S3 개요
- S3는 AWS를 구성하는 핵심 요소 중 하나이다.
- S3는 제한 없이 스케일을 할 수 있는 스토리지로 알려져있다.
- 많은 웹 사이트 들은 AWS S3를 백본(중요한 인프라, 기반)으로 사용하고 또 많은 AWS 서비스들도 AWS S3를 연동해서 활용한다.
S3 Use Cases
- S3는 백업과 저장소로 활용된다. 파일을 정장할 수도 있고 디스크 역할도 해준다.
- 재해 복구 용도로 사용된다.
- 꽤 저렴한 비용.
- 하이브리드 클라우드 스토리지. 온프레미스 스토리지가 있는데 클라우드로 확장하고 싶다면 AWS S3를 이용하면 된다.
- 애플리케이션이나 미디어, 즉 비디오 파일이나 이미지 같은 걸 호스팅할 수 있다. 또한 빅데이터 분석을 위한 큰 용량의 데이터 저장.
- 소프트웨어 업데이트
- 정적 웹사이트 호스팅
S3 Buckets
-
S3는 파일을 버킷에 저장한다. 버킷은 최상위 디렉토리 같은 거라고 보면 된다. 이 S3 버킷에 저장되는 파일을 "오브젝트" 라고 부른다.
-
버킷 이름은 전역적으로 고유한 이름이어야 한다. 즉, 가지고 있는 계정에 속한 모든 리전을 통틀어 고유해야 하면서 또 AWS에 있는 모든 계정을 대상으로도 고유해야 한다. --> AWS (리전) 에서 전역적으로 고유해야 하는 유일한 항목이 바로 S3다.
-
버킷은 리전 단위로 정의가 된다. --> 특정 리전 안에서 생성 되는 것이다.
S3 Objects
- 오브젝트는 파일을 뜻하며, 각각의 파일들은 키를 가진다. AWS S3에 저장되는 오브젝트의 키는 해당 파일의 전체 경로(Pull Path)이다.
- S3에서는 디렉토리라는 개념은 없으며, 무엇이든지 간에 전부 키로 구성된다.
키는 접두사랑 오브젝트 이름으로 구성된다. - 모든 오브젝트는 S3의 버킷에 저장된다.
- 우리는 무엇이던지 S3에 올릴 수 있다. 최대 5TB 짜리 오브젝트를 올릴 수 있다. 이걸 초과하면 멀티파트로 업로드 해야한다. 여러조각으로 나눠서.
- 오브젝트는 메타데이터를 키-값 형태의 목록으로 가진다. 이것은 파일의 어떤 요소를 명시하기 위한 것.
S3 Security
전체적으로 사용자 역할, 버킷 정책, 오브젝트 암호화 이렇게 3가지 있다고 보면 된다.
- 사용자 기준
- (IAM 정책) 사용자에겐 IAM 정책을 적용하는데, IAM 정책이 정의하는 건 어떤 API가 어떤 IAM 사용자에 의해 호출될 수 있는가이다.
- 리소스 기준
- (버킷 정책) 신규 기능, 여러 버킷에 적용되는 규칙을 S3 콘솔에서 바로 설정 가능하다. 이 규칙은 특정 사용자에게 이용을 허용하거나 또 다른 계정 사용자를 허용 가능하다. S3 버킷을 대상으로 교차 계정 액세스가 가능하다. 이걸 이용해서 S3 버킷을 공개 가능하다. 가장 일반적인 방식
- (ACL : Object Access Control List) 세밀하게 보안을 관리하는 장치. 비활성화 시킬 수도 있다.
- (ACL : Bucket Access Control List) 버킷 단위에서 관리하기 위해 버킷 ACL을 반들기도 한다. 흔한 방법 X
IAM 정책으로 S3 오브젝트에 접근할 수 있는 건 언제인가?
- IAM 권한이 허용으로 돼 있거나 리소스 정책이 허용으로 돼 있거나, 접근 거절 액션이 명시 돼 있지 않다면 API 호출 시 정책에 기반해 S3 오브젝트에 접근 가능하다.
- 암호화 - 암호화 키를 이용해 오브젝트를 암호화 하는 방식
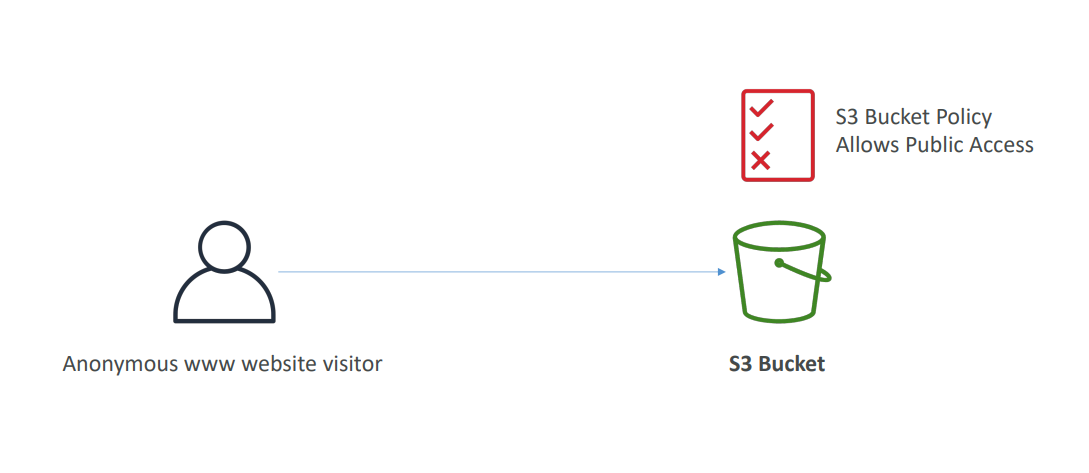
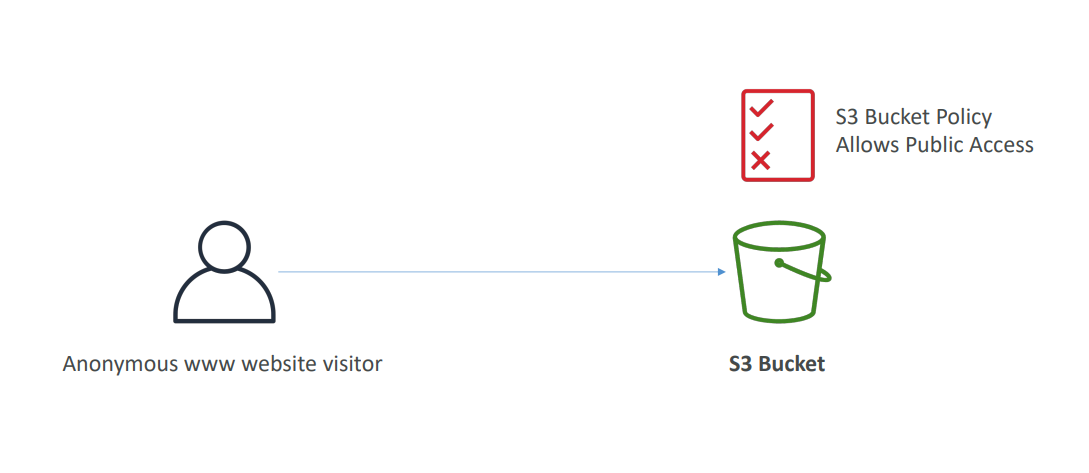
S3의 Bucket에 public access가 허용되어있으면 www 웹사이트로 S3dp 접근 가능

IAM 사용자에게 권한 (S3 getObject 같은 권한)이 있으면 S3에 접근 가능

EC2 인스턴스의 Role에 S3의 Bucket에 접근 가능한 권한이 있으면 S3에 접근가 능

S3의 Bucket 정책을 사용자 별로 교차적으로로 접근 가능하게 할 수 있다. 특정 AWS계정에 대한 특정 사용자는 허용, 특정 사용자는 불가
S3 Versioning
- S3에 업로드되는 오브젝트들의 버전을 관리하는 기능이다. 이 설정은 버킷 단위에서 설정해줘야한다.
- 사용자가 파일을 S3 Bucket에 업로드 하게 되면, 같은 파일의 경우 자동으로 v1,v2 이런식으로 업로드 된다. 이 기능을 활성화 해두는게 좋다. 이유는 의도치 않게 파일을 삭제하는 것을 잘 막아준다.
S3 Replication (CRR & SRR)
S3에는 2가지 복제 기능이 있다.
- CRR (Cross Region Replication) - 리전 간 복제
- SRR (Same Region Replication) - 동일 리전 복제
설정을 해주면, 각각의 기능에 따라 복제를 비동기 적으로 진행한다.
S3 Storage Classes
내구성과 가용성의 개념을 파악하자
내구성 (Durability) - S3로 인해 오브젝트가 손실될 수 있는 확률이다. 99.999999% 확률로 손상안됨.
가용성 - 얼마나 쉽게 서비스를 이용할 수 있느냐. 이것도 99.9% 이상의 확률이다. 클래스마다 약간다름.
스토리지 종류와 목적
-
Amazon S3 Standard - General Purpose
- 내구성 : 99.99% , 자주 액세스 하는 데이터용 , 기본값으로 사용하는 스토리지 유형, 지연 시간이 짧고 처리량이 많다.
- 두 곳에서 발생하느 동시 기능 장애를 감달 할 수 있어서 빅데이터 분석과 모바일 및 게임 애플리케이션 콘텐츠 배포의 사용 사례에 적합하다.
-
Amazon S3 Standard-Infrequent Aeccess (IA)
- 자주 액세스하지 않지만, 필요할 때 빠르게 액세스 가능. Standard보다는 요금이 저렴하지만, 검색 요금이 추가로 발생한다.
- 재해 복구와 백업에 이상적이다.
-
Amazon S3 One Zone-Infrequent Access
- 단일 AZ(가용영역)에서 내구성이 높지만(99.999999%), 가용영역이 파괴되면 데이터가 손실될 수 있다. 가용성 (99.5%)
- 온프레미스 데이터나 다시 생성 가능한 데이터의 보조 백업 복사본 저장에 적합하다.
-
Amazon S3 Glacier Instant Retrieval
- 밀리초 단위의 검색 가능, 분기에 한 번 데이터에 액세스할 때 적합하다.
- 밀리초 내에 액세스가 필요한 백업에 이상적이다.
- 최소 스토리지 기간은 90일
-
Amazon S3 Glacier Flexible Retrieval
- 유연한 무료 검색 기능을 제공한다.
- 1~5분의 빠른 검색과 3~5시간의 표준 검색, 5~12시간의 무료 대량 검색 중 선택 가능하다.
- 최소 스토리지 기간은 90일
-
Amazon S3 Glacier Deep Archive
- 2가지 옵션 -> 12시간의 표준 옵션과 48시간 대량 옵션
- 검색 시간이 아주 많이 들지만 가장 저렴하게 이용 가능하다.
- 최소 스토리지 기간은 180일
-
Amazon S3 Intelligent Tiering
- 사용 패턴을 기반으로 액세스 계층 간에 오브젝트를 이동시킨다.
- 매월 모니터링과 자동화 요금이 발생한다.
- 검색 요금은 발생하지 않는다.
- Frequent Access 계층에 오브젝트를 자동 저장하고, 30일 동안 액세스하지 않은 오브젝트는 Infrequent Access 계층에 이동된다. 90일 동안 액세스 하지 않으면 Archivce Instant Access 계층으로 이동된다. (여기는 자동)
- 90~700++일 동안 액세스하지 않은 오브젝트는 Archive Access 계층으로 이동 설정 가능하다. 180~700일 동안 액세스하지 않은 오브젝트는 Deep Archive Access 계층으로 이동하게 설정 가능하다. (여기는 옵션)
( Glacier 클래스 ) : 아카이브와 백업에 적합한 저비용 오브젝트 스토리지이다. 스토리지 비용에 검색 비용이 포함되어있다.
AWS S3에서 오브젝트를 선택할때 클래스를 선택할 수 있다. 스토리지 설정을 수동으로 구성할 수 있고, S3 수명 주기 구성을 이용해서 모든 스토리지 클래스 간에 오브젝트를 자동으로 이동시킬 수 도 있다.
S3 Encryption
-
서버측 암호화 (Server Side Encryption) - 기본적으로 버킷을 생성하거나 오브젝트를 올릴 때마다 암호화는 적용된다. 사용자가 파일을 S3에 업로드하면 보안을 위해 S3가 암호화시킨 상태로 저장된다. 암호화를 서버가 수행하기 떄문에 서버측 암호화라고 한다.
-
클라이언트측 암호화 (Client Side Encryption) - 사용자가 파일을 업로드 하기 전에 직접 암호화 하는 것이다.

이 2가지 방식은 AWS에 존재하지만, 서버측 암호화는 항상 기본적으로 활성화 되어있다.
S3 IAM Access Analyzer
- S3 버킷을 모니터링하는 기능.
- 의도된 대로 접근을 허용한 사람만 S3 버킷에 접근할 수 있나를 본다.
- 버킷 규칙이랑 S3 ACL이랑 S3 액세스포인트 규칙이랑 분석을 한다. 그리고 어떤 버킷이 퍼블릭 액세스가 가능한지 또 어느 버킷이 다른 AWS 계정과 공유가 됐는지 등을 본다. 이걸 통해 User 가 판단.
S3 공동 책임 모델
AWS
- 인프라에 대한 모든 책임
- S3 -> 내구성, 가용성
User
- S3 버전 관리를 잘하고 올바른 S3 버킷정책을 설정함으로써 데이터 손실 방지
- 복제 잡업이 필요하면 직접
- 로깅,모니터링은 선택사항이니 User가 자첵저긍로 활성화해야함
- 스토리지 클래스를 사용하는 것도 사용자 본인의 책임
- 어떤 암호화 할건지
AWS Snow Family
이는 AWS 내에서 "두 가지 사용 사례" 를 가진 매우 안전한 휴대용 장치이다.
엣지에서 데이터를 수집 및 처리하거나 AWS 내부 및 외부로 데이터를 마이그레이션하는 데 사용된다.
첫번째, 데이터 마이그레이션
- Snowcone
- 거대한 박스 이며, 테라바이트 또는 페타바이트의 데이터를 AWS 안팎으로 이동시키는 데 사용될 것이다. 네트워크를 통해 데이터를 이동하는 것의 대안이 될 것이다. 페타바이트 규모의 데이터를 이동하는데 적합. PB 데이터
- Snowball Edge
- 매우 작은 휴대용 장치이며 견고하다. 안전하고 열악한 환경을 견딜 수 있으며 데이터 양이 적은 환경에 적합하다. 가볍고 2.1kg정도된다. 원하면 드론에도 장착가능
- Snowmobile
- 실제 트럭이다. 엑사바이트 규모의 데이터를 전송 가능하다. 1엑사바이트는 1,000PB이고1,000,000TB 이다. 각 스노우모빌의 용량은 100PB이다.
두번째, 엣지 컴퓨팅
-
엣지 컴퓨팅이란? -> 엣지 로케이션에서 데이터가 생성되는 동안 데이터를 처리하는 것이다.
엣지 로케이션이란? -> 실제로 인터넷이 없거나 클라우드에서 멀리 떨어진 곳을 의미한다. -
따라서 연결이 제한되고 인터넷에 액세스할 수 없거나 컴퓨팅 성능에 액세스 할 수 없다는 것을 뜻함. 이러한 위치에서 데이터 처리를 계속 실행하고 싶을 수도 있다. 이를 위해서는 엣지 컴퓨팅이 필요하다.
-
엣지 컴퓨팅을 수행하려면 스노우볼 엣지 장치나 스노우콘을 주문하고 이를 엣지 로케이션에 내장하고 엣지 컴퓨팅을 시작할 수 있다. 엣지 컴퓨팅의 사용 사례는 데이터를 전처리하고 엣지에서 기계 학습을 수행하는 것이다.
-
따라서 클라우드로 돌아가지 않고도 주요 스트림을 미리 트랜스코딩하고, 필요에 따라 데이터를 다시 AWS로 전송해야 하는 경우 스노우콘 또는 스노우볼 엣지용 장치를 다시 배송할 수 있습니다.
Snowball Edge Pricing
-> 해당서비스를 사용함녀 비용은 발생한다. 다만, AWS로 데이터 이관 시엔 무료, 기가 바이트당 $0
Storage Gateway - Hybrid Cloud
지금 까지의 AWS는 독립 실행형 서비스 였으나, 하이브리드 클라우드 유형의 설정에서도 사용이 가능하다. AWS는 사용자의 온프레미스 환경과 AWS 간의 교두보를 제공하는데 바로 이를 하이브리드 클라우드라고 한다. 사용자의 인프라 중 일부는 온프레미스에 두고, 나머지는 클라우드에 존재하게 된다. 이 때 필요한 것은 "Storage Gateway" 이다.
AWS는 독점 스토리지 기술로 이전에 봤던 EFS 서비스나 NFS 프로토콜과는 다르다. 이 2가지 서비스는 클라우드 환경에서 운영되었다. 온프레미스에서 S3 데이터를 보려면 Storage Gateway를 사용해야 한다.

즉, AWS의 스토리지를 정리해보면
- EBS, 또는 EC2 인스턴스 스토어는 블록 스토리지
- EFS는 파일 스토리지
- S3 또는 Glacier는 오브젝트 스토리지
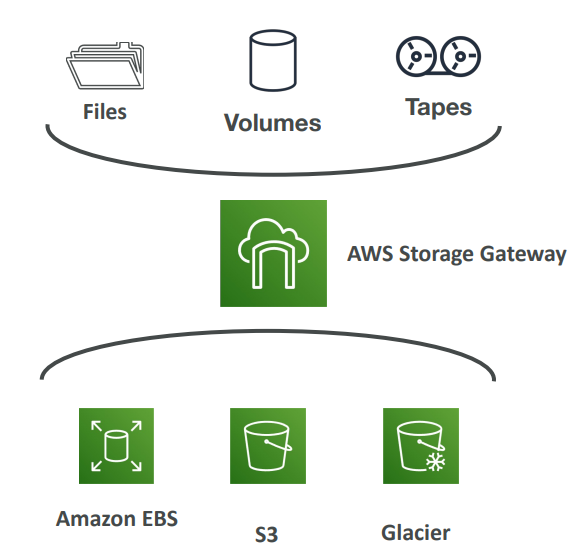
Storage Gateway의 역할은 무엇일까?
- AWS 내 사용자의 온프레미스 데이터와 클라우드 데이터를 연결해 준다. 즉 하이브리드 스토리지를 사용하여 온프레미스 시스템에서도 문제 없이 클라우드를 이용할 수 있도록 스토리지 기능을 확장하는 것이다. 이것은 재해복구나 백업,복원 혹은 스토리지 계층에 대해 활용하능하다.
S3 SUMMARY
- Buckets vs Objects : 버킷의 이름은 전역적으로 고유해야함, 또한 특정 리전에 위치한다. 오브젝트들은 버킷 안에 존재한다.
- S3 Security : 이를 위해선 사용자나 역할에 IAM 규칙을 적용할 수 있다. S3 버킷 규칙을 이용하는 방법(퍼블릭액세스, 암호화 등)도 있다.
- S3 Websites : 정적 웹사이트 호스팅 제공
- S3 Versioning : 파일을 버전 단위로 관리해서 실수로 작제하는 걸 방지, 필요에 따라 이전 버전으로 롤백 가능
- S3 Replication : 1. 동일 리전 복제 , 2. 리전 간 복제 - 뭘 하던지 버전 관리 기능을 활성화 시켜야 한다.
- S3 Storage Classes : S3의 스토리지 클래스들
- Snow Family : S3로 데이터를 임포트할 수 있는 물리적인 기기
- OpsHub : 데스크톱애플리케이션, Snow 패밀리 기기를 관리하고 데이터를 기기에 옮겨 준다.
- Storage Gateway : 온프레미스 스토리지를 S3로 확장하는 방법
