Intro
DL쪽을 처음 접하고 paper 작업에 투입되었을때 초창기때는 어떻게든 shape을 맞춰서 해당 모델을 돌리는것 에만 초점을 맞췄었다. 사실 어떻게 내부 값들이 변하는지는 크게 신경을 안쓰고, 단순하게 에러만 안나면서 GPU에서 돌아가게만 만드는데 초점을 맞췄었다.
하지만, 요즘은 GPU를 똑똑하게 부려먹는것 의 중요성을 느낄일이 많아졌다. 아무래도 최신논문에서 나오는 논문들이 모바일 On-Device에 활용할 수 있는 Light-Weighted 모델들 연구가 활발하게 이뤄지고 있다지만, SOTA 논문들은 역시 어느정도 무게감이 있는 모델들로 훈련을 시키는게 최고라는 생각이 들다보니, 해당 방식에 신경쓰게 됐다.
(무거운 모델들은 1epoch 당 2시간씩 걸리게 되고, 아무래도 이걸 고려하지 않고 훈련을 시키면 2-3배정도까지 시간이 소요된다)
그래서, 각각 주차별로 있었던 Issue 들을 고치는 Process들을 한번 매주 정리해보고자 한다.
물론, 단순한 shape Issue들은 내가 멍청한 것이므로 안적는다...
GPU Util
1. Nvidia-smi
GPU 활용상태를 알 수 있는 근본 명령어 nvidia-smi 이다. GPU 관련 드라이버들을 깔다보면 맞이하게 되는 NVIDIA 회사이다. 관련된 패키지들을 설치하고 나면 아래 명령어를 통해서 GPU 상태를 모니터링 가능하다.
nvidia-smi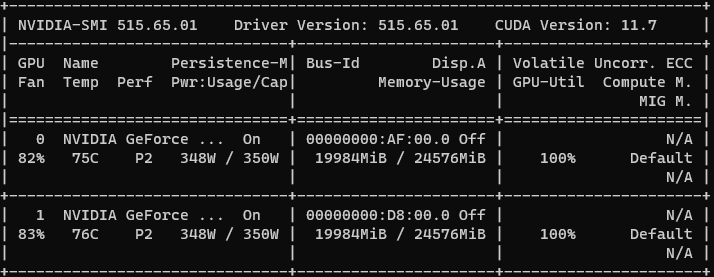

위에 창과 같이 현재 계정에 연결되어있는 (Docker, User 계정) GPU 이름, GPU에서 차지하고 있는 Process의 상태들을 모니터링 가능하다. 아래쪽 창에서 돌아가는 Processes 창을 통해서, 내가 원하는 GPU에 작업들이 할당 됐는지, 정상적으로 병렬적으로 잘 돌아가는지 확인 가능하다.
그리고 지나치게 Batch Size를 크게해서 터졌는지 내가 Parallell 한 코드를 제대로 작성했는지 등등을 확인가능하다.
특히, 오른쪽에 Volatile GPU-Util을 통해서 장착된 GPU가 놀지않고 놀고 있는지 모니터링 가능하다.
뭔가 한 에폭당 속도가 지나치게 오래걸린다 느껴진다면 아래의 명령어를 통해 감시해보자
watch -n 0.5 nvidia-smi(0.5초의 간격마다 nvidia-smi 명령어를 실행한 결과를 보여준다)
물론 방향키 윗키로 nvidia-smi를 반복하는것도 나쁘지않지만, 굳이 그럴 필요 없이 위 명령어를 통해서 모니터링 해주자. 만약에 도중에 Volatile GPU-Util이 떨어지는 현상이 발견된다면, GPU가 자리만 차지하고 도중에 돌고 있는거다. 다음 2개의 상황중 하나일 것이다.
1. DataLoader 병목현상
- Dataset을 Loading 하는 순간에 문제가 있는 것
- Pytorch 의 경우 Dataloader에서 nworkerThread 인자를 조절해주자
- Dataset이 NFS 경로상에 있지않은가? Network File System의 경로에 있는경우 속도가 굉장히 저하 된다. (NFS는 데이터들을 공유하도록 도와주는 훌륭한 도구지만, Training 시킬땐 아니다. 한시가 급하다
2. Model Multi-Branch 병목현상
- 사실 이건 Multi-Branch 모델을 정말 괴상하고 이상하게 짜지않은 이상 발생하지 않는다.
- 모델에서 Residual Branch를 잘못구현했거나
- Attention 을 계산하는 과정에서 이상이 없는지
- DDP (Distributed Data Parallel) 을 정말 잘 활용했는지 추적하자.
NVIDIA-SMI 명령어가 없는데요!?
일단 대체품 gpustat을 활용해봅시다.
pip install gpustat
gpustat
Nvidia-smi 보다 훨씬 이쁘게 잘나온다.
watch -n 0.5 gpustat위 명령어를 통해서 감시해주고, 문제상황을 유추해보자
CUDA_VISIBLE_DEVICES
Tensorflow, Pytorch 모두 CUDA Backend 를 활용하여 Trianing을 진행한다. 처음 Deep Learning Framework들을 다루다보면 CUDA Version Issue를 다양하게 맞이할 수 있다.
어쨌건 우리가 GPU를 활용하여 Training을 활용하려면 CUDA 관련된 변수들을 조절해 줄때가 있다.
그중, CUDA_VISIBLE_DEVICES는 여러분들이 공용으로 쓰는 서버 GPU에서 민폐를 끼치지않도록 도와주는 하나의 강력한 도구가 될 것이다.
CUDA_VISIBLE_DEVICES : 현재 실행할 프로그램에서 사용한 GPU를 강제지정 할 수 있다.
Default 값은 연결된 모든 GPU 이기 때문에, 4대의 GPU가 연결되어있다면 모든 GPU에 연결시켜서 프로그램을 실행시킬 수 있다. 하지만, 가령 2대의 GPU만 써야한다면 어떻게 해야할까?
os.environ['CUDA_VISIBLE_DEVICES'] = '0, 1'
이런식으로 조정을 해줄 수 있겠지만, 간단하게 아래와 같은 방법으로 설정 가능하다.
CUDA_VISIBLE_DEVICES=2,3 python ./trian.py 위와같이 python 실행명령어 대신 CUDA_VISIBLE_DEVICES 를 적어준다면 (어떤 환경변수든) 환경변수를 export 하지않아도 실행할 때, 변경된 환경변수로 실행시켜 줄 수 있다.
OMP_NUM_THREADS OPENBLAS_NUM_THREADS
해당 사항은 이번주 Training 도중에 처음 겪은 현상이다.
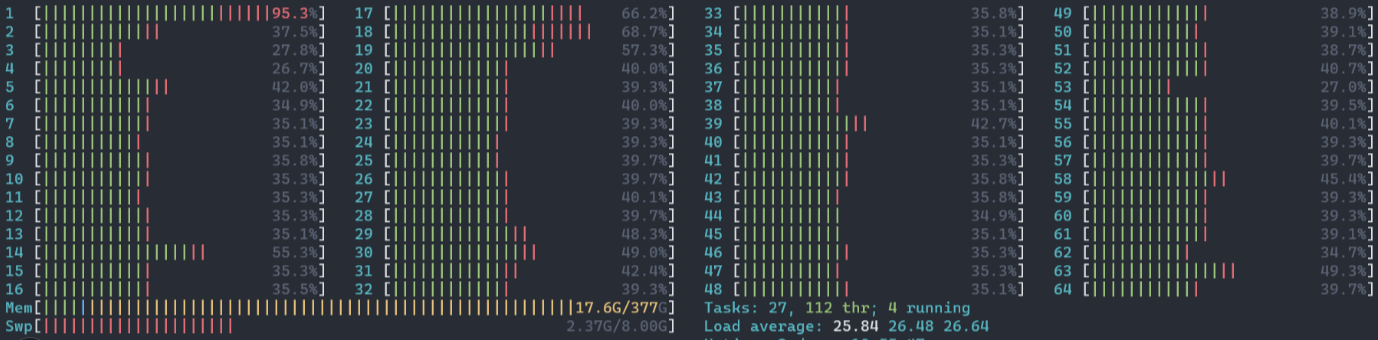
어떤 모델에서 AM_Softmax Loss function을 활용하는 일이 있었는데, 위와 같이 비정상적인 CPU 사용률을 보여줬다. 다음과 같은 명령어로 사용중인 코어수를 안정화 시킬 수 있다.
OMP나 OpenBLAS 연산을 활용하는게 Training 중간에 포함되어있을 경우, 다음과 같이 비정상적인 모습을 보여줄 수 있다. OMP, OpenBLAS 친구들의 기본값이 Default 이기때문에, 지나치게 사용할 수 있는 CPU 코어가 많다면 오히려 병렬적으로 처리해주는게 속도를 저해시키는 요인이 될 수 있다.
OMP_NUM_THREADS=4 OPENBLAS_NUM_THREADS=4 python ./train.py
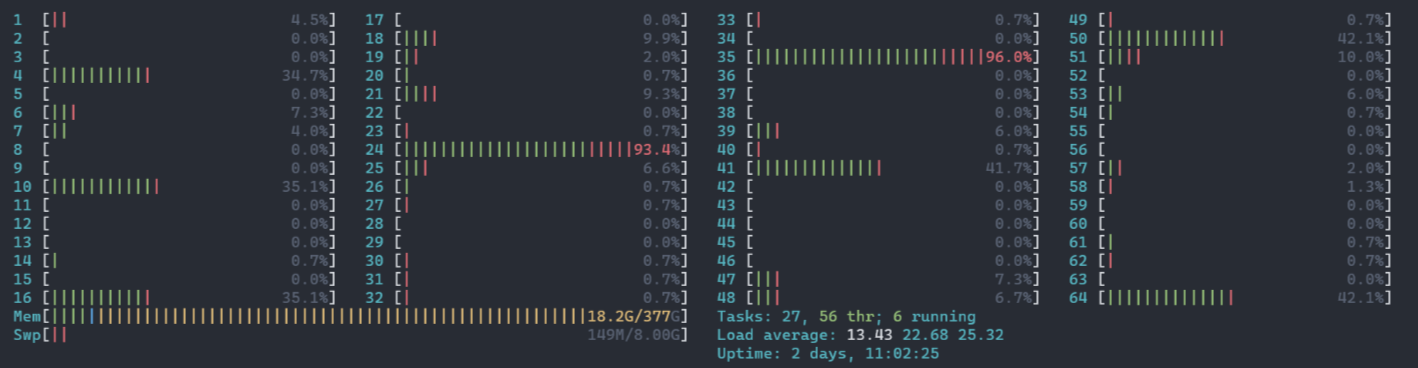
위 명령어를 실행하면 위와 같이 평안을 얻은 코어들과 퍼포먼스 이슈가 없는 프로세스들을 프로파일링 할 수 있다.
결론
Training 효율적으로 잘시키기 어렵다. 내가 못놀고 있는데 GPU들이 놀고있는 꼴은 더더욱 못보기 때문에 위요인들을 고려하여 최고의 퍼포먼스를 뽑아낼 수 있도록 합시다!
