포하기 때문에 각 단어의 의미가 명확히 구분되지 않을 우려가 있다. 물론 이러한 구분이 항상 옳은 것은 아니고(논문에서도 일부 이야기하는 바이다.) 다른 논문에선 anisotropic한 상태가 나쁜 것이 아니라고 이야기한다고도 하니 "아 이런 개념이구나~"하고 넘어가자.
2. Approach
2-1. Probing Tasks
이 논문에서 알아보고자 하는 것은 다음과 같다.
"pretrained LM에서 각 레이어의 output들이 얼마나 contextualized되어 있고, 그래서 그것이 무엇을 의미하는가?"
보통 이렇게 pretrained LM에 대해 분석하는 논문에서는 특정 태스크에 각 레이어의 output을 활용함으로써 분석하는 방법을 취한다. 하지만 이런 방법론으론 각 레이어의 output이 어떤 정보까지 활용해서 contextualizing 했는지는 파악할 수 있어도(static -> syntactic -> semantic) "얼마나" contextualized되었는지는 분석할 수 없다고 지적하고 있다. 즉, 각 단어가 문장에 따라 임베딩 벡터가 달라지는 정도를 파악하는데 특정 태스크를 사용하는 것은 옳바른 방법이 아니라고 이야기한다. 그래서 이 논문에선 특정 태스크(probing task)를 활용하지 않고 별도의 measure를 제안하고 있다.
2-2. Data
태스크에 해단 성능을 측정하는 기존 방법론은 그저 x -> y 로 이어지는 forward만 수행하면 되었다. 하지만 이 논문에선 다음과 같은 개념을 활용해서 contextuality를 측정한다.
하나의 단어가 다른 문장에서 다르게 임베딩되는 정도
이를 위해선 데이터셋을 조금 가공해야 한다.
- 기본적으로 SemEval이라고 하는 의미론적 유사도 측정 태스크에 활용되는 데이터셋을 활용한다.
- 각 단어가 출현한 문서를 정리한다.
이를 이용해서 하나의 단어가 다른 문장에서 문맥을 반영하여 임베딩되어 나타나는 차이를 살펴볼 수 있다. 이를 염두에 두고 이어가도록 하자.
2-3. Measures of Contextuality
그래서 이 논문에선 다음 3가지 지표를 통해 contextuality를 설명하고 있다.
- self similarity : 각기 다른 문장에서 사용되는 동일 단어의 유사도
- intra-sentence similarity : 한 문장 내 단어들의 유사도
- maximum explainable variance : static embedding으로 표현가능한 정도
각각에 대해 하나씩 살펴보자.
Self Similarity
- n : 단어 w가 등장한 문장의 수
- f : 우리가 실험에 사용하는 모델(ELMo, BERT, GPT)
- l : 모델의 해당 레이어
- : j번째 문장
- : j문장에서 단어 w가 등장한 위치
- : 문장 s에서 등장한 단어 w의 f 모델을 사용했을 때 l번째 layer의 output
위 식을 풀어서 이야기해보자.
BERT의 3번째 레이어의 임베딩을 기준으로 하면,
단어 w가 등장한 모든 문장들에서 단어 w의 BERT의 3번째 레이어 임베딩에 대한 각각의 유사도의 평균이라 할 수 있다.
만약 단어 w가 전혀 contextualize되지 않았다면 모든 문장에서 동일한 임베딩 벡터가 될 것이기 때문에 SelfSim = 1이 될 것이다.
Intra-Sentence Similarity
- : 모델 f의 레이어 l에서 문장 s의 모든 토큰에 대한 임베딩 벡터 평균
위 식을 풀어서 이야기하면
IntraSim은 해당 모델 레이어에서 문장 l의 각 단어들의 임베딩 벡터가 문장 벡터와 가지는 거리의 평균이다. 이는 한 문장이 모델을 통과하면서 얼마나 contextualize되고, 해당 레이어에서 context가 각 단어에 얼마나 임베딩 벡터에 영향을 끼치는지 볼 수 있다.
만약 IntraSim과 SelfSim이 모두 낮다면 해당 모델의 해당 레이어는 각 단어에게 context를 반영하여 임베딩하고 있지만, 각기 다른 context를 부여하고 있음을 알 수 있다. context를 부여했기때문에 SelfSim이 낮아진 것이고, 각 단어에 다른 context를 부여했기 때문에 IntraSim이 낮아진 것이다.
반대로 IntraSim은 높은데 SelfSim이 낮은 상황에선 하나의 context로 모든 단어가 통일되고 있는 것을 의미한다. 논문에선 "less nuanced contextualization"이라 표현하는데, 이를 좀 더 풀어서 설명해보자(주의 뇌피셜임).
contextualized라는 것은 결국 문장을 다음 두 요소의 합으로 처리하는 것이다.
Contextualization = 단어의 본래의 의미 + 문장 전체의 의미
이 상황에서 각 단어가 가지는 고유한 의미를 어느정도 살리되(뉘앙스) 문장 전체가 가지는 의미를 각 단어에 담아야 contextualized embedding이 될 수 있을 것이다. 그런데 IntraSim이 높으면 각 단어가 본래의 정보를 잃어버리고 문장 전체의 정보만 담게 되는 것이라 볼 수 있을 것이다.
Maximum Explainable Variance
단어 w가 문장들 에서 인덱스 에서 각각 등장한다고 할 때, 를 를 모델 f의 l번째 레이어에서 임베딩된 열벡터라고 하자. 이때 다음과 같은 행렬을 만들 수 있다.
즉, 행렬 O는 모델 f의 레이어 l에서 단어 w가 i번째 문장에서 등장하는 임베딩 벡터를 열로 가지는 행렬이다. 논문에서는 occurrence matrix라 표현한다. 그리고 이 행렬의 상위 m개의 특이값을 가지고 오면 우리가 원하는 지표를 다음과 같이 만들 수 있다.
이 부분에 대해서는 조금 이야기를 해보면 좋을 것 같은데, 내 이해는 다음과 같다.
행렬의 singular value라는 것은 해당 행렬의 열공간에서 기저를 이루는 축들의 크기이다. 이중 가장 큰 singluar value()는 가장 큰 분산을 가지는 축이다. 그러면 만약 MEV가 1에 가깝다면, 해당 단어 w는 모델 f의 레이어 l에서 거의 하나의 축으로 다른 문장에서 사용된 임베딩 벡터를 설명할 수 있다는 의미가 된다.
서로 다른 임베딩 벡터가 하나의 축으로 설명된다면 이는 static embedding으로 추정하여 대체할 수 있을 것이다. 즉, MEV는 static embedding을 통해 대체 가능한 해당 contextual embedding의 정보량에 대한 upper bound가 된다.
(설명이 완전한 것 같지 않다...)
Adjusting for Anisotropy
contextuality를 임베딩 벡터의 변화로 간주할 때 anisotropy는 꼭 고려해야 한다. 만약에 어떤 문장의 contextual embedding이 완전히 isotropic하다면, SelfSim = 0.95로 각 단어는 거의 context가 반영되지 않은 상태일 것이다.
반대로 엄청 anisotropic한 상황이라면 어떤 두 단어의 임베딩 간 유사도가 0.99이상 나올 수 있다. 이때, SelfSim = 0.99라면 오히려 context가 잘 반영된 상태라고 할 수 있다. 랜덤한 단어 간의 유사도보다 context가 같은 한 문장 내 단어 간 유사도가 높은 상황이기 때문이다.
이를 실험에도 반영하기 위해 위에서 제시한 각 지표마다 anisotropy를 배제하여 측정하였다. 각 방법은 다음과 같다.
- Self-Similarity, Intra-Senetence Similarity : base line으로 다른 문장에서 랜덤한 두 단어가 가지는 유사도를 삼음. anisotropy한 정도가 높을수록 baseline score 역시 올라가게 됨.
- MEV : 랜덤한 문장에서 뽑은 랜덤한 임베딩 벡터들로 만든 행렬에 대한 MEV 값이다. 이 역시 anisotropy할 수록 baseline score가 1에 가까워진다.
이때 1000개의 랜덤한 단어를 이용해 baseline 점수를 산출했다고 하며, 이를 이용해 anisotopy로 인해 발생한 점수의 왜곡을 보정하기 위해 본래 점수에서 baseline 점수를 뺏다고 한다.
3. Experiments
Random Words Similarity
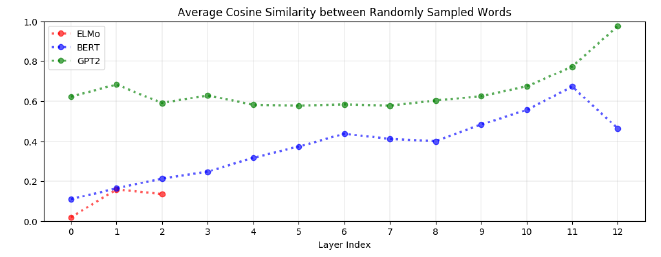
첫번째 실험은 위와 같다. 이는 각 레이어에서 생성되는 embedding vector에 대해 두 단어간의 유사도를 측정한 것이다. 만약 해당 레이어에서 생성되는 embedding space가 anisotropy하다면 랜덤한 두 단어 간의 유사도가 높게 나올 것이다. 그 결과는 위에 보이는 바와 같다.
- 모든 모델의 대부분의 레이어에서 anisotropy가 나타나고 있다.
- 예외는 ELMo의 embedding layer이다. 이는 ELMo의 embedding layer만 poistional encoding도 없고, context도 없다는 점에 기인하는 것으로 보인다.
- GPT-2의 경우 극심한 anisotropy를 보인다. 이는 GPT-2가 context에 무척 의존한다는 점을 보여준다.
- BERT의 경우 특이하게도 마지막 레이어에서 오히려 anisotropy가 감소하고 있다.
- 반대로 해석하면, Anisotropy는 Contextualization에서 이용되고 있거나, 부산물로 생성되었다.
Self Similarity
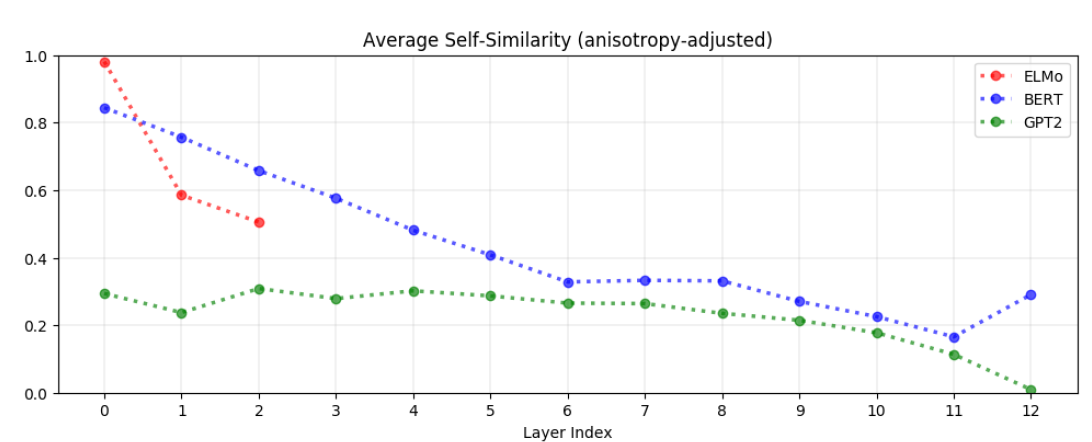
두번째 실험은 anisotropy를 보정한 SelfSim의 결과이다. 그 결과는 다음과 같다.
- GPT의 경우 모든 레이어에서 낮은 self similiarity를 보이고 있다.
- BERT의 경우 높은 self similiarity가 상위 레이어로 갈수록 낮아지고 있다.
- ELMo의 첫번째 레이어에서 self similarity = 1인 이유는 그 자체로 static embedding이기 때문이다.
여기서 알 수 있는 것은 높은 self similarity는 문맥에 관계없이 동일한 단어 벡터에 대해 비슷한 임베딩 벡터가 생성되었다는 의미이므로 세 모델 모두에서 상위 레이어로 갈수록 context가 반영되면서 단어 본래의 의미가 희석되고 있음을 볼 수 있다.
BERT의 경우 이전 실험에서와 비슷한 모습을 보여주어 마지막 레이어에선 오히려 self similarity가 높아지는 모습을 보이는데 그 이유가 무엇인지는 모르겠다.
장표에는 나타나지 않지만, the, of, to, a와 같은 stop words의 경우에는 거의 모든 레이어에서 가장 낮은 self similarity를 가진 단어였다고 한다. 이는 아무래도 stop word들이 자체가 가지고 있는 의미는 거의 없고 주변 단어와 주고 받으면서 의미가 생기기 때문으로 추측된다.
Intra-Sentence Similarity
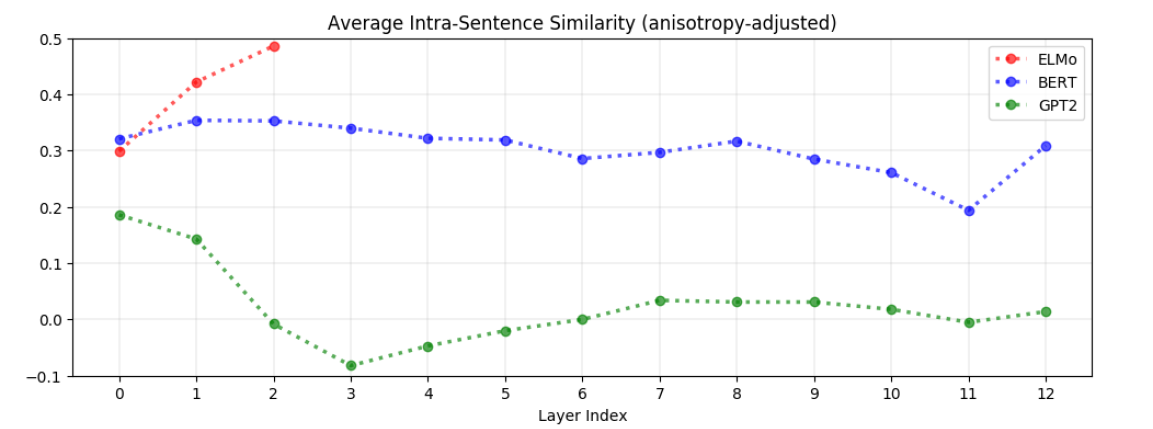
다음으로 Intra-sentence similarity를 살펴보자. 이는 약 500개의 랜덤 추출한 문장에 대한 Intra-sentence similarity를 평균낸것이다.
ELMo
- ELMo에선 상위 레이어로 갈수록 intra-sentence similarity가 높아지는 모습을 보인다. 이는 ELMo에선 상위 레이어에선 한 문장 내 다른 단어들의 임베딩 벡터가 유사해지는 것을 의미한다.
- 논문에선 이를 두고 분산표상이 문장 단위에서 나타났다고 볼 수 있다 했다.
BERT
- BERT에서는 상위 레이어로 갈수록 오히려 similarity가 떨어지는 모습을 보인다. 이는 상위 레이어로 갈수록 한 문장 내 단어들의 임베딩 벡터가 서로 멀어지는 것을 의미한다.
- 하지만 그렇다하더라도 랜덤한 두 문장의 각 단어들의 유사도보다는 한 문장내 단어들의 유사도가 높다.
- ELMo와 정반대의 현상이다. 이를 해석하자면 ELMo에 비해 BERT가 뉘앙스를 잘 살리고 있다고 볼 수 있다. 즉, 문장의 context를 가지면서도 각 단어의 의미가 살아있다고 볼 수 있다.
GPT-2
- GPT는 BERT와 비슷한 모양새이나, 그 정도가 훨씬 심하다. input layer를 제외한 모든 레이어에서 similarity가 0.2 미만이다.
- BERT와 달리 GPT는 intra-sentence similarity가 낮음에도 불구하고, 성능은 여전히 우수한 모습을 보이고 있다. 즉, intra-sentence similarity가 context에 필수적인 요소는 아닐 수 있다.
- 뇌피셜 anisotropic한 모습을 보임에도 불구하고, 그것을 걷어내면 이렇게 GPT-2에서 임베딩이 구분되는 상황이라면, anisotropy가 큰 문제는 아니지 않을까?
Static vs Contextualized
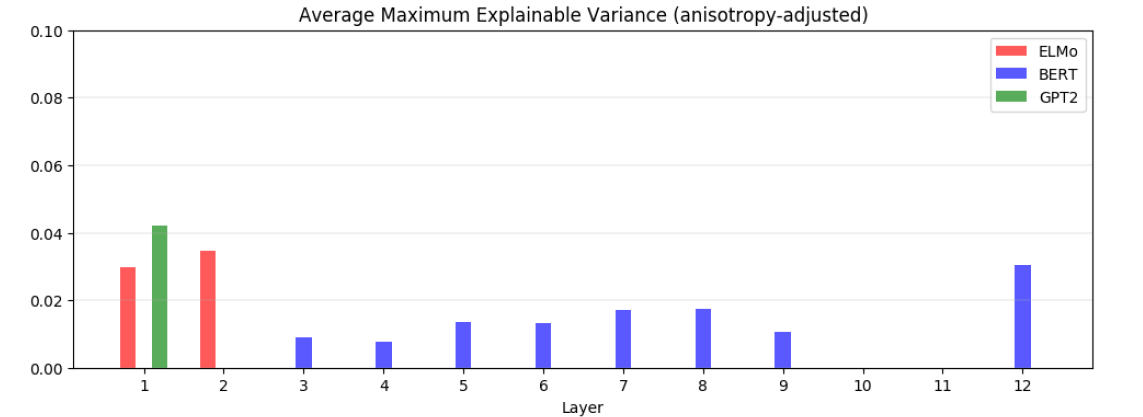
MEV를 통해 contextualized된 임베딩 벡터가 얼마나 static으로 표현가능한지 살펴보자. 우선 전반적으로 5% 미만의 분산만 설명 가능했다.
우선 모든 contextualized embedding은 anisotropy하므로, 이를 제외해야 하는데, 이때 anisotropy하게 만드는 해당 축의 정보를 제외하면 되기 때문에 위에서 가장 큰 singular value값을 제외하고 위 장표가 만들어졌다.
- 이러한 모습은 결국 contextualizing 과정에서 모델이 각 단어를 유한개의 의미 중에 배정하는 것이 아니라 정말 수많은 의미를 섞고 있음을 나타낸다. 예를 들어 apple에 (사과, 스마트폰 제조사)와 같은 두가지 의미 중에 하나만 배정하고 있었다면, static embedding으로 많은 부분이 설명이 될 수 있을 것이기 때문이다.
실제로 각 레이어에서 생성된 contextualized embedding의 첫번째 singular value에 대응하는 벡터를 static embedding으로 간주했을 때 여러 벤치마크에서 glove나 fasttext를 능가하는 모습을 보이고 있다.
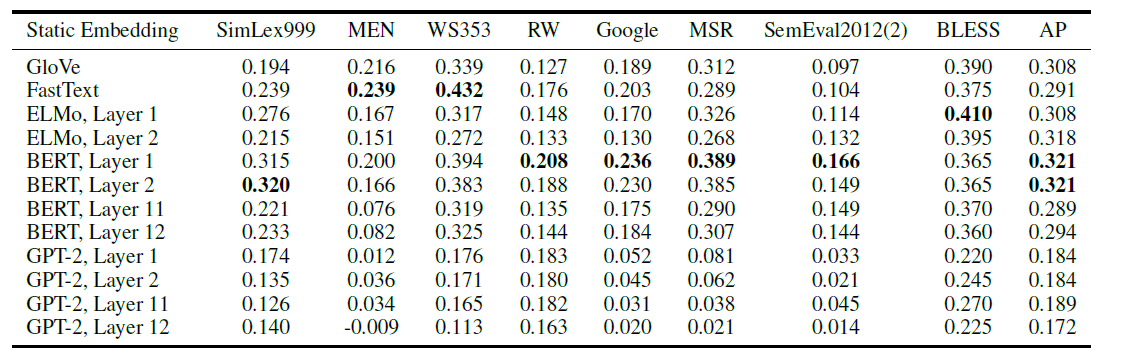
그 결과를 살펴보면 지금까지 이야기했던 것과 일맥상통한데, 낮은 레이어일수록 성능이 좋고, BERT가 가장 성능이 좋았다. 이는 GPT의 경우 너무 context에 의존하고 있기 때문에 각 단어의 의미는 오히려 보존하지 못했기 때문일 수 있다.
4. Other Experiment
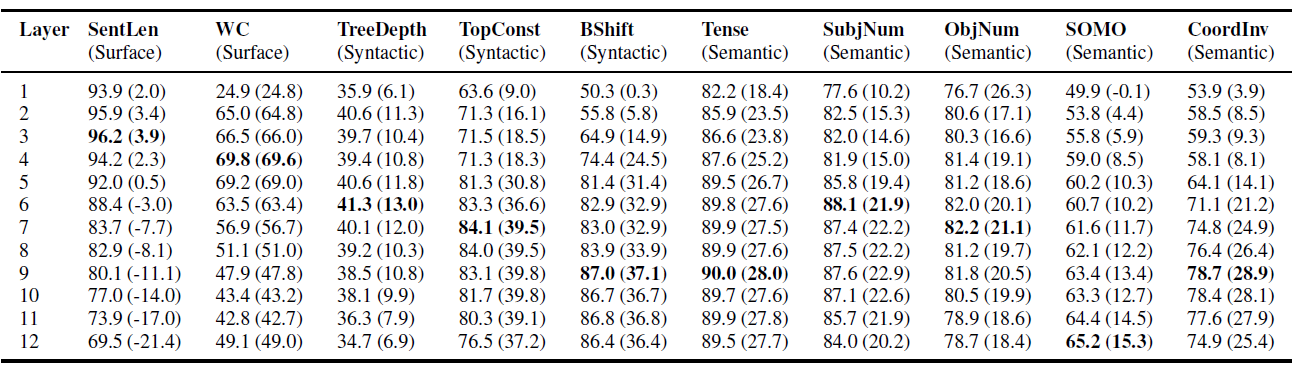
위 장표는 What does BERT learn about the structure of language의 실험 결과이다. BERT의 각 레이어 embedding을 이용해서 각 태스크를 수행했을 때 결과표이다.
각 태스크가 문장의 길이, 문법 정보, 의미 정보를 필요로 하기 때문에, 문장에서 추출해야 하는 정보가 다른데, 놀랍게도 BERT의 각 레이어가 다른 성능을 보이고 있다. 크게 보면 레이어가 깊어질수록 표면정보 -> 문법 정보 -> 의미 정보의 순으로 처리하고 있는 것으로 보인다.
그 이유는 레이어가 깊어지면서 좋은 성능을 보이는 태스크가 다르기 때문이다. 심지어 매우 표면적인 정보만 필요로 하는 태스크의 경우 깊은 레이어는 오히려 랜덤한 벡터를 임베딩 벡터로 사용한 것보다 성능이 좋지 못한 모습을 보이고 있다.
참고자료
DSBA 이유경 석박통합과정의 SimCSE 자료
What does BERT learn about the structure of language?
How Contextual are ContextualizedWord Representations?
Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings

글 너무 잘 읽었습니다! 논문을 읽다 Isotropic와 Anisotropic의 개념을 잘 몰라 헤매고 있었는데 정리를 잘 해주셔서 이해가 잘 됐습니다. 감사합니다 :)