
Optimization
- A methodology to find optimum solution
- Optimization 방법 중 하나가
Gradient Descent - 다른 advanced methods를 알아보자.
SGD
- Stochastic Gradient Descent (확률적 경사 하강법)
GDupdates once with all data errors.
-> After training all dataSGDupdates parameters using an error of mini-batch.
-> After training mini-batch

SGD는 비교적 덜 정확하더라도 빠르게 목적지에 도달한다.

Momentum
-
GD는 기울기가 작은 구간에서는 느리다.
-> 완만한 곳에서도 최적화를 빨리 하고 싶다. -
Remember recent moving history.
-
업데이트 속도를 조절하기 위해 Velocity(속력 + 방향)를 사용한다.
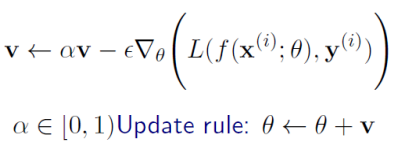
-
기존 파라미터 대신 velocity를 업데이트하고, velocity를 더한다.
-
Gradient velocity를 유지하면서, 이전 속도를 반영한다.
-
Ex. Slow 구간에서 slow 되기 전은 빨랐기 때문에 그 빠른 속도 정보를 반영한다.
-
Velocity는 계속 축적됨. 알파는 반영 가중치.
-
Momentum step + Gradient step 두 벡터를 합쳐서 반영하기 때문에,
SGD보다 빠르다.

NAG
- Nestrov Accelerated Gradient
- Nesterov Momentum
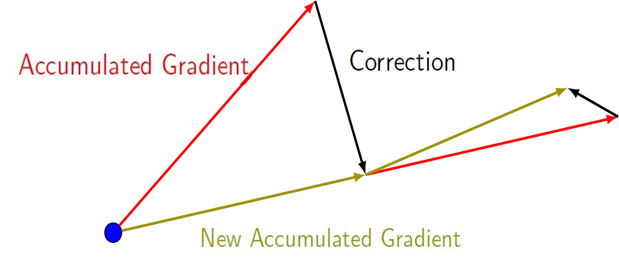
- Correlation을 사용해서 ..
- 현재 parameter에 velocity를 더한다.
- 그걸로 Loss를 구해서 업데이트를 실행한다.
- 즉, velocity를 더해서 미리 가보는 것.

AdaGrad
- Adaptive Gradient
- Gradient가 크면 경로가 지그재그 ->
SGD의 문제점을 보완하자. - Learning rate를 조절한다.

RMSProp
- Root Mean Squared Propagation
- Remember recent moving history
AdaGrad는 convex할 때는 적합. 그러나 너무 많이 반영되면 지그재그는 줄어들지만 느려질 수 있다.- 그러므로, Non-convex에도 적용할 수 있도록.

Adam
- ADAptive Moments
RMSProp+Momentum

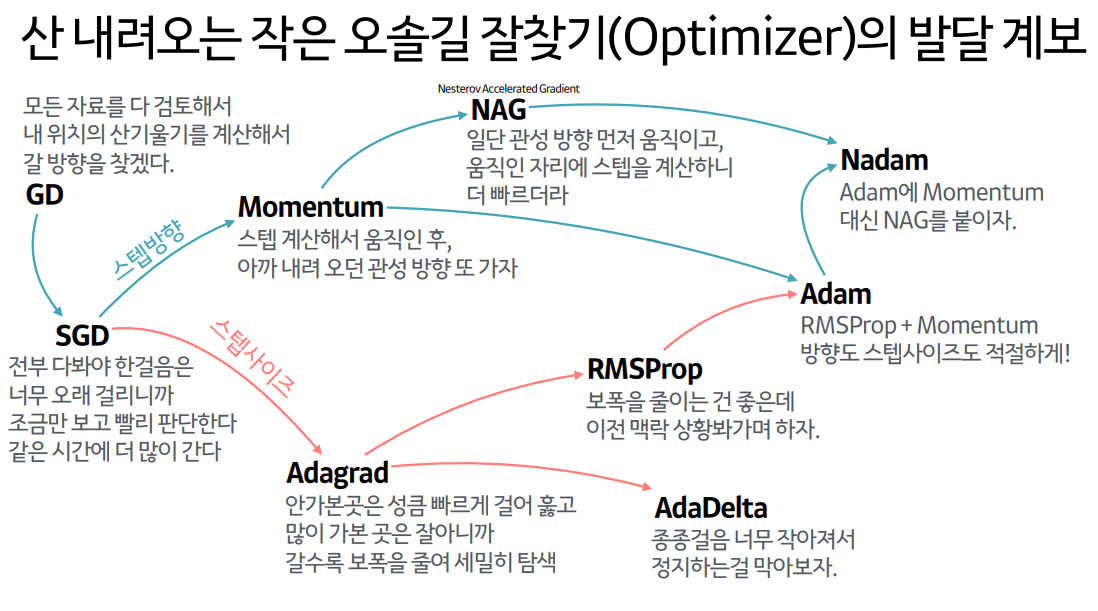
Summary

- SGD
sample examplemini batch를 가져온다. - Momentum
velocity관성 반영한다. - NAG
update parametersparameter에 velocity를 더해서 미리 가본다. - AdaGrad
accumulatelr를 조절하기 위해. 분모 생김 - RMSProp
accumulate로우 추가됨 - Adam
s, r / 로우1, 로우2 각각 나뉨
References
https://dbstndi6316.tistory.com/297

Übermensch