[next.js_app-router] SEO 적용하기
블로그 이전을 위해 레이아웃 구성 후, SEO 작업을 시작하기로 했다!
SEO의 개념을 알고는 있었지만 실제로 적용해본 적은 없어서 적용하면서 배운내용 정리한다!
SEO란 ?
Search Engine Optimization 검색엔진 최적화의 약어
검색 엔진 최적화는 웹 사이트나 웹 페이지가 검색 엔진에서 높은 순위를 차지하도록 최적화하는 데 사용된다.
지금 개발블로그를 만들기 때문에, 유저들이 검색했을 때 노출이 필요한 경우에는 SEO 설정을 잘 해놔야 검색이 잘 되는것!
page title, description 의 중요성
페이지의 title과 description 은 SEO에 중요한 역할을 한다.
• 페이지의 제목은 <title> 태그 안에 작성되며, 페이지의 설명은 <meta name="description"> 태그 안에 작성된다.
• 페이지의 제목과 설명은 페이지의 내용을 간략하게 설명하고, 검색 엔진에서 페이지를 검색할 때 사용된다.
• 페이지의 제목과 설명은 동적으로 생성할 수도 있으며, 정적인 메타데이터를 사용할 수도 있다.
• 페이지의 제목과 설명은 각 페이지마다 설정해주어야 하며, 기본값을 설정해둘 수도 있다.
next.js version (13.2)
블로그에 사용 된 next.js 버전은 App Router를 사용하는 13.2 버전을 사용중이였다.
12버전까지는 head.tsx 파일이 존재해서 따로 정의를 해주면 되었지만 13.2 버전부터는 적용방식이 바뀌었다.
1. 정적 페이지에서 사용 할 정적 메타데이터 생성
모든페이지에 적용할 metadata는 최상위 루트에 있는 layout.tsx 파일에다가 적용시킨다.

layout.tsx 적용하기
export const metadata: Metadata = {
title: {
default: 'moon_develog',
template: '%s | moon_develog',
},
description: 'moon_develog',
};template을 위와 같이 설정하게 된다면 동적으로 페이지의 타이틀이 생성된다.
%s 에는 각 페이지에서 내보내는 metadata의 title 값이 들어가게 된다.
만약 template 설정이 없다면 각 페이지에서 내보내는 metadata의 title이 들어가고
페이지에서 내보내는 title이 없다면 default 값이 들어간다.
2. 동적 페이지에서 사용 할 동적 메타데이터 생성
generate_datadata 비동기 함수 이용하기
동적인 페이지의 메타데이터를 생성하기 위해서는 generate metadata라는 비동기 함수를 사용해야 한다.
이 함수는 서버컴포넌트에서만 사용해야 한다.
- generate metadata 함수는 params라는 인자를 받는다.
- params에는 slug라는 문자열이 포함되어 있으며, 이를 통해 데이터를 받아올 수 있다.
- generate metadata 함수는 try-catch 문을 사용하여 예외 처리를 할 수 있다.
동적으로 seo 타이틀 바꾸기
export async function generateMetadata({ params }: Props): Promise<Metadata> {
const post = await getPost(params.slug);
if (!post)
return {
title: 'Not Found',
description: 'The page is not found',
};
return {
title: post.title,
description: post.content,
};
}3. 표준 URL 지정하기
웹 페이지의 HTML 소스 코드에서 사용되는 메타 태그 중 하나로, 검색 엔진에게 주요 콘텐츠 페이지 중 하나를 지정하는 데 사용된다.
?data=1 과 같이 파라미터에 따라 다른 페이지가 표시될 때
검색엔진은 이를 콘텐츠가 유사한 다른페이지로 인식해서 동일한 페이지의 중복버전으로 간주하게 된다.
이런 경우 캐노니컬 태그를 적용하지 않으면 원본 URL을 판단하여 적용해 중복되는 다른 페이지들을 덜 크롤링 하게 된다.
아래와 같이 canonical 옵션을 지정할 수 있다.
- root layout에 base matadata를 설정해준다 (공통으로 적용 될 부분)
- 각 페이지에서 metaData를 생성할 때 지정해준다.
// layout.tsx
export const metadata: Metadata = {
metadataBase: new URL(BASE_URL),
...
}
// post/[id].tsx
export async function generateMetadata({ params }: Props): Promise<Metadata> {
const post = await getPost(params.slug);
return {
...,
alternates: {
canonical: `/post/${post.id}`,
},
};
}
reference
4. ImageResponse를 이용해 icon, og 설정
Icon 만들어주기
원하는 페이지마다 icon.tsx 파일을 생성해서
ImageResponse 를 이용해 아이콘을 만들어 줄 수 있다.
//app/post/[slug]/icon.tsx
import { ImageResponse } from 'next/server';
export const size = {
width: 32,
height: 32,
};
export const contentType = 'image/png';
export default function icon() {
return new ImageResponse(
(
<div
style={{
fontSize: 24,
backgroundColor: 'black',
color: 'white',
width: '100%',
height: '100%',
display: 'flex',
justifyContent: 'center',
alignItems: 'center',
borderRadius: '50%',
}}
>
M
</div>
),
size
);
}
OpenGraph-Image를 JSX 태그로 만들 수 있다!
커스텀 Open Graph 이미지를 생성하기 위해서는 함수를 정의해서 사용할 수 있다.
각 페이지에 동적으로 적용하고 싶은 내용이 있다면,
아래와 같이 css와 함께 적용시켜 커스텀이미지를 생성할 수 있다.
//app/post/[slug]/opengraph-image.tsx
import { getPost } from '@/api/post/getPost';
import { ImageResponse } from 'next/server';
export const size = {
width: 900,
height: 450,
};
export const contentType = 'image/png';
interface Props {
params: {
slug: string;
};
}
export default async function og({ params }: Props) {
const post = await getPost(params.slug);
return new ImageResponse(
(
<div
style={{
fontSize: 24,
backgroundColor: 'black',
color: 'white',
width: '100%',
height: '100%',
display: 'flex',
justifyContent: 'center',
alignItems: 'center',
flexDirection: 'column',
gap: 12,
}}
>
<div
style={{
fontWeight: 'bold',
}}
>
{post.title}
</div>
<div
style={{
fontSize: 14,
}}
>
moon_develog
</div>
</div>
),
size
);
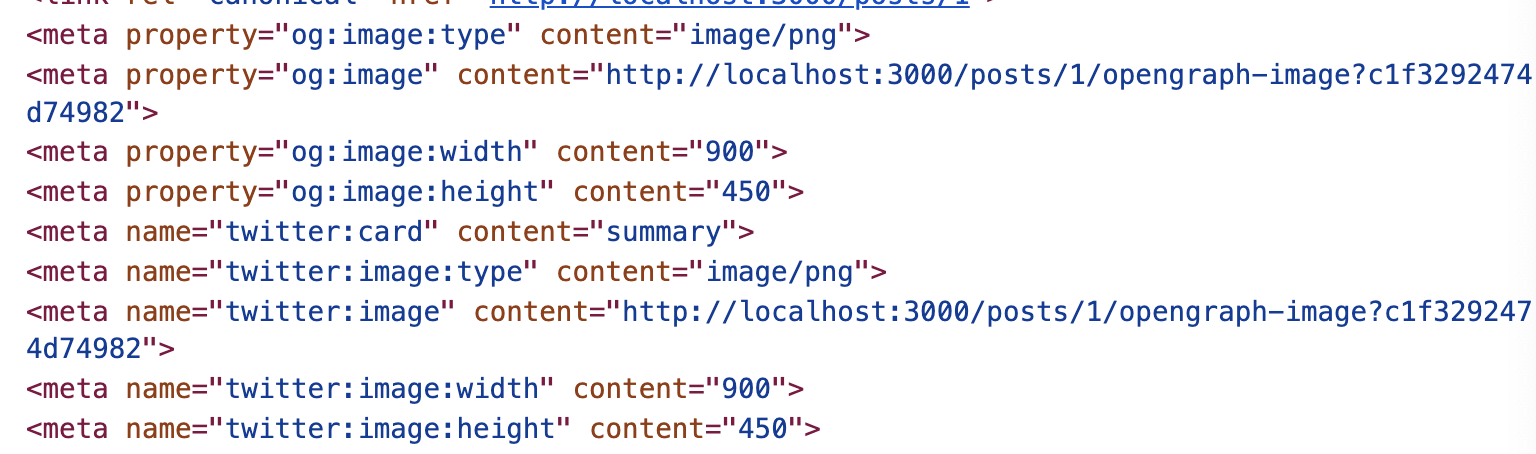
}적용 된 썸네일

head 태그에 og 관련 된 태그들이 추가 된 걸 볼 수 있다!
robots 설정
Robots는 웹 크롤러 봇, 주로 검색 엔진 크롤러가 웹 사이트를 방문할 때 어떤 페이지를 크롤링할 수 있는지와 어떤 페이지를 크롤링하지 말아야 하는지를 지정하는 파일이다.
Next.js의 문서를 참조하면 robots.txt 파일을 생성하는 세 가지 옵션이 있다.
• 첫 번째 옵션은 앱 디렉토리 내에 robots.txt 파일을 생성하고 해당 파일에 로봇 설정을 넣는 것이다.
• 두 번째 옵션은 robots.ts 파일을 생성하고 TypeScript 파일로 만든 뒤 로봇 설정을 포함한 객체를 반환하는 것이다.
• 세 번째 옵션은 페이지의 metadata 객체 내에서 로봇 설정을 포함한 객체를 반환하는 것이다.
크롤링 되지 않았으면 하는 페이지가 있어요!
해당 페이지에 아래와 같이 설정해놓으면 메타 테그가 설정되지 않도록 할 수 있다.
// page.tsx
robots:{
index : false,
nocache : true
}페이지에 설정하면 헤드 태그 안에 robots meat 태그가 생긴다.
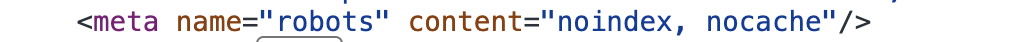
두번째 옵션으로 생성한 robots.ts 파일
// robots.ts
import { MetadataRoute } from 'next';
export default function robots(): MetadataRoute.Robots {
return {
rules: {
userAgent: '*',
allow: '/',
disallow: '/private/',
},
sitemap: 'https://moon-develog.vercel.app/sitemap.xml',
};
}sitemap
웹 사이트의 페이지 및 컨텐츠 구조를 검색 엔진에 알려주는데 사용된다.
아래 함수를 이용해서 모든 동적 페이지를 가져올 수 있고 이렇게 하면 사이트맵이 자동으로 생성되어 로봇이 웹페이지의 색인을 생성하고 구글에서 더 쉽게 순위를 매길 수 있게 한다.
아래와 같이 동적으로 url 을 정의할 수 있다.
// sitemap.ts
export const BASE_URL = `${process.env.NEXT_PUBLIC_BASE_URL}`;
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const _posts = await getPosts();
const _postsUrl = _posts.map((post: BlogData) => ({
url: `${BASE_URL}/posts/${post.id}`,
lastModified: post.date,
}));
return _postsUrl;
}결과

위 내용을 적용해서 light house의 검색엔진 최적화 점수를 올릴 수 있었다 😄
code
적용 된 코드 : https://github.com/moonseonyeong/moon-develog
