1. Problem
2. Solution
- Solution 1
import sys
N = int(sys.stdin.readline())
lst1 = set(map(int, sys.stdin.readline().split()))
M = int(input())
lst2 = list(map(int, sys.stdin.readline().split()))
result = []
for i in lst2:
if i in lst1:
result.append(1)
else:
result.append(0)
print(*result)- Solution 2 -> Binary Search algorithm 이용
import sys
def binary_search(lst1, target, start, end):
while start <= end:
mid = (start + end) // 2
if lst1[mid] == target:
result.append(1)
return
elif lst1[mid] > target:
end = mid - 1
else:
start = mid + 1
result.append(0)
return
N = int(sys.stdin.readline())
lst1 = list(map(int, sys.stdin.readline().split()))
M = int(input())
lst2 = list(map(int, sys.stdin.readline().split()))
result = []
lst1.sort()
for e in lst2:
binary_search(lst1, e, 0, N - 1)
print(*result, end=' ')
3. Detail
solution 1을 살펴보자.
for i in lst2:
if i in lst1:
result.append(1)
else:
result.append(0)lst2와 같은 크기의 list result를 만든 후 lst1 list 안의 값들이 lst2 list에 포함되어 있다면 해당 index 값을 1을 추가, 포함되어 있지 않다면 0을 추가한다.
solution 2는 binary search를 사용하여 풀었다.
* Binary Search Algorithm Example
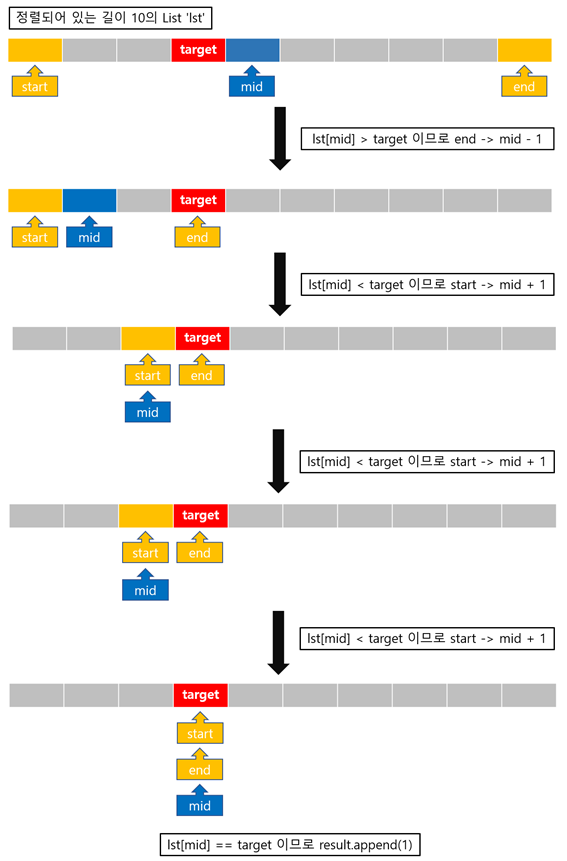
Binary search algorithm을 python code로 작성하면 아래의 code와 같다.
def binary_search(lst1, target, start, end):
while start <= end:
mid = (start + end) // 2
if lst1[mid] == target:
result.append(1)
return
elif lst1[mid] > target:
end = mid - 1
else:
start = mid + 1
result.append(0)
returnwhile문으로 end가 start 보다 크거나 같을 때 동안 반복되고, start가 end보다 커지면 멈추도록 한다. 초기에 start와 end 값은 각각 lst1의 첫 번째 index의 값, lst1의 마지막 index의 값이 된다. 그 후 start와 end의 중간 값인 mid를 구한다. 만약 짝수를 2로 나누어 중간 값을 구하는 경우에는 몫을 나타낸다. 그다음으로 lst1[mid] 값을 구하여 찾고자하는 값인 target과 비교하여 lst1[mid] == target의 경우에는 lst1에 원하는 target 값이 존재한다는 의미이기 때문에 result에 1을 추가한다. 만약 lst1[mid]가 target보다 크다면 mid index보다 좌측에 위치해야하기 때문에 end point를 mid - 1로 변경한다. 또는 lst1[mid]가 target보다 작다면 mid index보다 우측에 위치해야하기 때문에 start point를 mid + 1로 변경한다. 조건식 start <= end를 만족하는 동안에는 while문이 반복되고, start > end가 되는 순간 lst1 안에 target 값이 없다는 의미이므로 result에 0을 추가해준다.
result = []
lst1.sort()
for e in lst2:
binary_search(lst1, e, 0, N - 1)Binary search를 사용하기 위해서 list의 값은 정렬되어있어야 하므로 lst1.sort()로 lst1를 정렬한다. 그 후 binary_search() 함수를 이용하여 lst2의 element : e의 값이 lst1 list 안에 존재하는지 판별하여 존재한다면 result list에 1을 추가하고, 존재하지 않는다면 0을 추가한다. For문이 모두 돌고나면 result list에는 lst2의 값에 대해 존재 여부를 나타내는 값이 0 or 1로 저장되어 있다. 이를 python asterisk '*'를 이용하여 result 내의 값들을 분해하고, 한줄로 공백을 기준으로 순서대로 출력한다.
Tip
-
for i in range(n):와 같이range()를 사용하는 경우에는 index를 의미하는i를 사용하는 것이 권장되고,for e in lst2:와 같은 경우 index가 아니라 element를 받으므로e를 사용하는 것이 권장된다. -
set()자료형은 중복되는 element가 없게 하고, 순서가 없기 때문에list와tuple과 다르게 indexing이 불가능하다.set자료형이list자료형보다 빠르다는 특징도 있다.set자료형을list또는tuple로 변환하면 indexing이 가능해진다.
